 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Memory-guided Image De-raining Using Time-Lapse Data
Jan 06, 2022



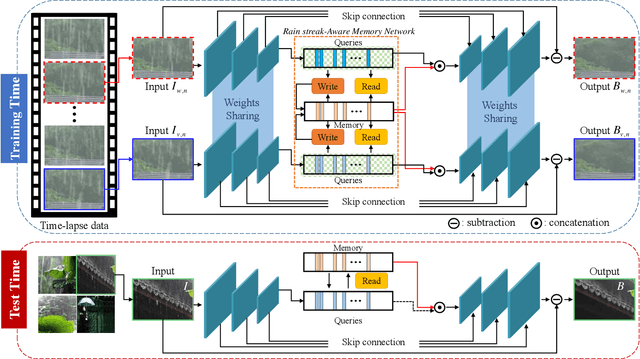
This paper addresses the problem of single image de-raining, that is, the task of recovering clean and rain-free background scenes from a single image obscured by a rainy artifact. Although recent advances adopt real-world time-lapse data to overcome the need for paired rain-clean images, they are limited to fully exploit the time-lapse data. The main cause is that, in terms of network architectures, they could not capture long-term rain streak information in the time-lapse data during training owing to the lack of memory components. To address this problem, we propose a novel network architecture based on a memory network that explicitly helps to capture long-term rain streak information in the time-lapse data. Our network comprises the encoder-decoder networks and a memory network. The features extracted from the encoder are read and updated in the memory network that contains several memory items to store rain streak-aware feature representations. With the read/update operation, the memory network retrieves relevant memory items in terms of the queries, enabling the memory items to represent the various rain streaks included in the time-lapse data. To boost the discriminative power of memory features, we also present a novel background selective whitening (BSW) loss for capturing only rain streak information in the memory network by erasing the background information. Experimental results on standard benchmarks demonstrate the effectiveness and superiority of our approach.
Improving Accuracy and Explainability of Online Handwriting Recognition
Sep 14, 2022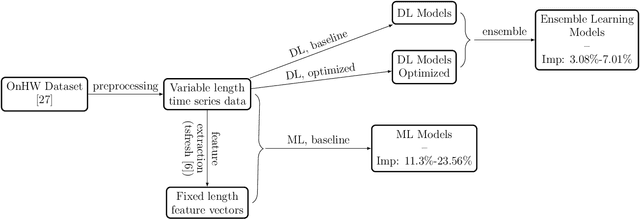
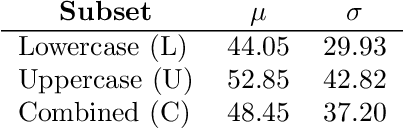
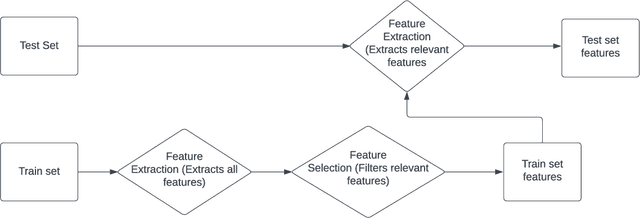
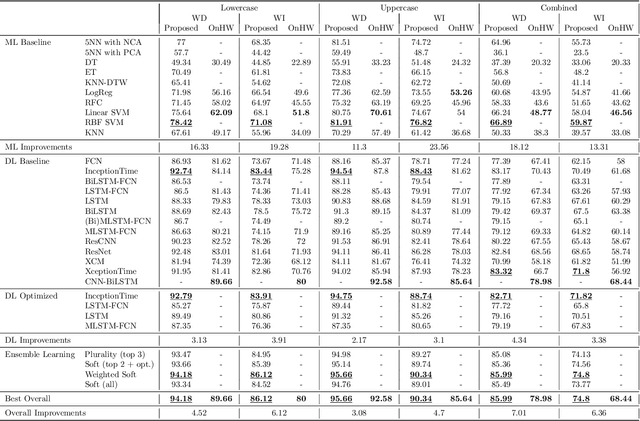
Handwriting recognition technology allows recognizing a written text from a given data. The recognition task can target letters, symbols, or words, and the input data can be a digital image or recorded by various sensors. A wide range of applications from signature verification to electronic document processing can be realized by implementing efficient and accurate handwriting recognition algorithms. Over the years, there has been an increasing interest in experimenting with different types of technology to collect handwriting data, create datasets, and develop algorithms to recognize characters and symbols. More recently, the OnHW-chars dataset has been published that contains multivariate time series data of the English alphabet collected using a ballpoint pen fitted with sensors. The authors of OnHW-chars also provided some baseline results through their machine learning (ML) and deep learning (DL) classifiers. In this paper, we develop handwriting recognition models on the OnHW-chars dataset and improve the accuracy of previous models. More specifically, our ML models provide $11.3\%$-$23.56\%$ improvements over the previous ML models, and our optimized DL models with ensemble learning provide $3.08\%$-$7.01\%$ improvements over the previous DL models. In addition to our accuracy improvements over the spectrum, we aim to provide some level of explainability for our models to provide more logic behind chosen methods and why the models make sense for the data type in the dataset. Our results are verifiable and reproducible via the provided public repository.
