 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Contrastive Cross-Modal Knowledge Sharing Pre-training for Vision-Language Representation Learning and Retrieval
Jul 08, 2022
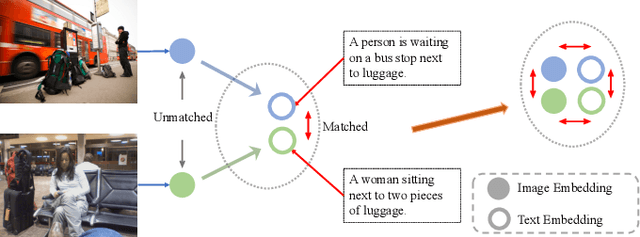
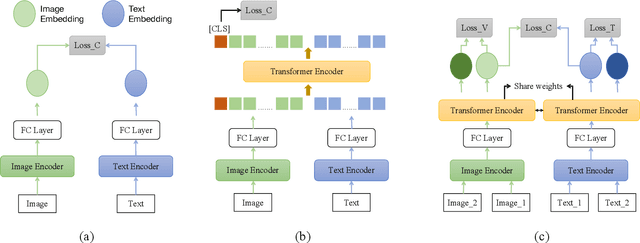
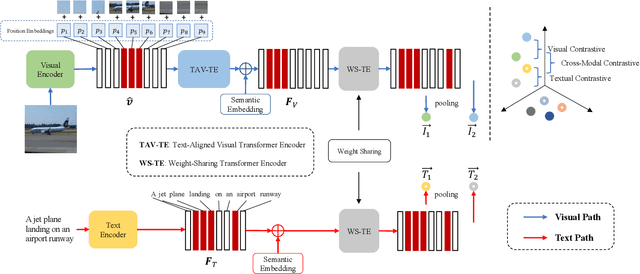

Recently, the cross-modal pre-training task has been a hotspot because of its wide application in various down-streaming researches including retrieval, captioning, question answering and so on. However, exiting methods adopt a one-stream pre-training model to explore the united vision-language representation for conducting cross-modal retrieval, which easily suffer from the calculation explosion. Moreover, although the conventional double-stream structures are quite efficient, they still lack the vital cross-modal interactions, resulting in low performances. Motivated by these challenges, we put forward a Contrastive Cross-Modal Knowledge Sharing Pre-training (COOKIE) to grasp the joint text-image representations. Structurally, COOKIE adopts the traditional double-stream structure because of the acceptable time consumption. To overcome the inherent defects of double-stream structure as mentioned above, we elaborately design two effective modules. Concretely, the first module is a weight-sharing transformer that builds on the head of the visual and textual encoders, aiming to semantically align text and image. This design enables visual and textual paths focus on the same semantics. The other one is three specially designed contrastive learning, aiming to share knowledge between different models. The shared cross-modal knowledge develops the study of unimodal representation greatly, promoting the single-modal retrieval tasks. Extensive experimental results on multi-modal matching researches that includes cross-modal retrieval, text matching, and image retrieval reveal the superiors in calculation efficiency and statistical indicators of our pre-training model.
The Weighting Game: Evaluating Quality of Explainability Methods
Aug 12, 2022
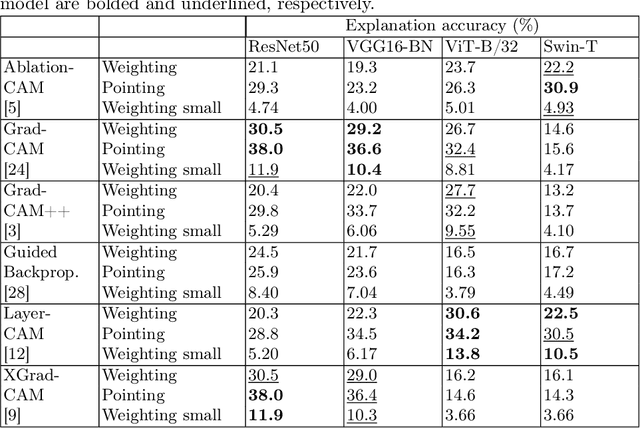

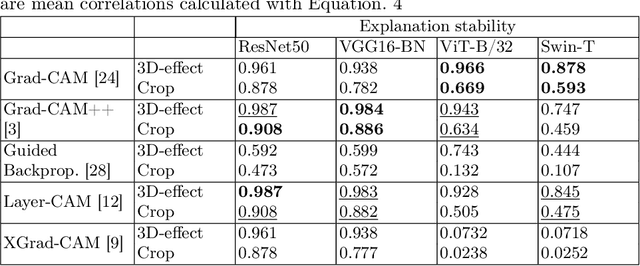
The objective of this paper is to assess the quality of explanation heatmaps for image classification tasks. To assess the quality of explainability methods, we approach the task through the lens of accuracy and stability. In this work, we make the following contributions. Firstly, we introduce the Weighting Game, which measures how much of a class-guided explanation is contained within the correct class' segmentation mask. Secondly, we introduce a metric for explanation stability, using zooming/panning transformations to measure differences between saliency maps with similar contents. Quantitative experiments are produced, using these new metrics, to evaluate the quality of explanations provided by commonly used CAM methods. The quality of explanations is also contrasted between different model architectures, with findings highlighting the need to consider model architecture when choosing an explainability method.
