 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Semi-Supervised Medical Image Segmentation via Cross Teaching between CNN and Transformer
Dec 09, 2021
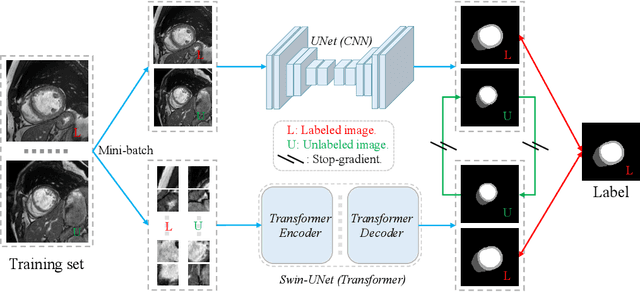
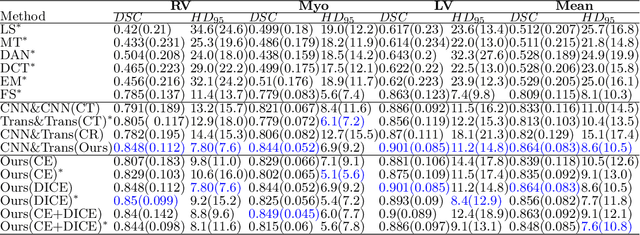

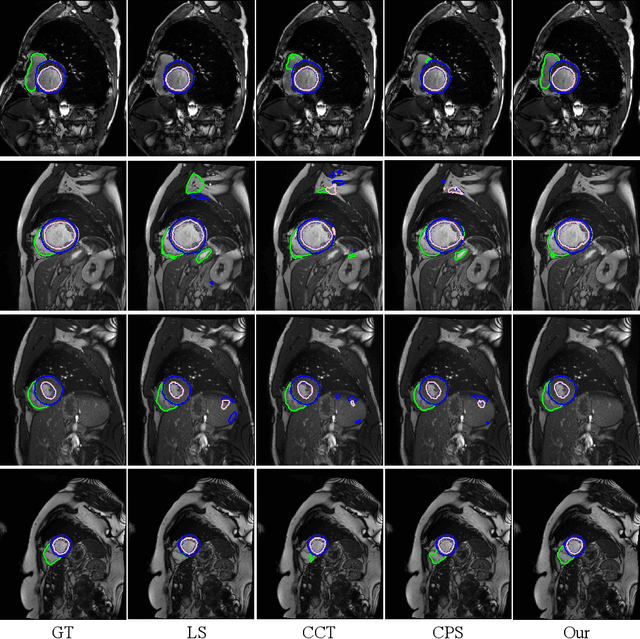
Recently, deep learning with Convolutional Neural Networks (CNNs) and Transformers has shown encouraging results in fully supervised medical image segmentation. However, it is still challenging for them to achieve good performance with limited annotations for training. In this work, we present a very simple yet efficient framework for semi-supervised medical image segmentation by introducing the cross teaching between CNN and Transformer. Specifically, we simplify the classical deep co-training from consistency regularization to cross teaching, where the prediction of a network is used as the pseudo label to supervise the other network directly end-to-end. Considering the difference in learning paradigm between CNN and Transformer, we introduce the Cross Teaching between CNN and Transformer rather than just using CNNs. Experiments on a public benchmark show that our method outperforms eight existing semi-supervised learning methods just with a simpler framework. Notably, this work may be the first attempt to combine CNN and transformer for semi-supervised medical image segmentation and achieve promising results on a public benchmark. The code will be released at: https://github.com/HiLab-git/SSL4MIS.