Spectral image clustering on dual-energy CT scans using functional regression mixtures
Jan 31, 2022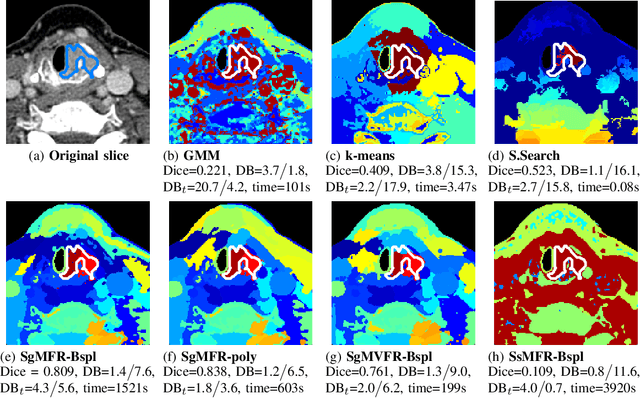
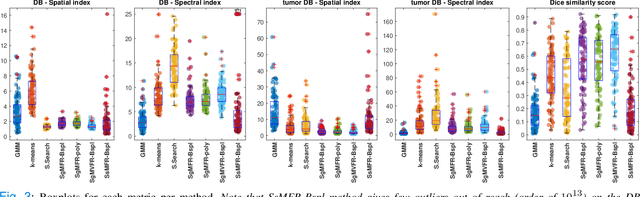
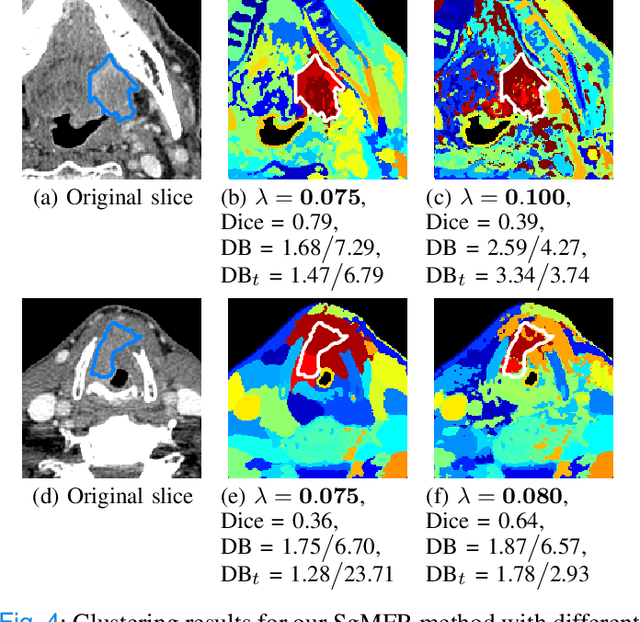
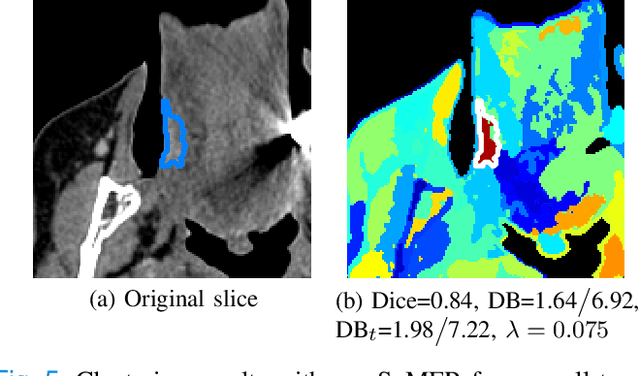
Dual-energy computed tomography (DECT) is an advanced CT scanning technique enabling material characterization not possible with conventional CT scans. It allows the reconstruction of energy decay curves at each 3D image voxel, representing varying image attenuation at different effective scanning energy levels. In this paper, we develop novel functional data analysis (FDA) techniques and adapt them to the analysis of DECT decay curves. More specifically, we construct functional mixture models that integrate spatial context in mixture weights, with mixture component densities being constructed upon the energy decay curves as functional observations. We design unsupervised clustering algorithms by developing dedicated expectation maximization (EM) algorithms for the maximum likelihood estimation of the model parameters. To our knowledge, this is the first article to adapt statistical FDA tools and model-based clustering to take advantage of the full spectral information provided by DECT. We evaluate our methods on 91 head and neck cancer DECT scans. We compare our unsupervised clustering results to tumor contours traced manually by radiologists, as well as to several baseline algorithms. Given the inter-rater variability even among experts at delineating head and neck tumors, and given the potential importance of tissue reactions surrounding the tumor itself, our proposed methodology has the potential to add value in downstream machine learning applications for clinical outcome prediction based on DECT data in head and neck cancer.
