 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
CarbonNet: How Computer Vision Plays a Role in Climate Change? Application: Learning Geomechanics from Subsurface Geometry of CCS to Mitigate Global Warming
Mar 12, 2024
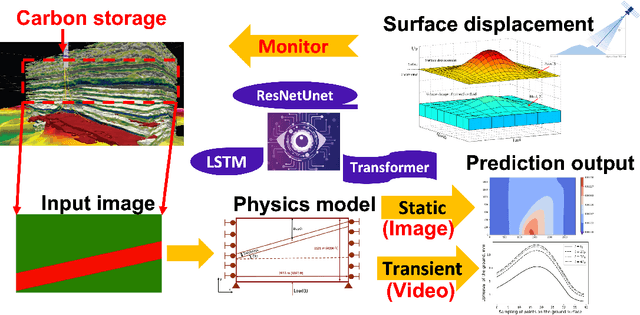

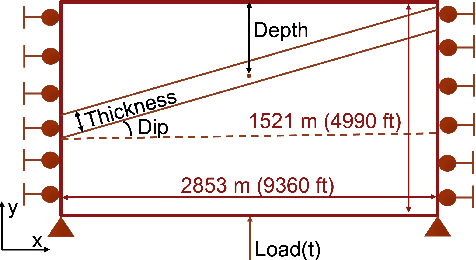
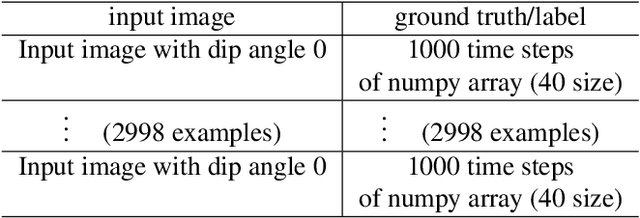
We introduce a new approach using computer vision to predict the land surface displacement from subsurface geometry images for Carbon Capture and Sequestration (CCS). CCS has been proved to be a key component for a carbon neutral society. However, scientists see there are challenges along the way including the high computational cost due to the large model scale and limitations to generalize a pre-trained model with complex physics. We tackle those challenges by training models directly from the subsurface geometry images. The goal is to understand the respons of land surface displacement due to carbon injection and utilize our trained models to inform decision making in CCS projects. We implement multiple models (CNN, ResNet, and ResNetUNet) for static mechanics problem, which is a image prediction problem. Next, we use the LSTM and transformer for transient mechanics scenario, which is a video prediction problem. It shows ResNetUNet outperforms the others thanks to its architecture in static mechanics problem, and LSTM shows comparable performance to transformer in transient problem. This report proceeds by outlining our dataset in detail followed by model descriptions in method section. Result and discussion state the key learning, observations, and conclusion with future work rounds out the paper.
Whiteness-based bilevel learning of regularization parameters in imaging
Mar 10, 2024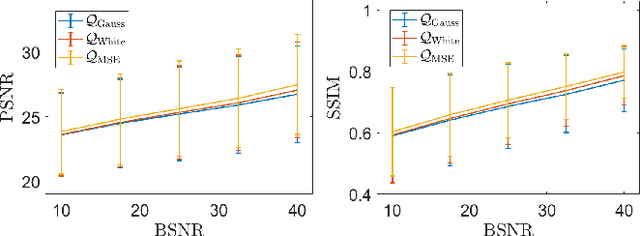
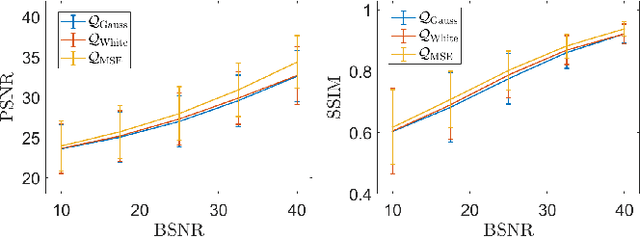
