 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
VISTA: Vision Transformer enhanced by U-Net and Image Colorfulness Frame Filtration for Automatic Retail Checkout
Apr 23, 2022


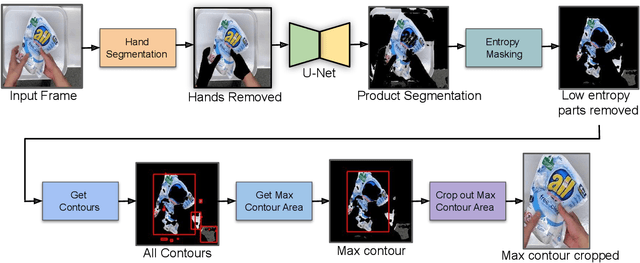
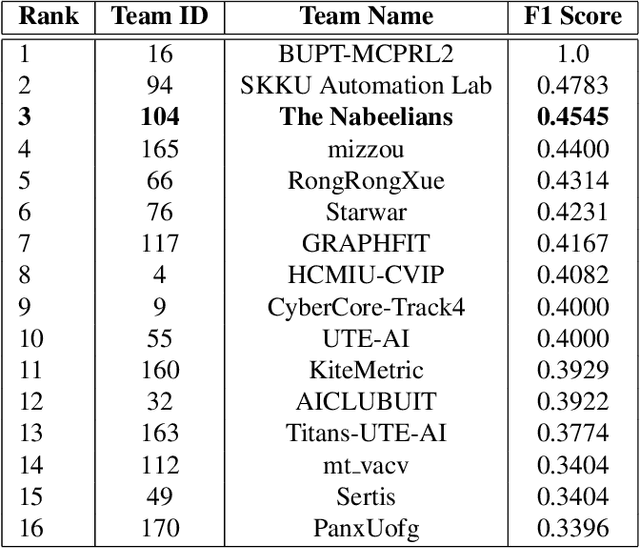
Multi-class product counting and recognition identifies product items from images or videos for automated retail checkout. The task is challenging due to the real-world scenario of occlusions where product items overlap, fast movement in the conveyor belt, large similarity in overall appearance of the items being scanned, novel products, and the negative impact of misidentifying items. Further, there is a domain bias between training and test sets, specifically, the provided training dataset consists of synthetic images and the test set videos consist of foreign objects such as hands and tray. To address these aforementioned issues, we propose to segment and classify individual frames from a video sequence. The segmentation method consists of a unified single product item- and hand-segmentation followed by entropy masking to address the domain bias problem. The multi-class classification method is based on Vision Transformers (ViT). To identify the frames with target objects, we utilize several image processing methods and propose a custom metric to discard frames not having any product items. Combining all these mechanisms, our best system achieves 3rd place in the AI City Challenge 2022 Track 4 with an F1 score of 0.4545. Code will be available at
Estimating the Direction and Radius of Pipe from GPR Image by Ellipse Inversion Model
Jan 25, 2022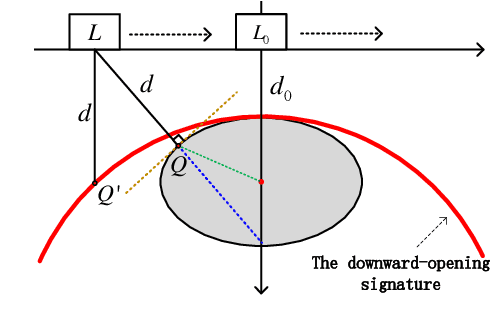
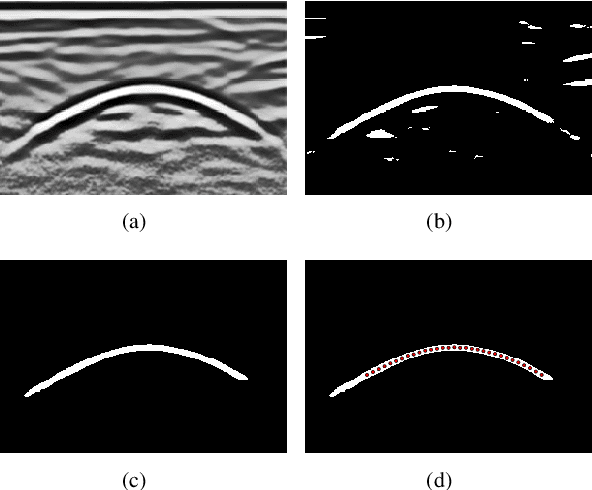
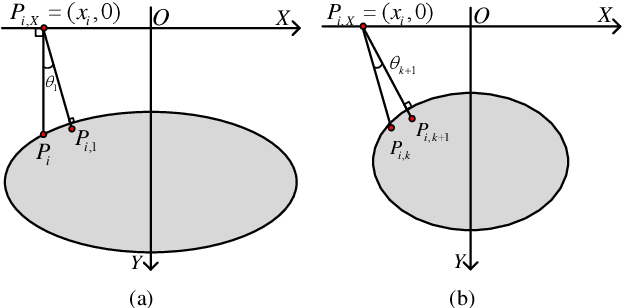
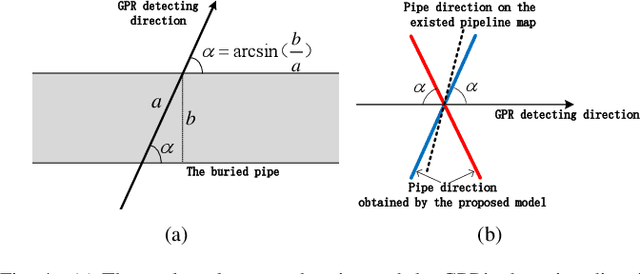
