 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Iterative Scene Graph Generation
Jul 27, 2022
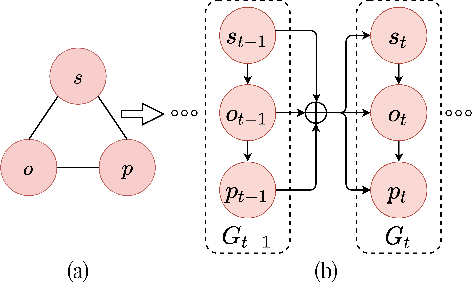
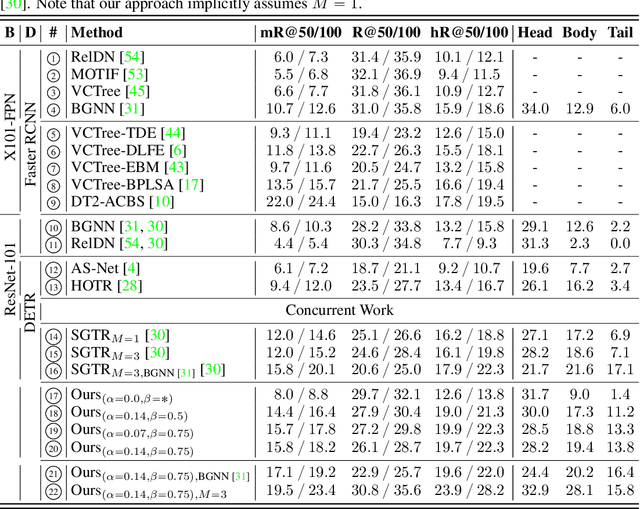
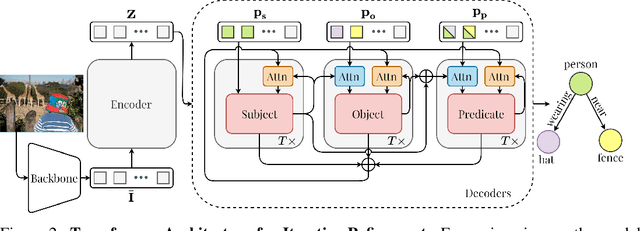
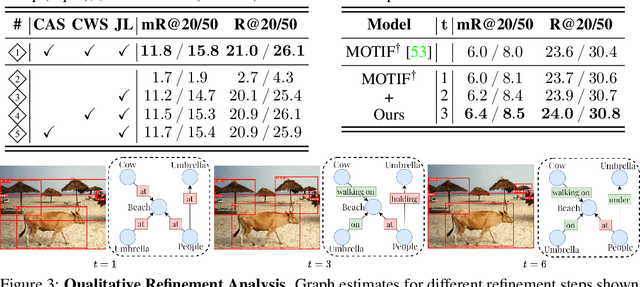
The task of scene graph generation entails identifying object entities and their corresponding interaction predicates in a given image (or video). Due to the combinatorially large solution space, existing approaches to scene graph generation assume certain factorization of the joint distribution to make the estimation feasible (e.g., assuming that objects are conditionally independent of predicate predictions). However, this fixed factorization is not ideal under all scenarios (e.g., for images where an object entailed in interaction is small and not discernible on its own). In this work, we propose a novel framework for scene graph generation that addresses this limitation, as well as introduces dynamic conditioning on the image, using message passing in a Markov Random Field. This is implemented as an iterative refinement procedure wherein each modification is conditioned on the graph generated in the previous iteration. This conditioning across refinement steps allows joint reasoning over entities and relations. This framework is realized via a novel and end-to-end trainable transformer-based architecture. In addition, the proposed framework can improve existing approach performance. Through extensive experiments on Visual Genome and Action Genome benchmark datasets we show improved performance on the scene graph generation.
