 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
LatteGAN: Visually Guided Language Attention for Multi-Turn Text-Conditioned Image Manipulation
Dec 28, 2021
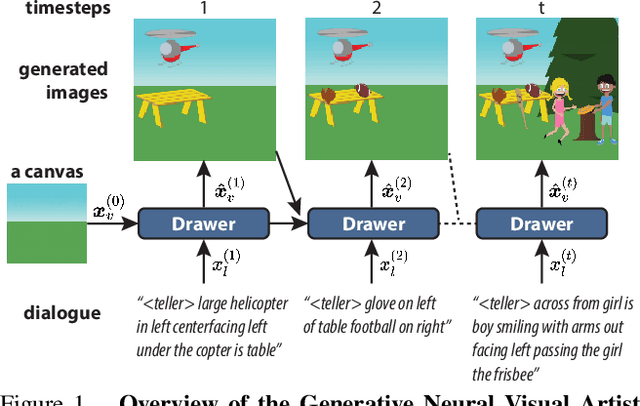
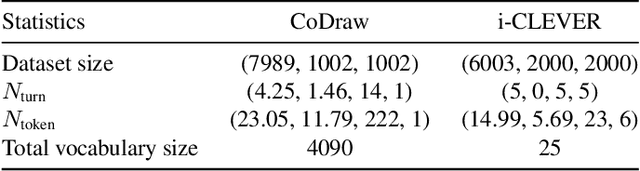
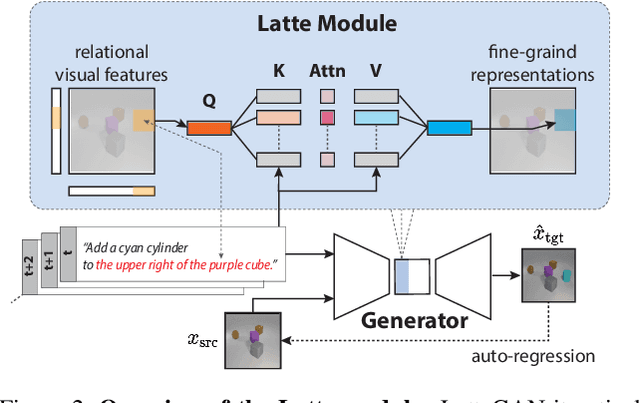
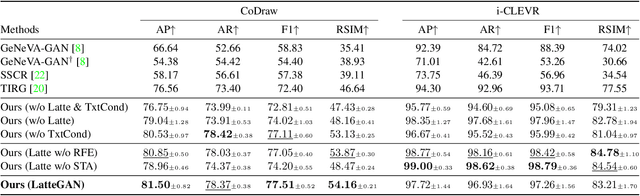
Text-guided image manipulation tasks have recently gained attention in the vision-and-language community. While most of the prior studies focused on single-turn manipulation, our goal in this paper is to address the more challenging multi-turn image manipulation (MTIM) task. Previous models for this task successfully generate images iteratively, given a sequence of instructions and a previously generated image. However, this approach suffers from under-generation and a lack of generated quality of the objects that are described in the instructions, which consequently degrades the overall performance. To overcome these problems, we present a novel architecture called a Visually Guided Language Attention GAN (LatteGAN). Here, we address the limitations of the previous approaches by introducing a Visually Guided Language Attention (Latte) module, which extracts fine-grained text representations for the generator, and a Text-Conditioned U-Net discriminator architecture, which discriminates both the global and local representations of fake or real images. Extensive experiments on two distinct MTIM datasets, CoDraw and i-CLEVR, demonstrate the state-of-the-art performance of the proposed model.
