 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
DCT-Net: Domain-Calibrated Translation for Portrait Stylization
Jul 06, 2022

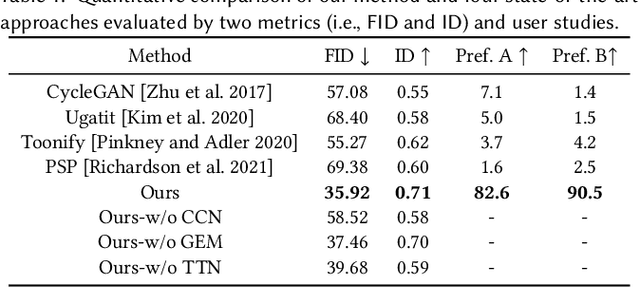
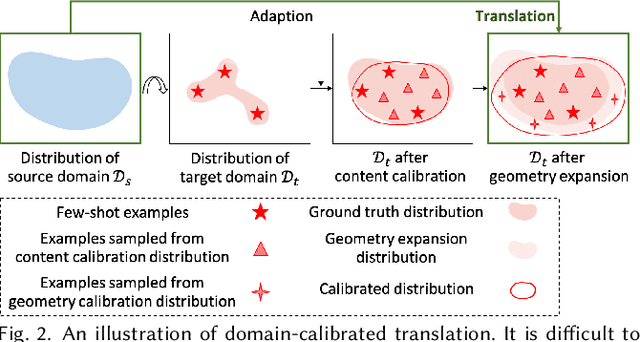
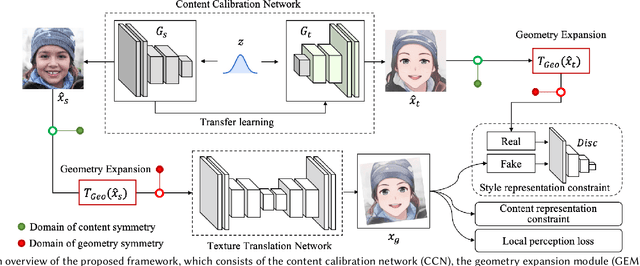
This paper introduces DCT-Net, a novel image translation architecture for few-shot portrait stylization. Given limited style exemplars ($\sim$100), the new architecture can produce high-quality style transfer results with advanced ability to synthesize high-fidelity contents and strong generality to handle complicated scenes (e.g., occlusions and accessories). Moreover, it enables full-body image translation via one elegant evaluation network trained by partial observations (i.e., stylized heads). Few-shot learning based style transfer is challenging since the learned model can easily become overfitted in the target domain, due to the biased distribution formed by only a few training examples. This paper aims to handle the challenge by adopting the key idea of "calibration first, translation later" and exploring the augmented global structure with locally-focused translation. Specifically, the proposed DCT-Net consists of three modules: a content adapter borrowing the powerful prior from source photos to calibrate the content distribution of target samples; a geometry expansion module using affine transformations to release spatially semantic constraints; and a texture translation module leveraging samples produced by the calibrated distribution to learn a fine-grained conversion. Experimental results demonstrate the proposed method's superiority over the state of the art in head stylization and its effectiveness on full image translation with adaptive deformations.
