 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
High-Resolution Virtual Try-On with Misalignment and Occlusion-Handled Conditions
Jun 28, 2022
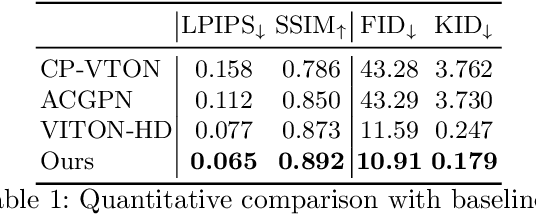
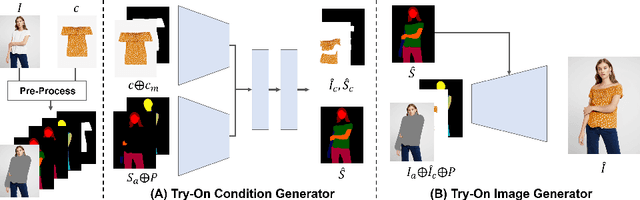
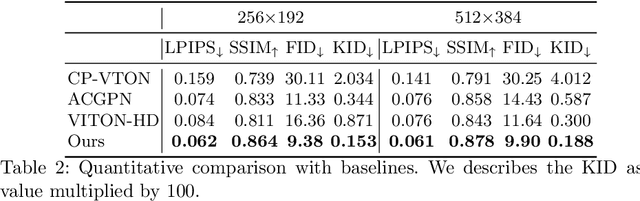
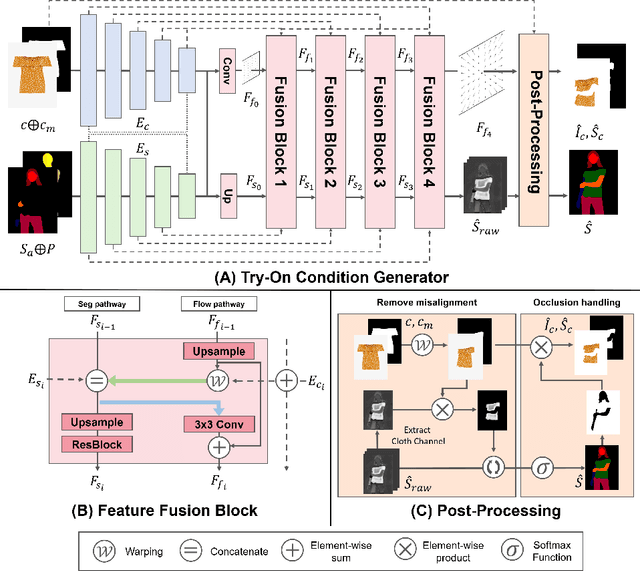
Image-based virtual try-on aims to synthesize an image of a person wearing a given clothing item. To solve the task, the existing methods warp the clothing item to fit the person's body and generate the segmentation map of the person wearing the item, before fusing the item with the person. However, when the warping and the segmentation generation stages operate individually without information exchange, the misalignment between the warped clothes and the segmentation map occurs, which leads to the artifacts in the final image. The information disconnection also causes excessive warping near the clothing regions occluded by the body parts, so called pixel-squeezing artifacts. To settle the issues, we propose a novel try-on condition generator as a unified module of the two stages (i.e., warping and segmentation generation stages). A newly proposed feature fusion block in the condition generator implements the information exchange, and the condition generator does not create any misalignment or pixel-squeezing artifacts. We also introduce discriminator rejection that filters out the incorrect segmentation map predictions and assures the performance of virtual try-on frameworks. Experiments on a high-resolution dataset demonstrate that our model successfully handles the misalignment and the occlusion, and significantly outperforms the baselines. Code is available at https://github.com/sangyun884/HR-VITON.
