 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Causality-inspired Single-source Domain Generalization for Medical Image Segmentation
Dec 06, 2021
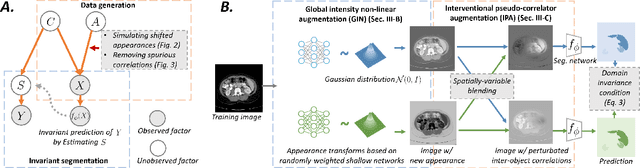
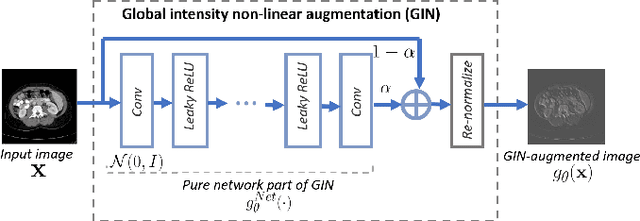
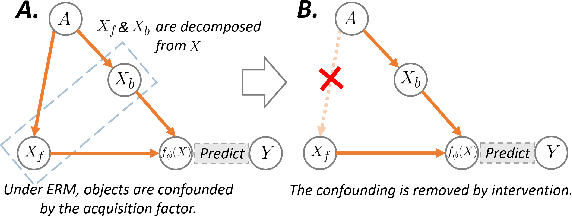
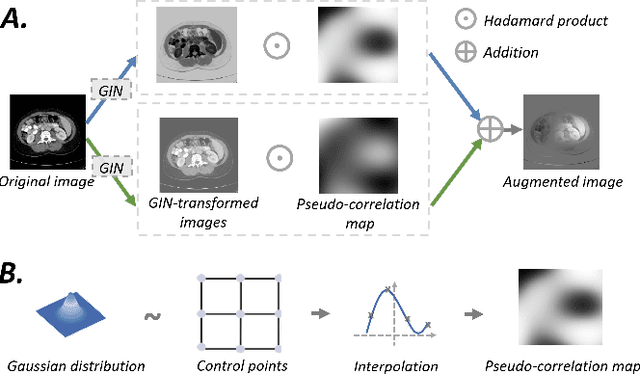
Deep learning models usually suffer from domain shift issues, where models trained on one source domain do not generalize well to other unseen domains. In this work, we investigate the single-source domain generalization problem: training a deep network that is robust to unseen domains, under the condition that training data is only available from one source domain, which is common in medical imaging applications. We tackle this problem in the context of cross-domain medical image segmentation. Under this scenario, domain shifts are mainly caused by different acquisition processes. We propose a simple causality-inspired data augmentation approach to expose a segmentation model to synthesized domain-shifted training examples. Specifically, 1) to make the deep model robust to discrepancies in image intensities and textures, we employ a family of randomly-weighted shallow networks. They augment training images using diverse appearance transformations. 2) Further we show that spurious correlations among objects in an image are detrimental to domain robustness. These correlations might be taken by the network as domain-specific clues for making predictions, and they may break on unseen domains. We remove these spurious correlations via causal intervention. This is achieved by resampling the appearances of potentially correlated objects independently. The proposed approach is validated on three cross-domain segmentation tasks: cross-modality (CT-MRI) abdominal image segmentation, cross-sequence (bSSFP-LGE) cardiac MRI segmentation, and cross-center prostate MRI segmentation. The proposed approach yields consistent performance gains compared with competitive methods when tested on unseen domains.