Constrained Sampling for Class-Agnostic Weakly Supervised Object Localization
Sep 09, 2022
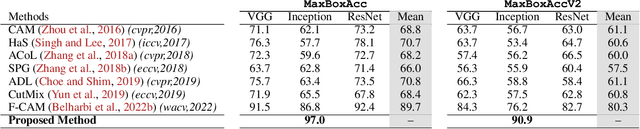
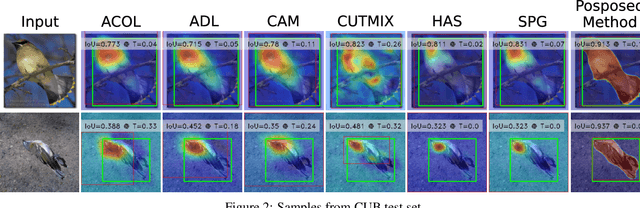
Self-supervised vision transformers can generate accurate localization maps of the objects in an image. However, since they decompose the scene into multiple maps containing various objects, and they do not rely on any explicit supervisory signal, they cannot distinguish between the object of interest from other objects, as required in weakly-supervised object localization (WSOL). To address this issue, we propose leveraging the multiple maps generated by the different transformer heads to acquire pseudo-labels for training a WSOL model. In particular, a new discriminative proposals sampling method is introduced that relies on a pretrained CNN classifier to identify discriminative regions. Then, foreground and background pixels are sampled from these regions in order to train a WSOL model for generating activation maps that can accurately localize objects belonging to a specific class. Empirical results on the challenging CUB benchmark dataset indicate that our proposed approach can outperform state-of-art methods over a wide range of threshold values. Our method provides class activation maps with a better coverage of foreground object regions w.r.t. the background.
A Lightweight Machine Learning Pipeline for LiDAR-simulation
Aug 05, 2022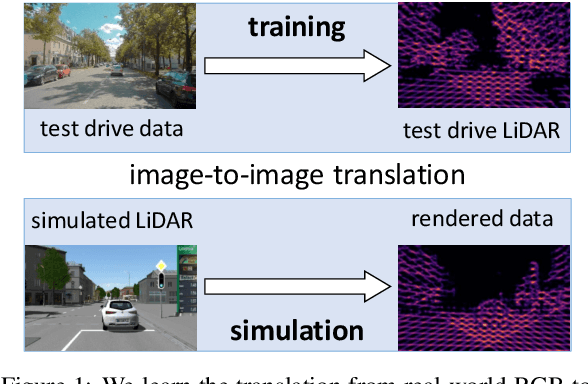
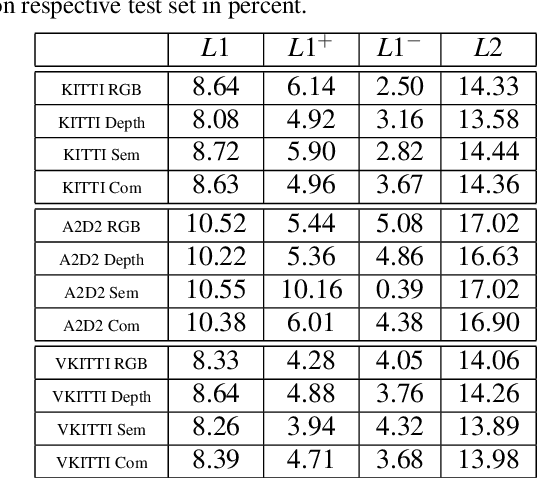
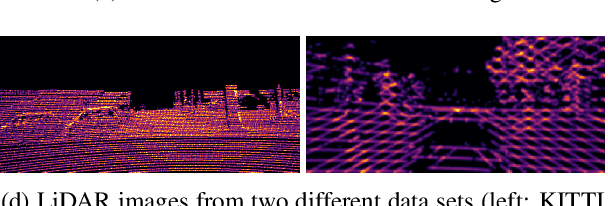
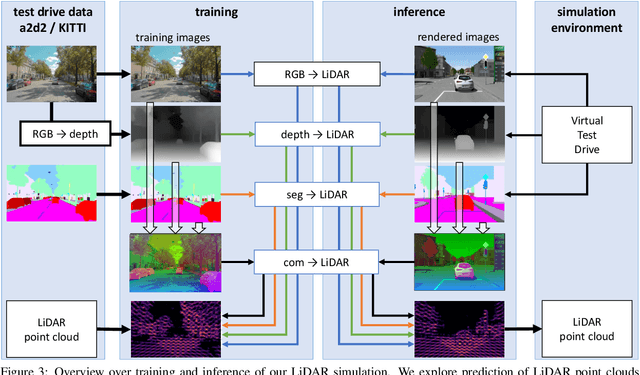
Virtual testing is a crucial task to ensure safety in autonomous driving, and sensor simulation is an important task in this domain. Most current LiDAR simulations are very simplistic and are mainly used to perform initial tests, while the majority of insights are gathered on the road. In this paper, we propose a lightweight approach for more realistic LiDAR simulation that learns a real sensor's behavior from test drive data and transforms this to the virtual domain. The central idea is to cast the simulation into an image-to-image translation problem. We train our pix2pix based architecture on two real world data sets, namely the popular KITTI data set and the Audi Autonomous Driving Dataset which provide both, RGB and LiDAR images. We apply this network on synthetic renderings and show that it generalizes sufficiently from real images to simulated images. This strategy enables to skip the sensor-specific, expensive and complex LiDAR physics simulation in our synthetic world and avoids oversimplification and a large domain-gap through the clean synthetic environment.