Refine and Represent: Region-to-Object Representation Learning
Aug 25, 2022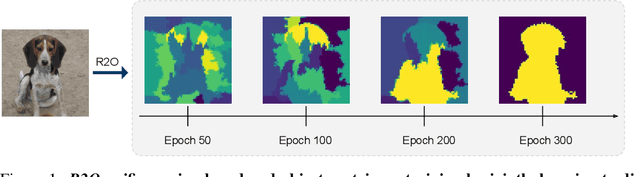
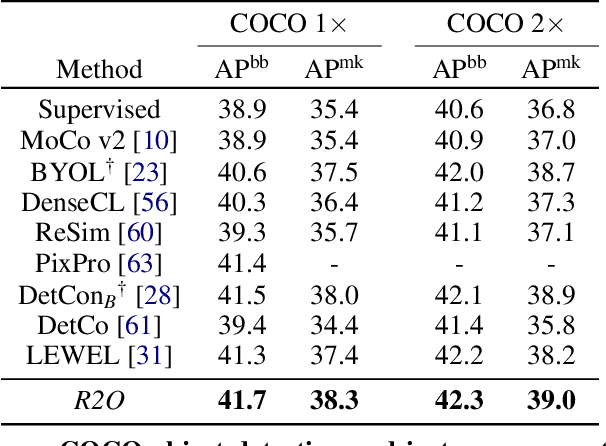
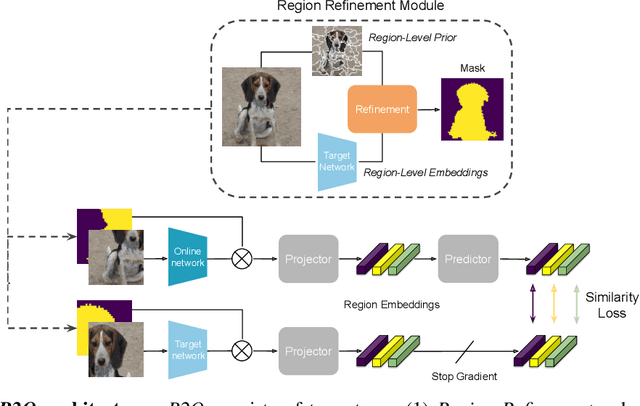
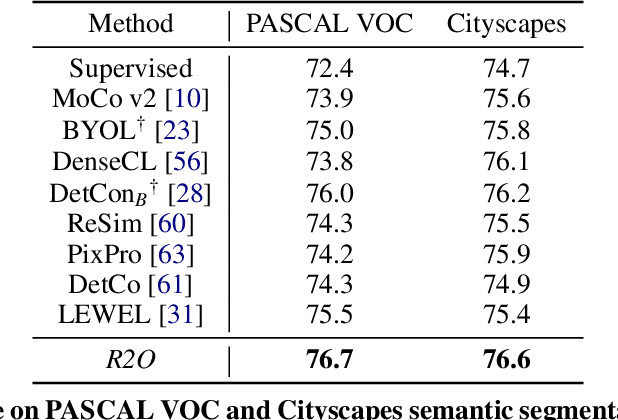
Recent works in self-supervised learning have demonstrated strong performance on scene-level dense prediction tasks by pretraining with object-centric or region-based correspondence objectives. In this paper, we present Region-to-Object Representation Learning (R2O) which unifies region-based and object-centric pretraining. R2O operates by training an encoder to dynamically refine region-based segments into object-centric masks and then jointly learns representations of the contents within the mask. R2O uses a "region refinement module" to group small image regions, generated using a region-level prior, into larger regions which tend to correspond to objects by clustering region-level features. As pretraining progresses, R2O follows a region-to-object curriculum which encourages learning region-level features early on and gradually progresses to train object-centric representations. Representations learned using R2O lead to state-of-the art performance in semantic segmentation for PASCAL VOC (+0.7 mIOU) and Cityscapes (+0.4 mIOU) and instance segmentation on MS COCO (+0.3 mask AP). Further, after pretraining on ImageNet, R2O pretrained models are able to surpass existing state-of-the-art in unsupervised object segmentation on the Caltech-UCSD Birds 200-2011 dataset (+2.9 mIoU) without any further training. We provide the code/models from this work at https://github.com/KKallidromitis/r2o.
