 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Constrained Sampling for Class-Agnostic Weakly Supervised Object Localization
Sep 09, 2022

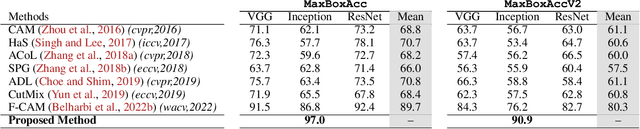
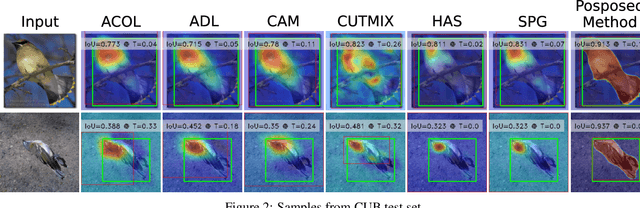
Self-supervised vision transformers can generate accurate localization maps of the objects in an image. However, since they decompose the scene into multiple maps containing various objects, and they do not rely on any explicit supervisory signal, they cannot distinguish between the object of interest from other objects, as required in weakly-supervised object localization (WSOL). To address this issue, we propose leveraging the multiple maps generated by the different transformer heads to acquire pseudo-labels for training a WSOL model. In particular, a new discriminative proposals sampling method is introduced that relies on a pretrained CNN classifier to identify discriminative regions. Then, foreground and background pixels are sampled from these regions in order to train a WSOL model for generating activation maps that can accurately localize objects belonging to a specific class. Empirical results on the challenging CUB benchmark dataset indicate that our proposed approach can outperform state-of-art methods over a wide range of threshold values. Our method provides class activation maps with a better coverage of foreground object regions w.r.t. the background.
Tilt-then-Blur or Blur-then-Tilt? Clarifying the Atmospheric Turbulence Model
Jul 13, 2022
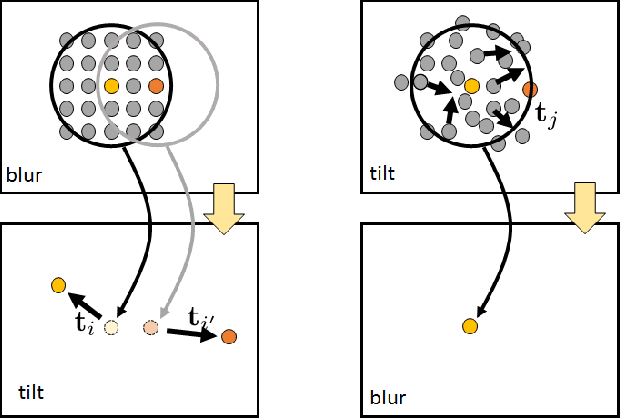

Imaging at a long distance often requires advanced image restoration algorithms to compensate for the distortions caused by atmospheric turbulence. However, unlike many standard restoration problems such as deconvolution, the forward image formation model of the atmospheric turbulence does not have a simple expression. Thanks to the Zernike representation of the phase, one can show that the forward model is a combination of tilt (pixel shifting due to the linear phase terms) and blur (image smoothing due to the high order aberrations). Confusions then arise between the ordering of the two operators. Should the model be tilt-then-blur, or blur-then-tilt? Some papers in the literature say that the model is tilt-then-blur, whereas more papers say that it is blur-then-tilt. This paper clarifies the differences between the two and discusses why the tilt-then-blur is the correct model. Recommendations are given to the research community.
