 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Pyramid Attention Network for Medical Image Registration
Feb 14, 2024
The advent of deep-learning-based registration networks has addressed the time-consuming challenge in traditional iterative methods.However, the potential of current registration networks for comprehensively capturing spatial relationships has not been fully explored, leading to inadequate performance in large-deformation image registration.The pure convolutional neural networks (CNNs) neglect feature enhancement, while current Transformer-based networks are susceptible to information redundancy.To alleviate these issues, we propose a pyramid attention network (PAN) for deformable medical image registration.Specifically, the proposed PAN incorporates a dual-stream pyramid encoder with channel-wise attention to boost the feature representation.Moreover, a multi-head local attention Transformer is introduced as decoder to analyze motion patterns and generate deformation fields.Extensive experiments on two public brain magnetic resonance imaging (MRI) datasets and one abdominal MRI dataset demonstrate that our method achieves favorable registration performance, while outperforming several CNN-based and Transformer-based registration networks.Our code is publicly available at https://github.com/JuliusWang-7/PAN.
NRDF: Neural Riemannian Distance Fields for Learning Articulated Pose Priors
Mar 05, 2024
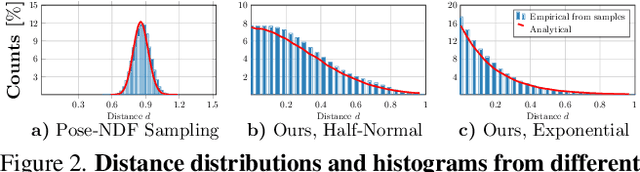
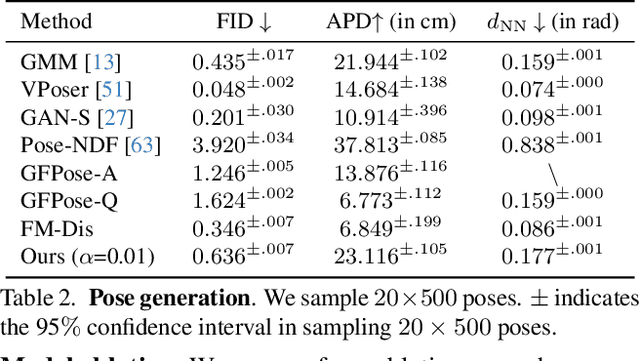
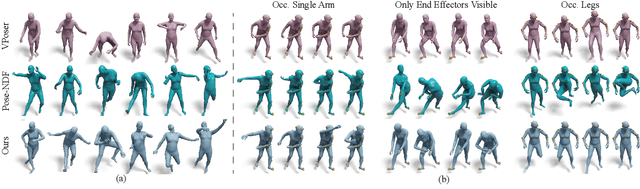
Faithfully modeling the space of articulations is a crucial task that allows recovery and generation of realistic poses, and remains a notorious challenge. To this end, we introduce Neural Riemannian Distance Fields (NRDFs), data-driven priors modeling the space of plausible articulations, represented as the zero-level-set of a neural field in a high-dimensional product-quaternion space. To train NRDFs only on positive examples, we introduce a new sampling algorithm, ensuring that the geodesic distances follow a desired distribution, yielding a principled distance field learning paradigm. We then devise a projection algorithm to map any random pose onto the level-set by an adaptive-step Riemannian optimizer, adhering to the product manifold of joint rotations at all times. NRDFs can compute the Riemannian gradient via backpropagation and by mathematical analogy, are related to Riemannian flow matching, a recent generative model. We conduct a comprehensive evaluation of NRDF against other pose priors in various downstream tasks, i.e., pose generation, image-based pose estimation, and solving inverse kinematics, highlighting NRDF's superior performance. Besides humans, NRDF's versatility extends to hand and animal poses, as it can effectively represent any articulation.