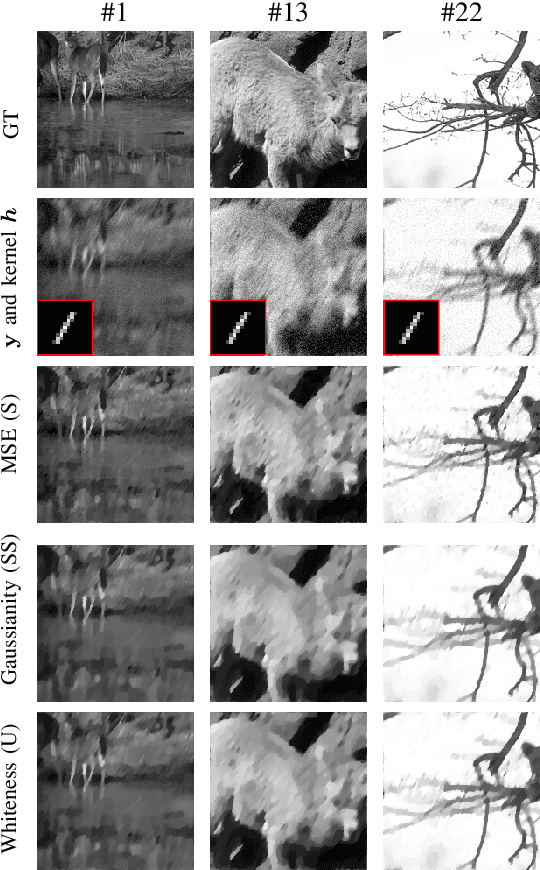

We consider an unsupervised bilevel optimization strategy for learning regularization parameters in the context of imaging inverse problems in the presence of additive white Gaussian noise. Compared to supervised and semi-supervised metrics relying either on the prior knowledge of reference data and/or on some (partial) knowledge on the noise statistics, the proposed approach optimizes the whiteness of the residual between the observed data and the observation model with no need of ground-truth data.We validate the approach on standard Total Variation-regularized image deconvolution problems which show that the proposed quality metric provides estimates close to the mean-square error oracle and to discrepancy-based principles.
A data-centric approach to class-specific bias in image data augmentation
Mar 07, 2024
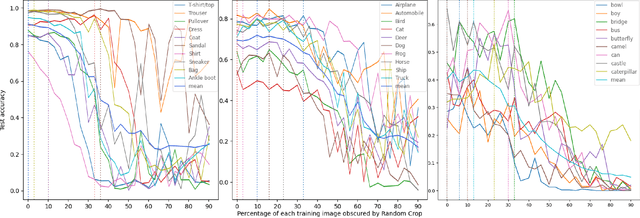
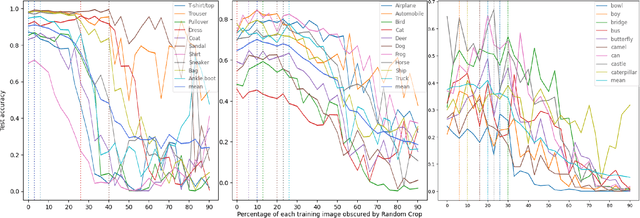
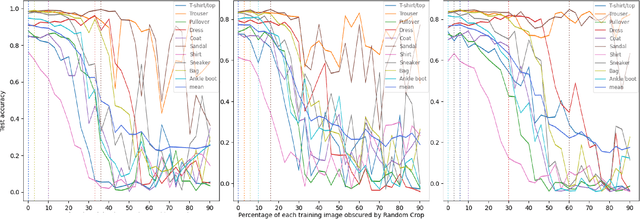
Data augmentation (DA) enhances model generalization in computer vision but may introduce biases, impacting class accuracy unevenly. Our study extends this inquiry, examining DA's class-specific bias across various datasets, including those distinct from ImageNet, through random cropping. We evaluated this phenomenon with ResNet50, EfficientNetV2S, and SWIN ViT, discovering that while residual models showed similar bias effects, Vision Transformers exhibited greater robustness or altered dynamics. This suggests a nuanced approach to model selection, emphasizing bias mitigation. We also refined a "data augmentation robustness scouting" method to manage DA-induced biases more efficiently, reducing computational demands significantly (training 112 models instead of 1860; a reduction of factor 16.2) while still capturing essential bias trends.
