 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Masked Sinogram Model with Transformer for ill-Posed Computed Tomography Reconstruction: a Preliminary Study
Sep 03, 2022
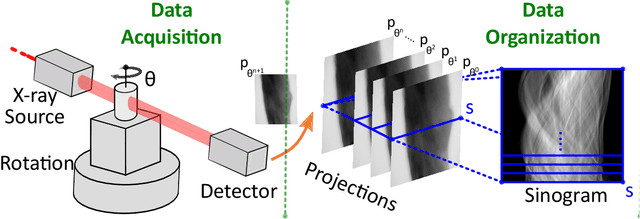

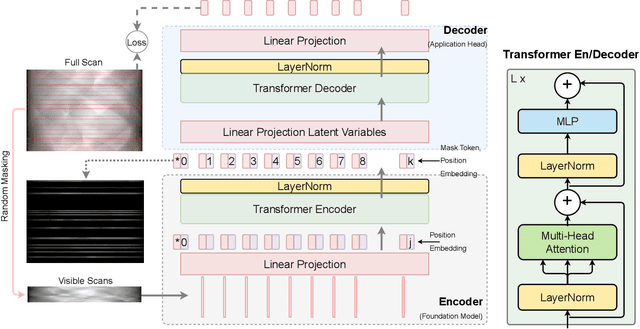

Computed Tomography (CT) is an imaging technique where information about an object are collected at different angles (called projections or scans). Then the cross-sectional image showing the internal structure of the slice is produced by solving an inverse problem. Limited by certain factors such as radiation dosage, projection angles, the produced images can be noisy or contain artifacts. Inspired by the success of transformer for natural language processing, the core idea of this preliminary study is to consider a projection of tomography as a word token, and the whole scan of the cross-section (A.K.A. sinogram) as a sentence in the context of natural language processing. Then we explore the idea of foundation model by training a masked sinogram model (MSM) and fine-tune MSM for various downstream applications including CT reconstruction under data collections restriction (e.g., photon-budget) and a data-driven solution to approximate solutions of the inverse problem for CT reconstruction. Models and data used in this study are available at https://github.com/lzhengchun/TomoTx.
Exploring Resolution and Degradation Clues as Self-supervised Signal for Low Quality Object Detection
Aug 05, 2022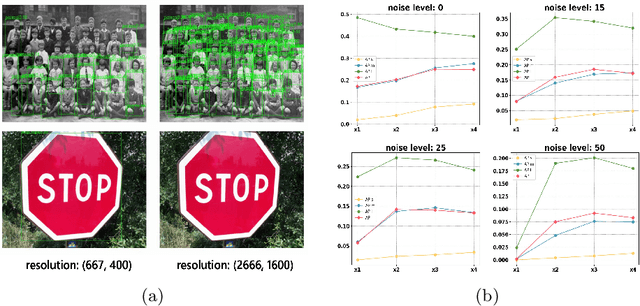
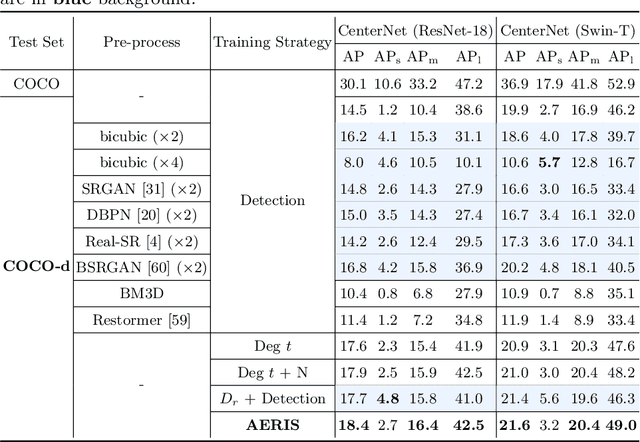
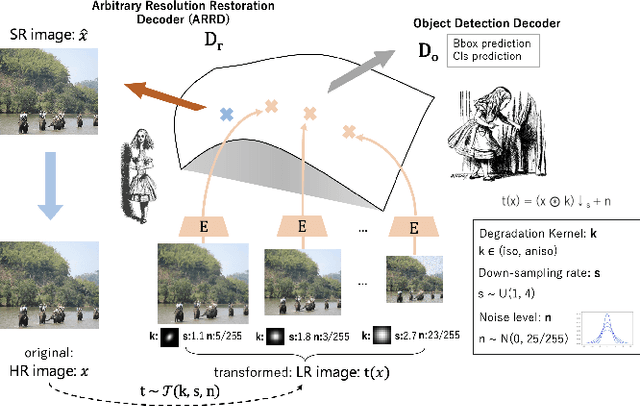
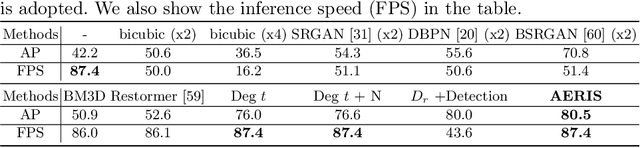
Image restoration algorithms such as super resolution (SR) are indispensable pre-processing modules for object detection in low quality images. Most of these algorithms assume the degradation is fixed and known a priori. However, in practical, either the real degradation or optimal up-sampling ratio rate is unknown or differs from assumption, leading to a deteriorating performance for both the pre-processing module and the consequent high-level task such as object detection. Here, we propose a novel self-supervised framework to detect objects in degraded low