 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Unsupervised Image Denoising with Frequency Domain Knowledge
Nov 29, 2021
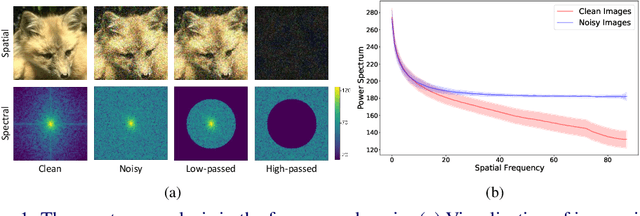
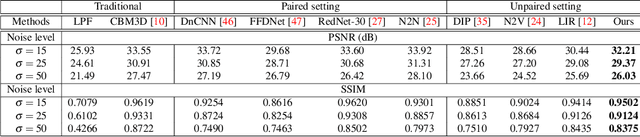
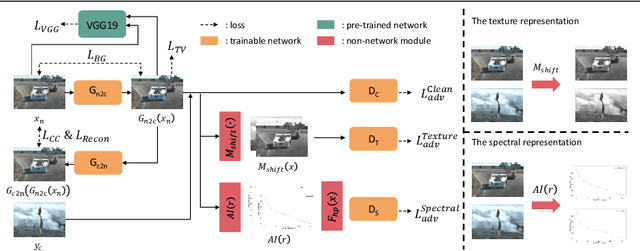

Supervised learning-based methods yield robust denoising results, yet they are inherently limited by the need for large-scale clean/noisy paired datasets. The use of unsupervised denoisers, on the other hand, necessitates a more detailed understanding of the underlying image statistics. In particular, it is well known that apparent differences between clean and noisy images are most prominent on high-frequency bands, justifying the use of low-pass filters as part of conventional image preprocessing steps. However, most learning-based denoising methods utilize only one-sided information from the spatial domain without considering frequency domain information. To address this limitation, in this study we propose a frequency-sensitive unsupervised denoising method. To this end, a generative adversarial network (GAN) is used as a base structure. Subsequently, we include spectral discriminator and frequency reconstruction loss to transfer frequency knowledge into the generator. Results using natural and synthetic datasets indicate that our unsupervised learning method augmented with frequency information achieves state-of-the-art denoising performance, suggesting that frequency domain information could be a viable factor in improving the overall performance of unsupervised learning-based methods.
High-Resolution Image Harmonization via Collaborative Dual Transformations
Sep 14, 2021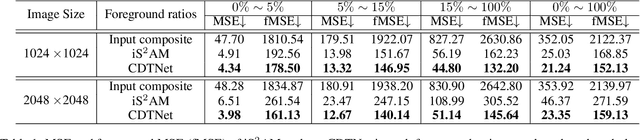

Given a composite image, image harmonization aims to adjust the foreground to make it compatible with the background. High-resolution image harmonization is in high demand, but still remains unexplored. Conventional image harmonization methods learn global RGB-to-RGB transformation which could effortlessly scale to high resolution, but ignore diverse local context. Recent deep learning methods learn the dense pixel-to-pixel transformation which could generate harmonious outputs, but are highly constrained in low resolution. In this work, we propose a high-resolution image harmonization network with Collaborative Dual Transformation (CDTNet) to combine pixel-to-pixel transformation and RGB-to-RGB transformation coherently in an end-to-end framework. Our CDTNet consists of a low-resolution generator for pixel-to-pixel transformation, a color mapping module for RGB-to-RGB transformation, and a refinement module to take advantage of both. Extensive experiments on high-resolution image harmonization dataset demonstrate that our CDTNet strikes a good balance between efficiency and effectiveness.