Image Magnification Network for Vessel Segmentation in OCTA Images
Oct 26, 2021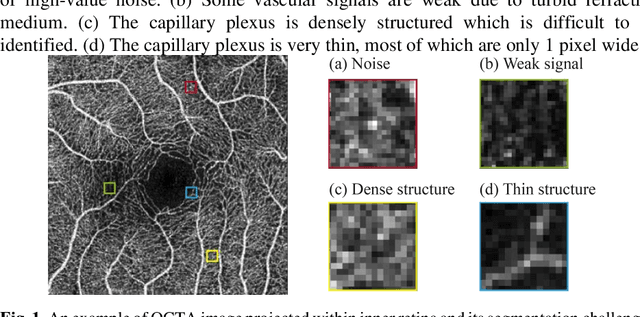
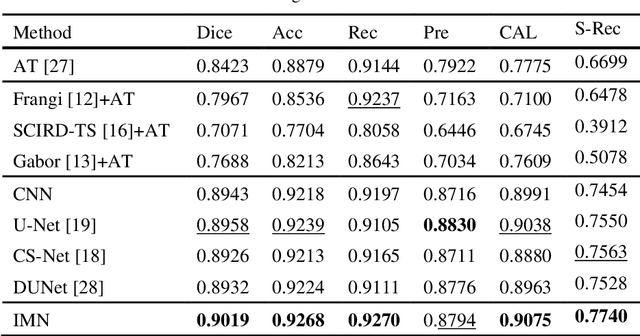
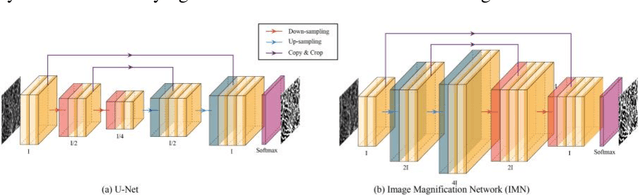
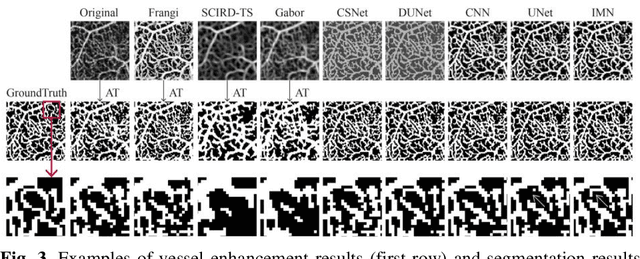
Optical coherence tomography angiography (OCTA) is a novel non-invasive imaging modality that allows micron-level resolution to visualize the retinal microvasculature. The retinal vessel segmentation in OCTA images is still an open problem, and especially the thin and dense structure of the capillary plexus is an important challenge of this problem. In this work, we propose a novel image magnification network (IMN) for vessel segmentation in OCTA images. Contrary to the U-Net structure with a down-sampling encoder and up-sampling decoder, the proposed IMN adopts the design of up-sampling encoding and then down-sampling decoding. This design is to capture more image details and reduce the omission of thin-and-small structures. The experimental results on three open OCTA datasets show that the proposed IMN with an average dice score of 90.2% achieves the best performance in vessel segmentation of OCTA images. Besides, we also demonstrate the superior performance of IMN in cross-field image vessel segmentation and vessel skeleton extraction.
Monocular 3D Object Detection with Depth from Motion
Jul 26, 2022
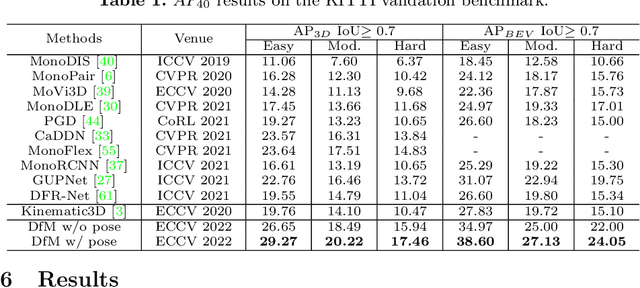
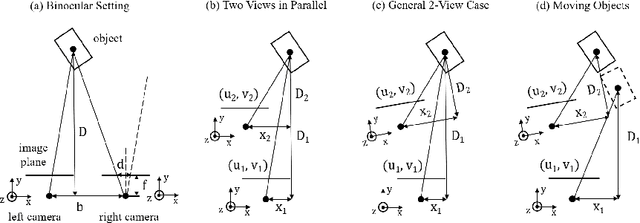

Perceiving 3D objects from monocular inputs is crucial for robotic systems, given its economy compared to multi-sensor settings. It is notably difficult as a single image can not provide any clues for predicting absolute depth values. Motivated by binocular methods for 3D object detection, we take advantage of the strong geometry structure provided by camera ego-motion for accurate object depth estimation and detection. We first make a theoretical analysis on this general two-view case and notice two challenges: 1) Cumulative errors from multiple estimations that make the direct prediction intractable; 2) Inherent dilemmas caused by static cameras and matching ambiguity. Accordingly, we establish the stereo correspondence with a geometry-aware cost volume as the alternative for depth estimation and further compensate it with monocular understanding to address the second problem. Our framework, named Depth from Motion (DfM), then uses the established geometry to lift 2D image features to the 3D space and detects 3D objects thereon. We also present a pose-free DfM to make it usable when the camera pose is unavailable. Our framework outperforms state-of-the-art methods by a large margin on the KITTI benchmark. Detailed quantitative and qualitative analyses also validate our theoretical conclusions. The code will be released at https://github.com/Tai-Wang/Depth-from-Motion.