resolution images. We utilizes the downsampling degradation as a kind of transformation for self-supervised signals to explore the equivariant representation against various resolutions and other degradation conditions. The Auto Encoding Resolution in Self-supervision (AERIS) framework could further take the advantage of advanced SR architectures with an arbitrary resolution restoring decoder to reconstruct the original correspondence from the degraded input image. Both the representation learning and object detection are optimized jointly in an end-to-end training fashion. The generic AERIS framework could be implemented on various mainstream object detection architectures with different backbones. The extensive experiments show that our methods has achieved superior performance compared with existing methods when facing variant degradation situations. Code would be released at https://github.com/cuiziteng/ECCV_AERIS.
Learning 6D Pose Estimation from Synthetic RGBD Images for Robotic Applications
Aug 30, 2022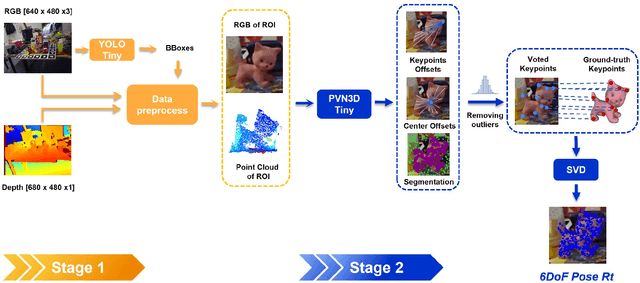
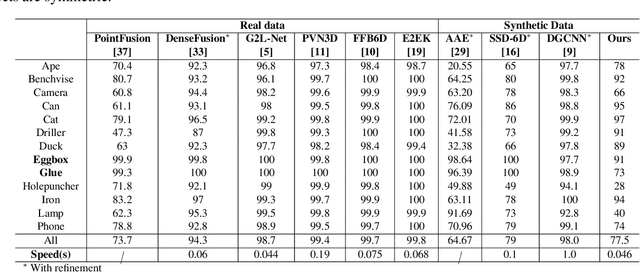

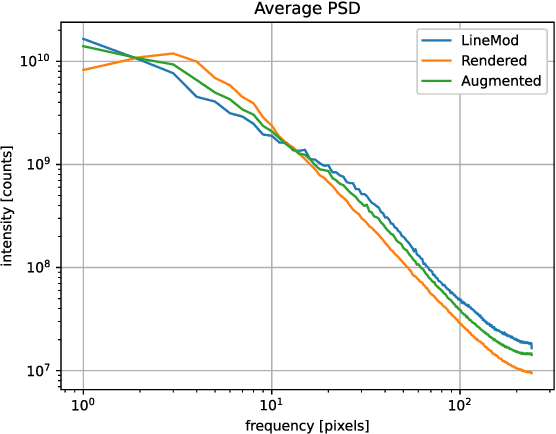
In this work, we propose a data generation pipeline by leveraging the 3D suite Blender to produce synthetic RGBD image datasets with 6D poses for robotic picking. The proposed pipeline can efficiently generate large amounts of photo-realistic RGBD images for the object of interest. In addition, a collection of domain randomization techniques is introduced to bridge the gap between real and synthetic data. Furthermore, we develop a real-time two-stage 6D pose estimation approach by integrating the object detector YOLO-V4-tiny and the 6D pose estimation algorithm PVN3D for time sensitive robotics applications. With the proposed data generation pipeline, our pose estimation approach can be trained from scratch using only synthetic data without any pre-trained models. The resulting network shows competitive performance compared to state-of-the-art methods when evaluated on LineMod dataset. We also demonstrate the proposed approach in a robotic experiment, grasping a household object from cluttered background under different lighting conditions.