SGBANet: Semantic GAN and Balanced Attention Network for Arbitrarily Oriented Scene Text Recognition
Jul 21, 2022
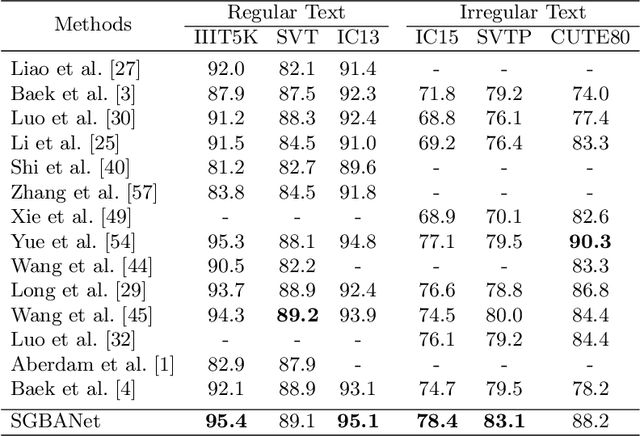
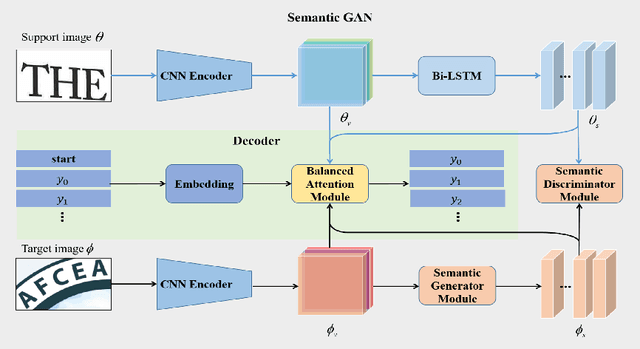

Scene text recognition is a challenging task due to the complex backgrounds and diverse variations of text instances. In this paper, we propose a novel Semantic GAN and Balanced Attention Network (SGBANet) to recognize the texts in scene images. The proposed method first generates the simple semantic feature using Semantic GAN and then recognizes the scene text with the Balanced Attention Module. The Semantic GAN aims to align the semantic feature distribution between the support domain and target domain. Different from the conventional image-to-image translation methods that perform at the image level, the Semantic GAN performs the generation and discrimination on the semantic level with the Semantic Generator Module (SGM) and Semantic Discriminator Module (SDM). For target images (scene text images), the Semantic Generator Module generates simple semantic features that share the same feature distribution with support images (clear text images). The Semantic Discriminator Module is used to distinguish the semantic features between the support domain and target domain. In addition, a Balanced Attention Module is designed to alleviate the problem of attention drift. The Balanced Attention Module first learns a balancing parameter based on the visual glimpse vector and semantic glimpse vector, and then performs the balancing operation for obtaining a balanced glimpse vector. Experiments on six benchmarks, including regular datasets, i.e., IIIT5K, SVT, ICDAR2013, and irregular datasets, i.e., ICDAR2015, SVTP, CUTE80, validate the effectiveness of our proposed method.
