 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
QSAM-Net: Rain streak removal by quaternion neural network with self-attention module
Aug 08, 2022
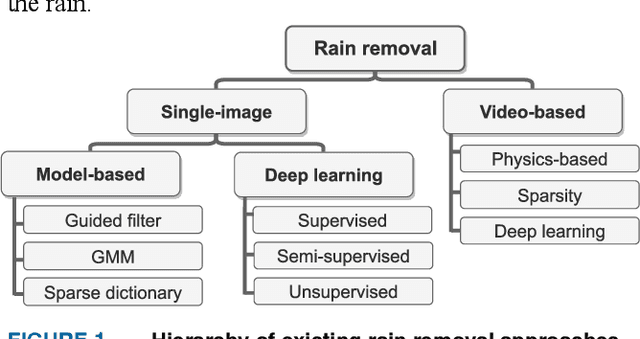
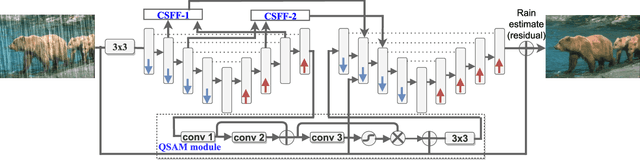


Images captured in real-world applications in remote sensing, image or video retrieval, and outdoor surveillance suffer degraded quality introduced by poor weather conditions. Conditions such as rain and mist, introduce artifacts that make visual analysis challenging and limit the performance of high-level computer vision methods. For time-critical applications where a rapid response is necessary, it becomes crucial to develop algorithms that automatically remove rain, without diminishing the quality of the image contents. This article aims to develop a novel quaternion multi-stage multiscale neural network with a self-attention module called QSAM-Net to remove rain streaks. The novelty of this algorithm is that it requires significantly fewer parameters by a factor of 3.98, over prior methods, while improving visual quality. This is demonstrated by the extensive evaluation and benchmarking on synthetic and real-world rainy images. This feature of QSAM-Net makes the network suitable for implementation on edge devices and applications requiring near real-time performance. The experiments demonstrate that by improving the visual quality of images. In addition, object detection accuracy and training speed are also improved.
FP8 Formats for Deep Learning
Sep 12, 2022
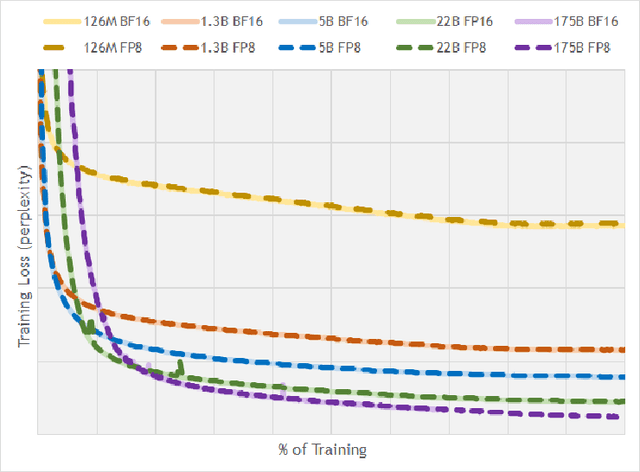
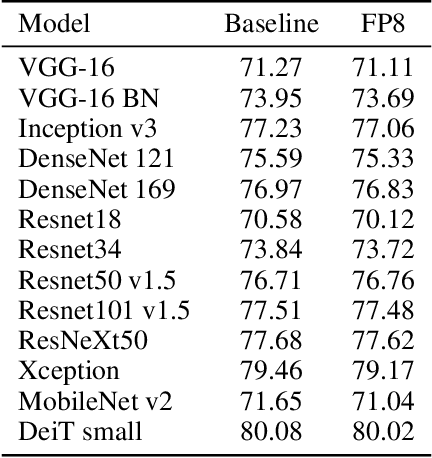
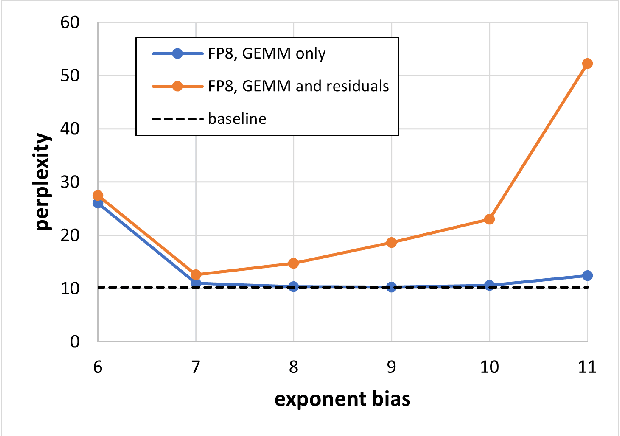
FP8 is a natural progression for accelerating deep learning training inference beyond the 16-bit formats common in modern processors. In this paper we propose an 8-bit floating point (FP8) binary interchange format consisting of two encodings - E4M3 (4-bit exponent and 3-bit mantissa) and E5M2 (5-bit exponent and 2-bit mantissa). While E5M2 follows IEEE 754 conventions for representatio of special values, E4M3's dynamic range is extended by not representing infinities and having only one mantissa bit-pattern for NaNs. We demonstrate the efficacy of the FP8 format on a variety of image and language tasks, effectively matching the result quality achieved by 16-bit training sessions. Our study covers the main modern neural network architectures - CNNs, RNNs, and Transformer-based models, leaving all the hyperparameters unchanged from the 16-bit baseline training sessions. Our training experiments include large, up to 175B parameter, language models. We also examine FP8 post-training-quantization of language models trained using 16-bit formats that resisted fixed point int8 quantization.
GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models
Dec 22, 2021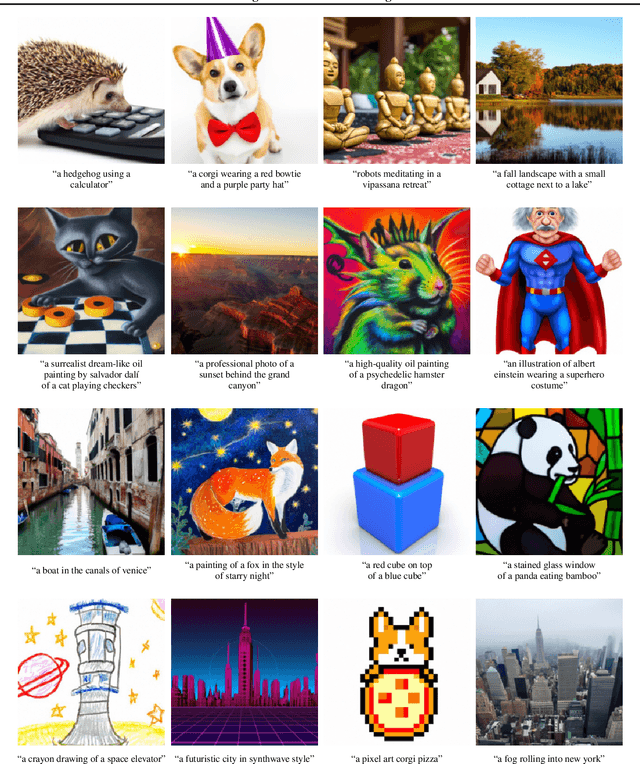


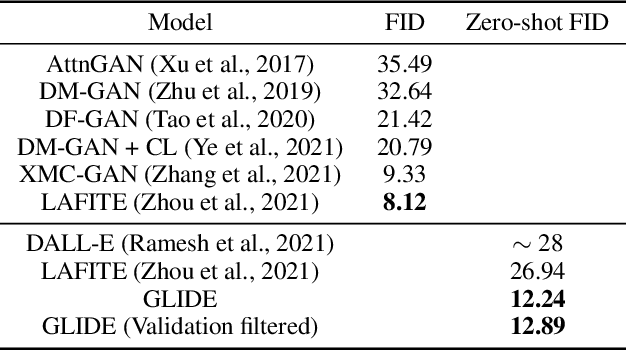
Diffusion models have recently been shown to generate high-quality synthetic images, especially when paired with a guidance technique to trade off diversity for fidelity. We explore diffusion models for the problem of text-conditional image synthesis and compare two different guidance strategies: CLIP guidance and classifier-free guidance. We find that the latter is preferred by human evaluators for both photorealism and caption similarity, and often produces photorealistic samples. Samples from a 3.5 billion parameter text-conditional diffusion model using classifier-free guidance are favored by human evaluators to those from DALL-E, even when the latter uses expensive CLIP reranking. Additionally, we find that our models can be fine-tuned to perform image inpainting, enabling powerful text-driven image editing. We train a smaller model on a filtered dataset and release the code and weights at https://github.com/openai/glide-text2im.
