 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Spatio-Temporal U-Net for Cerebral Artery and Vein Segmentation in Digital Subtraction Angiography
Aug 03, 2022
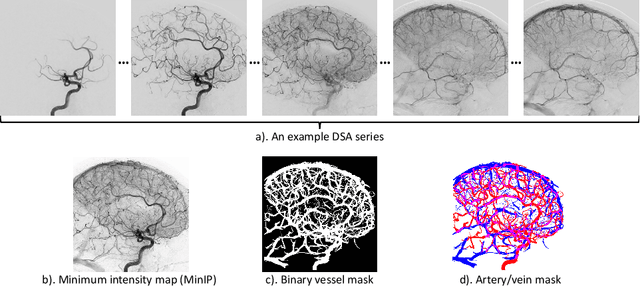
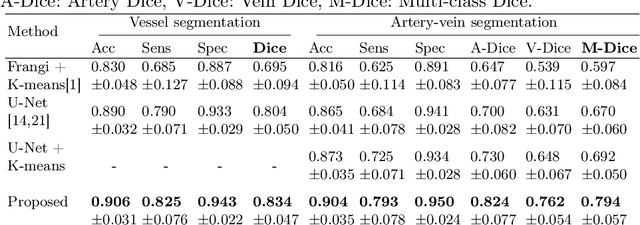
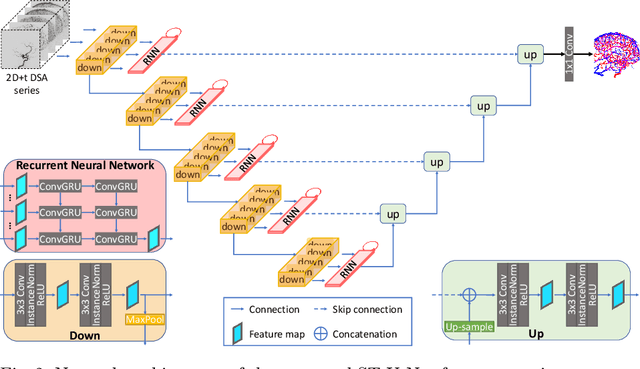
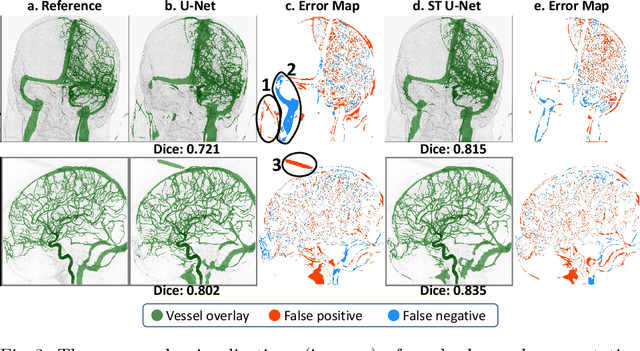
X-ray digital subtraction angiography (DSA) is widely used for vessel and/or flow visualization and interventional guidance during endovascular treatment of patients with a stroke or aneurysm. To assist in peri-operative decision making as well as post-operative prognosis, automatic DSA analysis algorithms are being developed to obtain relevant image-based information. Such analyses include detection of vascular disease, evaluation of perfusion based on time intensity curves (TIC), and quantitative biomarker extraction for automated treatment evaluation in endovascular thrombectomy. Methodologically, such vessel-based analysis tasks may be facilitated by automatic and accurate artery-vein segmentation algorithms. The present work describes to the best of our knowledge the first study that addresses automatic artery-vein segmentation in DSA using deep learning. We propose a novel spatio-temporal U-Net (ST U-Net) architecture which integrates convolutional gated recurrent units (ConvGRU) in the contracting branch of U-Net. The network encodes a 2D+t DSA series of variable length and decodes it into a 2D segmentation image. On a multi-center routinely acquired dataset, the proposed method significantly outperformed U-Net (P<0.001) and traditional Frangi-based K-means clustering (P$<$0.001). Particularly in artery-vein segmentation, ST U-Net achieved a Dice coefficient of 0.794, surpassing the existing state-of-the-art methods by a margin of 12\%-20\%. Code will be made publicly available upon acceptance.