Incremental Learning in Semantic Segmentation from Image Labels
Dec 03, 2021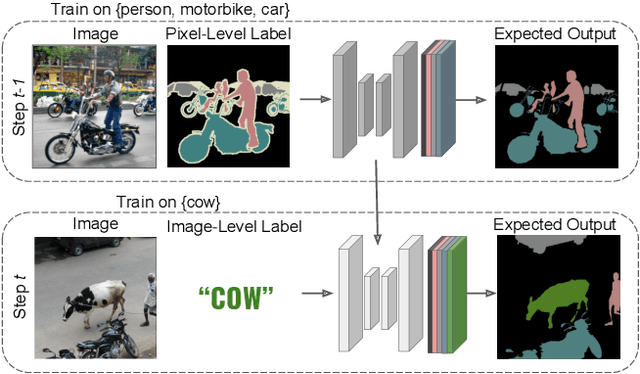
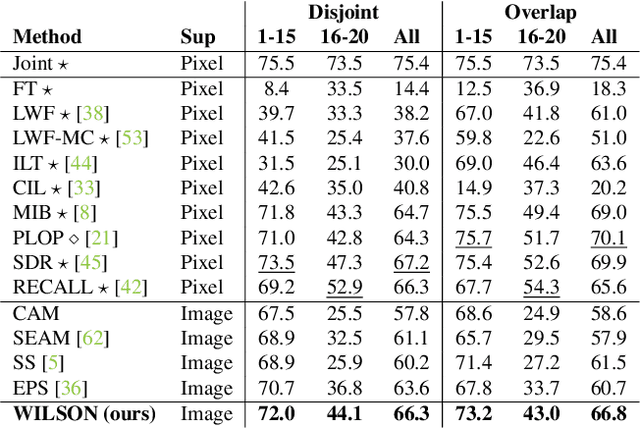
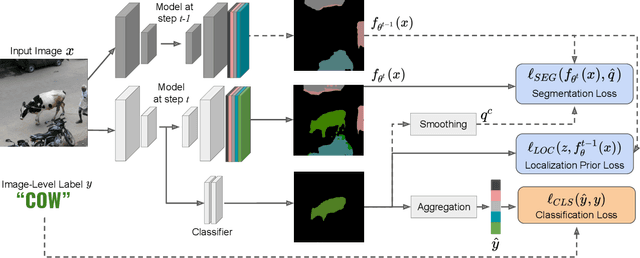
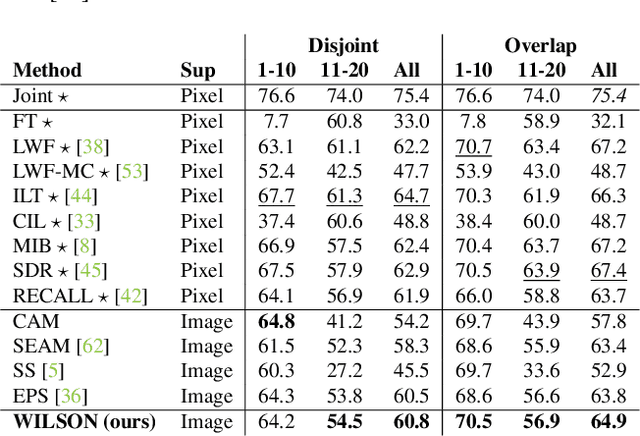
Although existing semantic segmentation approaches achieve impressive results, they still struggle to update their models incrementally as new categories are uncovered. Furthermore, pixel-by-pixel annotations are expensive and time-consuming. This paper proposes a novel framework for Weakly Incremental Learning for Semantic Segmentation, that aims at learning to segment new classes from cheap and largely available image-level labels. As opposed to existing approaches, that need to generate pseudo-labels offline, we use an auxiliary classifier, trained with image-level labels and regularized by the segmentation model, to obtain pseudo-supervision online and update the model incrementally. We cope with the inherent noise in the process by using soft-labels generated by the auxiliary classifier. We demonstrate the effectiveness of our approach on the Pascal VOC and COCO datasets, outperforming offline weakly-supervised methods and obtaining results comparable with incremental learning methods with full supervision.
A Survey on Adversarial Image Synthesis
Jul 16, 2021Generative Adversarial Networks (GANs) have been extremely successful in various application domains. Adversarial image synthesis has drawn increasing attention and made tremendous progress in recent years because of its wide range of applications in many computer vision and image processing problems. Among the many applications of GAN, image synthesis is the most well-studied one, and research in this area has already demonstrated the great potential of using GAN in image synthesis. In this paper, we provide a taxonomy of methods used in image synthesis, review different models for text-to-image synthesis and image-to-image translation, and discuss some evaluation metrics as well as possible future research directions in image synthesis with GAN.
