 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Clustered Saliency Prediction
Jul 05, 2022
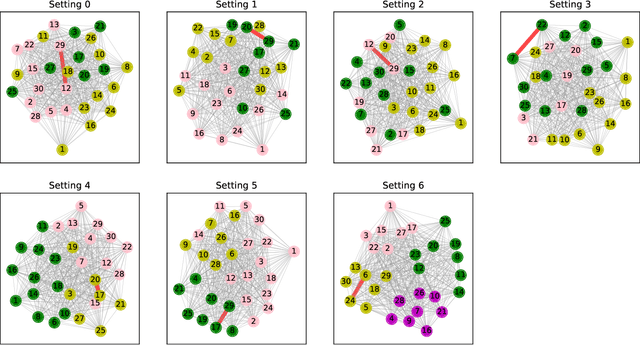
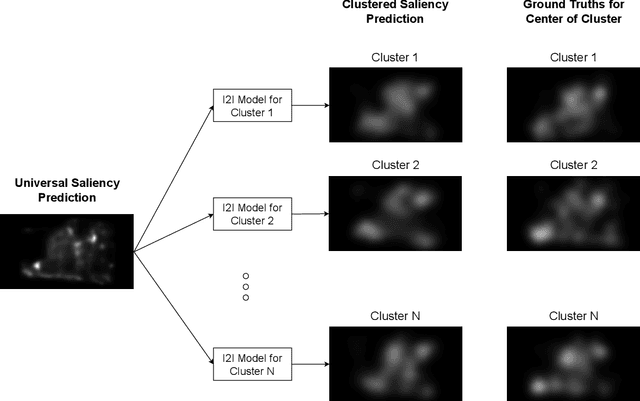
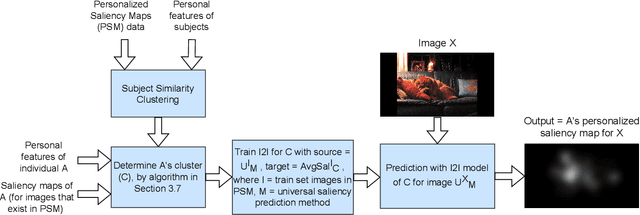

We present a new method for image salience prediction, Clustered Saliency Prediction. This method divides individuals into clusters based on their personal features and their known saliency maps, and generates a separate image salience model for each cluster. We test our approach on a public dataset of personalized saliency maps, with varying importance weights for personal feature factors and observe the effects on the clusters. For each cluster, we use an image-to-image translation method, mainly Pix2Pix model, to convert universal saliency maps to saliency maps of that cluster. We try three state-of-the-art universal saliency prediction methods, DeepGaze II, ML-Net and SalGAN, and see their impact on the results. We show that our Clustered Saliency Prediction technique outperforms the state-of-the-art universal saliency prediction models. Also we demonstrate the effectiveness of our clustering method by comparing the results of Clustered Saliency Prediction using clusters obtained by Subject Similarity Clustering algorithm with two baseline methods. We propose an approach to assign new people to the most appropriate cluster, based on their personal features and any known saliency maps. In our experiments we see that this method of assigning new people to a cluster on average chooses the cluster that gives higher saliency scores.
Can Language Understand Depth?
