 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Blockage Prediction for Mobile UE in RIS-assisted Wireless Networks: A Deep Learning Approach
Sep 22, 2022
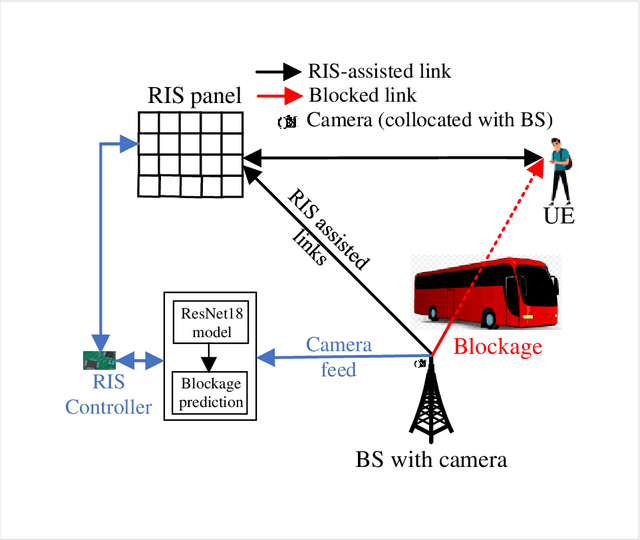
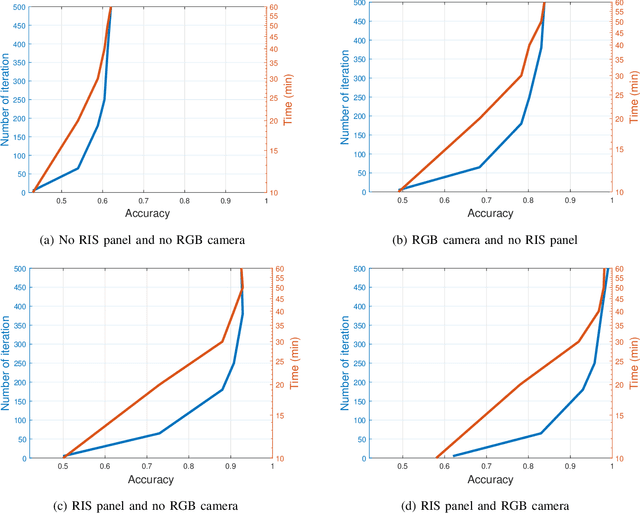
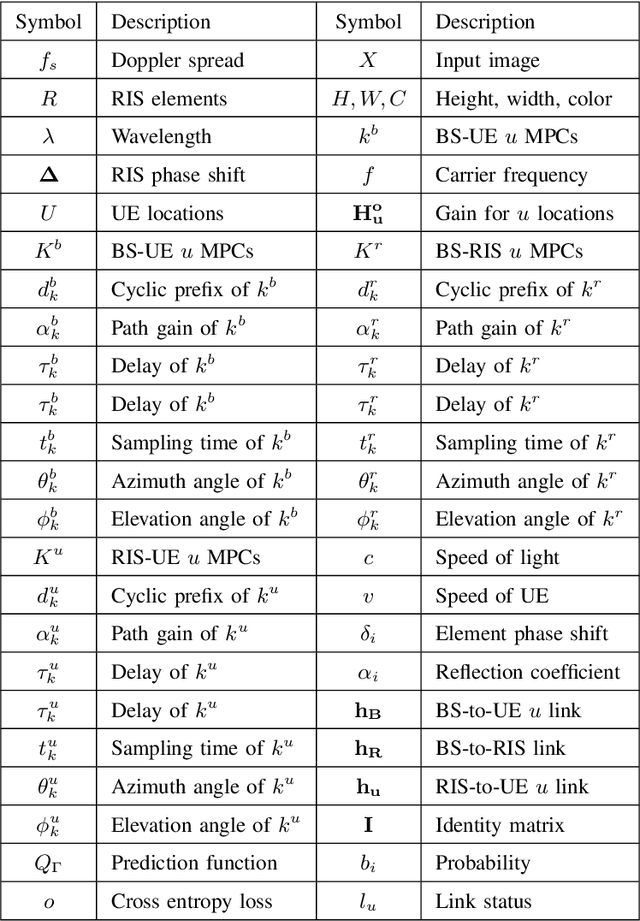
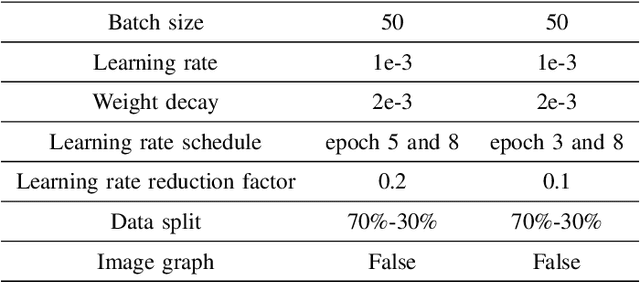
Due to significant blockage conditions in wireless networks, transmitted signals may considerably degrade before reaching the receiver. The reliability of the transmitted signals, therefore, may be critically problematic due to blockages between the communicating nodes. Thanks to the ability of Reconfigurable Intelligent Surfaces (RISs) to reflect the incident signals with different reflection angles, this may counter the blockage effect by optimally reflecting the transmit signals to receiving nodes, hence, improving the wireless network's performance. With this motivation, this paper formulates a RIS-aided wireless communication problem from a base station (BS) to a mobile user equipment (UE). The BS is equipped with an RGB camera. We use the RGB camera at the BS and the RIS panel to improve the system's performance while considering signal propagating through multiple paths and the Doppler spread for the mobile UE. First, the RGB camera is used to detect the presence of the UE with no blockage. When unsuccessful, the RIS-assisted gain takes over and is then used to detect if the UE is either "present but blocked" or "absent". The problem is determined as a ternary classification problem with the goal of maximizing