 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Multimodal Learning with Channel-Mixing and Masked Autoencoder on Facial Action Unit Detection
Sep 25, 2022
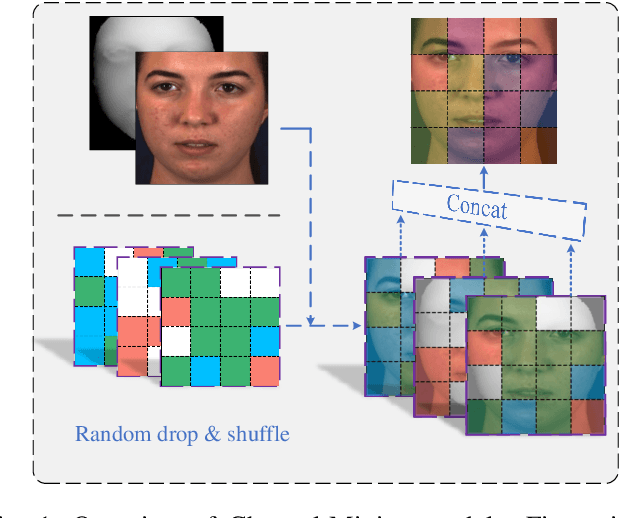
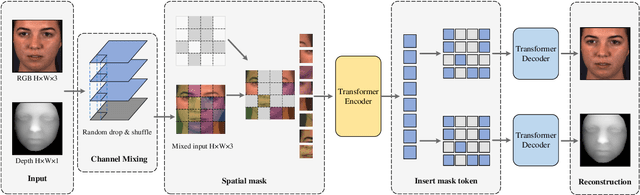
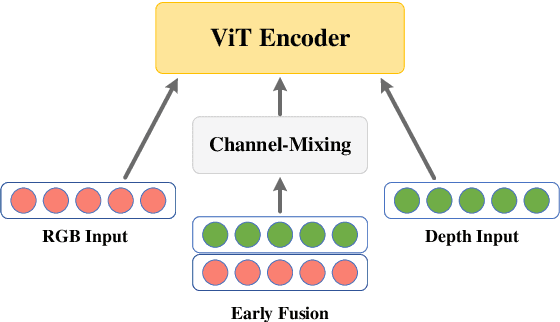

Recent studies utilizing multi-modal data aimed at building a robust model for facial Action Unit (AU) detection. However, due to the heterogeneity of multi-modal data, multi-modal representation learning becomes one of the main challenges. On one hand, it is difficult to extract the relevant features from multi-modalities by only one feature extractor, on the other hand, previous studies have not fully explored the potential of multi-modal fusion strategies. For example, early fusion usually required all modalities to be present during inference, while late fusion and middle fusion increased the network size for feature learning. In contrast to a large amount of work on late fusion, there are few works on early fusion to explore the channel information. This paper presents a novel multi-modal network called Multi-modal Channel-Mixing (MCM), as a pre-trained model to learn a robust representation in order to facilitate the multi-modal fusion. We evaluate the learned representation on a downstream task of automatic facial action units detection. Specifically, it is a single stream encoder network that uses a channel-mixing module in early fusion, requiring only one modality in the downstream detection task. We also utilize the masked ViT encoder to learn features from the fusion image and reconstruct back two modalities with two ViT decoders. We have conducted extensive experiments on two public datasets, known as BP4D and DISFA, to evaluate the effectiveness and robustness of the proposed multimodal framework. The results show our approach is comparable or superior to the state-of-the-art baseline methods.
