 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Gated SwitchGAN for multi-domain facial image translation
Nov 28, 2021
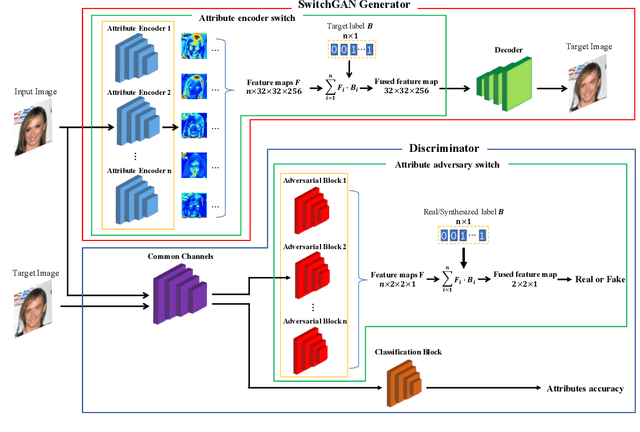


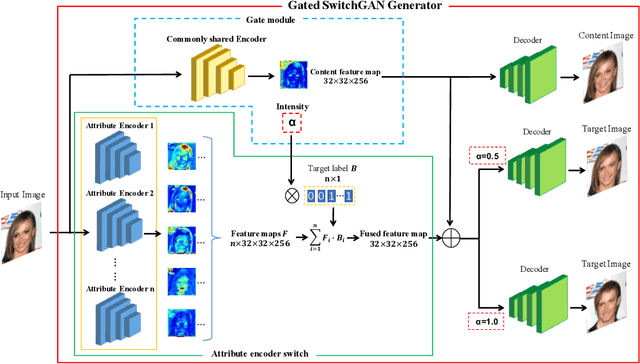
Recent studies on multi-domain facial image translation have achieved impressive results. The existing methods generally provide a discriminator with an auxiliary classifier to impose domain translation. However, these methods neglect important information regarding domain distribution matching. To solve this problem, we propose a switch generative adversarial network (SwitchGAN) with a more adaptive discriminator structure and a matched generator to perform delicate image translation among multiple domains. A feature-switching operation is proposed to achieve feature selection and fusion in our conditional modules. We demonstrate the effectiveness of our model. Furthermore, we also introduce a new capability of our generator that represents attribute intensity control and extracts content information without tailored training. Experiments on the Morph, RaFD and CelebA databases visually and quantitatively show that our extended SwitchGAN (i.e., Gated SwitchGAN) can achieve better translation results than StarGAN, AttGAN and STGAN. The attribute classification accuracy achieved using the trained ResNet-18 model and the FID score obtained using the ImageNet pretrained Inception-v3 model also quantitatively demonstrate the superior performance of our models.
A Survey on Adversarial Image Synthesis
Jun 30, 2021Generative Adversarial Networks (GANs) have been extremely successful in various application domains. Adversarial image synthesis has drawn increasing attention and made tremendous progress in recent years because of its wide range of applications in many computer vision and image processing problems. Among the many applications of GAN, image synthesis is the most well-studied one, and research in this area has already demonstrated the great potential of using GAN in image synthesis. In this paper, we provide a taxonomy of methods used in image synthesis, review different models for text-to-image synthesis and image-to-image translation, and discuss some evaluation metrics as well as possible future research directions in image synthesis with GAN.
