 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Instance-Aware Observer Network for Out-of-Distribution Object Segmentation
Jul 20, 2022
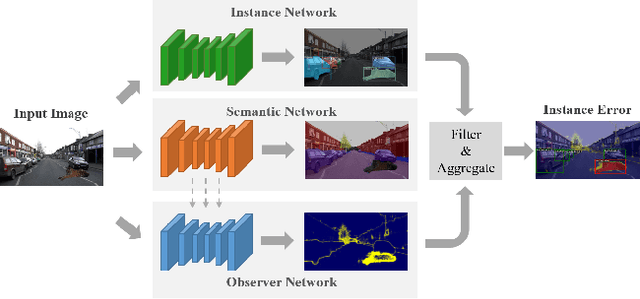
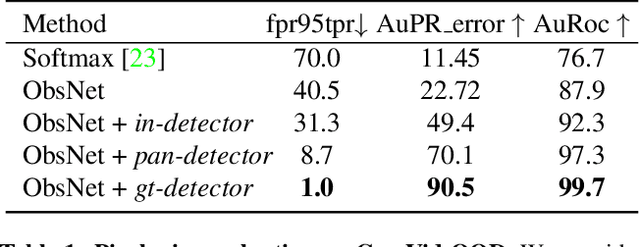

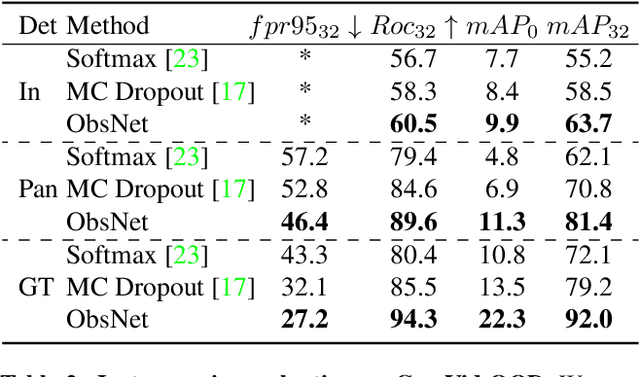
Recent work on Observer Network has shown promising results on Out-Of-Distribution (OOD) detection for semantic segmentation. These methods have difficulty in precisely locating the point of interest in the image, i.e, the anomaly. This limitation is due to the difficulty of fine-grained prediction at the pixel level. To address this issue, we provide instance knowledge to the observer. We extend the approach of ObsNet by harnessing an instance-wise mask prediction. We use an additional, class agnostic, object detector to filter and aggregate observer predictions. Finally, we predict an unique anomaly score for each instance in the image. We show that our proposed method accurately disentangle in-distribution objects from Out-Of-Distribution objects on three datasets.
Graph Signal Processing for Heterogeneous Change Detection Part II: Spectral Domain Analysis
Aug 08, 2022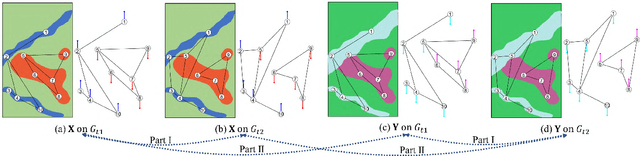
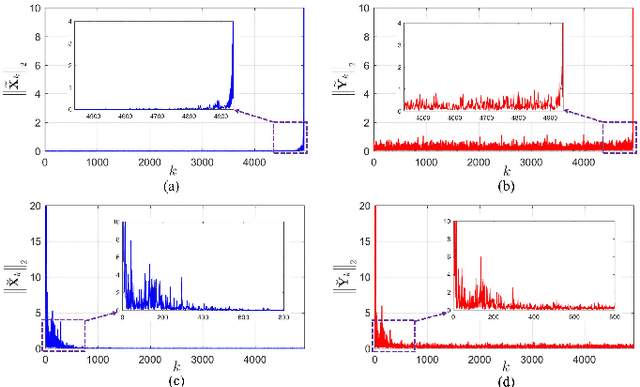
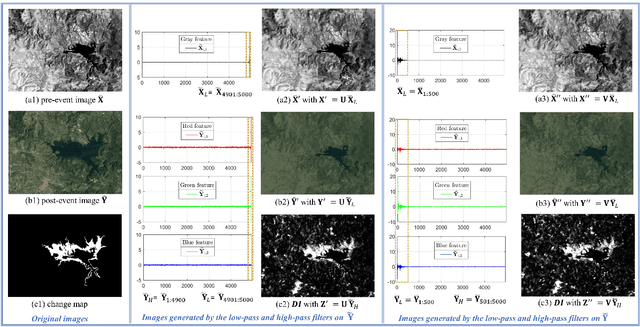
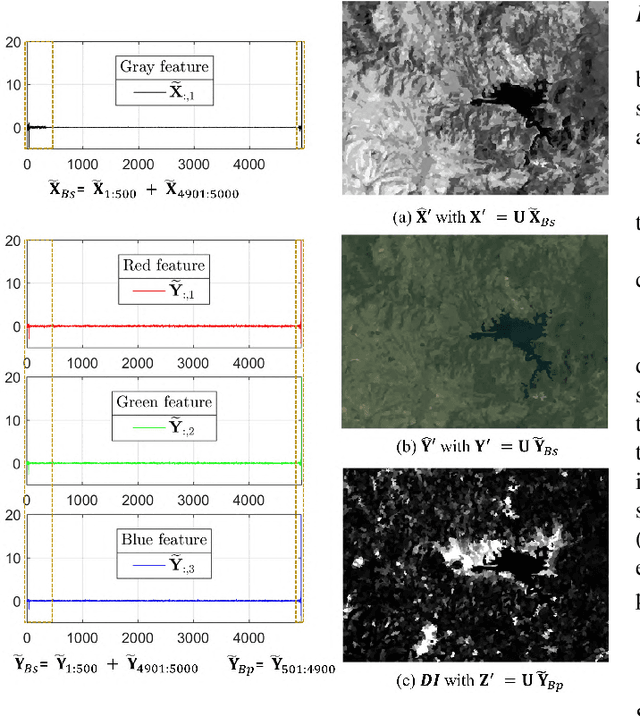
This is the second part of the paper that provides a new strategy for the heterogeneous change detection (HCD) problem, that is, solving HCD from the perspective of graph signal processing (GSP). We construct a graph to represent the structure of each image, and treat each image as a graph signal defined on the graph. In this way, we can convert the HCD problem into a comparison of responses of signals on systems defined on the graphs. In the part I, the changes are measured by comparing the structure difference between the graphs from the vertex domain. In this part II, we analyze the GSP for HCD from the spectral domain. We first