 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Enhancing Steganographic Text Extraction: Evaluating the Impact of NLP Models on Accuracy and Semantic Coherence
Feb 29, 2024
This study discusses a new method combining image steganography technology with Natural Language Processing (NLP) large models, aimed at improving the accuracy and robustness of extracting steganographic text. Traditional Least Significant Bit (LSB) steganography techniques face challenges in accuracy and robustness of information extraction when dealing with complex character encoding, such as Chinese characters. To address this issue, this study proposes an innovative LSB-NLP hybrid framework. This framework integrates the advanced capabilities of NLP large models, such as error detection, correction, and semantic consistency analysis, as well as information reconstruction techniques, thereby significantly enhancing the robustness of steganographic text extraction. Experimental results show that the LSB-NLP hybrid framework excels in improving the extraction accuracy of steganographic text, especially in handling Chinese characters. The findings of this study not only confirm the effectiveness of combining image steganography technology and NLP large models but also propose new ideas for research and application in the field of information hiding. The successful implementation of this interdisciplinary approach demonstrates the great potential of integrating image steganography technology with natural language processing technology in solving complex information processing problems.
PE-MVCNet: Multi-view and Cross-modal Fusion Network for Pulmonary Embolism Prediction
Feb 29, 2024The early detection of a pulmonary embolism (PE) is critical for enhancing patient survival rates. Both image-based and non-image-based features are of utmost importance in medical classification tasks. In a clinical setting, physicians tend to rely on the contextual information provided by Electronic Medical Records (EMR) to interpret medical imaging. However, very few models effectively integrate clinical information with imaging data. To address this shortcoming, we suggest a multimodal fusion methodology, termed PE-MVCNet, which capitalizes on Computed Tomography Pulmonary Angiography imaging and EMR data. This method comprises the Image-only module with an integrated multi-view block, the EMR-only module, and the Cross-modal Attention Fusion (CMAF) module. These modules cooperate to extract comprehensive features that subsequently generate predictions for PE. We conducted experiments using the publicly accessible Stanford University Medical Center dataset, achieving an AUROC of 94.1%, an accuracy rate of 90.2%, and an F1 score of 90.6%. Our proposed model outperforms existing methodologies, corroborating that our multimodal fusion model excels compared to models that use a single data modality. Our source code is available at https://github.com/LeavingStarW/PE-MVCNET.
How to Understand "Support"? An Implicit-enhanced Causal Inference Approach for Weakly-supervised Phrase Grounding
Mar 04, 2024Weakly-supervised Phrase Grounding (WPG) is an emerging task of inferring the fine-grained phrase-region matching, while merely leveraging the coarse-grained sentence-image pairs for training. However, existing studies on WPG largely ignore the implicit phrase-region matching relations, which are crucial for evaluating the capability of models in understanding the deep multimodal semantics. To this end, this paper proposes an Implicit-Enhanced Causal Inference (IECI) approach to address the challenges of modeling the implicit relations and highlighting them beyond the explicit. Specifically, this approach leverages both the intervention and counterfactual techniques to tackle the above two challenges respectively. Furthermore, a high-quality implicit-enhanced dataset is annotated to evaluate IECI and detailed evaluations show the great advantages of IECI over the state-of-the-art baselines. Particularly, we observe an interesting finding that IECI outperforms the advanced multimodal LLMs by a large margin on this implicit-enhanced dataset, which may facilitate more research to evaluate the multimodal LLMs in this direction.