PP-ShiTu: A Practical Lightweight Image Recognition System
Nov 01, 2021
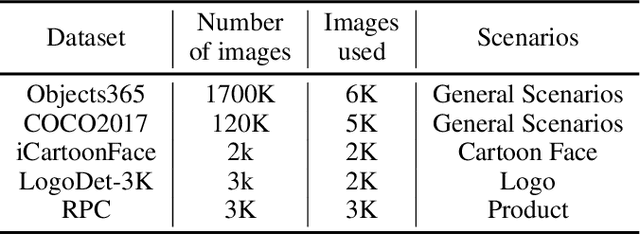
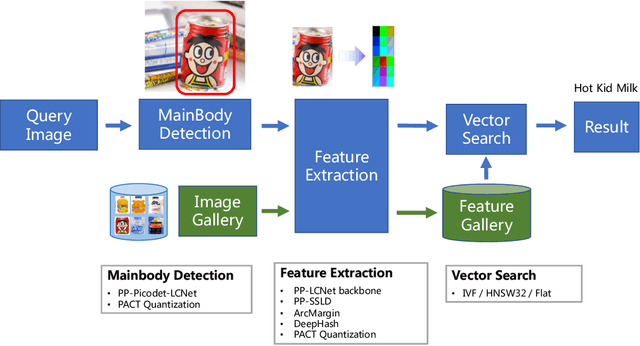
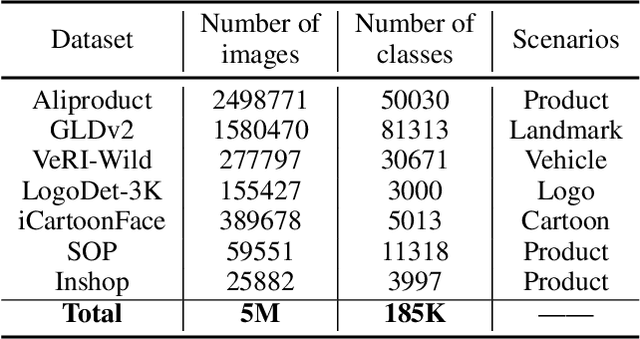
In recent years, image recognition applications have developed rapidly. A large number of studies and techniques have emerged in different fields, such as face recognition, pedestrian and vehicle re-identification, landmark retrieval, and product recognition. In this paper, we propose a practical lightweight image recognition system, named PP-ShiTu, consisting of the following 3 modules, mainbody detection, feature extraction and vector search. We introduce popular strategies including metric learning, deep hash, knowledge distillation and model quantization to improve accuracy and inference speed. With strategies above, PP-ShiTu works well in different scenarios with a set of models trained on a mixed dataset. Experiments on different datasets and benchmarks show that the system is widely effective in different domains of image recognition. All the above mentioned models are open-sourced and the code is available in the GitHub repository PaddleClas on PaddlePaddle.
A Study on the Efficient Product Search Service for the Damaged Image Information
Nov 14, 2021
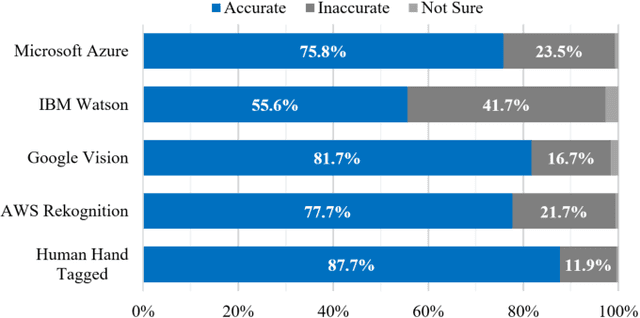

With the development of Information and Communication Technologies and the dissemination of smartphones, especially now that image search is possible through the internet, e-commerce markets are more activating purchasing services for a wide variety of products. However, it often happens that the image of the desired product is impaired and that the search engine does not recognize it properly. The idea of this study is to help search for products through image restoration using an image pre-processing and image inpainting algorithm for damaged images. It helps users easily purchase the items they want by providing a more accurate image search system. Besides, the system has the advantage of efficiently showing information by category, so that enables efficient sales of registered information.