analyze the spectral properties of the different images on the same graph, and show that their spectra exhibit commonalities and dissimilarities. Specially, it is the change that leads to the dissimilarities of their spectra. Then, we propose a regression model for the HCD, which decomposes the source signal into the regressed signal and changed signal, and requires the regressed signal have the same spectral property as the target signal on the same graph. With the help of graph spectral analysis, the proposed regression model is flexible and scalable. Experiments conducted on seven real data sets show the effectiveness of the proposed method.
Temporal Disentanglement of Representations for Improved Generalisation in Reinforcement Learning
Jul 12, 2022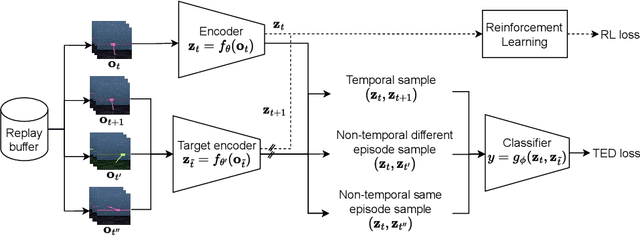

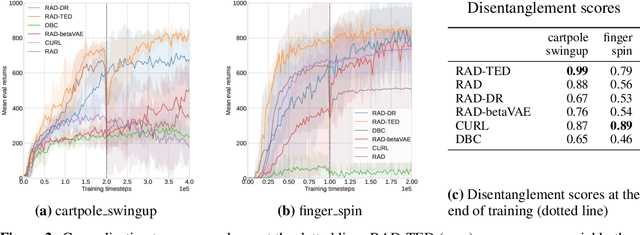
In real-world robotics applications, Reinforcement Learning (RL) agents are often unable to generalise to environment variations that were not observed during training. This issue is intensified for image-based RL where a change in one variable, such as the background colour, can change many pixels in the image, and in turn can change all values in the agent's internal representation of the image. To learn more robust representations, we introduce TEmporal Disentanglement (TED), a self-supervised auxiliary task that leads to disentangled representations using the sequential nature of RL observations. We find empirically that RL algorithms with TED as an auxiliary task adapt more quickly to changes in environment variables with continued training compared to state-of-the-art representation learning methods. Due to the disentangled structure of the representation, we also find that policies trained with TED generalise better to unseen values of variables irrelevant to the task (e.g. background colour) as well as unseen values of variables that affect the optimal policy (e.g. goal positions).