Video Coding Using Learned Latent GAN Compression
Jul 12, 2022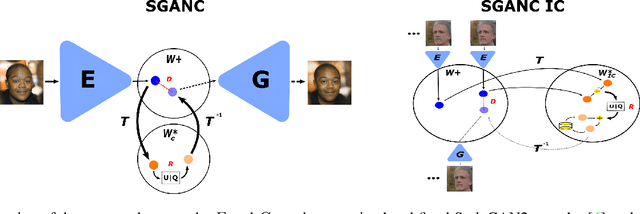

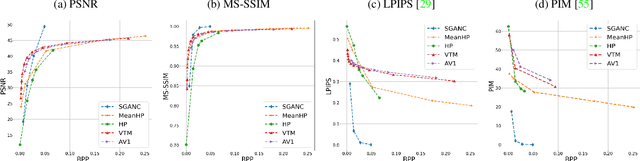

We propose in this paper a new paradigm for facial video compression. We leverage the generative capacity of GANs such as StyleGAN to represent and compress a video, including intra and inter compression. Each frame is inverted in the latent space of StyleGAN, from which the optimal compression is learned. To do so, a diffeomorphic latent representation is learned using a normalizing flows model, where an entropy model can be optimized for image coding. In addition, we propose a new perceptual loss that is more efficient than other counterparts. Finally, an entropy model for video inter coding with residual is also learned in the previously constructed latent representation. Our method (SGANC) is simple, faster to train, and achieves better results for image and video coding compared to state-of-the-art codecs such as VTM, AV1, and recent deep learning techniques. In particular, it drastically minimizes perceptual distortion at low bit rates.
Reconstruct Face from Features Using GAN Generator as a Distribution Constraint
Jun 09, 2022
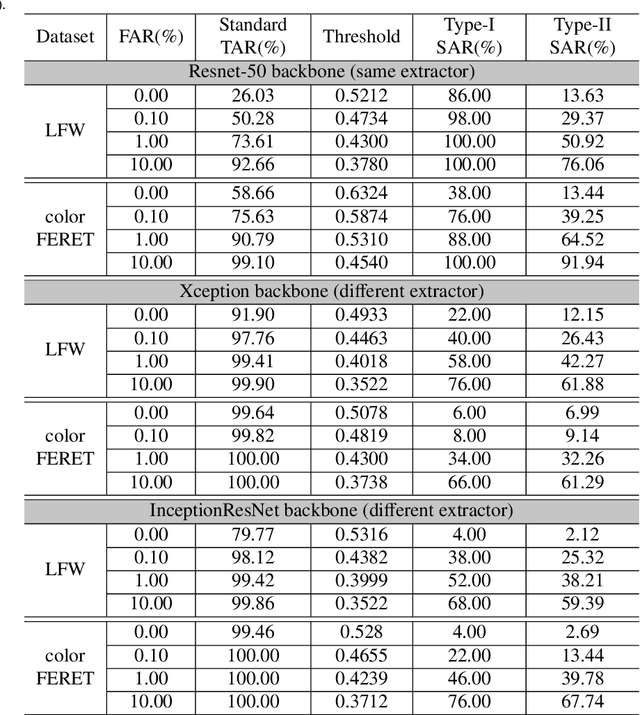
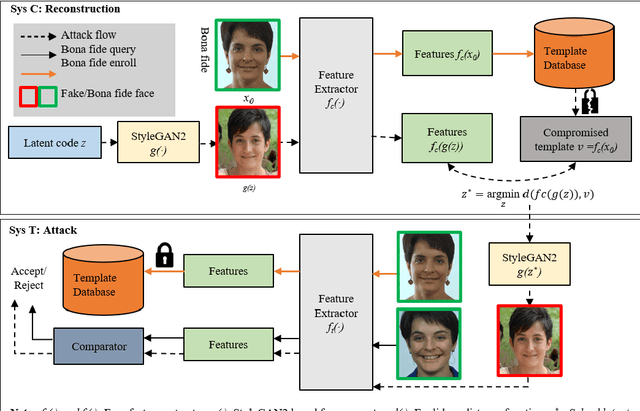
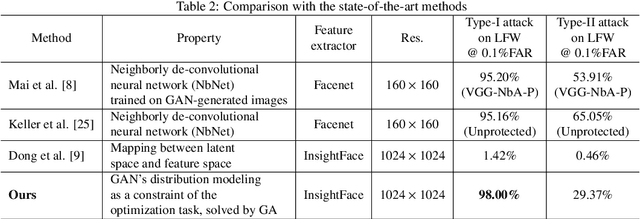
Face recognition based on the deep convolutional neural networks (CNN) shows superior accuracy performance attributed to the high discriminative features extracted. Yet, the security and privacy of the extracted features from deep learning models (deep features) have been often overlooked. This paper proposes the reconstruction of face images from deep features without accessing the CNN network configurations as a constrained optimization