Matrix Completion with Convex Optimization and Column Subset Selection
Mar 05, 2024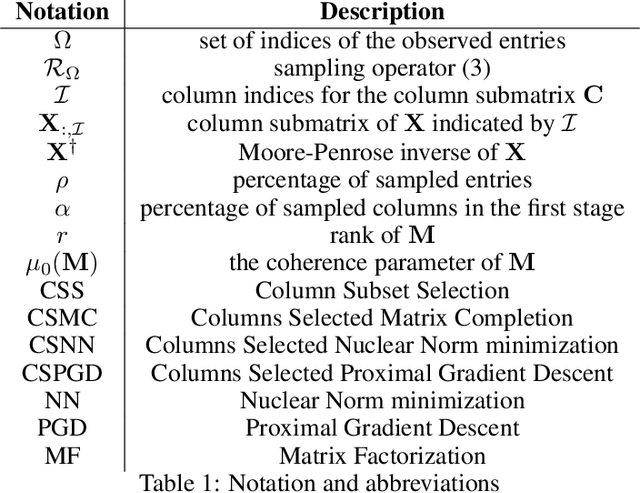
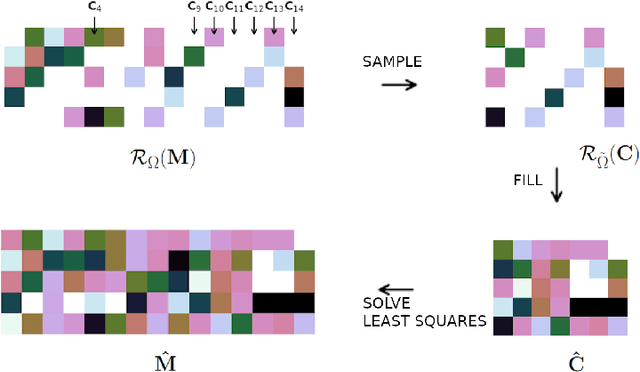
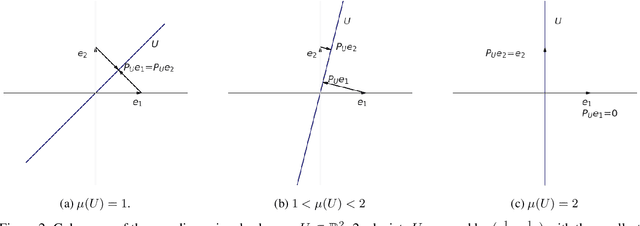
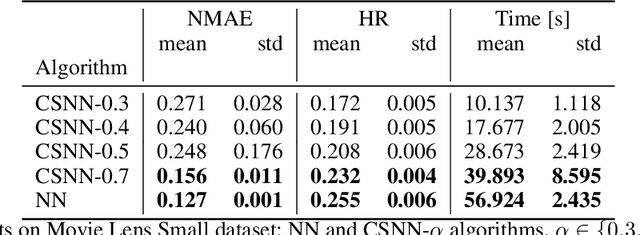
We introduce a two-step method for the matrix recovery problem. Our approach combines the theoretical foundations of the Column Subset Selection and Low-rank Matrix Completion problems. The proposed method, in each step, solves a convex optimization task. We present two algorithms that implement our Columns Selected Matrix Completion (CSMC) method, each dedicated to a different size problem. We performed a formal analysis of the presented method, in which we formulated the necessary assumptions and the probability of finding a correct solution. In the second part of the paper, we present the results of the experimental work. Numerical experiments verified the correctness and performance of the algorithms. To study the influence of the matrix size, rank, and the proportion of missing elements on the quality of the solution and the computation time, we performed experiments on synthetic data. The presented method was applied to two real-life problems problems: prediction of movie rates in a recommendation system and image inpainting. Our thorough analysis shows that CSMC provides solutions of comparable quality to matrix completion algorithms, which are based on convex optimization. However, CSMC offers notable savings in terms of runtime.