Ground Penetrating Radar (GPR) is widely used as a non-destructive approach to estimate buried utilities. When the GPR's detecting direction is perpendicular to a pipeline, a hyperbolic characteristic would be formed on the GPR B-scan image. However, in real-world applications, the direction of pipelines on the existing pipeline map could be inaccurate, and it is hard to ensure the moving direction of GPR to be actually perpendicular to underground pipelines. In this paper, a novel model is proposed to estimate the direction and radius of pipeline and revise the existing pipeline map from GPR B-scan images. The model consists of two parts: GPR B-scan image processing and Ellipse Iterative Inversion Algorithm (EIIA). Firstly, the GPR B-scan image is processed with downward-opening point set extracted. The obtained point set is then iteratively inverted to the elliptical cross section of the buried pipeline, which is caused by the angle between the GPR's detecting direction and the pipeline's direction. By minimizing the sum of the algebraic distances from the extracted point set to the inverted ellipse, the most likely pipeline's direction and radius are determined. Experiments on real-world datasets are conducted, and the results demonstrate the effectiveness of the method.
Warm Start Active Learning with Proxy Labels \& Selection via Semi-Supervised Fine-Tuning
Sep 13, 2022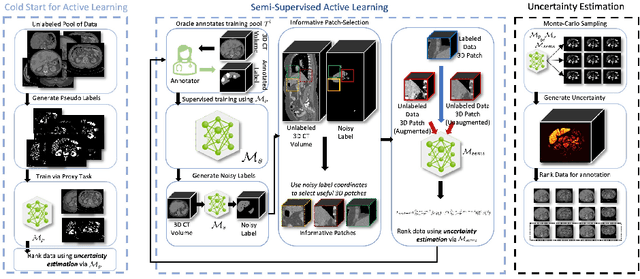
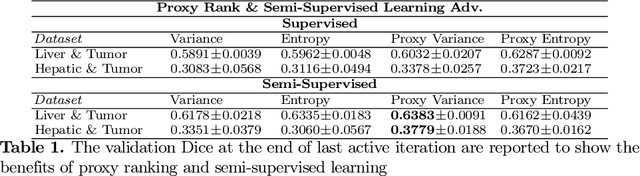
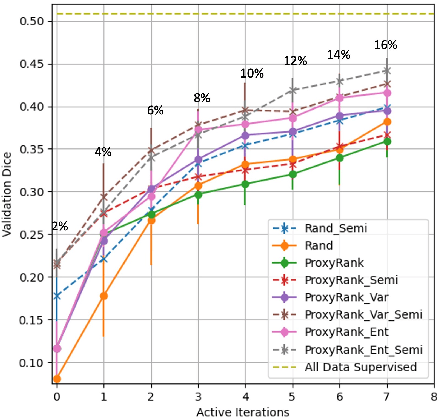
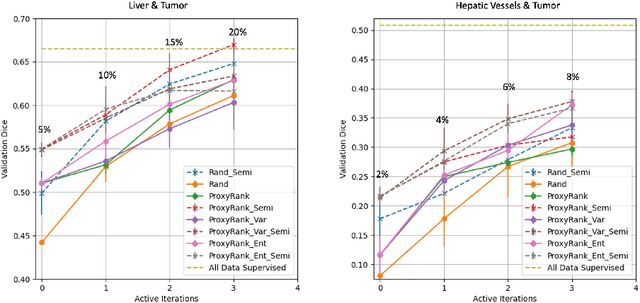
Which volume to annotate next is a challenging problem in building medical imaging datasets for deep learning. One of the promising methods to approach this question is active learning (AL). However, AL has been a hard nut to crack in terms of which AL algorithm and acquisition functions are most useful for which datasets. Also, the problem is exacerbated with which volumes to label first when there is zero labeled data to start with. This is known as the cold start problem in AL. We propose two novel strategies for AL specifically for 3D