problem. Such optimization minimizes the distance between the features extracted from the original face image and the reconstructed face image. Instead of directly solving the optimization problem in the image space, we innovatively reformulate the problem by looking for a latent vector of a GAN generator, then use it to generate the face image. The GAN generator serves as a dual role in this novel framework, i.e., face distribution constraint of the optimization goal and a face generator. On top of the novel optimization task, we also propose an attack pipeline to impersonate the target user based on the generated face image. Our results show that the generated face images can achieve a state-of-the-art successful attack rate of 98.0\% on LFW under type-I attack @ FAR of 0.1\%. Our work sheds light on the biometric deployment to meet the privacy-preserving and security policies.
Three multi-objective memtic algorithms for observation scheduling problem of active-imaging AEOS
Jul 04, 2022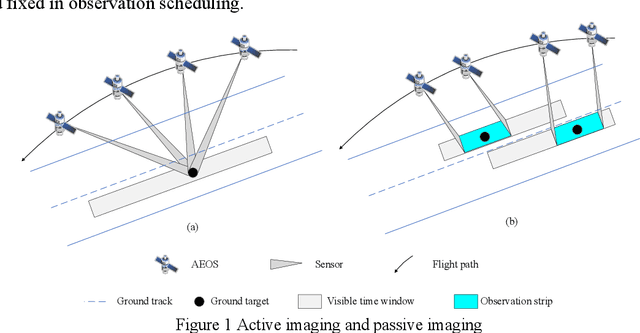
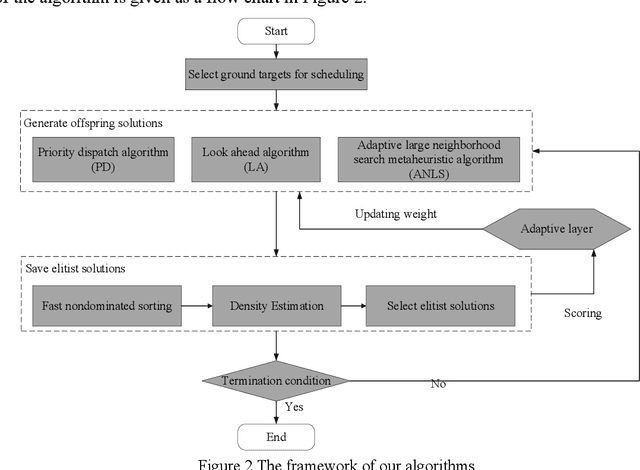
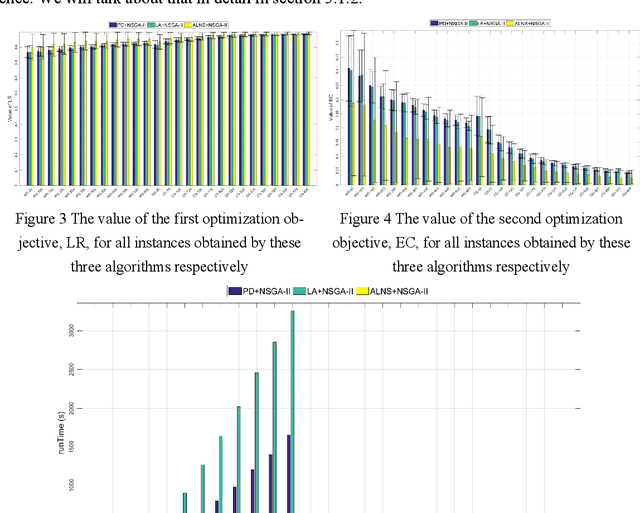
Observation scheduling problem for agile earth observation satellites (OSPFAS) plays a critical role in management of agile earth observation satellites (AEOSs). Active imaging enriches the extension of OSPFAS, we call the novel problem as observation scheduling problem for AEOS with variable image duration (OSWVID). A cumulative image quality and a detailed energy consumption is proposed to build OSWVID as a bi-objective optimization model. Three multi-objective memetic algorithms, PD+NSGA-II, LA+NSGA-II and ALNS+NSGA-II, are then designed to solve OSWVID. Considering the heuristic knowledge summarized in our previous research, several