 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
OmniCity: Omnipotent City Understanding with Multi-level and Multi-view Images
Aug 04, 2022
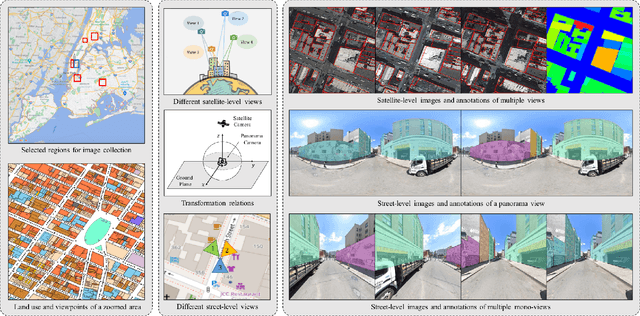
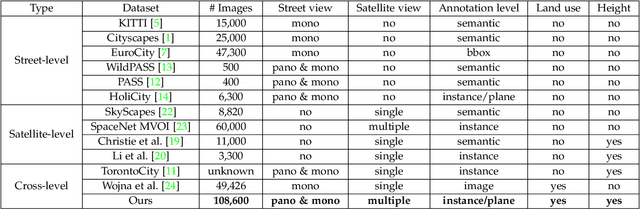
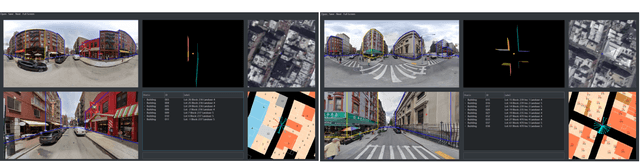

This paper presents OmniCity, a new dataset for omnipotent city understanding from multi-level and multi-view images. More precisely, the OmniCity contains multi-view satellite images as well as street-level panorama and mono-view images, constituting over 100K pixel-wise annotated images that are well-aligned and collected from 25K geo-locations in New York City. To alleviate the substantial pixel-wise annotation efforts, we propose an efficient street-view image annotation pipeline that leverages the existing label maps of satellite view and the transformation relations between different views (satellite, panorama, and mono-view). With the new OmniCity dataset, we provide benchmarks for a variety of tasks including building footprint extraction, height estimation, and building plane/instance/fine-grained segmentation. Compared with the existing multi-level and multi-view benchmarks, OmniCity contains a larger number of images with richer annotation types and more views, provides more benchmark results of state-of-the-art models, and introduces a novel task for fine-grained building instance segmentation on street-level panorama images. Moreover, OmniCity provides new problem settings for existing tasks, such as cross-view image matching, synthesis, segmentation, detection, etc., and facilitates the developing of new methods for large-scale city understanding, reconstruction, and simulation. The OmniCity dataset as well as the benchmarks will be available at https://city-super.github.io/omnicity.
Transformers in Remote Sensing: A Survey
Sep 02, 2022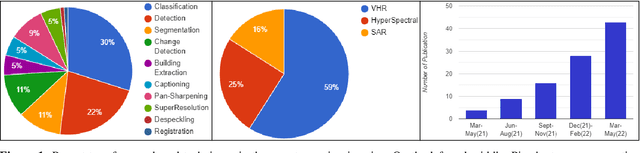
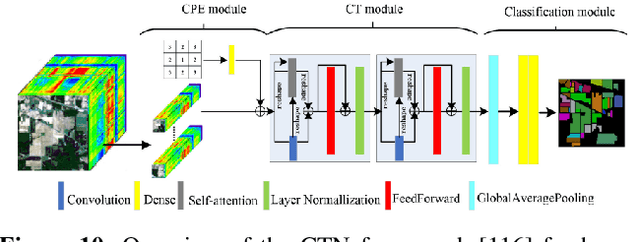
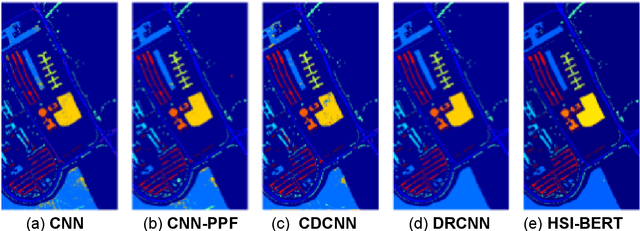
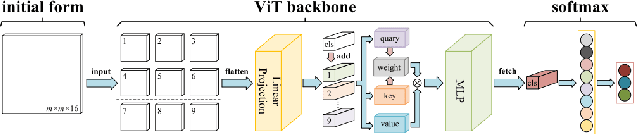
Deep learning-based algorithms have seen a massive popularity in different areas of remote sensing image analysis over the past decade. Recently, transformers-based architectures, originally introduced in natural language processing, have pervaded computer vision field where the self-attention mechanism has been utilized as a replacement to the popular convolution operator for capturing long-range dependencies. Inspired by recent