Continual Learning with Dependency Preserving Hypernetworks
Sep 16, 2022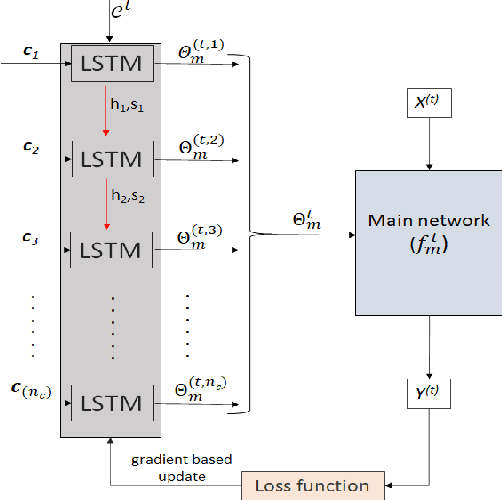
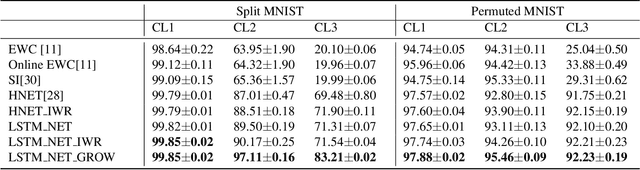
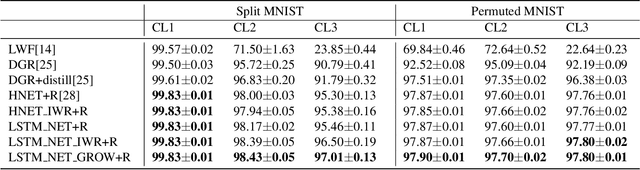
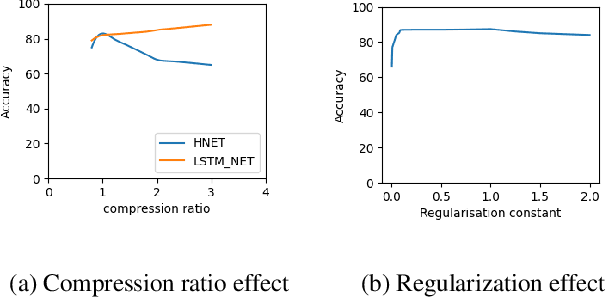
Humans learn continually throughout their lifespan by accumulating diverse knowledge and fine-tuning it for future tasks. When presented with a similar goal, neural networks suffer from catastrophic forgetting if data distributions across sequential tasks are not stationary over the course of learning. An effective approach to address such continual learning (CL) problems is to use hypernetworks which generate task dependent weights for a target network. However, the continual learning performance of existing hypernetwork based approaches are affected by the assumption of independence of the weights across the layers in order to maintain parameter efficiency. To address this limitation, we propose a novel approach that uses a dependency preserving hypernetwork to generate weights for the target network while also maintaining the parameter efficiency. We propose to use recurrent neural network (RNN) based hypernetwork that can generate layer weights efficiently while allowing for dependencies across them. In addition, we propose novel regularisation and network growth techniques for the RNN based hypernetwork to further improve the continual learning performance. To demonstrate the effectiveness of the proposed methods, we conducted experiments on several image classification continual learning tasks and settings. We found that the proposed methods based on the RNN hypernetworks outperformed the baselines in all these CL settings and tasks.