Causality-inspired Single-source Domain Generalization for Medical Image Segmentation
Nov 26, 2021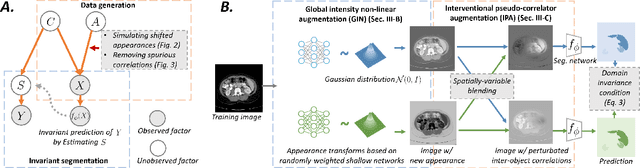
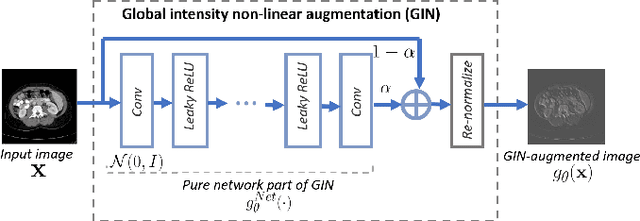
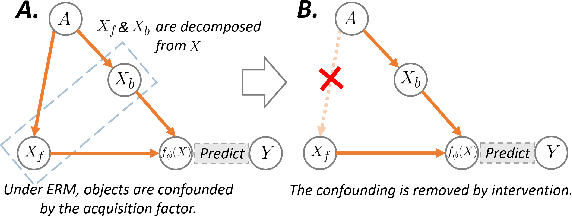
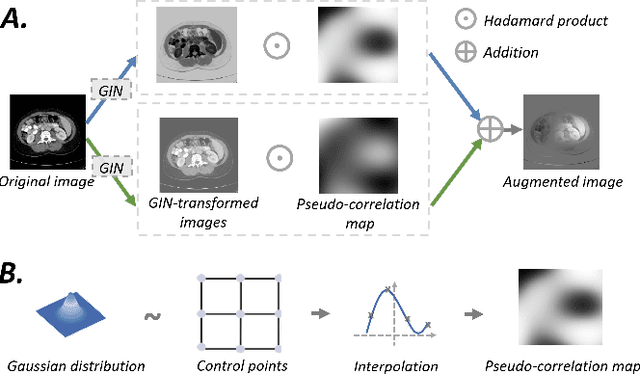
Deep learning models usually suffer from domain shift issues, where models trained on one source domain do not generalize well to other unseen domains. In this work, we investigate the single-source domain generalization problem: training a deep network that is robust to unseen domains, under the condition that training data is only available from one source domain, which is common in medical imaging applications. We tackle this problem in the context of cross-domain medical image segmentation. Under this scenario, domain shifts are mainly caused by different acquisition processes. We propose a simple causality-inspired data augmentation approach to expose a segmentation model to synthesized domain-shifted training examples. Specifically, 1) to make the deep model robust to discrepancies in image intensities and textures, we employ a family of randomly-weighted shallow networks. They augment training images using diverse appearance transformations. 2) Further we show that spurious correlations among objects in an image are detrimental to domain robustness. These correlations might be taken by the network as domain-specific clues for making predictions, and they may break on unseen domains. We remove these spurious correlations via causal intervention. This is achieved by resampling the appearances of potentially correlated objects independently. The proposed approach is validated on three cross-domain segmentation tasks: cross-modality (CT-MRI) abdominal image segmentation, cross-sequence (bSSFP-LGE) cardiac MRI segmentation, and cross-center prostate MRI segmentation. The proposed approach yields consistent performance gains compared with competitive methods when tested on unseen domains.