VLMixer: Unpaired Vision-Language Pre-training via Cross-Modal CutMix
Jun 17, 2022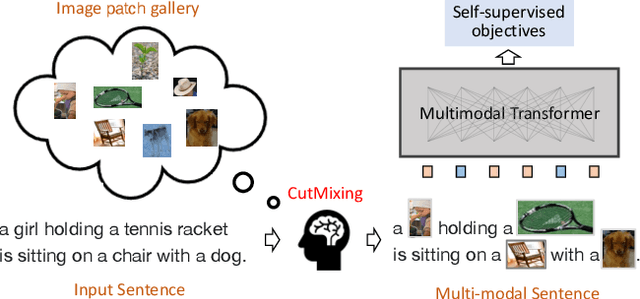
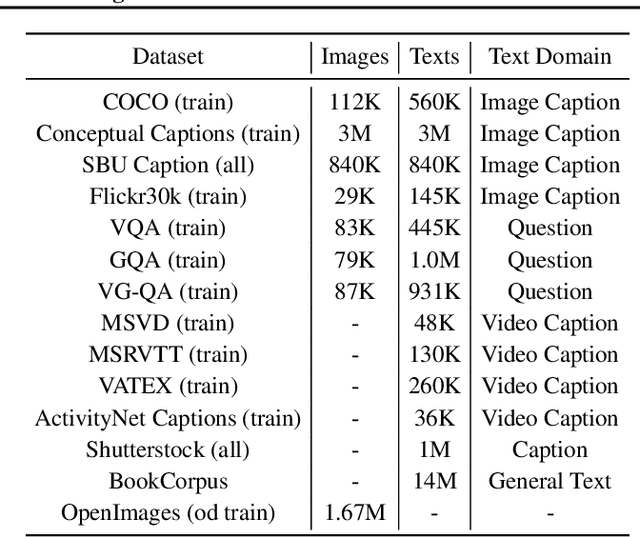
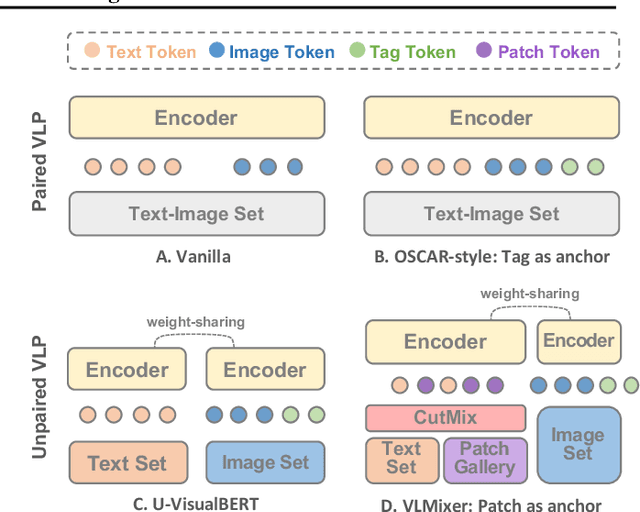
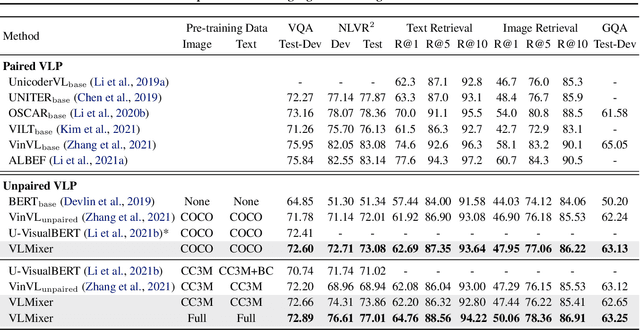
Existing vision-language pre-training (VLP) methods primarily rely on paired image-text datasets, which are either annotated by enormous human labors, or crawled from the internet followed by elaborate data cleaning techniques. To reduce the dependency on well-aligned image-text pairs, it is promising to directly leverage the large-scale text-only and image-only corpora. This paper proposes a data augmentation method, namely cross-modal CutMix (CMC), for implicit cross-modal alignment learning in unpaired VLP. Specifically, CMC transforms natural sentences from the textual view into a multi-modal view, where visually-grounded words in a sentence are randomly replaced by diverse image patches with similar semantics. There are several appealing proprieties of the proposed CMC. First, it enhances the data diversity while keeping the semantic meaning intact for tackling problems where the aligned data are scarce; Second, by attaching cross-modal noise on uni-modal data, it guides models to learn token-level interactions across modalities for better denoising. Furthermore, we present a new unpaired VLP method, dubbed as VLMixer, that integrates CMC with contrastive learning to pull together the uni-modal and multi-modal views for better instance-level alignments among different modalities. Extensive experiments on five downstream tasks show that VLMixer could surpass previous state-of-the-art unpaired VLP methods.