StyleMC: Multi-Channel Based Fast Text-Guided Image Generation and Manipulation
Dec 15, 2021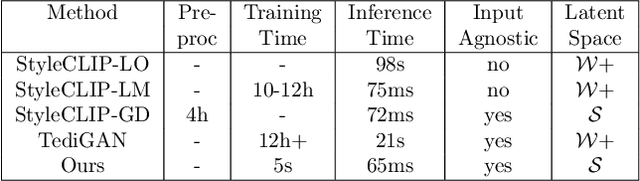
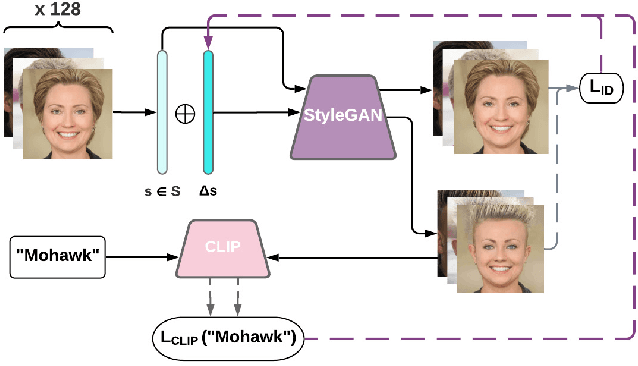


Discovering meaningful directions in the latent space of GANs to manipulate semantic attributes typically requires large amounts of labeled data. Recent work aims to overcome this limitation by leveraging the power of Contrastive Language-Image Pre-training (CLIP), a joint text-image model. While promising, these methods require several hours of preprocessing or training to achieve the desired manipulations. In this paper, we present StyleMC, a fast and efficient method for text-driven image generation and manipulation. StyleMC uses a CLIP-based loss and an identity loss to manipulate images via a single text prompt without significantly affecting other attributes. Unlike prior work, StyleMC requires only a few seconds of training per text prompt to find stable global directions, does not require prompt engineering and can be used with any pre-trained StyleGAN2 model. We demonstrate the effectiveness of our method and compare it to state-of-the-art methods. Our code can be found at http://catlab-team.github.io/stylemc.
Approaching the Limit of Image Rescaling via Flow Guidance
Nov 09, 2021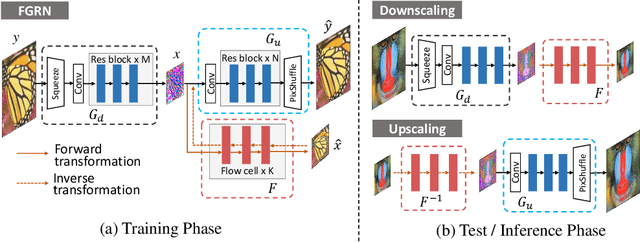
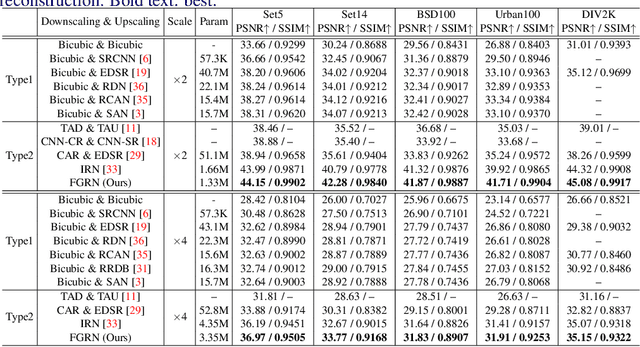
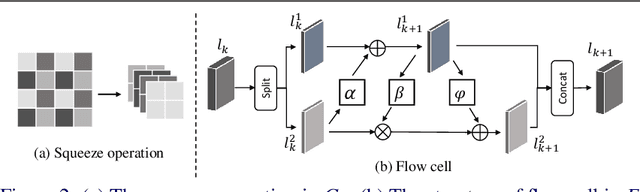
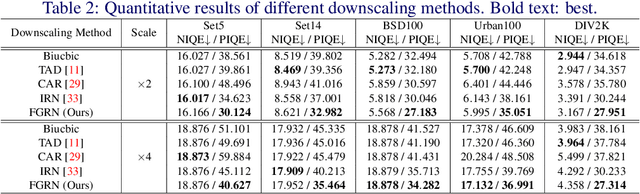
Image downscaling and upscaling are two basic rescaling operations. Once the image is downscaled, it is difficult to be reconstructed via upscaling due to the loss of information. To make these two processes more compatible and improve the reconstruction performance, some efforts model them as a joint encoding-decoding task, with the constraint that the downscaled (i.e. encoded) low-resolution (LR) image must preserve the original visual appearance. To implement this constraint, most methods guide the downscaling module by supervising it with the bicubically downscaled LR version of the original high-resolution (HR) image. However, this bicubic LR guidance may be suboptimal for the subsequent upscaling (i.e. decoding) and restrict the final reconstruction performance. In this paper, instead of directly applying the LR guidance, we propose an additional invertible flow guidance module (FGM), which can transform the downscaled representation to the visually plausible image during downscaling and transform it back during upscaling. Benefiting from the invertibility of FGM, the downscaled representation could get rid of the LR guidance and would not disturb the downscaling-upscaling process. It allows us to remove the restrictions on the downscaling module and optimize the downscaling and upscaling modules in an end-to-end manner. In this way, these two modules could cooperate to maximize the HR reconstruction performance. Extensive experiments demonstrate that the proposed method can achieve state-of-the-art (SotA) performance on both downscaled and reconstructed images.
