 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Res-Dense Net for 3D Covid Chest CT-scan classification
Aug 09, 2022
One of the most contentious areas of research in Medical Image Preprocessing is 3D CT-scan. With the rapid spread of COVID-19, the function of CT-scan in properly and swiftly diagnosing the disease has become critical. It has a positive impact on infection prevention. There are many tasks to diagnose the illness through CT-scan images, include COVID-19. In this paper, we propose a method that using a Stacking Deep Neural Network to detect the Covid 19 through the series of 3D CT-scans images . In our method, we experiment with two backbones are DenseNet 121 and ResNet 101. This method achieves a competitive performance on some evaluation metrics
SegPGD: An Effective and Efficient Adversarial Attack for Evaluating and Boosting Segmentation Robustness
Jul 25, 2022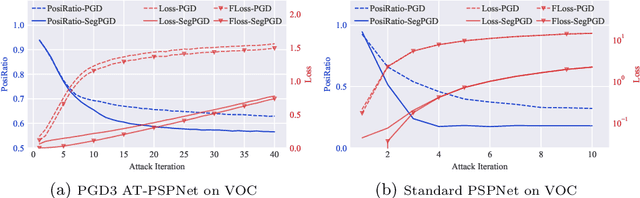
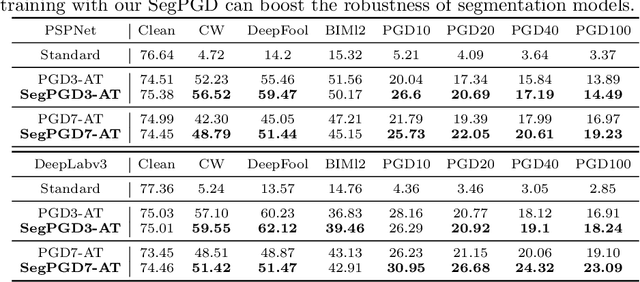
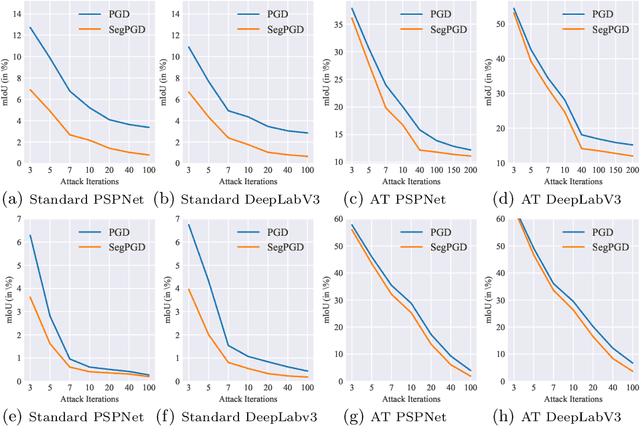
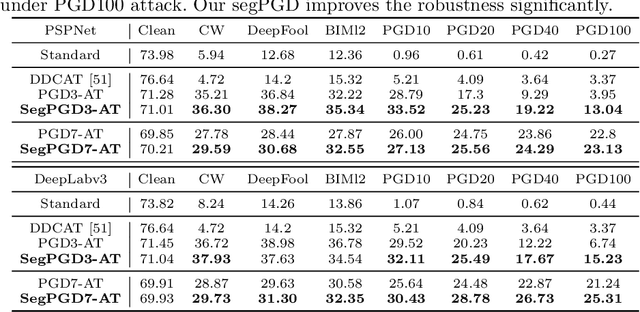
Deep neural network-based image classifications are vulnerable to adversarial perturbations. The image classifications can be easily fooled by adding artificial small and imperceptible perturbations to input images. As one of the most effective defense strategies, adversarial training was proposed to address the vulnerability of classification models, where the adversarial examples are created and injected into training data during training. The attack and defense of classification models have been intensively studied in past years. Semantic segmentation, as an extension of classifications, has also received great attention recently. Recent work shows a large number of attack iterations are required to create effective adversarial examples to fool segmentation models. The observation makes both robustness evaluation and adversarial training on segmentation models challenging. In this work, we propose an effective and efficient segmentation attack method, dubbed SegPGD. Besides, we provide a convergence analysis to show the proposed SegPGD can create more effective adversarial examples than PGD under the same number of attack iterations. Furthermore, we propose to apply our SegPGD as the underlying attack method for segmentation adversarial training. Since SegPGD can create more effective adversarial examples, the adversarial training with our SegPGD can boost the robustness of segmentation models. Our proposals are also verified with experiments on popular Segmentation model architectures and standard segmentation datasets.