Federated Learning of Generative Image Priors for MRI Reconstruction
Feb 08, 2022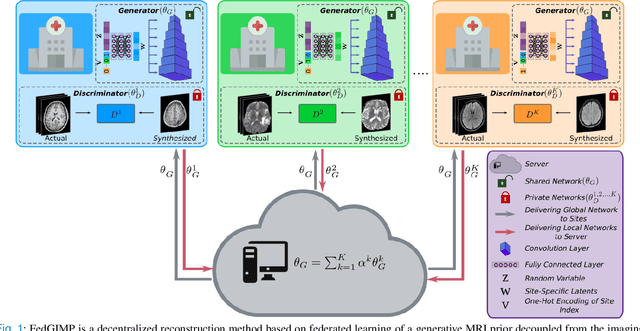
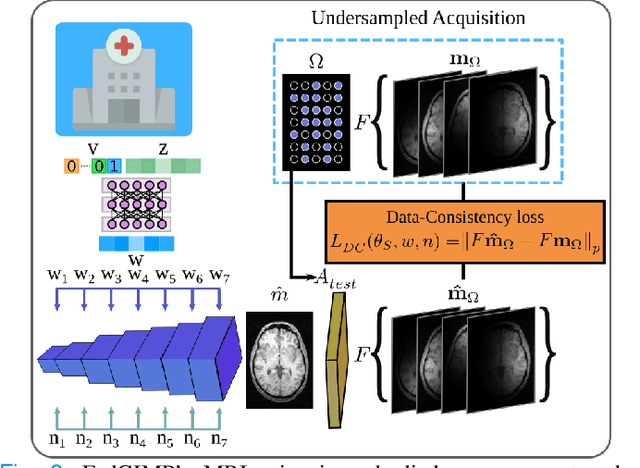
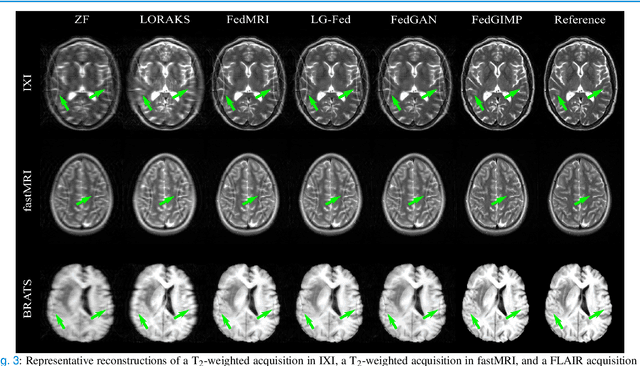
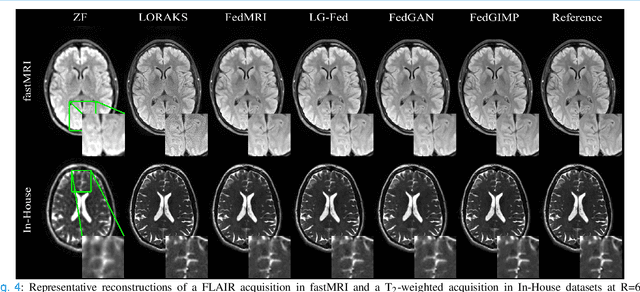
Multi-institutional efforts can facilitate training of deep MRI reconstruction models, albeit privacy risks arise during cross-site sharing of imaging data. Federated learning (FL) has recently been introduced to address privacy concerns by enabling distributed training without transfer of imaging data. Existing FL methods for MRI reconstruction employ conditional models to map from undersampled to fully-sampled acquisitions via explicit knowledge of the imaging operator. Since conditional models generalize poorly across different acceleration rates or sampling densities, imaging operators must be fixed between training and testing, and they are typically matched across sites. To improve generalization and flexibility in multi-institutional collaborations, here we introduce a novel method for MRI reconstruction based on Federated learning of Generative IMage Priors (FedGIMP). FedGIMP leverages a two-stage approach: cross-site learning of a generative MRI prior, and subject-specific injection of the imaging operator. The global MRI prior is learned via an unconditional adversarial model that synthesizes high-quality MR images based on latent variables. Specificity in the prior is preserved via a mapper subnetwork that produces site-specific latents. During inference, the prior is combined with subject-specific imaging operators to enable reconstruction, and further adapted to individual test samples by minimizing data-consistency loss. Comprehensive experiments on multi-institutional datasets clearly demonstrate enhanced generalization performance of FedGIMP against site-specific and federated methods based on conditional models, as well as traditional reconstruction methods.