PAANet: Progressive Alternating Attention for Automatic Medical Image Segmentation
Nov 20, 2021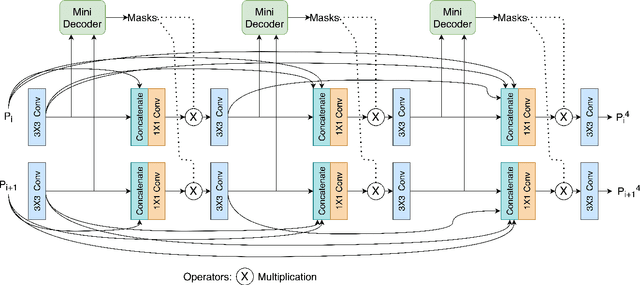
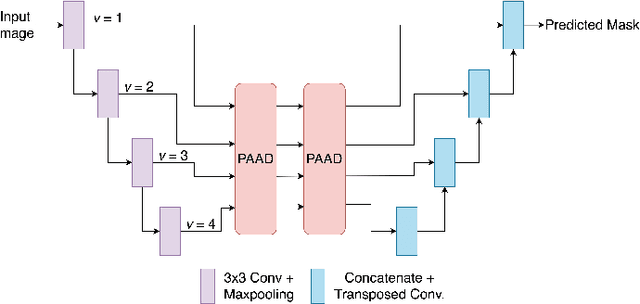
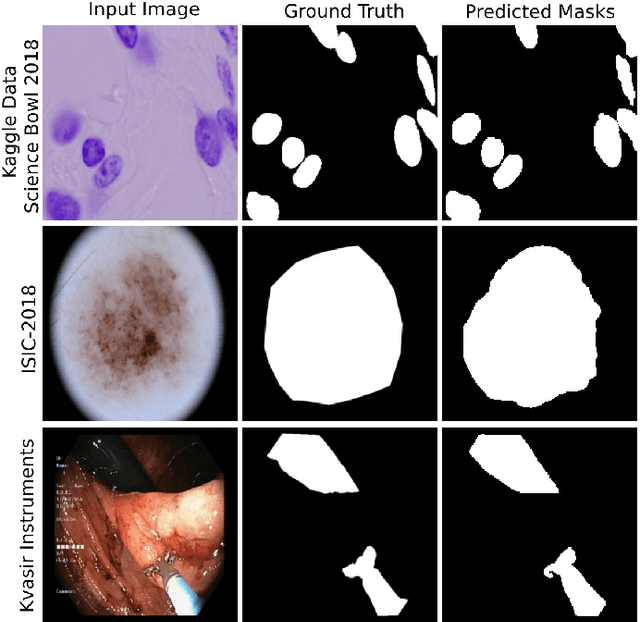
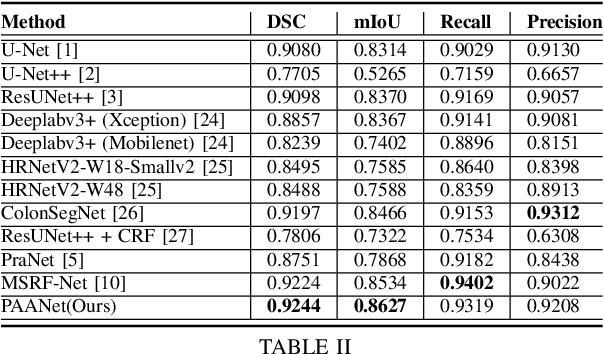
Medical image segmentation can provide detailed information for clinical analysis which can be useful for scenarios where the detailed location of a finding is important. Knowing the location of disease can play a vital role in treatment and decision-making. Convolutional neural network (CNN) based encoder-decoder techniques have advanced the performance of automated medical image segmentation systems. Several such CNN-based methodologies utilize techniques such as spatial- and channel-wise attention to enhance performance. Another technique that has drawn attention in recent years is residual dense blocks (RDBs). The successive convolutional layers in densely connected blocks are capable of extracting diverse features with varied receptive fields and thus, enhancing performance. However, consecutive stacked convolutional operators may not necessarily generate features that facilitate the identification of the target structures. In this paper, we propose a progressive alternating attention network (PAANet). We develop progressive alternating attention dense (PAAD) blocks, which construct a guiding attention map (GAM) after every convolutional layer in the dense blocks using features from all scales. The GAM allows the following layers in the dense blocks to focus on the spatial locations relevant to the target region. Every alternate PAAD block inverts the GAM to generate a reverse attention map which guides ensuing layers to extract boundary and edge-related information, refining the segmentation process. Our experiments on three different biomedical image segmentation datasets exhibit that our PAANet achieves favourable performance when compared to other state-of-the-art methods.