the probability of UE communication blockage detection. We find the optimal solution for the probability of predicting the blockage status for a given RGB image and RIS-assisted data rate using a deep neural learning model. We employ the residual network 18-layer neural network model to find this optimal probability of blockage prediction. Extensive simulation results reveal that our proposed RIS panel-assisted model enhances the accuracy of maximization of the blockage prediction probability problem by over 38\% compared to the baseline scheme.
Scene Graph Generation for Better Image Captioning?
Sep 23, 2021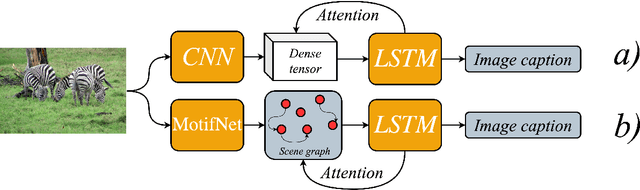
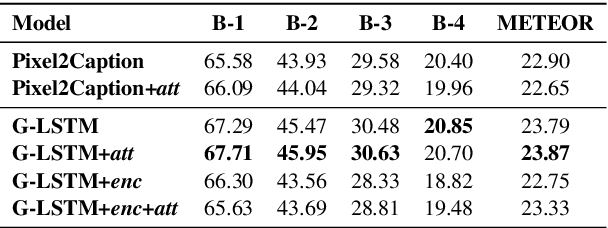
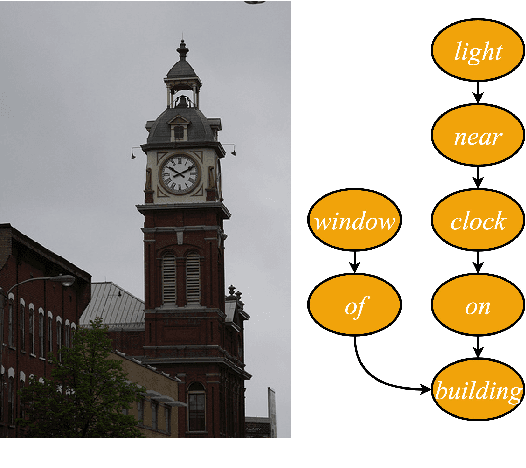
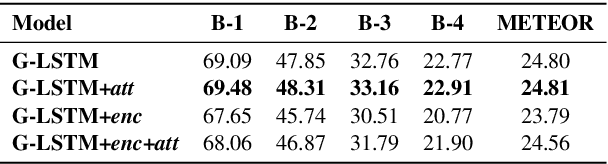
We investigate the incorporation of visual relationships into the task of supervised image caption generation by proposing a model that leverages detected objects and auto-generated visual relationships to describe images in natural language. To do so, we first generate a scene graph from raw image pixels by identifying individual objects and visual relationships between them. This scene graph then serves as input to our graph-to-text model, which generates the final caption. In contrast to previous approaches, our model thus explicitly models the detection of objects and visual relationships in the image. For our experiments we construct a new dataset from the intersection of Visual Genome and MS COCO, consisting of images with both a corresponding gold scene graph and