Label Assistant: A Workflow for Assisted Data Annotation in Image Segmentation Tasks
Nov 27, 2021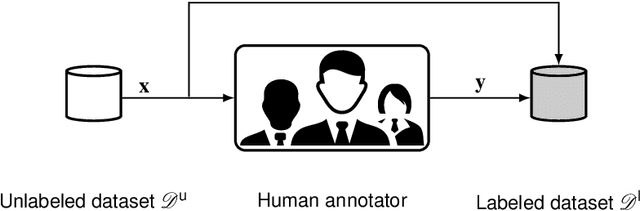
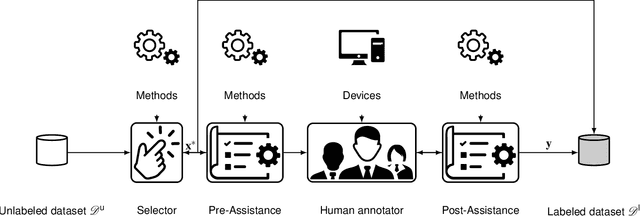
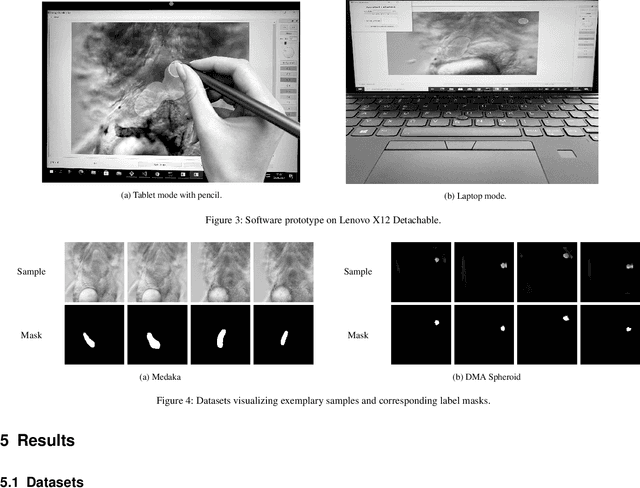
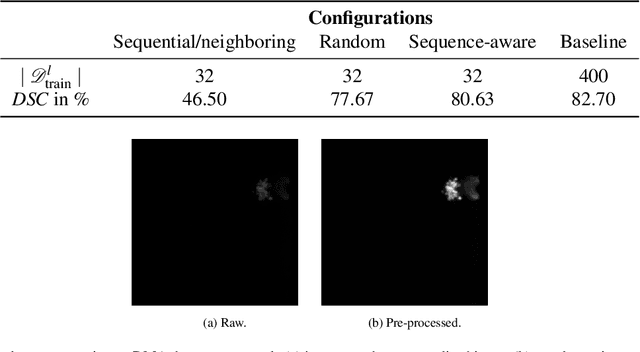
Recent research in the field of computer vision strongly focuses on deep learning architectures to tackle image processing problems. Deep neural networks are often considered in complex image processing scenarios since traditional computer vision approaches are expensive to develop or reach their limits due to complex relations. However, a common criticism is the need for large annotated datasets to determine robust parameters. Annotating images by human experts is time-consuming, burdensome, and expensive. Thus, support is needed to simplify annotation, increase user efficiency, and annotation quality. In this paper, we propose a generic workflow to assist the annotation process and discuss methods on an abstract level. Thereby, we review the possibilities of focusing on promising samples, image pre-processing, pre-labeling, label inspection, or post-processing of annotations. In addition, we present an implementation of the proposal by means of a developed flexible and extendable software prototype nested in hybrid touchscreen/laptop device.