HistoPerm: A Permutation-Based View Generation Approach for Learning Histopathologic Feature Representations
Sep 13, 2022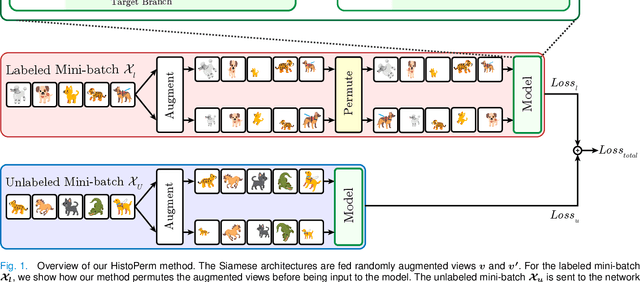
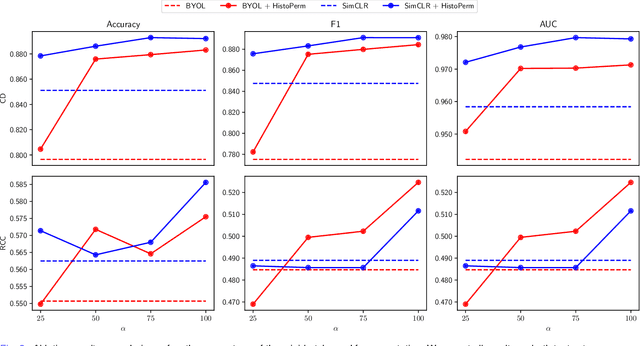
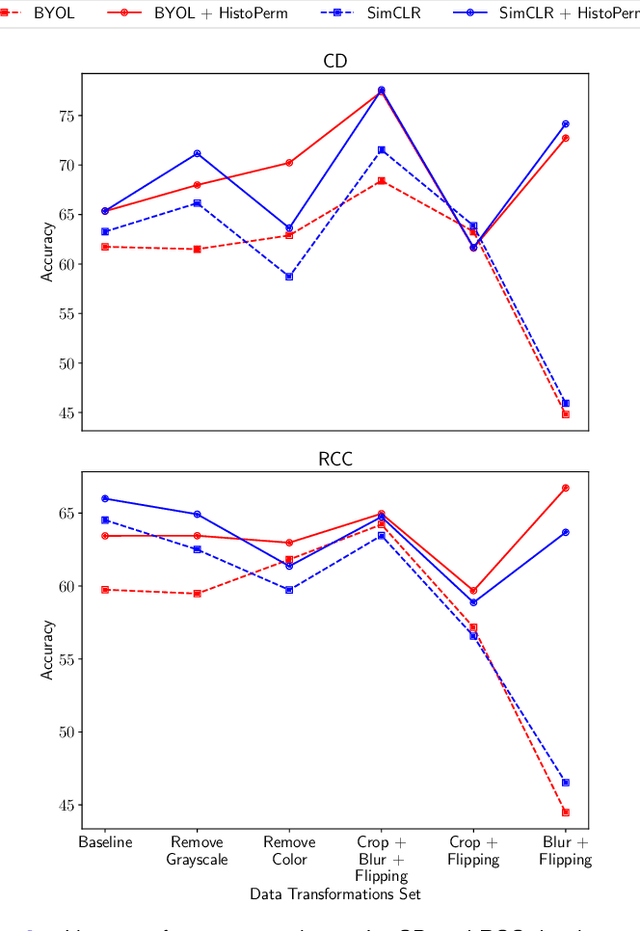
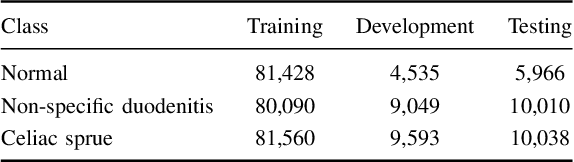
Recently, deep learning methods have been successfully applied to solve numerous challenges in the field of digital pathology. However, many of these approaches are fully supervised and require annotated images. Annotating a histology image is a time-consuming and tedious process for even a highly skilled pathologist, and, as such, most histology datasets lack region-of-interest annotations and are weakly labeled. In this paper, we introduce HistoPerm, a view generation approach designed for improving the performance of representation learning techniques on histology images in weakly supervised settings. In HistoPerm, we permute augmented views of patches generated from whole-slide histology images to improve classification accuracy. These permuted views belong to the same original slide-level class but are produced from distinct patch instances. We tested adding HistoPerm to BYOL and SimCLR, two prominent representation learning methods, on two public histology datasets for Celiac disease and Renal Cell Carcinoma. For both datasets, we found improved performance in terms of accuracy, F1-score, and AUC compared to the standard BYOL and SimCLR approaches. Particularly, in a linear evaluation configuration, HistoPerm increases classification accuracy on the Celiac disease dataset by 8% for BYOL and 3% for SimCLR. Similarly, with HistoPerm, classification accuracy increases by 2% for BYOL and 0.25% for SimCLR on the Renal Cell Carcinoma dataset. The proposed permutation-based view generation approach can be adopted in common representation learning frameworks to capture histopathology features in weakly supervised settings and can lead to whole-slide classification outcomes that are close to, or even better than, fully supervised methods.