Revisiting registration-based synthesis: A focus on unsupervised MR image synthesis
Feb 19, 2024Deep learning (DL) has led to significant improvements in medical image synthesis, enabling advanced image-to-image translation to generate synthetic images. However, DL methods face challenges such as domain shift and high demands for training data, limiting their generalizability and applicability. Historically, image synthesis was also carried out using deformable image registration (DIR), a method that warps moving images of a desired modality to match the anatomy of a fixed image. However, concerns about its speed and accuracy led to its decline in popularity. With the recent advances of DL-based DIR, we now revisit and reinvigorate this line of research. In this paper, we propose a fast and accurate synthesis method based on DIR. We use the task of synthesizing a rare magnetic resonance (MR) sequence, white matter nulled (WMn) T1-weighted (T1-w) images, to demonstrate the potential of our approach. During training, our method learns a DIR model based on the widely available MPRAGE sequence, which is a cerebrospinal fluid nulled (CSFn) T1-w inversion recovery gradient echo pulse sequence. During testing, the trained DIR model is first applied to estimate the deformation between moving and fixed CSFn images. Subsequently, this estimated deformation is applied to align the paired WMn counterpart of the moving CSFn image, yielding a synthetic WMn image for the fixed CSFn image. Our experiments demonstrate promising results for unsupervised image synthesis using DIR. These findings highlight the potential of our technique in contexts where supervised synthesis methods are constrained by limited training data.
The R2D2 deep neural network series paradigm for fast precision imaging in radio astronomy
Mar 08, 2024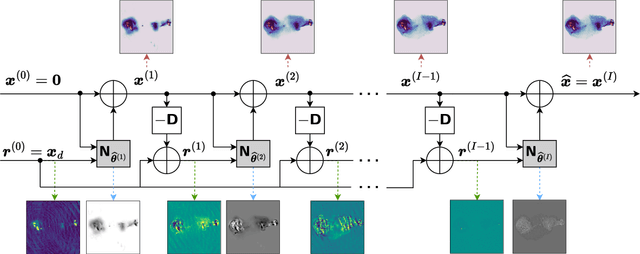
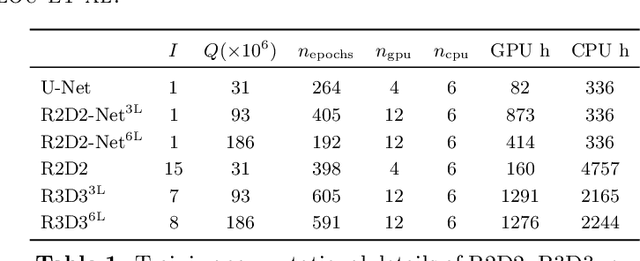
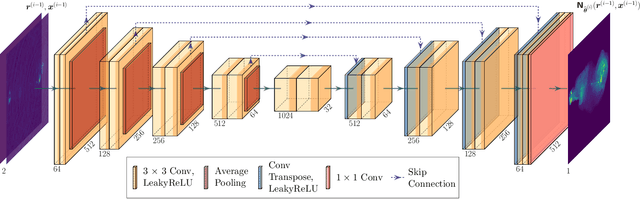

Radio-interferometric (RI) imaging entails solving high-resolution high-dynamic range inverse problems from large data volumes. Recent image reconstruction techniques grounded in optimization theory have demonstrated remarkable capability for imaging precision, well beyond CLEAN's capability. These range from advanced proximal algorithms propelled by handcrafted regularization operators, such as the SARA family, to hybrid plug-and-play (PnP) algorithms propelled by learned regularization denoisers, such as AIRI. Optimization and PnP structures are however highly iterative, which hinders their ability to handle the extreme data sizes expected from future instruments. To address this scalability challenge, we introduce a novel deep learning approach, dubbed ``Residual-to-Residual DNN series for high-Dynamic range imaging'. R2D2's reconstruction is formed as a series of residual images, iteratively estimated as outputs of Deep Neural Networks (DNNs) taking the previous iteration's image estimate and associated data residual as inputs. It thus takes a hybrid structure between a PnP algorithm and a learned version of the matching pursuit algorithm that underpins CLEAN. We present a comprehensive study of our approach, featuring its multiple incarnations distinguished by their DNN architectures. We provide a detailed description of its training process, targeting a telescope-specific approach. R2D2's capability to deliver high precision is demonstrated in simulation, across a variety of image and observation settings using the Very Large Array (VLA). Its reconstruction speed is also demonstrated: with only few iterations required to clean data residuals at dynamic ranges up to 105, R2D2 opens the door to fast precision imaging. R2D2 codes are available in the BASPLib library on GitHub.