Discriminative Sampling of Proposals in Self-Supervised Transformers for Weakly Supervised Object Localization
Sep 09, 2022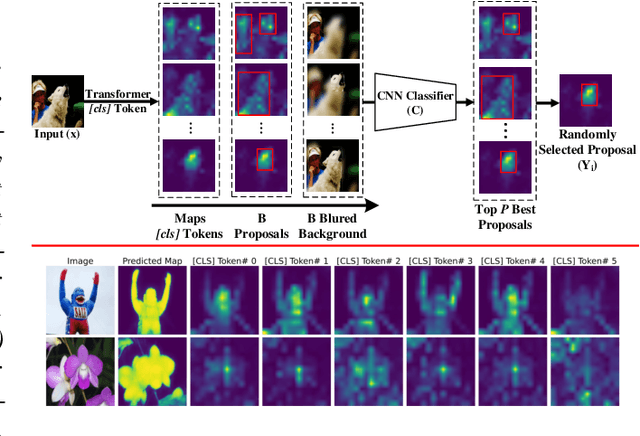
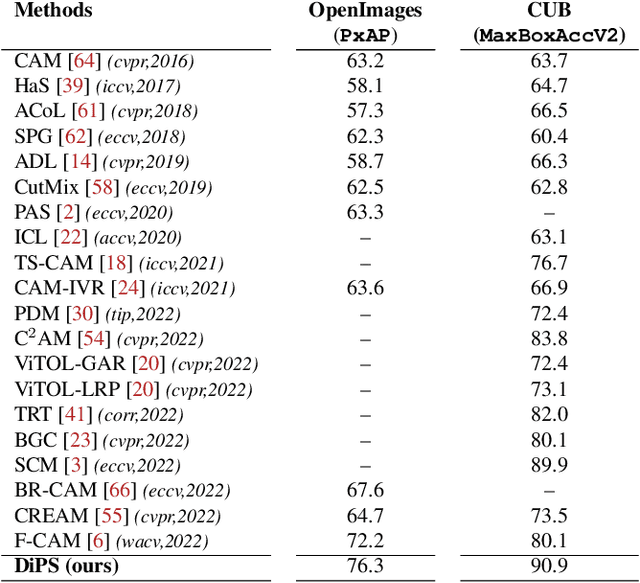
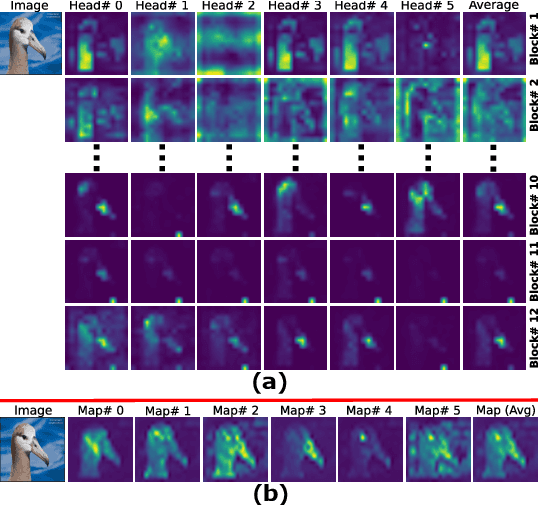
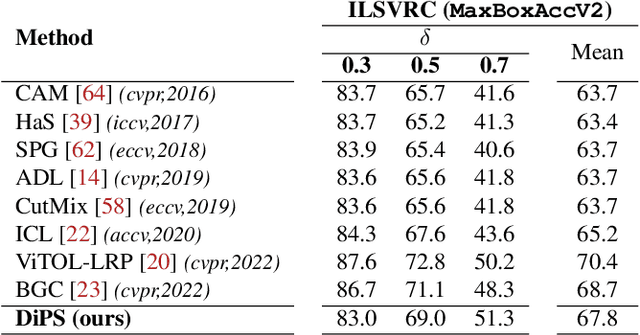
Self-supervised vision transformers can generate accurate localization maps of the objects in an image. However, since they decompose the scene into multiple maps containing various objects, and they do not rely on any explicit supervisory signal, they cannot distinguish between the object of interest from other objects, as required in weakly-supervised object localization (WSOL). To address this issue, we propose leveraging the multiple maps generated by the different transformer heads to acquire pseudo-labels for training a WSOL model. In particular, a new Discriminative Proposals Sampling (DiPS) method is introduced that relies on a pretrained CNN classifier to identify discriminative regions. Then, foreground and background pixels are sampled from these regions in order to train a WSOL model for generating activation maps that can accurately localize objects belonging to a specific class. Empirical results on the challenging CUB, OpenImages, and ILSVRC benchmark datasets indicate that our proposed approach can outperform state-of-art methods over a wide range of threshold values. DiPS provides class activation maps with a better coverage of foreground object regions w.r.t. the background.