Towards Generating Large Synthetic Phytoplankton Datasets for Efficient Monitoring of Harmful Algal Blooms
Aug 03, 2022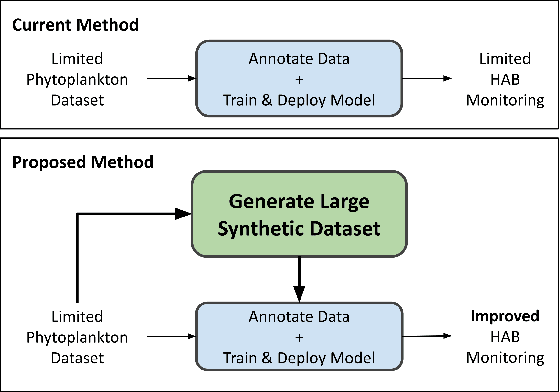
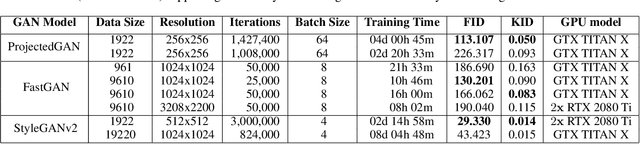


Climate change is increasing the frequency and severity of harmful algal blooms (HABs), which cause significant fish deaths in aquaculture farms. This contributes to ocean pollution and greenhouse gas (GHG) emissions since dead fish are either dumped into the ocean or taken to landfills, which in turn negatively impacts the climate. Currently, the standard method to enumerate harmful algae and other phytoplankton is to manually observe and count them under a microscope. This is a time-consuming, tedious and error-prone process, resulting in compromised management decisions by farmers. Hence, automating this process for quick and accurate HAB monitoring is extremely helpful. However, this requires large and diverse datasets of phytoplankton images, and such datasets are hard to produce quickly. In this work, we explore the feasibility of generating novel high-resolution photorealistic synthetic phytoplankton images, containing multiple species in the same image, given a small dataset of real images. To this end, we employ Generative Adversarial Networks (GANs) to generate synthetic images. We evaluate three different GAN architectures: ProjectedGAN, FastGAN, and StyleGANv2 using standard image quality metrics. We empirically show the generation of high-fidelity synthetic phytoplankton images using a training dataset of only 961 real images. Thus, this work demonstrates the ability of GANs to create large synthetic datasets of phytoplankton from small training datasets, accomplishing a key step towards sustainable systematic monitoring of harmful algal blooms.