Enhancing Generalization in Medical Visual Question Answering Tasks via Gradient-Guided Model Perturbation
Mar 05, 2024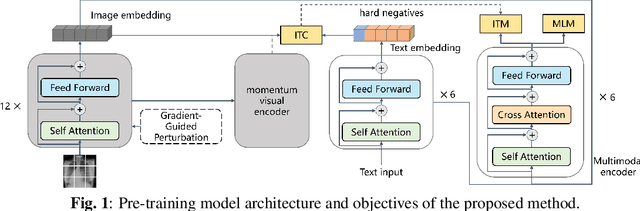
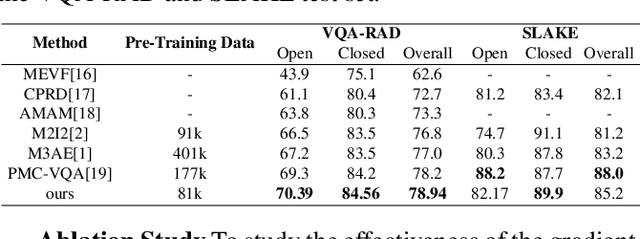
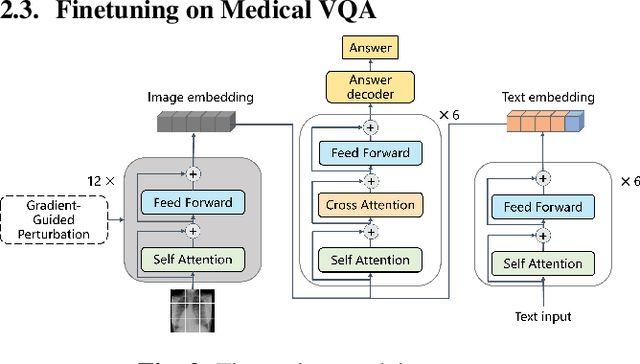
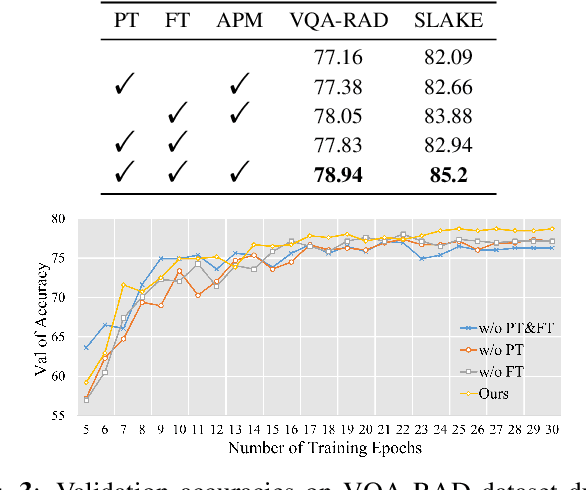
Leveraging pre-trained visual language models has become a widely adopted approach for improving performance in downstream visual question answering (VQA) applications. However, in the specialized field of medical VQA, the scarcity of available data poses a significant barrier to achieving reliable model generalization. Numerous methods have been proposed to enhance model generalization, addressing the issue from data-centric and model-centric perspectives. Data augmentation techniques are commonly employed to enrich the dataset, while various regularization approaches aim to prevent model overfitting, especially when training on limited data samples. In this paper, we introduce a method that incorporates gradient-guided parameter perturbations to the visual encoder of the multimodality model during both pre-training and fine-tuning phases, to improve model generalization for downstream medical VQA tasks. The small perturbation is adaptively generated by aligning with the direction of the moving average gradient in the optimization landscape, which is opposite to the directions of the optimizer's historical updates. It is subsequently injected into the model's visual encoder. The results show that, even with a significantly smaller pre-training image caption dataset, our approach achieves competitive outcomes on both VQA-RAD and SLAKE datasets.