* Conference: DeLTA 22; ISBN 978-989-758-584-5; ISSN 2184-9277; publisher: SciTePress, organization: INSTICC
Discriminative Sampling of Proposals in Self-Supervised Transformers for Weakly Supervised Object Localization
Sep 09, 2022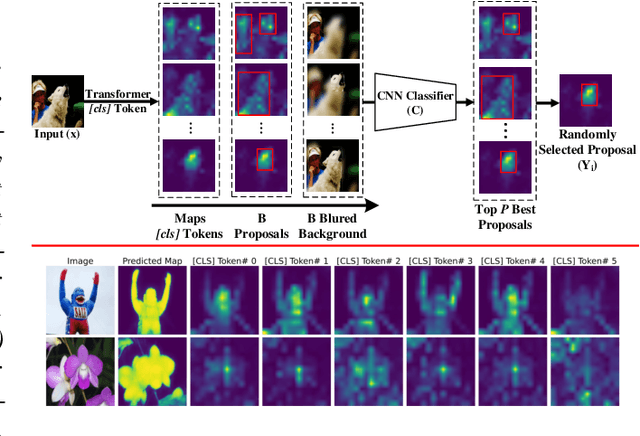
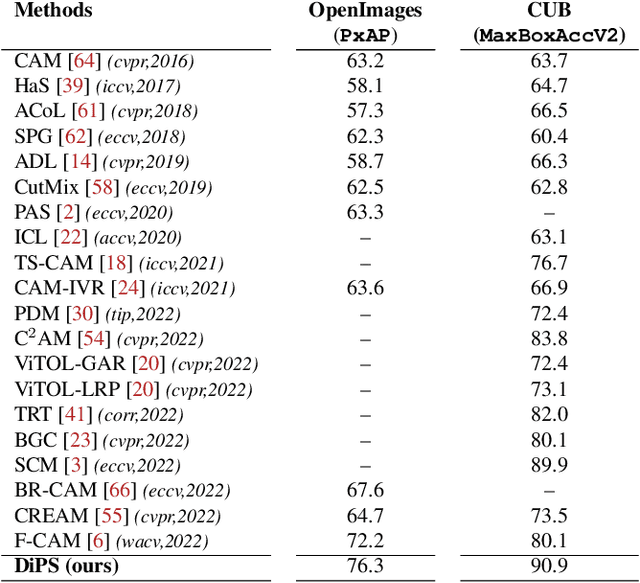
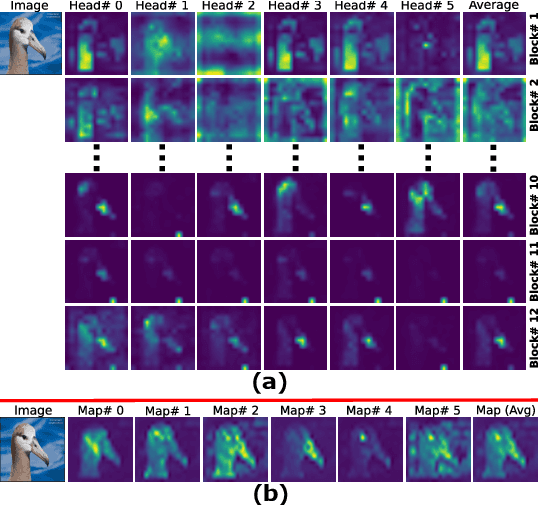
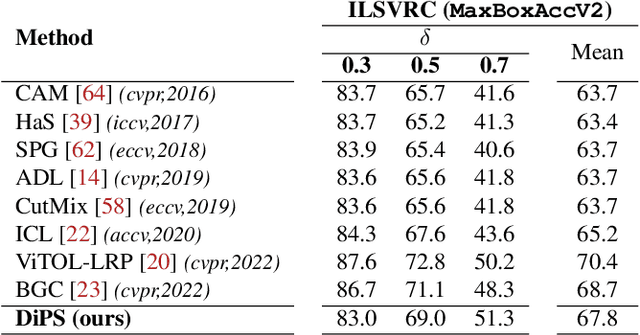
Self-supervised vision transformers can generate accurate localization maps of the objects in an image. However, since they decompose the scene into multiple maps containing various objects, and they do not rely on any explicit supervisory signal, they cannot distinguish between the object of interest from other objects, as required in weakly-supervised object localization (WSOL). To address this issue, we propose leveraging the multiple maps generated by the different transformer heads to acquire pseudo-labels for training a WSOL model. In particular, a new Discriminative Proposals Sampling (DiPS) method is introduced that relies on a pretrained CNN classifier to identify discriminative regions. Then, foreground and background pixels are sampled from these regions in order to train a WSOL model for generating activation maps that can accurately localize objects belonging to a specific class. Empirical results on the challenging CUB, OpenImages, and ILSVRC benchmark datasets indicate that our proposed approach can outperform state-of-art methods over a wide range of threshold values. DiPS provides class activation maps with a better coverage of foreground object regions w.r.t. the background.