A hierarchical semantic segmentation framework for computer vision-based bridge damage detection
Jul 18, 2022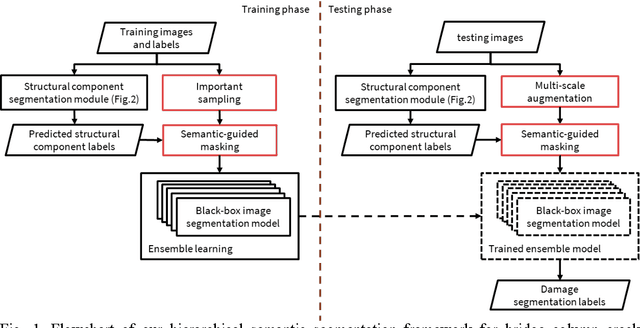
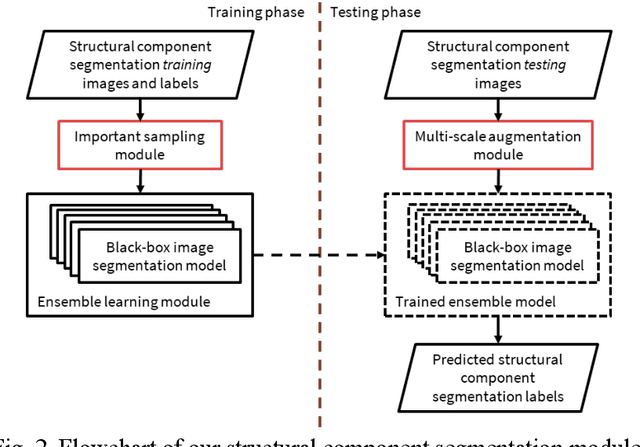


Computer vision-based damage detection using remote cameras and unmanned aerial vehicles (UAVs) enables efficient and low-cost bridge health monitoring that reduces labor costs and the needs for sensor installation and maintenance. By leveraging recent semantic image segmentation approaches, we are able to find regions of critical structural components and recognize damage at the pixel level using images as the only input. However, existing methods perform poorly when detecting small damages (e.g., cracks and exposed rebars) and thin objects with limited image samples, especially when the components of interest are highly imbalanced. To this end, this paper introduces a semantic segmentation framework that imposes the hierarchical semantic relationship between component category and damage types. For example, certain concrete cracks only present on bridge columns and therefore the non-column region will be masked out when detecting such damages. In this way, the damage detection model could focus on learning features from possible damaged regions only and avoid the effects of other irrelevant regions. We also utilize multi-scale augmentation that provides views with different scales that preserves contextual information of each image without losing the ability of handling small and thin objects. Furthermore, the proposed framework employs important sampling that repeatedly samples images containing rare components (e.g., railway sleeper and exposed rebars) to provide more data samples, which addresses the imbalanced data challenge.