Communication-Efficient and Privacy-Preserving Feature-based Federated Transfer Learning
Sep 12, 2022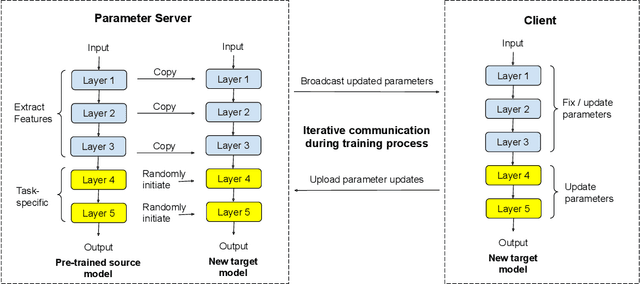
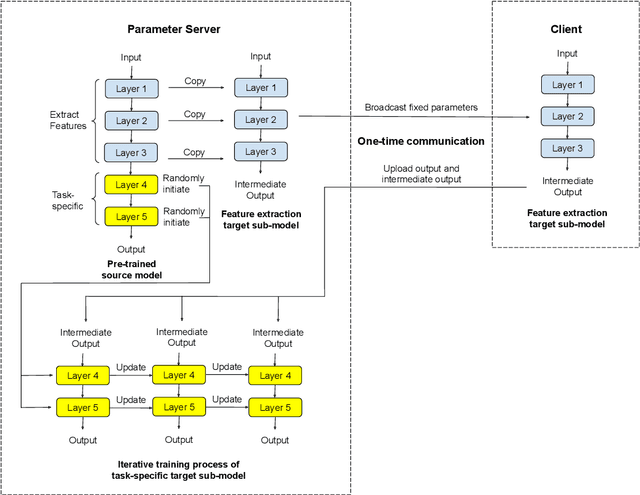


Federated learning has attracted growing interest as it preserves the clients' privacy. As a variant of federated learning, federated transfer learning utilizes the knowledge from similar tasks and thus has also been intensively studied. However, due to the limited radio spectrum, the communication efficiency of federated learning via wireless links is critical since some tasks may require thousands of Terabytes of uplink payload. In order to improve the communication efficiency, we in this paper propose the feature-based federated transfer learning as an innovative approach to reduce the uplink payload by more than five orders of magnitude compared to that of existing approaches. We first introduce the system design in which the extracted features and outputs are uploaded instead of parameter updates, and then determine the required payload with this approach and provide comparisons with the existing approaches. Subsequently, we analyze the random shuffling scheme that preserves the clients' privacy. Finally, we evaluate the performance of the proposed learning scheme via experiments on an image classification task to show its effectiveness.
Federated CycleGAN for Privacy-Preserving Image-to-Image Translation
Jun 17, 2021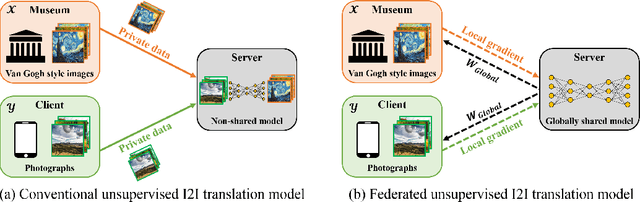
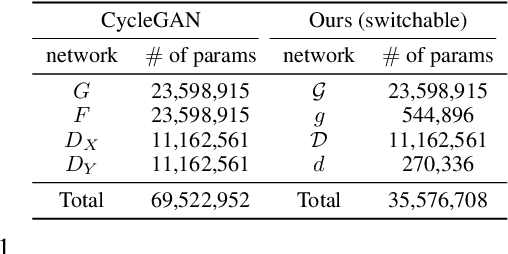
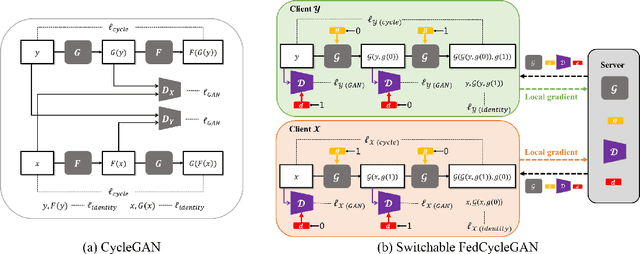
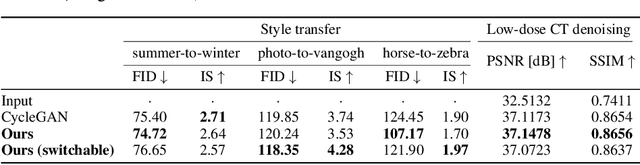
Unsupervised image-to-image translation methods such as CycleGAN learn to convert images from one domain to another using unpaired training data sets from different domains. Unfortunately, these approaches still require centrally collected unpaired records, potentially violating privacy and security issues. Although the recent federated learning (FL) allows a neural network to be trained without data exchange, the basic assumption of the FL is that all clients have their own training data from a similar domain, which is different from our image-to-image translation scenario in which each client has images from its unique domain and the goal is to learn image translation between different domains without accessing the target domain data. To address this, here we propose a novel federated CycleGAN architecture that can learn image translation in an unsupervised manner while maintaining the data privacy. Specifically, our approach arises from a novel observation that CycleGAN loss can be decomposed into the sum of client specific local objectives that can be evaluated using only their data. This local objective decomposition allows multiple clients to participate in federated CycleGAN training without sacrificing performance. Furthermore, our method employs novel switchable generator and discriminator architecture using Adaptive Instance Normalization (AdaIN) that significantly reduces the band-width requirement of the federated learning. Our experimental results on various unsupervised image translation tasks show that our federated CycleGAN provides comparable performance compared to the non-federated counterpart.