RenderNet: Visual Relocalization Using Virtual Viewpoints in Large-Scale Indoor Environments
Jul 26, 2022
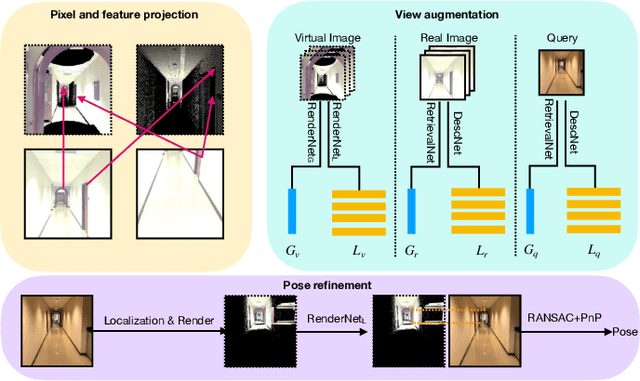
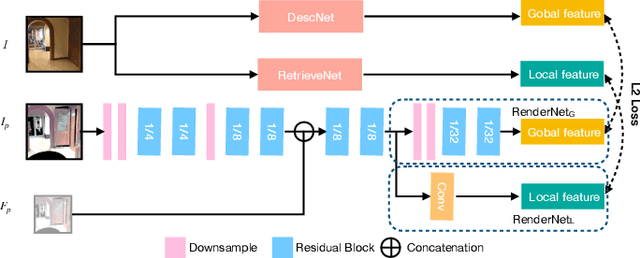

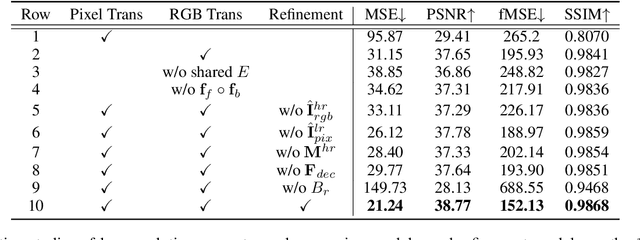
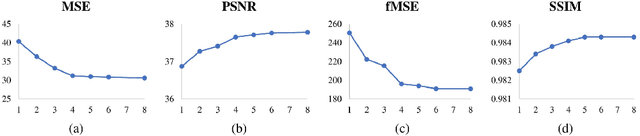
Visual relocalization has been a widely discussed problem in 3D vision: given a pre-constructed 3D visual map, the 6 DoF (Degrees-of-Freedom) pose of a query image is estimated. Relocalization in large-scale indoor environments enables attractive applications such as augmented reality and robot navigation. However, appearance changes fast in such environments when the camera moves, which is challenging for the relocalization system. To address this problem, we propose a virtual view synthesis-based approach, RenderNet, to enrich the database and refine poses regarding this particular scenario. Instead of rendering real images which requires high-quality 3D models, we opt to directly render the needed global and local features of virtual viewpoints and apply them in the subsequent image retrieval and feature matching operations respectively. The proposed method can largely improve the performance in large-scale indoor environments, e.g., achieving an improvement of 7.1\% and 12.2\% on the Inloc dataset.