CMA-CLIP: Cross-Modality Attention CLIP for Image-Text Classification
Dec 09, 2021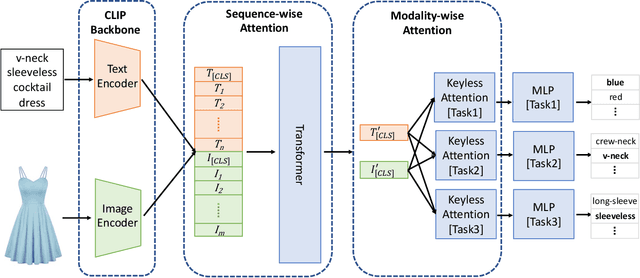

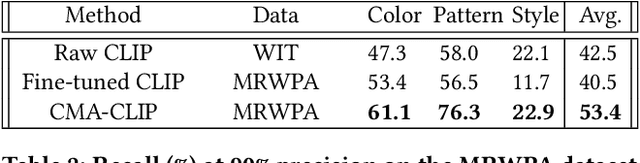

Modern Web systems such as social media and e-commerce contain rich contents expressed in images and text. Leveraging information from multi-modalities can improve the performance of machine learning tasks such as classification and recommendation. In this paper, we propose the Cross-Modality Attention Contrastive Language-Image Pre-training (CMA-CLIP), a new framework which unifies two types of cross-modality attentions, sequence-wise attention and modality-wise attention, to effectively fuse information from image and text pairs. The sequence-wise attention enables the framework to capture the fine-grained relationship between image patches and text tokens, while the modality-wise attention weighs each modality by its relevance to the downstream tasks. In addition, by adding task specific modality-wise attentions and multilayer perceptrons, our proposed framework is capable of performing multi-task classification with multi-modalities. We conduct experiments on a Major Retail Website Product Attribute (MRWPA) dataset and two public datasets, Food101 and Fashion-Gen. The results show that CMA-CLIP outperforms the pre-trained and fine-tuned CLIP by an average of 11.9% in recall at the same level of precision on the MRWPA dataset for multi-task classification. It also surpasses the state-of-the-art method on Fashion-Gen Dataset by 5.5% in accuracy and achieves competitive performance on Food101 Dataset. Through detailed ablation studies, we further demonstrate the effectiveness of both cross-modality attention modules and our method's robustness against noise in image and text inputs, which is a common challenge in practice.
A Deep Learning-based Audio-in-Image Watermarking Scheme
Oct 06, 2021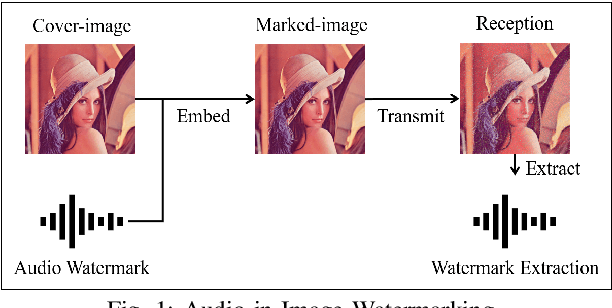
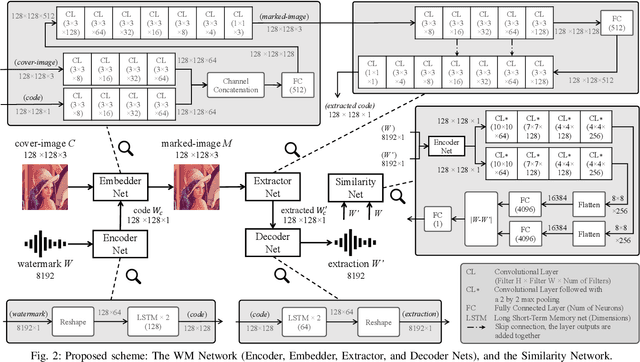
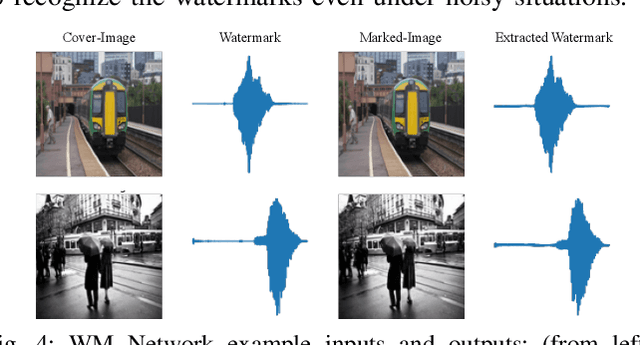
This paper presents a deep learning-based audio-in-image watermarking scheme. Audio-in-image watermarking is the process of covertly embedding and extracting audio watermarks on a cover-image. Using audio watermarks can open up possibilities for different downstream applications. For the purpose of implementing an audio-in-image watermarking that adapts to the demands of increasingly diverse situations, a neural network architecture is designed to automatically learn the watermarking process in an unsupervised manner. In addition, a similarity network is developed to recognize the audio watermarks under distortions, therefore providing robustness to the proposed method. Experimental results have shown high fidelity and robustness of the proposed blind audio-in-image watermarking scheme.