TEXterity -- Tactile Extrinsic deXterity: Simultaneous Tactile Estimation and Control for Extrinsic Dexterity
Mar 04, 2024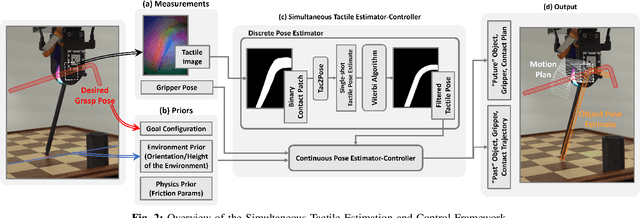
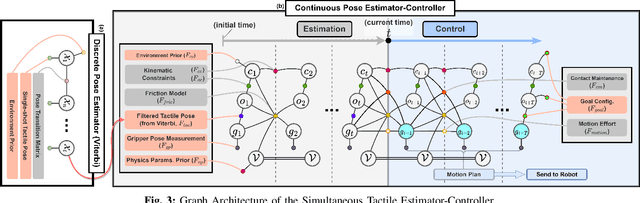
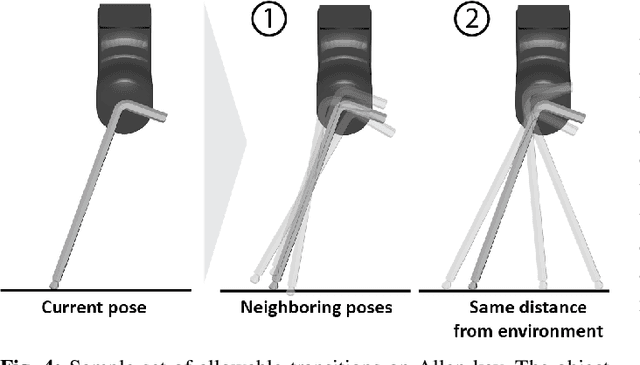
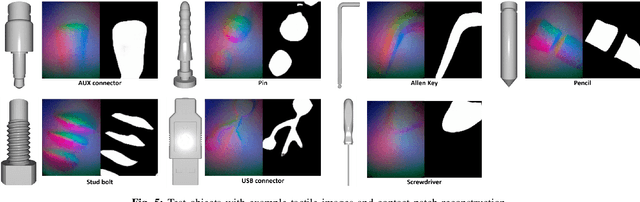
We introduce a novel approach that combines tactile estimation and control for in-hand object manipulation. By integrating measurements from robot kinematics and an image-based tactile sensor, our framework estimates and tracks object pose while simultaneously generating motion plans in a receding horizon fashion to control the pose of a grasped object. This approach consists of a discrete pose estimator that tracks the most likely sequence of object poses in a coarsely discretized grid, and a continuous pose estimator-controller to refine the pose estimate and accurately manipulate the pose of the grasped object. Our method is tested on diverse objects and configurations, achieving desired manipulation objectives and outperforming single-shot methods in estimation accuracy. The proposed approach holds potential for tasks requiring precise manipulation and limited intrinsic in-hand dexterity under visual occlusion, laying the foundation for closed-loop behavior in applications such as regrasping, insertion, and tool use. Please see https://sites.google.com/view/texterity for videos of real-world demonstrations.
Making Pre-trained Language Models Great on Tabular Prediction
Mar 04, 2024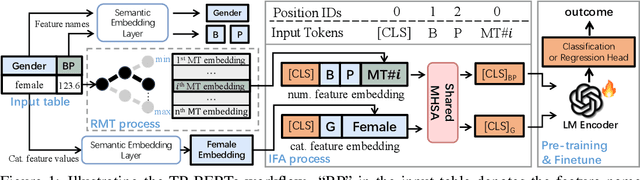
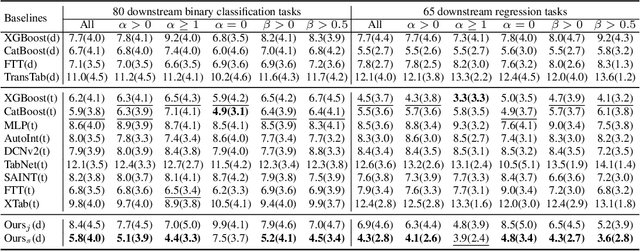
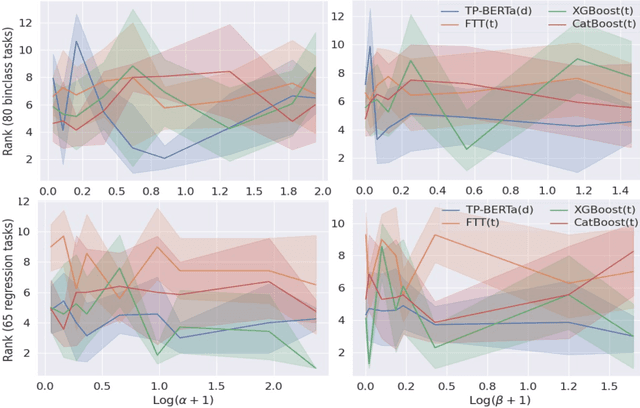
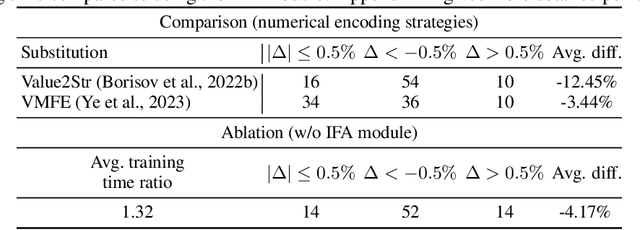
The transferability of deep neural networks (DNNs) has made significant progress in image and language processing. However, due to the heterogeneity among tables, such DNN bonus is still far from being well exploited on tabular data prediction (e.g., regression or classification tasks). Condensing knowledge from diverse domains, language models (LMs) possess the capability to comprehend feature names from various tables, potentially serving as versatile learners in transferring knowledge across distinct tables and diverse prediction tasks, but their discrete text representation space is inherently incompatible with numerical feature values in tables. In this paper, we present TP-BERTa, a specifically pre-trained LM model for tabular data