Exploring Resolution and Degradation Clues as Self-supervised Signal for Low Quality Object Detection
Aug 05, 2022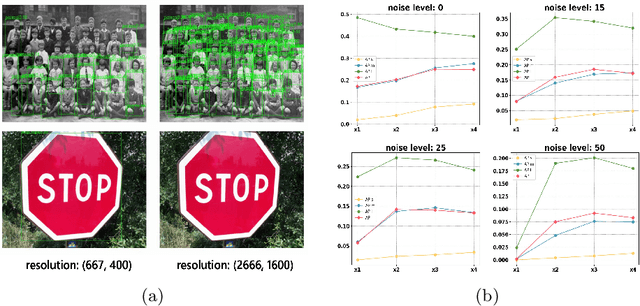
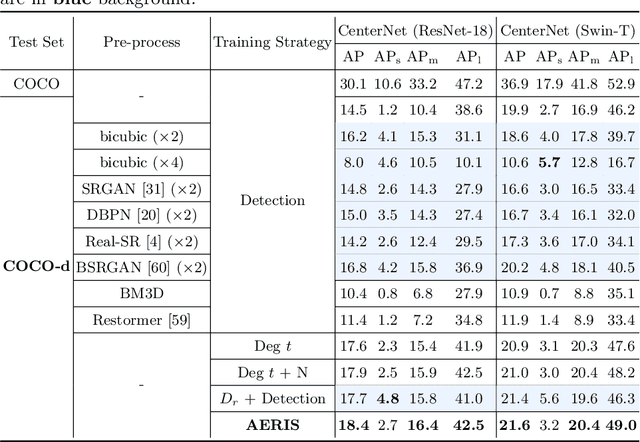
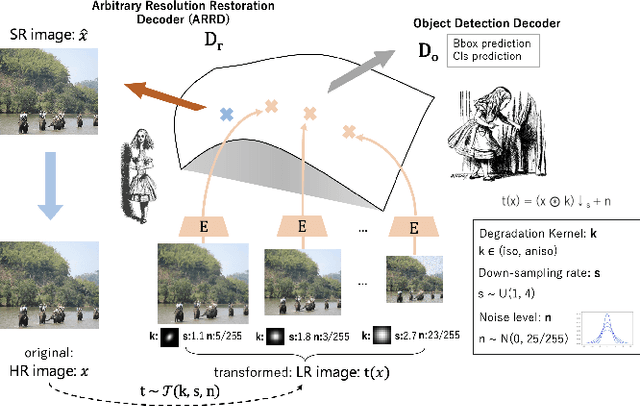
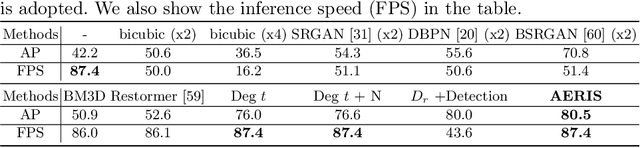
Image restoration algorithms such as super resolution (SR) are indispensable pre-processing modules for object detection in low quality images. Most of these algorithms assume the degradation is fixed and known a priori. However, in practical, either the real degradation or optimal up-sampling ratio rate is unknown or differs from assumption, leading to a deteriorating performance for both the pre-processing module and the consequent high-level task such as object detection. Here, we propose a novel self-supervised framework to detect objects in degraded low resolution images. We utilizes the downsampling degradation as a kind of transformation for self-supervised signals to explore the equivariant representation against various resolutions and other degradation conditions. The Auto Encoding Resolution in Self-supervision (AERIS) framework could further take the advantage of advanced SR architectures with an arbitrary resolution restoring decoder to reconstruct the original correspondence from the degraded input image. Both the representation learning and object detection are optimized jointly in an end-to-end training fashion. The generic AERIS framework could be implemented on various mainstream object detection architectures with different backbones. The extensive experiments show that our methods has achieved superior performance compared with existing methods when facing variant degradation situations. Code would be released at https://github.com/cuiziteng/ECCV_AERIS.