Suggestive Annotation of Brain MR Images with Gradient-guided Sampling
Jun 02, 2022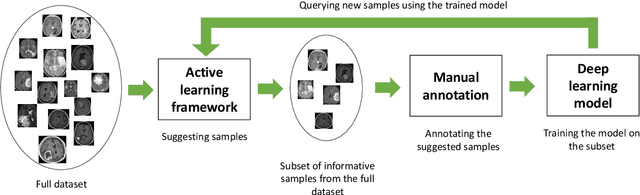
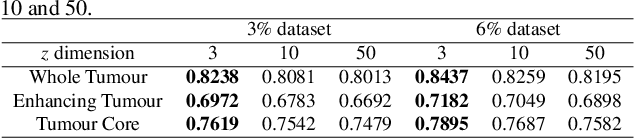
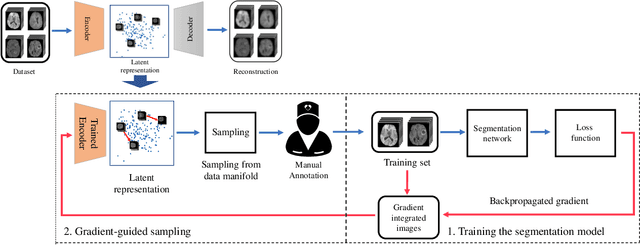

Machine learning has been widely adopted for medical image analysis in recent years given its promising performance in image segmentation and classification tasks. The success of machine learning, in particular supervised learning, depends on the availability of manually annotated datasets. For medical imaging applications, such annotated datasets are not easy to acquire, it takes a substantial amount of time and resource to curate an annotated medical image set. In this paper, we propose an efficient annotation framework for brain MR images that can suggest informative sample images for human experts to annotate. We evaluate the framework on two different brain image analysis tasks, namely brain tumour segmentation and whole brain segmentation. Experiments show that for brain tumour segmentation task on the BraTS 2019 dataset, training a segmentation model with only 7% suggestively annotated image samples can achieve a performance comparable to that of training on the full dataset. For whole brain segmentation on the MALC dataset, training with 42% suggestively annotated image samples can achieve a comparable performance to training on the full dataset. The proposed framework demonstrates a promising way to save manual annotation cost and improve data efficiency in medical imaging applications.
Practical No-box Adversarial Attacks with Training-free Hybrid Image Transformation
Mar 09, 2022


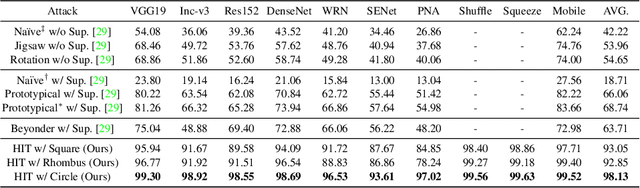
In recent years, the adversarial vulnerability of deep neural networks (DNNs) has raised increasing attention. Among all the threat models, no-box attacks are the most practical but extremely challenging since they neither rely on any knowledge of the target model or similar substitute model, nor access the dataset for training a new substitute model. Although a recent method has attempted such an attack in a loose sense, its performance is not good enough and computational overhead of training is expensive. In this paper, we move a step forward and show the existence of a \textbf{training-free} adversarial perturbation under the no-box threat model, which can be successfully used to attack different DNNs in real-time. Motivated by our observation that high-frequency component (HFC) domains in low-level features and plays a crucial role in classification, we attack an image mainly by manipulating its frequency components. Specifically, the perturbation is manipulated by suppression of the original HFC and adding of noisy HFC. We empirically and experimentally analyze the requirements of effective noisy HFC and show that it should be regionally homogeneous, repeating and dense. Extensive experiments on the ImageNet dataset demonstrate the effectiveness of our proposed no-box method. It attacks ten well-known models with a success rate of \textbf{98.13\%} on average, which outperforms state-of-the-art no-box attacks by \textbf{29.39\%}. Furthermore, our method is even competitive to mainstream transfer-based black-box attacks.
