 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Shrinking the Semantic Gap: Spatial Pooling of Local Moment Invariants for Copy-Move Forgery Detection
Jul 19, 2022
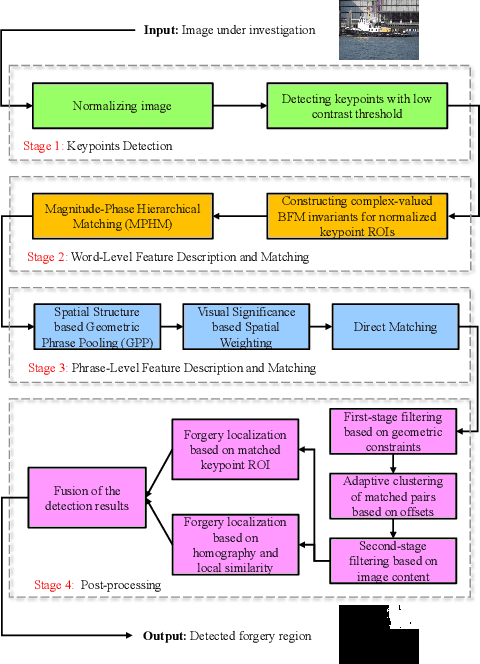
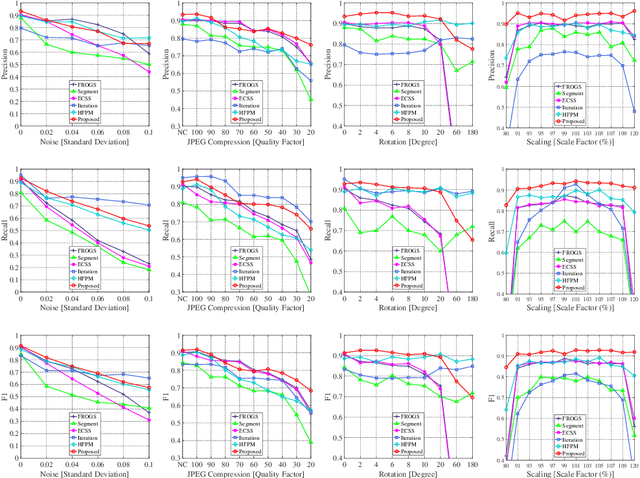
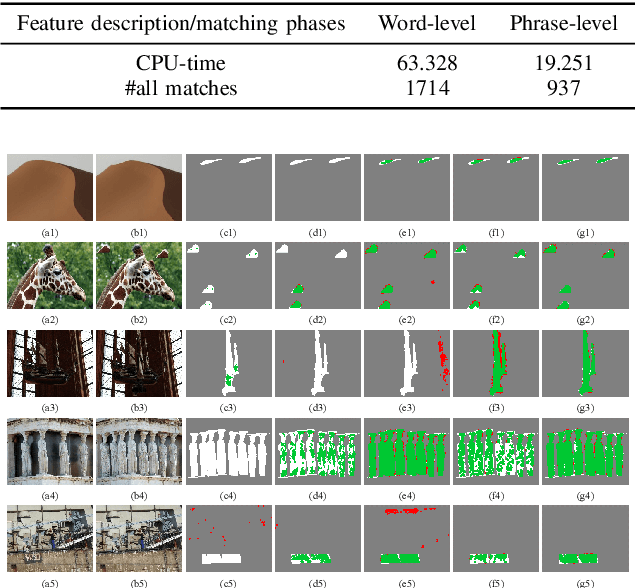

Copy-move forgery is a manipulation of copying and pasting specific patches from and to an image, with potentially illegal or unethical uses. Recent advances in the forensic methods for copy-move forgery have shown increasing success in detection accuracy and robustness. However, for images with high self-similarity or strong signal corruption, the existing algorithms often exhibit inefficient processes and unreliable results. This is mainly due to the inherent semantic gap between low-level visual representation and high-level semantic concept. In this paper, we present a very first study of trying to mitigate the semantic gap problem in copy-move forgery detection, with spatial pooling of local moment invariants for midlevel image representation. Our detection method expands the traditional works on two aspects: 1) we introduce the bag-of-visual-words model into this field for the first time, may meaning a new perspective of forensic study; 2) we propose a word-to-phrase feature description and matching pipeline, covering the spatial structure and visual saliency information of digital images. Extensive experimental results show the superior performance of our framework over state-of-the-art algorithms in overcoming the related problems caused by the semantic gap.
