 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Refine and Represent: Region-to-Object Representation Learning
Aug 25, 2022
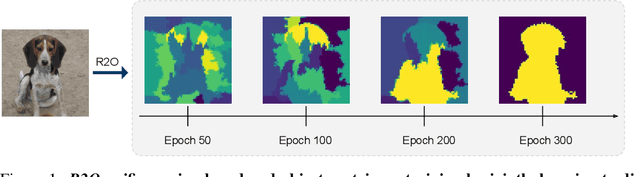
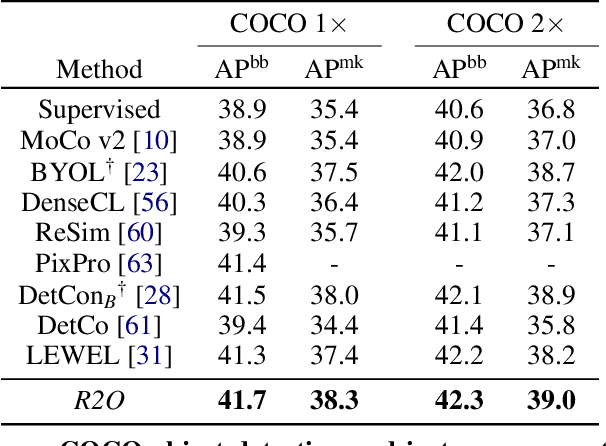
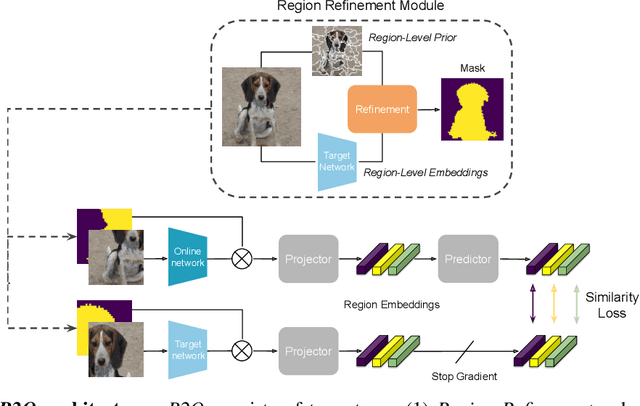
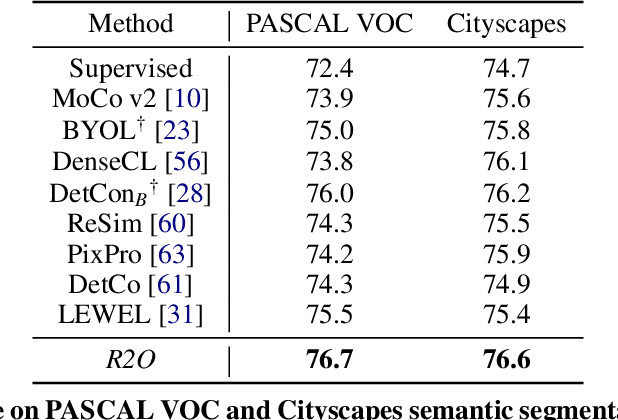
Recent works in self-supervised learning have demonstrated strong performance on scene-level dense prediction tasks by pretraining with object-centric or region-based correspondence objectives. In this paper, we present Region-to-Object Representation Learning (R2O) which unifies region-based and object-centric pretraining. R2O operates by training an encoder to dynamically refine region-based segments into object-centric masks and then jointly learns representations of the contents within the mask. R2O uses a "region refinement module" to group small image regions, generated using a region-level prior, into larger regions which tend to correspond to objects by clustering region-level features. As pretraining progresses, R2O follows a region-to-object curriculum which encourages learning region-level features early on and gradually progresses to train object-centric representations. Representations learned using R2O lead to state-of-the art performance in semantic segmentation for PASCAL VOC (+0.7 mIOU) and Cityscapes (+0.4 mIOU) and instance segmentation on MS COCO (+0.3 mask AP). Further, after pretraining on ImageNet, R2O pretrained models are able to surpass existing state-of-the-art in unsupervised object segmentation on the Caltech-UCSD Birds 200-2011 dataset (+2.9 mIoU) without any further training. We provide the code/models from this work at https://github.com/KKallidromitis/r2o.