human-authored caption. Our results show that our methods outperform existing state-of-the-art end-to-end models that generate image descriptions directly from raw input pixels when compared in terms of the BLEU and METEOR evaluation metrics.
High-Resolution Image Harmonization via Collaborative Dual Transformations
Sep 14, 2021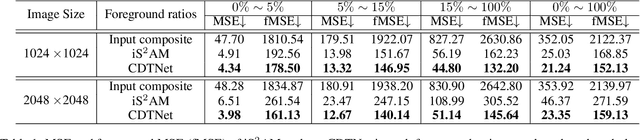

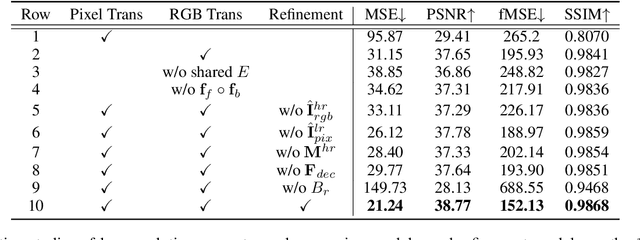
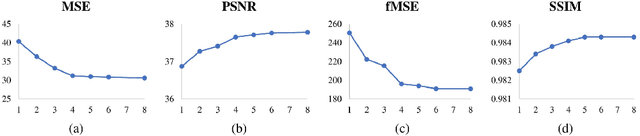
Given a composite image, image harmonization aims to adjust the foreground to make it compatible with the background. High-resolution image harmonization is in high demand, but still remains unexplored. Conventional image harmonization methods learn global RGB-to-RGB transformation which could effortlessly scale to high resolution, but ignore diverse local context. Recent deep learning methods learn the dense pixel-to-pixel transformation which could generate harmonious outputs, but are highly constrained in low resolution. In this work, we propose a high-resolution image harmonization network with Collaborative Dual Transformation (CDTNet) to combine pixel-to-pixel transformation and RGB-to-RGB transformation coherently in an end-to-end framework. Our CDTNet consists of a low-resolution generator for pixel-to-pixel transformation, a color mapping module for RGB-to-RGB transformation, and a refinement module to take advantage of both. Extensive experiments on high-resolution image harmonization dataset demonstrate that our CDTNet strikes a good balance between efficiency and effectiveness.