Rethinking Cost-sensitive Classification in Deep Learning via Adversarial Data Augmentation
Aug 24, 2022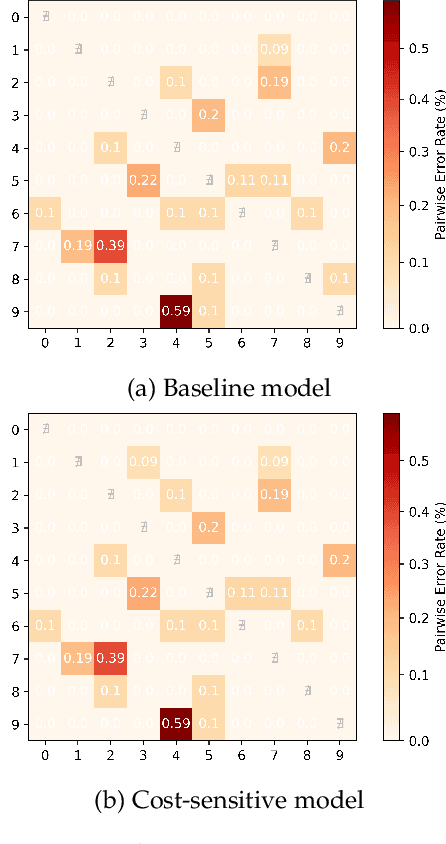

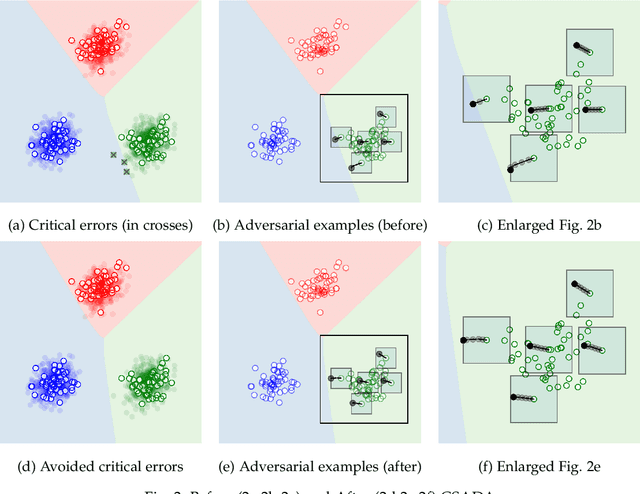
Cost-sensitive classification is critical in applications where misclassification errors widely vary in cost. However, over-parameterization poses fundamental challenges to the cost-sensitive modeling of deep neural networks (DNNs). The ability of a DNN to fully interpolate a training dataset can render a DNN, evaluated purely on the training set, ineffective in distinguishing a cost-sensitive solution from its overall accuracy maximization counterpart. This necessitates rethinking cost-sensitive classification in DNNs. To address this challenge, this paper proposes a cost-sensitive adversarial data augmentation (CSADA) framework to make over-parameterized models cost-sensitive. The overarching idea is to generate targeted adversarial examples that push the decision boundary in cost-aware directions. These targeted adversarial samples are generated by maximizing the probability of critical misclassifications and used to train a model with more conservative decisions on costly pairs. Experiments on well-known datasets and a pharmacy medication image (PMI) dataset made publicly available show that our method can effectively minimize the overall cost and reduce critical errors, while achieving comparable performance in terms of overall accuracy.