Combining Counterfactuals With Shapley Values To Explain Image Models
Jun 14, 2022
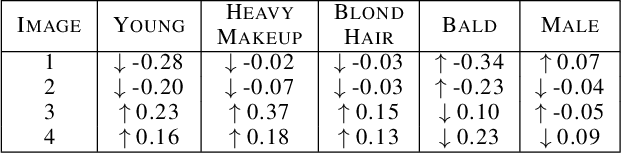
With the widespread use of sophisticated machine learning models in sensitive applications, understanding their decision-making has become an essential task. Models trained on tabular data have witnessed significant progress in explanations of their underlying decision making processes by virtue of having a small number of discrete features. However, applying these methods to high-dimensional inputs such as images is not a trivial task. Images are composed of pixels at an atomic level and do not carry any interpretability by themselves. In this work, we seek to use annotated high-level interpretable features of images to provide explanations. We leverage the Shapley value framework from Game Theory, which has garnered wide acceptance in general XAI problems. By developing a pipeline to generate counterfactuals and subsequently using it to estimate Shapley values, we obtain contrastive and interpretable explanations with strong axiomatic guarantees.
Self-supervised Learning with Local Contrastive Loss for Detection and Semantic Segmentation
Jul 10, 2022
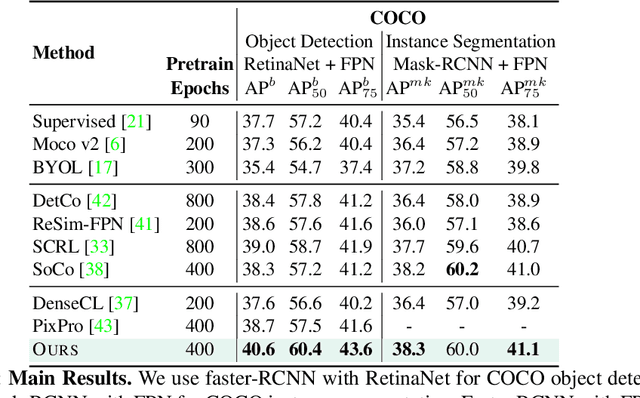
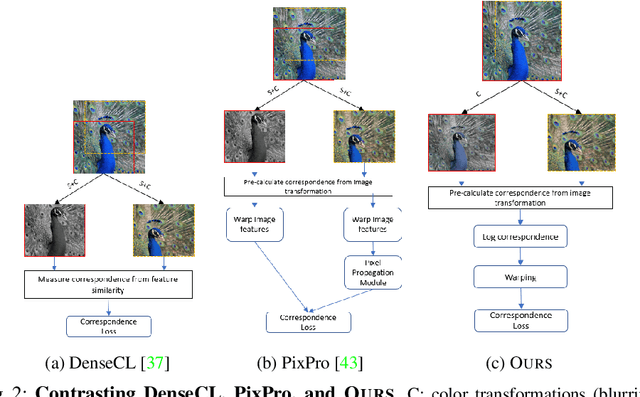
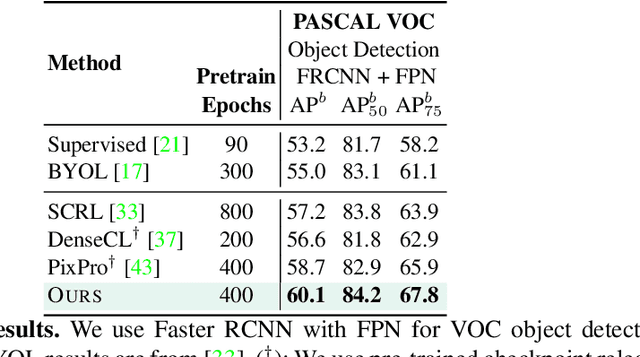
We present a self-supervised learning (SSL) method suitable for semi-global tasks such as object detection and semantic segmentation. We enforce local consistency between self-learned features, representing corresponding image locations of transformed versions of the same image, by minimizing a pixel-level local contrastive (LC) loss during training. LC-loss can be added to existing self-supervised learning methods with minimal overhead. We evaluate our SSL approach on two downstream tasks -- object detection and semantic segmentation, using COCO, PASCAL VOC, and CityScapes datasets. Our method outperforms the existing state-of-the-art SSL approaches by 1.9% on COCO object detection, 1.4% on PASCAL VOC detection, and 0.6% on CityScapes segmentation.