advances in computer vision, remote sensing community has also witnessed an increased exploration of vision transformers for a diverse set of tasks. Although a number of surveys have focused on transformers in computer vision in general, to the best of our knowledge we are the first to present a systematic review of recent advances based on transformers in remote sensing. Our survey covers more than 60 recent transformers-based methods for different remote sensing problems in sub-areas of remote sensing: very high-resolution (VHR), hyperspectral (HSI) and synthetic aperture radar (SAR) imagery. We conclude the survey by discussing different challenges and open issues of transformers in remote sensing. Additionally, we intend to frequently update and maintain the latest transformers in remote sensing papers with their respective code at: https://github.com/VIROBO-15/Transformer-in-Remote-Sensing
Learning Modal-Invariant and Temporal-Memory for Video-based Visible-Infrared Person Re-Identification
Aug 04, 2022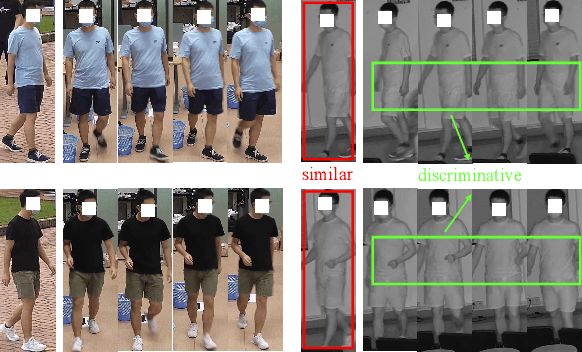


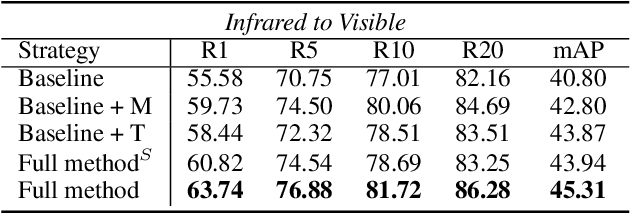
Thanks for the cross-modal retrieval techniques, visible-infrared (RGB-IR) person re-identification (Re-ID) is achieved by projecting them into a common space, allowing person Re-ID in 24-hour surveillance systems. However, with respect to the probe-to-gallery, almost all existing RGB-IR based cross-modal person Re-ID methods focus on image-to-image matching, while the video-to-video matching which contains much richer spatial- and temporal-information remains under-explored. In this paper, we primarily study the video-based cross-modal person Re-ID method. To achieve this task, a video-based RGB-IR dataset is constructed, in which 927 valid identities with 463,259 frames and 21,863 tracklets captured by 12 RGB/IR cameras are collected. Based on our constructed dataset, we prove that with the increase of frames in a tracklet, the performance does meet more enhancement, demonstrating the significance of video-to-video matching in RGB-IR person Re-ID. Additionally, a novel method is further proposed, which not only projects two modalities to a modal-invariant subspace, but also extracts the temporal-memory for motion-invariant. Thanks to these two strategies, much better results are achieved on our video-based cross-modal person Re-ID. The code and dataset are released at: https://github.com/VCMproject233/MITML.