Monocular Human Shape and Pose with Dense Mesh-borne Local Image Features
Nov 10, 2021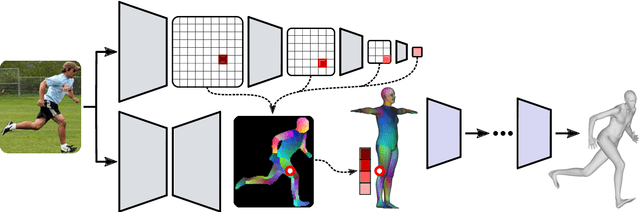

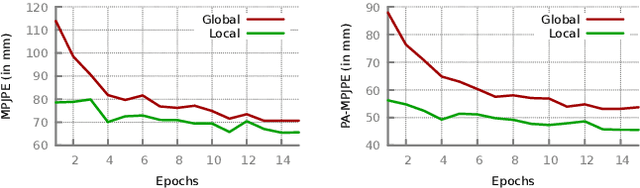
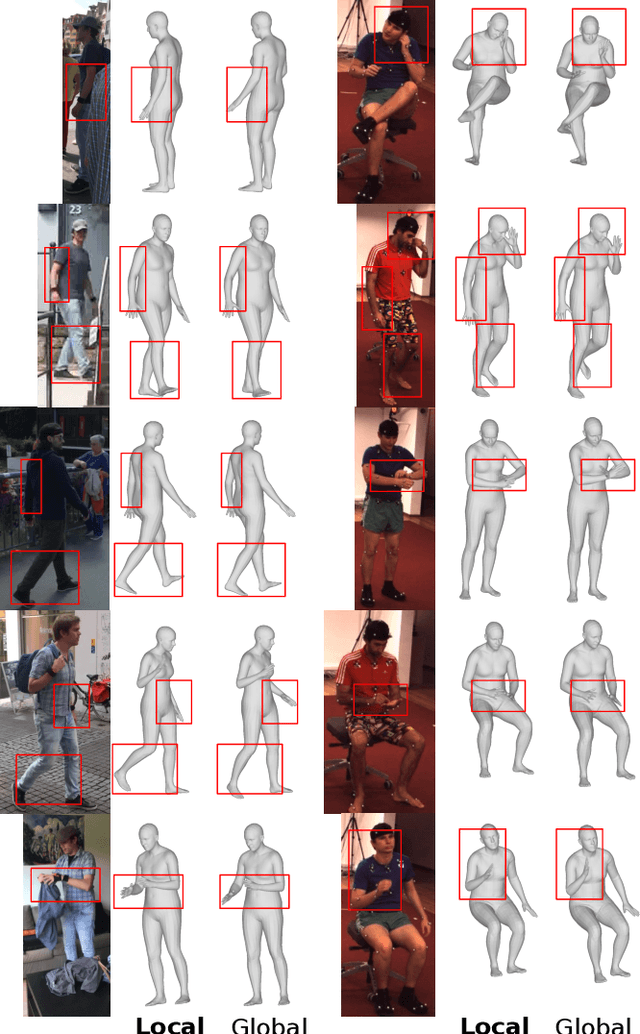
We propose to improve on graph convolution based approaches for human shape and pose estimation from monocular input, using pixel-aligned local image features. Given a single input color image, existing graph convolutional network (GCN) based techniques for human shape and pose estimation use a single convolutional neural network (CNN) generated global image feature appended to all mesh vertices equally to initialize the GCN stage, which transforms a template T-posed mesh into the target pose. In contrast, we propose for the first time the idea of using local image features per vertex. These features are sampled from the CNN image feature maps by utilizing pixel-to-mesh correspondences generated with DensePose. Our quantitative and qualitative results on standard benchmarks show that using local features improves on global ones and leads to competitive performances with respect to the state-of-the-art.