Towards Panoptic 3D Parsing for Single Image in the Wild
Nov 29, 2021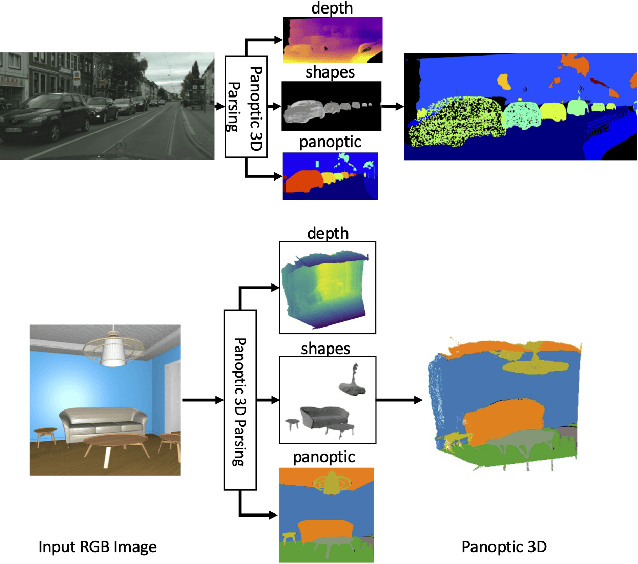
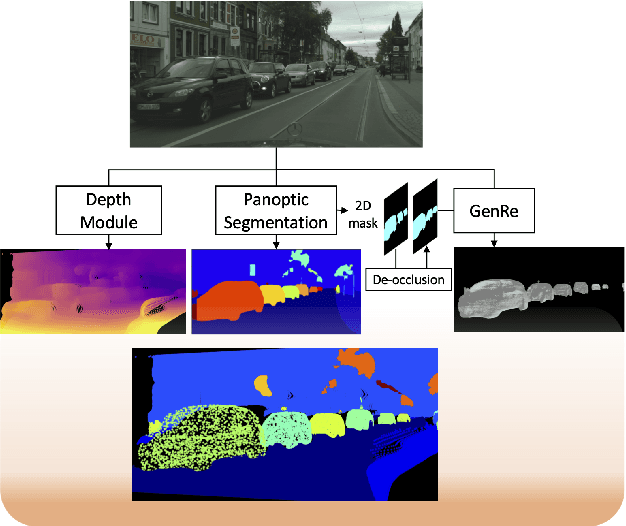

Performing single image holistic understanding and 3D reconstruction is a central task in computer vision. This paper presents an integrated system that performs dense scene labeling, object detection, instance segmentation, depth estimation, 3D shape reconstruction, and 3D layout estimation for indoor and outdoor scenes from a single RGB image. We name our system panoptic 3D parsing (Panoptic3D) in which panoptic segmentation ("stuff" segmentation and "things" detection/segmentation) with 3D reconstruction is performed. We design a stage-wise system, Panoptic3D (stage-wise), where a complete set of annotations is absent. Additionally, we present an end-to-end pipeline, Panoptic3D (end-to-end), trained on a synthetic dataset with a full set of annotations. We show results on both indoor (3D-FRONT) and outdoor (COCO and Cityscapes) scenes. Our proposed panoptic 3D parsing framework points to a promising direction in computer vision. Panoptic3D can be applied to a variety of applications, including autonomous driving, mapping, robotics, design, computer graphics, robotics, human-computer interaction, and augmented reality.