Maintaining Performance with Less Data
Aug 03, 2022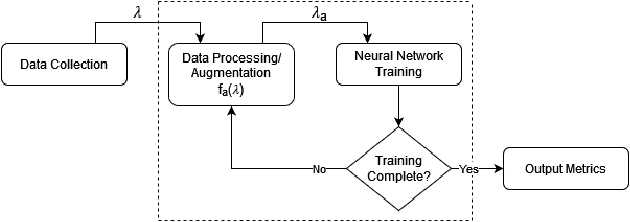
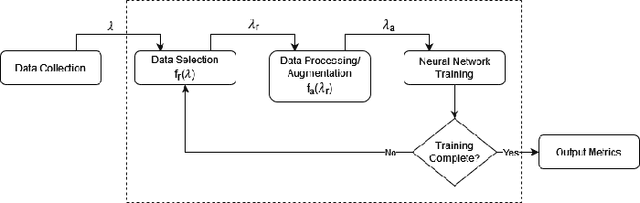
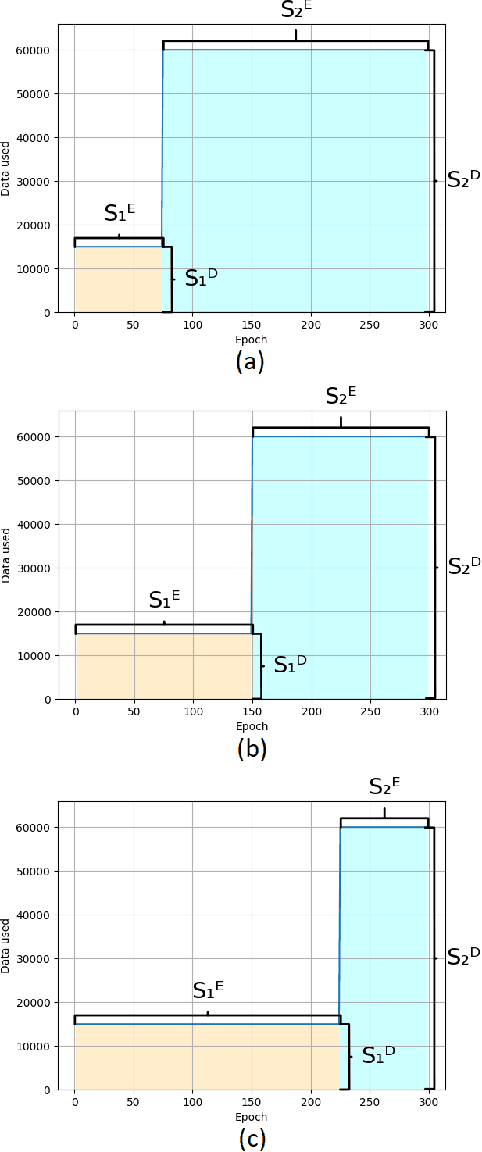
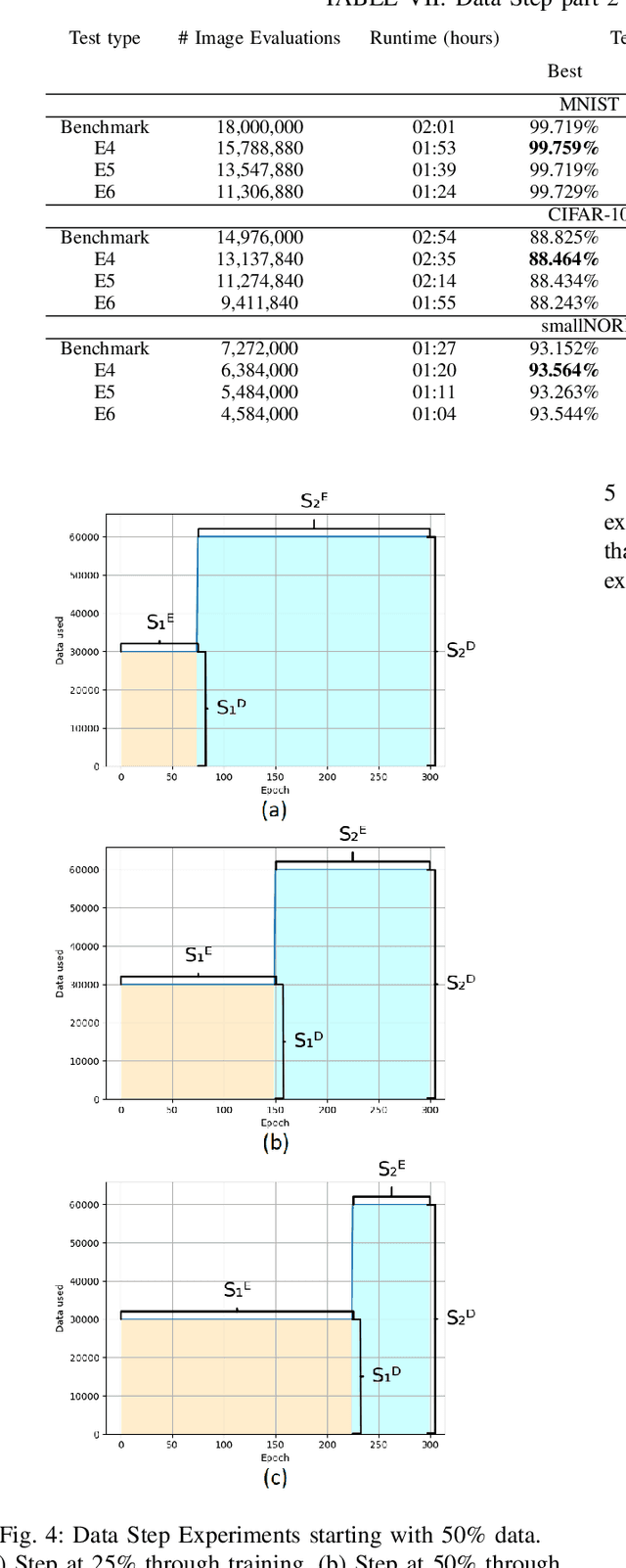
We propose a novel method for training a neural network for image classification to reduce input data dynamically, in order to reduce the costs of training a neural network model. As Deep Learning tasks become more popular, their computational complexity increases, leading to more intricate algorithms and models which have longer runtimes and require more input data. The result is a greater cost on time, hardware, and environmental resources. By using data reduction techniques, we reduce the amount of work performed, and therefore the environmental impact of AI techniques, and with dynamic data reduction we show that accuracy may be maintained while reducing runtime by up to 50%, and reducing carbon emission proportionally.
Rethinking Generalization in Few-Shot Classification
Jun 15, 2022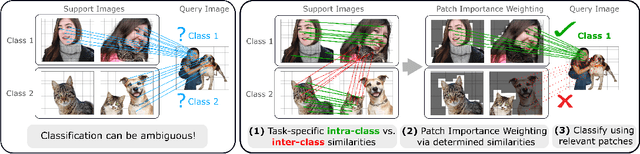
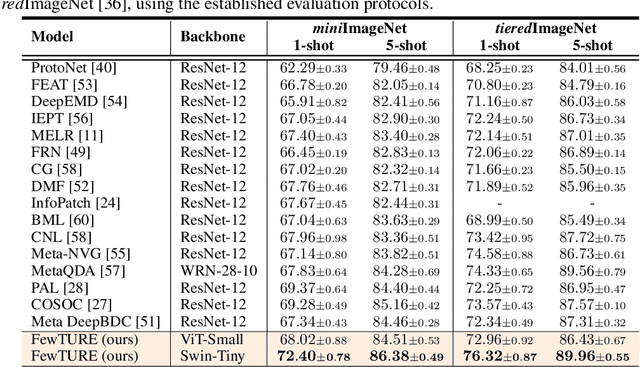
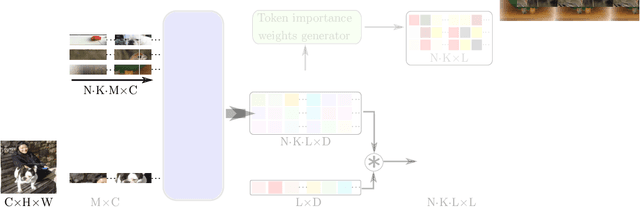
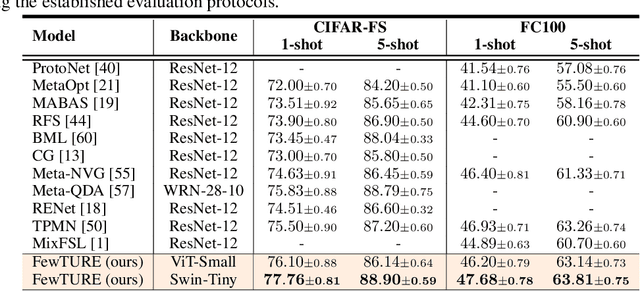
Single image-level annotations only correctly describe an often small subset of an image's content, particularly when complex real-world scenes are depicted. While this might be acceptable in many classification scenarios, it poses a significant challenge for applications where the set of classes differs significantly between training and test time. In this paper, we take a closer look at the implications in the context of $\textit{few-shot learning}$. Splitting the input samples into patches and encoding these via the help of Vision Transformers allows us to establish semantic correspondences between local regions across images and independent of their respective class. The most informative patch embeddings for the task at hand are then determined as a function of the support set via online optimization at inference time, additionally providing visual interpretability of `$\textit{what matters most}$' in the image. We build on recent advances in unsupervised training of networks via masked image modelling to overcome the lack of fine-grained labels and learn the more general statistical structure of the data while avoiding negative image-level annotation influence, $\textit{aka}$ supervision collapse. Experimental results show the competitiveness of our approach, achieving new state-of-the-art results on four popular few-shot classification benchmarks for $5$-shot and $1$-shot scenarios.