Continual Learning with Dependency Preserving Hypernetworks
Sep 16, 2022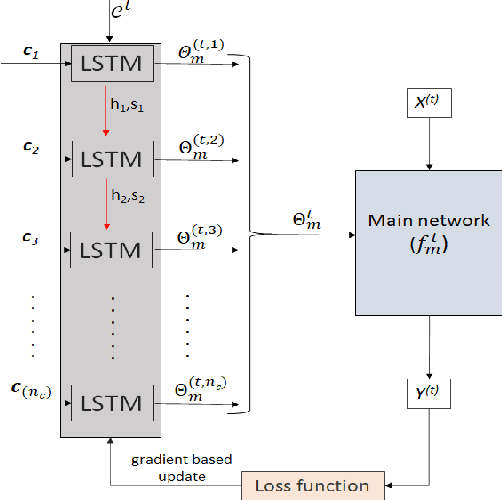
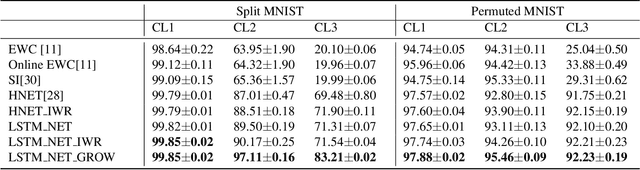
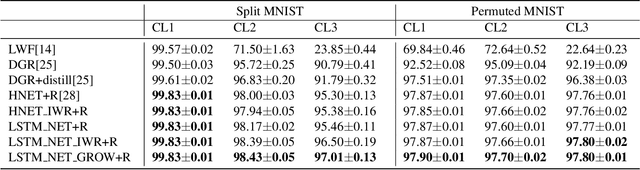
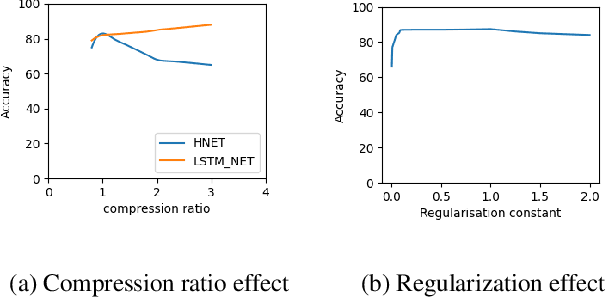
Humans learn continually throughout their lifespan by accumulating diverse knowledge and fine-tuning it for future tasks. When presented with a similar goal, neural networks suffer from catastrophic forgetting if data distributions across sequential tasks are not stationary over the course of learning. An effective approach to address such continual learning (CL) problems is to use hypernetworks which generate task dependent weights for a target network. However, the continual learning performance of existing hypernetwork based approaches are affected by the assumption of independence of the weights across the layers in order to maintain parameter efficiency. To address this limitation, we propose a novel approach that uses a dependency preserving hypernetwork to generate weights for the target network while also maintaining the parameter efficiency. We propose to use recurrent neural network (RNN) based hypernetwork that can generate layer weights efficiently while allowing for dependencies across them. In addition, we propose novel regularisation and network growth techniques for the RNN based hypernetwork to further improve the continual learning performance. To demonstrate the effectiveness of the proposed methods, we conducted experiments on several image classification continual learning tasks and settings. We found that the proposed methods based on the RNN hypernetworks outperformed the baselines in all these CL settings and tasks.