Universal Fourier Attack for Time Series
Sep 02, 2022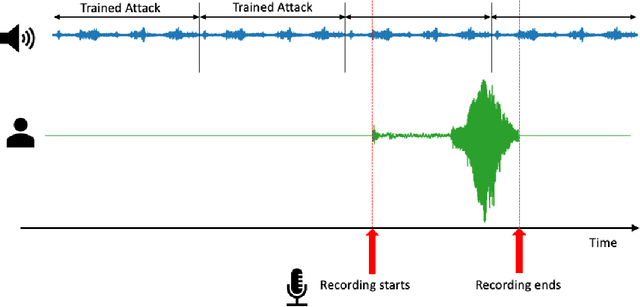
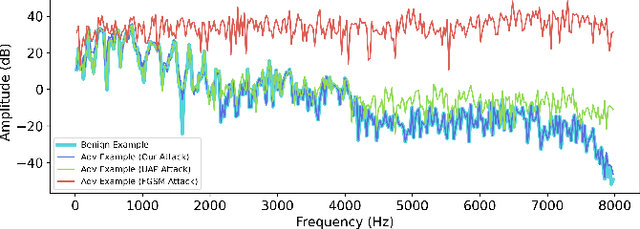
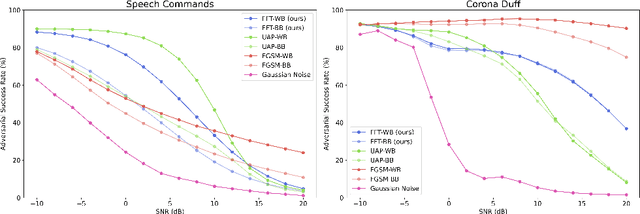
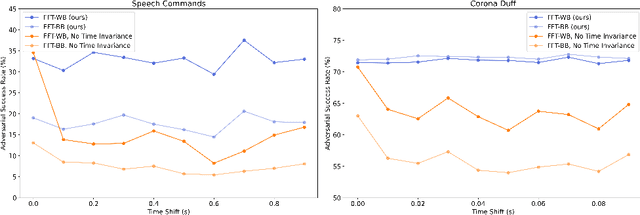
A wide variety of adversarial attacks have been proposed and explored using image and audio data. These attacks are notoriously easy to generate digitally when the attacker can directly manipulate the input to a model, but are much more difficult to implement in the real-world. In this paper we present a universal, time invariant attack for general time series data such that the attack has a frequency spectrum primarily composed of the frequencies present in the original data. The universality of the attack makes it fast and easy to implement as no computation is required to add it to an input, while time invariance is useful for real-world deployment. Additionally, the frequency constraint ensures the attack can withstand filtering. We demonstrate the effectiveness of the attack in two different domains, speech recognition and unintended radiated emission, and show that the attack is robust against common transform-and-compare defense pipelines.