High-Resolution Virtual Try-On with Misalignment and Occlusion-Handled Conditions
Jun 28, 2022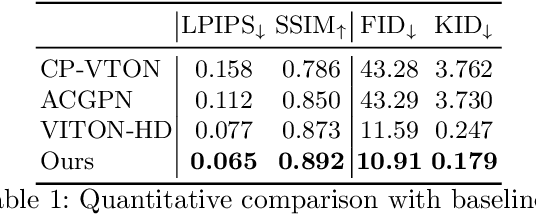
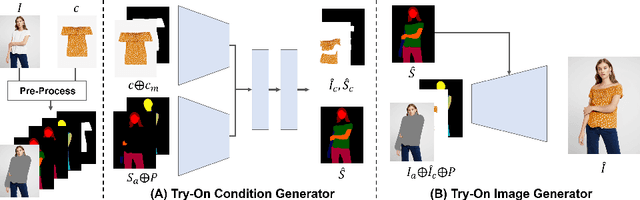
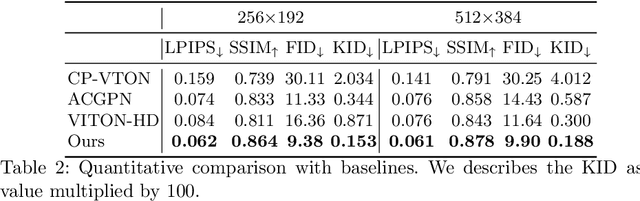
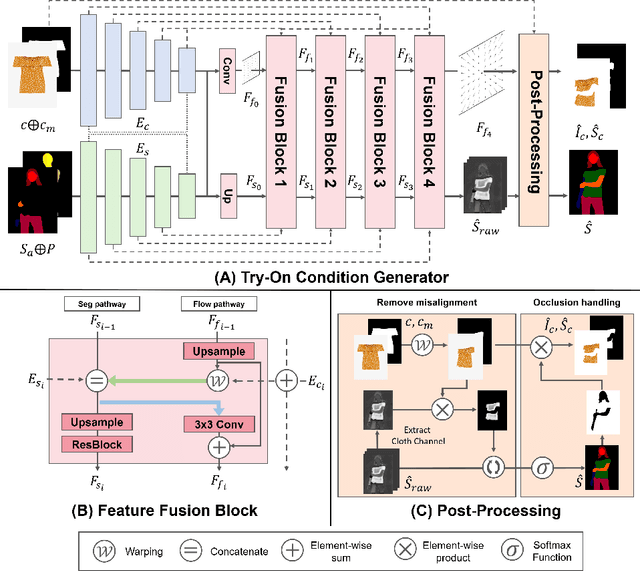
Image-based virtual try-on aims to synthesize an image of a person wearing a given clothing item. To solve the task, the existing methods warp the clothing item to fit the person's body and generate the segmentation map of the person wearing the item, before fusing the item with the person. However, when the warping and the segmentation generation stages operate individually without information exchange, the misalignment between the warped clothes and the segmentation map occurs, which leads to the artifacts in the final image. The information disconnection also causes excessive warping near the clothing regions occluded by the body parts, so called pixel-squeezing artifacts. To settle the issues, we propose a novel try-on condition generator as a unified module of the two stages (i.e., warping and segmentation generation stages). A newly proposed feature fusion block in the condition generator implements the information exchange, and the condition generator does not create any misalignment or pixel-squeezing artifacts. We also introduce discriminator rejection that filters out the incorrect segmentation map predictions and assures the performance of virtual try-on frameworks. Experiments on a high-resolution dataset demonstrate that our model successfully handles the misalignment and the occlusion, and significantly outperforms the baselines. Code is available at https://github.com/sangyun884/HR-VITON.