Domain-Agnostic Mutual Prompting for Unsupervised Domain Adaptation
Mar 05, 2024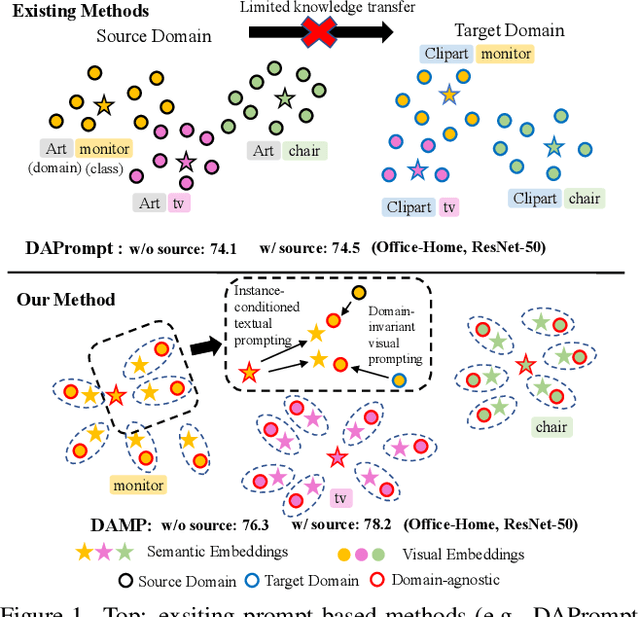
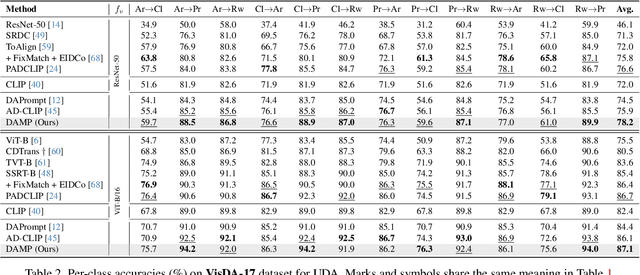
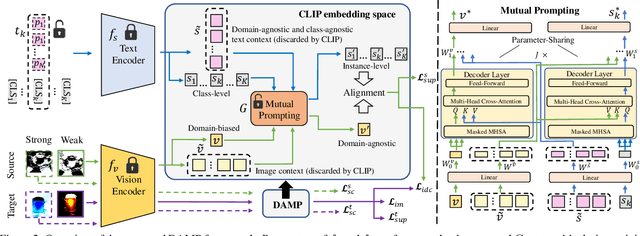
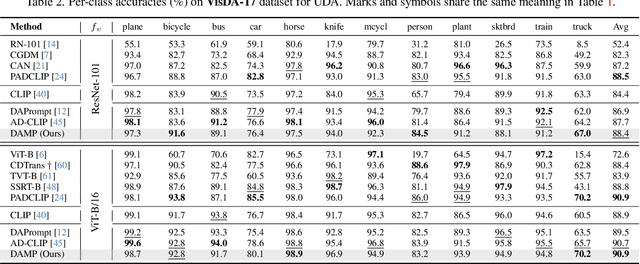
Conventional Unsupervised Domain Adaptation (UDA) strives to minimize distribution discrepancy between domains, which neglects to harness rich semantics from data and struggles to handle complex domain shifts. A promising technique is to leverage the knowledge of large-scale pre-trained vision-language models for more guided adaptation. Despite some endeavors, current methods often learn textual prompts to embed domain semantics for source and target domains separately and perform classification within each domain, limiting cross-domain knowledge transfer. Moreover, prompting only the language branch lacks flexibility to adapt both modalities dynamically. To bridge this gap, we propose Domain-Agnostic Mutual Prompting (DAMP) to exploit domain-invariant semantics by mutually aligning visual and textual embeddings. Specifically, the image contextual information is utilized to prompt the language branch in a domain-agnostic and instance-conditioned way. Meanwhile, visual prompts are imposed based on the domain-agnostic textual prompt to elicit domain-invariant visual embeddings. These two branches of prompts are learned mutually with a cross-attention module and regularized with a semantic-consistency loss and an instance-discrimination contrastive loss. Experiments on three UDA benchmarks demonstrate the superiority of DAMP over state-of-the-art approaches.