TRUST: An Accurate and End-to-End Table structure Recognizer Using Splitting-based Transformers
Aug 31, 2022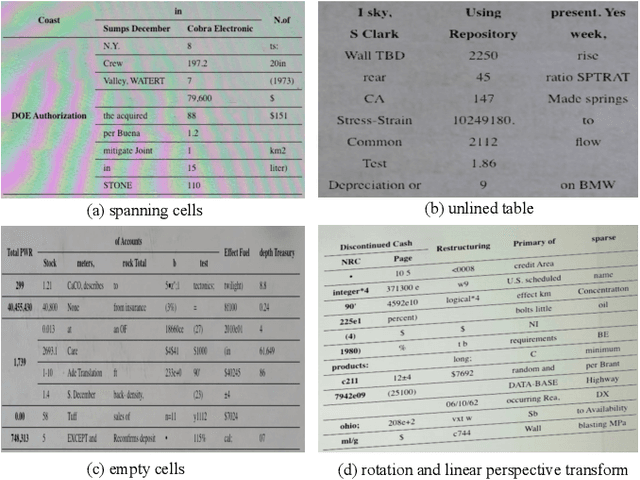
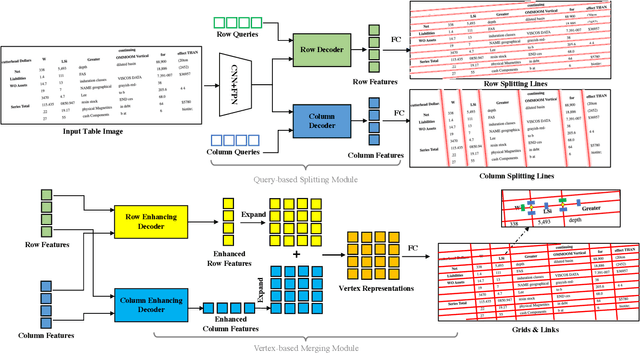
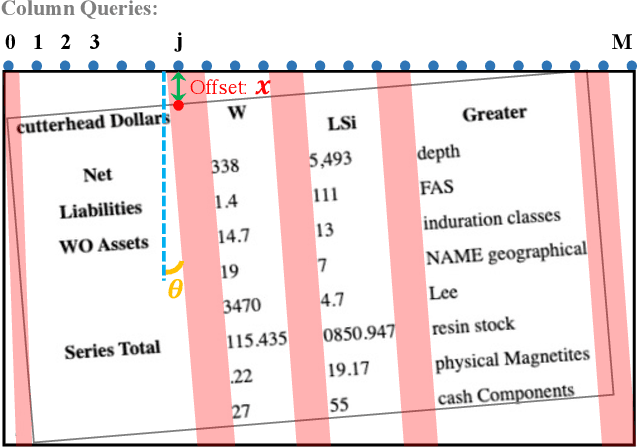
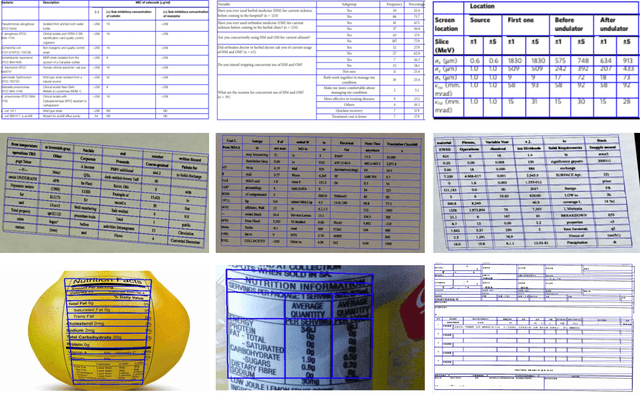
Table structure recognition is a crucial part of document image analysis domain. Its difficulty lies in the need to parse the physical coordinates and logical indices of each cell at the same time. However, the existing methods are difficult to achieve both these goals, especially when the table splitting lines are blurred or tilted. In this paper, we propose an accurate and end-to-end transformer-based table structure recognition method, referred to as TRUST. Transformers are suitable for table structure recognition because of their global computations, perfect memory, and parallel computation. By introducing novel Transformer-based Query-based Splitting Module and Vertex-based Merging Module, the table structure recognition problem is decoupled into two joint optimization sub-tasks: multi-oriented table row/column splitting and table grid merging. The Query-based Splitting Module learns strong context information from long dependencies via Transformer networks, accurately predicts the multi-oriented table row/column separators, and obtains the basic grids of the table accordingly. The Vertex-based Merging Module is capable of aggregating local contextual information between adjacent basic grids, providing the ability to merge basic girds that belong to the same spanning cell accurately. We conduct experiments on several popular benchmarks including PubTabNet and SynthTable, our method achieves new state-of-the-art results. In particular, TRUST runs at 10 FPS on PubTabNet, surpassing the previous methods by a large margin.