Dual Contrastive Learning for Unsupervised Image-to-Image Translation
Apr 15, 2021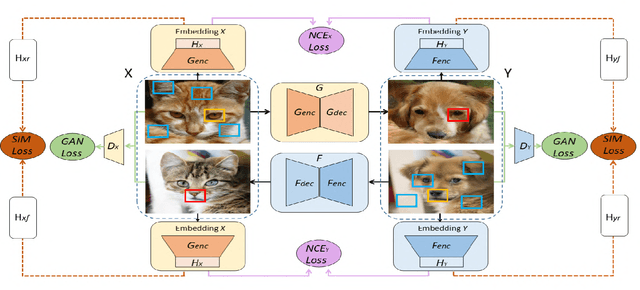
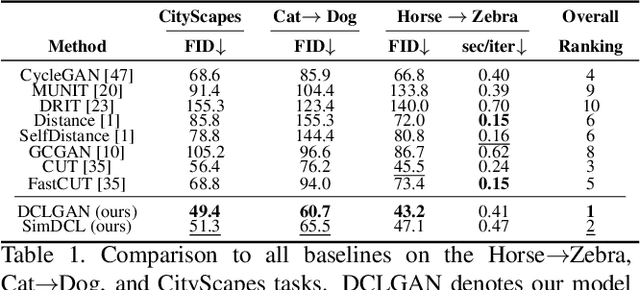


Unsupervised image-to-image translation tasks aim to find a mapping between a source domain X and a target domain Y from unpaired training data. Contrastive learning for Unpaired image-to-image Translation (CUT) yields state-of-the-art results in modeling unsupervised image-to-image translation by maximizing mutual information between input and output patches using only one encoder for both domains. In this paper, we propose a novel method based on contrastive learning and a dual learning setting (exploiting two encoders) to infer an efficient mapping between unpaired data. Additionally, while CUT suffers from mode collapse, a variant of our method efficiently addresses this issue. We further demonstrate the advantage of our approach through extensive ablation studies demonstrating superior performance comparing to recent approaches in multiple challenging image translation tasks. Lastly, we demonstrate that the gap between unsupervised methods and supervised methods can be efficiently closed.
StyleLight: HDR Panorama Generation for Lighting Estimation and Editing
Jul 29, 2022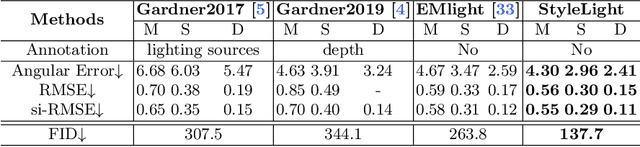
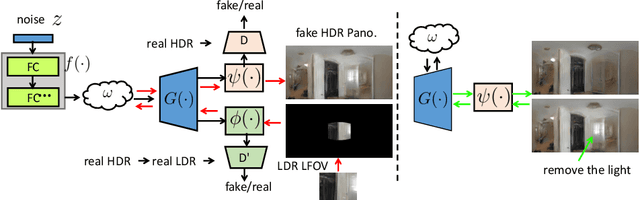


We present a new lighting estimation and editing framework to generate high-dynamic-range (HDR) indoor panorama lighting from a single limited field-of-view (LFOV) image captured by low-dynamic-range (LDR) cameras. Existing lighting estimation methods either directly regress lighting representation parameters or decompose this problem into LFOV-to-panorama and LDR-to-HDR lighting generation sub-tasks. However, due to the partial observation, the high-dynamic-range lighting, and the intrinsic ambiguity of a scene, lighting estimation remains a challenging task. To tackle this problem, we propose a coupled dual-StyleGAN panorama synthesis network (StyleLight) that integrates LDR and HDR panorama synthesis into a unified framework. The LDR and HDR panorama synthesis share a similar generator but have separate discriminators. During inference, given an LDR LFOV image, we propose a focal-masked GAN inversion method to find its latent code by the LDR panorama synthesis branch and then synthesize the HDR panorama by the HDR panorama synthesis branch. StyleLight takes LFOV-to-panorama and LDR-to-HDR lighting generation into a unified framework and thus greatly improves lighting estimation. Extensive experiments demonstrate that our framework achieves superior performance over state-of-the-art methods on indoor lighting estimation. Notably, StyleLight also enables intuitive lighting editing on indoor HDR panoramas, which is suitable for real-world applications. Code is available at https://style-light.github.io.