Image Segmentation with Topological Priors
May 12, 2022
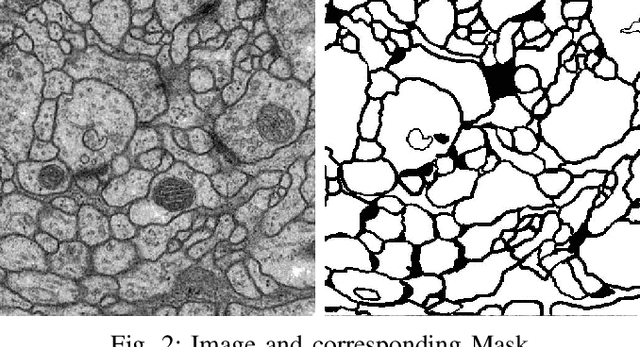
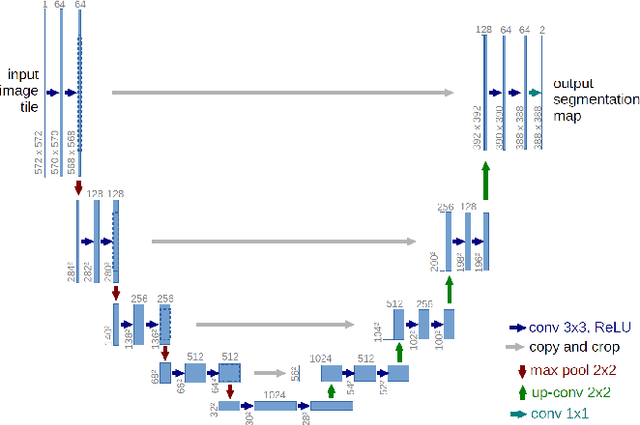
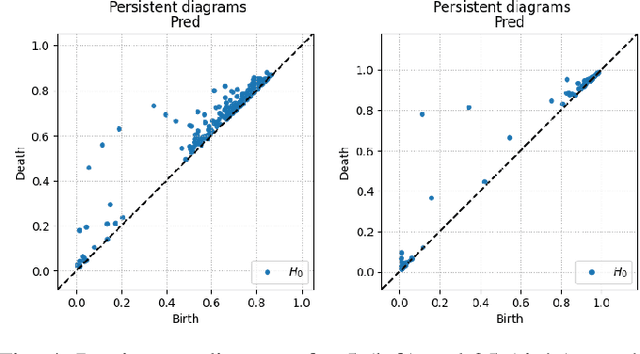
Solving segmentation tasks with topological priors proved to make fewer errors in fine-scale structures. In this work, we use topological priors both before and during the deep neural network training procedure. We compared the results of the two approaches with simple segmentation on various accuracy metrics and the Betti number error, which is directly related to topological correctness, and discovered that incorporating topological information into the classical UNet model performed significantly better. We conducted experiments on the ISBI EM segmentation dataset.
Automated Classification of Nanoparticles with Various Ultrastructures and Sizes
Jul 28, 2022
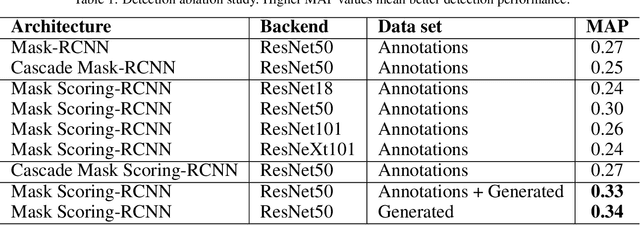
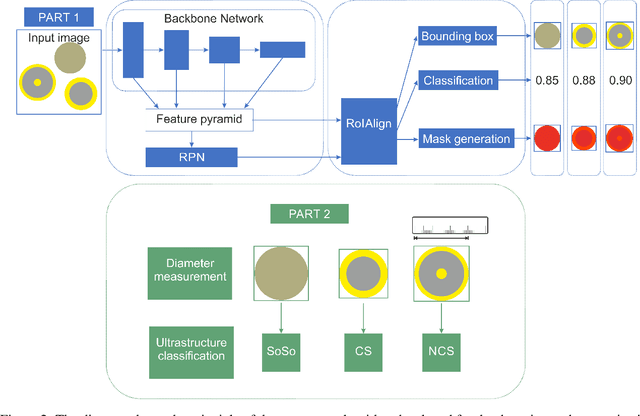
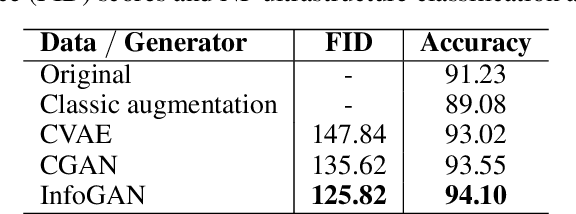
Accurately measuring the size, morphology, and structure of nanoparticles is very important, because they are strongly dependent on their properties for many applications. In this paper, we present a deep-learning based method for nanoparticle measurement and classification trained from a small data set of scanning transmission electron microscopy images. Our approach is comprised of two stages: localization, i.e., detection of nanoparticles, and classification, i.e., categorization of their ultrastructure. For each stage, we optimize the segmentation and classification by analysis of the different state-of-the-art neural networks. We show how the generation of synthetic images, either using image processing or using various image generation neural networks, can be used to improve the results in both stages. Finally, the application of the algorithm to bimetallic nanoparticles demonstrates the automated data collection of size distributions including classification of complex ultrastructures. The developed method can be easily transferred to other material systems and nanoparticle structures.