Reconciliation of Statistical and Spatial Sparsity For Robust Image and Image-Set Classification
Jun 01, 2021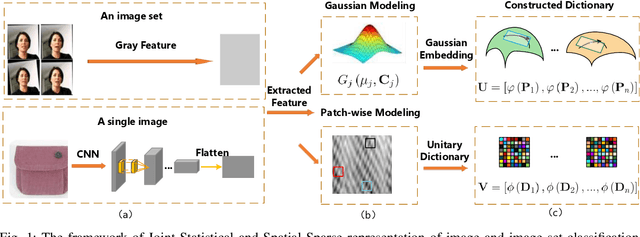
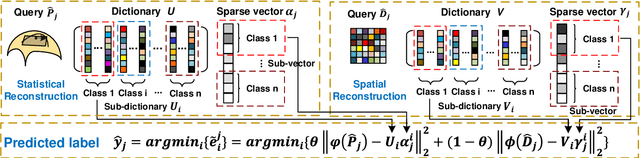

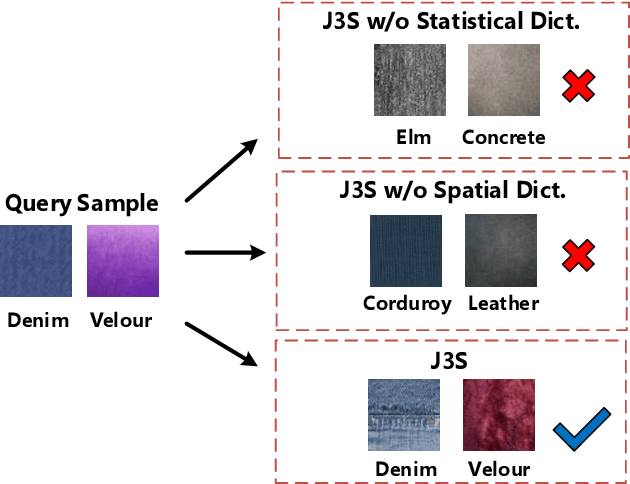
Recent image classification algorithms, by learning deep features from large-scale datasets, have achieved significantly better results comparing to the classic feature-based approaches. However, there are still various challenges of image classifications in practice, such as classifying noisy image or image-set queries and training deep image classification models over the limited-scale dataset. Instead of applying generic deep features, the model-based approaches can be more effective and data-efficient for robust image and image-set classification tasks, as various image priors are exploited for modeling the inter- and intra-set data variations while preventing over-fitting. In this work, we propose a novel Joint Statistical and Spatial Sparse representation, dubbed \textit{J3S}, to model the image or image-set data for classification, by reconciling both their local patch structures and global Gaussian distribution mapped into Riemannian manifold. To the best of our knowledge, no work to date utilized both global statistics and local patch structures jointly via joint sparse representation. We propose to solve the joint sparse coding problem based on the J3S model, by coupling the local and global image representations using joint sparsity. The learned J3S models are used for robust image and image-set classification. Experiments show that the proposed J3S-based image classification scheme outperforms the popular or state-of-the-art competing methods over FMD, UIUC, ETH-80 and YTC databases.
CLIFF: Carrying Location Information in Full Frames into Human Pose and Shape Estimation
Aug 01, 2022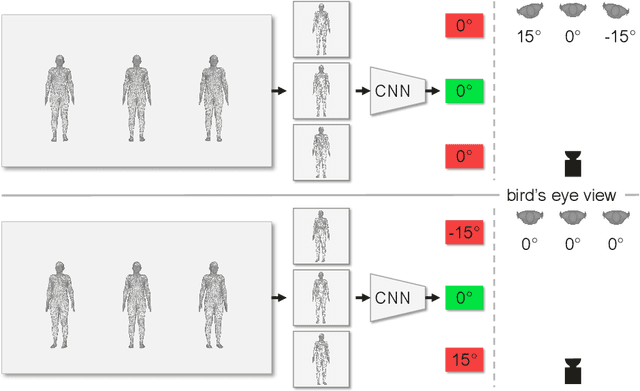
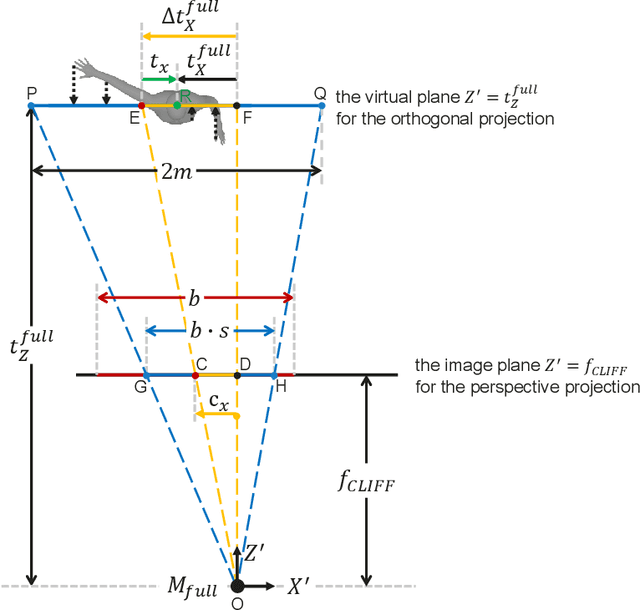