Distributed Image Transmission using Deep Joint Source-Channel Coding
Jan 25, 2022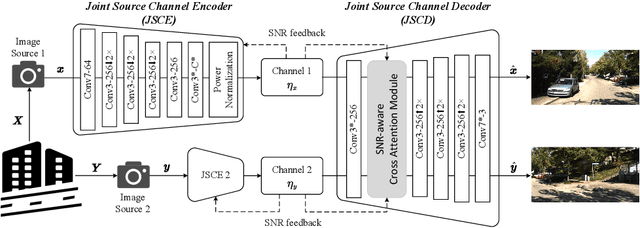
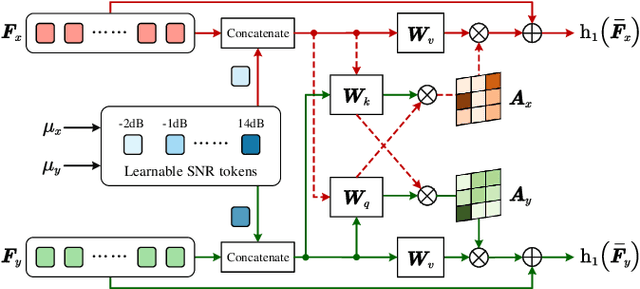
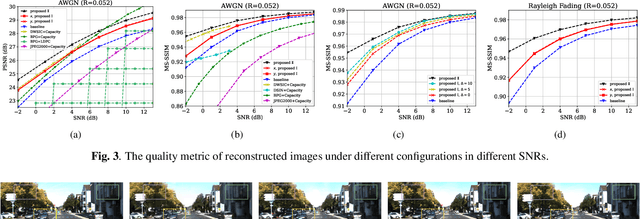

We study the problem of deep joint source-channel coding (D-JSCC) for correlated image sources, where each source is transmitted through a noisy independent channel to the common receiver. In particular, we consider a pair of images captured by two cameras with probably overlapping fields of view transmitted over wireless channels and reconstructed in the center node. The challenging problem involves designing a practical code to utilize both source and channel correlations to improve transmission efficiency without additional transmission overhead. To tackle this, we need to consider the common information across two stereo images as well as the differences between two transmission channels. In this case, we propose a deep neural networks solution that includes lightweight edge encoders and a powerful center decoder. Besides, in the decoder, we propose a novel channel state information aware cross attention module to highlight the overlapping fields and leverage the relevance between two noisy feature maps.Our results show the impressive improvement of reconstruction quality in both links by exploiting the noisy representations of the other link. Moreover, the proposed scheme shows competitive results compared to the separated schemes with capacity-achieving channel codes.