Personalized Image Semantic Segmentation
Aug 12, 2021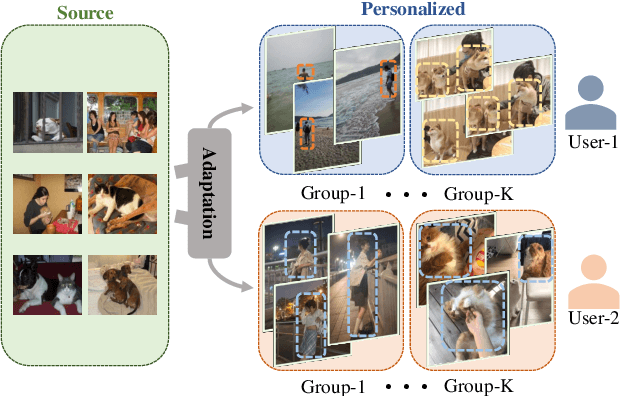
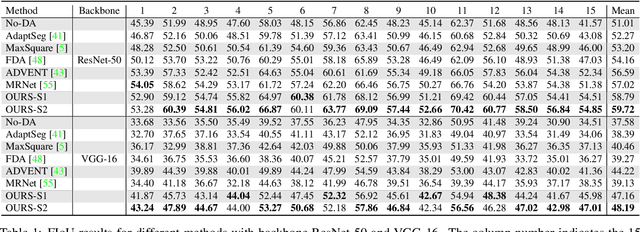
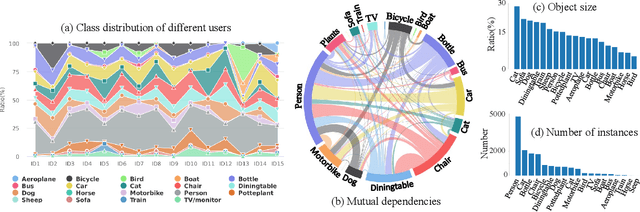
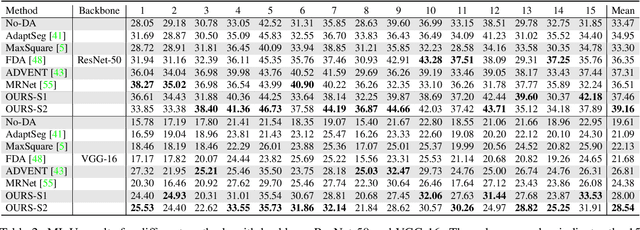
Semantic segmentation models trained on public datasets have achieved great success in recent years. However, these models didn't consider the personalization issue of segmentation though it is important in practice. In this paper, we address the problem of personalized image segmentation. The objective is to generate more accurate segmentation results on unlabeled personalized images by investigating the data's personalized traits. To open up future research in this area, we collect a large dataset containing various users' personalized images called PIS (Personalized Image Semantic Segmentation). We also survey some recent researches related to this problem and report their performance on our dataset. Furthermore, by observing the correlation among a user's personalized images, we propose a baseline method that incorporates the inter-image context when segmenting certain images. Extensive experiments show that our method outperforms the existing methods on the proposed dataset. The code and the PIS dataset will be made publicly available.
Improving Accuracy and Explainability of Online Handwriting Recognition
Sep 14, 2022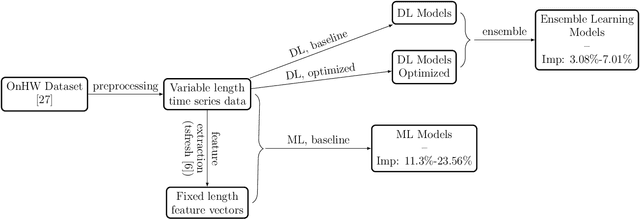
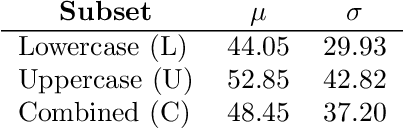
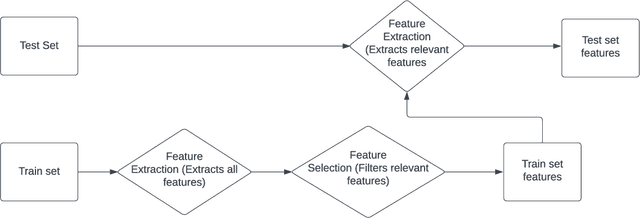
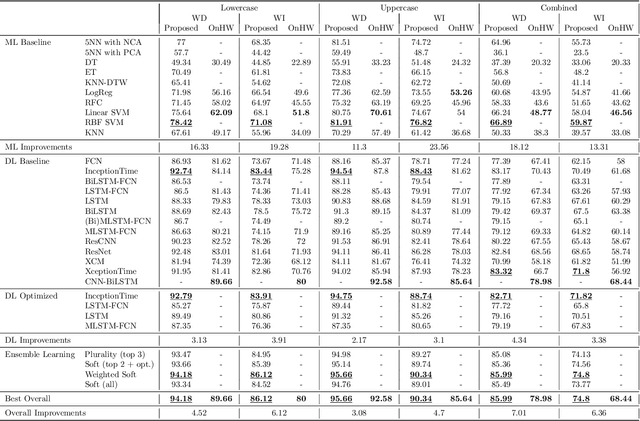
Handwriting recognition technology allows recognizing a written text from a given data. The recognition task can target letters, symbols, or words, and the input data can be a digital image or recorded by various sensors. A wide range of applications from signature verification to electronic document processing can be realized by implementing efficient and accurate handwriting recognition algorithms. Over the years, there has been an increasing interest in experimenting with different types of technology