operators are designed for improving these three algorithms respectively. Based on existing instances, we analyze the critical parameters optimization, operators evolution, and efficiency of these three algorithms according to extensive simulation experiments.
Distributed Attention for Grounded Image Captioning
Aug 22, 2021
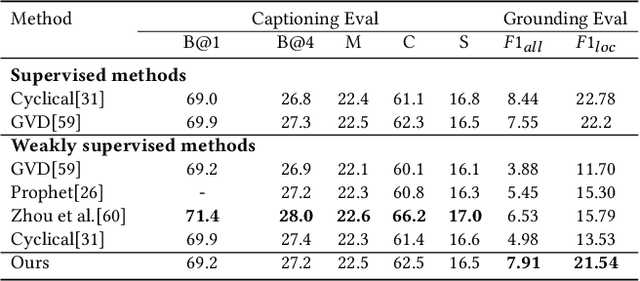
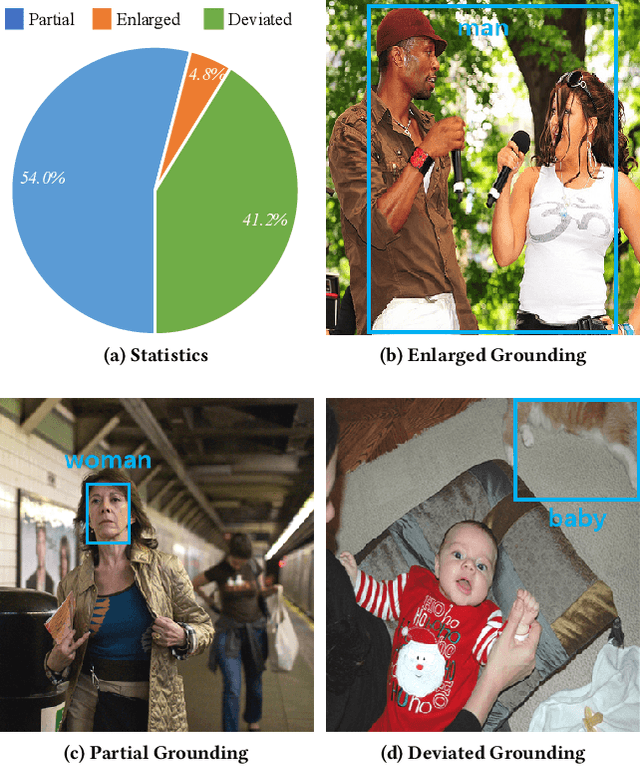
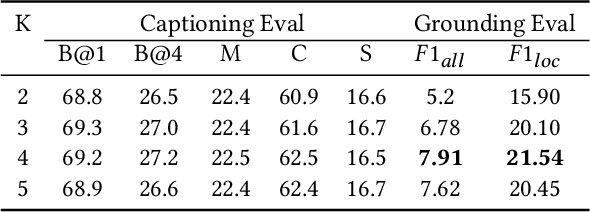
We study the problem of weakly supervised grounded image captioning. That is, given an image, the goal is to automatically generate a sentence describing the context of the image with each noun word grounded to the corresponding region in the image. This task is challenging due to the lack of explicit fine-grained region word alignments as supervision. Previous weakly supervised methods mainly explore various kinds of regularization schemes to improve attention accuracy. However, their performances are still far from the fully supervised ones. One main issue that has been ignored is that the attention for generating visually groundable words may only focus on the most discriminate parts and can not cover the whole object. To this end, we propose a simple yet effective method to alleviate the issue, termed as partial grounding problem in our paper. Specifically, we design a distributed attention mechanism to enforce the network to aggregate information from multiple spatially different regions with consistent semantics while generating the words. Therefore, the union of the focused region proposals should form a visual region that encloses the object of interest completely. Extensive experiments have demonstrated the superiority of our proposed method compared with the state-of-the-arts.