SOFFLFM: Super-resolution optical fluctuation Fourier light-field microscopy
Aug 26, 2022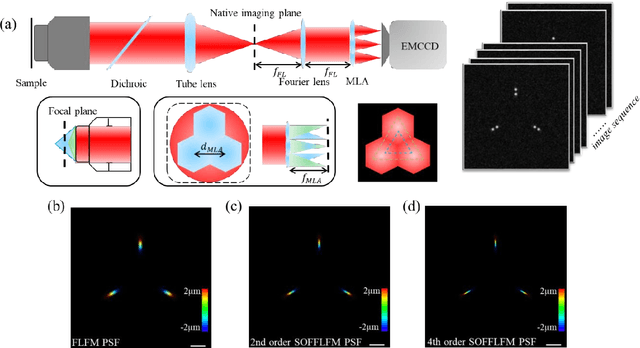

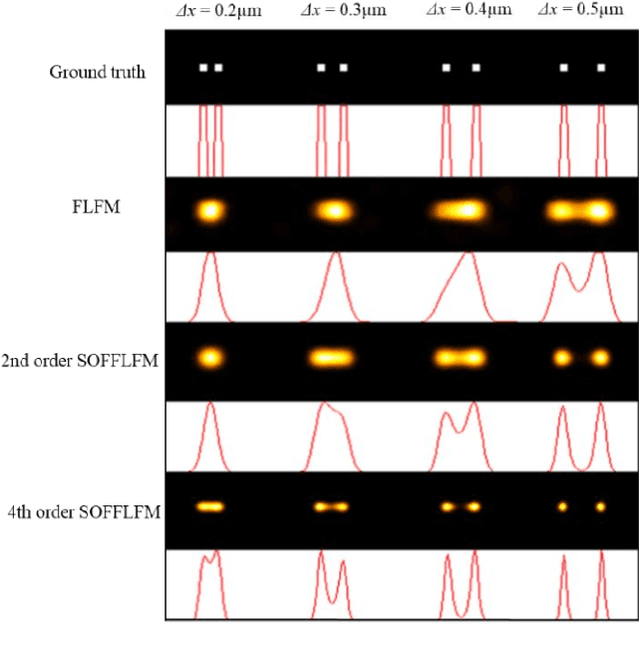
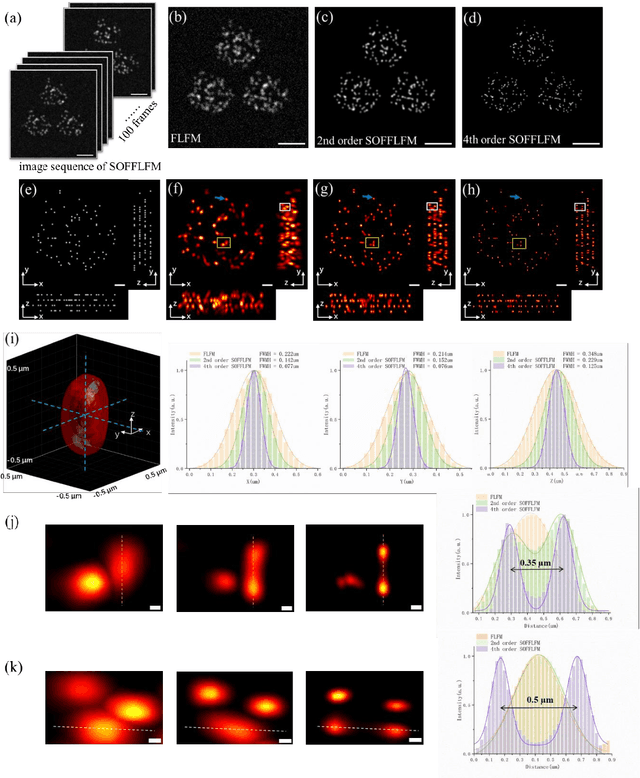
Fourier light-field microscopy (FLFM) uses a micro-lens array (MLA) to segment the Fourier Plane of the microscopic objective lens to generate multiple two-dimensional perspective views, thereby reconstructing the three-dimensional(3D) structure of the sample using 3D deconvolution calculation without scanning. However, the resolution of FLFM is still limited by diffraction, and furthermore, dependent on the aperture division. In order to improve its resolution, a Super-resolution optical fluctuation Fourier light field microscopy (SOFFLFM) was proposed here, in which the Sofi method with ability of super-resolution was introduced into FLFM. SOFFLFM uses higher-order cumulants statistical analysis on an image sequence collected by FLFM, and then carries out 3D deconvolution calculation to reconstruct the 3D structure of the sample. Theoretical basis of SOFFLFM on improving resolution was explained and then verified with simulations. Simulation results demonstrated that SOFFLFM improved lateral and axial resolution by more than sqrt(2) and 2 times in the 2nd and 4th order accumulations, compared with that of FLFM.