Automated Classification of Nanoparticles with Various Ultrastructures and Sizes
Jul 28, 2022
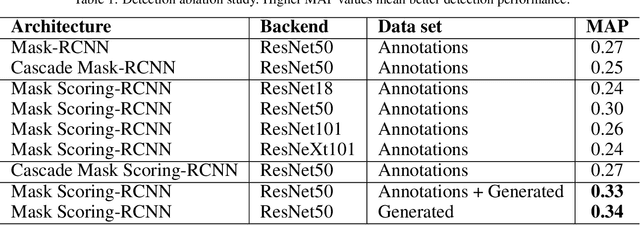
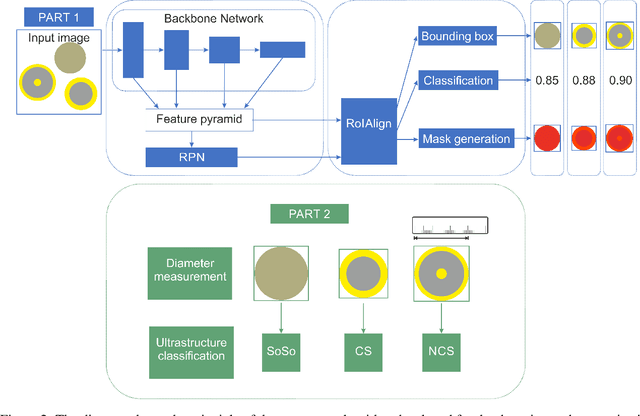
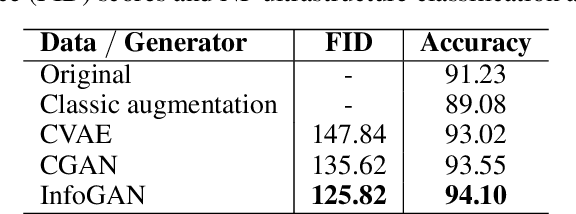
Accurately measuring the size, morphology, and structure of nanoparticles is very important, because they are strongly dependent on their properties for many applications. In this paper, we present a deep-learning based method for nanoparticle measurement and classification trained from a small data set of scanning transmission electron microscopy images. Our approach is comprised of two stages: localization, i.e., detection of nanoparticles, and classification, i.e., categorization of their ultrastructure. For each stage, we optimize the segmentation and classification by analysis of the different state-of-the-art neural networks. We show how the generation of synthetic images, either using image processing or using various image generation neural networks, can be used to improve the results in both stages. Finally, the application of the algorithm to bimetallic nanoparticles demonstrates the automated data collection of size distributions including classification of complex ultrastructures. The developed method can be easily transferred to other material systems and nanoparticle structures.
Bridging Music and Text with Crowdsourced Music Comments: A Sequence-to-Sequence Framework for Thematic Music Comments Generation
Sep 05, 2022
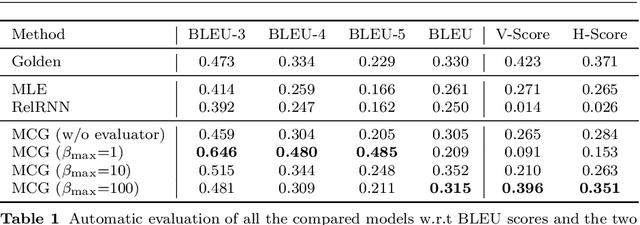
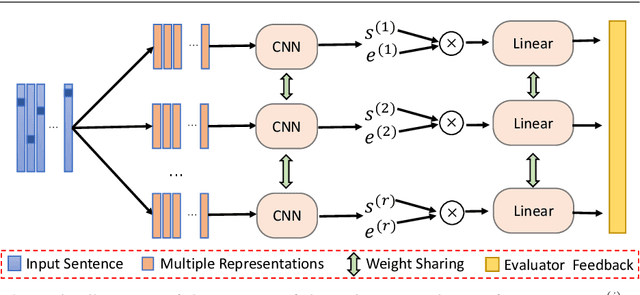

We consider a novel task of automatically generating text descriptions of music. Compared with other well-established text generation tasks such as image caption, the scarcity of well-paired music and text datasets makes it a much more challenging task. In this paper, we exploit the crowd-sourced music comments to construct a new dataset and propose a sequence-to-sequence model to generate text descriptions of music. More concretely, we use the dilated convolutional layer as the basic component of the encoder and a memory based recurrent neural network as the decoder. To enhance the authenticity and thematicity of generated texts, we further propose to fine-tune the model with a discriminator as well as a novel topic evaluator. To measure the quality of generated texts, we also propose two new evaluation metrics, which are more aligned with human evaluation than traditional metrics such as BLEU. Experimental results verify that our model is capable of generating fluent and meaningful comments while containing thematic and content information of the original music.