Object Level Depth Reconstruction for Category Level 6D Object Pose Estimation From Monocular RGB Image
Apr 04, 2022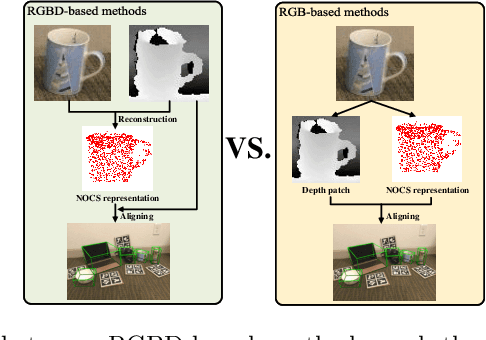
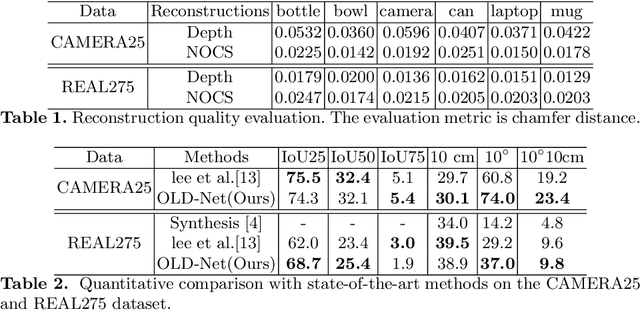
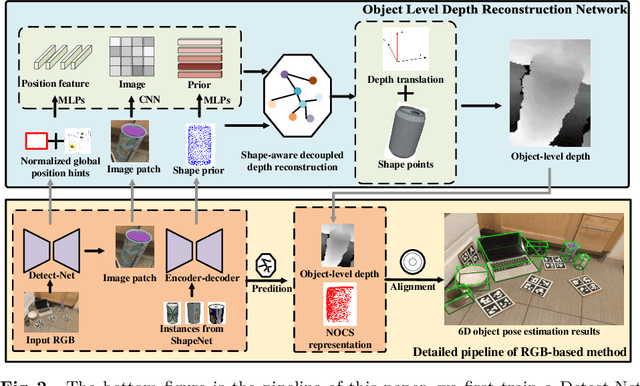

Recently, RGBD-based category-level 6D object pose estimation has achieved promising improvement in performance, however, the requirement of depth information prohibits broader applications. In order to relieve this problem, this paper proposes a novel approach named Object Level Depth reconstruction Network (OLD-Net) taking only RGB images as input for category-level 6D object pose estimation. We propose to directly predict object-level depth from a monocular RGB image by deforming the category-level shape prior into object-level depth and the canonical NOCS representation. Two novel modules named Normalized Global Position Hints (NGPH) and Shape-aware Decoupled Depth Reconstruction (SDDR) module are introduced to learn high fidelity object-level depth and delicate shape representations. At last, the 6D object pose is solved by aligning the predicted canonical representation with the back-projected object-level depth. Extensive experiments on the challenging CAMERA25 and REAL275 datasets indicate that our model, though simple, achieves state-of-the-art performance.
Contrastive Masked Autoencoders are Stronger Vision Learners
Jul 27, 2022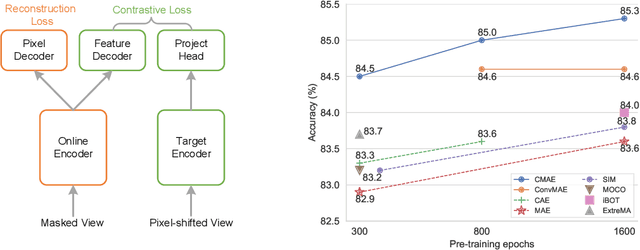

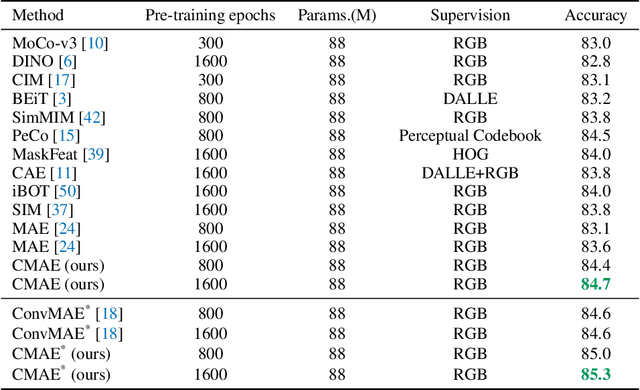
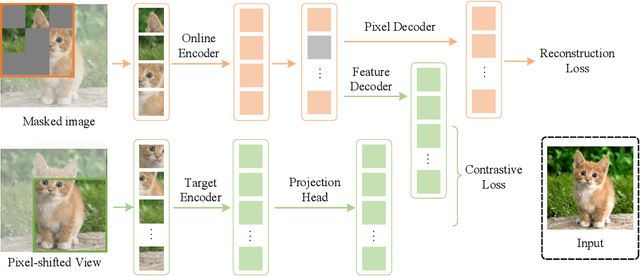
Masked image modeling (MIM) has achieved promising results on various vision tasks. However, the limited discriminability of learned representation manifests there is still plenty to go for making a stronger vision learner. Towards this goal, we propose Contrastive Masked Autoencoders (CMAE), a new self-supervised pre-training method for learning more comprehensive and capable vision representations. By elaboratively unifying contrastive learning (CL) and masked image model (MIM) through novel designs, CMAE leverages their respective