Heterogeneous Semantic Transfer for Multi-label Recognition with Partial Labels
May 23, 2022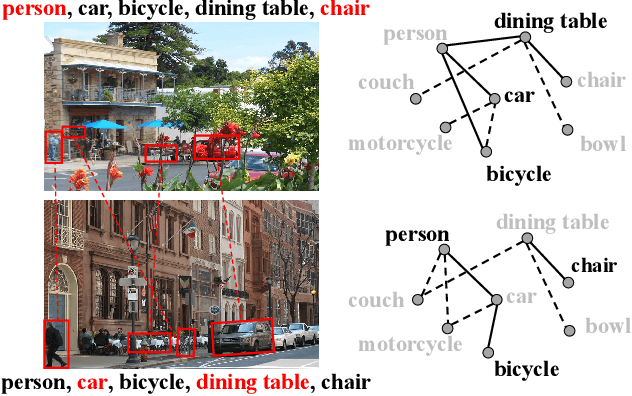
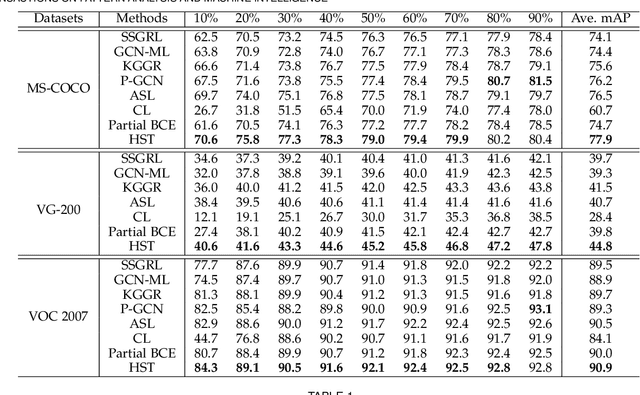

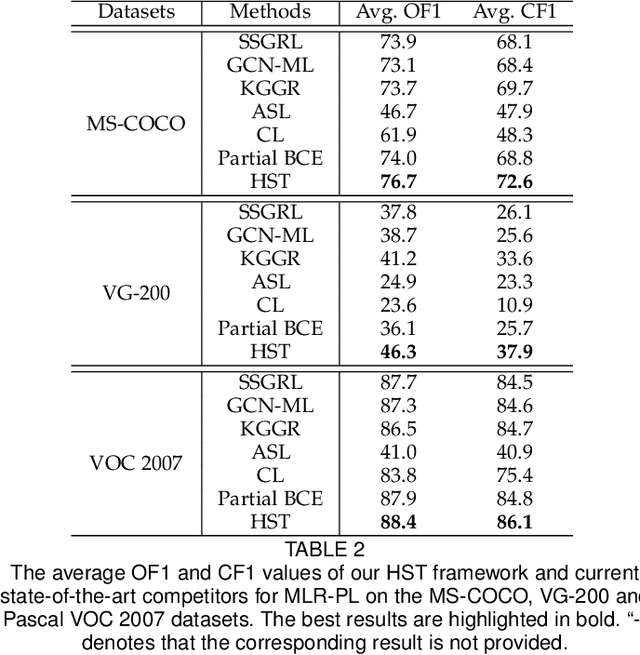
Multi-label image recognition with partial labels (MLR-PL), in which some labels are known while others are unknown for each image, may greatly reduce the cost of annotation and thus facilitate large-scale MLR. We find that strong semantic correlations exist within each image and across different images, and these correlations can help transfer the knowledge possessed by the known labels to retrieve the unknown labels and thus improve the performance of the MLR-PL task (see Figure 1). In this work, we propose a novel heterogeneous semantic transfer (HST) framework that consists of two complementary transfer modules that explore both within-image and cross-image semantic correlations to transfer the knowledge possessed by known labels to generate pseudo labels for the unknown labels. Specifically, an intra-image semantic transfer (IST) module learns an image-specific label co-occurrence matrix for each image and maps the known labels to complement the unknown labels based on these matrices. Additionally, a cross-image transfer (CST) module learns category-specific feature-prototype similarities and then helps complement the unknown labels that have high degrees of similarity with the corresponding prototypes. Finally, both the known and generated pseudo labels are used to train MLR models. Extensive experiments conducted on the Microsoft COCO, Visual Genome, and Pascal VOC 2007 datasets show that the proposed HST framework achieves superior performance to that of current state-of-the-art algorithms. Specifically, it obtains mean average precision (mAP) improvements of 1.4%, 3.3%, and 0.4% on the three datasets over the results of the best-performing previously developed algorithm.