prediction. Concretely, a novel relative magnitude tokenization converts scalar numerical feature values to finely discrete, high-dimensional tokens, and an intra-feature attention approach integrates feature values with the corresponding feature names. Comprehensive experiments demonstrate that our pre-trained TP-BERTa leads the performance among tabular DNNs and is competitive with Gradient Boosted Decision Tree models in typical tabular data regime.
VTG-GPT: Tuning-Free Zero-Shot Video Temporal Grounding with GPT
Mar 04, 2024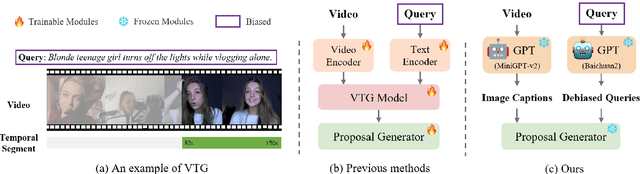
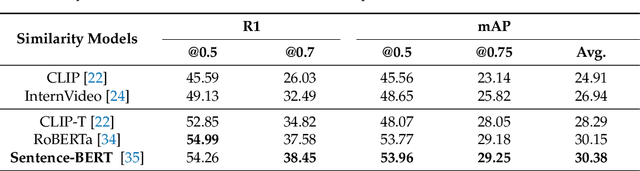

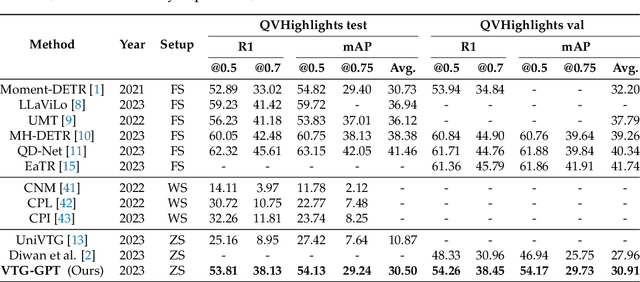
Video temporal grounding (VTG) aims to locate specific temporal segments from an untrimmed video based on a linguistic query. Most existing VTG models are trained on extensive annotated video-text pairs, a process that not only introduces human biases from the queries but also incurs significant computational costs. To tackle these challenges, we propose VTG-GPT, a GPT-based method for zero-shot VTG without training or fine-tuning. To reduce prejudice in the original query, we employ Baichuan2 to generate debiased queries. To lessen redundant information in videos, we apply MiniGPT-v2 to transform visual content into more precise captions. Finally, we devise the proposal generator and post-processing to produce accurate segments from debiased queries and image captions. Extensive experiments demonstrate that VTG-GPT significantly outperforms SOTA methods in zero-shot settings and surpasses unsupervised approaches. More notably, it achieves competitive performance comparable to supervised methods. The code is available on https://github.com/YoucanBaby/VTG-GPT
TAMM: TriAdapter Multi-Modal Learning for 3D Shape Understanding
Feb 28, 2024The limited scale of current 3D shape datasets hinders the advancements in 3D shape understanding, and motivates multi-modal learning approaches which transfer learned knowledge from data-abundant 2D image and language modalities to 3D shapes. However, even though the image and language representations have been aligned by cross-modal models like CLIP, we find that the image modality fails to contribute as much as the language in existing multi-modal 3D representation learning methods. This is attributed to the domain shift in the 2D images and the distinct focus of each modality. To more effectively leverage