image segmentation. First, we tackle the cold start problem by proposing a proxy task and then utilizing uncertainty generated from the proxy task to rank the unlabeled data to be annotated. Second, we craft a two-stage learning framework for each active iteration where the unlabeled data is also used in the second stage as a semi-supervised fine-tuning strategy. We show the promise of our approach on two well-known large public datasets from medical segmentation decathlon. The results indicate that the initial selection of data and semi-supervised framework both showed significant improvement for several AL strategies.
FixMatchSeg: Fixing FixMatch for Semi-Supervised Semantic Segmentation
Aug 02, 2022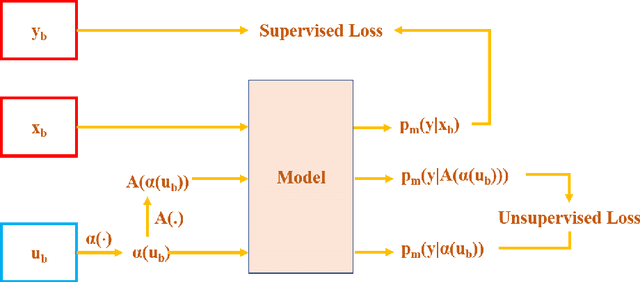
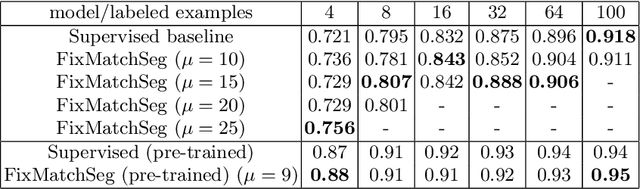
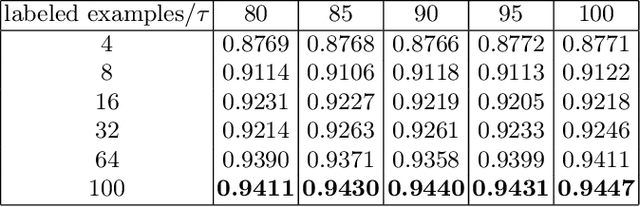
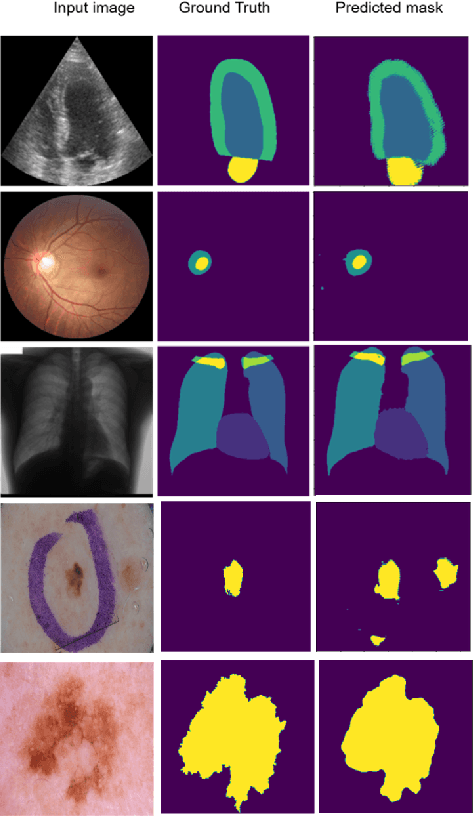
Supervised deep learning methods for semantic medical image segmentation are getting increasingly popular in the past few years.However, in resource constrained settings, getting large number of annotated images is very difficult as it mostly requires experts, is expensive and time-consuming.Semi-supervised segmentation can be an attractive solution where a very few labeled images are used along with a large number of unlabeled ones. While the gap between supervised and semi-supervised methods have been dramatically reduced for classification problems in the past couple of years, there still remains a larger gap in segmentation methods. In this work, we adapt a state-of-the-art semi-supervised classification method FixMatch to semantic segmentation task, introducing FixMatchSeg. FixMatchSeg is evaluated in four different publicly available datasets of different anatomy and different modality: cardiac ultrasound, chest X-ray, retinal fundus image, and skin images. When there are few labels, we show that FixMatchSeg performs on par with strong supervised baselines.