Estimating Image Depth in the Comics Domain
Oct 07, 2021
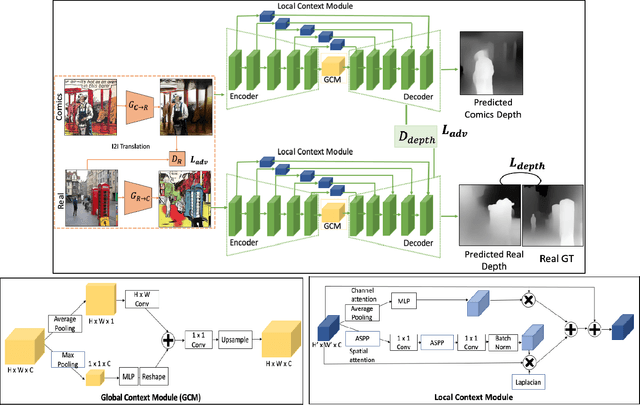
Estimating the depth of comics images is challenging as such images a) are monocular; b) lack ground-truth depth annotations; c) differ across different artistic styles; d) are sparse and noisy. We thus, use an off-the-shelf unsupervised image to image translation method to translate the comics images to natural ones and then use an attention-guided monocular depth estimator to predict their depth. This lets us leverage the depth annotations of existing natural images to train the depth estimator. Furthermore, our model learns to distinguish between text and images in the comics panels to reduce text-based artefacts in the depth estimates. Our method consistently outperforms the existing state-ofthe-art approaches across all metrics on both the DCM and eBDtheque images. Finally, we introduce a dataset to evaluate depth prediction on comics.
Conditional Variational Autoencoder for Learned Image Reconstruction
Oct 25, 2021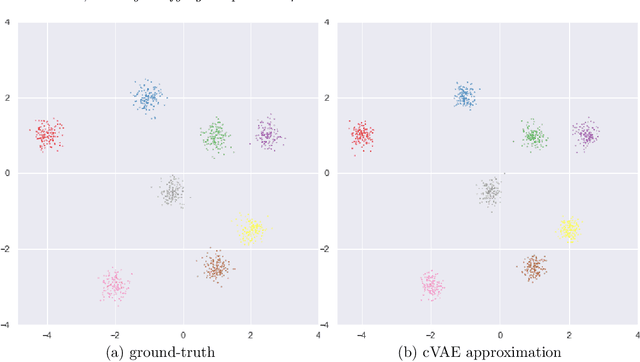

Learned image reconstruction techniques using deep neural networks have recently gained popularity, and have delivered promising empirical results. However, most approaches focus on one single recovery for each observation, and thus neglect the uncertainty information. In this work, we develop a novel computational framework that approximates the posterior distribution of the unknown image at each query observation. The proposed framework is very flexible: It handles implicit noise models and priors, it incorporates the data formation process (i.e., the forward operator), and the learned reconstructive properties are transferable between different datasets. Once the network is trained using the conditional variational autoencoder loss, it provides a computationally efficient sampler for the approximate posterior distribution via feed-forward propagation, and the summarizing statistics of the generated samples