On the Optimal Combination of Cross-Entropy and Soft Dice Losses for Lesion Segmentation with Out-of-Distribution Robustness
Sep 14, 2022
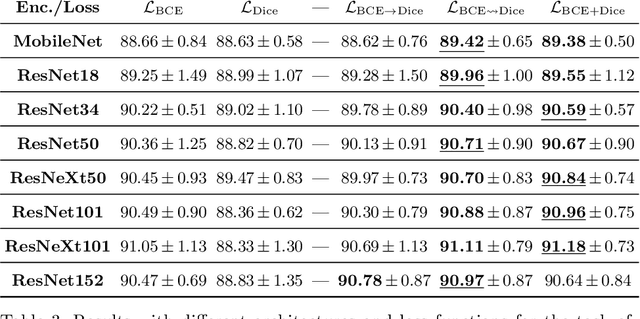
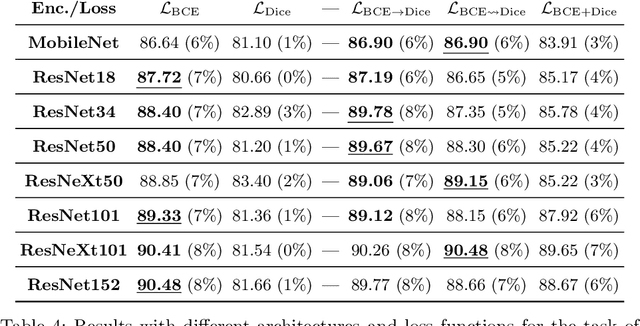
We study the impact of different loss functions on lesion segmentation from medical images. Although the Cross-Entropy (CE) loss is the most popular option when dealing with natural images, for biomedical image segmentation the soft Dice loss is often preferred due to its ability to handle imbalanced scenarios. On the other hand, the combination of both functions has also been successfully applied in this kind of tasks. A much less studied problem is the generalization ability of all these losses in the presence of Out-of-Distribution (OoD) data. This refers to samples appearing in test time that are drawn from a different distribution than training images. In our case, we train our models on images that always contain lesions, but in test time we also have lesion-free samples. We analyze the impact of the minimization of different loss functions on in-distribution performance, but also its ability to generalize to OoD data, via comprehensive experiments on polyp segmentation from endoscopic images and ulcer segmentation from diabetic feet images. Our findings are surprising: CE-Dice loss combinations that excel in segmenting in-distribution images have a poor performance when dealing with OoD data, which leads us to recommend the adoption of the CE loss for this kind of problems, due to its robustness and ability to generalize to OoD samples. Code associated to our experiments can be found at https://github.com/agaldran/lesion_losses_ood .