Behavior Generation with Latent Actions
Mar 05, 2024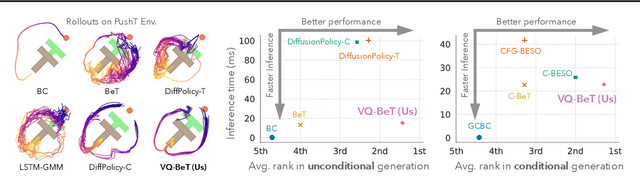
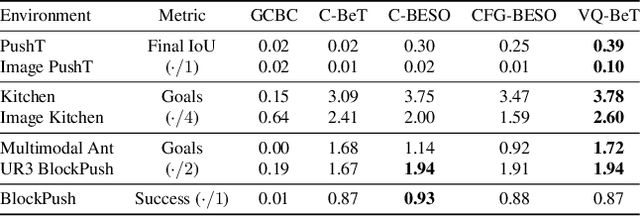
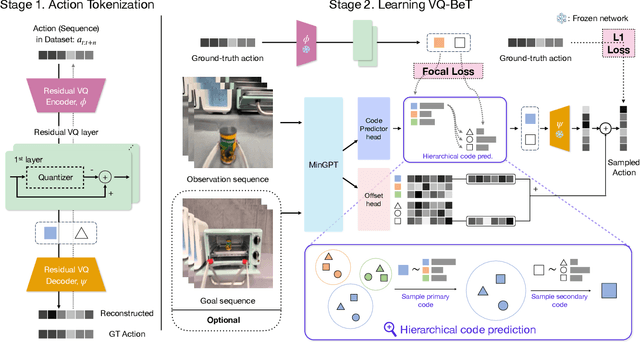
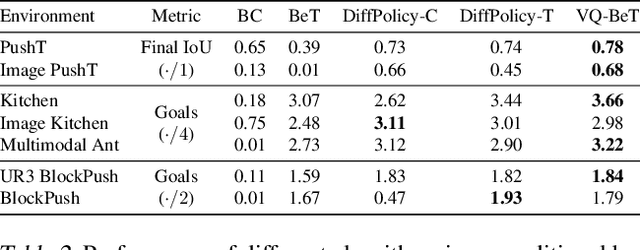
Generative modeling of complex behaviors from labeled datasets has been a longstanding problem in decision making. Unlike language or image generation, decision making requires modeling actions - continuous-valued vectors that are multimodal in their distribution, potentially drawn from uncurated sources, where generation errors can compound in sequential prediction. A recent class of models called Behavior Transformers (BeT) addresses this by discretizing actions using k-means clustering to capture different modes. However, k-means struggles to scale for high-dimensional action spaces or long sequences, and lacks gradient information, and thus BeT suffers in modeling long-range actions. In this work, we present Vector-Quantized Behavior Transformer (VQ-BeT), a versatile model for behavior generation that handles multimodal action prediction, conditional generation, and partial observations. VQ-BeT augments BeT by tokenizing continuous actions with a hierarchical vector quantization module. Across seven environments including simulated manipulation, autonomous driving, and robotics, VQ-BeT improves on state-of-the-art models such as BeT and Diffusion Policies. Importantly, we demonstrate VQ-BeT's improved ability to capture behavior modes while accelerating inference speed 5x over Diffusion Policies. Videos and code can be found https://sjlee.cc/vq-bet
Feast Your Eyes: Mixture-of-Resolution Adaptation for Multimodal Large Language Models
Mar 05, 2024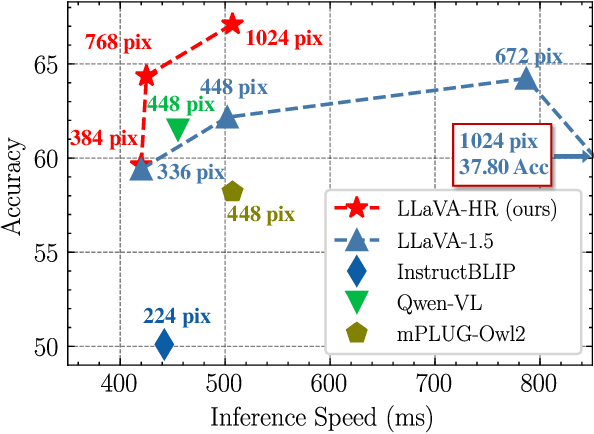
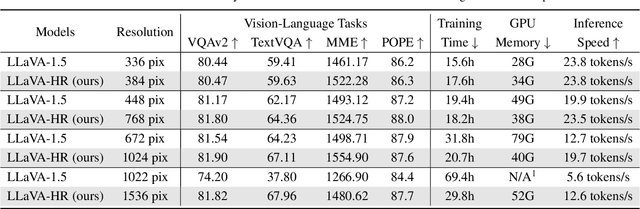
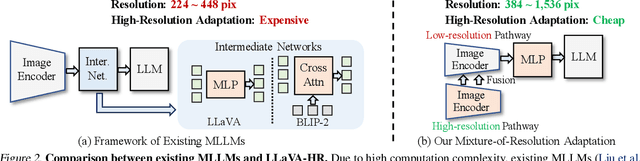
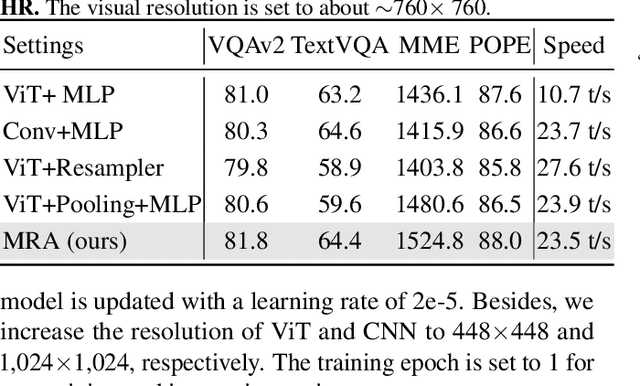