DID-M3D: Decoupling Instance Depth for Monocular 3D Object Detection
Jul 18, 2022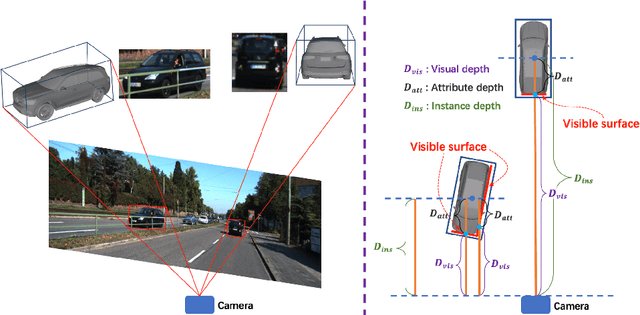
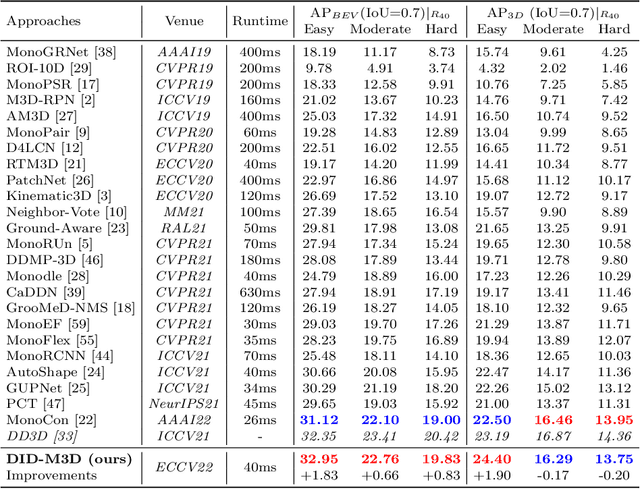
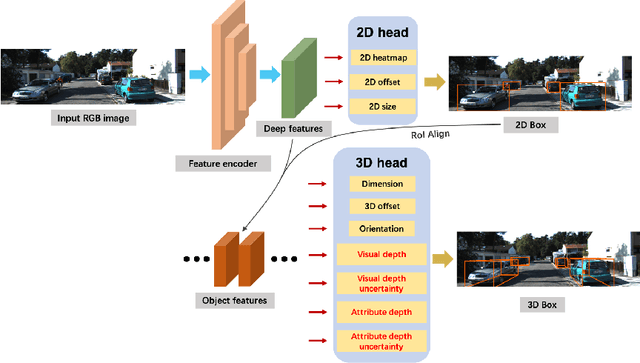

Monocular 3D detection has drawn much attention from the community due to its low cost and setup simplicity. It takes an RGB image as input and predicts 3D boxes in the 3D space. The most challenging sub-task lies in the instance depth estimation. Previous works usually use a direct estimation method. However, in this paper we point out that the instance depth on the RGB image is non-intuitive. It is coupled by visual depth clues and instance attribute clues, making it hard to be directly learned in the network. Therefore, we propose to reformulate the instance depth to the combination of the instance visual surface depth (visual depth) and the instance attribute depth (attribute depth). The visual depth is related to objects' appearances and positions on the image. By contrast, the attribute depth relies on objects' inherent attributes, which are invariant to the object affine transformation on the image. Correspondingly, we decouple the 3D location uncertainty into visual depth uncertainty and attribute depth uncertainty. By combining different types of depths and associated uncertainties, we can obtain the final instance depth. Furthermore, data augmentation in monocular 3D detection is usually limited due to the physical nature, hindering the boost of performance. Based on the proposed instance depth disentanglement strategy, we can alleviate this problem. Evaluated on KITTI, our method achieves new state-of-the-art results, and extensive ablation studies validate the effectiveness of each component in our method. The codes are released at https://github.com/SPengLiang/DID-M3D.