advantages and learns representations with both strong instance discriminability and local perceptibility. Specifically, CMAE consists of two branches where the online branch is an asymmetric encoder-decoder and the target branch is a momentum updated encoder. During training, the online encoder reconstructs original images from latent representations of masked images to learn holistic features. The target encoder, fed with the full images, enhances the feature discriminability via contrastive learning with its online counterpart. To make CL compatible with MIM, CMAE introduces two new components, i.e. pixel shift for generating plausible positive views and feature decoder for complementing features of contrastive pairs. Thanks to these novel designs, CMAE effectively improves the representation quality and transfer performance over its MIM counterpart. CMAE achieves the state-of-the-art performance on highly competitive benchmarks of image classification, semantic segmentation and object detection. Notably, CMAE-Base achieves $85.3\%$ top-1 accuracy on ImageNet and $52.5\%$ mIoU on ADE20k, surpassing previous best results by $0.7\%$ and $1.8\%$ respectively. Codes will be made publicly available.
Artifact- and content-specific quality assessment for MRI with image rulers
Nov 06, 2021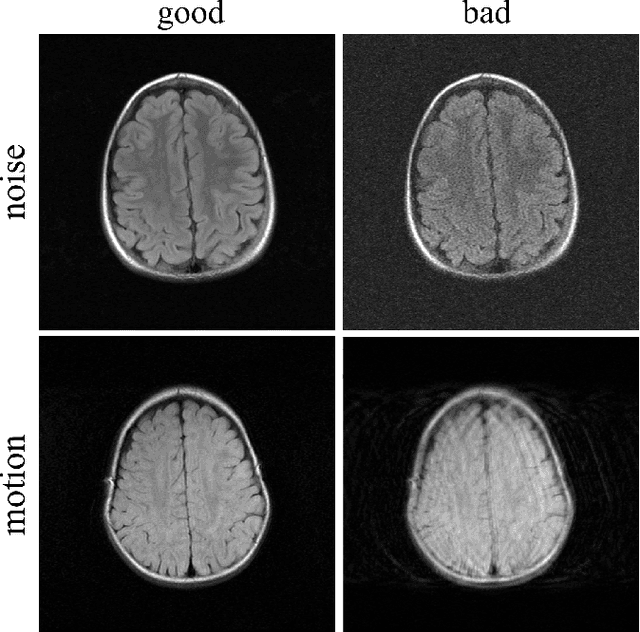

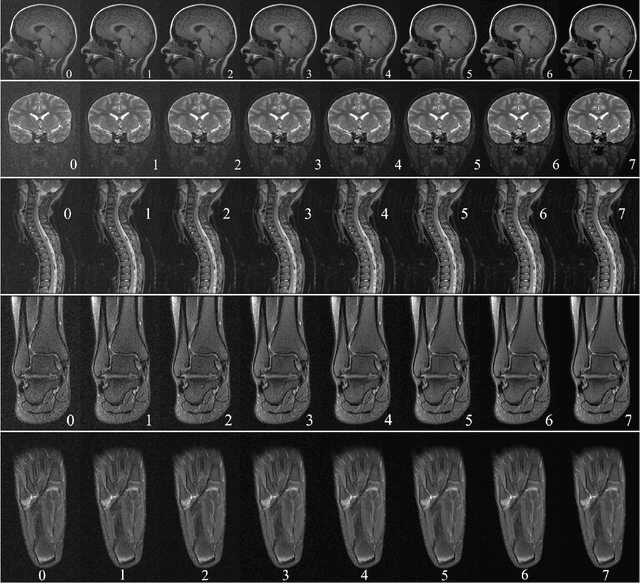

In clinical practice MR images are often first seen by radiologists long after the scan. If image quality is inadequate either patients have to return for an additional scan, or a suboptimal interpretation is rendered. An automatic image quality assessment (IQA) would enable real-time remediation. Existing IQA works for MRI give only a general quality score, agnostic to the cause of and solution to low-quality scans. Furthermore, radiologists' image quality requirements vary with the scan type and diagnostic task. Therefore, the same score may have different implications for different scans. We propose a framework with multi-task CNN model trained with