Jul 09, 2022
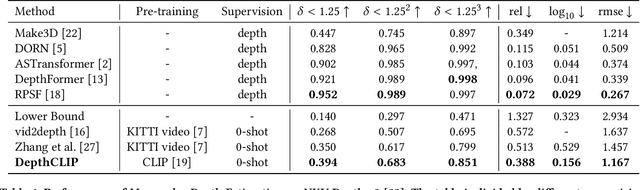
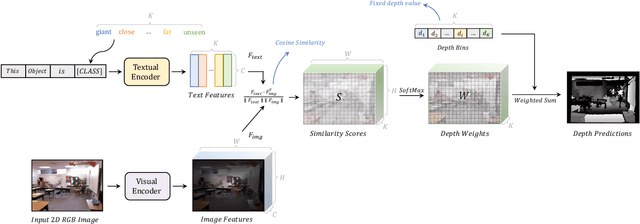
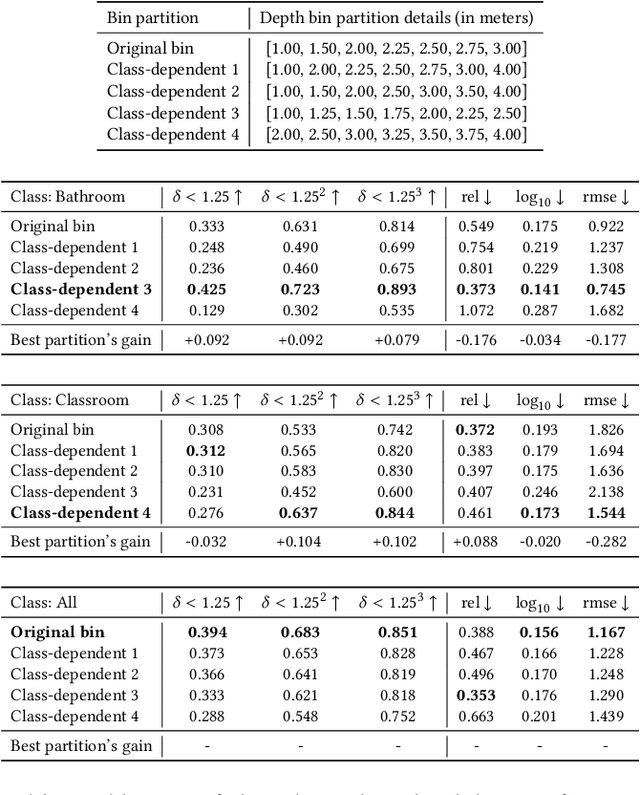
Besides image classification, Contrastive Language-Image Pre-training (CLIP) has accomplished extraordinary success for a wide range of vision tasks, including object-level and 3D space understanding. However, it's still challenging to transfer semantic knowledge learned from CLIP into more intricate tasks of quantified targets, such as depth estimation with geometric information. In this paper, we propose to apply CLIP for zero-shot monocular depth estimation, named DepthCLIP. We found that the patches of the input image could respond to a certain semantic distance token and then be projected to a quantified depth bin for coarse estimation. Without any training, our DepthCLIP surpasses existing unsupervised methods and even approaches the early fully-supervised networks. To our best knowledge, we are the first to conduct zero-shot adaptation from the semantic language knowledge to quantified downstream tasks and perform zero-shot monocular depth estimation. We hope our work could cast a light on future research. The code is available at https://github.com/Adonis-galaxy/DepthCLIP.
RFVTM: A Recovery and Filtering Vertex Trichotomy Matching for Remote Sensing Image Registration
Apr 02, 2022



Reliable feature point matching is a vital yet challenging process in feature-based image registration. In this paper,a robust feature point matching algorithm called Recovery and Filtering Vertex Trichotomy Matching (RFVTM) is proposed to remove outliers and retain sufficient inliers for remote sensing images. A novel affine invariant descriptor called vertex trichotomy descriptor is proposed on the basis of that geometrical relations between any of vertices and lines are preserved after affine transformations, which is constructed by mapping each vertex into trichotomy sets. The outlier removals in Vertex Trichotomy Matching (VTM) are implemented by iteratively comparing the disparity of corresponding vertex trichotomy descriptors. Some inliers mistakenly validated by a large amount of outliers are removed in VTM iterations, and several residual outliers close to correct locations cannot be excluded with the same graph structures. Therefore, a recovery and filtering strategy is designed to recover some inliers based on identical vertex trichotomy descriptors and restricted transformation errors. Assisted with the additional recovered inliers, residual outliers can also be filtered out during the process of reaching identical graph for the expanded vertex sets. Experimental results demonstrate the superior performance on precision and stability of this algorithm under various conditions, such as remote sensing images with large transformations, duplicated patterns, or inconsistent spectral content.