Estimating MRI Image Quality via Image Reconstruction Uncertainty
Jun 21, 2021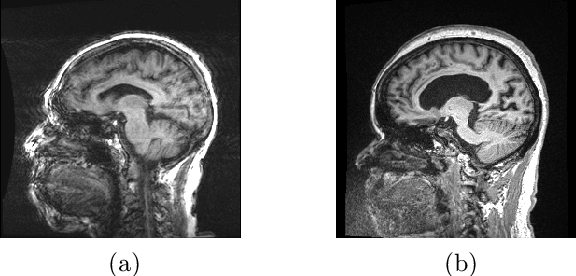
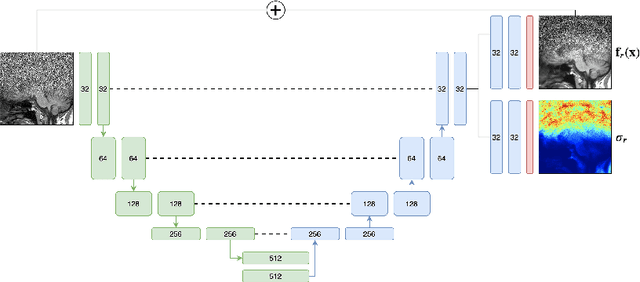
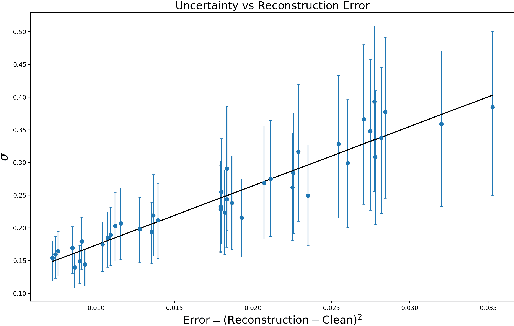
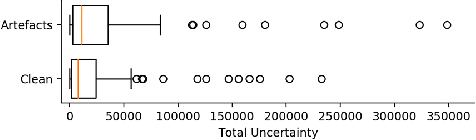
Quality control (QC) in medical image analysis is time-consuming and laborious, leading to increased interest in automated methods. However, what is deemed suitable quality for algorithmic processing may be different from human-perceived measures of visual quality. In this work, we pose MR image quality assessment from an image reconstruction perspective. We train Bayesian CNNs using a heteroscedastic uncertainty model to recover clean images from noisy data, providing measures of uncertainty over the predictions. This framework enables us to divide data corruption into learnable and non-learnable components and leads us to interpret the predictive uncertainty as an estimation of the achievable recovery of an image. Thus, we argue that quality control for visual assessment cannot be equated to quality control for algorithmic processing. We validate this statement in a multi-task experiment combining artefact recovery with uncertainty prediction and grey matter segmentation. Recognising this distinction between visual and algorithmic quality has the impact that, depending on the downstream task, less data can be excluded based on ``visual quality" reasons alone.