Novel Deep Learning Approach to Derive Cytokeratin Expression and Epithelium Segmentation from DAPI
Aug 16, 2022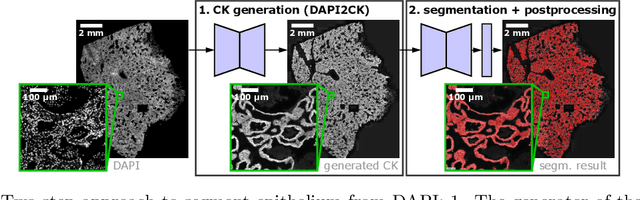

Generative Adversarial Networks (GANs) are state of the art for image synthesis. Here, we present dapi2ck, a novel GAN-based approach to synthesize cytokeratin (CK) staining from immunofluorescent (IF) DAPI staining of nuclei in non-small cell lung cancer (NSCLC) images. We use the synthetic CK to segment epithelial regions, which, compared to expert annotations, yield equally good results as segmentation on stained CK. Considering the limited number of markers in a multiplexed IF (mIF) panel, our approach allows to replace CK by another marker addressing the complexity of the tumor micro-environment (TME) to facilitate patient selection for immunotherapies. In contrast to stained CK, dapi2ck does not suffer from issues like unspecific CK staining or loss of tumoral CK expression.
Exploring Smoothness and Class-Separation for Semi-supervised Medical Image Segmentation
Mar 02, 2022
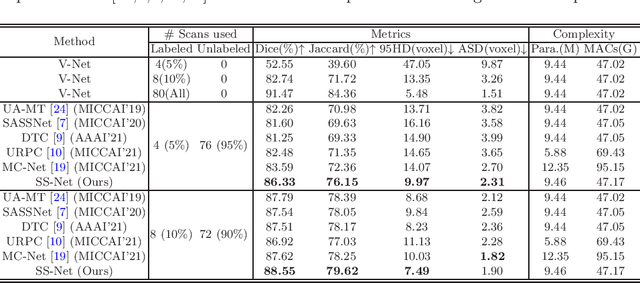
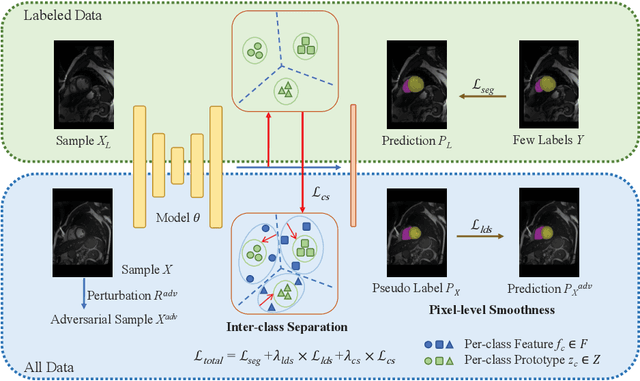
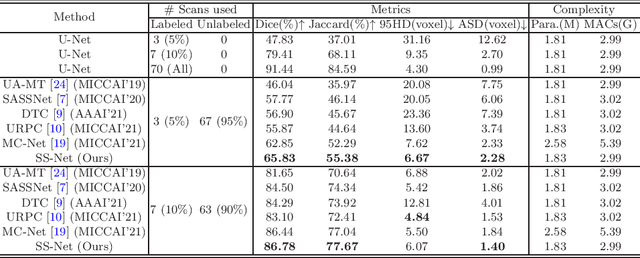
Semi-supervised segmentation remains challenging in medical imaging since the amount of annotated medical data is often limited and there are many blurred pixels near the adhesive edges or low-contrast regions. To address the issues, we advocate to firstly constrain the consistency of samples with and without strong perturbations to apply sufficient smoothness regularization and further encourage the class-level separation to exploit the unlabeled ambiguous pixels for the model training. Particularly, in this paper, we propose the SS-Net for semi-supervised medical image segmentation tasks, via exploring the pixel-level Smoothness and inter-class Separation at the same time. The pixel-level smoothness forces the model to generate invariant results under adversarial perturbations. Meanwhile, the inter-class separation constrains individual class features should approach their corresponding high-quality prototypes, in order to make each class distribution compact and separate different classes. We evaluated our SS-Net against five recent methods on the public LA and ACDC datasets. The experimental results under two semi-supervised settings demonstrate the superiority of our proposed SS-Net, achieving new state-of-the-art (SOTA) performance on both datasets. The codes will be released.