Your ViT is Secretly a Hybrid Discriminative-Generative Diffusion Model
Aug 16, 2022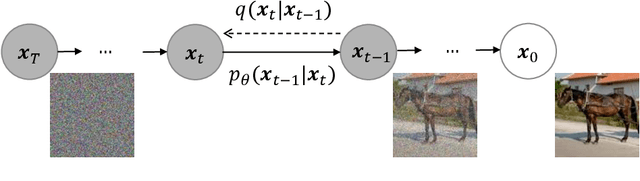
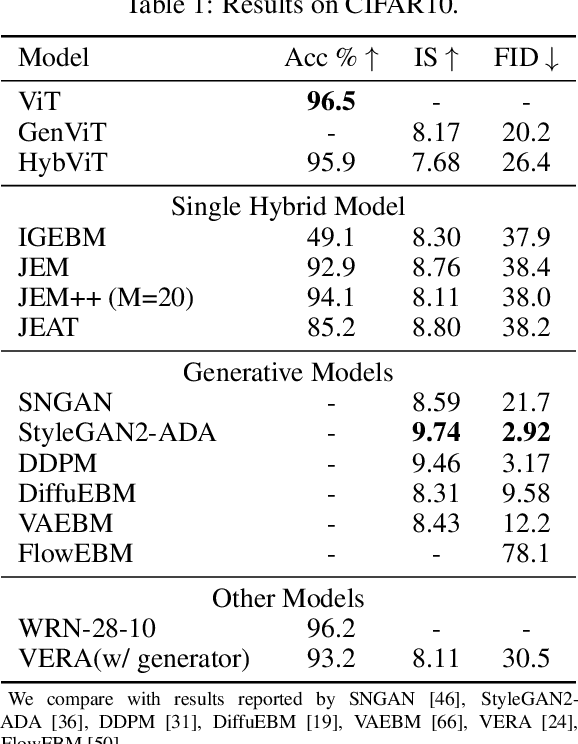
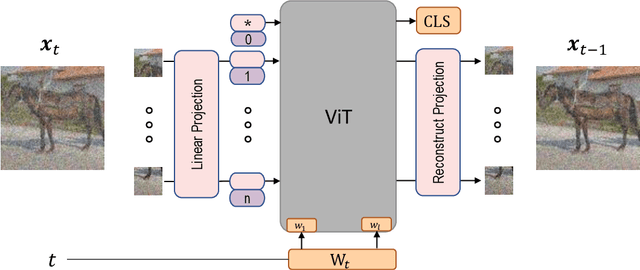
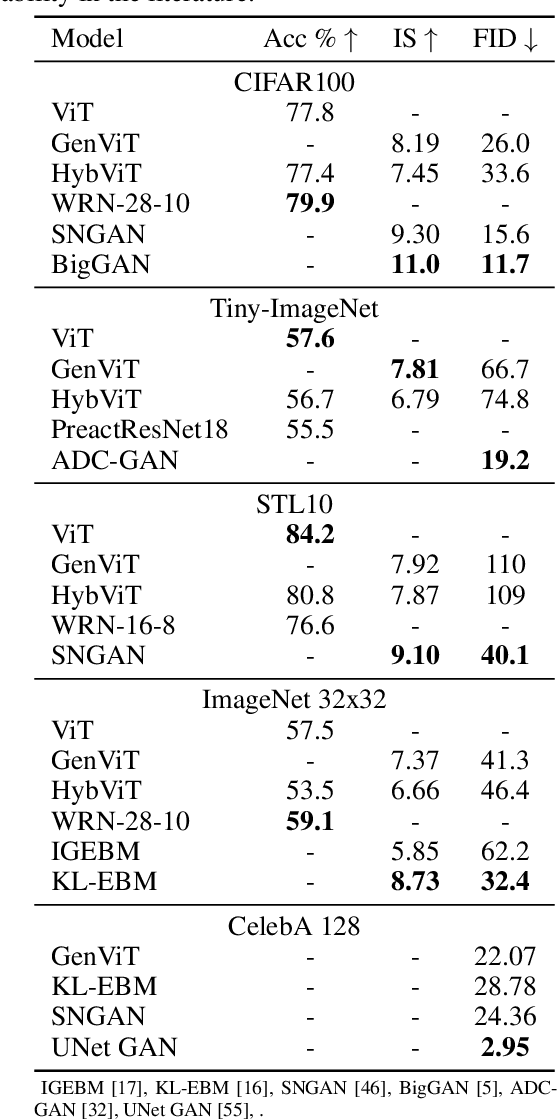
Diffusion Denoising Probability Models (DDPM) and Vision Transformer (ViT) have demonstrated significant progress in generative tasks and discriminative tasks, respectively, and thus far these models have largely been developed in their own domains. In this paper, we establish a direct connection between DDPM and ViT by integrating the ViT architecture into DDPM, and introduce a new generative model called Generative ViT (GenViT). The modeling flexibility of ViT enables us to further extend GenViT to hybrid discriminative-generative modeling, and introduce a Hybrid ViT (HybViT). Our work is among the first to explore a single ViT for image generation and classification jointly. We conduct a series of experiments to analyze the performance of proposed models and demonstrate their superiority over prior state-of-the-arts in both generative and discriminative tasks. Our code and pre-trained models can be found in https://github.com/sndnyang/Diffusion_ViT .