VertXNet: Automatic Segmentation and Identification of Lumbar and Cervical Vertebrae from Spinal X-ray Images
Jul 12, 2022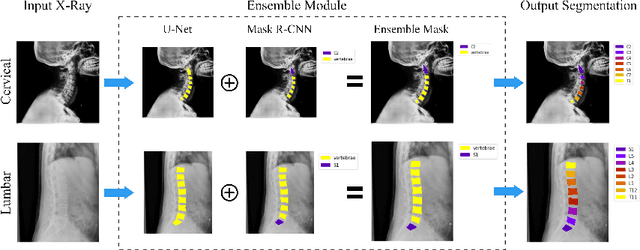
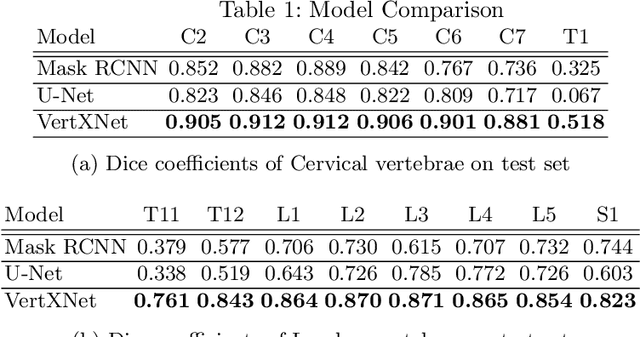
Manual annotation of vertebrae on spinal X-ray imaging is costly and time-consuming due to bone shape complexity and image quality variations. In this study, we address this challenge by proposing an ensemble method called VertXNet, to automatically segment and label vertebrae in X-ray spinal images. VertXNet combines two state-of-the-art segmentation models, namely U-Net and Mask R-CNN to improve vertebrae segmentation. A main feature of VertXNet is to also infer vertebrae labels thanks to its Mask R-CNN component (trained to detect 'reference' vertebrae) on a given spinal X-ray image. VertXNet was evaluated on an in-house dataset of lateral cervical and lumbar X-ray imaging for ankylosing spondylitis (AS) patients. Our results show that VertXNet can accurately label spinal X-rays (mean Dice of 0.9). It can be used to circumvent the lack of annotated vertebrae without requiring human expert review. This step is crucial to investigate clinical associations by solving the lack of segmentation, a common bottleneck for most computational imaging projects.
Light Weight Character and Shape Recognition for Autonomous Drones
Aug 14, 2022


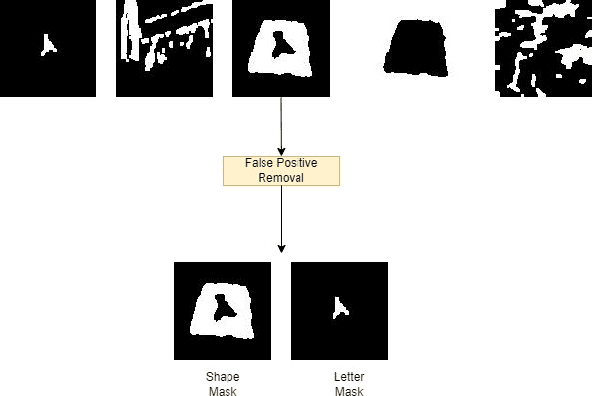
There has been an extensive use of Unmanned Aerial Vehicles in search and rescue missions to distribute first aid kits and food packets. It is important that these UAVs are able to identify and distinguish the markers from one another for effective distribution. One of the common ways to mark the locations is via the use of characters superimposed on shapes of various colors which gives rise to wide variety of markers based on combination of different shapes, characters, and their respective colors. In this paper, we propose an object detection and classification pipeline which prevents false positives and minimizes misclassification of alphanumeric characters and shapes in aerial images. Our method makes use of traditional computer vision techniques and unsupervised machine learning methods for identifying region proposals, segmenting the image targets and removing false positives. We make use of a computationally light model for classification, making it easy to be deployed on any aerial vehicle.