Object-Level Targeted Selection via Deep Template Matching
Jul 05, 2022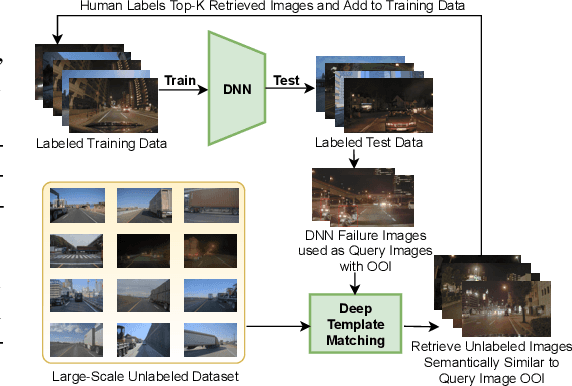
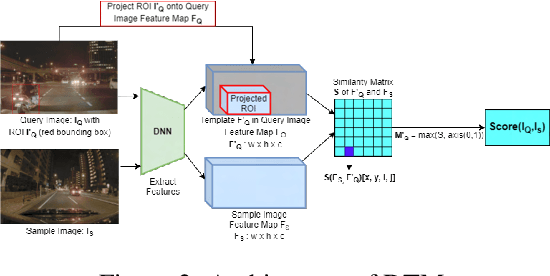
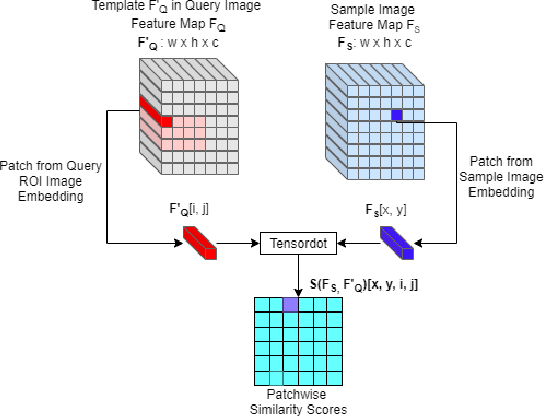
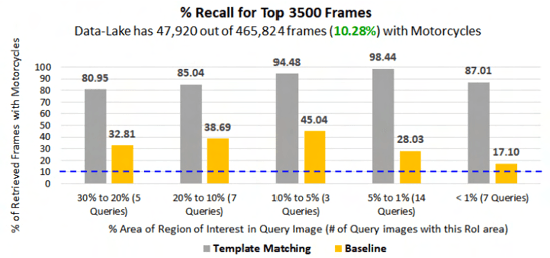
Retrieving images with objects that are semantically similar to objects of interest (OOI) in a query image has many practical use cases. A few examples include fixing failures like false negatives/positives of a learned model or mitigating class imbalance in a dataset. The targeted selection task requires finding the relevant data from a large-scale pool of unlabeled data. Manual mining at this scale is infeasible. Further, the OOI are often small and occupy less than 1% of image area, are occluded, and co-exist with many semantically different objects in cluttered scenes. Existing semantic image retrieval methods often focus on mining for larger sized geographical landmarks, and/or require extra labeled data, such as images/image-pairs with similar objects, for mining images with generic objects. We propose a fast and robust template matching algorithm in the DNN feature space, that retrieves semantically similar images at the object-level from a large unlabeled pool of data. We project the region(s) around the OOI in the query image to the DNN feature space for use as the template. This enables our method to focus on the semantics of the OOI without requiring extra labeled data. In the context of autonomous driving, we evaluate our system for targeted selection by using failure cases of object detectors as OOI. We demonstrate its efficacy on a large unlabeled dataset with 2.2M images and show high recall in mining for images with small-sized OOI. We compare our method against a well-known semantic image retrieval method, which also does not require extra labeled data. Lastly, we show that our method is flexible and retrieves images with one or more semantically different co-occurring OOI seamlessly.
StyleSwin: Transformer-based GAN for High-resolution Image Generation
Dec 20, 2021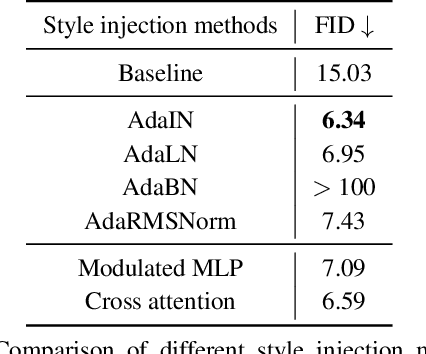
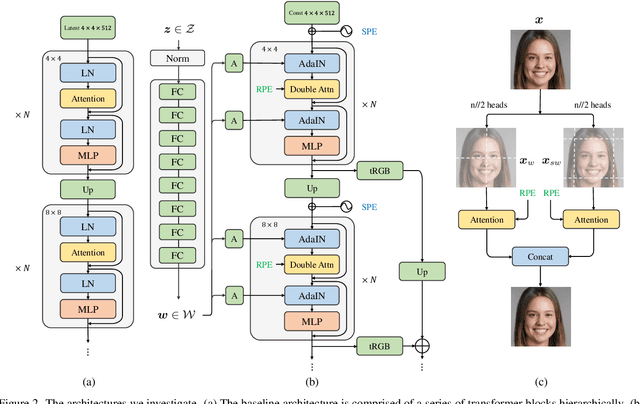
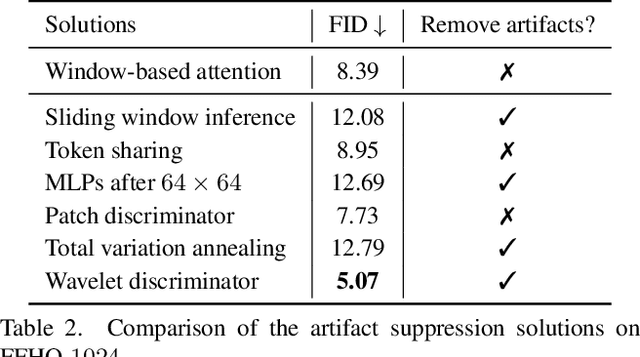

Despite the tantalizing success in a broad of vision tasks, transformers have not yet demonstrated on-par ability as ConvNets in high-resolution image generative modeling. In this paper, we seek to explore using pure transformers to build a generative adversarial network for high-resolution image synthesis. To this end, we believe that local attention is crucial to strike the balance between computational efficiency and modeling capacity. Hence, the proposed generator adopts Swin transformer in a style-based architecture. To achieve a larger receptive field, we propose double attention which simultaneously leverages the context of the local and