VL-Taboo: An Analysis of Attribute-based Zero-shot Capabilities of Vision-Language Models
Sep 12, 2022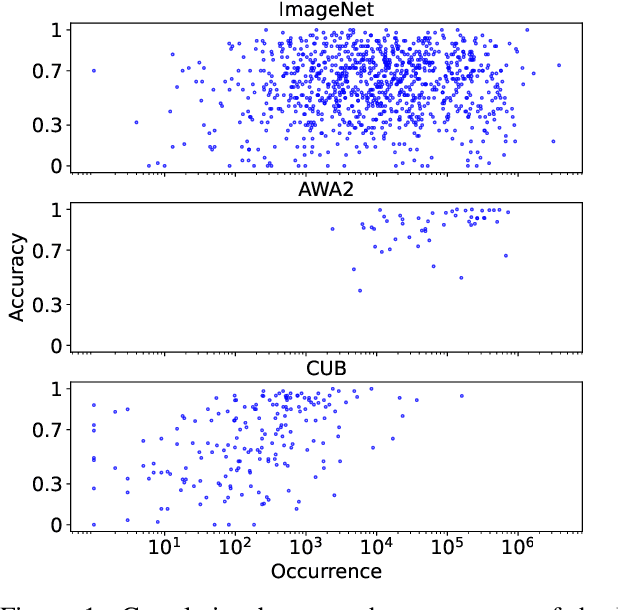
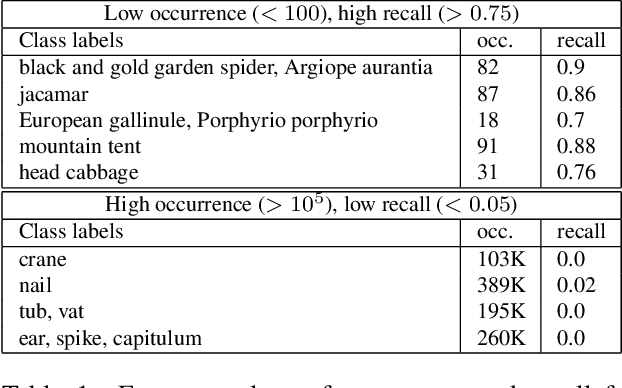
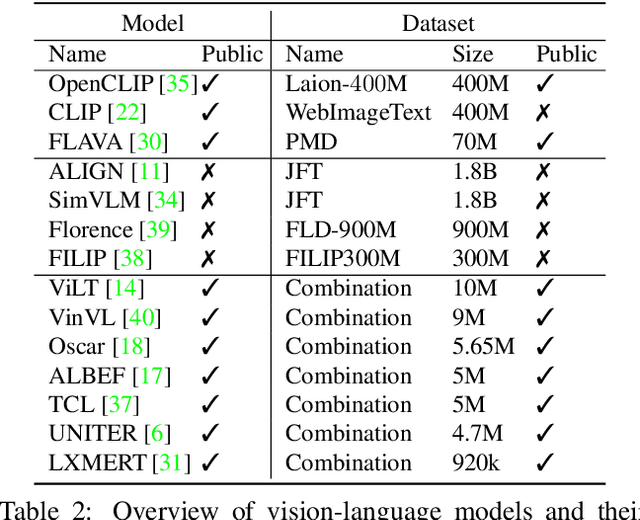
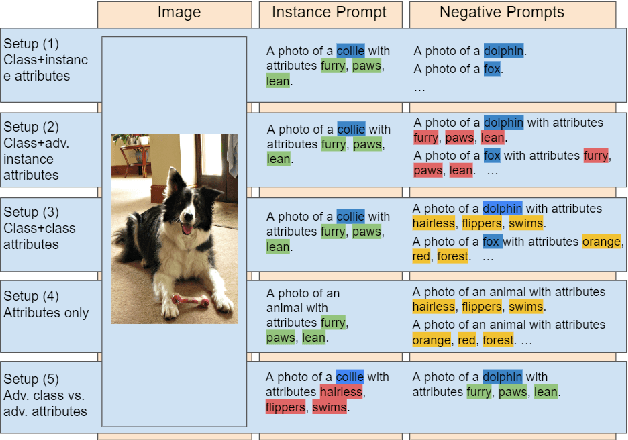
Vision-language models trained on large, randomly collected data had significant impact in many areas since they appeared. But as they show great performance in various fields, such as image-text-retrieval, their inner workings are still not fully understood. The current work analyses the true zero-shot capabilities of those models. We start from the analysis of the training corpus assessing to what extent (and which of) the test classes are really zero-shot and how this correlates with individual classes performance. We follow up with the analysis of the attribute-based zero-shot learning capabilities of these models, evaluating how well this classical zero-shot notion emerges from large-scale webly supervision. We leverage the recently released LAION400M data corpus as well as the publicly available pretrained models of CLIP, OpenCLIP, and FLAVA, evaluating the attribute-based zero-shot capabilities on CUB and AWA2 benchmarks. Our analysis shows that: (i) most of the classes in popular zero-shot benchmarks are observed (a lot) during pre-training; (ii) zero-shot performance mainly comes out of models' capability of recognizing class labels, whenever they are present in the text, and a significantly lower performing capability of attribute-based zeroshot learning is only observed when class labels are not used; (iii) the number of the attributes used can have a significant effect on performance, and can easily cause a significant performance decrease.