Analysis of Branch Specialization and its Application in Image Decomposition
Jun 12, 2022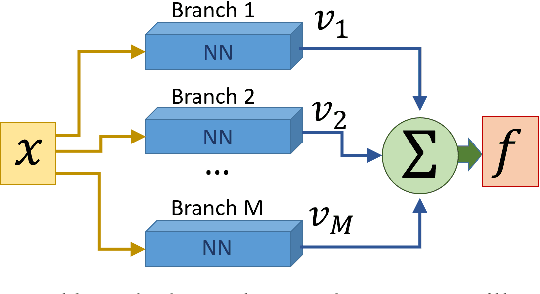
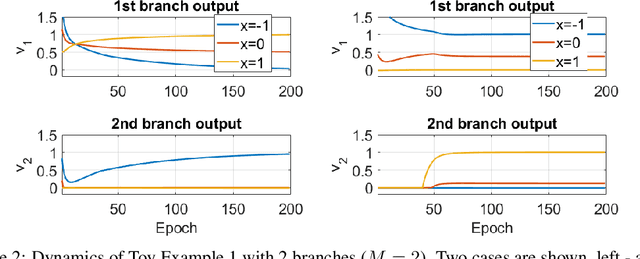
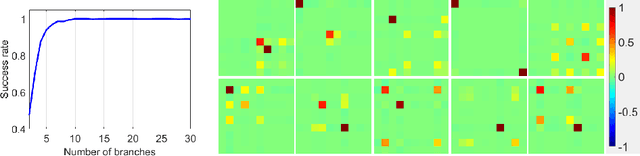
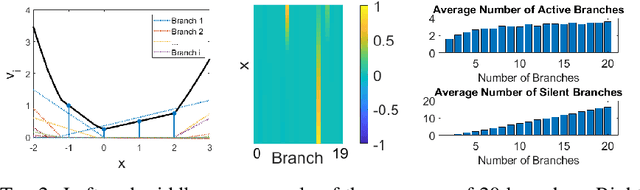
Branched neural networks have been used extensively for a variety of tasks. Branches are sub-parts of the model that perform independent processing followed by aggregation. It is known that this setting induces a phenomenon called Branch Specialization, where different branches become experts in different sub-tasks. Such observations were qualitative by nature. In this work, we present a methodological analysis of Branch Specialization. We explain the role of gradient descent in this phenomenon. We show that branched generative networks naturally decompose animal images to meaningful channels of fur, whiskers and spots and face images to channels such as different illumination components and face parts.
Granular Directed Rough Sets, Concept Organization and Soft Clustering
Aug 13, 2022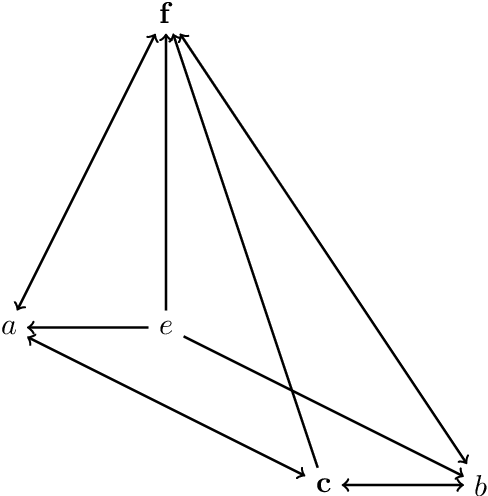

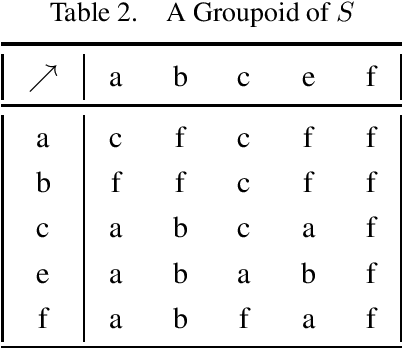
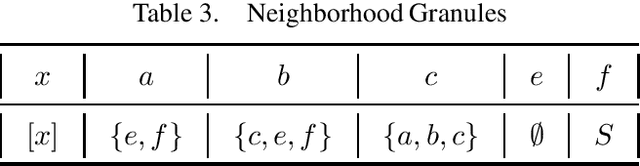
Up-directed rough sets are introduced and studied by the present author in earlier papers. This is extended by her in two different granular directions in this research, with a surprising algebraic semantics. The granules are based on ideas of generalized closure under up-directedness that may be read as a form of weak consequence. This yields approximation operators that satisfy cautious monotony, while pi-groupoidal approximations (that additionally involve strategic choice and algebraic operators) have nicer properties. The study is primarily motivated by possible structure of concepts in distributed cognition perspectives, real or virtual classroom learning contexts, and student-centric teaching. Rough clustering techniques for datasets that involve up-directed relations (as in the study of Sentinel project image data) are additionally proposed. This research is expected to see significant theoretical and practical applications in related domains.