the shifted windows, leading to improved generation quality. Moreover, we show that offering the knowledge of the absolute position that has been lost in window-based transformers greatly benefits the generation quality. The proposed StyleSwin is scalable to high resolutions, with both the coarse geometry and fine structures benefit from the strong expressivity of transformers. However, blocking artifacts occur during high-resolution synthesis because performing the local attention in a block-wise manner may break the spatial coherency. To solve this, we empirically investigate various solutions, among which we find that employing a wavelet discriminator to examine the spectral discrepancy effectively suppresses the artifacts. Extensive experiments show the superiority over prior transformer-based GANs, especially on high resolutions, e.g., 1024x1024. The StyleSwin, without complex training strategies, excels over StyleGAN on CelebA-HQ 1024, and achieves on-par performance on FFHQ-1024, proving the promise of using transformers for high-resolution image generation. The code and models will be available at https://github.com/microsoft/StyleSwin.
Attack as the Best Defense: Nullifying Image-to-image Translation GANs via Limit-aware Adversarial Attack
Oct 06, 2021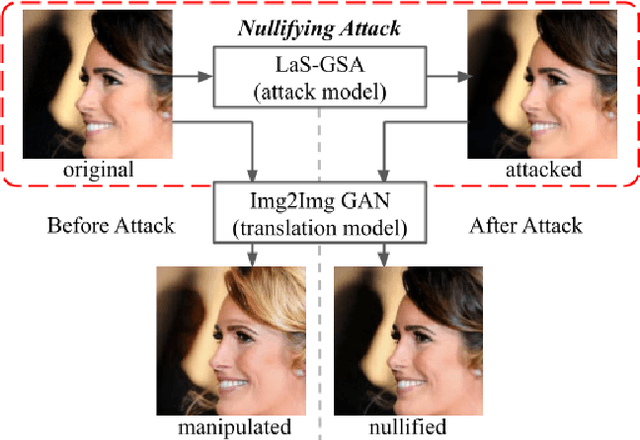
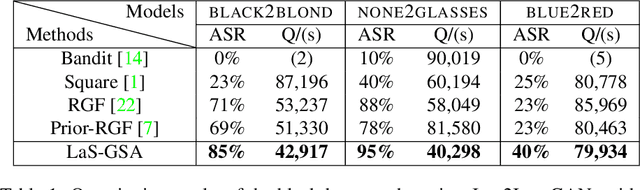
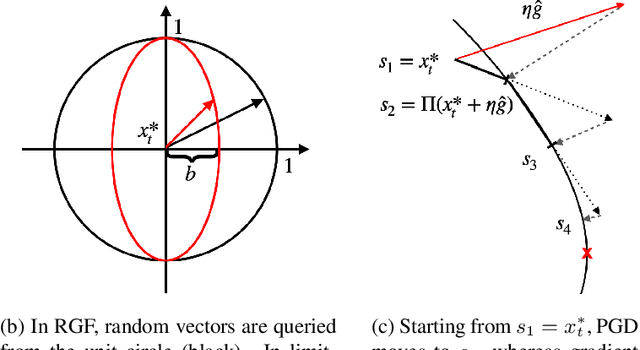

With the successful creation of high-quality image-to-image (Img2Img) translation GANs comes the non-ethical applications of DeepFake and DeepNude. Such misuses of img2img techniques present a challenging problem for society. In this work, we tackle the problem by introducing the Limit-Aware Self-Guiding Gradient Sliding Attack (LaS-GSA). LaS-GSA follows the Nullifying Attack to cancel the img2img translation process under a black-box setting. In other words, by processing input images with the proposed LaS-GSA before publishing, any targeted img2img GANs can be nullified, preventing the model from maliciously manipulating the images. To improve efficiency, we introduce the limit-aware random gradient-free estimation and the gradient sliding mechanism to estimate the gradient that adheres to the adversarial limit, i.e., the pixel value limitations of the adversarial example. Theoretical justifications validate how the above techniques prevent inefficiency caused by the adversarial limit in both the direction and the step length. Furthermore, an effective self-guiding prior is extracted solely from the threat model and the target image to efficiently leverage the prior information and guide the gradient estimation process. Extensive experiments demonstrate that LaS-GSA requires fewer queries to nullify the image translation process with higher success rates than 4 state-of-the-art black-box methods.