Implicit Transformer Network for Screen Content Image Continuous Super-Resolution
Dec 12, 2021
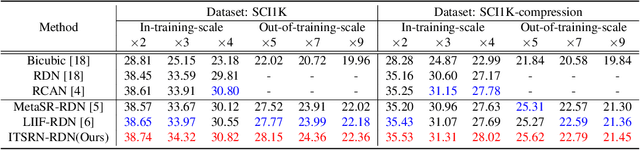
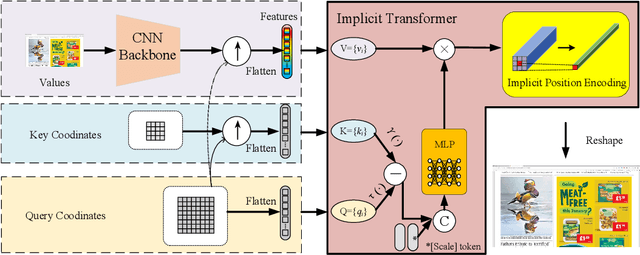
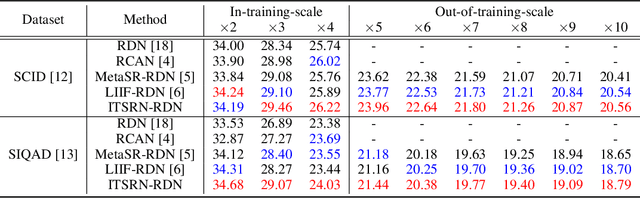
Nowadays, there is an explosive growth of screen contents due to the wide application of screen sharing, remote cooperation, and online education. To match the limited terminal bandwidth, high-resolution (HR) screen contents may be downsampled and compressed. At the receiver side, the super-resolution (SR) of low-resolution (LR) screen content images (SCIs) is highly demanded by the HR display or by the users to zoom in for detail observation. However, image SR methods mostly designed for natural images do not generalize well for SCIs due to the very different image characteristics as well as the requirement of SCI browsing at arbitrary scales. To this end, we propose a novel Implicit Transformer Super-Resolution Network (ITSRN) for SCISR. For high-quality continuous SR at arbitrary ratios, pixel values at query coordinates are inferred from image features at key coordinates by the proposed implicit transformer and an implicit position encoding scheme is proposed to aggregate similar neighboring pixel values to the query one. We construct benchmark SCI1K and SCI1K-compression datasets with LR and HR SCI pairs. Extensive experiments show that the proposed ITSRN significantly outperforms several competitive continuous and discrete SR methods for both compressed and uncompressed SCIs.
Class-Level Logit Perturbation
Sep 13, 2022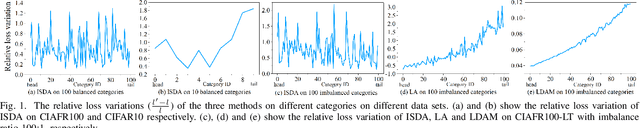

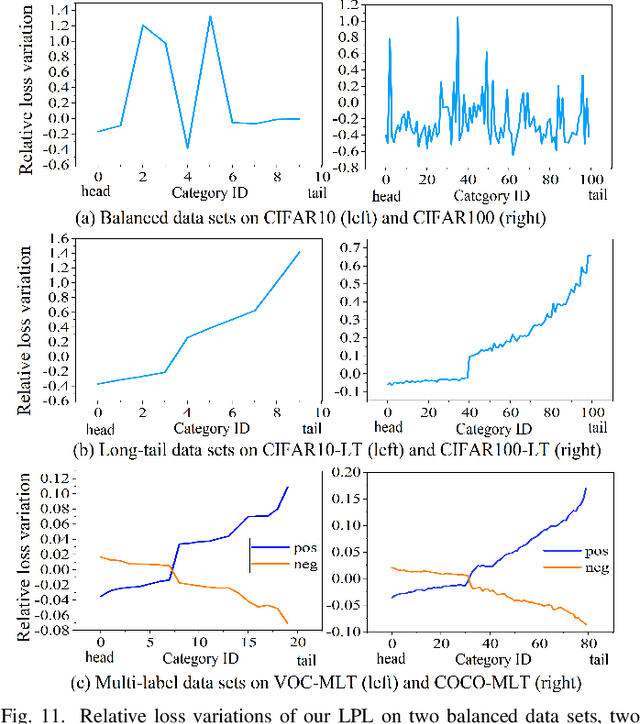
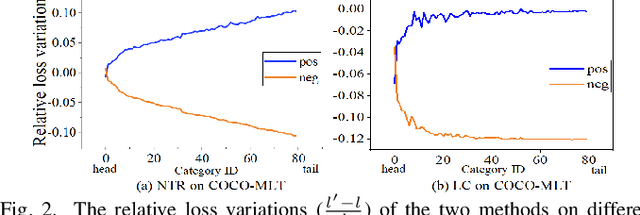
Features, logits, and labels are the three primary data when a sample passes through a deep neural network. Feature perturbation and label perturbation receive increasing attention in recent years. They have been proven to be useful in various deep learning approaches. For example, (adversarial) feature perturbation can improve the robustness or even generalization capability of learned models. However, limited studies have explicitly explored for the perturbation of logit vectors. This work discusses several existing methods related to class-level logit perturbation. A unified viewpoint between positive/negative data augmentation and loss variations incurred by logit perturbation is established. A theoretical analysis is provided to illuminate why class-level logit perturbation is useful. Accordingly, new methodologies are proposed to explicitly learn to perturb logits for both single-label and multi-label classification tasks. Extensive experiments on benchmark image classification data sets and their long-tail versions indicated the competitive performance of our learning method. As it only perturbs on logit, it can be used as a plug-in to fuse with any existing classification algorithms. All the codes are available at https://github.com/limengyang1992/lpl.