Pixel-Level Face Image Quality Assessment for Explainable Face Recognition
Oct 21, 2021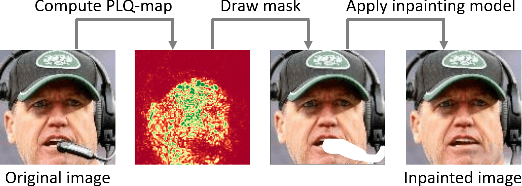
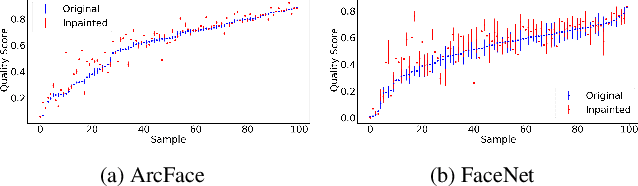
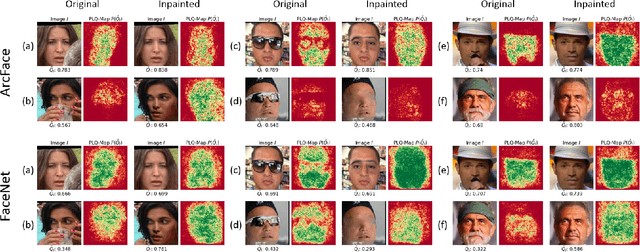
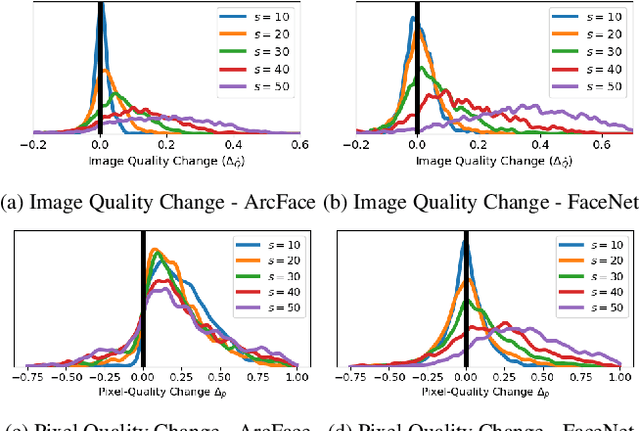
An essential factor to achieve high performance in face recognition systems is the quality of its samples. Since these systems are involved in various daily life there is a strong need of making face recognition processes understandable for humans. In this work, we introduce the concept of pixel-level face image quality that determines the utility of pixels in a face image for recognition. Given an arbitrary face recognition network, in this work, we propose a training-free approach to assess the pixel-level qualities of a face image. To achieve this, a model-specific quality value of the input image is estimated and used to build a sample-specific quality regression model. Based on this model, quality-based gradients are back-propagated and converted into pixel-level quality estimates. In the experiments, we qualitatively and quantitatively investigated the meaningfulness of the pixel-level qualities based on real and artificial disturbances and by comparing the explanation maps on ICAO-incompliant faces. In all scenarios, the results demonstrate that the proposed solution produces meaningful pixel-level qualities. The code is publicly available.