Semantic uncertainty intervals for disentangled latent spaces
Jul 20, 2022

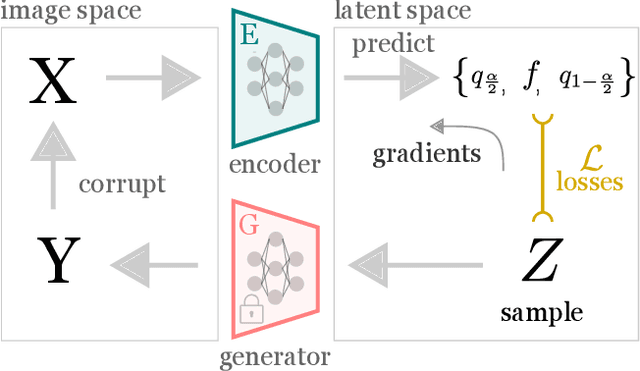
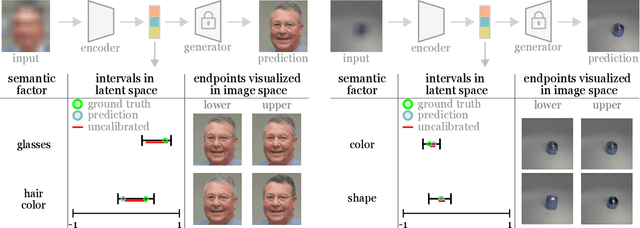
Meaningful uncertainty quantification in computer vision requires reasoning about semantic information -- say, the hair color of the person in a photo or the location of a car on the street. To this end, recent breakthroughs in generative modeling allow us to represent semantic information in disentangled latent spaces, but providing uncertainties on the semantic latent variables has remained challenging. In this work, we provide principled uncertainty intervals that are guaranteed to contain the true semantic factors for any underlying generative model. The method does the following: (1) it uses quantile regression to output a heuristic uncertainty interval for each element in the latent space (2) calibrates these uncertainties such that they contain the true value of the latent for a new, unseen input. The endpoints of these calibrated intervals can then be propagated through the generator to produce interpretable uncertainty visualizations for each semantic factor. This technique reliably communicates semantically meaningful, principled, and instance-adaptive uncertainty in inverse problems like image super-resolution and image completion.
Label Propagation for 3D Carotid Vessel Wall Segmentation and Atherosclerosis Diagnosis
Aug 29, 2022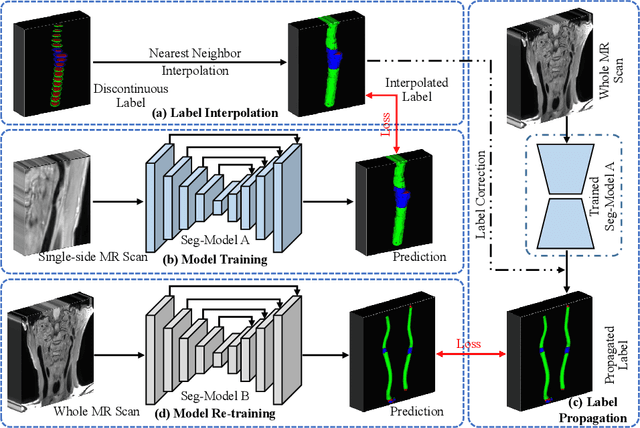
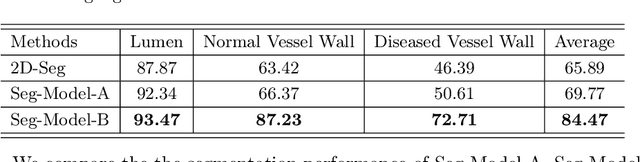
Carotid vessel wall segmentation is a crucial yet challenging task in the computer-aided diagnosis of atherosclerosis. Although numerous deep learning models have achieved remarkable success in many medical image segmentation tasks, accurate segmentation of carotid vessel wall on magnetic resonance (MR) images remains challenging, due to limited annotations and heterogeneous arteries. In this paper, we propose a semi-supervised label propagation framework to segment lumen, normal vessel walls, and atherosclerotic vessel wall on 3D MR images. By interpolating the provided annotations, we get 3D continuous labels for training 3D segmentation model. With the trained model, we generate pseudo labels for unlabeled slices to incorporate them for model training. Then we use the whole MR scans and the propagated labels to re-train the segmentation model and improve its robustness. We evaluated the label propagation framework on the CarOtid vessel wall SegMentation and atherosclerOsis diagnosiS (COSMOS) Challenge dataset and achieved a QuanM score of 83.41\% on the testing dataset, which got the 1-st place on the online evaluation leaderboard. The results demonstrate the effectiveness of the proposed framework.