Learning Correspondency in Frequency Domain by a Latent-Space Similarity Loss for Multispectral Pansharpening
Jul 18, 2022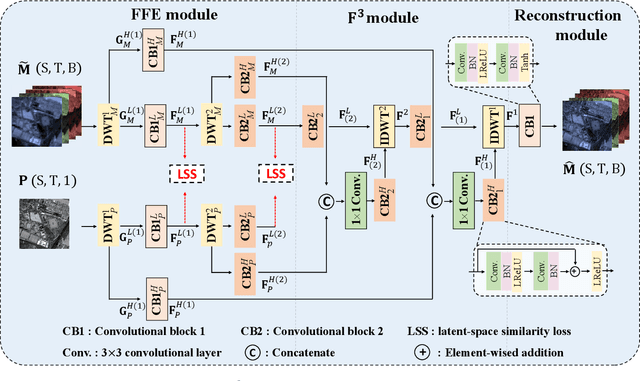


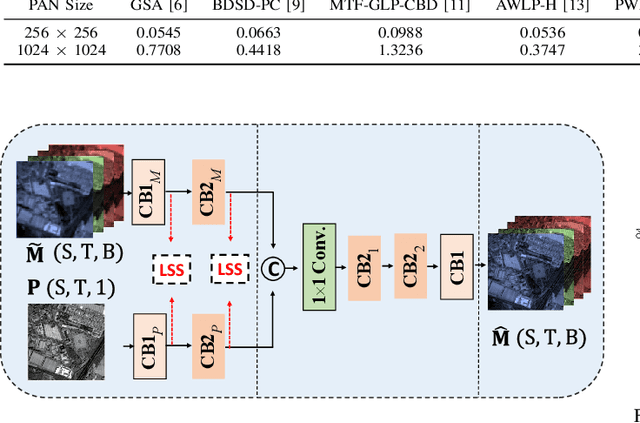
The process of fuse a high spatial resolution (HR) panchromatic (PAN) image and a low spatial resolution (LR) multispectral (MS) image to obtain an HRMS image is known as pansharpening. With the development of convolutional neural networks, the performance of pansharpening methods has been improved, however, the blurry effects and the spectral distortion still exist in their fusion results due to the insufficiency in details learning and the mismatch between the high-frequency (HF) and low-frequency (LF) components. Therefore, the improvements of spatial details at the premise of reducing spectral distortion is still a challenge. In this paper, we propose a frequency-aware network (FAN) together with a novel latent-space similarity loss to address above mentioned problems. FAN is composed of three modules, where the frequency feature extraction module aims to extract features in the frequency domain with the help of discrete wavelet transform (DWT) layers, and the inverse DWT (IDWT) layers are then utilized in the frequency feature fusion module to reconstruct the features. Finally, the fusion results are obtained through the reconstruction module. In order to learn the correspondency, we also propose a latent-space similarity loss to constrain the LF features derived from PAN and MS branches, so that HF features of PAN can reasonably be used to supplement that of MS. Experimental results on three datasets at both reduced- and full-resolution demonstrate the superiority of the proposed method compared with several state-of-the-art pansharpening models, especially for the fusion at full resolution.
A Deep Moving-camera Background Model
Sep 16, 2022
In video analysis, background models have many applications such as background/foreground separation, change detection, anomaly detection, tracking, and more. However, while learning such a model in a video captured by a static camera is a fairly-solved task, in the case of a Moving-camera Background Model (MCBM), the success has been far more modest due to algorithmic and scalability challenges that arise due to the camera motion. Thus, existing MCBMs are limited in their scope and their supported camera-motion types. These hurdles also impeded the employment, in this unsupervised task, of end-to-end solutions based on deep learning (DL). Moreover, existing MCBMs usually model the background either on the domain of a typically-large panoramic image or in an online fashion. Unfortunately, the former creates several problems, including poor scalability, while the latter prevents the recognition and leveraging of cases where the camera revisits previously-seen parts of the scene. This paper proposes a new method, called DeepMCBM, that eliminates all the aforementioned issues and achieves state-of-the-art results. Concretely, first we identify the difficulties associated with joint alignment of video frames in general and in a DL setting in particular. Next, we propose a new strategy for joint alignment that lets us use a spatial transformer net with neither a regularization nor any form of specialized (and non-differentiable) initialization. Coupled with an autoencoder conditioned on unwarped robust central moments (obtained from the joint alignment), this yields an end-to-end regularization-free MCBM that supports a broad range of camera motions and scales gracefully. We demonstrate DeepMCBM's utility on a variety of videos, including ones beyond the scope of other methods. Our code is available at https://github.com/BGU-CS-VIL/DeepMCBM .