both modalities in the pre-training, we introduce TriAdapter Multi-Modal Learning (TAMM) -- a novel two-stage learning approach based on three synergetic adapters. First, our CLIP Image Adapter mitigates the domain gap between 3D-rendered images and natural images, by adapting the visual representations of CLIP for synthetic image-text pairs. Subsequently, our Dual Adapters decouple the 3D shape representation space into two complementary sub-spaces: one focusing on visual attributes and the other for semantic understanding, which ensure a more comprehensive and effective multi-modal pre-training. Extensive experiments demonstrate that TAMM consistently enhances 3D representations for a wide range of 3D encoder architectures, pre-training datasets, and downstream tasks. Notably, we boost the zero-shot classification accuracy on Objaverse-LVIS from 46.8 to 50.7, and improve the 5-way 10-shot linear probing classification accuracy on ModelNet40 from 96.1 to 99.0. Project page: \url{https://alanzhangcs.github.io/tamm-page}.
Flattening Singular Values of Factorized Convolution for Medical Images
Mar 01, 2024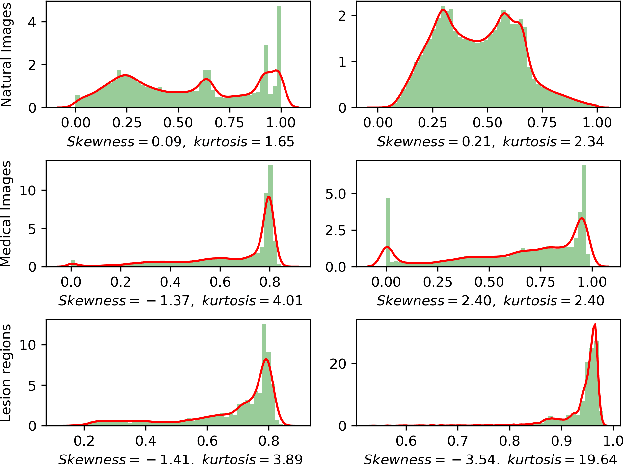
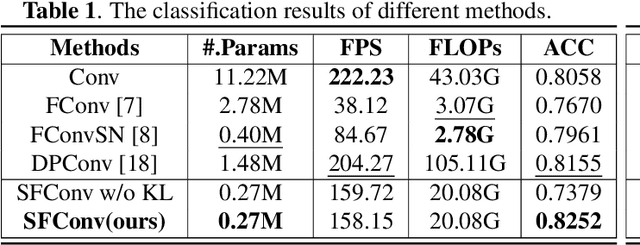
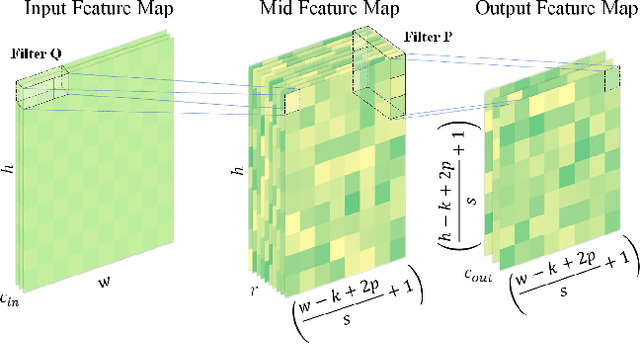
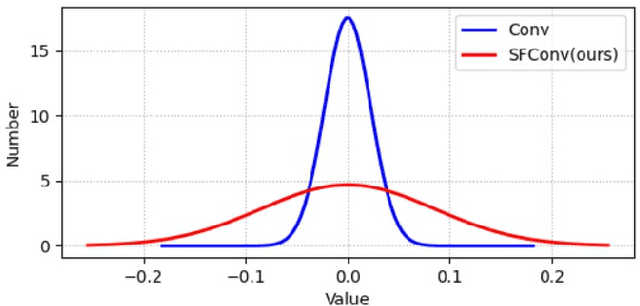
Convolutional neural networks (CNNs) have long been the paradigm of choice for robust medical image processing (MIP). Therefore, it is crucial to effectively and efficiently deploy CNNs on devices with different computing capabilities to support computer-aided diagnosis. Many methods employ factorized convolutional layers to alleviate the burden of limited computational resources at the expense of expressiveness. To this end, given weak medical image-driven CNN model optimization, a Singular value equalization generalizer-induced Factorized Convolution (SFConv) is proposed to improve the expressive power of factorized convolutions in MIP models. We first decompose the weight matrix of convolutional filters into two low-rank matrices to achieve model reduction. Then minimize the KL divergence between the two low-rank weight matrices and the uniform distribution, thereby reducing the number of singular value directions with significant variance. Extensive experiments on fundus and OCTA datasets demonstrate that our SFConv yields competitive expressiveness over vanilla convolutions while reducing complexity.