RFVTM: A Recovery and Filtering Vertex Trichotomy Matching for Remote Sensing Image Registration
Apr 02, 2022



Reliable feature point matching is a vital yet challenging process in feature-based image registration. In this paper,a robust feature point matching algorithm called Recovery and Filtering Vertex Trichotomy Matching (RFVTM) is proposed to remove outliers and retain sufficient inliers for remote sensing images. A novel affine invariant descriptor called vertex trichotomy descriptor is proposed on the basis of that geometrical relations between any of vertices and lines are preserved after affine transformations, which is constructed by mapping each vertex into trichotomy sets. The outlier removals in Vertex Trichotomy Matching (VTM) are implemented by iteratively comparing the disparity of corresponding vertex trichotomy descriptors. Some inliers mistakenly validated by a large amount of outliers are removed in VTM iterations, and several residual outliers close to correct locations cannot be excluded with the same graph structures. Therefore, a recovery and filtering strategy is designed to recover some inliers based on identical vertex trichotomy descriptors and restricted transformation errors. Assisted with the additional recovered inliers, residual outliers can also be filtered out during the process of reaching identical graph for the expanded vertex sets. Experimental results demonstrate the superior performance on precision and stability of this algorithm under various conditions, such as remote sensing images with large transformations, duplicated patterns, or inconsistent spectral content.
CACTUSS: Common Anatomical CT-US Space for US examinations
Jul 18, 2022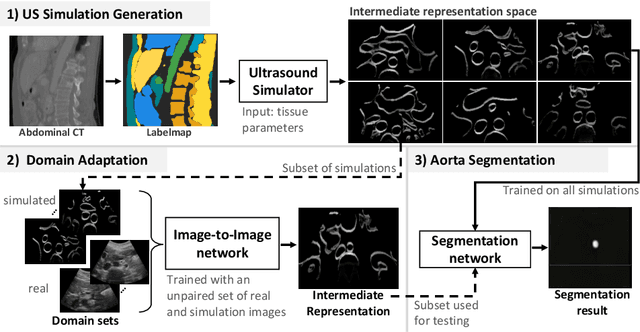
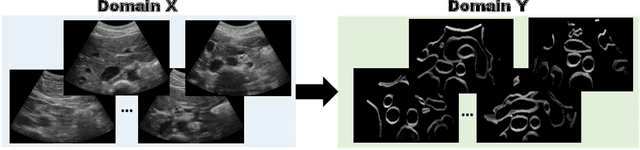
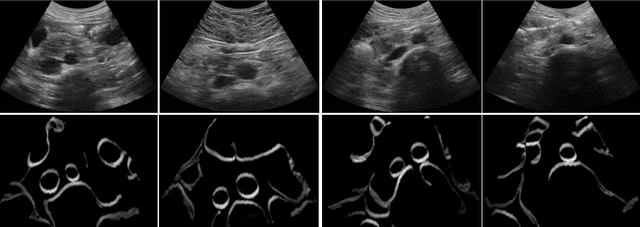
Abdominal aortic aneurysm (AAA) is a vascular disease in which a section of the aorta enlarges, weakening its walls and potentially rupturing the vessel. Abdominal ultrasound has been utilized for diagnostics, but due to its limited image quality and operator dependency, CT scans are usually required for monitoring and treatment planning. Recently, abdominal CT datasets have been successfully utilized to train deep neural networks for automatic aorta segmentation. Knowledge gathered from this solved task could therefore be leveraged to improve US segmentation for AAA diagnosis and monitoring. To this end, we propose CACTUSS: a common anatomical CT-US space, which acts as a virtual bridge between CT and US modalities to enable automatic AAA screening sonography. CACTUSS makes use of publicly available labelled data to learn to segment based on an intermediary representation that inherits properties from both US and CT. We train a segmentation network in this new representation and employ an additional image-to-image translation network which enables our model to perform on real B-mode images. Quantitative comparisons against fully supervised methods demonstrate the capabilities of CACTUSS in terms of Dice Score and diagnostic metrics, showing that our method also meets the clinical requirements for AAA scanning and diagnosis.