Multi-Modal Masked Autoencoders for Medical Vision-and-Language Pre-Training
Sep 15, 2022Medical vision-and-language pre-training provides a feasible solution to extract effective vision-and-language representations from medical images and texts. However, few studies have been dedicated to this field to facilitate medical vision-and-language understanding. In this paper, we propose a self-supervised learning paradigm with multi-modal masked autoencoders (M$^3$AE), which learn cross-modal domain knowledge by reconstructing missing pixels and tokens from randomly masked images and texts. There are three key designs to make this simple approach work. First, considering the different information densities of vision and language, we adopt different masking ratios for the input image and text, where a considerably larger masking ratio is used for images. Second, we use visual and textual features from different layers to perform the reconstruction to deal with different levels of abstraction in visual and language. Third, we develop different designs for vision and language decoders (i.e., a Transformer for vision and a multi-layer perceptron for language). To perform a comprehensive evaluation and facilitate further research, we construct a medical vision-and-language benchmark including three tasks. Experimental results demonstrate the effectiveness of our approach, where state-of-the-art results are achieved on all downstream tasks. Besides, we conduct further analysis to better verify the effectiveness of different components of our approach and various settings of pre-training. The source code is available at~\url{https://github.com/zhjohnchan/M3AE}.
Continual Learning for Steganalysis
Sep 03, 2022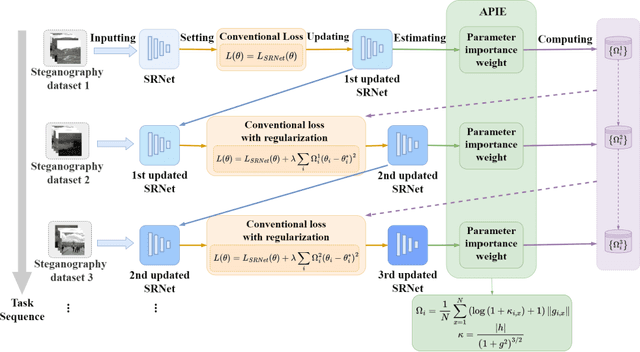
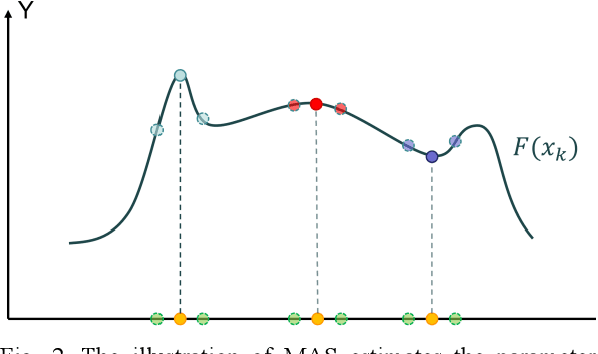
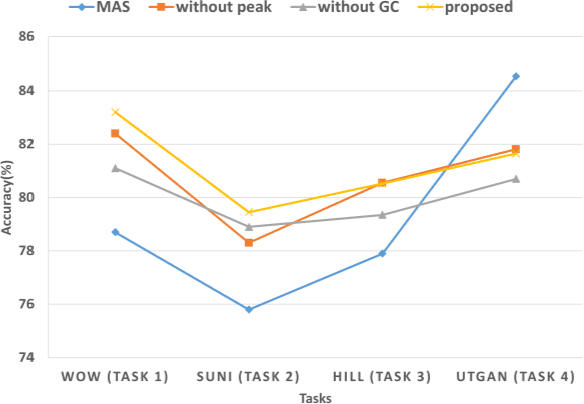
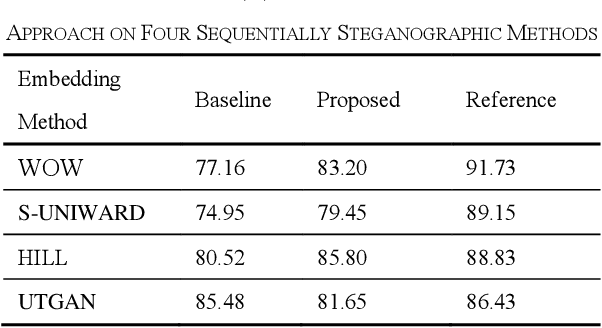
To detect the existing steganographic algorithms, recent steganalysis methods usually train a Convolutional Neural Network (CNN) model on the dataset consisting of corresponding paired cover/stego-images. However, it is inefficient and impractical for those steganalysis tools to completely retrain the CNN model to make it effective against both the existing steganographic algorithms and a new emerging steganographic algorithm. Thus, existing steganalysis models usually lack dynamic extensibility for new steganographic algorithms, which limits their application in real-world scenarios. To address this issue, we propose an accurate parameter importance estimation (APIE) based-continual learning scheme for steganalysis. In this scheme, when a steganalysis model is trained on the new image dataset generated by the new steganographic algorithm, its network parameters are effectively and efficiently updated with sufficient consideration of their importance evaluated in the previous training process. This approach can guide the steganalysis model to learn the patterns of the new steganographic algorithm without significantly degrading the detectability against the previous steganographic algorithms. Experimental results demonstrate the proposed scheme has promising extensibility for new emerging steganographic algorithms.