Study of detecting behavioral signatures within DeepFake videos
Aug 06, 2022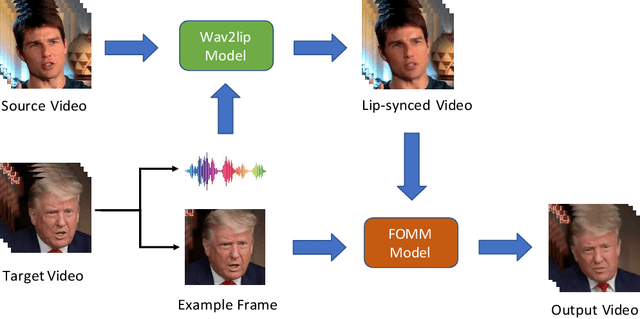
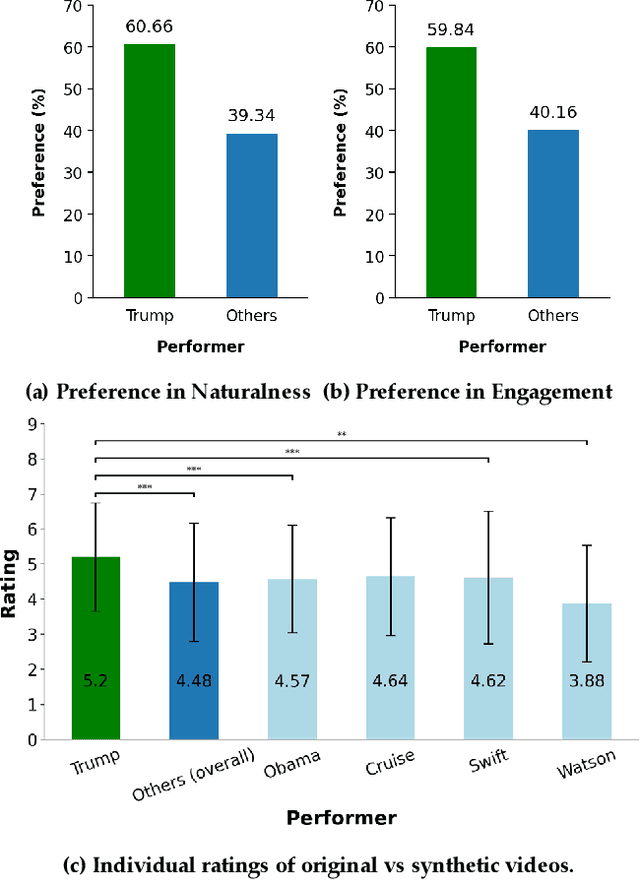
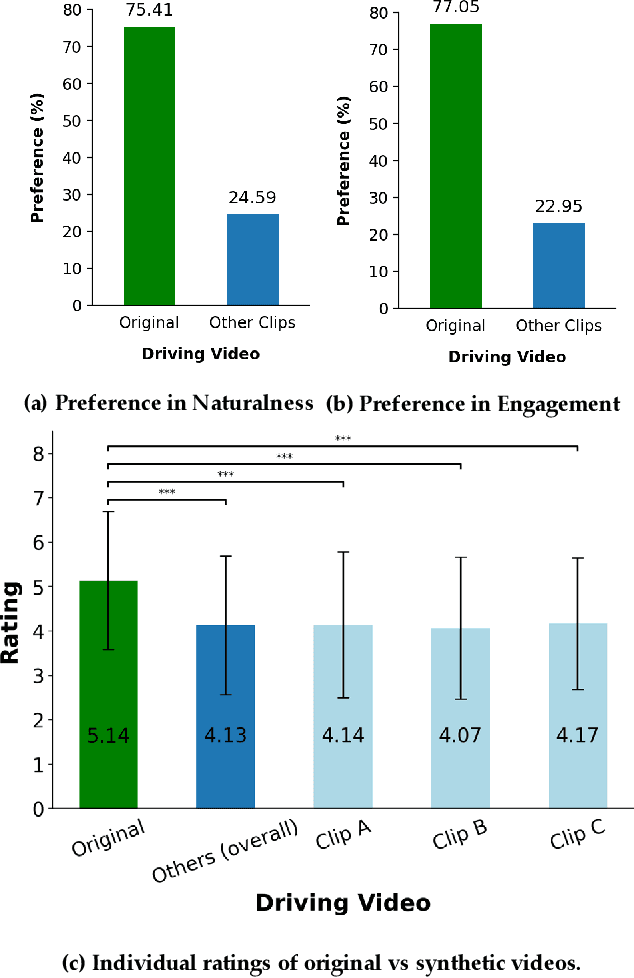

There is strong interest in the generation of synthetic video imagery of people talking for various purposes, including entertainment, communication, training, and advertisement. With the development of deep fake generation models, synthetic video imagery will soon be visually indistinguishable to the naked eye from a naturally capture video. In addition, many methods are continuing to improve to avoid more careful, forensic visual analysis. Some deep fake videos are produced through the use of facial puppetry, which directly controls the head and face of the synthetic image through the movements of the actor, allow the actor to 'puppet' the image of another. In this paper, we address the question of whether one person's movements can be distinguished from the original speaker by controlling the visual appearance of the speaker but transferring the behavior signals from another source. We conduct a study by comparing synthetic imagery that: 1) originates from a different person speaking a different utterance, 2) originates from the same person speaking a different utterance, and 3) originates from a different person speaking the same utterance. Our study shows that synthetic videos in all three cases are seen as less real and less engaging than the original source video. Our results indicate that there could be a behavioral signature that is detectable from a person's movements that is separate from their visual appearance, and that this behavioral signature could be used to distinguish a deep fake from a properly captured video.