Deep-Learning-Based Single-Image Height Reconstruction from Very-High-Resolution SAR Intensity Data
Nov 19, 2021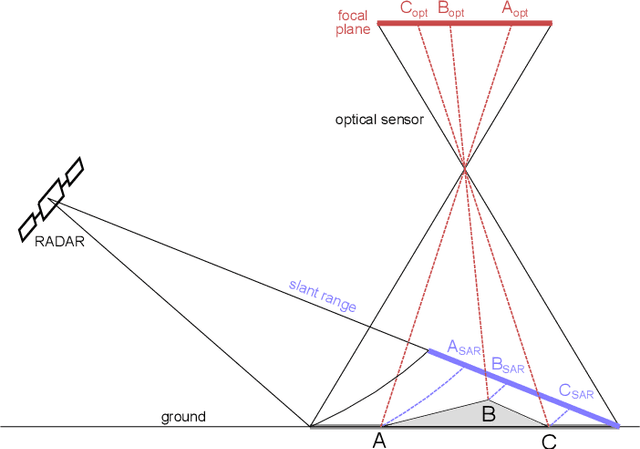
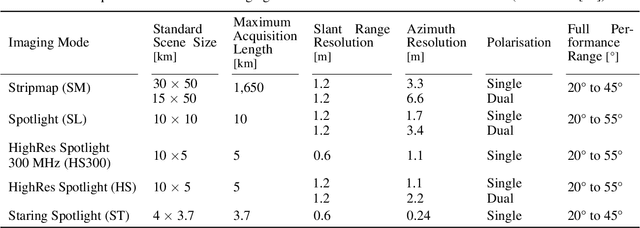
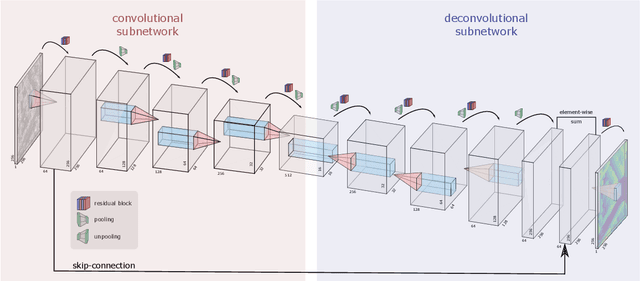
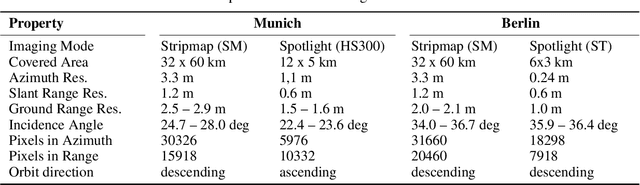
Originally developed in fields such as robotics and autonomous driving with image-based navigation in mind, deep learning-based single-image depth estimation (SIDE) has found great interest in the wider image analysis community. Remote sensing is no exception, as the possibility to estimate height maps from single aerial or satellite imagery bears great potential in the context of topographic reconstruction. A few pioneering investigations have demonstrated the general feasibility of single image height prediction from optical remote sensing images and motivate further studies in that direction. With this paper, we present the first-ever demonstration of deep learning-based single image height prediction for the other important sensor modality in remote sensing: synthetic aperture radar (SAR) data. Besides the adaptation of a convolutional neural network (CNN) architecture for SAR intensity images, we present a workflow for the generation of training data, and extensive experimental results for different SAR imaging modes and test sites. Since we put a particular emphasis on transferability, we are able to confirm that deep learning-based single-image height estimation is not only possible, but also transfers quite well to unseen data, even if acquired by different imaging modes and imaging parameters.