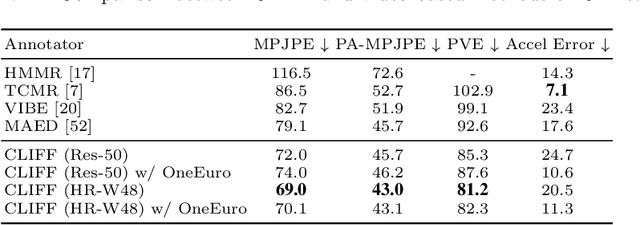
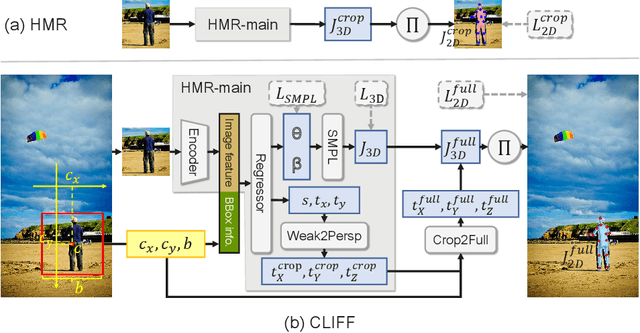
Top-down methods dominate the field of 3D human pose and shape estimation, because they are decoupled from human detection and allow researchers to focus on the core problem. However, cropping, their first step, discards the location information from the very beginning, which makes themselves unable to accurately predict the global rotation in the original camera coordinate system. To address this problem, we propose to Carry Location Information in Full Frames (CLIFF) into this task. Specifically, we feed more holistic features to CLIFF by concatenating the cropped-image feature with its bounding box information. We calculate the 2D reprojection loss with a broader view of the full frame, taking a projection process similar to that of the person projected in the image. Fed and supervised by global-location-aware information, CLIFF directly predicts the global rotation along with more accurate articulated poses. Besides, we propose a pseudo-ground-truth annotator based on CLIFF, which provides high-quality 3D annotations for in-the-wild 2D datasets and offers crucial full supervision for regression-based methods. Extensive experiments on popular benchmarks show that CLIFF outperforms prior arts by a significant margin, and reaches the first place on the AGORA leaderboard (the SMPL-Algorithms track). The code and data are available at https://github.com/huawei-noah/noah-research/tree/master/CLIFF.
Impact of Colour Variation on Robustness of Deep Neural Networks
Sep 02, 2022
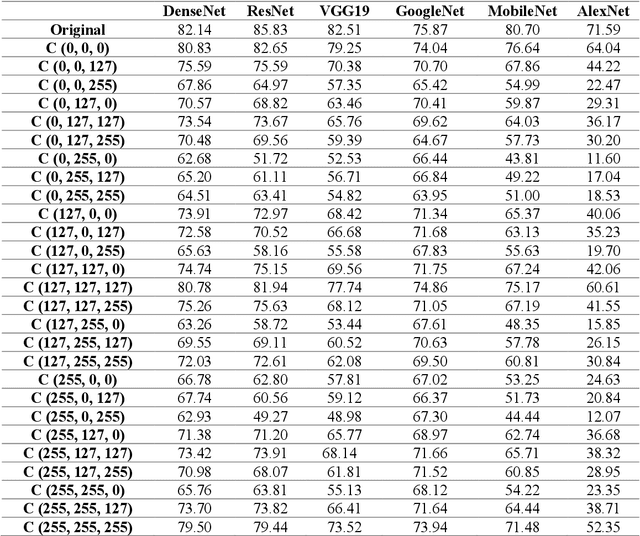
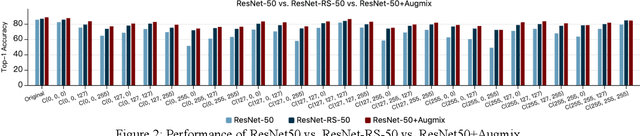
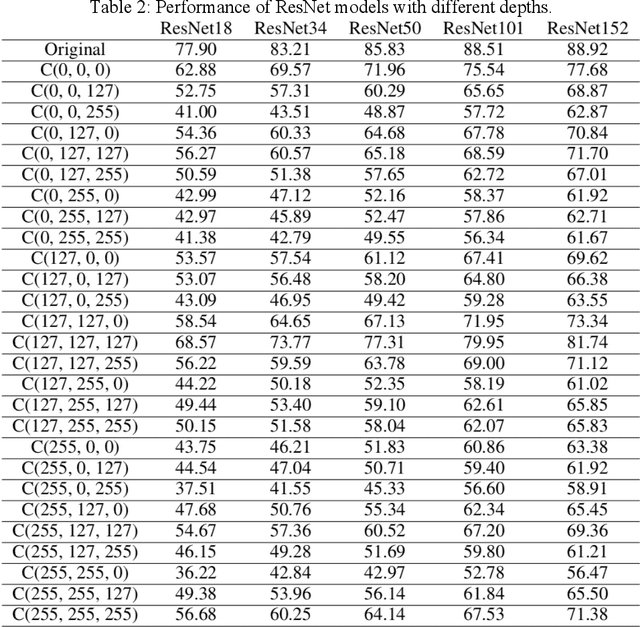