Efficient Motion Modelling with Variable-sized blocks from Hierarchical Cuboidal Partitioning
Aug 28, 2022

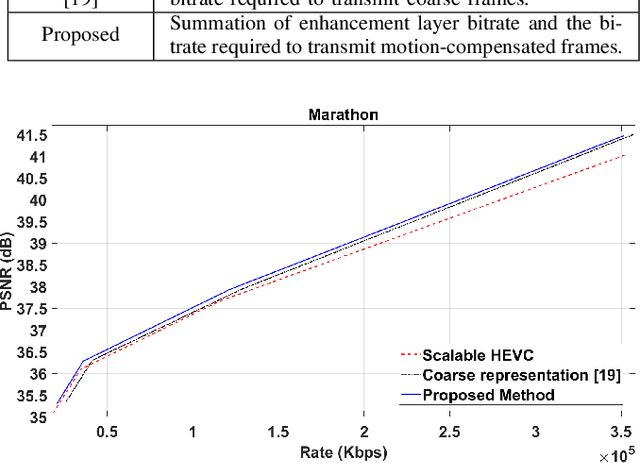
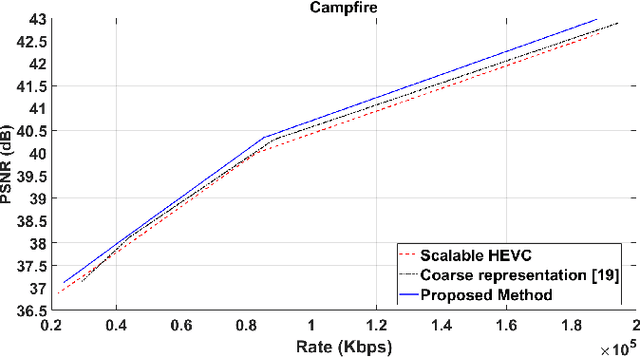
Motion modelling with block-based architecture has been widely used in video coding where a frame is divided into fixed-sized blocks that are motion compensated independently. This often leads to coding inefficiency as fixed-sized blocks hardly align with the object boundaries. Although hierarchical block-partitioning has been introduced to address this, the increased number of motion vectors limits the benefit. Recently, approximate segmentation of images with cuboidal partitioning has gained popularity. Not only are the variable-sized rectangular segments (cuboids) readily amenable to block-based image/video coding techniques, but they are also capable of aligning well with the object boundaries. This is because cuboidal partitioning is based on a homogeneity constraint, minimising the sum of squared errors (SSE). In this paper, we have investigated the potential of cuboids in motion modelling against the fixed-sized blocks used in scalable video coding. Specifically, we have constructed motion-compensated current frame using the cuboidal partitioning information of the anchor frame in a group-of-picture (GOP). The predicted current frame has then been used as the base layer while encoding the current frame as an enhancement layer using the scalable HEVC encoder. Experimental results confirm 6.71%-10.90% bitrate savings on 4K video sequences.