Data Poisoning Attacks Against Multimodal Encoders
Sep 30, 2022

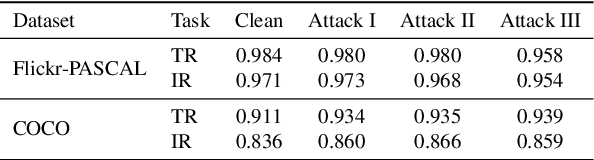

Traditional machine learning (ML) models usually rely on large-scale labeled datasets to achieve strong performance. However, such labeled datasets are often challenging and expensive to obtain. Also, the predefined categories limit the model's ability to generalize to other visual concepts as additional labeled data is required. On the contrary, the newly emerged multimodal model, which contains both visual and linguistic modalities, learns the concept of images from the raw text. It is a promising way to solve the above problems as it can use easy-to-collect image-text pairs to construct the training dataset and the raw texts contain almost unlimited categories according to their semantics. However, learning from a large-scale unlabeled dataset also exposes the model to the risk of potential poisoning attacks, whereby the adversary aims to perturb the model's training dataset to trigger malicious behaviors in it. Previous work mainly focuses on the visual modality. In this paper, we instead focus on answering two questions: (1) Is the linguistic modality also vulnerable to poisoning attacks? and (2) Which modality is most vulnerable? To answer the two questions, we conduct three types of poisoning attacks against CLIP, the most representative multimodal contrastive learning framework. Extensive evaluations on different datasets and model architectures show that all three attacks can perform well on the linguistic modality with only a relatively low poisoning rate and limited epochs. Also, we observe that the poisoning effect differs between different modalities, i.e., with lower MinRank in the visual modality and with higher Hit@K when K is small in the linguistic modality. To mitigate the attacks, we propose both pre-training and post-training defenses. We empirically show that both defenses can significantly reduce the attack performance while preserving the model's utility.
MD-Net: Multi-Detector for Local Feature Extraction
Aug 10, 2022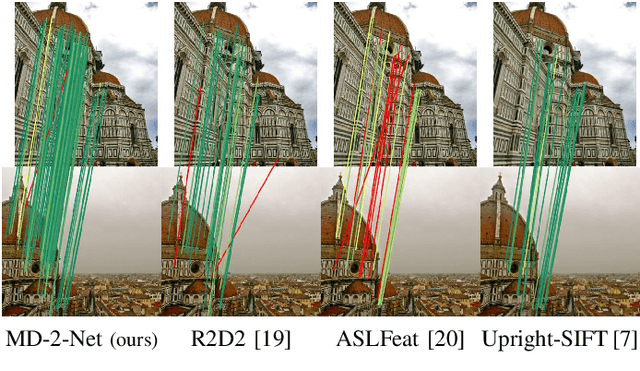
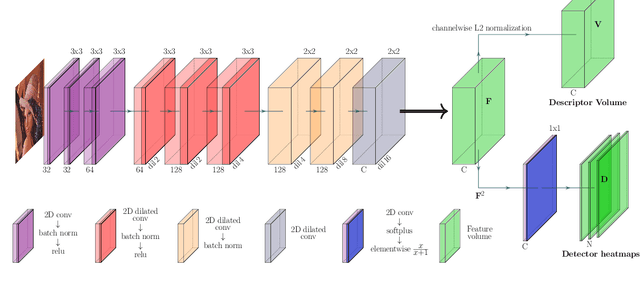
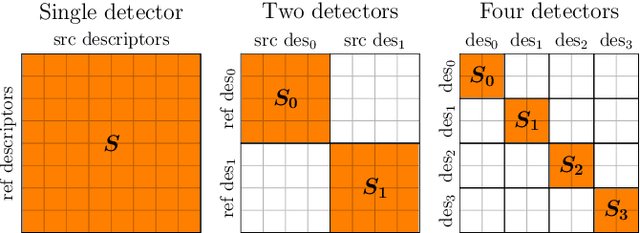

Establishing a sparse set of keypoint correspon dences between images is a fundamental task in many computer vision pipelines. Often, this translates into a computationally expensive nearest neighbor search, where every keypoint descriptor at one image must be compared with all the descriptors at the others. In order to lower the computational cost of the matching phase, we propose a deep feature extraction network capable of detecting a predefined number of complementary sets of keypoints at each image. Since only the descriptors within the same set need to be compared across the different images, the matching phase computational complexity decreases with the number of sets. We train our network to predict the keypoints and compute the corresponding descriptors jointly. In particular, in order to learn complementary sets of keypoints, we introduce a novel unsupervised loss which penalizes intersections among the different sets. Additionally, we propose a novel descriptor-based weighting scheme meant to penalize the detection of keypoints with non-discriminative descriptors. With extensive experiments we show that our feature extraction network, trained only on synthetically warped images and in a fully unsupervised manner, achieves competitive results on 3D reconstruction and re-localization tasks at a reduced matching complexity.