The Curious Layperson: Fine-Grained Image Recognition without Expert Labels
Nov 05, 2021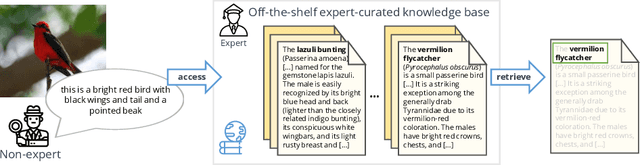
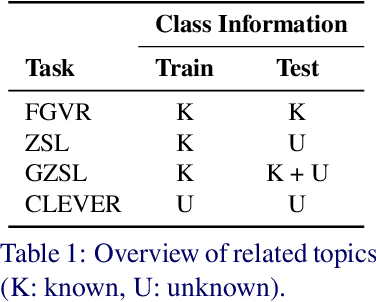
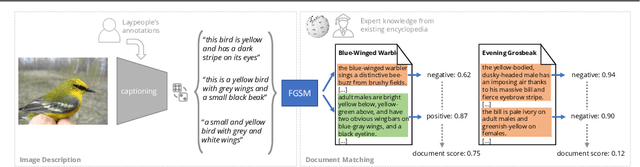
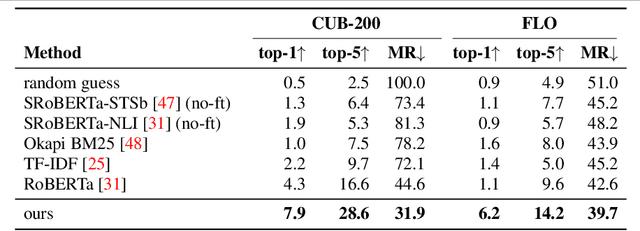
Most of us are not experts in specific fields, such as ornithology. Nonetheless, we do have general image and language understanding capabilities that we use to match what we see to expert resources. This allows us to expand our knowledge and perform novel tasks without ad-hoc external supervision. On the contrary, machines have a much harder time consulting expert-curated knowledge bases unless trained specifically with that knowledge in mind. Thus, in this paper we consider a new problem: fine-grained image recognition without expert annotations, which we address by leveraging the vast knowledge available in web encyclopedias. First, we learn a model to describe the visual appearance of objects using non-expert image descriptions. We then train a fine-grained textual similarity model that matches image descriptions with documents on a sentence-level basis. We evaluate the method on two datasets and compare with several strong baselines and the state of the art in cross-modal retrieval. Code is available at: https://github.com/subhc/clever
Deep Autoencoder Model Construction Based on Pytorch
Aug 17, 2022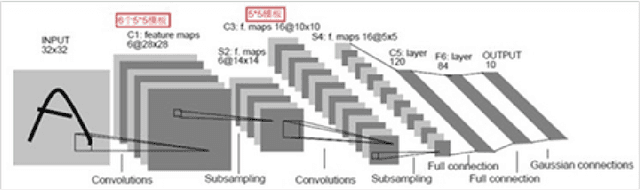
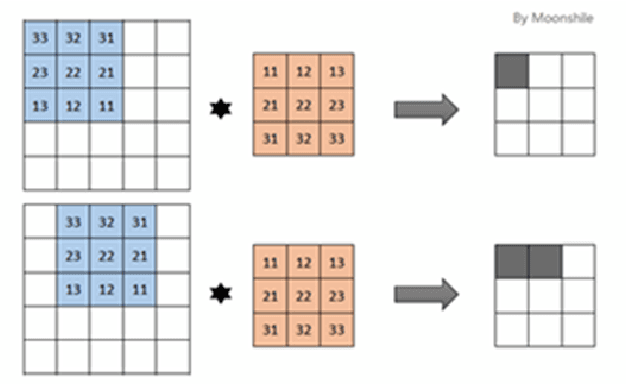
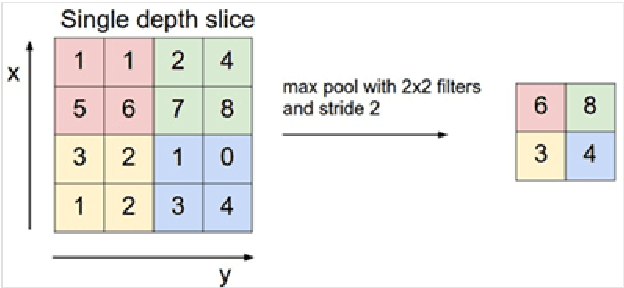
This paper proposes a deep autoencoder model based on Pytorch. This algorithm introduces the idea of Pytorch into the auto-encoder, and randomly clears the input weights connected to the hidden layer neurons with a certain probability, so as to achieve the effect of sparse network, which is similar to the starting point of the sparse auto-encoder. The new algorithm effectively solves the problem of possible overfitting of the model and improves the accuracy of image classification. Finally, the experiment is carried out, and the experimental results are compared with ELM, RELM, AE, SAE, DAE.