2D GANs Meet Unsupervised Single-view 3D Reconstruction
Jul 20, 2022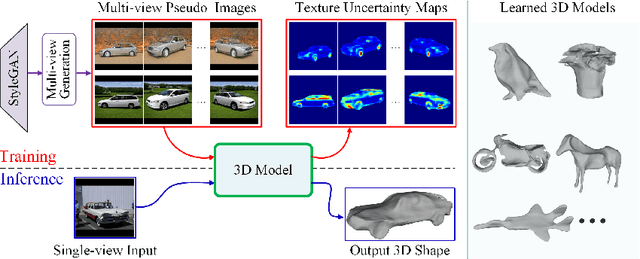
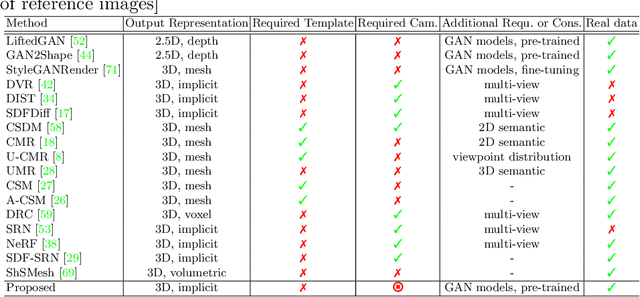
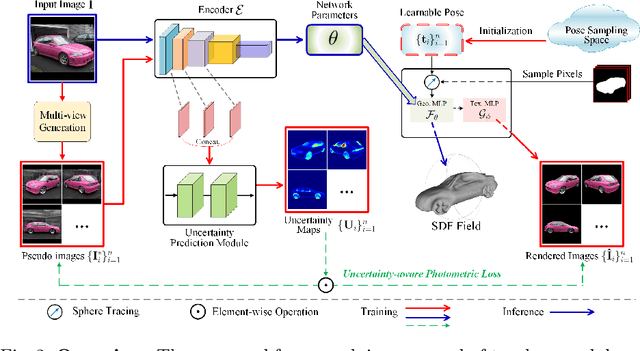
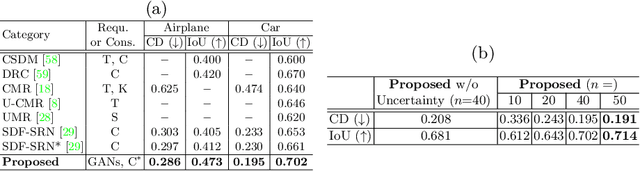
Recent research has shown that controllable image generation based on pre-trained GANs can benefit a wide range of computer vision tasks. However, less attention has been devoted to 3D vision tasks. In light of this, we propose a novel image-conditioned neural implicit field, which can leverage 2D supervisions from GAN-generated multi-view images and perform the single-view reconstruction of generic objects. Firstly, a novel offline StyleGAN-based generator is presented to generate plausible pseudo images with full control over the viewpoint. Then, we propose to utilize a neural implicit function, along with a differentiable renderer to learn 3D geometry from pseudo images with object masks and rough pose initializations. To further detect the unreliable supervisions, we introduce a novel uncertainty module to predict uncertainty maps, which remedy the negative effect of uncertain regions in pseudo images, leading to a better reconstruction performance. The effectiveness of our approach is demonstrated through superior single-view 3D reconstruction results of generic objects.