Identifying the exterior image of buildings on a 3D map and extracting elevation information using deep learning and digital image processing
Jan 04, 2022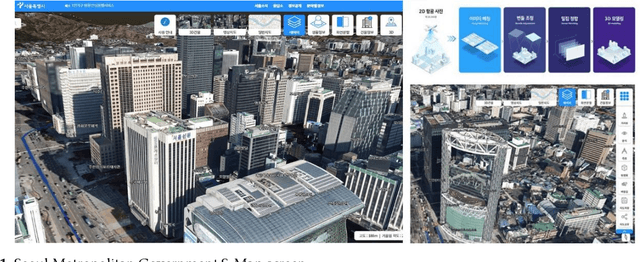

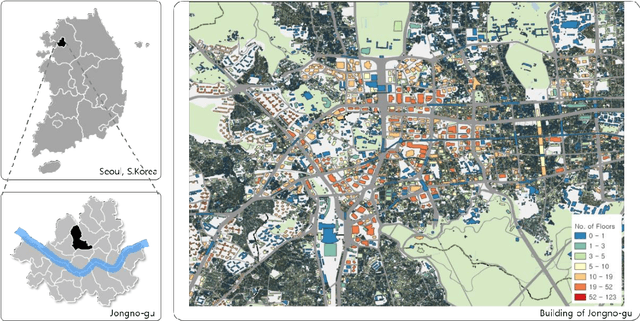

Despite the fact that architectural administration information in Korea has been providing high-quality information for a long period of time, the level of utility of the information is not high because it focuses on administrative information. While this is the case, a three-dimensional (3D) map with higher resolution has emerged along with the technological development. However, it cannot function better than visual transmission, as it includes only image information focusing on the exterior of the building. If information related to the exterior of the building can be extracted or identified from a 3D map, it is expected that the utility of the information will be more valuable as the national architectural administration information can then potentially be extended to include such information regarding the building exteriors to the level of BIM(Building Information Modeling). This study aims to present and assess a basic method of extracting information related to the appearance of the exterior of a building for the purpose of 3D mapping using deep learning and digital image processing. After extracting and preprocessing images from the map, information was identified using the Fast R-CNN(Regions with Convolutional Neuron Networks) model. The information was identified using the Faster R-CNN model after extracting and preprocessing images from the map. As a result, it showed approximately 93% and 91% accuracy in terms of detecting the elevation and window parts of the building, respectively, as well as excellent performance in an experiment aimed at extracting the elevation information of the building. Nonetheless, it is expected that improved results will be obtained by supplementing the probability of mixing the false detection rate or noise data caused by the misunderstanding of experimenters in relation to the unclear boundaries of windows.