to collect handwriting data, create datasets, and develop algorithms to recognize characters and symbols. More recently, the OnHW-chars dataset has been published that contains multivariate time series data of the English alphabet collected using a ballpoint pen fitted with sensors. The authors of OnHW-chars also provided some baseline results through their machine learning (ML) and deep learning (DL) classifiers. In this paper, we develop handwriting recognition models on the OnHW-chars dataset and improve the accuracy of previous models. More specifically, our ML models provide $11.3\%$-$23.56\%$ improvements over the previous ML models, and our optimized DL models with ensemble learning provide $3.08\%$-$7.01\%$ improvements over the previous DL models. In addition to our accuracy improvements over the spectrum, we aim to provide some level of explainability for our models to provide more logic behind chosen methods and why the models make sense for the data type in the dataset. Our results are verifiable and reproducible via the provided public repository.
Transformer based Models for Unsupervised Anomaly Segmentation in Brain MR Images
Jul 05, 2022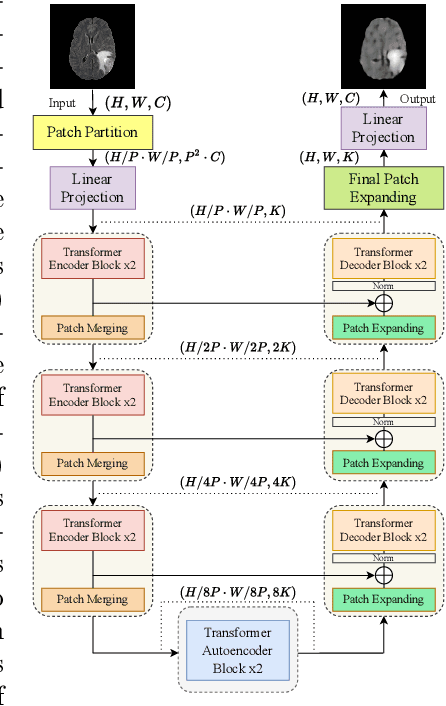
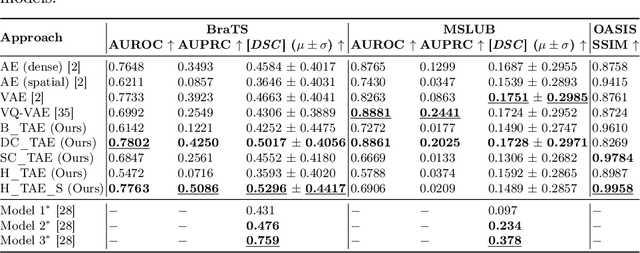
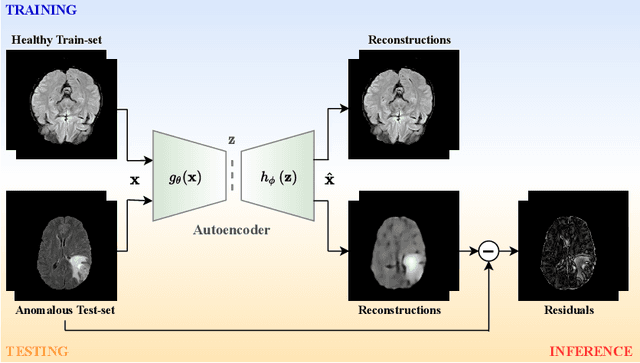
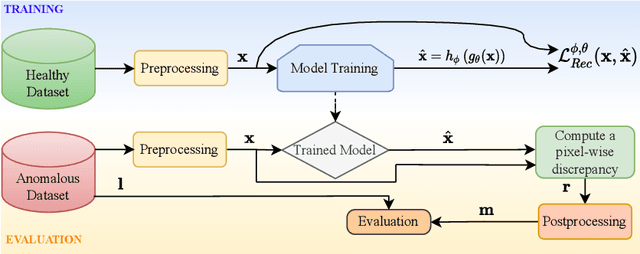
The quality of patient care associated with diagnostic radiology is proportionate to a physician workload. Segmentation is a fundamental limiting precursor to diagnostic and therapeutic procedures. Advances in Machine Learning (ML) aim to increase diagnostic efficiency to replace single application with generalized algorithms. In Unsupervised Anomaly Detection (UAD), Convolutional Neural Network (CNN) based Autoencoders (AEs) and Variational Autoencoders (VAEs) are considered as a de facto approach for reconstruction based anomaly segmentation. Looking for anomalous regions in medical images is one of the main applications that use anomaly segmentation. The restricted receptive field