Optimizing Edge Detection for Image Segmentation with Multicut Penalties
Dec 10, 2021
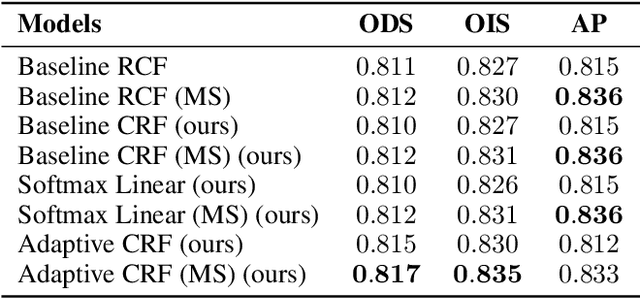
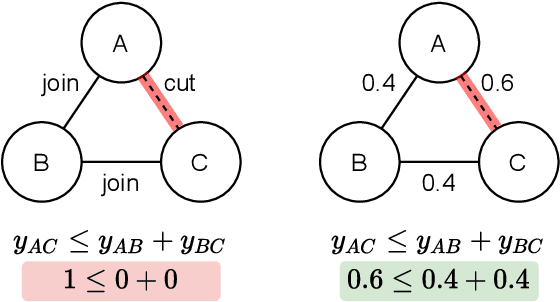
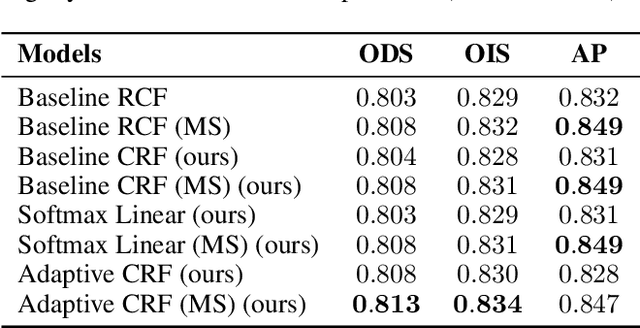
The Minimum Cost Multicut Problem (MP) is a popular way for obtaining a graph decomposition by optimizing binary edge labels over edge costs. While the formulation of a MP from independently estimated costs per edge is highly flexible and intuitive, solving the MP is NP-hard and time-expensive. As a remedy, recent work proposed to predict edge probabilities with awareness to potential conflicts by incorporating cycle constraints in the prediction process. We argue that such formulation, while providing a first step towards end-to-end learnable edge weights, is suboptimal, since it is built upon a loose relaxation of the MP. We therefore propose an adaptive CRF that allows to progressively consider more violated constraints and, in consequence, to issue solutions with higher validity. Experiments on the BSDS500 benchmark for natural image segmentation as well as on electron microscopic recordings show that our approach yields more precise edge detection and image segmentation.