are used for both point-estimation and uncertainty quantification. We illustrate the proposed framework with extensive numerical experiments on positron emission tomography (with both moderate and low count levels) showing that the framework generates high-quality samples when compared with state-of-the-art methods.
VLMixer: Unpaired Vision-Language Pre-training via Cross-Modal CutMix
Jun 17, 2022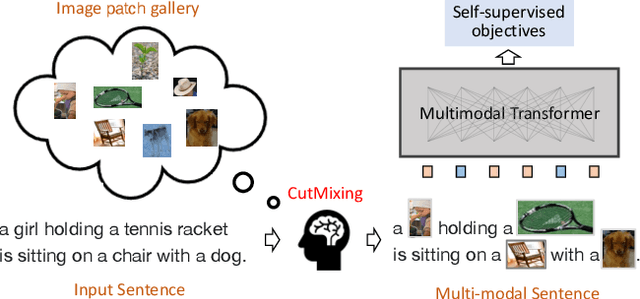
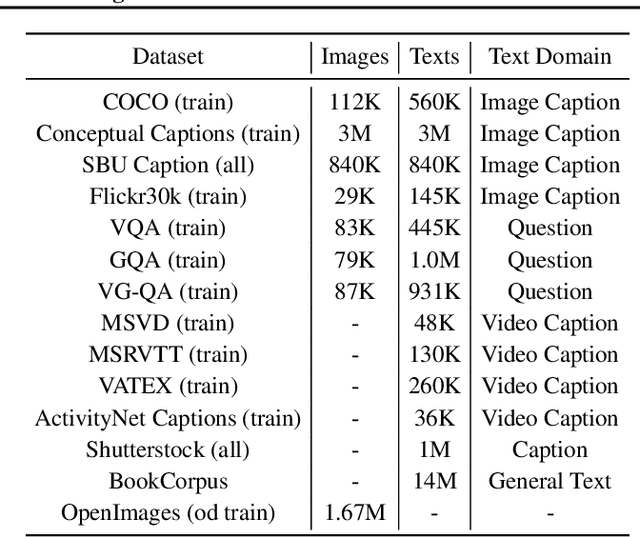
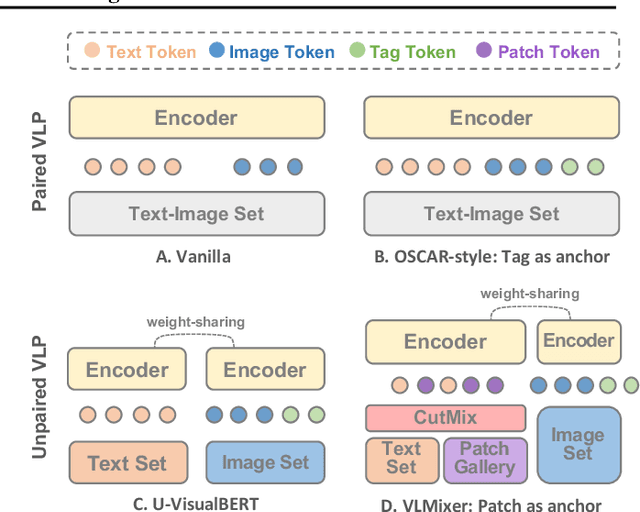
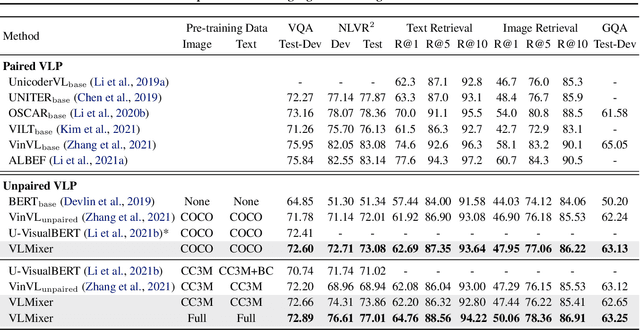
Existing vision-language pre-training (VLP) methods primarily rely on paired image-text datasets, which are either annotated by enormous human labors, or crawled from the internet followed by elaborate data cleaning techniques. To reduce the dependency on well-aligned image-text pairs, it is promising to directly leverage the large-scale text-only and image-only corpora. This paper proposes a data augmentation method, namely cross-modal CutMix (CMC), for implicit cross-modal alignment learning in unpaired VLP. Specifically, CMC transforms natural sentences from the textual view into a multi-modal view, where visually-grounded words in a sentence are randomly replaced by diverse image patches with similar semantics. There are several appealing proprieties of the proposed CMC. First, it enhances the data diversity while keeping the semantic meaning intact for tackling problems where the aligned data are scarce; Second, by attaching cross-modal noise on uni-modal data, it guides models to learn token-level interactions across modalities for better denoising. Furthermore, we present a new unpaired VLP method, dubbed as VLMixer, that integrates CMC with contrastive learning to pull together the uni-modal and multi-modal views for better instance-level alignments among different modalities. Extensive experiments on five downstream tasks show that VLMixer could surpass previous state-of-the-art unpaired VLP methods.