Attention Spiking Neural Networks
Sep 28, 2022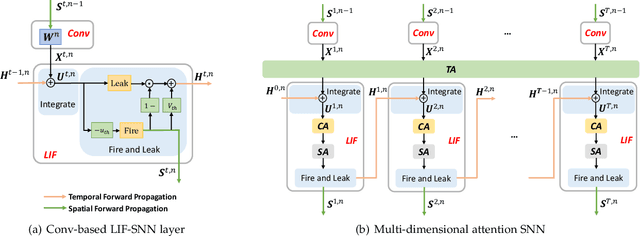
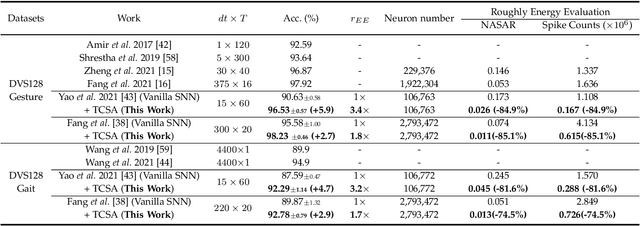
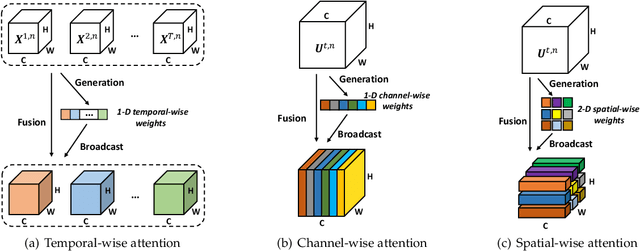
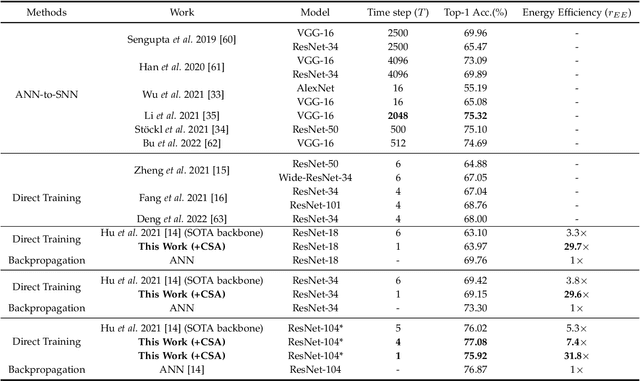
Benefiting from the event-driven and sparse spiking characteristics of the brain, spiking neural networks (SNNs) are becoming an energy-efficient alternative to artificial neural networks (ANNs). However, the performance gap between SNNs and ANNs has been a great hindrance to deploying SNNs ubiquitously for a long time. To leverage the full potential of SNNs, we study the effect of attention mechanisms in SNNs. We first present our idea of attention with a plug-and-play kit, termed the Multi-dimensional Attention (MA). Then, a new attention SNN architecture with end-to-end training called "MA-SNN" is proposed, which infers attention weights along the temporal, channel, as well as spatial dimensions separately or simultaneously. Based on the existing neuroscience theories, we exploit the attention weights to optimize membrane potentials, which in turn regulate the spiking response in a data-dependent way. At the cost of negligible additional parameters, MA facilitates vanilla SNNs to achieve sparser spiking activity, better performance, and energy efficiency concurrently. Experiments are conducted in event-based DVS128 Gesture/Gait action recognition and ImageNet-1k image classification. On Gesture/Gait, the spike counts are reduced by 84.9%/81.6%, and the task accuracy and energy efficiency are improved by 5.9%/4.7% and 3.4$\times$/3.2$\times$. On ImageNet-1K, we achieve top-1 accuracy of 75.92% and 77.08% on single/4-step Res-SNN-104, which are state-of-the-art results in SNNs. To our best knowledge, this is for the first time, that the SNN community achieves comparable or even better performance compared with its ANN counterpart in the large-scale dataset. Our work lights up SNN's potential as a general backbone to support various applications for SNNs, with a great balance between effectiveness and efficiency.