Real-time 3D-aware Portrait Editing from a Single Image
Feb 21, 2024This work presents 3DPE, a practical tool that can efficiently edit a face image following given prompts, like reference images or text descriptions, in the 3D-aware manner. To this end, a lightweight module is distilled from a 3D portrait generator and a text-to-image model, which provide prior knowledge of face geometry and open-vocabulary editing capability, respectively. Such a design brings two compelling advantages over existing approaches. First, our system achieves real-time editing with a feedforward network (i.e., ~0.04s per image), over 100x faster than the second competitor. Second, thanks to the powerful priors, our module could focus on the learning of editing-related variations, such that it manages to handle various types of editing simultaneously in the training phase and further supports fast adaptation to user-specified novel types of editing during inference (e.g., with ~5min fine-tuning per case). The code, the model, and the interface will be made publicly available to facilitate future research.
LeOCLR: Leveraging Original Images for Contrastive Learning of Visual Representations
Mar 11, 2024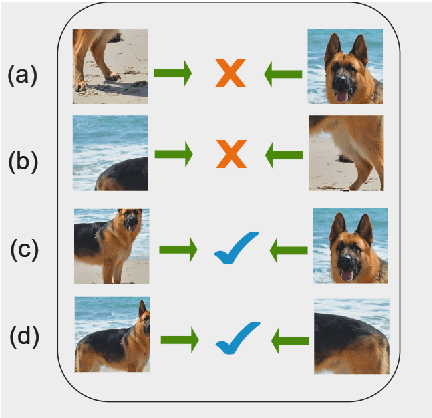
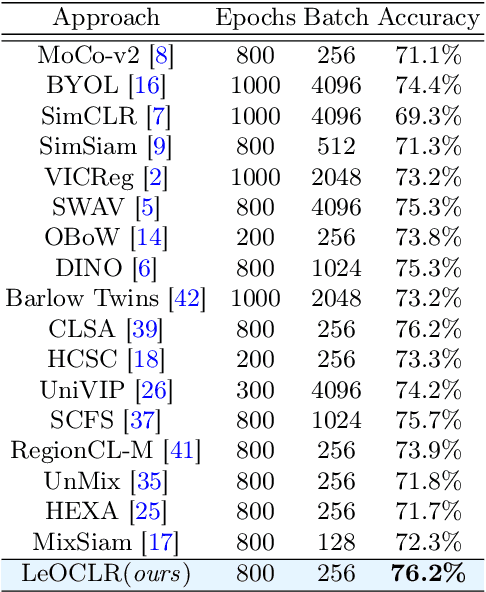
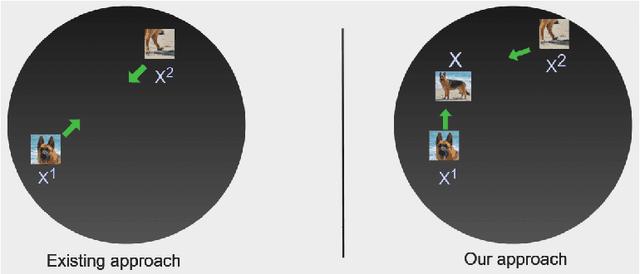
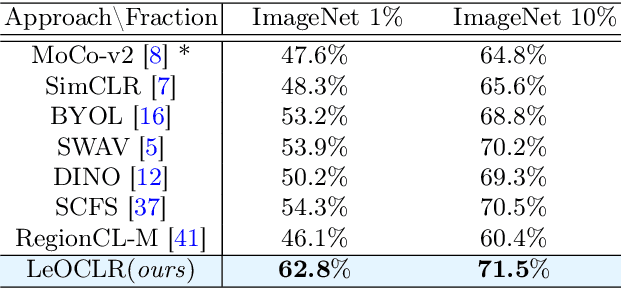
Contrastive instance discrimination outperforms supervised learning in downstream tasks like image classification and object detection. However, this approach heavily relies on data augmentation during representation learning, which may result in inferior results if not properly implemented. Random cropping followed by resizing is a common form of data augmentation used in contrastive learning, but it can lead to degraded representation learning if the two random crops contain distinct semantic content. To address this issue, this paper introduces LeOCLR (Leveraging Original Images for Contrastive Learning of Visual Representations), a framework that employs a new instance discrimination approach and an adapted loss function that ensures the shared region between positive pairs is semantically correct. The experimental results show that our approach consistently improves representation learning across different datasets compared to baseline models. For example, our approach outperforms MoCo-v2 by 5.1% on ImageNet-1K in linear evaluation and several other methods on transfer learning tasks.