Open-Vocabulary Multi-Label Classification via Multi-modal Knowledge Transfer
Jul 05, 2022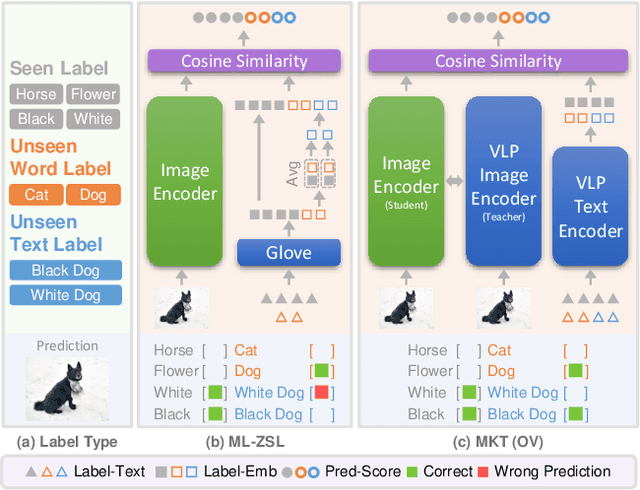



Real-world recognition system often encounters a plenty of unseen labels in practice. To identify such unseen labels, multi-label zero-shot learning (ML-ZSL) focuses on transferring knowledge by a pre-trained textual label embedding (e.g., GloVe). However, such methods only exploit singlemodal knowledge from a language model, while ignoring the rich semantic information inherent in image-text pairs. Instead, recently developed open-vocabulary (OV) based methods succeed in exploiting such information of image-text pairs in object detection, and achieve impressive performance. Inspired by the success of OV-based methods, we propose a novel open-vocabulary framework, named multimodal knowledge transfer (MKT), for multi-label classification. Specifically, our method exploits multi-modal knowledge of image-text pairs based on a vision and language pretraining (VLP) model. To facilitate transferring the imagetext matching ability of VLP model, knowledge distillation is used to guarantee the consistency of image and label embeddings, along with prompt tuning to further update the label embeddings. To further recognize multiple objects, a simple but effective two-stream module is developed to capture both local and global features. Extensive experimental results show that our method significantly outperforms state-of-theart methods on public benchmark datasets. Code will be available at https://github.com/seanhe97/MKT.