Realtime strategy for image data labelling using binary models and active sampling
Feb 28, 2022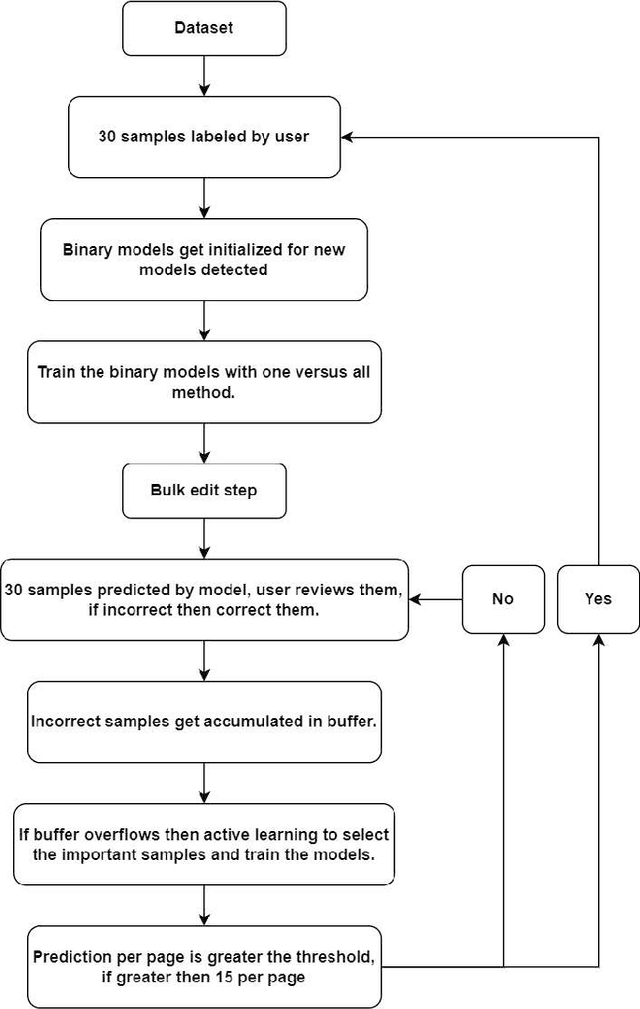
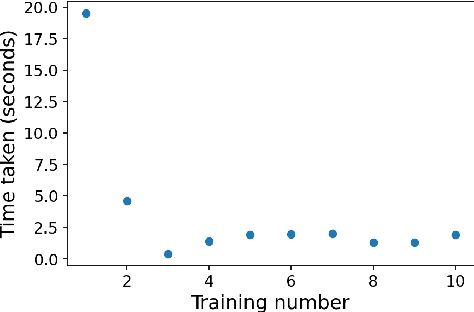
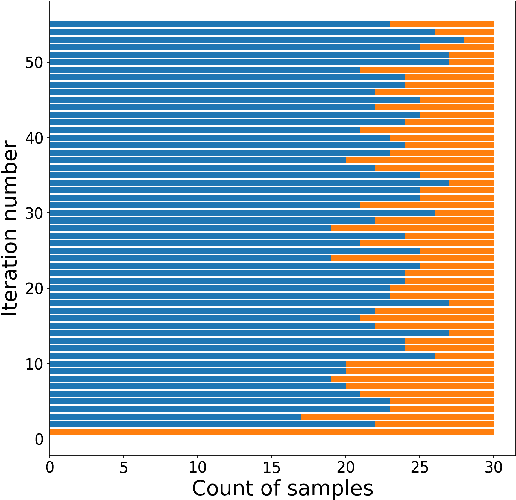
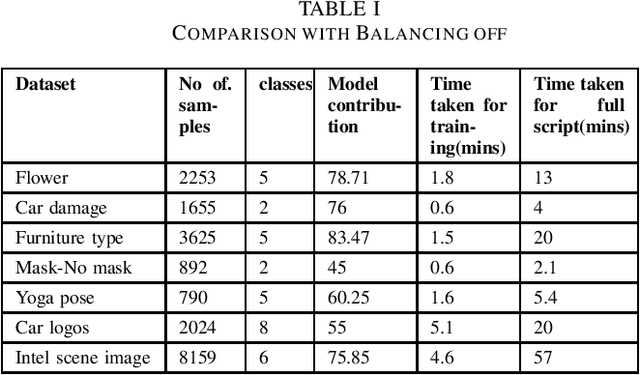
Machine learning (ML) and Deep Learning (DL) tasks primarily depend on data. Most of the ML and DL applications involve supervised learning which requires labelled data. In the initial phases of ML realm lack of data used to be a problem, now we are in a new era of big data. The supervised ML algorithms require data to be labelled and of good quality. Labelling task requires a large amount of money and time investment. Data labelling require a skilled person who will charge high for this task, consider the case of the medical field or the data is in bulk that requires a lot of people assigned to label it. The amount of data that is well enough for training needs to be known, money and time can not be wasted to label the whole data. This paper mainly aims to propose a strategy that helps in labelling the data along with oracle in real-time. With balancing on model contribution for labelling is 89 and 81.1 for furniture type and intel scene image data sets respectively. Further with balancing being kept off model contribution is found to be 83.47 and 78.71 for furniture type and flower data sets respectively.