RFormer: Transformer-based Generative Adversarial Network for Real Fundus Image Restoration on A New Clinical Benchmark
Jan 03, 2022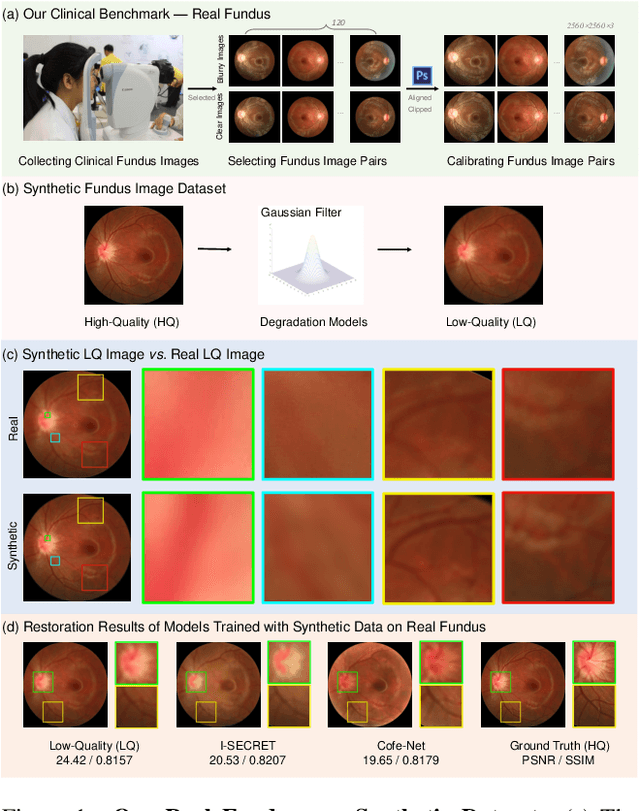
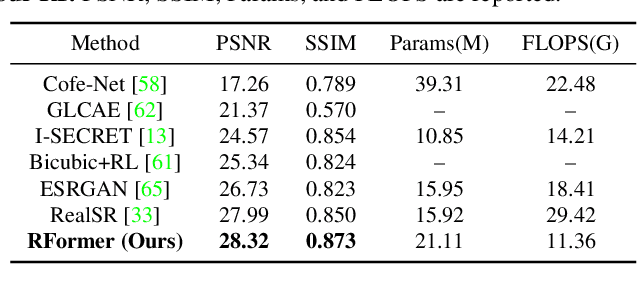
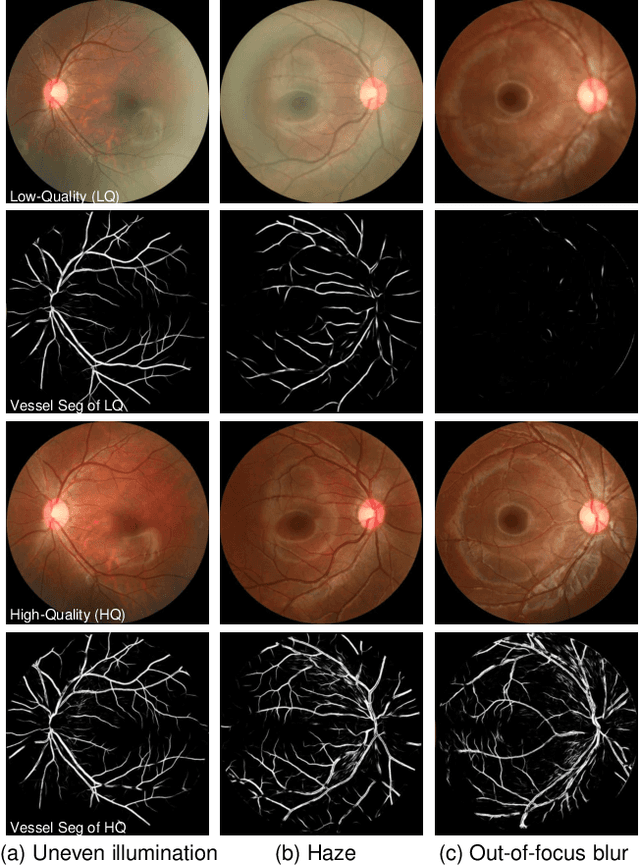
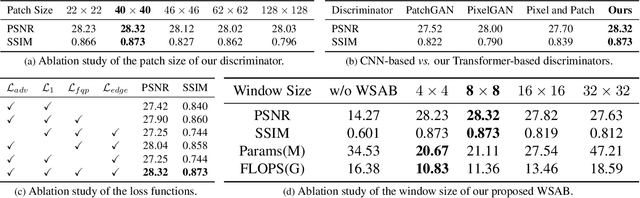
Ophthalmologists have used fundus images to screen and diagnose eye diseases. However, different equipments and ophthalmologists pose large variations to the quality of fundus images. Low-quality (LQ) degraded fundus images easily lead to uncertainty in clinical screening and generally increase the risk of misdiagnosis. Thus, real fundus image restoration is worth studying. Unfortunately, real clinical benchmark has not been explored for this task so far. In this paper, we investigate the real clinical fundus image restoration problem. Firstly, We establish a clinical dataset, Real Fundus (RF), including 120 low- and high-quality (HQ) image pairs. Then we propose a novel Transformer-based Generative Adversarial Network (RFormer) to restore the real degradation of clinical fundus images. The key component in our network is the Window-based Self-Attention Block (WSAB) which captures non-local self-similarity and long-range dependencies. To produce more visually pleasant results, a Transformer-based discriminator is introduced. Extensive