Analysing Statistical methods for Automatic Detection of Image Forgery
Nov 24, 2021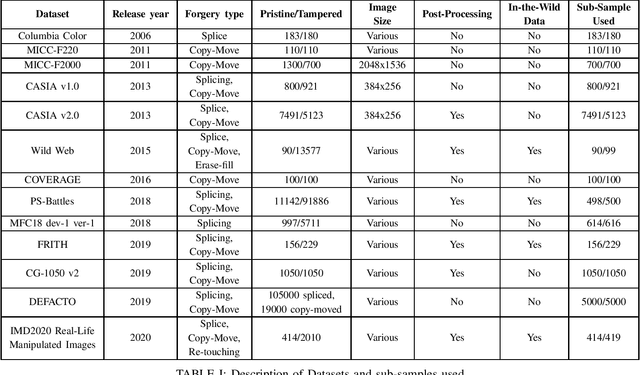
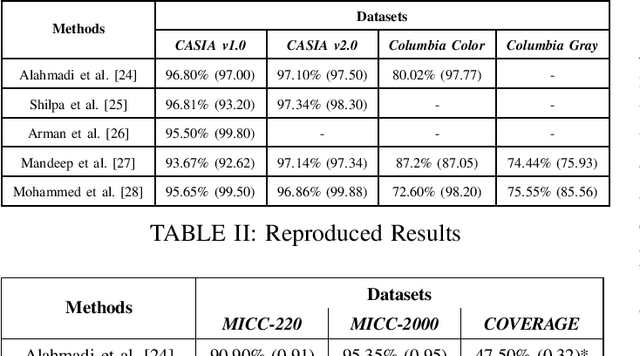
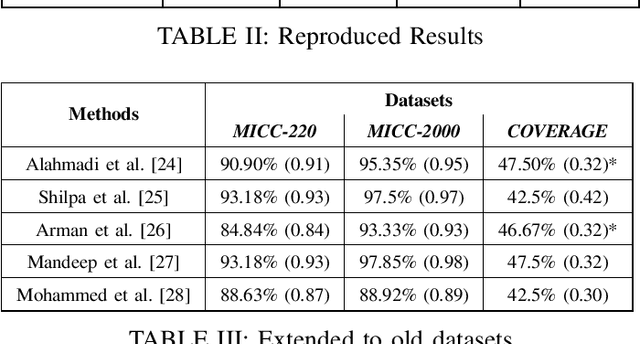
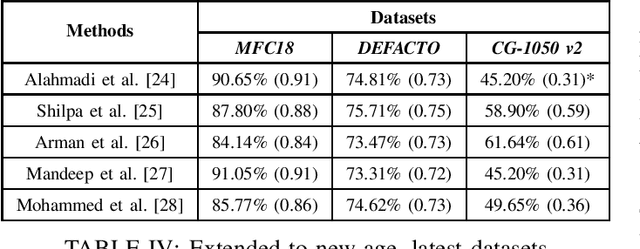
Image manipulation and forgery detection have been a topic of research for more than a decade now. New-age tools and large-scale social platforms have given space for manipulated media to thrive. These media can be potentially dangerous and thus innumerable methods have been designed and tested to prove their robustness in detecting forgery. However, the results reported by state-of-the-art systems indicate that supervised approaches achieve almost perfect performance but only with particular datasets. In this work, we analyze the issue of out-of-distribution generalisability of the current state-of-the-art image forgery detection techniques through several experiments. Our study focuses on models that utilise handcrafted features for image forgery detection. We show that the developed methods fail to perform well on cross-dataset evaluations and in-the-wild manipulated media. As a consequence, a question is raised about the current evaluation and overestimated performance of the systems under consideration. Note: This work was done during a summer research internship at ITMR Lab, IIIT-Allahabad under the supervision of Prof. Anupam Agarwal.