Scene Graph Generation for Better Image Captioning?
Sep 23, 2021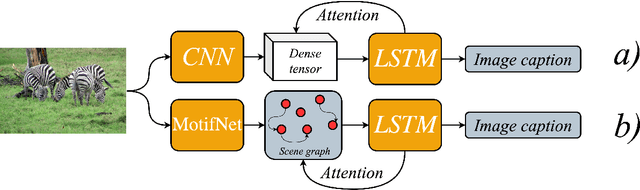
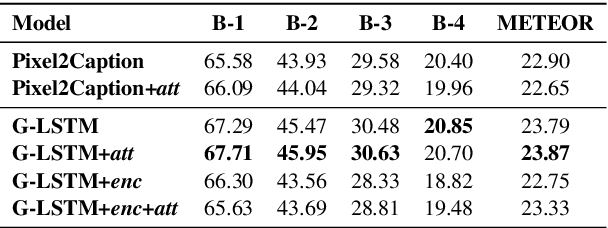
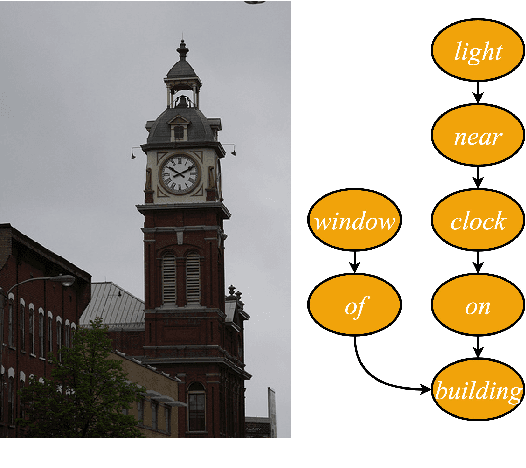
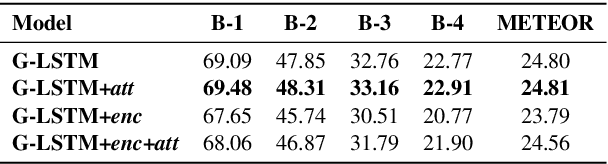
We investigate the incorporation of visual relationships into the task of supervised image caption generation by proposing a model that leverages detected objects and auto-generated visual relationships to describe images in natural language. To do so, we first generate a scene graph from raw image pixels by identifying individual objects and visual relationships between them. This scene graph then serves as input to our graph-to-text model, which generates the final caption. In contrast to previous approaches, our model thus explicitly models the detection of objects and visual relationships in the image. For our experiments we construct a new dataset from the intersection of Visual Genome and MS COCO, consisting of images with both a corresponding gold scene graph and human-authored caption. Our results show that our methods outperform existing state-of-the-art end-to-end models that generate image descriptions directly from raw input pixels when compared in terms of the BLEU and METEOR evaluation metrics.