experiments on our clinical benchmark show that the proposed RFormer significantly outperforms the state-of-the-art (SOTA) methods. In addition, experiments of downstream tasks such as vessel segmentation and optic disc/cup detection demonstrate that our proposed RFormer benefits clinical fundus image analysis and applications. The dataset, code, and models will be released.
Self-supervised Learning with Local Contrastive Loss for Detection and Semantic Segmentation
Jul 10, 2022
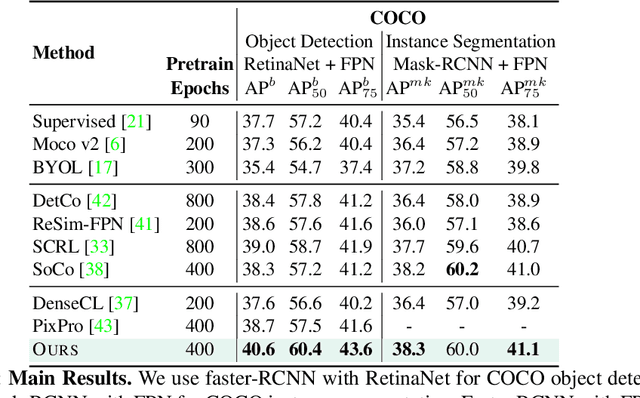
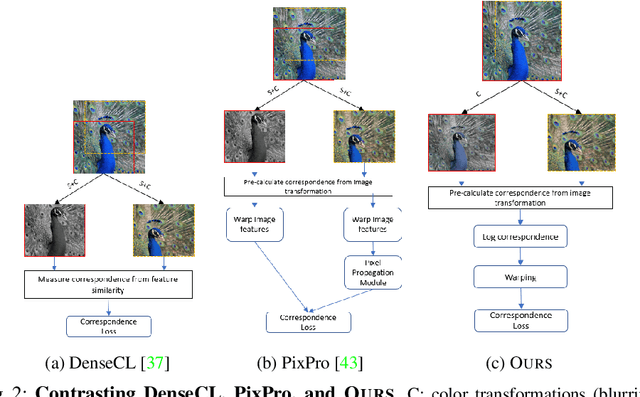
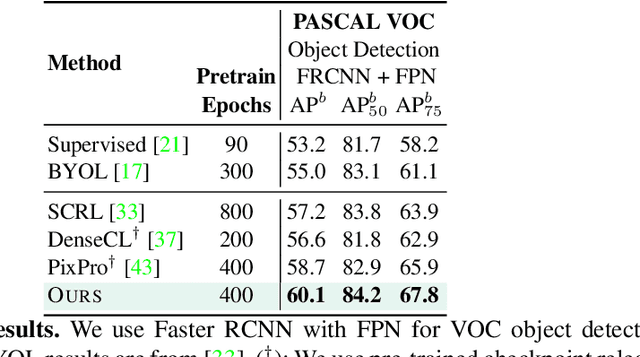
We present a self-supervised learning (SSL) method suitable for semi-global tasks such as object detection and semantic segmentation. We enforce local consistency between self-learned features, representing corresponding image locations of transformed versions of the same image, by minimizing a pixel-level local contrastive (LC) loss during training. LC-loss can be added to existing self-supervised learning methods with minimal overhead. We evaluate our SSL approach on two downstream tasks -- object detection and semantic segmentation, using COCO, PASCAL VOC, and CityScapes datasets. Our method outperforms the existing state-of-the-art SSL approaches by 1.9% on COCO object detection, 1.4% on PASCAL VOC detection, and 0.6% on CityScapes segmentation.