Generalized One-shot Domain Adaption of Generative Adversarial Networks
Sep 08, 2022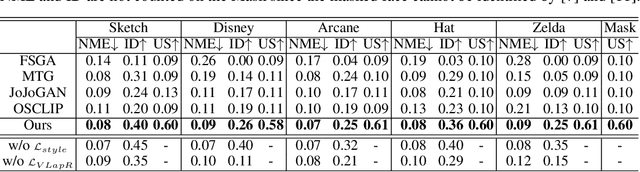
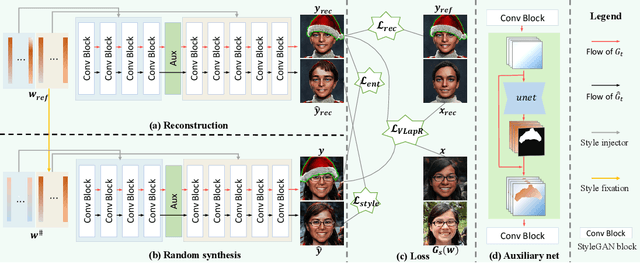

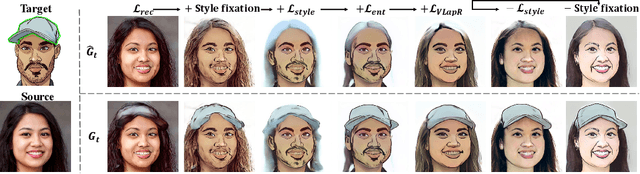
The adaption of Generative Adversarial Network (GAN) aims to transfer a pre-trained GAN to a given domain with limited training data. In this paper, we focus on the one-shot case, which is more challenging and rarely explored in previous works. We consider that the adaptation from source domain to target domain can be decoupled into two parts: the transfer of global style like texture and color, and the emergence of new entities that do not belong to the source domain. While previous works mainly focus on the style transfer, we propose a novel and concise framework\footnote{\url{https://github.com/thevoidname/Generalized-One-shot-GAN-Adaption}} to address the \textit{generalized one-shot adaption} task for both style and entity transfer, in which a reference image and its binary entity mask are provided. Our core objective is to constrain the gap between the internal distributions of the reference and syntheses by sliced Wasserstein distance. To better achieve it, style fixation is used at first to roughly obtain the exemplary style, and an auxiliary network is introduced to the original generator to disentangle entity and style transfer. Besides, to realize cross-domain correspondence, we propose the variational Laplacian regularization to constrain the smoothness of the adapted generator. Both quantitative and qualitative experiments demonstrate the effectiveness of our method in various scenarios.