Despite remarkable progress, existing multimodal large language models (MLLMs) are still inferior in granular visual recognition. Contrary to previous works, we study this problem from the perspective of image resolution, and reveal that a combination of low- and high-resolution visual features can effectively mitigate this shortcoming. Based on this observation, we propose a novel and efficient method for MLLMs, termed Mixture-of-Resolution Adaptation (MRA). In particular, MRA adopts two visual pathways for images with different resolutions, where high-resolution visual information is embedded into the low-resolution pathway via the novel mixture-of-resolution adapters (MR-Adapters). This design also greatly reduces the input sequence length of MLLMs. To validate MRA, we apply it to a recent MLLM called LLaVA, and term the new model LLaVA-HR. We conduct extensive experiments on 11 vision-language (VL) tasks, which show that LLaVA-HR outperforms existing MLLMs on 8 VL tasks, e.g., +9.4% on TextVQA. More importantly, both training and inference of LLaVA-HR remain efficient with MRA, e.g., 20 training hours and 3$\times$ inference speed than LLaVA-1.5. Source codes are released at: https://github.com/luogen1996/LLaVA-HR.
Beyond Night Visibility: Adaptive Multi-Scale Fusion of Infrared and Visible Images
Mar 02, 2024
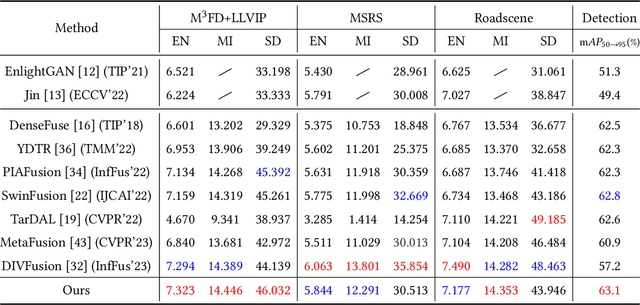
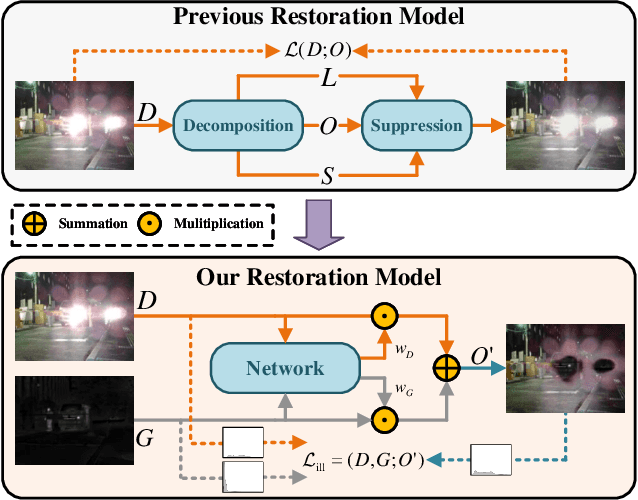
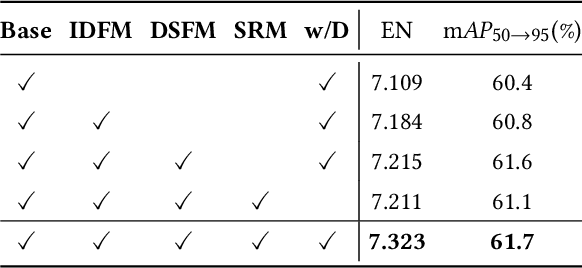
In addition to low light, night images suffer degradation from light effects (e.g., glare, floodlight, etc). However, existing nighttime visibility enhancement methods generally focus on low-light regions, which neglects, or even amplifies the light effects. To address this issue, we propose an Adaptive Multi-scale Fusion network (AMFusion) with infrared and visible images, which designs fusion rules according to different illumination regions. First, we separately fuse spatial and semantic features from infrared and visible images, where the former are used for the adjustment of light distribution and the latter are used for the improvement of detection accuracy. Thereby, we obtain an image free of