Single Frame Atmospheric Turbulence Mitigation: A Benchmark Study and A New Physics-Inspired Transformer Model
Jul 24, 2022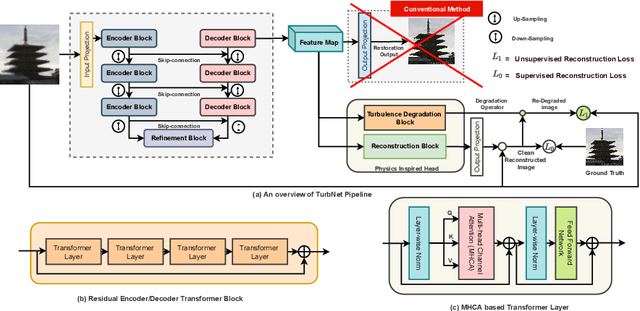
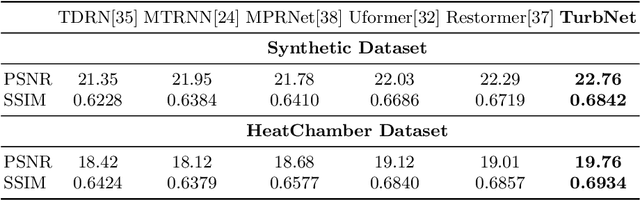
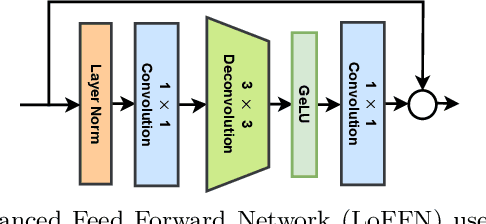

Image restoration algorithms for atmospheric turbulence are known to be much more challenging to design than traditional ones such as blur or noise because the distortion caused by the turbulence is an entanglement of spatially varying blur, geometric distortion, and sensor noise. Existing CNN-based restoration methods built upon convolutional kernels with static weights are insufficient to handle the spatially dynamical atmospheric turbulence effect. To address this problem, in this paper, we propose a physics-inspired transformer model for imaging through atmospheric turbulence. The proposed network utilizes the power of transformer blocks to jointly extract a dynamical turbulence distortion map and restore a turbulence-free image. In addition, recognizing the lack of a comprehensive dataset, we collect and present two new real-world turbulence datasets that allow for evaluation with both classical objective metrics (e.g., PSNR and SSIM) and a new task-driven metric using text recognition accuracy. Both real testing sets and all related code will be made publicly available.
OrthoMAD: Morphing Attack Detection Through Orthogonal Identity Disentanglement
Aug 23, 2022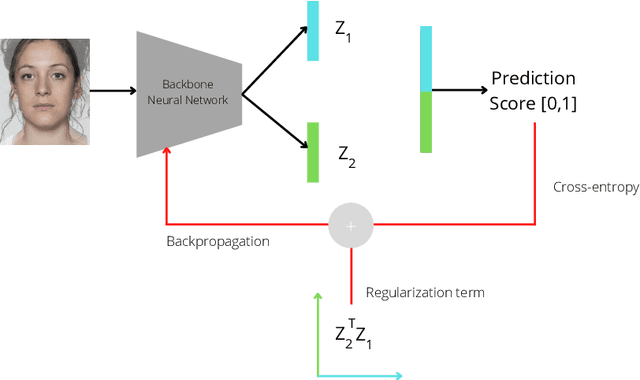
Morphing attacks are one of the many threats that are constantly affecting deep face recognition systems. It consists of selecting two faces from different individuals and fusing them into a final image that contains the identity information of both. In this work, we propose a novel regularisation term that takes into account the existent identity information in both and promotes the creation of two orthogonal latent vectors. We evaluate our proposed method (OrthoMAD) in five different types of morphing in the FRLL dataset and evaluate the performance of our model when trained on five distinct datasets. With a small ResNet-18 as the backbone, we achieve state-of-the-art results in the majority of the experiments, and competitive results in the others. The code of this paper will be publicly available.
Harnessing the Conditioning Sensorium for Improved Image Translation
Oct 13, 2021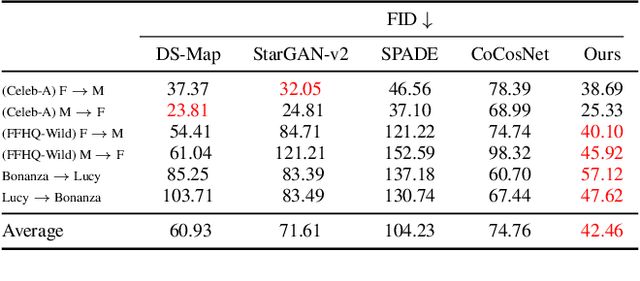
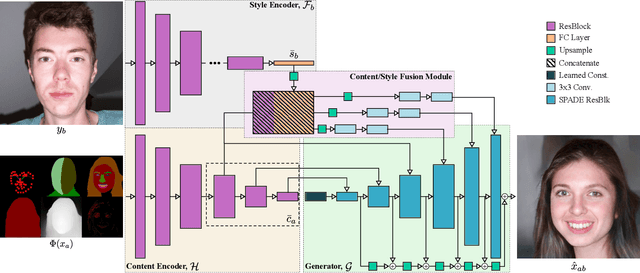


Multi-modal domain translation typically refers to synthesizing a novel image that inherits certain localized attributes from a 'content' image (e.g. layout, semantics, or geometry), and inherits everything else (e.g. texture, lighting, sometimes even semantics) from a 'style' image. The dominant approach to this task is attempting to learn disentangled 'content' and 'style' representations from scratch. However, this is not only challenging, but ill-posed, as what users wish to preserve during translation varies depending on their goals. Motivated by this inherent ambiguity, we define 'content' based on conditioning information extracted by off-the-shelf pre-trained models. We then train our style extractor and image decoder with an easy to optimize set of reconstruction objectives. The wide variety of high-quality pre-trained models available and simple training procedure makes our approach straightforward to apply across numerous domains and definitions of 'content'. Additionally it offers intuitive control over which aspects of 'content' are preserved across domains. We evaluate our method on traditional, well-aligned, datasets such as CelebA-HQ, and propose two novel datasets for evaluation on more complex scenes: ClassicTV and FFHQ-Wild. Our approach, Sensorium, enables higher quality domain translation for more complex scenes.