RGB-Event Fusion for Moving Object Detection in Autonomous Driving
Sep 17, 2022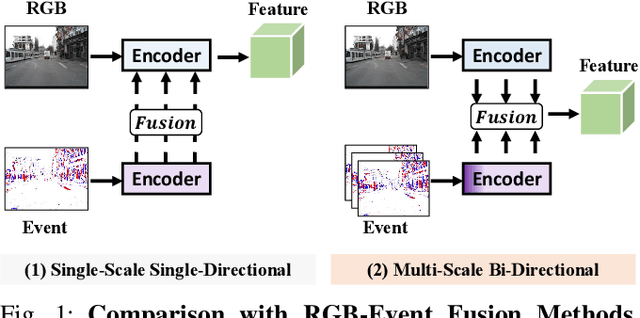
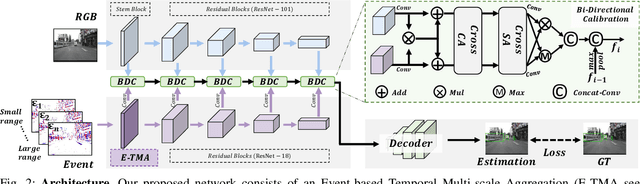
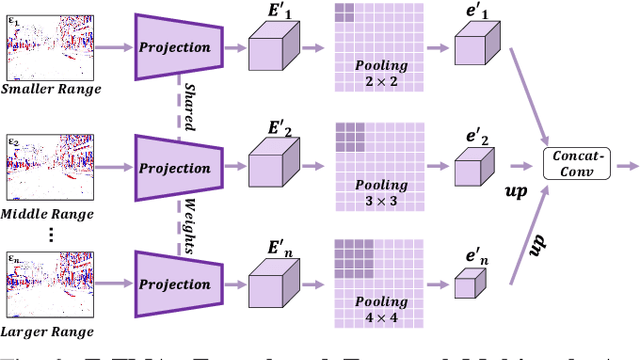
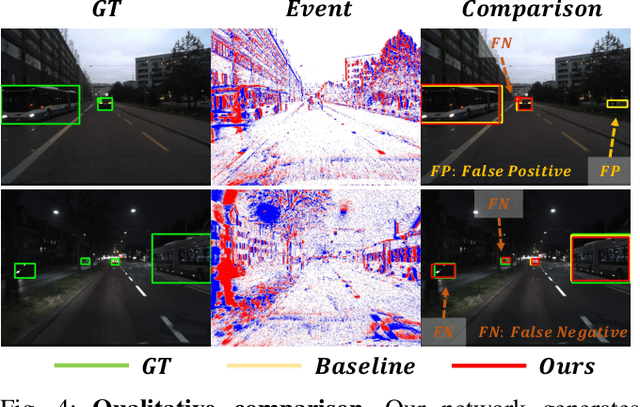
Moving Object Detection (MOD) is a critical vision task for successfully achieving safe autonomous driving. Despite plausible results of deep learning methods, most existing approaches are only frame-based and may fail to reach reasonable performance when dealing with dynamic traffic participants. Recent advances in sensor technologies, especially the Event camera, can naturally complement the conventional camera approach to better model moving objects. However, event-based works often adopt a pre-defined time window for event representation, and simply integrate it to estimate image intensities from events, neglecting much of the rich temporal information from the available asynchronous events. Therefore, from a new perspective, we propose RENet, a novel RGB-Event fusion Network, that jointly exploits the two complementary modalities to achieve more robust MOD under challenging scenarios for autonomous driving. Specifically, we first design a temporal multi-scale aggregation module to fully leverage event frames from both the RGB exposure time and larger intervals. Then we introduce a bi-directional fusion module to attentively calibrate and fuse multi-modal features. To evaluate the performance of our network, we carefully select and annotate a sub-MOD dataset from the commonly used DSEC dataset. Extensive experiments demonstrate that our proposed method performs significantly better than the state-of-the-art RGB-Event fusion alternatives.