The Image Local Autoregressive Transformer
Jun 04, 2021

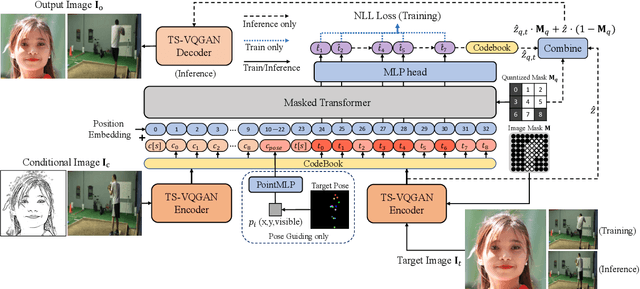
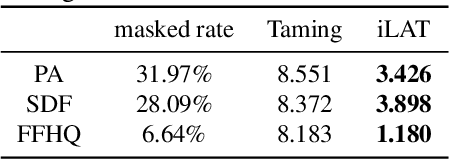
Recently, AutoRegressive (AR) models for the whole image generation empowered by transformers have achieved comparable or even better performance to Generative Adversarial Networks (GANs). Unfortunately, directly applying such AR models to edit/change local image regions, may suffer from the problems of missing global information, slow inference speed, and information leakage of local guidance. To address these limitations, we propose a novel model -- image Local Autoregressive Transformer (iLAT), to better facilitate the locally guided image synthesis. Our iLAT learns the novel local discrete representations, by the newly proposed local autoregressive (LA) transformer of the attention mask and convolution mechanism. Thus iLAT can efficiently synthesize the local image regions by key guidance information. Our iLAT is evaluated on various locally guided image syntheses, such as pose-guided person image synthesis and face editing. Both the quantitative and qualitative results show the efficacy of our model.