Open-Vocabulary Multi-Label Classification via Multi-modal Knowledge Transfer
Jul 05, 2022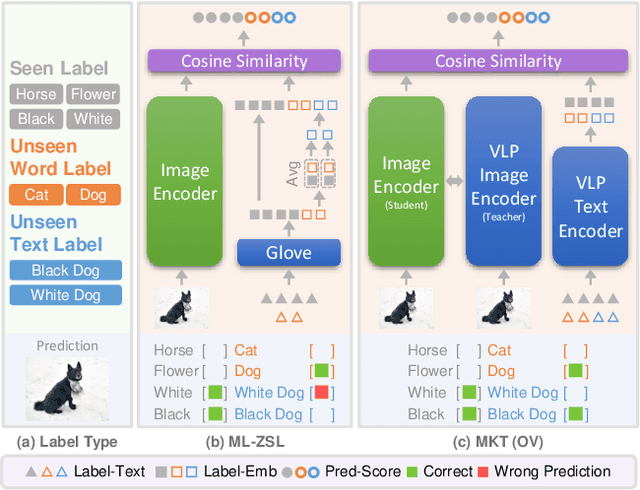



Real-world recognition system often encounters a plenty of unseen labels in practice. To identify such unseen labels, multi-label zero-shot learning (ML-ZSL) focuses on transferring knowledge by a pre-trained textual label embedding (e.g., GloVe). However, such methods only exploit singlemodal knowledge from a language model, while ignoring the rich semantic information inherent in image-text pairs. Instead, recently developed open-vocabulary (OV) based methods succeed in exploiting such information of image-text pairs in object detection, and achieve impressive performance. Inspired by the success of OV-based methods, we propose a novel open-vocabulary framework, named multimodal knowledge transfer (MKT), for multi-label classification. Specifically, our method exploits multi-modal knowledge of image-text pairs based on a vision and language pretraining (VLP) model. To facilitate transferring the imagetext matching ability of VLP model, knowledge distillation is used to guarantee the consistency of image and label embeddings, along with prompt tuning to further update the label embeddings. To further recognize multiple objects, a simple but effective two-stream module is developed to capture both local and global features. Extensive experimental results show that our method significantly outperforms state-of-theart methods on public benchmark datasets. Code will be available at https://github.com/seanhe97/MKT.
On Real-time Image Reconstruction with Neural Networks for MRI-guided Radiotherapy
Feb 10, 2022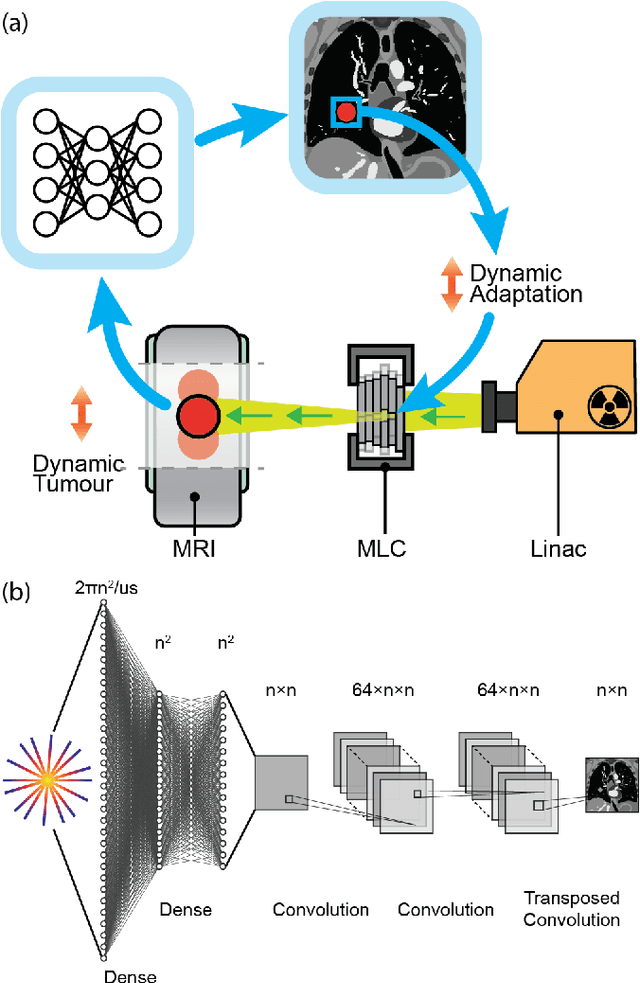