Deep AUC Maximization for Medical Image Classification: Challenges and Opportunities
Nov 01, 2021
In this extended abstract, we will present and discuss opportunities and challenges brought about by a new deep learning method by AUC maximization (aka \underline{\bf D}eep \underline{\bf A}UC \underline{\bf M}aximization or {\bf DAM}) for medical image classification. Since AUC (aka area under ROC curve) is a standard performance measure for medical image classification, hence directly optimizing AUC could achieve a better performance for learning a deep neural network than minimizing a traditional loss function (e.g., cross-entropy loss). Recently, there emerges a trend of using deep AUC maximization for large-scale medical image classification. In this paper, we will discuss these recent results by highlighting (i) the advancements brought by stochastic non-convex optimization algorithms for DAM; (ii) the promising results on various medical image classification problems. Then, we will discuss challenges and opportunities of DAM for medical image classification from three perspectives, feature learning, large-scale optimization, and learning trustworthy AI models.
CRAFT: Camera-Radar 3D Object Detection with Spatio-Contextual Fusion Transformer
Sep 14, 2022
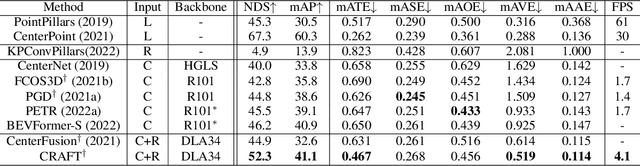
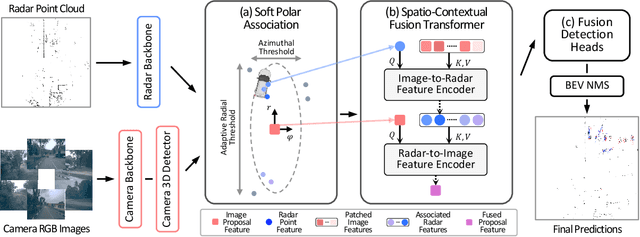

Camera and radar sensors have significant advantages in cost, reliability, and maintenance compared to LiDAR. Existing fusion methods often fuse the outputs of single modalities at the result-level, called the late fusion strategy. This can benefit from using off-the-shelf single sensor detection algorithms, but late fusion cannot fully exploit the complementary properties of sensors, thus having limited performance despite the huge potential of camera-radar fusion. Here we propose a novel proposal-level early fusion approach that effectively exploits both spatial and contextual properties of camera and radar for 3D object detection. Our fusion framework first associates image proposal with radar points in the polar coordinate system to efficiently handle the discrepancy between the coordinate system and spatial properties. Using this as a first stage, following consecutive cross-attention based feature fusion layers adaptively exchange spatio-contextual information between camera and radar, leading to a robust and attentive fusion. Our camera-radar fusion approach achieves the state-of-the-art 41.1% mAP and 52.3% NDS on the nuScenes test set, which is 8.7 and 10.8 points higher than the camera-only baseline, as well as yielding competitive performance on the LiDAR method.