Convolution Neural Network based Mode Decomposition for Degenerated Modes via Multiple Images from Polarizers
Jul 08, 2022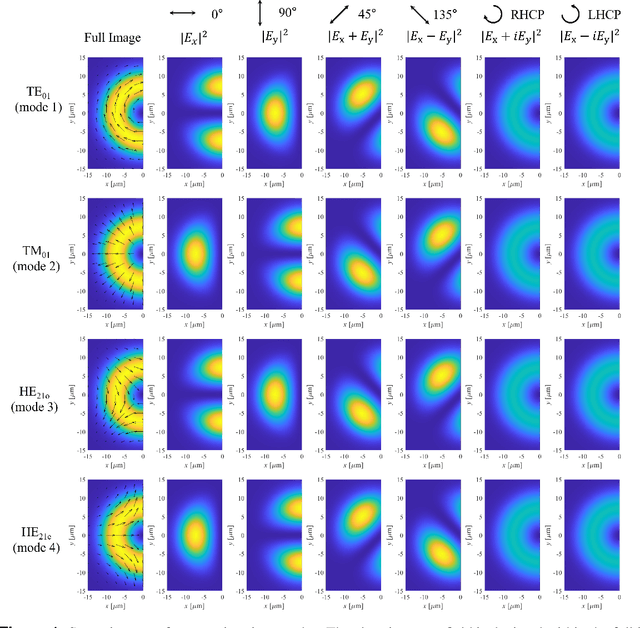
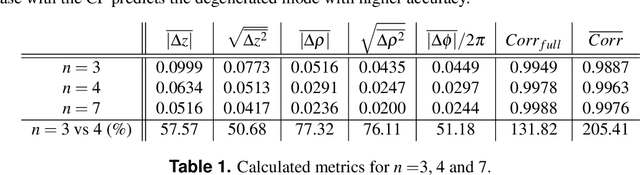
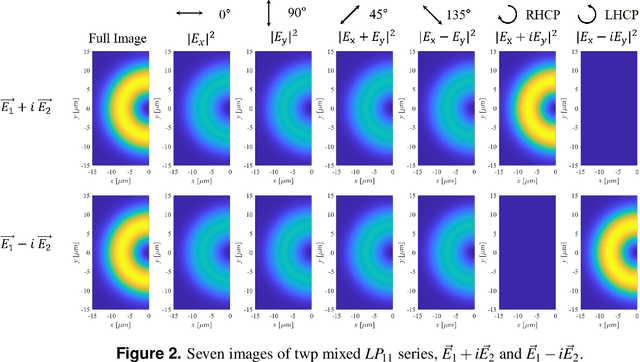
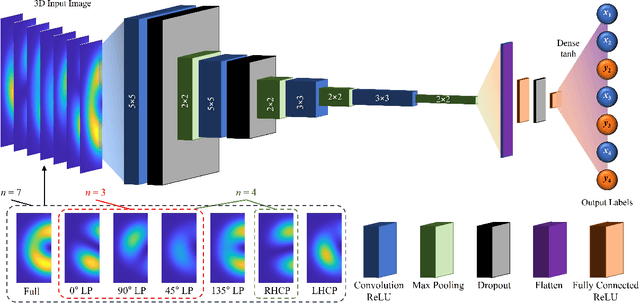
In this paper, a mode decomposition (MD) method for degenerated modes has been studied. Convolution neural network (CNN) has been applied for image training and predicting the mode coefficients. Four-fold degenerated $LP_{11}$ series has been the target to be decomposed. Multiple images are regarded as an input to decompose the degenerate modes. Total of seven different images, including the full original near-field image, and images after linear polarizers of four directions (0$^\circ$, 45$^\circ$, 90$^\circ$, and 135$^\circ$), and images after two circular polarizers (right-handed and left-handed) has been considered for training, validation, and test. The output label of the model has been chosen as the real and imaginary components of the mode coefficient, and the loss function has been selected to be the root-mean-square (RMS) of the labels. The RMS and mean-absolute-error (MAE) of the label, intensity, phase, and field correlation between the actual and predicted values have been selected to be the metrics to evaluate the CNN model. The CNN model has been trained with 100,000 three-dimensional images with depths of three, four, and seven. The performance of the trained model was evaluated via 10,000 test samples with four sets of images - images after three linear polarizers (0$^\circ$, 45$^\circ$, 90$^\circ$) and image after right-handed circular polarizer - showed 0.0634 of label RMS, 0.0292 of intensity RMS, 0.1867 rad of phase MAE, and 0.9978 of average field correlation. The performance of 4 image sets showed at least 50.68\% of performance enhancement compared to models considering only images after linear polarizers.