Back to the Basics: Revisiting Out-of-Distribution Detection Baselines
Jul 07, 2022


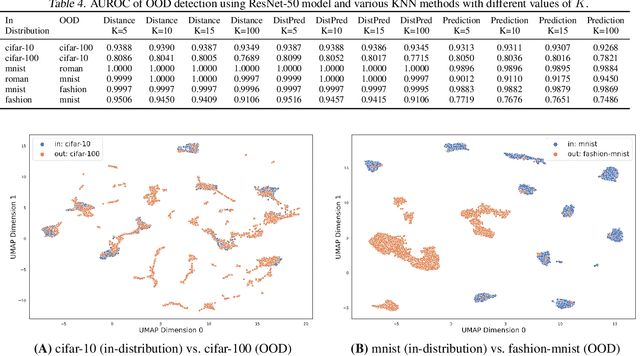
We study simple methods for out-of-distribution (OOD) image detection that are compatible with any already trained classifier, relying on only its predictions or learned representations. Evaluating the OOD detection performance of various methods when utilized with ResNet-50 and Swin Transformer models, we find methods that solely consider the model's predictions can be easily outperformed by also considering the learned representations. Based on our analysis, we advocate for a dead-simple approach that has been neglected in other studies: simply flag as OOD images whose average distance to their K nearest neighbors is large (in the representation space of an image classifier trained on the in-distribution data).
Implicit Neural Representation Learning for Hyperspectral Image Super-Resolution
Dec 20, 2021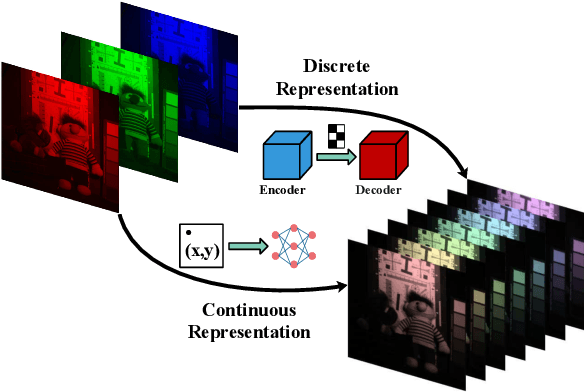
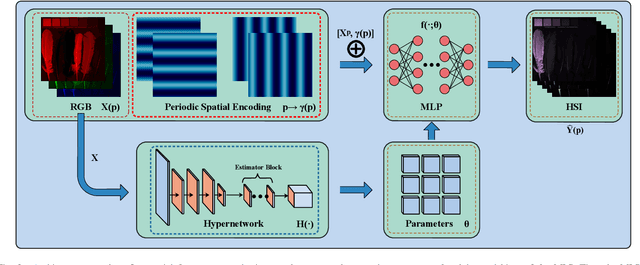
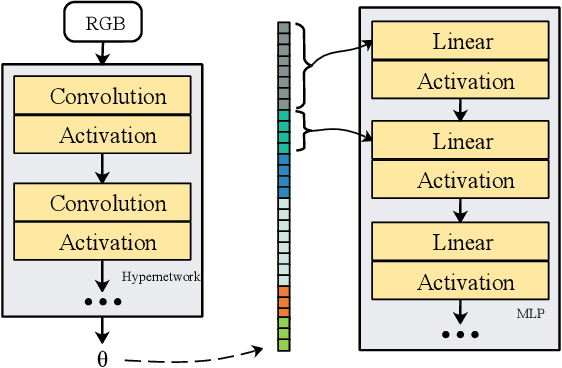
Hyperspectral image (HSI) super-resolution without additional auxiliary image remains a constant challenge due to its high-dimensional spectral patterns, where learning an effective spatial and spectral representation is a fundamental issue. Recently, Implicit Neural Representations (INRs) are making strides as a novel and effective representation, especially in the reconstruction task. Therefore, in this work, we propose a novel HSI reconstruction model based on INR which represents HSI by a continuous function mapping a spatial coordinate to its corresponding spectral radiance values. In particular, as a specific implementation of INR, the parameters of parametric model are predicted by a hypernetwork that operates on feature extraction using convolution network. It makes the continuous functions map the spatial coordinates to pixel values in a content-aware manner. Moreover, periodic spatial encoding are deeply integrated with the reconstruction procedure, which makes our model capable of recovering more high frequency details. To verify the efficacy of our model, we conduct experiments on three HSI datasets (CAVE, NUS, and NTIRE2018). Experimental results show that the proposed model can achieve competitive reconstruction performance in comparison with the state-of-the-art methods. In addition, we provide an ablation study on the effect of individual components of our model. We hope this paper could server as a potent reference for future research.