Fully Convolutional Cross-Scale-Flows for Image-based Defect Detection
Oct 06, 2021
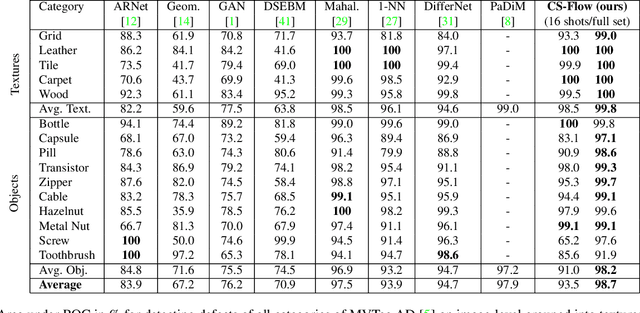
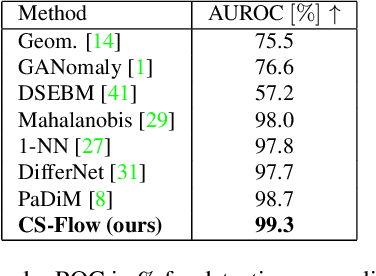
In industrial manufacturing processes, errors frequently occur at unpredictable times and in unknown manifestations. We tackle the problem of automatic defect detection without requiring any image samples of defective parts. Recent works model the distribution of defect-free image data, using either strong statistical priors or overly simplified data representations. In contrast, our approach handles fine-grained representations incorporating the global and local image context while flexibly estimating the density. To this end, we propose a novel fully convolutional cross-scale normalizing flow (CS-Flow) that jointly processes multiple feature maps of different scales. Using normalizing flows to assign meaningful likelihoods to input samples allows for efficient defect detection on image-level. Moreover, due to the preserved spatial arrangement the latent space of the normalizing flow is interpretable which enables to localize defective regions in the image. Our work sets a new state-of-the-art in image-level defect detection on the benchmark datasets Magnetic Tile Defects and MVTec AD showing a 100% AUROC on 4 out of 15 classes.