A Lightweight Machine Learning Pipeline for LiDAR-simulation
Aug 05, 2022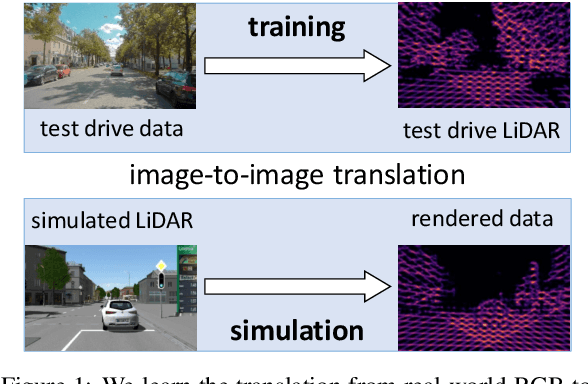
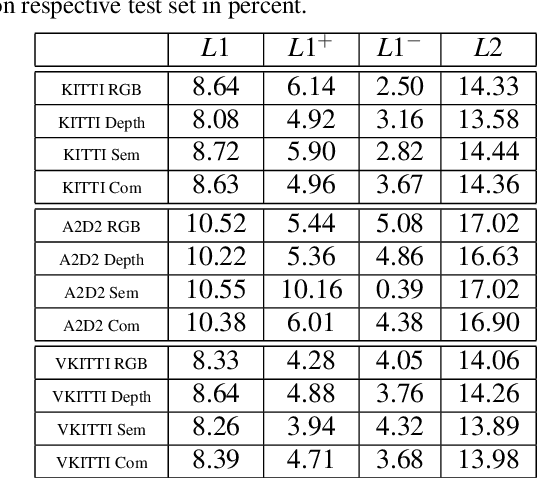
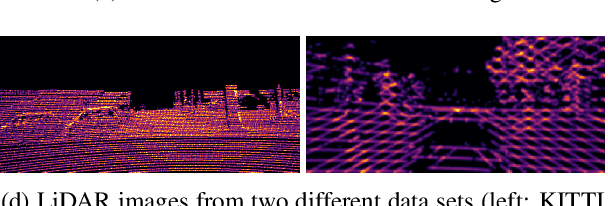
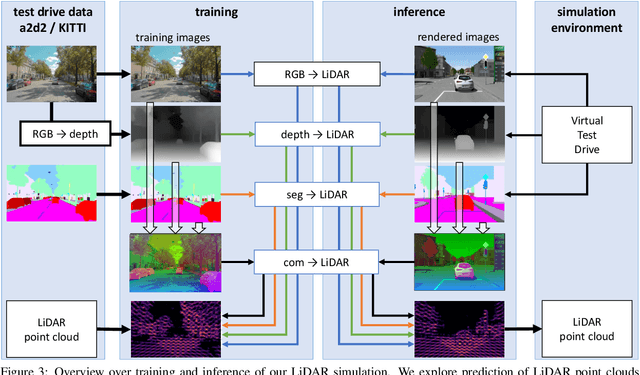
Virtual testing is a crucial task to ensure safety in autonomous driving, and sensor simulation is an important task in this domain. Most current LiDAR simulations are very simplistic and are mainly used to perform initial tests, while the majority of insights are gathered on the road. In this paper, we propose a lightweight approach for more realistic LiDAR simulation that learns a real sensor's behavior from test drive data and transforms this to the virtual domain. The central idea is to cast the simulation into an image-to-image translation problem. We train our pix2pix based architecture on two real world data sets, namely the popular KITTI data set and the Audi Autonomous Driving Dataset which provide both, RGB and LiDAR images. We apply this network on synthetic renderings and show that it generalizes sufficiently from real images to simulated images. This strategy enables to skip the sensor-specific, expensive and complex LiDAR physics simulation in our synthetic world and avoids oversimplification and a large domain-gap through the clean synthetic environment.