Deep neural networks (DNNs) have have shown state-of-the-art performance for computer vision applications like image classification, segmentation and object detection. Whereas recent advances have shown their vulnerability to manual digital perturbations in the input data, namely adversarial attacks. The accuracy of the networks is significantly affected by the data distribution of their training dataset. Distortions or perturbations on color space of input images generates out-of-distribution data, which make networks more likely to misclassify them. In this work, we propose a color-variation dataset by distorting their RGB color on a subset of the ImageNet with 27 different combinations. The aim of our work is to study the impact of color variation on the performance of DNNs. We perform experiments on several state-of-the-art DNN architectures on the proposed dataset, and the result shows a significant correlation between color variation and loss of accuracy. Furthermore, based on the ResNet50 architecture, we demonstrate some experiments of the performance of recently proposed robust training techniques and strategies, such as Augmix, revisit, and free normalizer, on our proposed dataset. Experimental results indicate that these robust training techniques can improve the robustness of deep networks to color variation.
Learning Probabilistic Structural Representation for Biomedical Image Segmentation
Jun 03, 2022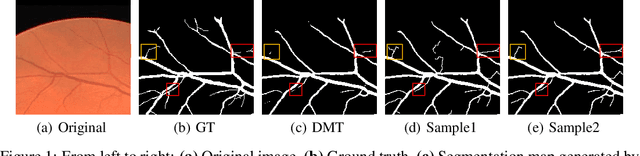
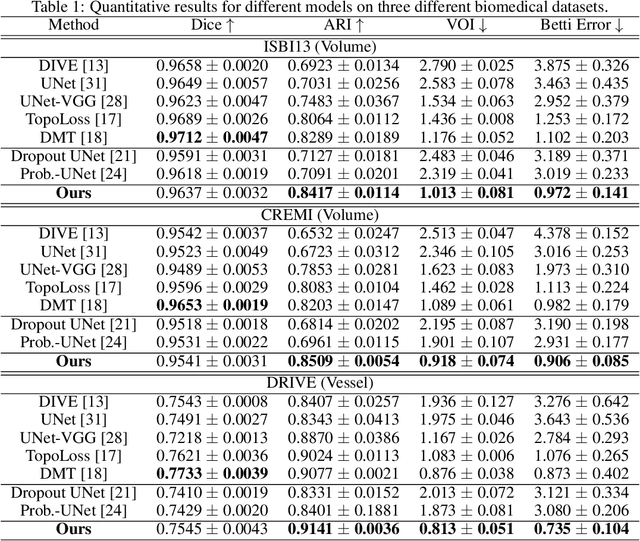
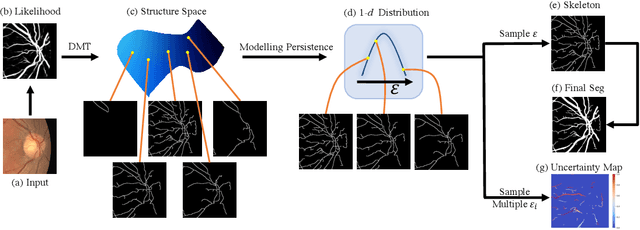
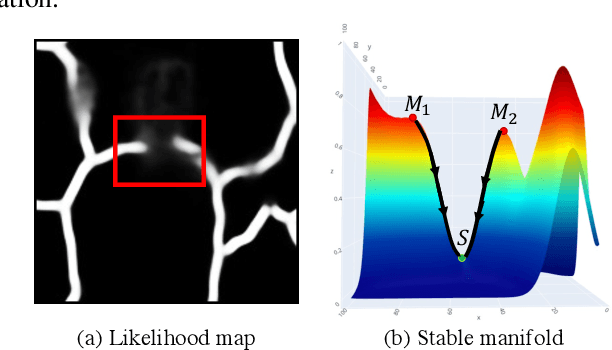
Accurate segmentation of various fine-scale structures from biomedical images is a very important yet challenging problem. Existing methods use topological information as an additional training loss, but are ultimately learning a pixel-wise representation. In this paper, we propose the first deep learning method to learn a structural representation. We use discrete Morse theory and persistent homology to construct an one-parameter family of structures as the structural representation space. Furthermore, we learn