Semantic uncertainty intervals for disentangled latent spaces
Jul 20, 2022

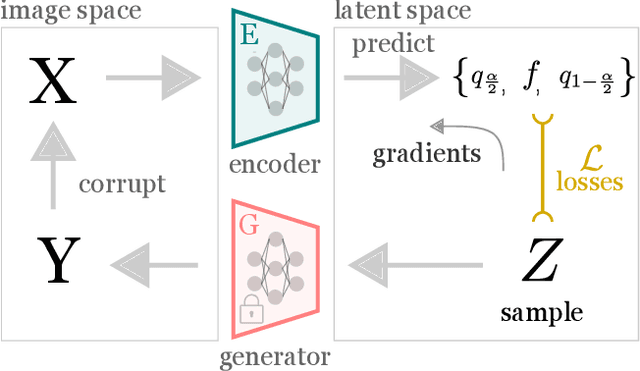
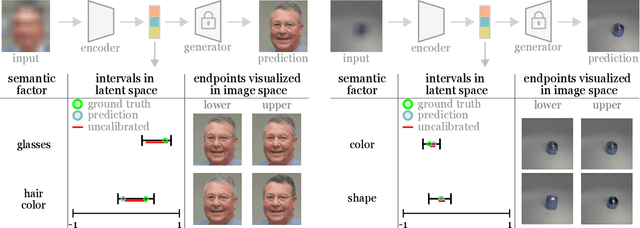
Meaningful uncertainty quantification in computer vision requires reasoning about semantic information -- say, the hair color of the person in a photo or the location of a car on the street. To this end, recent breakthroughs in generative modeling allow us to represent semantic information in disentangled latent spaces, but providing uncertainties on the semantic latent variables has remained challenging. In this work, we provide principled uncertainty intervals that are guaranteed to contain the true semantic factors for any underlying generative model. The method does the following: (1) it uses quantile regression to output a heuristic uncertainty interval for each element in the latent space (2) calibrates these uncertainties such that they contain the true value of the latent for a new, unseen input. The endpoints of these calibrated intervals can then be propagated through the generator to produce interpretable uncertainty visualizations for each semantic factor. This technique reliably communicates semantically meaningful, principled, and instance-adaptive uncertainty in inverse problems like image super-resolution and image completion.
CounTR: Transformer-based Generalised Visual Counting
Aug 29, 2022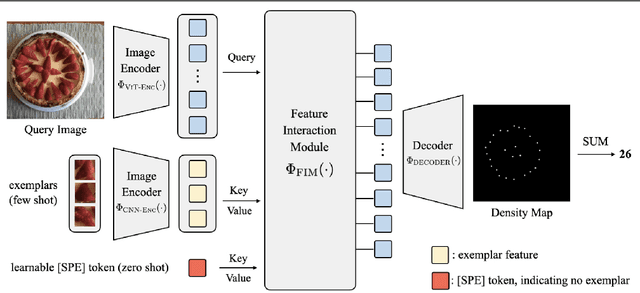
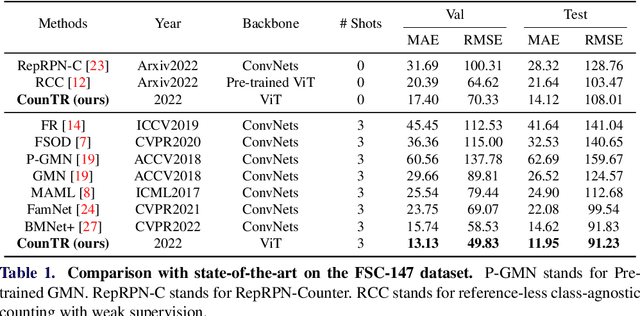

In this paper, we consider the problem of generalised visual object counting, with the goal of developing a computational model for counting the number of objects from arbitrary semantic categories, using arbitrary number of "exemplars", i.e. zero-shot or few-shot counting. To this end, we make the following four contributions: (1) We introduce a novel transformer-based architecture for generalised visual object counting, termed as Counting Transformer (CounTR), which explicitly capture the similarity between image patches or with given "exemplars" with the attention mechanism;(2) We adopt a two-stage training regime, that first pre-trains the model with self-supervised learning, and followed by supervised fine-tuning;(3) We propose a simple, scalable pipeline for synthesizing training images with a large number of instances or that from different semantic categories, explicitly forcing the model to make use of the given "exemplars";(4) We conduct thorough ablation studies on the large-scale counting benchmark, e.g. FSC-147, and demonstrate state-of-the-art performance on both zero and few-shot settings.