Local-Aware Global Attention Network for Person Re-Identification
Sep 11, 2022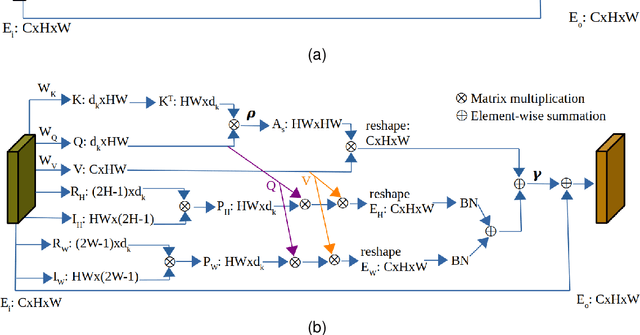
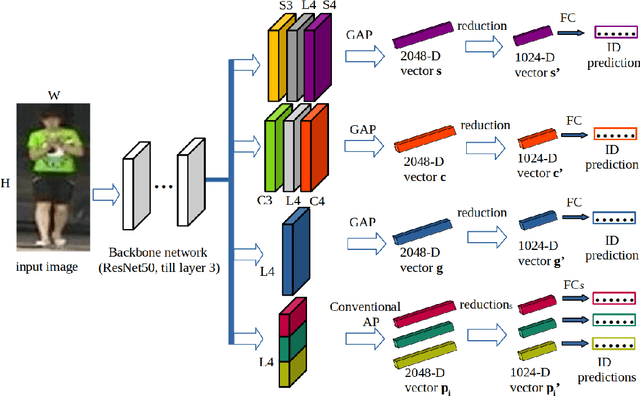


Learning representative, robust and discriminative information from images is essential for effective person re-identification (Re-Id). In this paper, we propose a compound approach for end-to-end discriminative deep feature learning for person Re-Id based on both body and hand images. We carefully design the Local-Aware Global Attention Network (LAGA-Net), a multi-branch deep network architecture consisting of one branch for spatial attention, one branch for channel attention, one branch for global feature representations and another branch for local feature representations. The attention branches focus on the relevant features of the image while suppressing the irrelevant backgrounds. In order to overcome the weakness of the attention mechanisms, equivariant to pixel shuffling, we integrate relative positional encodings into the spatial attention module to capture the spatial positions of pixels. The global branch intends to preserve the global context or structural information. For the the local branch, which intends to capture the fine-grained information, we perform uniform partitioning to generate stripes on the conv-layer horizontally. We retrieve the parts by conducting a soft partition without explicitly partitioning the images or requiring external cues such as pose estimation. A set of