calibrated labels and inferenced with image rulers. Labels calibrated by human inputs follow a well-defined and efficient labeling task. Image rulers address varying quality standards and provide a concrete way of interpreting raw scores from the CNN. The model supports assessments of two of the most common artifacts in MRI: noise and motion. It achieves accuracies of around 90%, 6% better than the best previous method examined, and 3% better than human experts on noise assessment. Our experiments show that label calibration, image rulers, and multi-task training improve the model's performance and generalizability.
Portuguese Man-of-War Image Classification with Convolutional Neural Networks
Jul 04, 2022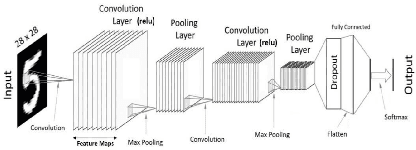


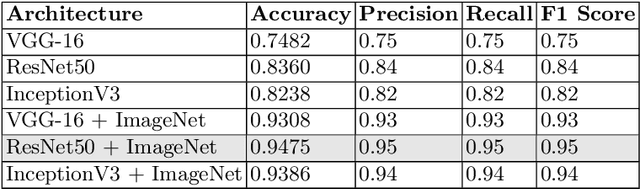
Portuguese man-of-war (PMW) is a gelatinous organism with long tentacles capable of causing severe burns, thus leading to negative impacts on human activities, such as tourism and fishing. There is a lack of information about the spatio-temporal dynamics of this species. Therefore, the use of alternative methods for collecting data can contribute to their monitoring. Given the widespread use of social networks and the eye-catching look of PMW, Instagram posts can be a promising data source for monitoring. The first task to follow this approach is to identify posts that refer to PMW. This paper reports on the use of convolutional neural networks for PMW images classification, in order to automate the recognition of Instagram posts. We created a suitable dataset, and trained three different neural networks: VGG-16, ResNet50, and InceptionV3, with and without a pre-trained step with the ImageNet dataset. We analyzed their results using accuracy, precision, recall, and F1 score metrics. The pre-trained ResNet50 network presented the best results, obtaining 94% of accuracy and 95% of precision, recall, and F1 score. These results show that convolutional neural networks can be very effective for recognizing PMW images from the Instagram social media.