a probabilistic model that can do inference tasks on such a structural representation space. We empirically demonstrate the strength of our method, i.e., generating true structures rather than pixel-maps with better topological integrity, and facilitating a human-in-the-loop annotation pipeline using the sampling of structures and structure-aware uncertainty.
Pro-tuning: Unified Prompt Tuning for Vision Tasks
Jul 28, 2022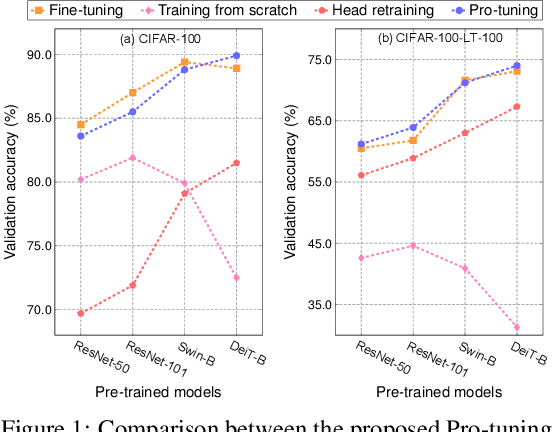
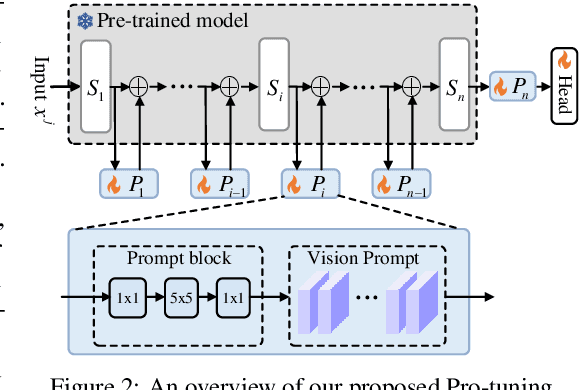
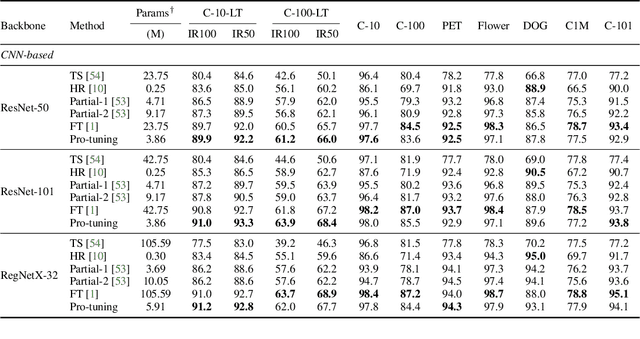
In computer vision, fine-tuning is the de-facto approach to leverage pre-trained vision models to perform downstream tasks. However, deploying it in practice is quite challenging, due to adopting parameter inefficient global update and heavily relying on high-quality downstream data. Recently, prompt-based learning, which adds a task-relevant prompt to adapt the downstream tasks to pre-trained models, has drastically boosted the performance of many natural language downstream tasks. In this work, we extend this notable transfer ability benefited from prompt into vision models as an alternative to fine-tuning. To this end, we propose parameter-efficient Prompt tuning (Pro-tuning) to adapt frozen vision models to various downstream vision tasks. The key to Pro-tuning is prompt-based tuning, i.e., learning task-specific vision prompts for downstream input images with the pre-trained model frozen. By only training a few additional parameters, it can work on diverse CNN-based and Transformer-based architectures. Extensive experiments evidence that Pro-tuning outperforms fine-tuning in a broad range of vision tasks and scenarios, including image classification (generic objects, class imbalance, image corruption, adversarial robustness, and out-of-distribution generalization), and dense prediction tasks such as object detection and semantic segmentation.