G-EvoNAS: Evolutionary Neural Architecture Search Based on Network Growth
Mar 05, 2024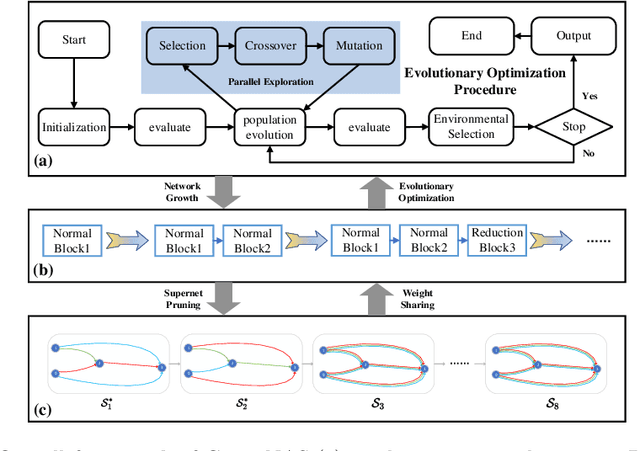
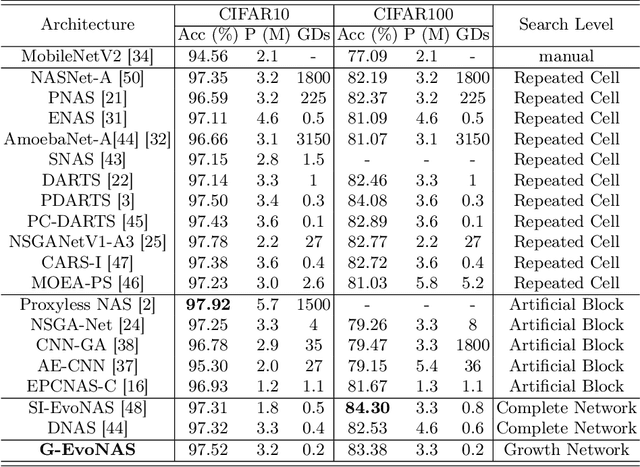
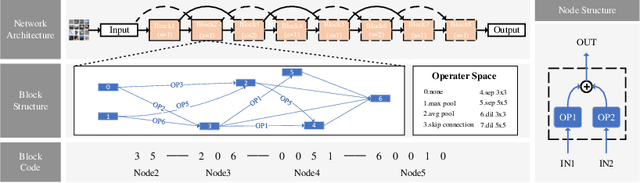
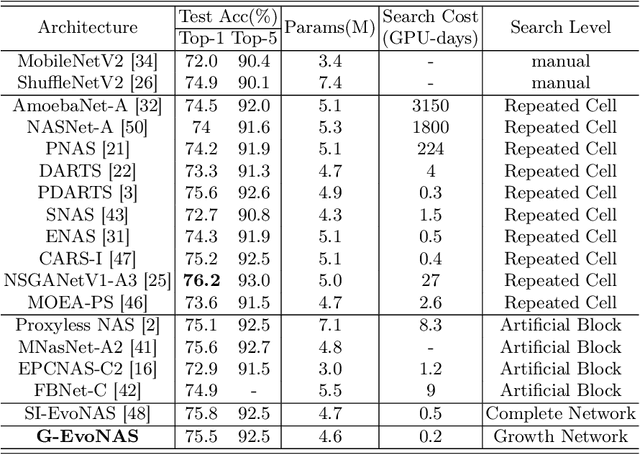
The evolutionary paradigm has been successfully applied to neural network search(NAS) in recent years. Due to the vast search complexity of the global space, current research mainly seeks to repeatedly stack partial architectures to build the entire model or to seek the entire model based on manually designed benchmark modules. The above two methods are attempts to reduce the search difficulty by narrowing the search space. To efficiently search network architecture in the global space, this paper proposes another solution, namely a computationally efficient neural architecture evolutionary search framework based on network growth (G-EvoNAS). The complete network is obtained by gradually deepening different Blocks. The process begins from a shallow network, grows and evolves, and gradually deepens into a complete network, reducing the search complexity in the global space. Then, to improve the ranking accuracy of the network, we reduce the weight coupling of each network in the SuperNet by pruning the SuperNet according to elite groups at different growth stages. The G-EvoNAS is tested on three commonly used image classification datasets, CIFAR10, CIFAR100, and ImageNet, and compared with various state-of-the-art algorithms, including hand-designed networks and NAS networks. Experimental results demonstrate that G-EvoNAS can find a neural network architecture comparable to state-of-the-art designs in 0.2 GPU days.