Learn2Reg: comprehensive multi-task medical image registration challenge, dataset and evaluation in the era of deep learning
Dec 23, 2021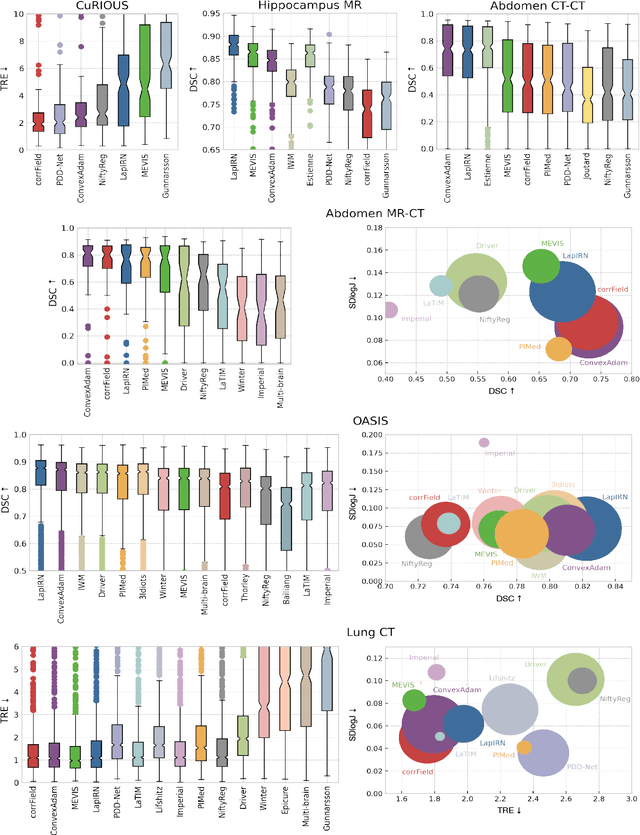
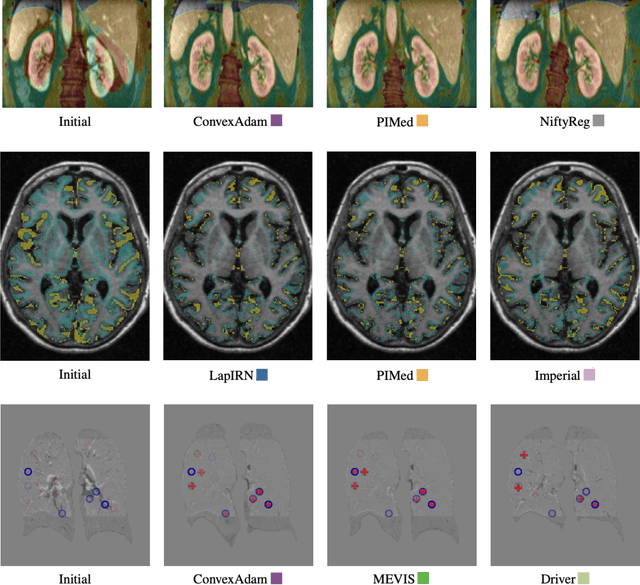
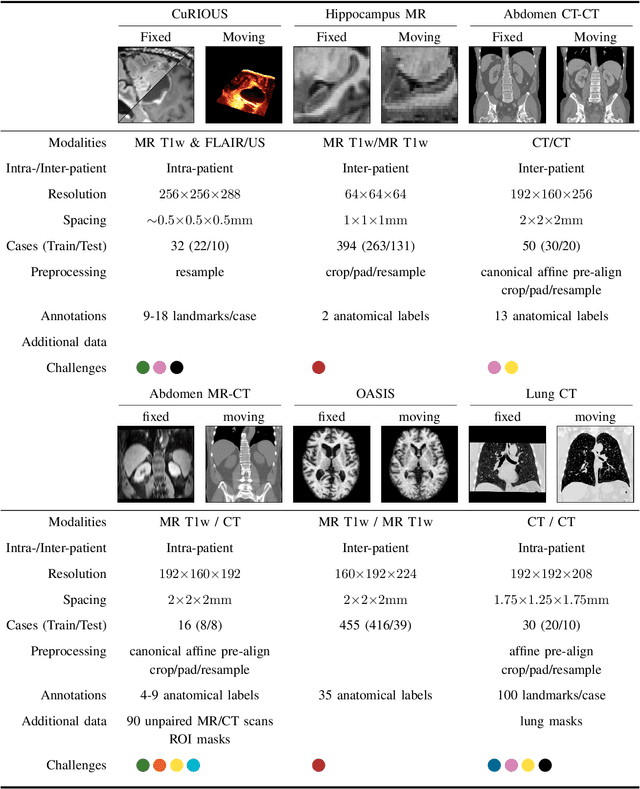
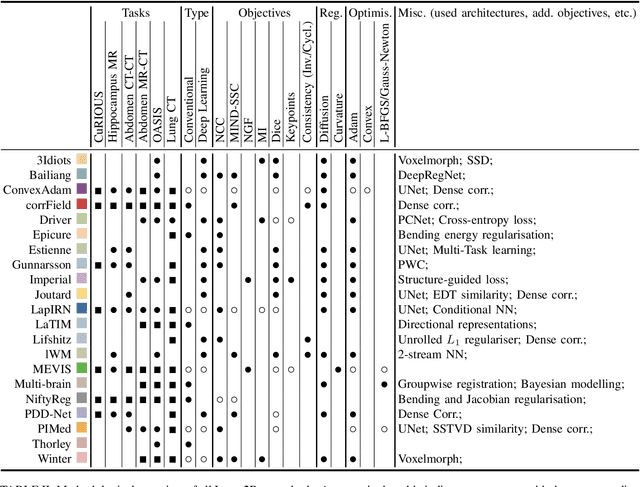
Image registration is a fundamental medical image analysis task, and a wide variety of approaches have been proposed. However, only a few studies have comprehensively compared medical image registration approaches on a wide range of clinically relevant tasks, in part because of the lack of availability of such diverse data. This limits the development of registration methods, the adoption of research advances into practice, and a fair benchmark across competing approaches. The Learn2Reg challenge addresses these limitations by providing a multi-task medical image registration benchmark for comprehensive characterisation of deformable registration algorithms. A continuous evaluation will be possible at https://learn2reg.grand-challenge.org. Learn2Reg covers a wide range of anatomies (brain, abdomen, and thorax), modalities (ultrasound, CT, MR), availability of annotations, as well as intra- and inter-patient registration evaluation. We established an easily accessible framework for training and validation of 3D registration methods, which enabled the compilation of results of over 65 individual method submissions from more than 20 unique teams. We used a complementary set of metrics, including robustness, accuracy, plausibility, and runtime, enabling unique insight into the current