High-Resolution Image Harmonization via Collaborative Dual Transformations
Sep 14, 2021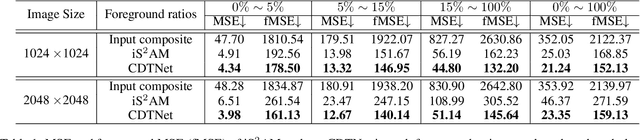

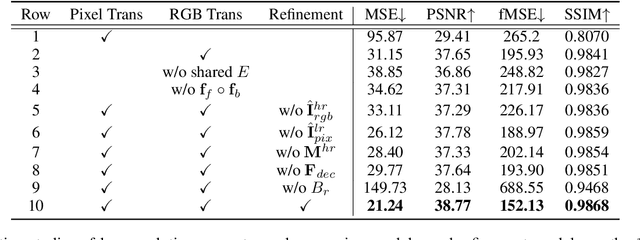
Given a composite image, image harmonization aims to adjust the foreground to make it compatible with the background. High-resolution image harmonization is in high demand, but still remains unexplored. Conventional image harmonization methods learn global RGB-to-RGB transformation which could effortlessly scale to high resolution, but ignore diverse local context. Recent deep learning methods learn the dense pixel-to-pixel transformation which could generate harmonious outputs, but are highly constrained in low resolution. In this work, we propose a high-resolution image harmonization network with Collaborative Dual Transformation (CDTNet) to combine pixel-to-pixel transformation and RGB-to-RGB transformation coherently in an end-to-end framework. Our CDTNet consists of a low-resolution generator for pixel-to-pixel transformation, a color mapping module for RGB-to-RGB transformation, and a refinement module to take advantage of both. Extensive experiments on high-resolution image harmonization dataset demonstrate that our CDTNet strikes a good balance between efficiency and effectiveness.
CARBEN: Composite Adversarial Robustness Benchmark
Jul 16, 2022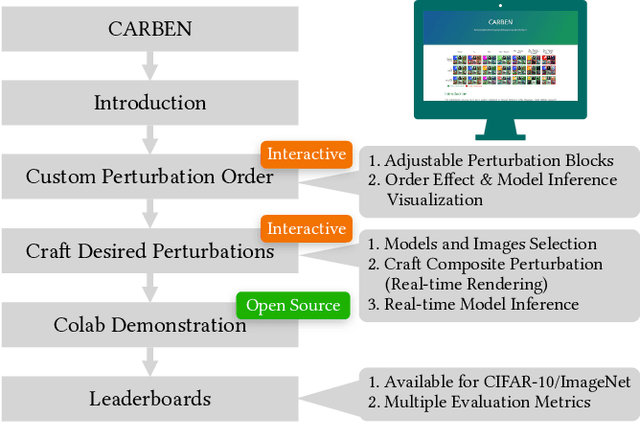



Prior literature on adversarial attack methods has mainly focused on attacking with and defending against a single threat model, e.g., perturbations bounded in Lp ball. However, multiple threat models can be combined into composite perturbations. One such approach, composite adversarial attack (CAA), not only expands the perturbable space of the image, but also may be overlooked by current modes of robustness evaluation. This paper demonstrates how CAA's attack order affects the resulting image, and provides real-time inferences of different models, which will facilitate users' configuration of the parameters of the attack level and their rapid evaluation of model prediction. A leaderboard to benchmark adversarial robustness against CAA is also introduced.
Fully trainable Gaussian derivative convolutional layer
Jul 18, 2022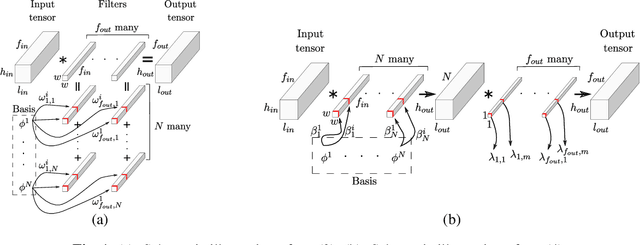
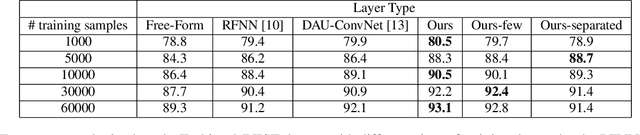

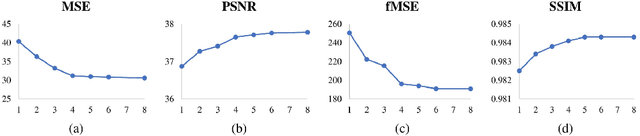
The Gaussian kernel and its derivatives have already been employed for Convolutional Neural Networks in several previous works. Most of these papers proposed to compute filters by linearly combining one or several bases of fixed or slightly trainable Gaussian kernels with or without their derivatives. In this article, we propose a high-level configurable layer based on anisotropic, oriented and shifted Gaussian derivative kernels which generalize notions encountered in previous related works while keeping their main advantage. The results show that the proposed layer has competitive performance compared to previous works and that it can be successfully included in common deep architectures such as VGG16 for image classification and U-net for image segmentation.