Towards Deep Learning-aided Wireless Channel Estimation and Channel State Information Feedback for 6G
Sep 05, 2022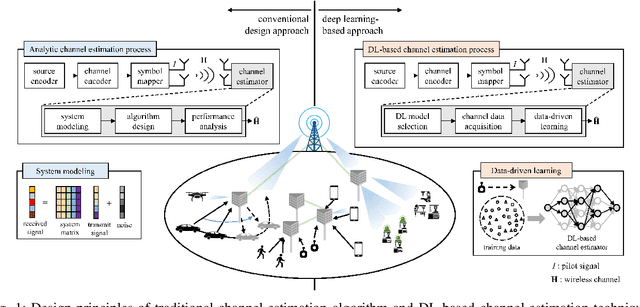
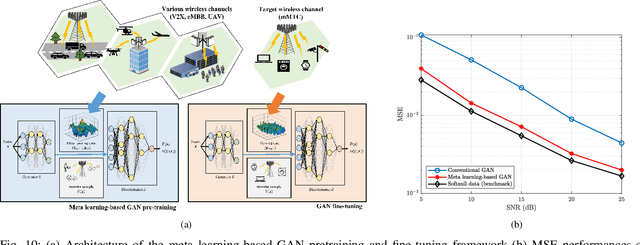
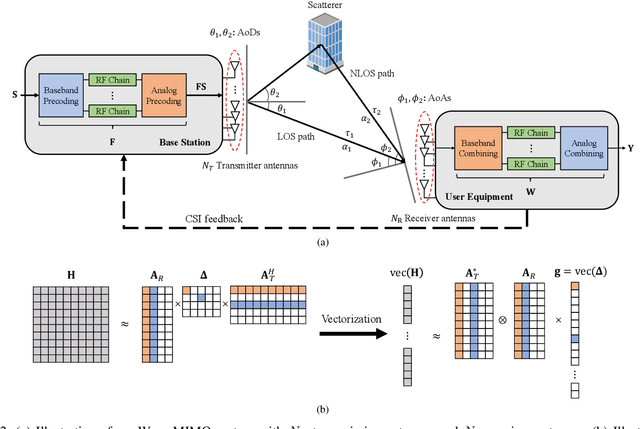
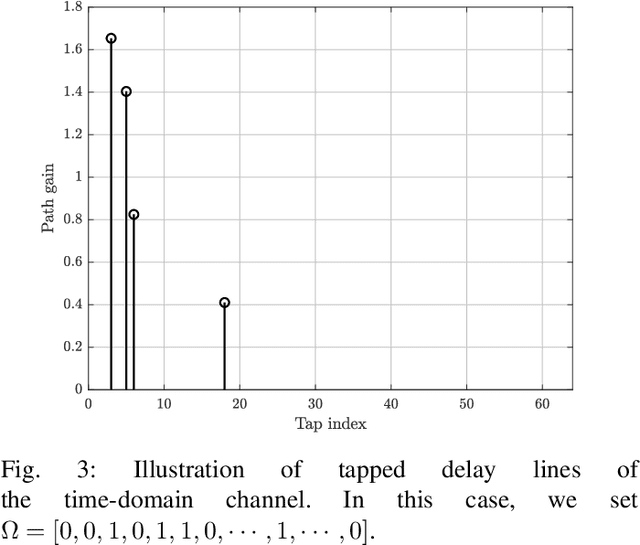
Deep learning (DL), a branch of artificial intelligence (AI) techniques, has shown great promise in various disciplines such as image classification and segmentation, speech recognition, language translation, among others. This remarkable success of DL has stimulated increasing interest in applying this paradigm to wireless channel estimation in recent years. Since DL principles are inductive in nature and distinct from the conventional rule-based algorithms, when one tries to use DL technique to the channel estimation, one might easily get stuck and confused by so many knobs to control and small details to be aware of. The primary purpose of this paper is to discuss key issues and possible solutions in DL-based wireless channel estimation and channel state information (CSI) feedback including the DL model selection, training data acquisition, and neural network design for 6G. Specifically, we present several case studies together with the numerical experiments to demonstrate the effectiveness of the DL-based wireless channel estimation framework.
Data Feedback Loops: Model-driven Amplification of Dataset Biases
Sep 08, 2022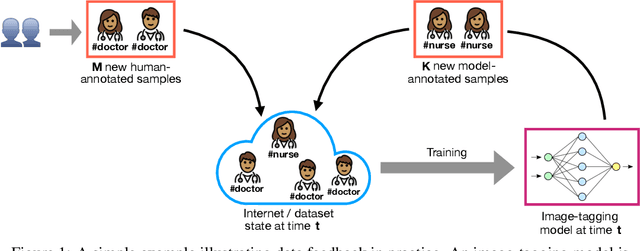

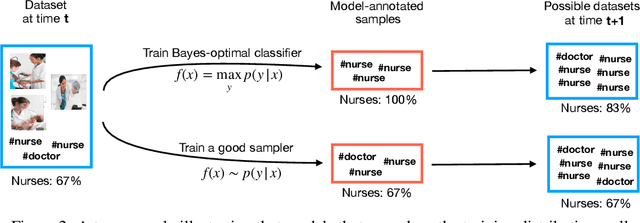

Datasets scraped from the internet have been critical to the successes of large-scale machine learning. Yet, this very success puts the utility of future internet-derived datasets at potential risk, as model outputs begin to replace human annotations as a source of supervision. In this work, we first formalize a system where interactions with one model are recorded as history and scraped as training data in the future. We then analyze its stability over time by tracking changes to a test-time bias statistic (e.g. gender bias of model predictions). We find that the degree of bias amplification is closely linked to whether the model's outputs behave like samples from the training distribution, a behavior which we characterize and define as consistent calibration. Experiments in three conditional prediction scenarios - image classification, visual role-labeling, and language generation - demonstrate that models that exhibit a sampling-like behavior are more calibrated and thus more stable. Based on this insight, we propose an intervention to help calibrate and stabilize unstable feedback systems. Code is available at https://github.com/rtaori/data_feedback.