* Conference: DeLTA 22; ISBN 978-989-758-584-5; ISSN 2184-9277; publisher: SciTePress, organization: INSTICC
Class-Level Logit Perturbation
Sep 13, 2022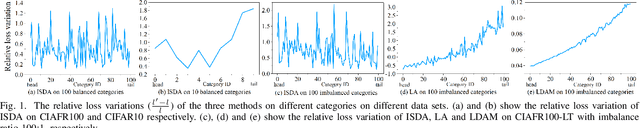

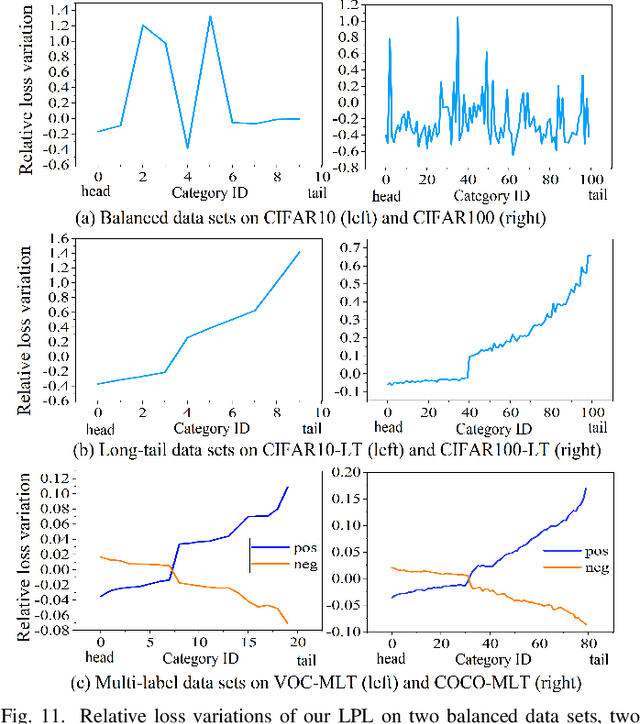
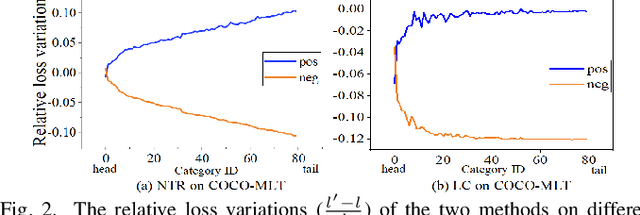
Features, logits, and labels are the three primary data when a sample passes through a deep neural network. Feature perturbation and label perturbation receive increasing attention in recent years. They have been proven to be useful in various deep learning approaches. For example, (adversarial) feature perturbation can improve the robustness or even generalization capability of learned models. However, limited studies have explicitly explored for the perturbation of logit vectors. This work discusses several existing methods related to class-level logit perturbation. A unified viewpoint between positive/negative data augmentation and loss variations incurred by logit perturbation is established. A theoretical analysis is provided to illuminate why class-level logit perturbation is useful. Accordingly, new methodologies are proposed to explicitly learn to perturb logits for both single-label and multi-label classification tasks. Extensive experiments on benchmark image classification data sets and their long-tail versions indicated the competitive performance of our learning method. As it only perturbs on logit, it can be used as a plug-in to fuse with any existing classification algorithms. All the codes are available at https://github.com/limengyang1992/lpl.