MontageGAN: Generation and Assembly of Multiple Components by GANs
May 31, 2022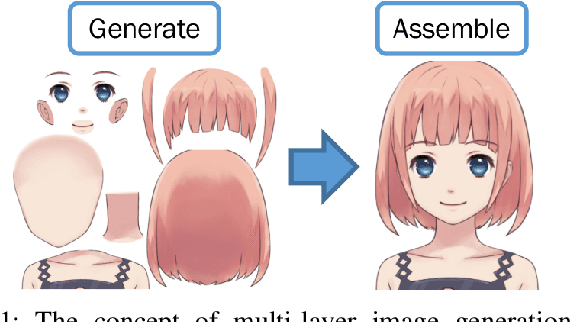
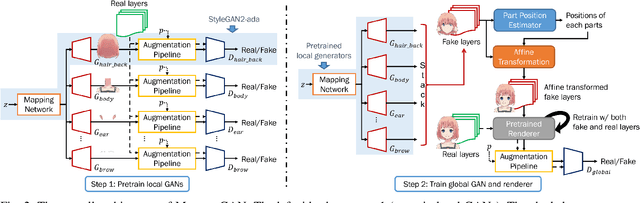
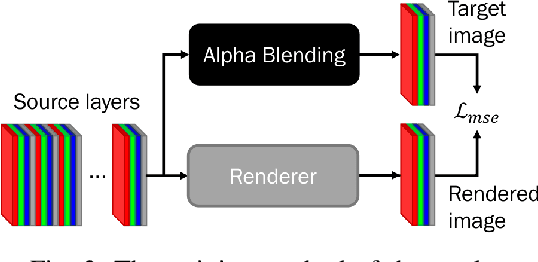
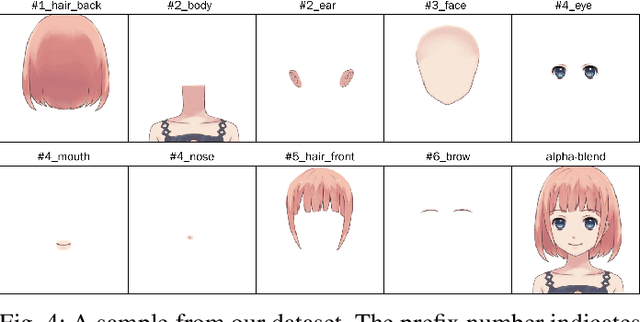
A multi-layer image is more valuable than a single-layer image from a graphic designer's perspective. However, most of the proposed image generation methods so far focus on single-layer images. In this paper, we propose MontageGAN, which is a Generative Adversarial Networks (GAN) framework for generating multi-layer images. Our method utilized a two-step approach consisting of local GANs and global GAN. Each local GAN learns to generate a specific image layer, and the global GAN learns the placement of each generated image layer. Through our experiments, we show the ability of our method to generate multi-layer images and estimate the placement of the generated image layers.