low light and light effects, which improves the performance of nighttime object detection. Second, we utilize detection features extracted by a pre-trained backbone that guide the fusion of semantic features. Hereby, we design a Detection-guided Semantic Fusion Module (DSFM) to bridge the domain gap between detection and semantic features. Third, we propose a new illumination loss to constrain fusion image with normal light intensity. Experimental results demonstrate the superiority of AMFusion with better visual quality and detection accuracy. The source code will be released after the peer review process.
LDSF: Lightweight Dual-Stream Framework for SAR Target Recognition by Coupling Local Electromagnetic Scattering Features and Global Visual Features
Mar 06, 2024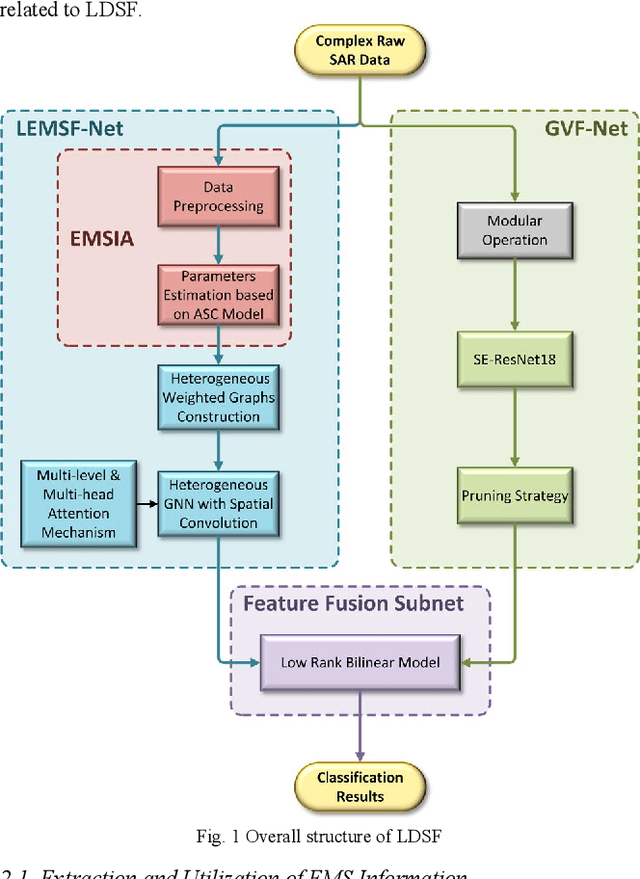

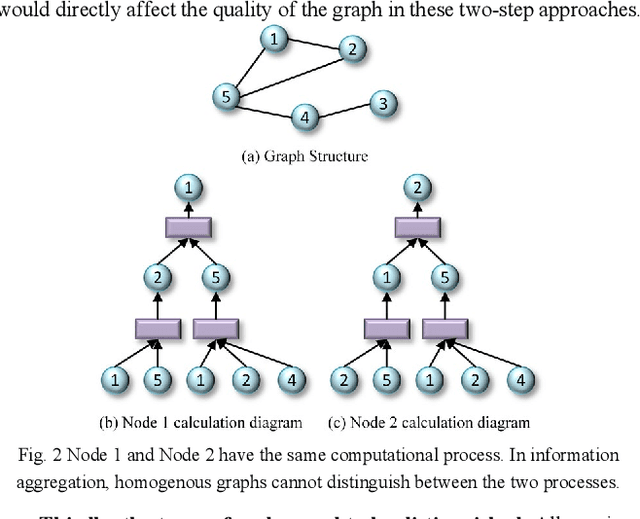
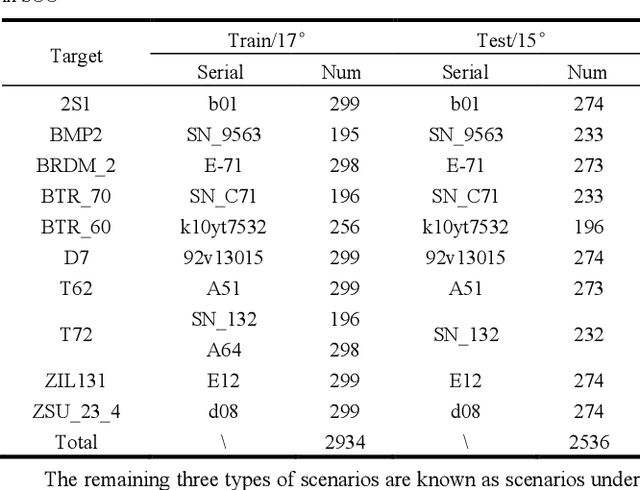
Mainstream DNN-based SAR-ATR methods still face issues such as easy overfitting of a few training data, high computational overhead, and poor interpretability of the black-box model. Integrating physical knowledge into DNNs to improve performance and achieve a higher level of physical interpretability becomes the key to solving the above problems. This paper begins by focusing on the electromagnetic (EM) backscattering mechanism. We extract the EM scattering (EMS) information from the complex SAR data and integrate the physical properties of the target into the network through a dual-stream framework to guide the network to learn physically meaningful and discriminative features. Specifically, one stream is the local EMS feature (LEMSF) extraction net. It is a heterogeneous graph neural network (GNN) guided by a multi-level multi-head attention mechanism. LEMSF uses the EMS information to obtain topological structure features and high-level physical semantic features. The other stream is a CNN-based global visual features (GVF) extraction net that captures the visual features of SAR pictures