Estimation of Non-Functional Properties for Embedded Hardware with Application to Image Processing
Mar 03, 2022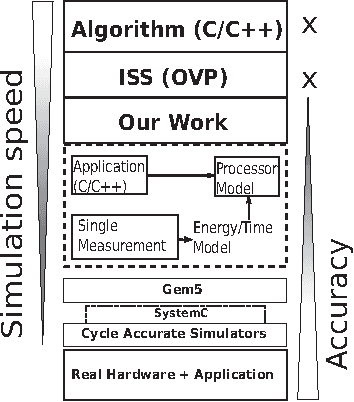
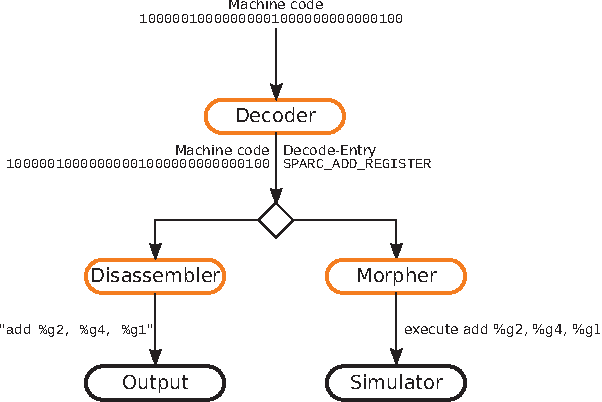
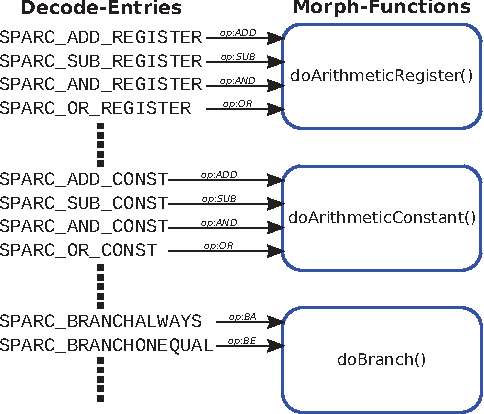
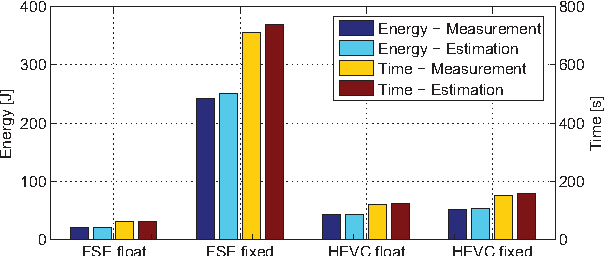
In recent years, due to a higher demand for portable devices, which provide restricted amounts of processing capacity and battery power, the need for energy and time efficient hard- and software solutions has increased. Preliminary estimations of time and energy consumption can thus be valuable to improve implementations and design decisions. To this end, this paper presents a method to estimate the time and energy consumption of a given software solution, without having to rely on the use of a traditional Cycle Accurate Simulator (CAS). Instead, we propose to utilize a combination of high-level functional simulation with a mechanistic extension to include non-functional properties: Instruction counts from virtual execution are multiplied with corresponding specific energies and times. By evaluating two common image processing algorithms on an FPGA-based CPU, where a mean relative estimation error of 3% is achieved for cacheless systems, we show that this estimation tool can be a valuable aid in the development of embedded processor architectures. The tool allows the developer to reach well-suited design decisions regarding the optimal processor hardware configuration for a given algorithm at an early stage in the design process.
Light Weight Character and Shape Recognition for Autonomous Drones
Aug 14, 2022


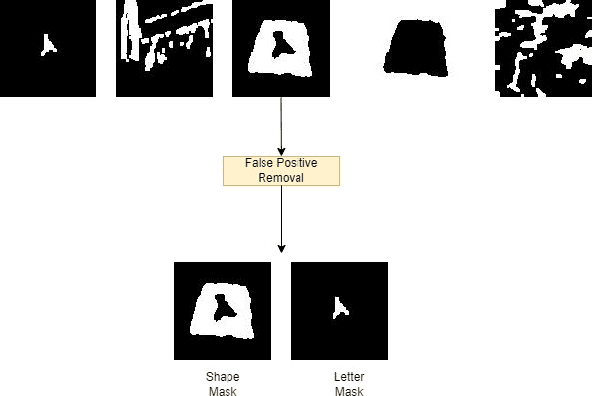
There has been an extensive use of Unmanned Aerial Vehicles in search and rescue missions to distribute first aid kits and food packets. It is important that these UAVs are able to identify and distinguish the markers from one another for effective distribution. One of the common ways to mark the locations is via the use of characters superimposed on shapes of various colors which gives rise to wide variety of markers based on combination of different shapes, characters, and their respective colors. In this paper, we propose an object detection and classification pipeline which prevents false positives and minimizes misclassification of alphanumeric characters and shapes in aerial images. Our method makes use of traditional computer vision techniques and unsupervised machine learning methods for identifying region proposals, segmenting the image targets and removing false positives. We make use of a computationally light model for classification, making it easy to be deployed on any aerial vehicle.