state-of-the-art of medical image registration. This paper describes datasets, tasks, evaluation methods and results of the challenge, and the results of further analysis of transferability to new datasets, the importance of label supervision, and resulting bias.
Deep Semantic Statistics Matching (D2SM) Denoising Network
Jul 19, 2022
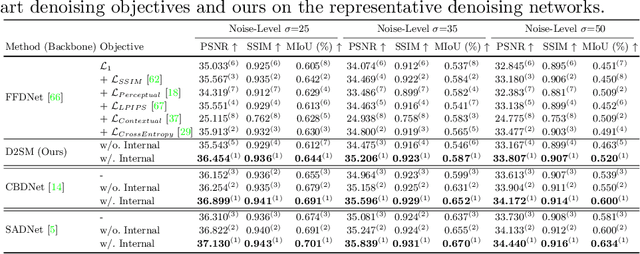
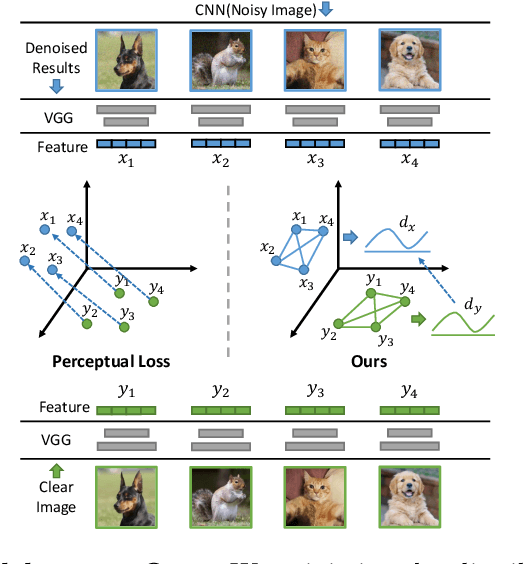
The ultimate aim of image restoration like denoising is to find an exact correlation between the noisy and clear image domains. But the optimization of end-to-end denoising learning like pixel-wise losses is performed in a sample-to-sample manner, which ignores the intrinsic correlation of images, especially semantics. In this paper, we introduce the Deep Semantic Statistics Matching (D2SM) Denoising Network. It exploits semantic features of pretrained classification networks, then it implicitly matches the probabilistic distribution of clear images at the semantic feature space. By learning to preserve the semantic distribution of denoised images, we empirically find our method significantly improves the denoising capabilities of networks, and the denoised results can be better understood by high-level vision tasks. Comprehensive experiments conducted on the noisy Cityscapes dataset demonstrate the superiority of our method on both the denoising performance and semantic segmentation accuracy. Moreover, the performance improvement observed on our extended tasks including super-resolution and dehazing experiments shows its potentiality as a new general plug-and-play component.