Global and Local Features through Gaussian Mixture Models on Image Semantic Segmentation
Jul 19, 2022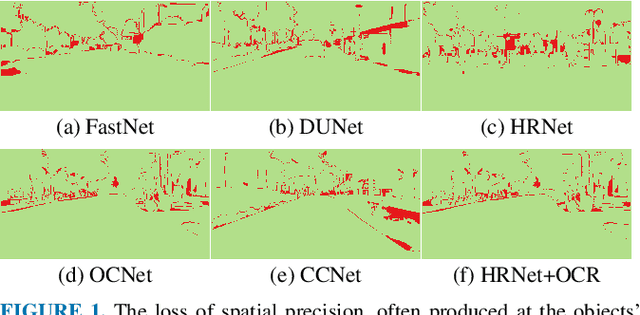
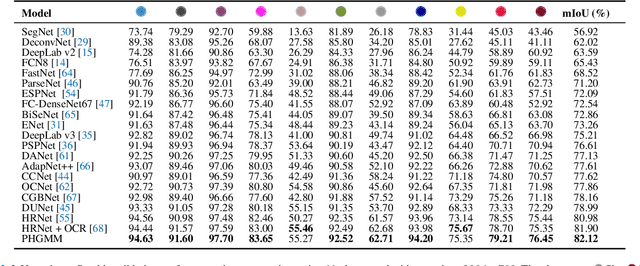
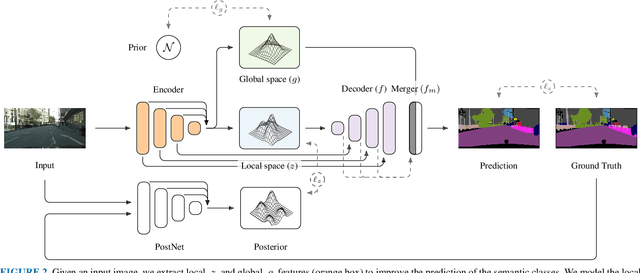
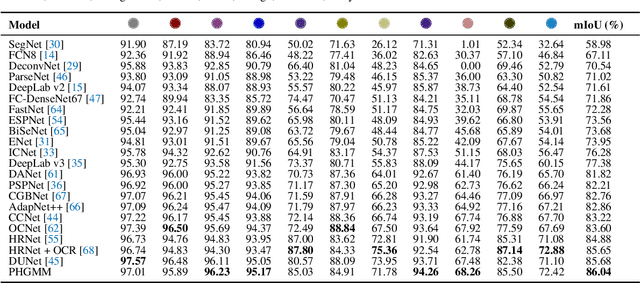
The semantic segmentation task aims at dense classification at the pixel-wise level. Deep models exhibited progress in tackling this task. However, one remaining problem with these approaches is the loss of spatial precision, often produced at the segmented objects' boundaries. Our proposed model addresses this problem by providing an internal structure for the feature representations while extracting a global representation that supports the former. To fit the internal structure, during training, we predict a Gaussian Mixture Model from the data, which, merged with the skip connections and the decoding stage, helps avoid wrong inductive biases. Furthermore, our results show that we can improve semantic segmentation by providing both learning representations (global and local) with a clustering behavior and combining them. Finally, we present results demonstrating our advances in Cityscapes and Synthia datasets.