Genetic Learning for Designing Sim-to-Real Data Augmentations
Mar 11, 2024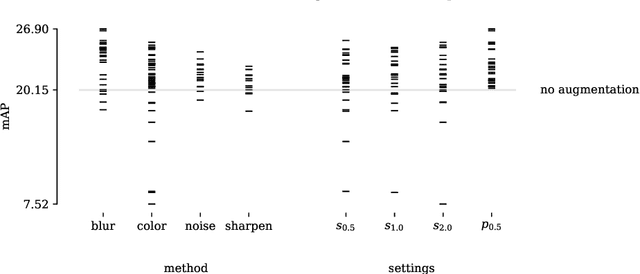
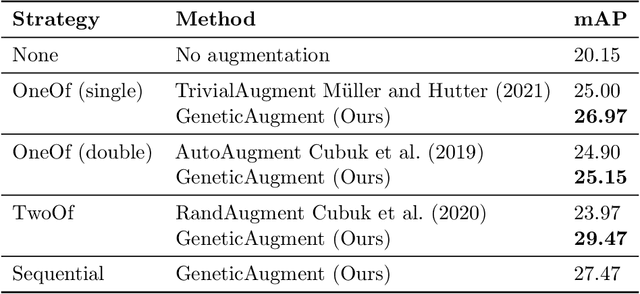
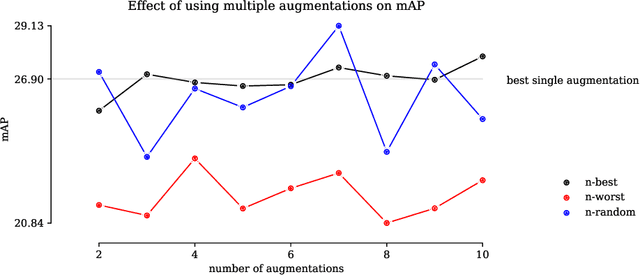

Data augmentations are useful in closing the sim-to-real domain gap when training on synthetic data. This is because they widen the training data distribution, thus encouraging the model to generalize better to other domains. Many image augmentation techniques exist, parametrized by different settings, such as strength and probability. This leads to a large space of different possible augmentation policies. Some policies work better than others for overcoming the sim-to-real gap for specific datasets, and it is unclear why. This paper presents two different interpretable metrics that can be combined to predict how well a certain augmentation policy will work for a specific sim-to-real setting, focusing on object detection. We validate our metrics by training many models with different augmentation policies and showing a strong correlation with performance on real data. Additionally, we introduce GeneticAugment, a genetic programming method that can leverage these metrics to automatically design an augmentation policy for a specific dataset without needing to train a model.
Transferring Relative Monocular Depth to Surgical Vision with Temporal Consistency
Mar 11, 2024
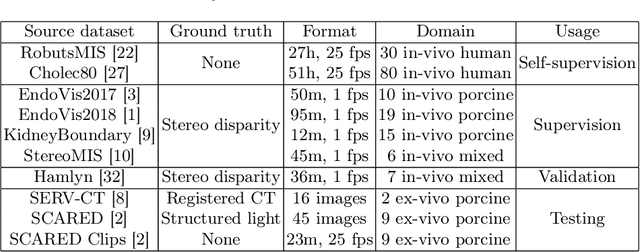
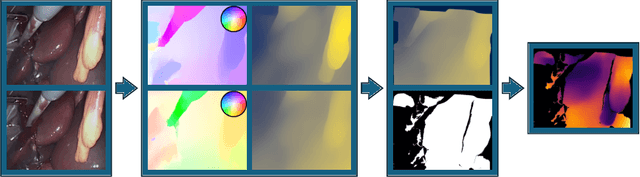
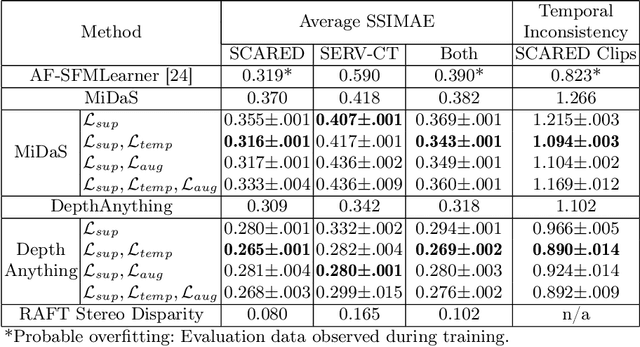
Relative monocular depth, inferring depth up to shift and scale from a single image, is an active research topic. Recent deep learning models, trained on large and varied meta-datasets, now provide excellent performance in the domain of natural images. However, few datasets exist which provide ground truth depth for endoscopic images, making training such models from scratch unfeasible. This work investigates the transfer of these models into the surgical domain, and presents an effective and simple way to improve on standard supervision through the use of temporal consistency self-supervision. We show temporal consistency significantly improves supervised training alone when transferring to the low-data regime of endoscopy, and outperforms the prevalent self-supervision technique for this task. In addition we show our method drastically outperforms the state-of-the-art method from within the domain of endoscopy. We also release our code, model and ensembled meta-dataset, Meta-MED, establishing a strong benchmark for future work.