A Non-isotropic Probabilistic Take on Proxy-based Deep Metric Learning
Jul 08, 2022
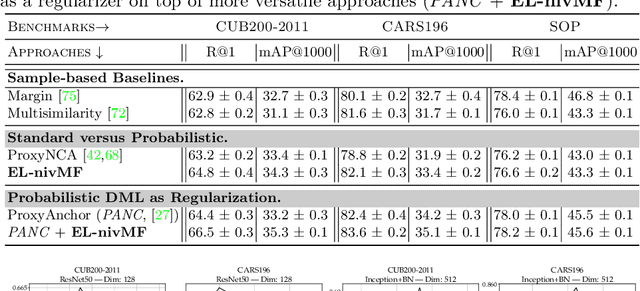
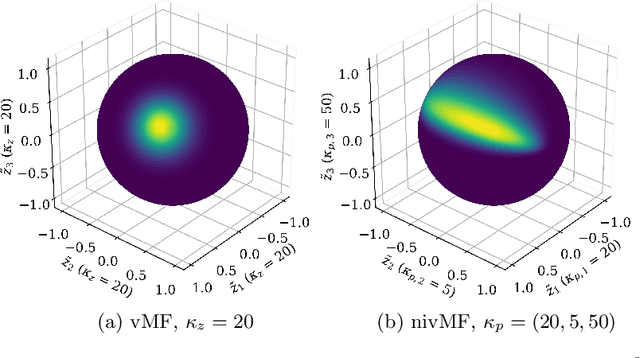
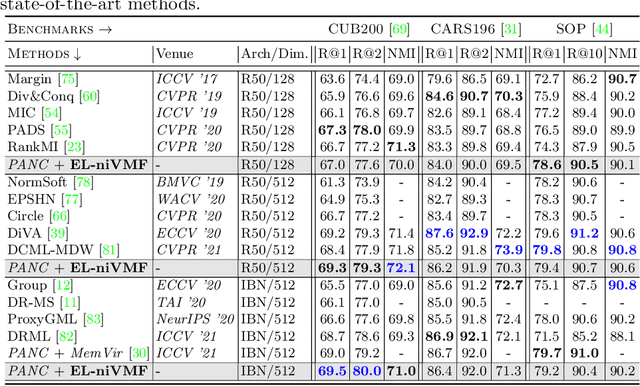
Proxy-based Deep Metric Learning (DML) learns deep representations by embedding images close to their class representatives (proxies), commonly with respect to the angle between them. However, this disregards the embedding norm, which can carry additional beneficial context such as class- or image-intrinsic uncertainty. In addition, proxy-based DML struggles to learn class-internal structures. To address both issues at once, we introduce non-isotropic probabilistic proxy-based DML. We model images as directional von Mises-Fisher (vMF) distributions on the hypersphere that can reflect image-intrinsic uncertainties. Further, we derive non-isotropic von Mises-Fisher (nivMF) distributions for class proxies to better represent complex class-specific variances. To measure the proxy-to-image distance between these models, we develop and investigate multiple distribution-to-point and distribution-to-distribution metrics. Each framework choice is motivated by a set of ablational studies, which showcase beneficial properties of our probabilistic approach to proxy-based DML, such as uncertainty-awareness, better-behaved gradients during training, and overall improved generalization performance. The latter is especially reflected in the competitive performance on the standard DML benchmarks, where our approach compares favorably, suggesting that existing proxy-based DML can significantly benefit from a more probabilistic treatment. Code is available at github.com/ExplainableML/Probabilistic_Deep_Metric_Learning.