Generalization in Neural Networks: A Broad Survey
Sep 04, 2022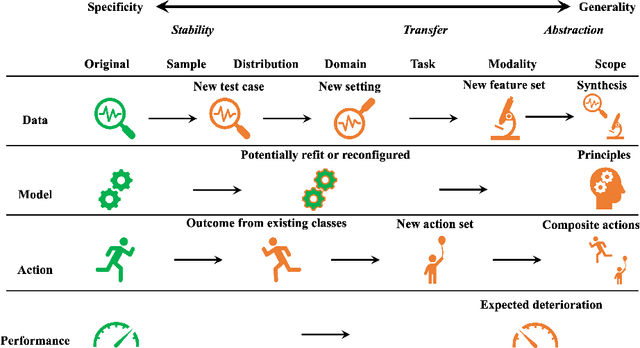
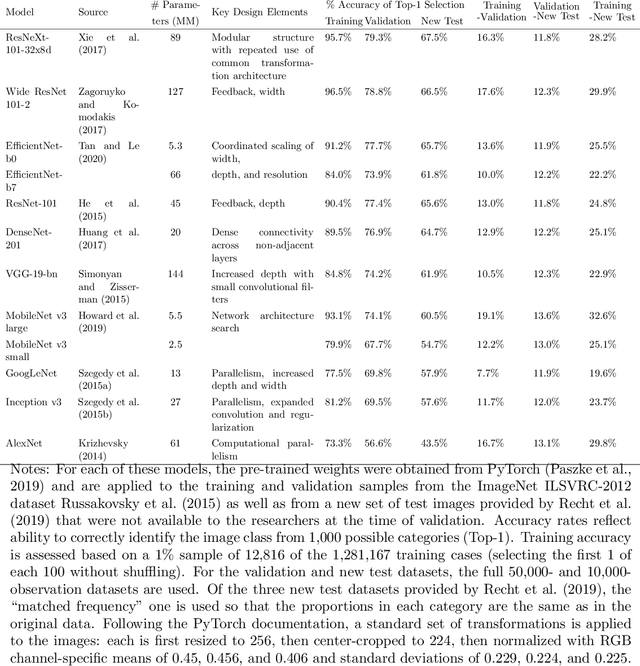
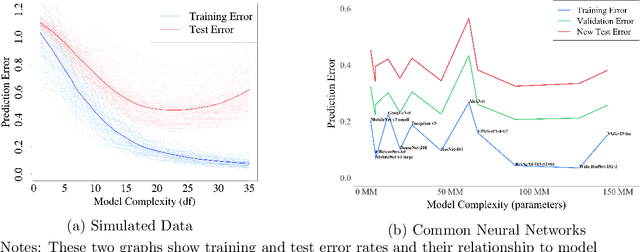
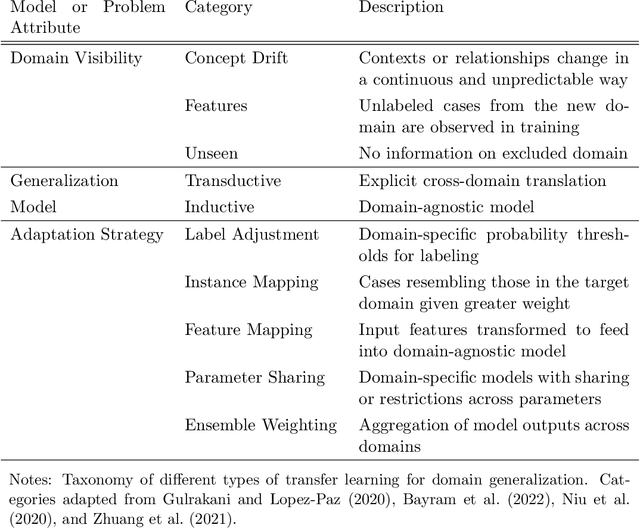
This paper reviews concepts, modeling approaches, and recent findings along a spectrum of different levels of abstraction of neural network models including generalization across (1) Samples, (2) Distributions, (3) Domains, (4) Tasks, (5) Modalities, and (6) Scopes. Results on (1) sample generalization show that, in the case of ImageNet, nearly all the recent improvements reduced training error while overfitting stayed flat; with nearly all the training error eliminated, future progress will require a focus on reducing overfitting. Perspectives from statistics highlight how (2) distribution generalization can be viewed alternately as a change in sample weights or a change in the input-output relationship. Transfer learning approaches to (3) domain generalization are summarized, as are recent advances and the wealth of domain adaptation benchmark datasets available. Recent breakthroughs surveyed in (4) task generalization include few-shot meta-learning approaches and the BERT NLP engine, and recent (5) modality generalization studies are discussed that integrate image and text data and that apply a biologically-inspired network across olfactory, visual, and auditory modalities. Recent (6) scope generalization results are reviewed that embed knowledge graphs into deep NLP approaches. Additionally, concepts from neuroscience are discussed on the modular architecture of brains and the steps by which dopamine-driven conditioning leads to abstract thinking.