ERS: a novel comprehensive endoscopy image dataset for machine learning, compliant with the MST 3.0 specification
Jan 21, 2022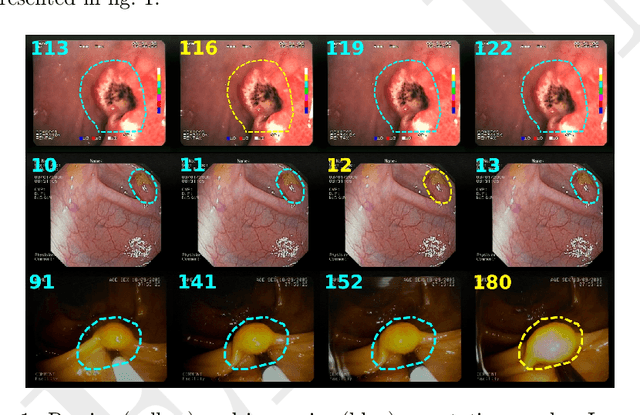
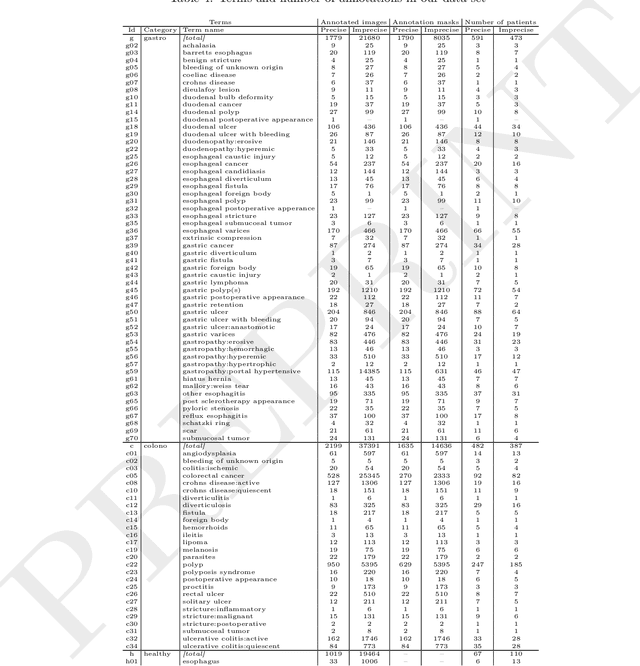

The article presents a new multi-label comprehensive image dataset from flexible endoscopy, colonoscopy and capsule endoscopy, named ERS. The collection has been labeled according to the full medical specification of 'Minimum Standard Terminology 3.0' (MST 3.0), describing all possible findings in the gastrointestinal tract (104 possible labels), extended with an additional 19 labels useful in common machine learning applications. The dataset contains around 6000 precisely and 115,000 approximately labeled frames from endoscopy videos, 3600 precise and 22,600 approximate segmentation masks, and 1.23 million unlabeled frames from flexible and capsule endoscopy videos. The labeled data cover almost entirely the MST 3.0 standard. The data came from 1520 videos of 1135 patients. Additionally, this paper proposes and describes four exemplary experiments in gastrointestinal image classification task performed using the created dataset. The obtained results indicate the high usefulness and flexibility of the dataset in training and testing machine learning algorithms in the field of endoscopic data analysis.
Forward Error Correction applied to JPEG-XS codestreams
Jul 11, 2022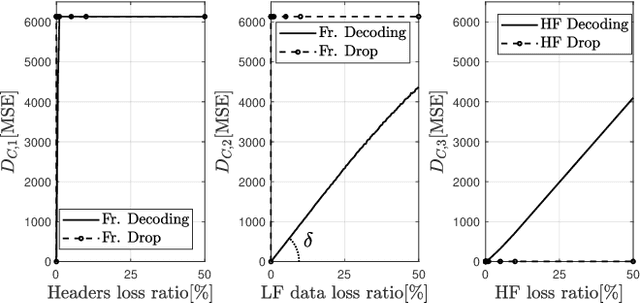
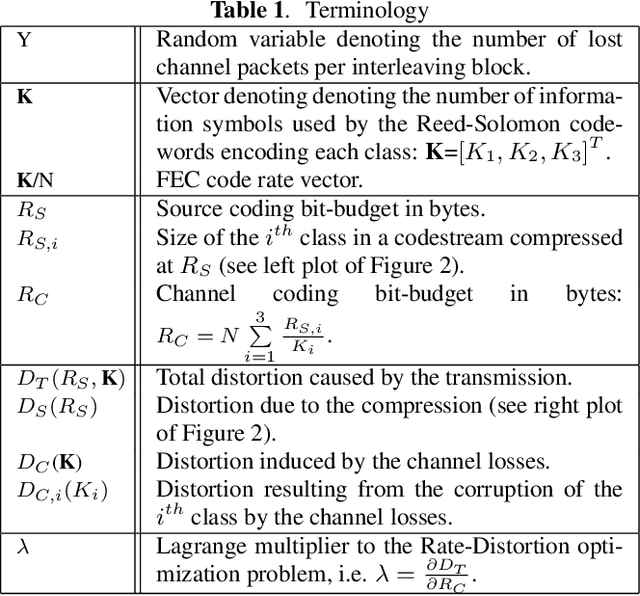
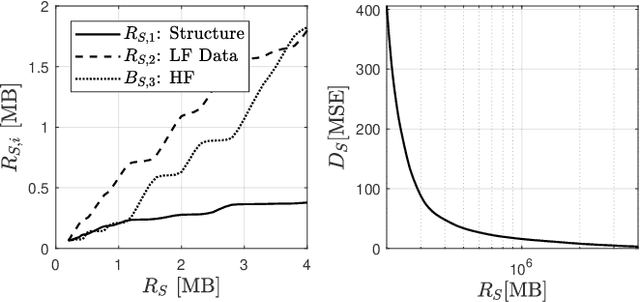
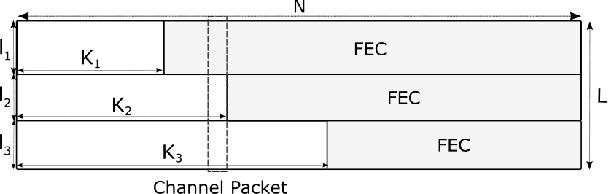
JPEG-XS offers low complexity image compression for applications with constrained but reasonable bit-rate, and low latency. Our paper explores the deployment of JPEG-XS on lossy packet networks. To preserve low latency, Forward Error Correction (FEC) is envisioned as the protection mechanism of interest. Despite the JPEG-XS