Multiscale Convolutional Transformer with Center Mask Pretraining for Hyperspectral Image Classificationtion
Mar 09, 2022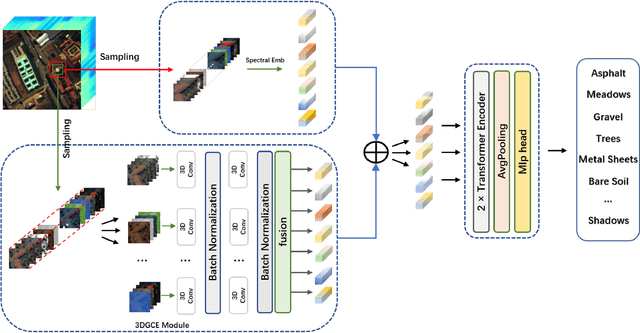
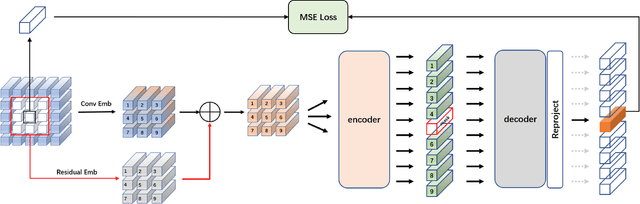
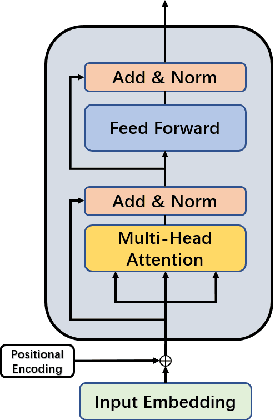
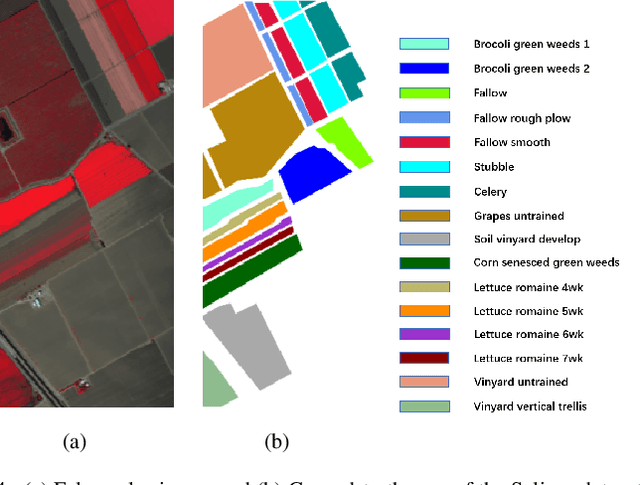
Hyperspectral images (HSI) not only have a broad macroscopic field of view but also contain rich spectral information, and the types of surface objects can be identified through spectral information, which is one of the main applications in hyperspectral image related research.In recent years, more and more deep learning methods have been proposed, among which convolutional neural networks (CNN) are the most influential. However, CNN-based methods are difficult to capture long-range dependencies, and also require a large amount of labeled data for model training.Besides, most of the self-supervised training methods in the field of HSI classification are based on the reconstruction of input samples, and it is difficult to achieve effective use of unlabeled samples. To address the shortcomings of CNN networks, we propose a noval multi-scale convolutional embedding module for HSI to realize effective extraction of spatial-spectral information, which can be better combined with Transformer network.In order to make more efficient use of unlabeled data, we propose a new self-supervised pretask. Similar to Mask autoencoder, but our pre-training method only masks the corresponding token of the central pixel in the encoder, and inputs the remaining token into the decoder to reconstruct the spectral information of the central pixel.Such a pretask can better model the relationship between the central feature and the domain feature, and obtain more stable training results.