SeasoNet: A Seasonal Scene Classification, segmentation and Retrieval dataset for satellite Imagery over Germany
Jul 19, 2022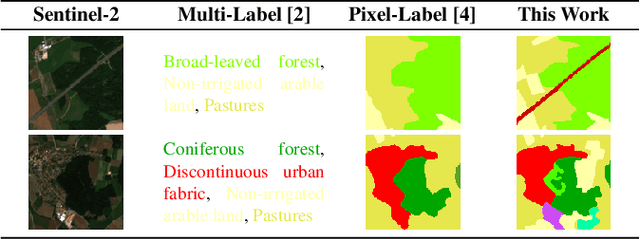
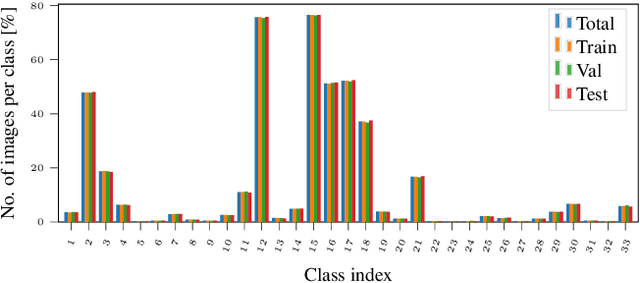
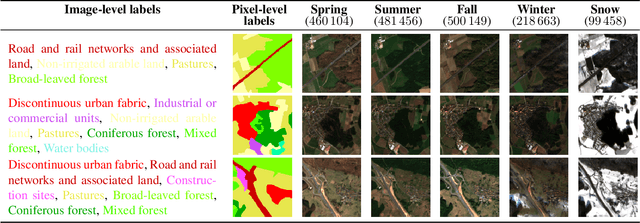
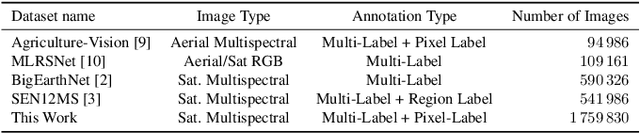
This work presents SeasoNet, a new large-scale multi-label land cover and land use scene understanding dataset. It includes $1\,759\,830$ images from Sentinel-2 tiles, with 12 spectral bands and patch sizes of up to $ 120 \ \mathrm{px} \times 120 \ \mathrm{px}$. Each image is annotated with large scale pixel level labels from the German land cover model LBM-DE2018 with land cover classes based on the CORINE Land Cover database (CLC) 2018 and a five times smaller minimum mapping unit (MMU) than the original CLC maps. We provide pixel synchronous examples from all four seasons, plus an additional snowy set. These properties make SeasoNet the currently most versatile and biggest remote sensing scene understanding dataset with possible applications ranging from scene classification over land cover mapping to content-based cross season image retrieval and self-supervised feature learning. We provide baseline results by evaluating state-of-the-art deep networks on the new dataset in scene classification and semantic segmentation scenarios.
Accelerating Score-based Generative Models with Preconditioned Diffusion Sampling
Jul 19, 2022


Score-based generative models (SGMs) have recently emerged as a promising class of generative models. However, a fundamental limitation is that their inference is very slow due to a need for many (e.g., 2000) iterations of sequential computations. An intuitive acceleration method is to reduce the sampling iterations which however causes severe performance degradation. We investigate this problem by viewing the diffusion sampling process as a Metropolis adjusted Langevin algorithm, which helps reveal the underlying cause to be ill-conditioned curvature. Under this insight, we propose a model-agnostic preconditioned diffusion sampling (PDS) method that leverages matrix preconditioning to alleviate the aforementioned problem. Crucially, PDS is proven theoretically to converge to the original target distribution of a SGM, no need for retraining. Extensive experiments on three image datasets with a variety of resolutions and diversity validate that PDS consistently accelerates off-the-shelf SGMs whilst maintaining the synthesis quality. In particular, PDS can accelerate by up to 29x on more challenging high resolution (1024x1024) image generation.