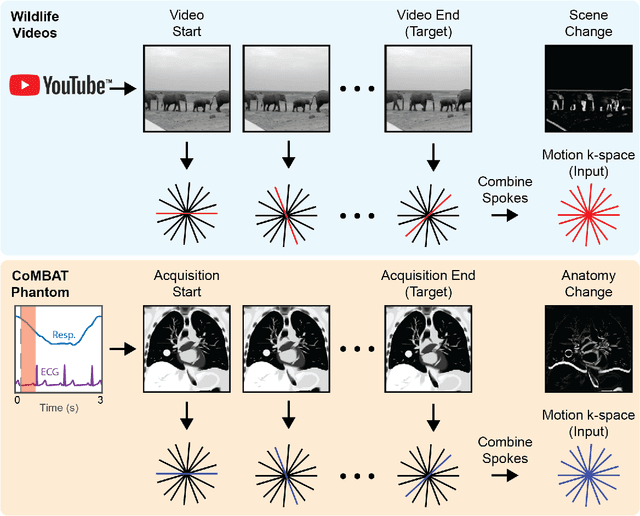
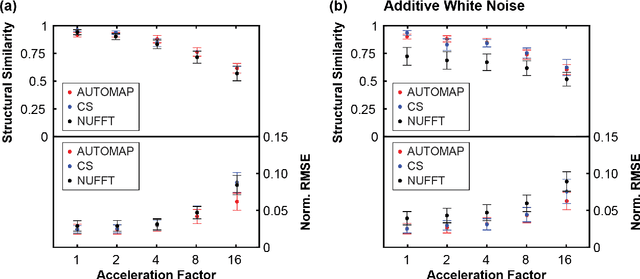
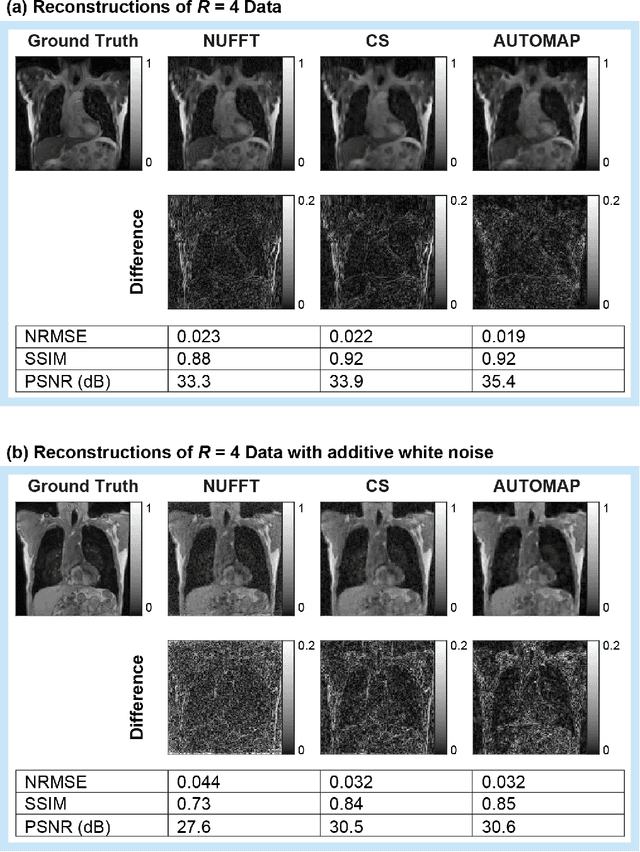
MRI-guidance techniques that dynamically adapt radiation beams to follow tumor motion in real-time will lead to more accurate cancer treatments and reduced collateral healthy tissue damage. The gold-standard for reconstruction of undersampled MR data is compressed sensing (CS) which is computationally slow and limits the rate that images can be available for real-time adaptation. Here, we demonstrate the use of automated transform by manifold approximation (AUTOMAP), a generalized framework that maps raw MR signal to the target image domain, to rapidly reconstruct images from undersampled radial k-space data. The AUTOMAP neural network was trained to reconstruct images from a golden-angle radial acquisition, a benchmark for motion-sensitive imaging, on lung cancer patient data and generic images from ImageNet. Model training was subsequently augmented with motion-encoded k-space data derived from videos in the YouTube-8M dataset to encourage motion robust reconstruction. We find that AUTOMAP-reconstructed radial k-space has equivalent accuracy to CS but with much shorter processing times after initial fine-tuning on retrospectively acquired lung cancer patient data. Validation of motion-trained models with a virtual dynamic lung tumor phantom showed that the generalized motion properties learned from YouTube lead to improved target tracking accuracy. Our work shows that AUTOMAP can achieve real-time, accurate reconstruction of radial data. These findings imply that neural-network-based reconstruction is potentially superior to existing approaches for real-time image guidance applications.