Monocular Human Shape and Pose with Dense Mesh-borne Local Image Features
Nov 10, 2021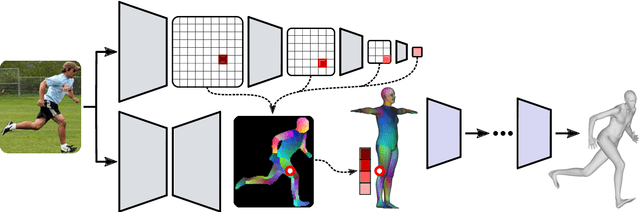

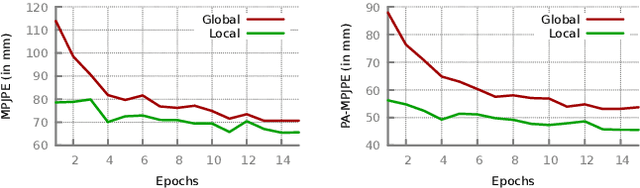
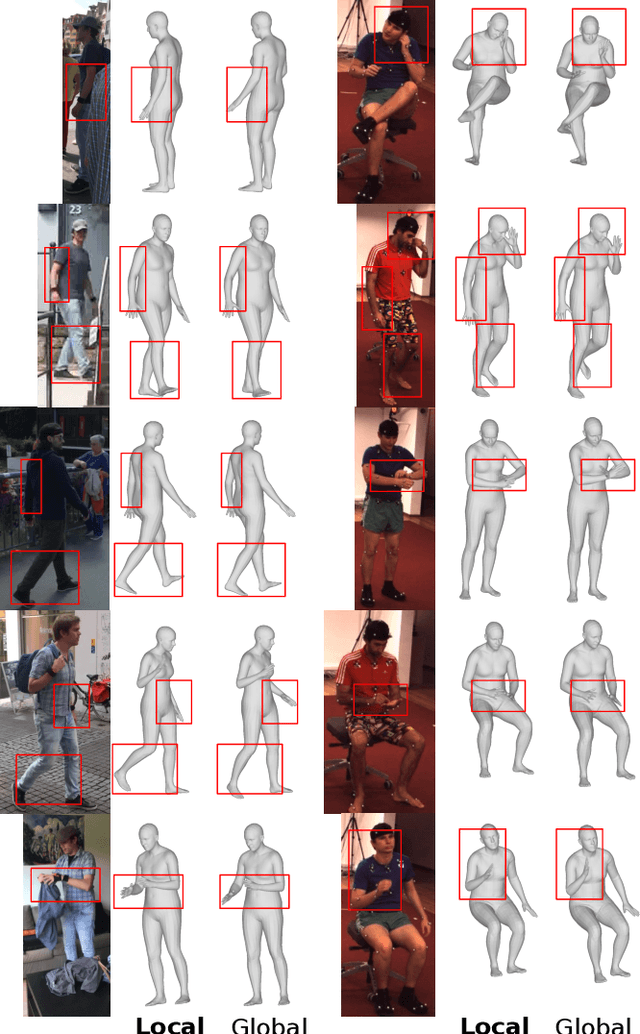
We propose to improve on graph convolution based approaches for human shape and pose estimation from monocular input, using pixel-aligned local image features. Given a single input color image, existing graph convolutional network (GCN) based techniques for human shape and pose estimation use a single convolutional neural network (CNN) generated global image feature appended to all mesh vertices equally to initialize the GCN stage, which transforms a template T-posed mesh into the target pose. In contrast, we propose for the first time the idea of using local image features per vertex. These features are sampled from the CNN image feature maps by utilizing pixel-to-mesh correspondences generated with DensePose. Our quantitative and qualitative results on standard benchmarks show that using local features improves on global ones and leads to competitive performances with respect to the state-of-the-art.