from the image domain. After obtaining the two-stream features, a feature fusion subnetwork is proposed to adaptively learn the fusion strategy. Thus, the two-stream features can maximize the performance. Furthermore, the loss function is designed based on the graph distance measure to promote intra-class aggregation. We discard overly complex design ideas and effectively control the model size while maintaining algorithm performance. Finally, to better validate the performance and generalizability of the algorithms, two more rigorous evaluation protocols, namely once-for-all (OFA) and less-for-more (LFM), are used to verify the superiority of the proposed algorithm on the MSTAR.
CAMixerSR: Only Details Need More "Attention"
Feb 29, 2024To satisfy the rapidly increasing demands on the large image (2K-8K) super-resolution (SR), prevailing methods follow two independent tracks: 1) accelerate existing networks by content-aware routing, and 2) design better super-resolution networks via token mixer refining. Despite directness, they encounter unavoidable defects (e.g., inflexible route or non-discriminative processing) limiting further improvements of quality-complexity trade-off. To erase the drawbacks, we integrate these schemes by proposing a content-aware mixer (CAMixer), which assigns convolution for simple contexts and additional deformable window-attention for sparse textures. Specifically, the CAMixer uses a learnable predictor to generate multiple bootstraps, including offsets for windows warping, a mask for classifying windows, and convolutional attentions for endowing convolution with the dynamic property, which modulates attention to include more useful textures self-adaptively and improves the representation capability of convolution. We further introduce a global classification loss to improve the accuracy of predictors. By simply stacking CAMixers, we obtain CAMixerSR which achieves superior performance on large-image SR, lightweight SR, and omnidirectional-image SR.