CACTUSS: Common Anatomical CT-US Space for US examinations
Jul 18, 2022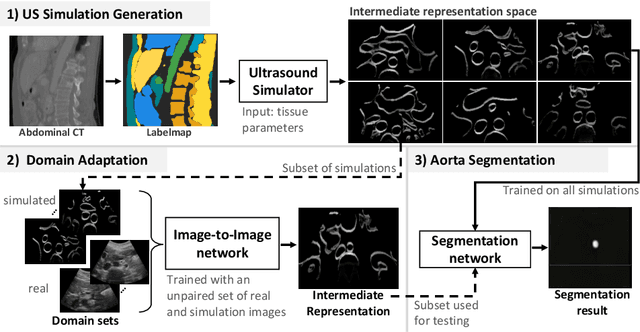
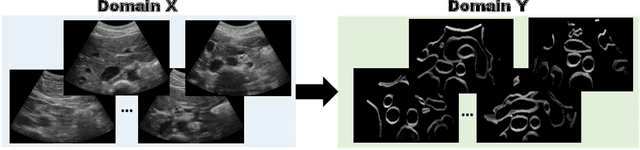
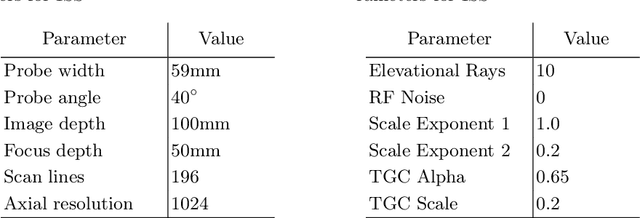
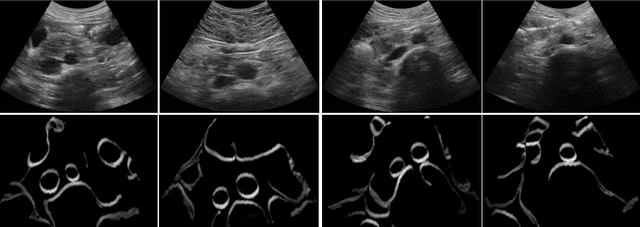
Abdominal aortic aneurysm (AAA) is a vascular disease in which a section of the aorta enlarges, weakening its walls and potentially rupturing the vessel. Abdominal ultrasound has been utilized for diagnostics, but due to its limited image quality and operator dependency, CT scans are usually required for monitoring and treatment planning. Recently, abdominal CT datasets have been successfully utilized to train deep neural networks for automatic aorta segmentation. Knowledge gathered from this solved task could therefore be leveraged to improve US segmentation for AAA diagnosis and monitoring. To this end, we propose CACTUSS: a common anatomical CT-US space, which acts as a virtual bridge between CT and US modalities to enable automatic AAA screening sonography. CACTUSS makes use of publicly available labelled data to learn to segment based on an intermediary representation that inherits properties from both US and CT. We train a segmentation network in this new representation and employ an additional image-to-image translation network which enables our model to perform on real B-mode images. Quantitative comparisons against fully supervised methods demonstrate the capabilities of CACTUSS in terms of Dice Score and diagnostic metrics, showing that our method also meets the clinical requirements for AAA scanning and diagnosis.
Universal Fourier Attack for Time Series
Sep 02, 2022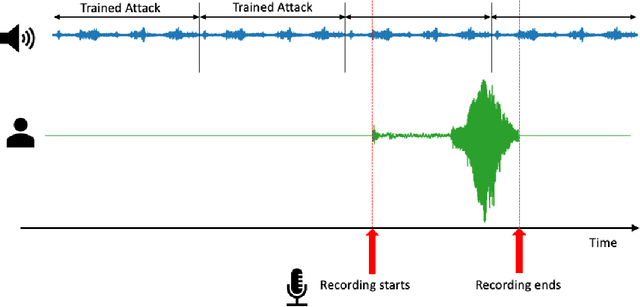
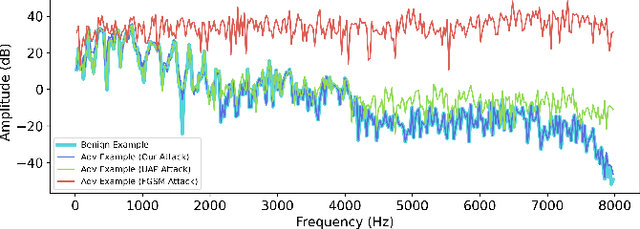
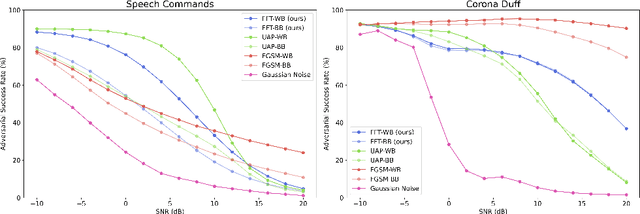
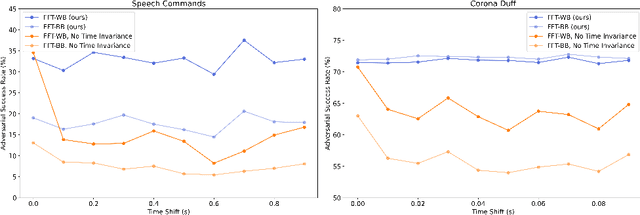
A wide variety of adversarial attacks have been proposed and explored using image and audio data. These attacks are notoriously easy to generate digitally when the attacker can directly manipulate the input to a model, but are much more difficult to implement in the real-world. In this paper we present a universal, time invariant attack for general time series data such