STS: Surround-view Temporal Stereo for Multi-view 3D Detection
Aug 22, 2022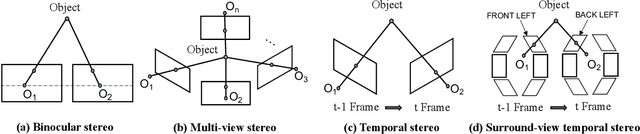
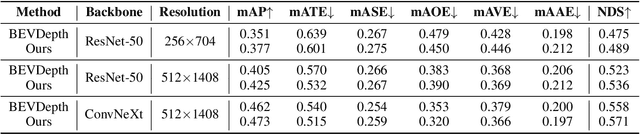
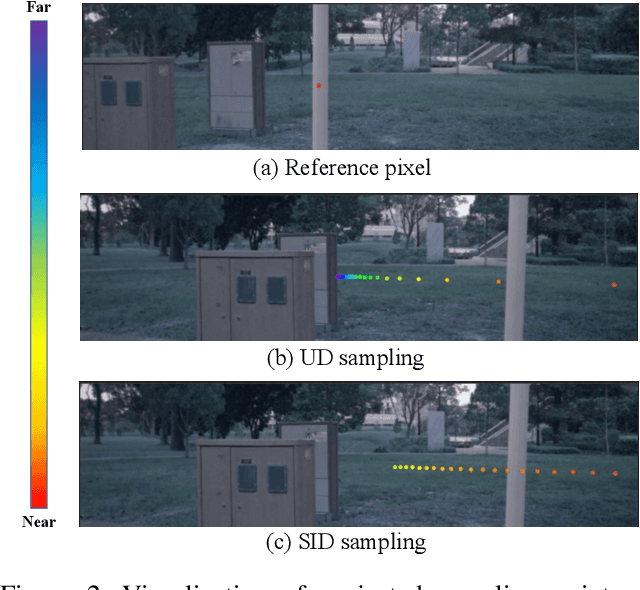
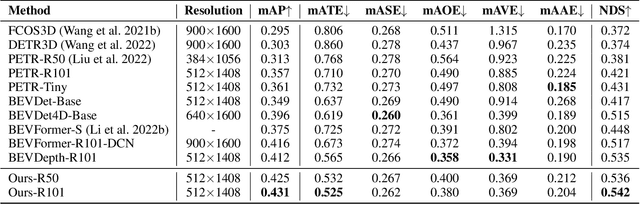
Learning accurate depth is essential to multi-view 3D object detection. Recent approaches mainly learn depth from monocular images, which confront inherent difficulties due to the ill-posed nature of monocular depth learning. Instead of using a sole monocular depth method, in this work, we propose a novel Surround-view Temporal Stereo (STS) technique that leverages the geometry correspondence between frames across time to facilitate accurate depth learning. Specifically, we regard the field of views from all cameras around the ego vehicle as a unified view, namely surroundview, and conduct temporal stereo matching on it. The resulting geometrical correspondence between different frames from STS is utilized and combined with the monocular depth to yield final depth prediction. Comprehensive experiments on nuScenes show that STS greatly boosts 3D detection ability, notably for medium and long distance objects. On BEVDepth with ResNet-50 backbone, STS improves mAP and NDS by 2.6% and 1.4%, respectively. Consistent improvements are observed when using a larger backbone and a larger image resolution, demonstrating its effectiveness
3D Photo Stylization: Learning to Generate Stylized Novel Views from a Single Image
Nov 30, 2021
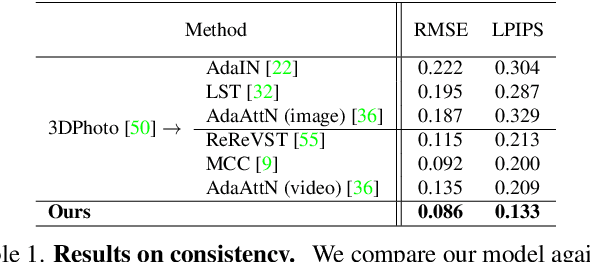

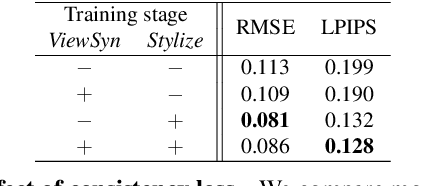
Visual content creation has spurred a soaring interest given its applications in mobile photography and AR / VR. Style transfer and single-image 3D photography as two representative tasks have so far evolved independently. In this paper, we make a connection between the two, and address the challenging task of 3D photo stylization - generating stylized novel views from a single image given an arbitrary style. Our key intuition is that style transfer and view synthesis have to be jointly modeled for this task. To this end, we propose a deep model that learns geometry-aware content features for stylization from a point cloud representation of the scene, resulting in high-quality stylized images that are consistent across views. Further, we introduce a novel training protocol to enable the learning using only 2D images. We demonstrate the superiority of our method via extensive qualitative and quantitative studies, and showcase key applications of our method in light of the growing demand for 3D content creation from 2D image assets.