ablation study shows that each component contributes to the increased performance of the LAGA-Net. Extensive evaluations on four popular body-based person Re-Id benchmarks and two publicly available hand datasets demonstrate that our proposed method consistently outperforms existing state-of-the-art methods.
A Plug-and-Play Approach to Multiparametric Quantitative MRI: Image Reconstruction using Pre-Trained Deep Denoisers
Feb 10, 2022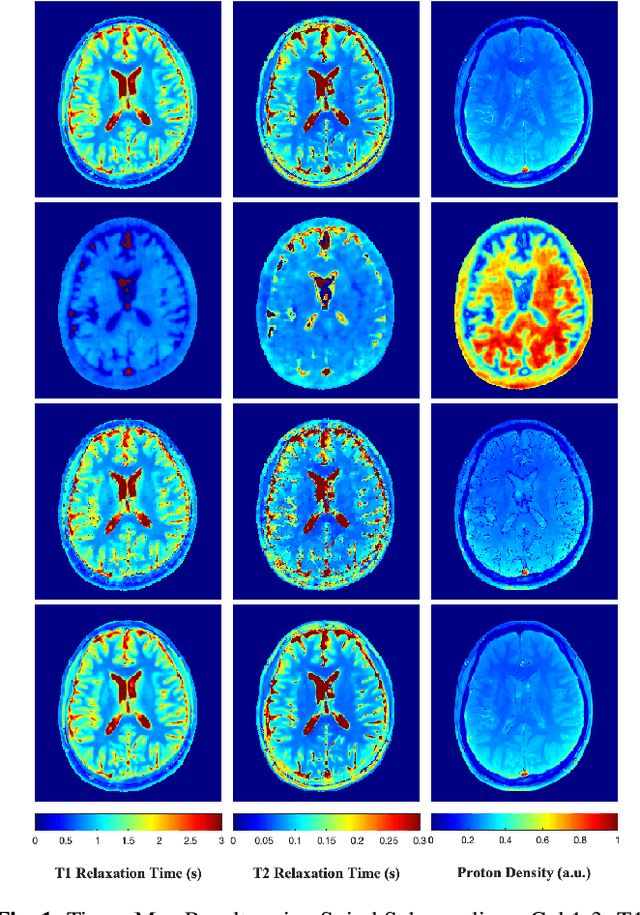
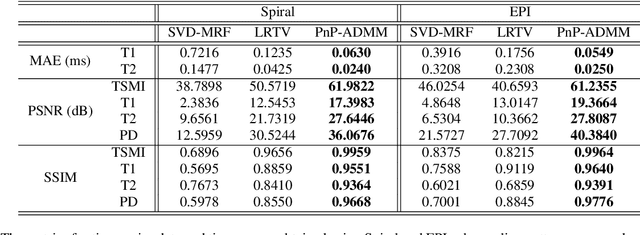
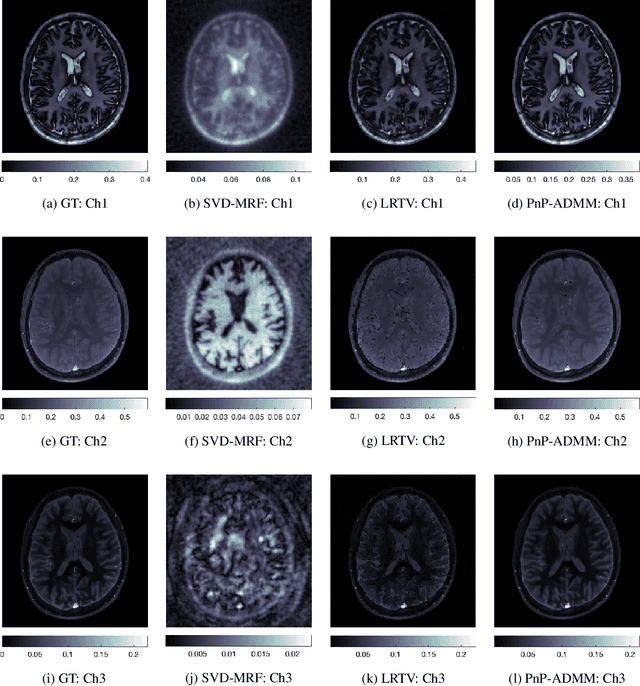
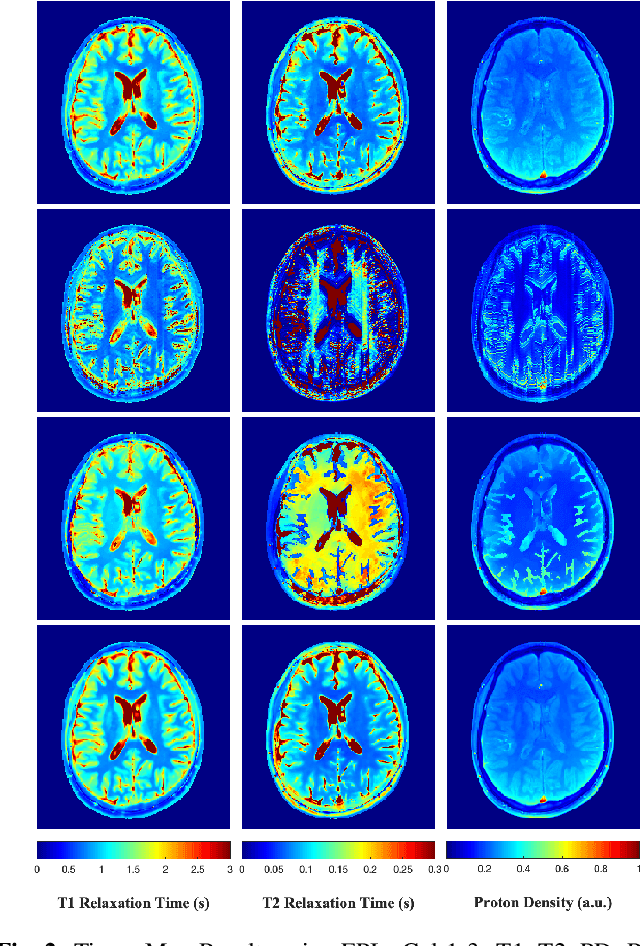
Current spatiotemporal deep learning approaches to Magnetic Resonance Fingerprinting (MRF) build artefact-removal models customised to a particular k-space subsampling pattern which is used for fast (compressed) acquisition. This may not be useful when the acquisition process is unknown during training of the deep learning model and/or changes during testing time. This paper proposes an iterative deep learning plug-and-play reconstruction approach to MRF which is adaptive to the forward acquisition process. Spatiotemporal image priors are learned by an image denoiser i.e. a Convolutional Neural Network (CNN), trained to remove generic white gaussian noise (not a particular subsampling artefact) from data. This CNN denoiser is then used as a data-driven shrinkage operator within the iterative reconstruction algorithm. This algorithm with the same denoiser model is then