in CNNs limit the CNN to model the global context and hence if the anomalous regions cover parts of the image, the CNN-based AEs are not capable to bring semantic understanding of the image. On the other hand, Vision Transformers (ViTs) have emerged as a competitive alternative to CNNs. It relies on the self-attention mechanism that is capable to relate image patches to each other. To reconstruct a coherent and more realistic image, in this work, we investigate Transformer capabilities in building AEs for reconstruction based UAD task. We focus on anomaly segmentation for Brain Magnetic Resonance Imaging (MRI) and present five Transformer-based models while enabling segmentation performance comparable or superior to State-of-The-Art (SOTA) models. The source code is available on Github https://github.com/ahmedgh970/Transformers_Unsupervised_Anomaly_Segmentation.git
MetaComp: Learning to Adapt for Online Depth Completion
Jul 21, 2022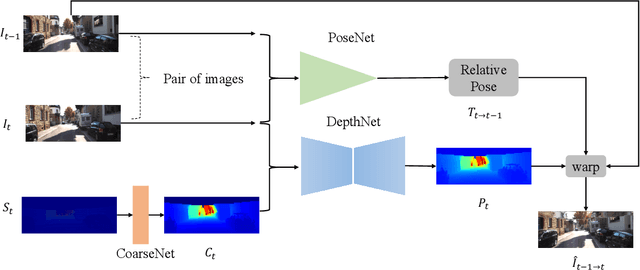
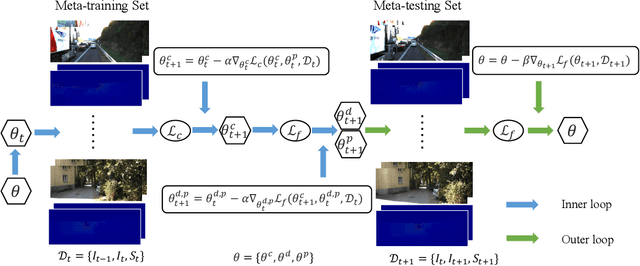
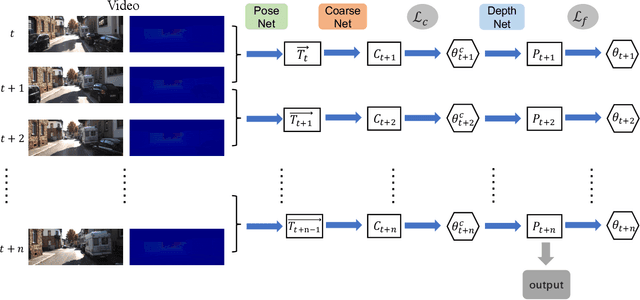
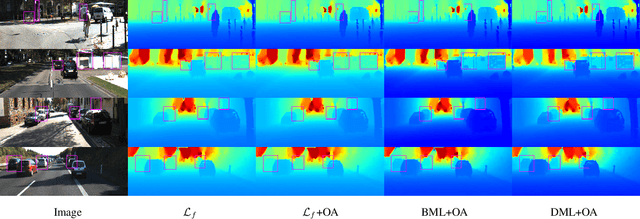
Relying on deep supervised or self-supervised learning, previous methods for depth completion from paired single image and sparse depth data have achieved impressive performance in recent years. However, facing a new environment where the test data occurs online and differs from the training data in the RGB image content and depth sparsity, the trained model might suffer severe performance drop. To encourage the trained model to work well in such conditions, we expect it to be capable of adapting to the new environment continuously and effectively. To achieve this, we propose MetaComp. It utilizes the meta-learning technique to simulate adaptation policies during the training phase, and then adapts the model to new environments in a self-supervised manner in testing. Considering that the input is multi-modal data, it would be challenging to adapt a model to variations in two modalities simultaneously, due to