Twin identification over viewpoint change: A deep convolutional neural network surpasses humans
Jul 12, 2022
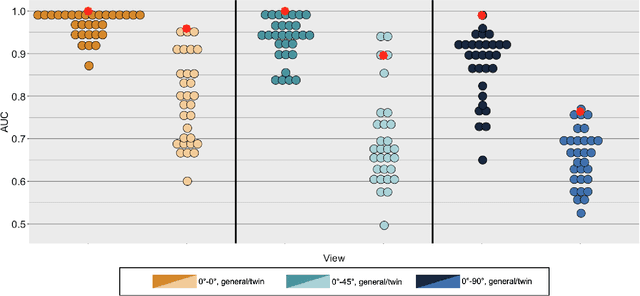
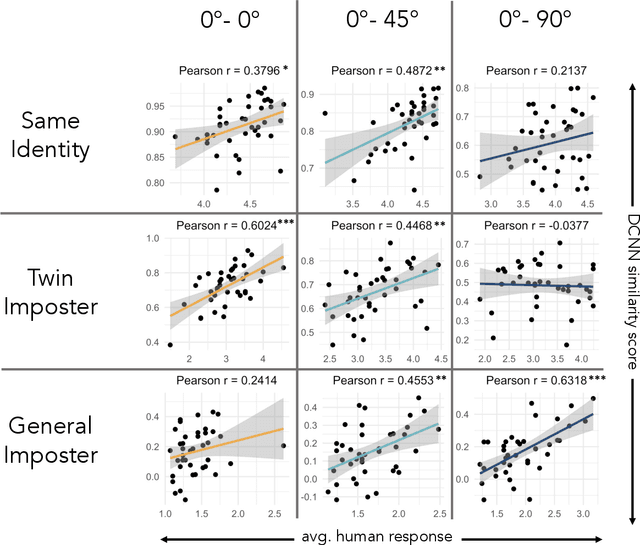
Deep convolutional neural networks (DCNNs) have achieved human-level accuracy in face identification (Phillips et al., 2018), though it is unclear how accurately they discriminate highly-similar faces. Here, humans and a DCNN performed a challenging face-identity matching task that included identical twins. Participants (N=87) viewed pairs of face images of three types: same-identity, general imposter pairs (different identities from similar demographic groups), and twin imposter pairs (identical twin siblings). The task was to determine whether the pairs showed the same person or different people. Identity comparisons were tested in three viewpoint-disparity conditions: frontal to frontal, frontal to 45-degree profile, and frontal to 90-degree profile. Accuracy for discriminating matched-identity pairs from twin-imposters and general imposters was assessed in each viewpoint-disparity condition. Humans were more accurate for general-imposter pairs than twin-imposter pairs, and accuracy declined with increased viewpoint disparity between the images in a pair. A DCNN trained for face identification (Ranjan et al., 2018) was tested on the same image pairs presented to humans. Machine performance mirrored the pattern of human accuracy, but with performance at or above all humans in all but one condition. Human and machine similarity scores were compared across all image-pair types. This item-level analysis showed that human and machine similarity ratings correlated significantly in six of nine image-pair types [range r=0.38 to r=0.63], suggesting general accord between the perception of face similarity by humans and the DCNN. These findings also contribute to our understanding of DCNN performance for discriminating high-resemblance faces, demonstrate that the DCNN performs at a level at or above humans, and suggest a degree of parity between the features used by humans and the DCNN.
Detecting the unknown in Object Detection
Aug 24, 2022
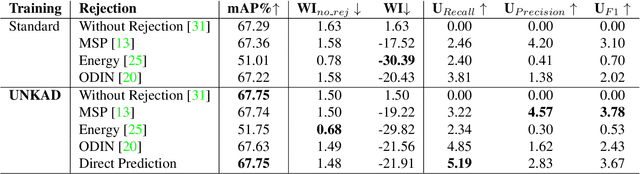

Object detection methods have witnessed impressive improvements in the last years thanks to the design of novel neural network architectures and the availability of large scale datasets. However, current methods have a significant limitation: they are able to detect only the classes observed during training time, that are only a subset of all the classes that a detector may encounter in the real world. Furthermore, the presence of unknown classes is often not considered at training time, resulting in methods not even able to detect that an unknown object is present in the image. In this work, we address the problem of detecting unknown objects, known as open-set object detection. We propose a novel training strategy, called UNKAD, able to predict unknown objects without requiring any annotation of them, exploiting non annotated objects that are already present in the background of training images. In particular, exploiting the four-steps training strategy of Faster R-CNN, UNKAD first identifies and pseudo-labels unknown objects and then uses the pseudo-annotations to train an additional unknown class. While UNKAD can directly detect unknown objects, we further combine it with previous unknown detection techniques, showing that it improves their performance at no costs.