SGD with Partial Hessian for Deep Neural Networks Optimization
Mar 05, 2024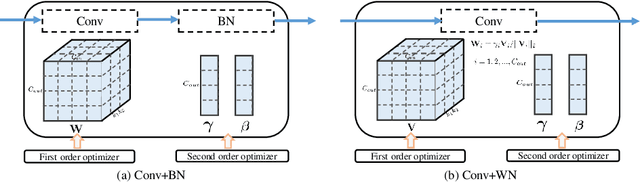
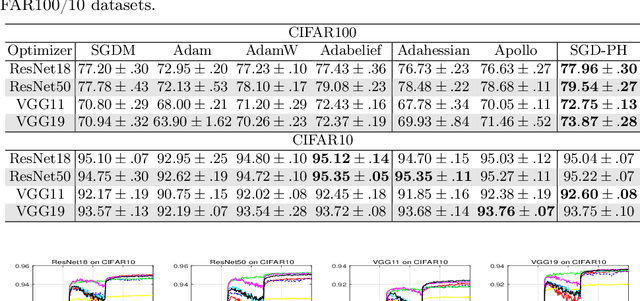
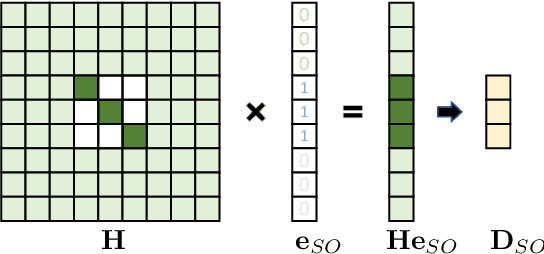

Due to the effectiveness of second-order algorithms in solving classical optimization problems, designing second-order optimizers to train deep neural networks (DNNs) has attracted much research interest in recent years. However, because of the very high dimension of intermediate features in DNNs, it is difficult to directly compute and store the Hessian matrix for network optimization. Most of the previous second-order methods approximate the Hessian information imprecisely, resulting in unstable performance. In this work, we propose a compound optimizer, which is a combination of a second-order optimizer with a precise partial Hessian matrix for updating channel-wise parameters and the first-order stochastic gradient descent (SGD) optimizer for updating the other parameters. We show that the associated Hessian matrices of channel-wise parameters are diagonal and can be extracted directly and precisely from Hessian-free methods. The proposed method, namely SGD with Partial Hessian (SGD-PH), inherits the advantages of both first-order and second-order optimizers. Compared with first-order optimizers, it adopts a certain amount of information from the Hessian matrix to assist optimization, while compared with the existing second-order optimizers, it keeps the good generalization performance of first-order optimizers. Experiments on image classification tasks demonstrate the effectiveness of our proposed optimizer SGD-PH. The code is publicly available at \url{https://github.com/myingysun/SGDPH}.