that the attack has a frequency spectrum primarily composed of the frequencies present in the original data. The universality of the attack makes it fast and easy to implement as no computation is required to add it to an input, while time invariance is useful for real-world deployment. Additionally, the frequency constraint ensures the attack can withstand filtering. We demonstrate the effectiveness of the attack in two different domains, speech recognition and unintended radiated emission, and show that the attack is robust against common transform-and-compare defense pipelines.
iColoriT: Towards Propagating Local Hint to the Right Region in Interactive Colorization by Leveraging Vision Transformer
Jul 15, 2022
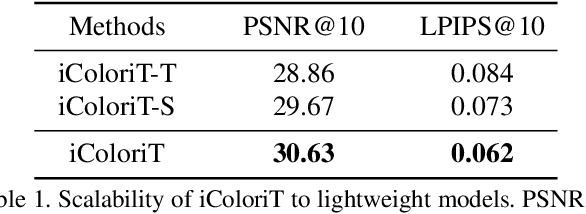

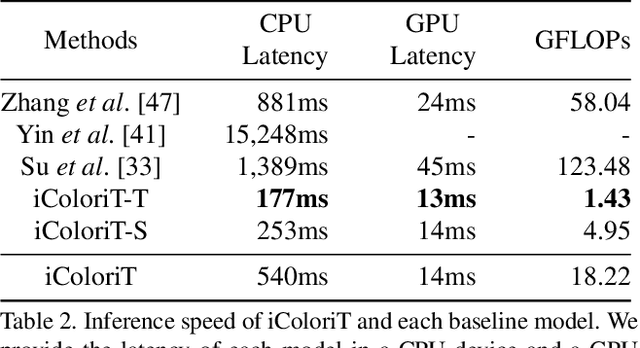
Point-interactive image colorization aims to colorize grayscale images when a user provides the colors for specific locations. It is essential for point-interactive colorization methods to appropriately propagate user-provided colors (i.e., user hints) in the entire image to obtain a reasonably colorized image with minimal user effort. However, existing approaches often produce partially colorized results due to the inefficient design of stacking convolutional layers to propagate hints to distant relevant regions. To address this problem, we present iColoriT, a novel point-interactive colorization Vision Transformer capable of propagating user hints to relevant regions, leveraging the global receptive field of Transformers. The self-attention mechanism of Transformers enables iColoriT to selectively colorize relevant regions with only a few local hints. Our approach colorizes images in real-time by utilizing pixel shuffling, an efficient upsampling technique that replaces the decoder architecture. Also, in order to mitigate the artifacts caused by pixel shuffling with large upsampling ratios, we present the local stabilizing layer. Extensive quantitative and qualitative results demonstrate that our approach highly outperforms existing methods for point-interactive colorization, producing accurately colorized images with a user's minimal effort.