Curriculum-style Local-to-global Adaptation for Cross-domain Remote Sensing Image Segmentation
Mar 03, 2022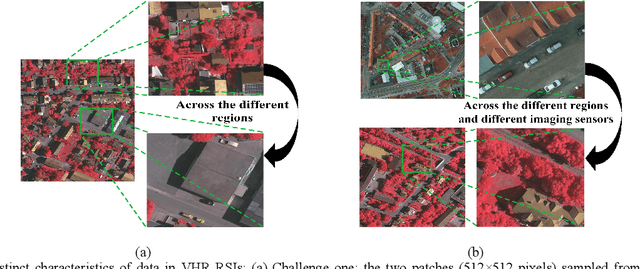
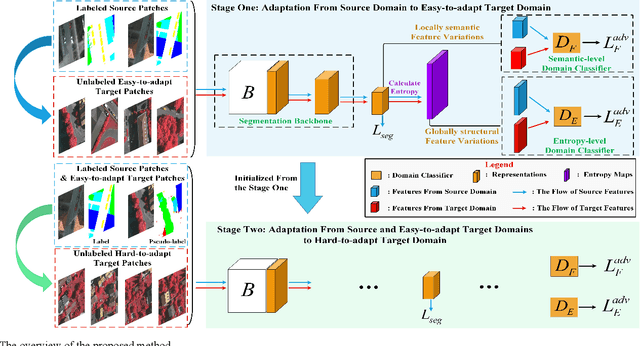
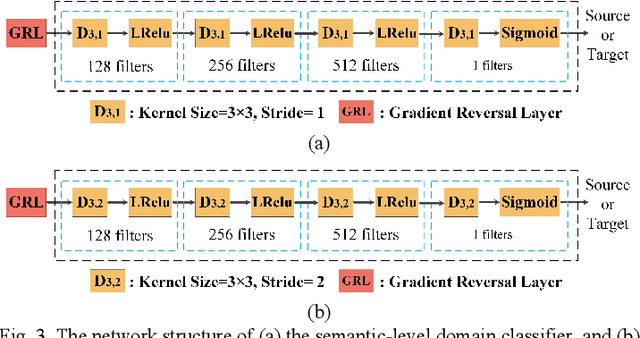
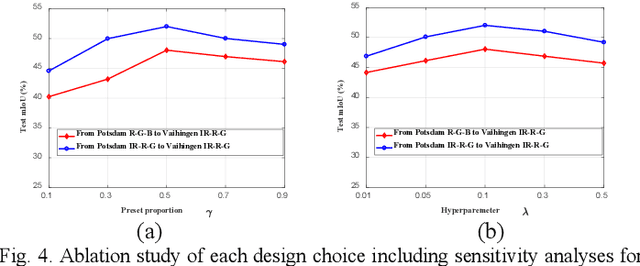
Although domain adaptation has been extensively studied in natural image-based segmentation task, the research on cross-domain segmentation for very high resolution (VHR) remote sensing images (RSIs) still remains underexplored. The VHR RSIs-based cross-domain segmentation mainly faces two critical challenges: 1) Large area land covers with many diverse object categories bring severe local patch-level data distribution deviations, thus yielding different adaptation difficulties for different local patches; 2) Different VHR sensor types or dynamically changing modes cause the VHR images to go through intensive data distribution differences even for the same geographical location, resulting in different global feature-level domain gap. To address these challenges, we propose a curriculum-style local-to-global cross-domain adaptation framework for the segmentation of VHR RSIs. The proposed curriculum-style adaptation performs the adaptation process in an easy-to-hard way according to the adaptation difficulties that can be obtained using an entropy-based score for each patch of the target domain, and thus well aligns the local patches in a domain image. The proposed local-to-global adaptation performs the feature alignment process from the locally semantic to globally structural feature discrepancies, and consists of a semantic-level domain classifier and an entropy-level domain classifier that can reduce the above cross-domain feature discrepancies. Extensive experiments have been conducted in various cross-domain scenarios, including geographic location variations and imaging mode variations, and the experimental results demonstrate that the proposed method can significantly boost the domain adaptability of segmentation networks for VHR RSIs. Our code is available at: https://github.com/BOBrown/CCDA_LGFA.