Medical Knowledge-Guided Deep Learning for Imbalanced Medical Image Classification
Nov 20, 2021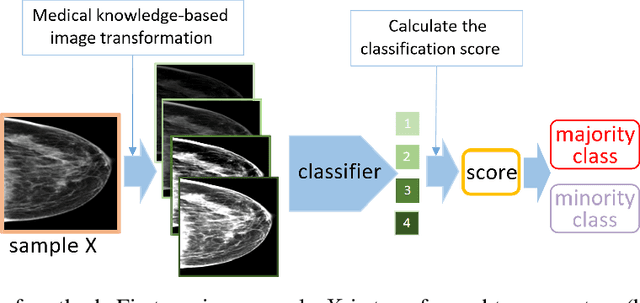
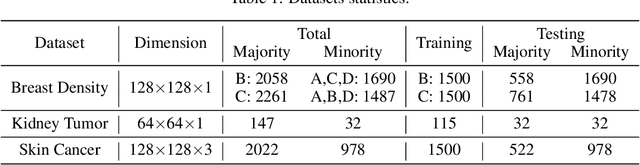
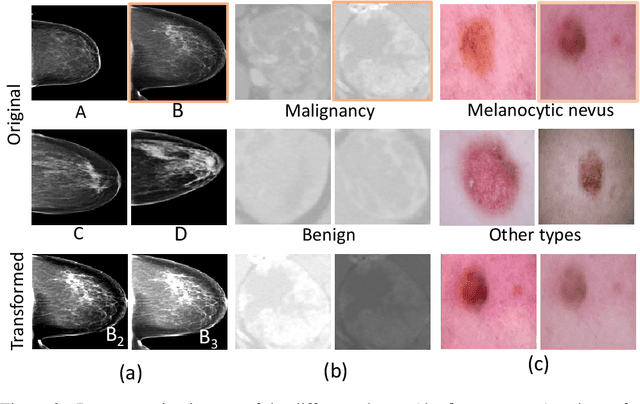

Deep learning models have gained remarkable performance on a variety of image classification tasks. However, many models suffer from limited performance in clinical or medical settings when data are imbalanced. To address this challenge, we propose a medical-knowledge-guided one-class classification approach that leverages domain-specific knowledge of classification tasks to boost the model's performance. The rationale behind our approach is that some existing prior medical knowledge can be incorporated into data-driven deep learning to facilitate model learning. We design a deep learning-based one-class classification pipeline for imbalanced image classification, and demonstrate in three use cases how we take advantage of medical knowledge of each specific classification task by generating additional middle classes to achieve higher classification performances. We evaluate our approach on three different clinical image classification tasks (a total of 8459 images) and show superior model performance when compared to six state-of-the-art methods. All codes of this work will be publicly available upon acceptance of the paper.
Point spread function estimation for blind image deblurring problems based on framelet transform
Dec 21, 2021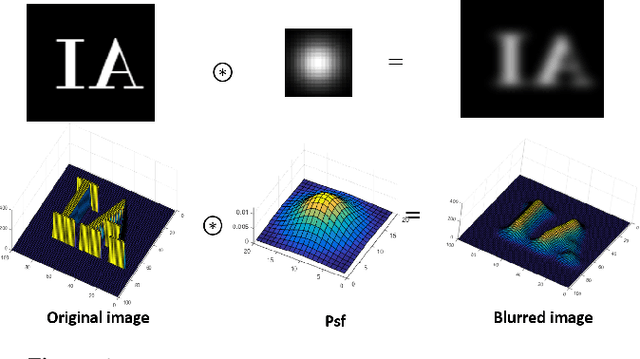
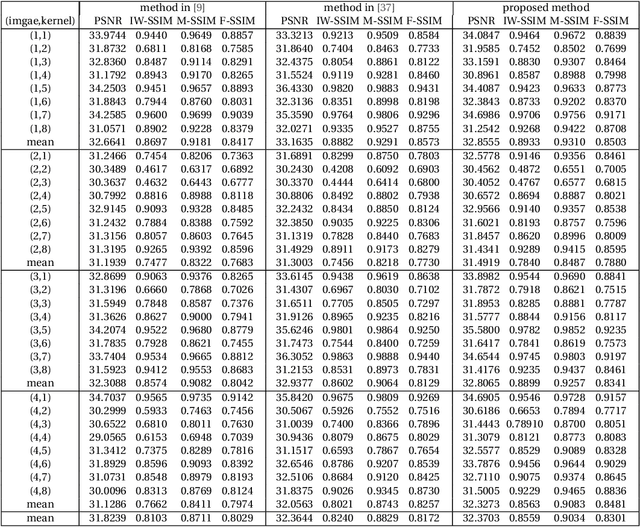


One of the most important issues in the image processing is the approximation of the image that has been lost due to the blurring process. These types of matters are divided into non-blind and blind problems. The second type of problem is more complex in terms of calculations than the first problems due to the unknown of original image and point spread function estimation. In the present paper, an algorithm based on coarse-to-fine iterative by $l_0-\alpha l_1$ regularization and framelet transform is introduced to approximate the spread function estimation. Framelet transfer improves the restored kernel due to the decomposition of the kernel to different frequencies. Also in the proposed model fraction gradient operator is used instead of ordinary gradient operator. The proposed method is investigated on different kinds of images such as text, face, natural. The output of the proposed method reflects the effectiveness of the proposed algorithm in restoring the images from blind problems.