Computerized Tomography Pulmonary Angiography Image Simulation using Cycle Generative Adversarial Network from Chest CT imaging in Pulmonary Embolism Patients
May 17, 2022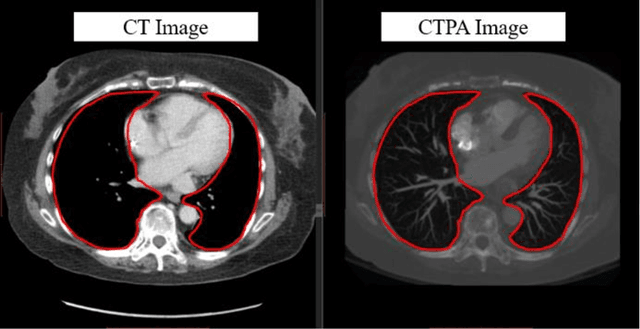
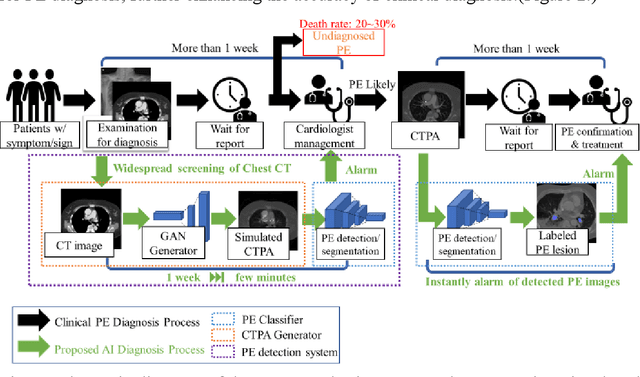

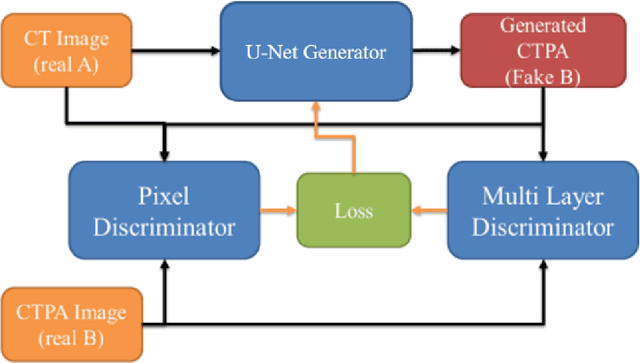
The purpose of this research is to develop a system that generates simulated computed tomography pulmonary angiography (CTPA) images clinically for pulmonary embolism diagnoses. Nowadays, CTPA images are the gold standard computerized detection method to determine and identify the symptoms of pulmonary embolism (PE), although performing CTPA is harmful for patients and also expensive. Therefore, we aim to detect possible PE patients through CT images. The system will simulate CTPA images with deep learning models for the identification of PE patients' symptoms, providing physicians with another reference for determining PE patients. In this study, the simulated CTPA image generation system uses a generative antagonistic network to enhance the features of pulmonary vessels in the CT images to strengthen the reference value of the images and provide a basis for hospitals to judge PE patients. We used the CT images of 22 patients from National Cheng Kung University Hospital and the corresponding CTPA images as the training data for the task of simulating CTPA images and generated them using two sets of generative countermeasure networks. This study is expected to propose a new approach to the clinical diagnosis of pulmonary embolism, in which a deep learning network is used to assist in the complex screening process and to review the generated simulated CTPA images, allowing physicians to assess whether a patient needs to undergo detailed testing for CTPA, improving the speed of detection of pulmonary embolism and significantly reducing the number of undetected patients.