codestream is not scalable in essence, we observe that the loss of a codestream fraction impacts the decoded image quality differently, depending on whether this codestream fraction corresponds to codestream headers, to coefficients significance information, or to low/high frequency data, respectively. Hence, we propose a rate-distortion optimal unequal error protection scheme that adapts the redundancy level of Reed-Solomon codes according to the rate of channel losses and the type of information protected by the code. Our experiments demonstrate that, at 5% loss rates, it reduces the Mean Squared Error by up to 92% and 65%, compared to a transmission without and with optimal but equal protection, respectively.
Rapid, remote and low-cost finger vasculature mapping for heart rate monitoring
Aug 15, 2022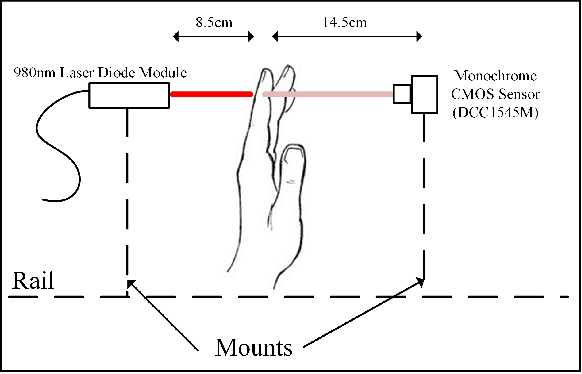

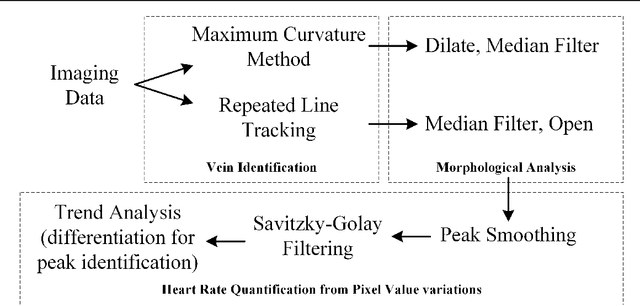

Today's diagnostics include devices such as pulse oximeters, blood pressure monitors, and temperature measurements. These devices provide vital information to medical personnel when making treatment decisions. Drawing inspiration from the fundamental utility of pulse oximeters, we present a methodology for a robust low-cost approach to imaging subsurface vasculature and monitoring heart rate. The approach uses off-the-shelf equipment, set up in free space without physical contact and exploits the nature of the interaction between light at near-infrared wavelengths with tissue. Image processing algorithms extract heart rate information from the snapshot and video sequence captured at a stand-off distance. The method can be applied in a room with ambient light and remains robust to scenarios comparable to medical situations. This research sets the platform for future diagnostic devices based on imaging systems and algorithms for non-contact point-of-care investigations.