tested on two simulated acquisition processes with distinct subsampling patterns. The results show consistent de-aliasing performance against both acquisition schemes and accurate mapping of tissues' quantitative bio-properties. Software available: https://github.com/ketanfatania/QMRI-PnP-Recon-POC
Trace and Detect Adversarial Attacks on CNNs using Feature Response Maps
Aug 24, 2022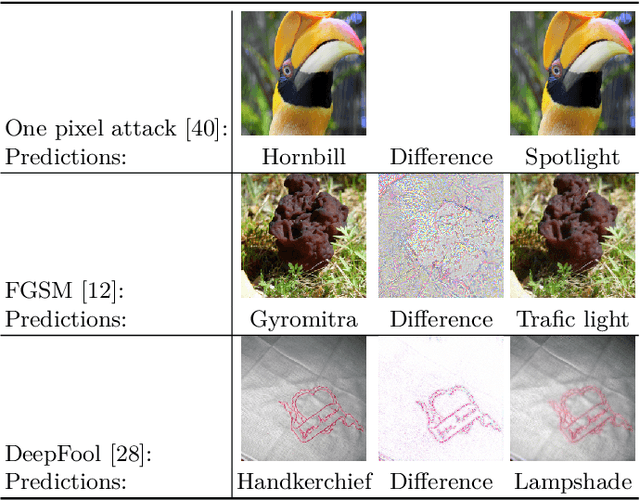
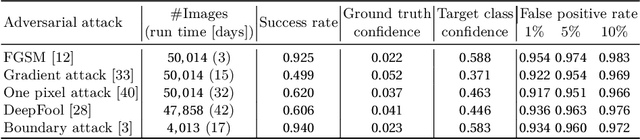

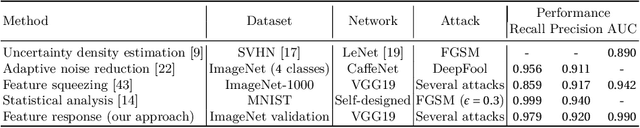
The existence of adversarial attacks on convolutional neural networks (CNN) questions the fitness of such models for serious applications. The attacks manipulate an input image such that misclassification is evoked while still looking normal to a human observer -- they are thus not easily detectable. In a different context, backpropagated activations of CNN hidden layers -- "feature responses" to a given input -- have been helpful to visualize for a human "debugger" what the CNN "looks at" while computing its output. In this work, we propose a novel detection method for adversarial examples to prevent attacks. We do so by tracking adversarial perturbations in feature responses, allowing for automatic detection using average local spatial entropy. The method does not alter the original network architecture and is fully human-interpretable. Experiments confirm the validity of our approach for state-of-the-art attacks on large-scale models trained on ImageNet.