A Supervised Tensor Dimension Reduction-Based Prognostics Model for Applications with Incomplete Imaging Data
Jul 22, 2022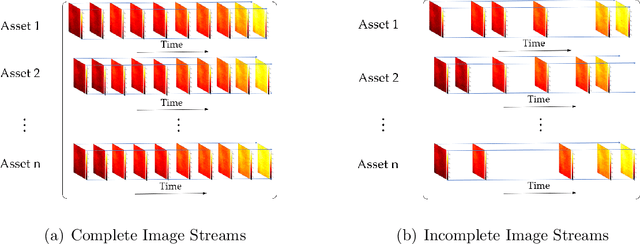
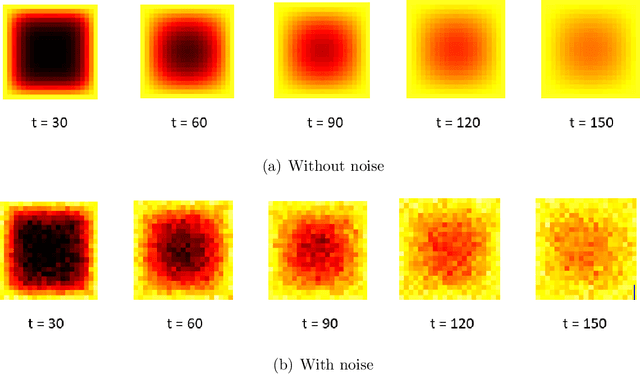
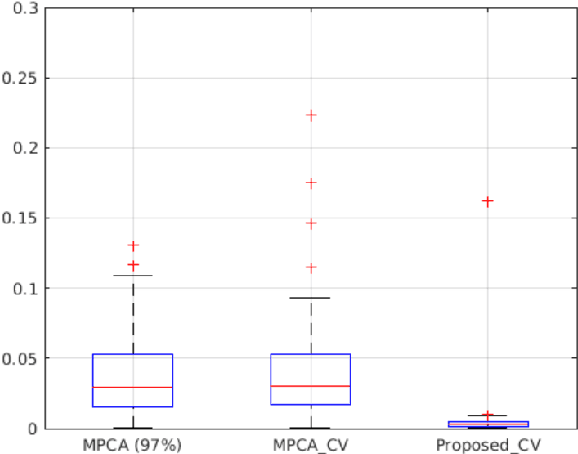
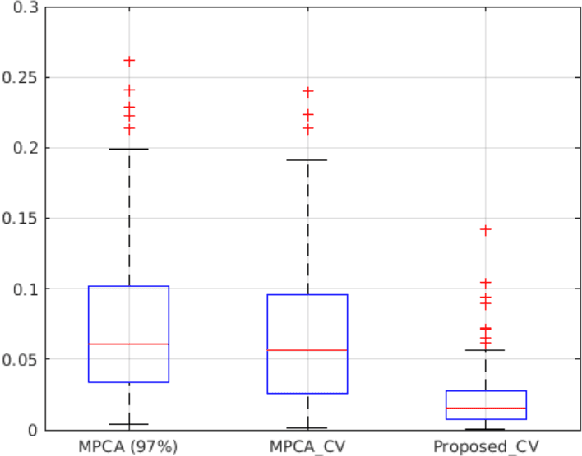
This paper proposes a supervised dimension reduction methodology for tensor data which has two advantages over most image-based prognostic models. First, the model does not require tensor data to be complete which expands its application to incomplete data. Second, it utilizes time-to-failure (TTF) to supervise the extraction of low-dimensional features which makes the extracted features more effective for the subsequent prognostic. Besides, an optimization algorithm is proposed for parameter estimation and closed-form solutions are derived under certain distributions.