significant differences in structure and form of the two modal data. Therefore, we further propose to disentangle the adaptation procedure in the basic meta-learning training into two steps, the first one focusing on the depth sparsity while the second attending to the image content. During testing, we take the same strategy to adapt the model online to new multi-modal data. Experimental results and comprehensive ablations show that our MetaComp is capable of adapting to the depth completion in a new environment effectively and robust to changes in different modalities.
A new face swap method for image and video domains: a technical report
Feb 07, 2022Deep fake technology became a hot field of research in the last few years. Researchers investigate sophisticated Generative Adversarial Networks (GAN), autoencoders, and other approaches to establish precise and robust algorithms for face swapping. Achieved results show that the deep fake unsupervised synthesis task has problems in terms of the visual quality of generated data. These problems usually lead to high fake detection accuracy when an expert analyzes them. The first problem is that existing image-to-image approaches do not consider video domain specificity and frame-by-frame processing leads to face jittering and other clearly visible distortions. Another problem is the generated data resolution, which is low for many existing methods due to high computational complexity. The third problem appears when the source face has larger proportions (like bigger cheeks), and after replacement it becomes visible on the face border. Our main goal was to develop such an approach that could solve these problems and outperform existing solutions on a number of clue metrics. We introduce a new face swap pipeline that is based on FaceShifter architecture and fixes the problems stated above. With a new eye loss function, super-resolution block, and Gaussian-based face mask generation leads to improvements in quality which is confirmed during evaluation.