* 13 pages, 6 figures
Active learning for interactive satellite image change detection
Oct 08, 2021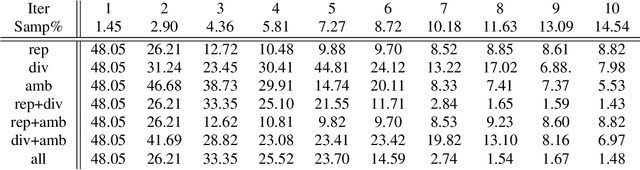
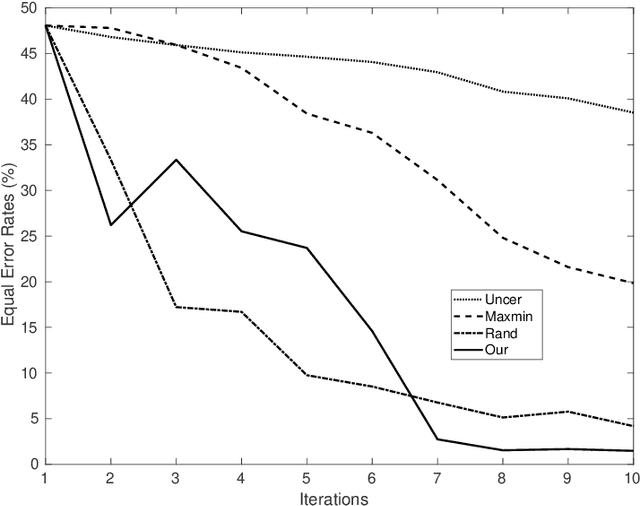
We introduce in this paper a novel active learning algorithm for satellite image change detection. The proposed solution is interactive and based on a question and answer model, which asks an oracle (annotator) the most informative questions about the relevance of sampled satellite image pairs, and according to the oracle's responses, updates a decision function iteratively. We investigate a novel framework which models the probability that samples are relevant; this probability is obtained by minimizing an objective function capturing representativity, diversity and ambiguity. Only data with a high probability according to these criteria are selected and displayed to the oracle for further annotation. Extensive experiments on the task of satellite image change detection after natural hazards (namely tornadoes) show the relevance of the proposed method against the related work.
Patch Selection for Melanoma Classification
Jun 27, 2022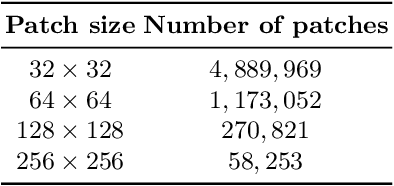
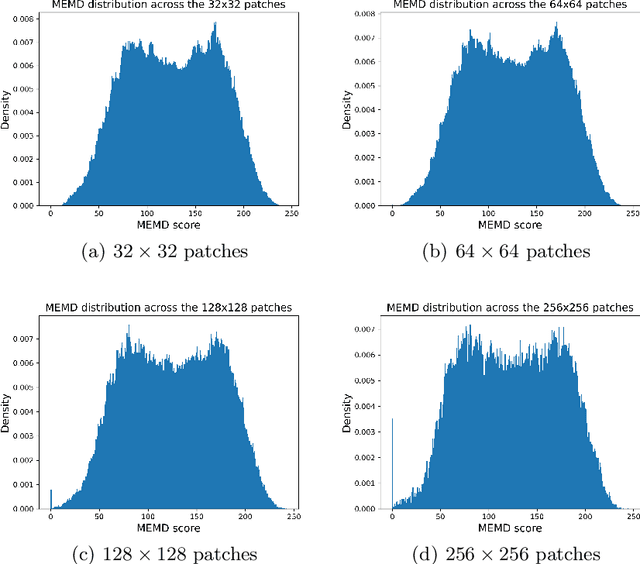
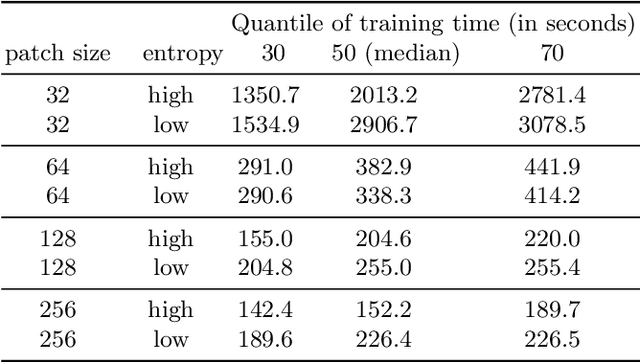

In medical image processing, the most important information is often located on small parts of the image. Patch-based approaches aim at using only the most relevant parts of the image. Finding ways to automatically select the patches is a challenge. In this paper, we investigate two criteria to choose patches: entropy and a spectral similarity criterion. We perform experiments at different levels of patch size. We train a Convolutional Neural Network on the subsets of patches and analyze the training time. We find that, in addition to requiring less preprocessing time, the classifiers trained on the datasets of patches selected based on entropy converge faster than on those selected based on the spectral similarity criterion and, furthermore, lead to higher accuracy. Moreover, patches of high entropy lead to faster convergence and better accuracy than patches of low entropy.