Locally Adaptive Structure and Texture Similarity for Image Quality Assessment
Oct 16, 2021
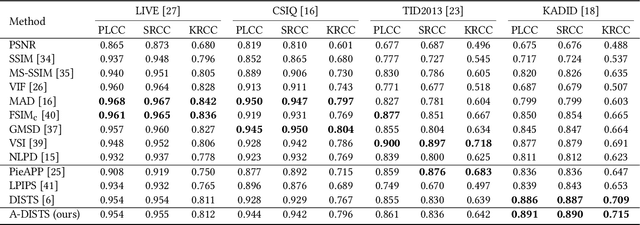

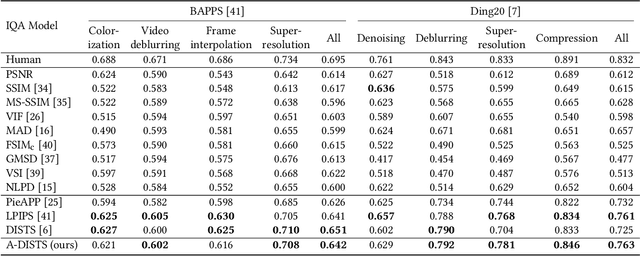
The latest advances in full-reference image quality assessment (IQA) involve unifying structure and texture similarity based on deep representations. The resulting Deep Image Structure and Texture Similarity (DISTS) metric, however, makes rather global quality measurements, ignoring the fact that natural photographic images are locally structured and textured across space and scale. In this paper, we describe a locally adaptive structure and texture similarity index for full-reference IQA, which we term A-DISTS. Specifically, we rely on a single statistical feature, namely the dispersion index, to localize texture regions at different scales. The estimated probability (of one patch being texture) is in turn used to adaptively pool local structure and texture measurements. The resulting A-DISTS is adapted to local image content, and is free of expensive human perceptual scores for supervised training. We demonstrate the advantages of A-DISTS in terms of correlation with human data on ten IQA databases and optimization of single image super-resolution methods.
Shape-Aware Masking for Inpainting in Medical Imaging
Jul 12, 2022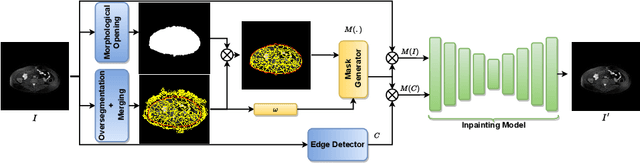

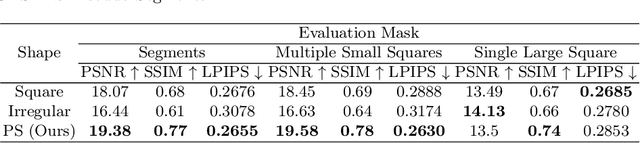
Inpainting has recently been proposed as a successful deep learning technique for unsupervised medical image model discovery. The masks used for inpainting are generally independent of the dataset and are not tailored to perform on different given classes of anatomy. In this work, we introduce a method for generating shape-aware masks for inpainting, which aims at learning the statistical shape prior. We hypothesize that although the variation of masks improves the generalizability of inpainting models, the shape of the masks should follow the topology of the organs of interest. Hence, we propose an unsupervised guided masking approach based on an off-the-shelf inpainting model and a superpixel over-segmentation algorithm to generate a wide range of shape-dependent masks. Experimental results on abdominal MR image reconstruction show the superiority of our proposed masking method over standard methods using square-shaped or dataset of irregular shape masks.