Bayesian Diffusion Models for 3D Shape Reconstruction
Mar 11, 2024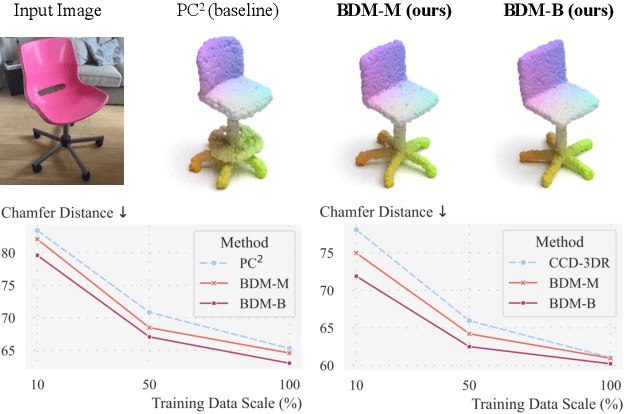
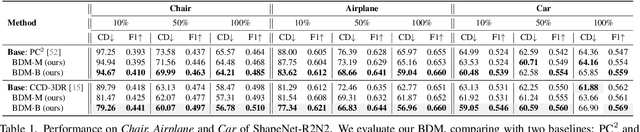
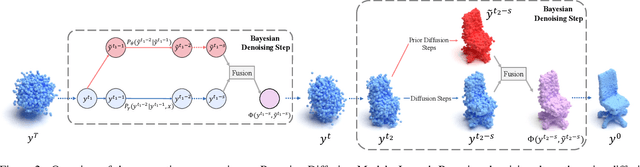
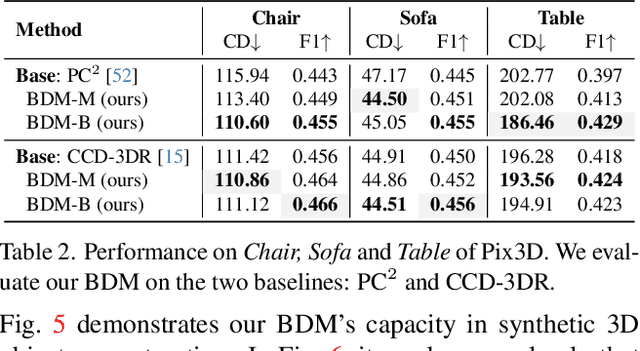
We present Bayesian Diffusion Models (BDM), a prediction algorithm that performs effective Bayesian inference by tightly coupling the top-down (prior) information with the bottom-up (data-driven) procedure via joint diffusion processes. We show the effectiveness of BDM on the 3D shape reconstruction task. Compared to prototypical deep learning data-driven approaches trained on paired (supervised) data-labels (e.g. image-point clouds) datasets, our BDM brings in rich prior information from standalone labels (e.g. point clouds) to improve the bottom-up 3D reconstruction. As opposed to the standard Bayesian frameworks where explicit prior and likelihood are required for the inference, BDM performs seamless information fusion via coupled diffusion processes with learned gradient computation networks. The specialty of our BDM lies in its capability to engage the active and effective information exchange and fusion of the top-down and bottom-up processes where each itself is a diffusion process. We demonstrate state-of-the-art results on both synthetic and real-world benchmarks for 3D shape reconstruction.