Noisy Inliers Make Great Outliers: Out-of-Distribution Object Detection with Noisy Synthetic Outliers
Aug 29, 2022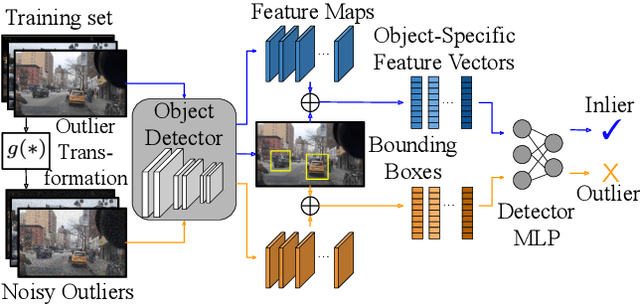
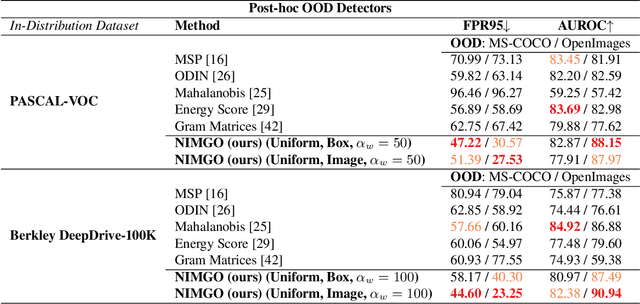

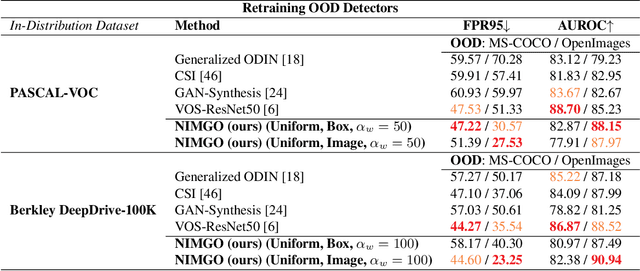
Many high-performing works on out-of-distribution (OOD) detection use real or synthetically generated outlier data to regularise model confidence; however, they often require retraining of the base network or specialised model architectures. Our work demonstrates that Noisy Inliers Make Great Outliers (NIMGO) in the challenging field of OOD object detection. We hypothesise that synthetic outliers need only be minimally perturbed variants of the in-distribution (ID) data in order to train a discriminator to identify OOD samples -- without expensive retraining of the base network. To test our hypothesis, we generate a synthetic outlier set by applying an additive-noise perturbation to ID samples at the image or bounding-box level. An auxiliary feature monitoring multilayer perceptron (MLP) is then trained to detect OOD feature representations using the perturbed ID samples as a proxy. During testing, we demonstrate that the auxiliary MLP distinguishes ID samples from OOD samples at a state-of-the-art level, reducing the false positive rate by more than 20\% (absolute) over the previous state-of-the-art on the OpenImages dataset. Extensive additional ablations provide empirical evidence in support of our hypothesis.
OrthoMAD: Morphing Attack Detection Through Orthogonal Identity Disentanglement
Aug 16, 2022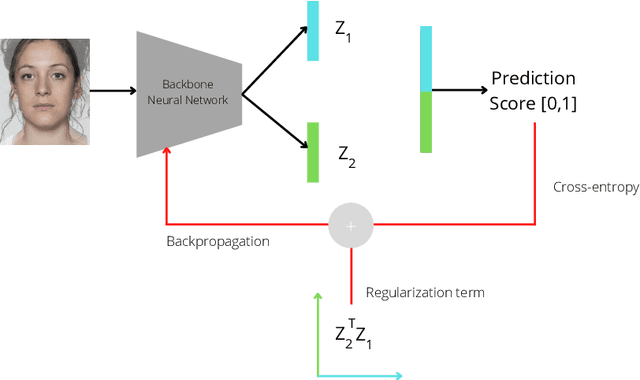
Morphing attacks are one of the many threats that are constantly affecting deep face recognition systems. It consists of selecting two faces from different individuals and fusing them into a final image that contains the identity information of both. In this work, we propose a novel regularisation term that takes into account the existent identity information in both and promotes the creation of two orthogonal latent vectors. We evaluate our proposed method (OrthoMAD) in five different types of morphing in the FRLL dataset and evaluate the performance of our model when trained on five distinct datasets. With a small ResNet-18 as the backbone, we achieve state-of-the-art results in the majority of the experiments, and competitive results in the others. The code of this paper will be publicly available.