Experiments on Anomaly Detection in Autonomous Driving by Forward-Backward Style Transfers
Jul 13, 2022



Great progress has been achieved in the community of autonomous driving in the past few years. As a safety-critical problem, however, anomaly detection is a huge hurdle towards a large-scale deployment of autonomous vehicles in the real world. While many approaches, such as uncertainty estimation or segmentation-based image resynthesis, are extremely promising, there is more to be explored. Especially inspired by works on anomaly detection based on image resynthesis, we propose a novel approach for anomaly detection through style transfer. We leverage generative models to map an image from its original style domain of road traffic to an arbitrary one and back to generate pixelwise anomaly scores. However, our experiments have proven our hypothesis wrong, and we were unable to produce significant results. Nevertheless, we want to share our findings, so that others can learn from our experiments.
Mixed X-Ray Image Separation for Artworks with Concealed Designs
Jan 23, 2022
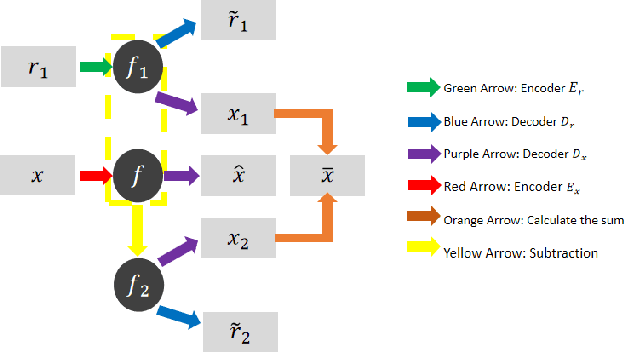
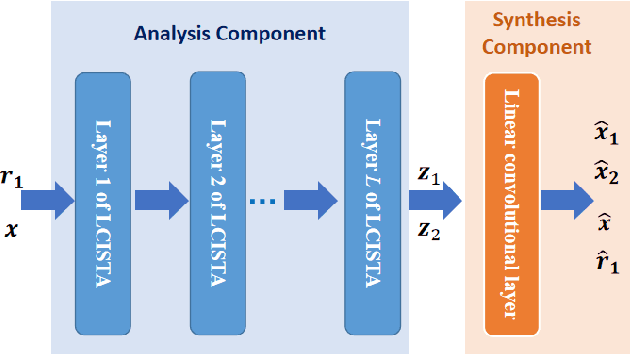
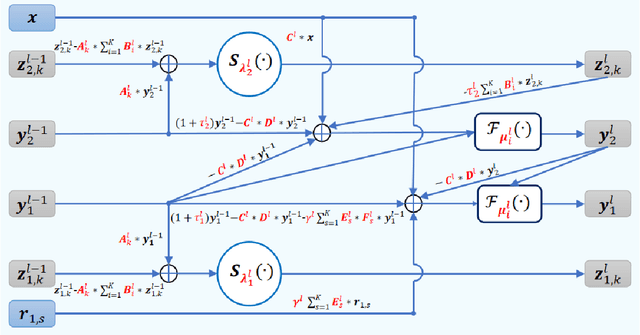
In this paper, we focus on X-ray images of paintings with concealed sub-surface designs (e.g., deriving from reuse of the painting support or revision of a composition by the artist), which include contributions from both the surface painting and the concealed features. In particular, we propose a self-supervised deep learning-based image separation approach that can be applied to the X-ray images from such paintings to separate them into two hypothetical X-ray images. One of these reconstructed images is related to the X-ray image of the concealed painting, while the second one contains only information related to the X-ray of the visible painting. The proposed separation network consists of two components: the analysis and the synthesis sub-networks. The analysis sub-network is based on learned coupled iterative shrinkage thresholding algorithms (LCISTA) designed using algorithm unrolling techniques, and the synthesis sub-network consists of several linear mappings. The learning algorithm operates in a totally self-supervised fashion without requiring a sample set that contains both the mixed X-ray images and the separated ones. The proposed method is demonstrated on a real painting with concealed content, Do\~na Isabel de Porcel by Francisco de Goya, to show its effectiveness.