Single Image Object Counting and Localizing using Active-Learning
Nov 16, 2021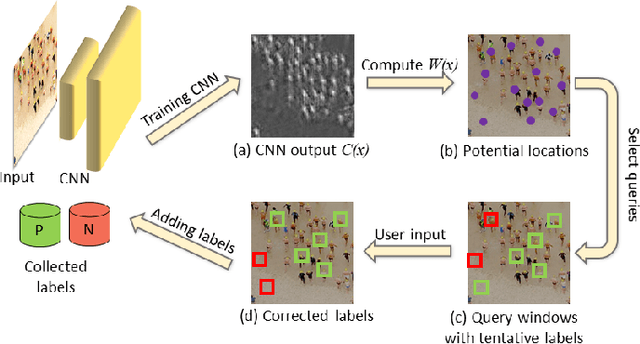
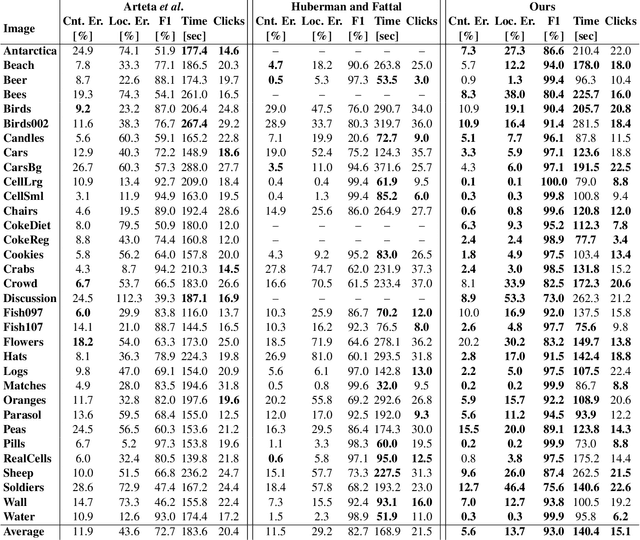
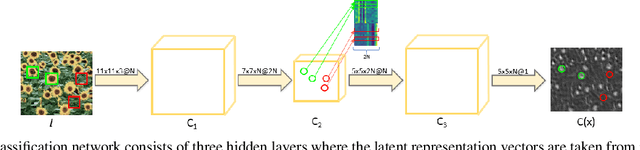

The need to count and localize repeating objects in an image arises in different scenarios, such as biological microscopy studies, production lines inspection, and surveillance recordings analysis. The use of supervised Convoutional Neural Networks (CNNs) achieves accurate object detection when trained over large class-specific datasets. The labeling effort in this approach does not pay-off when the counting is required over few images of a unique object class. We present a new method for counting and localizing repeating objects in single-image scenarios, assuming no pre-trained classifier is available. Our method trains a CNN over a small set of labels carefully collected from the input image in few active-learning iterations. At each iteration, the latent space of the network is analyzed to extract a minimal number of user-queries that strives to both sample the in-class manifold as thoroughly as possible as well as avoid redundant labels. Compared with existing user-assisted counting methods, our active-learning iterations achieve state-of-the-art performance in terms of counting and localizing accuracy, number of user mouse clicks, and running-time. This evaluation was performed through a large user study over a wide range of image classes with diverse conditions of illumination and occlusions.
What is Where by Looking: Weakly-Supervised Open-World Phrase-Grounding without Text Inputs
Jun 27, 2022

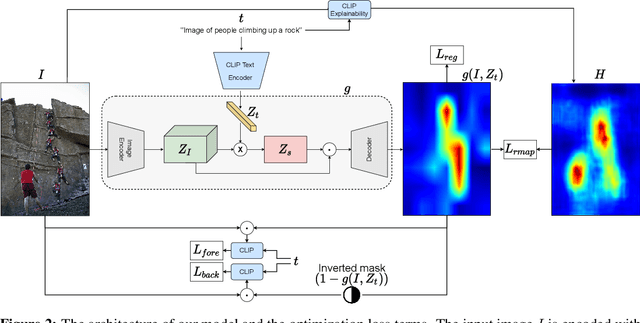

Given an input image, and nothing else, our method returns the bounding boxes of objects in the image and phrases that describe the objects. This is achieved within an open world paradigm, in which the objects in the input image may not have been encountered during the training of the localization mechanism. Moreover, training takes place in a weakly supervised setting, where no bounding boxes are provided. To achieve this, our method combines two pre-trained networks: the CLIP image-to-text matching score and the BLIP image captioning tool. Training takes place on COCO images and their captions and is based on CLIP. Then, during inference, BLIP is used to generate a hypothesis regarding various regions of the current image. Our work generalizes weakly supervised segmentation and phrase grounding and is shown empirically to outperform the state of the art in both domains. It also shows very convincing results in the novel task of weakly-supervised open-world purely visual phrase-grounding presented in our work. For example, on the datasets used for benchmarking phrase-grounding, our method results in a very modest degradation in comparison to methods that employ human captions as an additional input. Our code is available at https://github.com/talshaharabany/what-is-where-by-looking and a live demo can be found at https://replicate.com/talshaharabany/what-is-where-by-looking.