3d sequential image mosaicing for underwater navigation and mapping
Oct 04, 2021
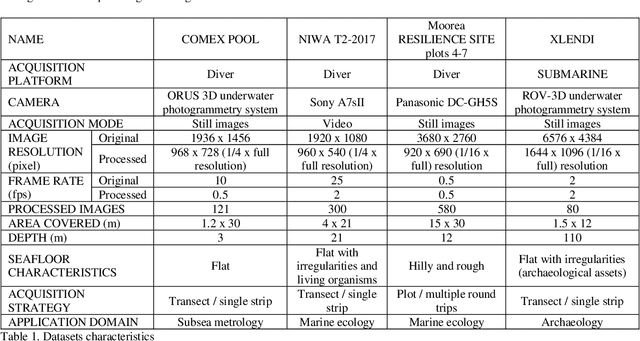
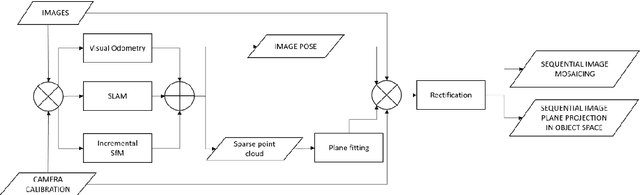

Although fully autonomous mapping methods are becoming more and more common and reliable, still the human operator is regularly employed in many 3D surveying missions. In a number of underwater applications, divers or pilots of remotely operated vehicles (ROVs) are still considered irreplaceable, and tools for real-time visualization of the mapped scene are essential to support and maximize the navigation and surveying efforts. For underwater exploration, image mosaicing has proved to be a valid and effective approach to visualize large mapped areas, often employed in conjunction with autonomous underwater vehicles (AUVs) and ROVs. In this work, we propose the use of a modified image mosaicing algorithm that coupled with image-based real-time navigation and mapping algorithms provides two visual navigation aids. The first is a classic image mosaic, where the recorded and processed images are incrementally added, named 2D sequential image mosaicing (2DSIM). The second one geometrically transform the images so that they are projected as planar point clouds in the 3D space providing an incremental point cloud mosaicing, named 3D sequential image plane projection (3DSIP). In the paper, the implemented procedure is detailed, and experiments in different underwater scenarios presented and discussed. Technical considerations about computational efforts, frame rate capabilities and scalability to different and more compact architectures (i.e. embedded systems) is also provided.
Disentangled Representation Learning Using ($β$-)VAE and GAN
Aug 09, 2022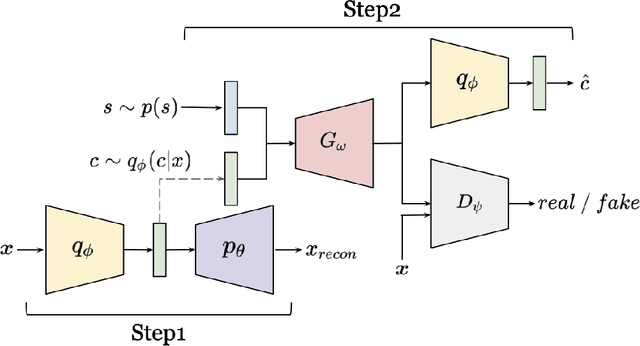



Given a dataset of images containing different objects with different features such as shape, size, rotation, and x-y position; and a Variational Autoencoder (VAE); creating a disentangled encoding of these features in the hidden space vector of the VAE was the task of interest in this paper. The dSprite dataset provided the desired features for the required experiments in this research. After training the VAE combined with a Generative Adversarial Network (GAN), each dimension of the hidden vector was disrupted to explore the disentanglement in each dimension. Note that the GAN was used to improve the quality of output image reconstruction.