Bangla Image Caption Generation through CNN-Transformer based Encoder-Decoder Network
Oct 24, 2021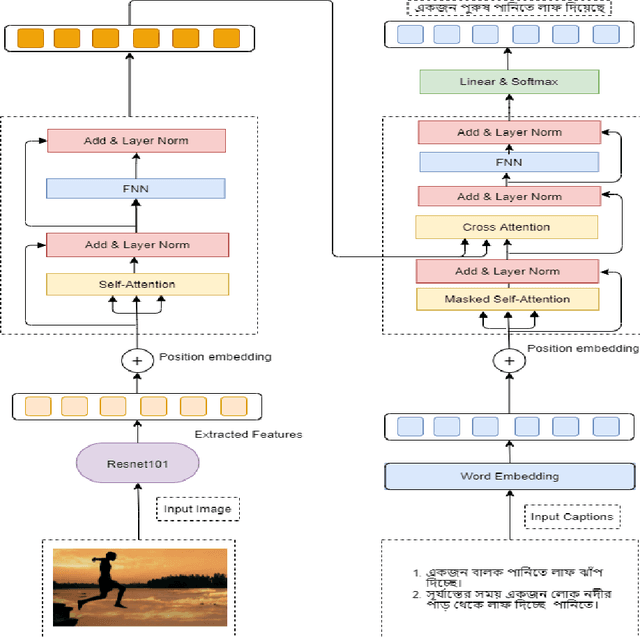

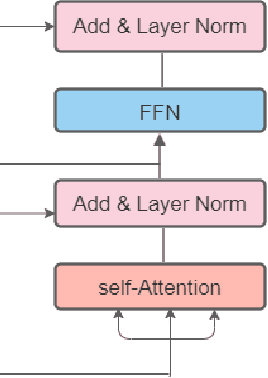
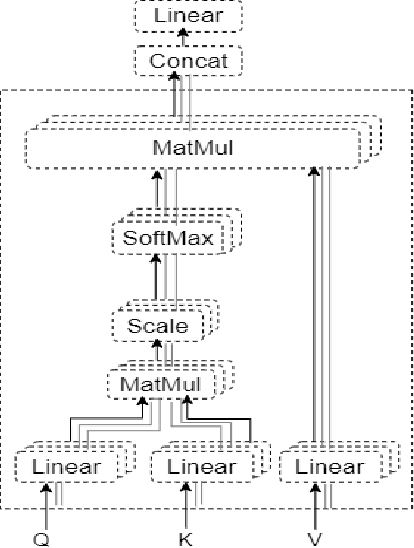
Automatic Image Captioning is the never-ending effort of creating syntactically and validating the accuracy of textual descriptions of an image in natural language with context. The encoder-decoder structure used throughout existing Bengali Image Captioning (BIC) research utilized abstract image feature vectors as the encoder's input. We propose a novel transformer-based architecture with an attention mechanism with a pre-trained ResNet-101 model image encoder for feature extraction from images. Experiments demonstrate that the language decoder in our technique captures fine-grained information in the caption and, then paired with image features, produces accurate and diverse captions on the BanglaLekhaImageCaptions dataset. Our approach outperforms all existing Bengali Image Captioning work and sets a new benchmark by scoring 0.694 on BLEU-1, 0.630 on BLEU-2, 0.582 on BLEU-3, and 0.337 on METEOR.