RewriteNet: Realistic Scene Text Image Generation via Editing Text in Real-world Image
Jul 23, 2021
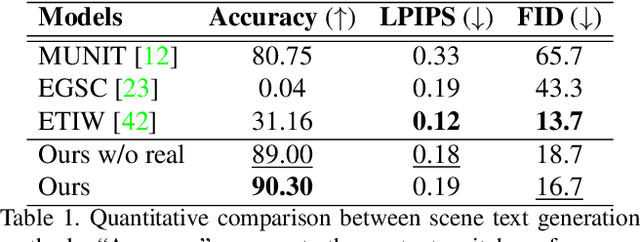
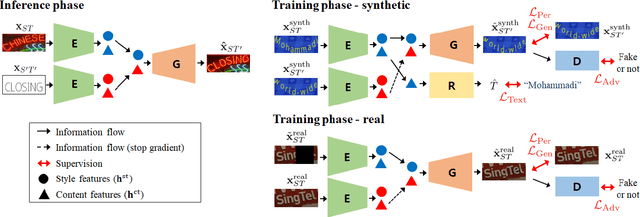
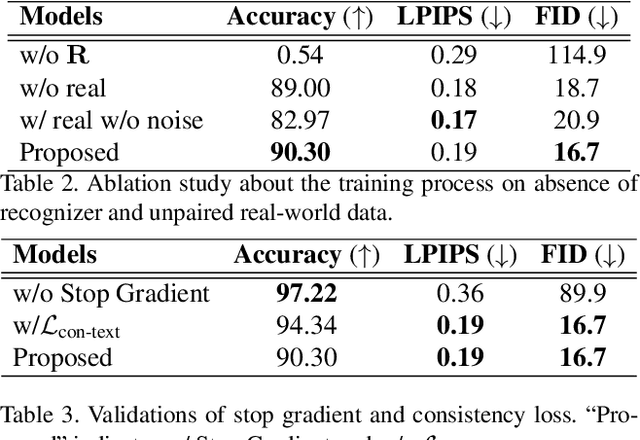
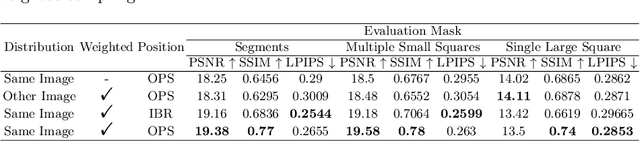
Scene text editing (STE), which converts a text in a scene image into the desired text while preserving an original style, is a challenging task due to a complex intervention between text and style. To address this challenge, we propose a novel representational learning-based STE model, referred to as RewriteNet that employs textual information as well as visual information. We assume that the scene text image can be decomposed into content and style features where the former represents the text information and style represents scene text characteristics such as font, alignment, and background. Under this assumption, we propose a method to separately encode content and style features of the input image by introducing the scene text recognizer that is trained by text information. Then, a text-edited image is generated by combining the style feature from the original image and the content feature from the target text. Unlike previous works that are only able to use synthetic images in the training phase, we also exploit real-world images by proposing a self-supervised training scheme, which bridges the domain gap between synthetic and real data. Our experiments demonstrate that RewriteNet achieves better quantitative and qualitative performance than other comparisons. Moreover, we validate that the use of text information and the self-supervised training scheme improves text switching performance. The implementation and dataset will be publicly available.
Video + CLIP Baseline for Ego4D Long-term Action Anticipation
Jul 01, 2022
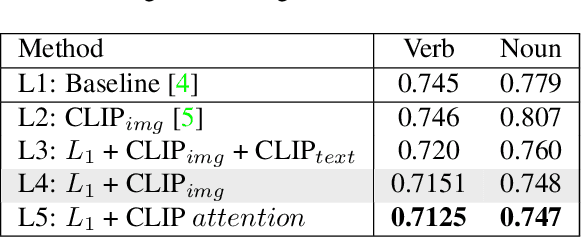
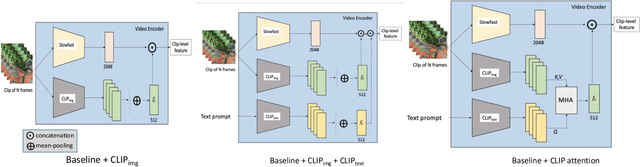
In this report, we introduce our adaptation of image-text models for long-term action anticipation. Our Video + CLIP framework makes use of a large-scale pre-trained paired image-text model: CLIP and a video encoder Slowfast network. The CLIP embedding provides fine-grained understanding of objects relevant for an action whereas the slowfast network is responsible for modeling temporal information within a video clip of few frames. We show that the features obtained from both encoders are complementary to each other, thus outperforming the baseline on Ego4D for the task of long-term action anticipation. Our code is available at github.com/srijandas07/clip_baseline_LTA_Ego4d.