Adaptive Diffusion Priors for Accelerated MRI Reconstruction
Jul 12, 2022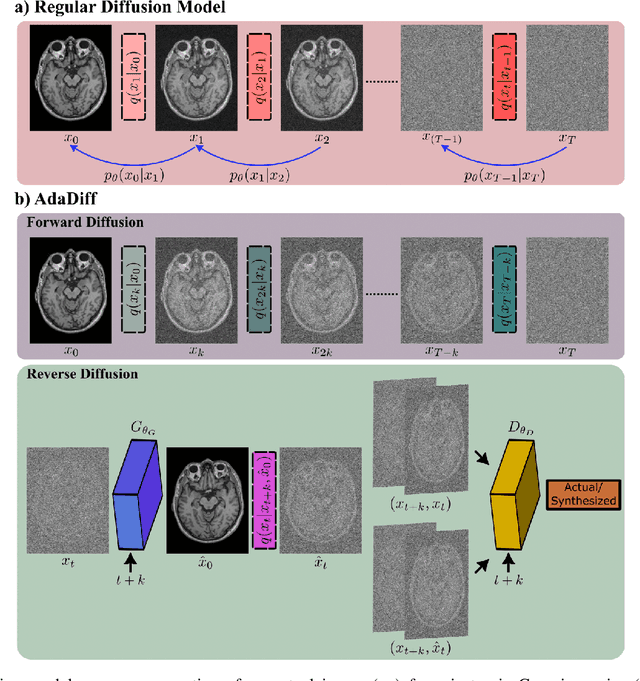
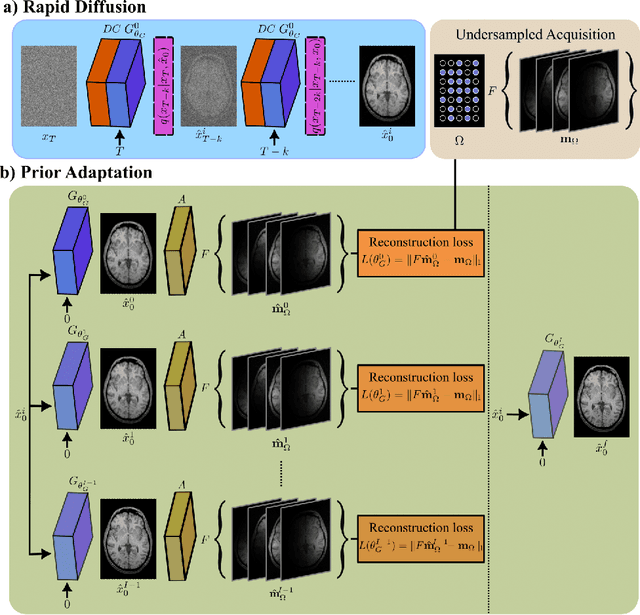
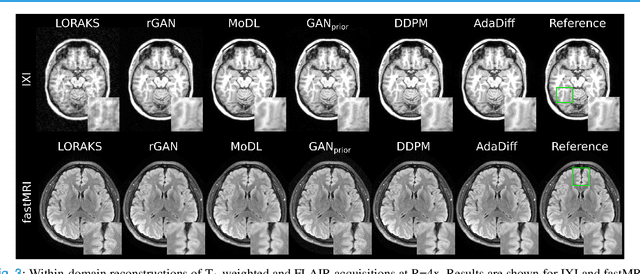
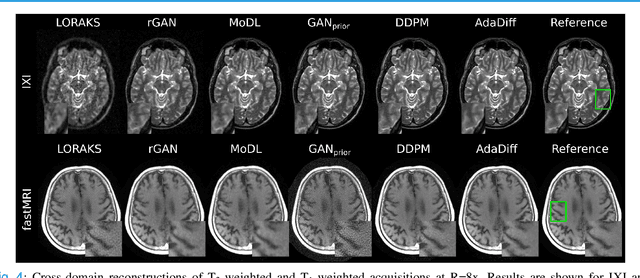
Deep MRI reconstruction is commonly performed with conditional models that map undersampled data as input onto fully-sampled data as output. Conditional models perform de-aliasing under knowledge of the accelerated imaging operator, so they poorly generalize under domain shifts in the operator. Unconditional models are a powerful alternative that instead learn generative image priors to improve reliability against domain shifts. Recent diffusion models are particularly promising given their high representational diversity and sample quality. Nevertheless, projections through a static image prior can lead to suboptimal performance. Here we propose a novel MRI reconstruction, AdaDiff, based on an adaptive diffusion prior. To enable efficient image sampling, an adversarial mapper is introduced that enables use of large diffusion steps. A two-phase reconstruction is performed with the trained prior: a rapid-diffusion phase that produces an initial reconstruction, and an adaptation phase where the diffusion prior is updated to minimize reconstruction loss on acquired k-space data. Demonstrations on multi-contrast brain MRI clearly indicate that AdaDiff achieves superior performance to competing models in cross-domain tasks, and superior or on par performance in within-domain tasks.