PC-GANs: Progressive Compensation Generative Adversarial Networks for Pan-sharpening
Jul 29, 2022
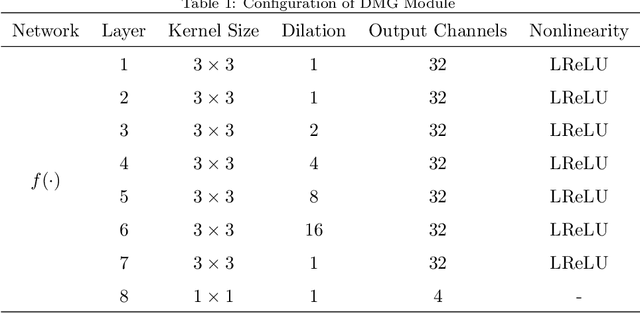
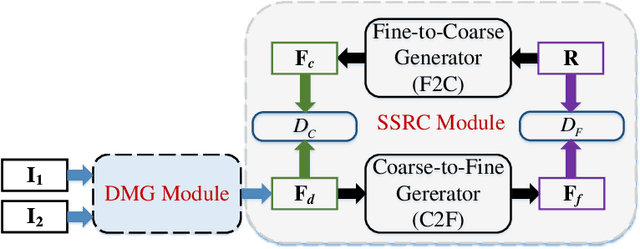
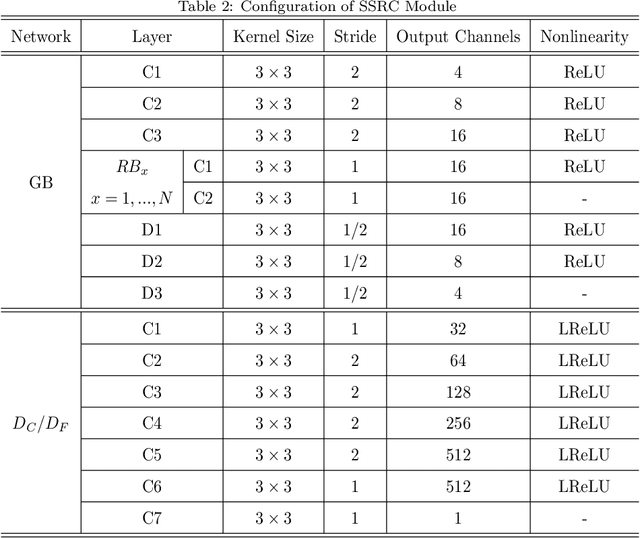
The fusion of multispectral and panchromatic images is always dubbed pansharpening. Most of the available deep learning-based pan-sharpening methods sharpen the multispectral images through a one-step scheme, which strongly depends on the reconstruction ability of the network. However, remote sensing images always have large variations, as a result, these one-step methods are vulnerable to the error accumulation and thus incapable of preserving spatial details as well as the spectral information. In this paper, we propose a novel two-step model for pan-sharpening that sharpens the MS image through the progressive compensation of the spatial and spectral information. Firstly, a deep multiscale guided generative adversarial network is used to preliminarily enhance the spatial resolution of the MS image. Starting from the pre-sharpened MS image in the coarse domain, our approach then progressively refines the spatial and spectral residuals over a couple of generative adversarial networks (GANs) that have reverse architectures. The whole model is composed of triple GANs, and based on the specific architecture, a joint compensation loss function is designed to enable the triple GANs to be trained simultaneously. Moreover, the spatial-spectral residual compensation structure proposed in this paper can be extended to other pan-sharpening methods to further enhance their fusion results. Extensive experiments are performed on different datasets and the results demonstrate the effectiveness and efficiency of our proposed method.
$β$-CapsNet: Learning Disentangled Representation for CapsNet by Information Bottleneck
Sep 12, 2022We present a framework for learning disentangled representation of CapsNet by information bottleneck constraint that distills information into a compact form and motivates to learn an interpretable factorized capsule. In our $\beta$-CapsNet framework, hyperparameter $\beta$ is utilized to trade-off disentanglement and other tasks, variational inference is utilized to convert the information bottleneck term into a KL divergence that is approximated as a constraint on the mean of the capsule. For supervised learning, class independent mask vector is used for understanding the types of variations synthetically irrespective of the image class, we carry out extensive quantitative and qualitative experiments by tuning the parameter $\beta$ to figure out the relationship between disentanglement, reconstruction and classfication performance. Furthermore, the unsupervised $\beta$-CapsNet and the corresponding dynamic routing algorithm is proposed for learning disentangled capsule in an unsupervised manner, extensive empirical evaluations suggest that our $\beta$-CapsNet achieves state-of-the-art disentanglement performance compared to CapsNet and various baselines on several complex datasets both in supervision and unsupervised scenes.