 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Self-supervised learning with rotation-invariant kernels
Jul 28, 2022
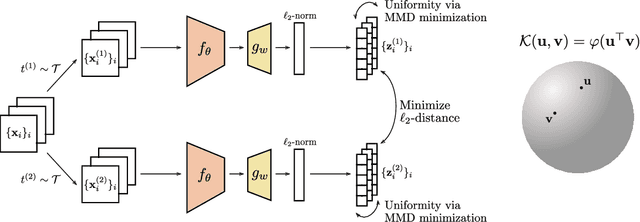
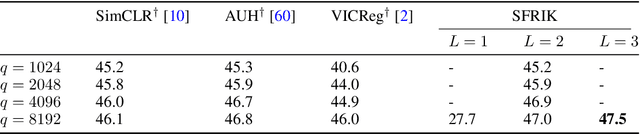
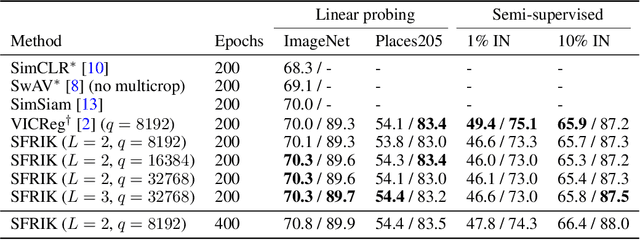

A major paradigm for learning image representations in a self-supervised manner is to learn a model that is invariant to some predefined image transformations (cropping, blurring, color jittering, etc.), while regularizing the embedding distribution to avoid learning a degenerate solution. Our first contribution is to propose a general kernel framework to design a generic regularization loss that promotes the embedding distribution to be close to the uniform distribution on the hypersphere, with respect to the maximum mean discrepancy pseudometric. Our framework uses rotation-invariant kernels defined on the hypersphere, also known as dot-product kernels. Our second contribution is to show that this flexible kernel approach encompasses several existing self-supervised learning methods, including uniformity-based and information-maximization methods. Finally, by exploring empirically several kernel choices, our experiments demonstrate that using a truncated rotation-invariant kernel provides competitive results compared to state-of-the-art methods, and we show practical situations where our method benefits from the kernel trick to reduce computational complexity.
Remote Sensing Cross-Modal Text-Image Retrieval Based on Global and Local Information
Apr 21, 2022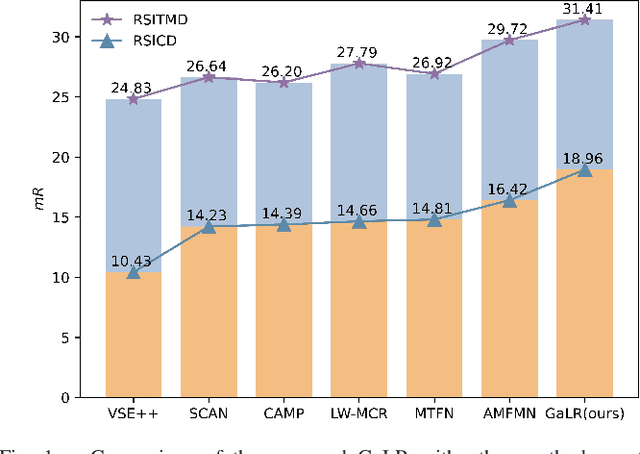
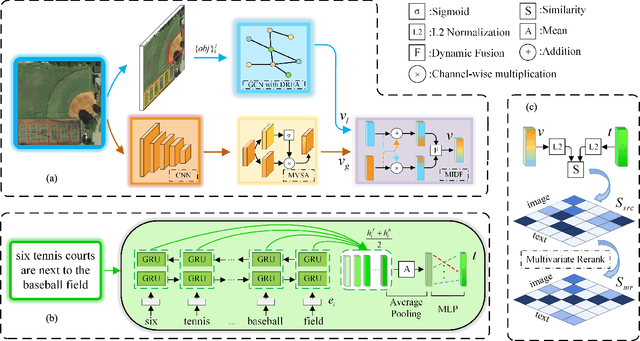
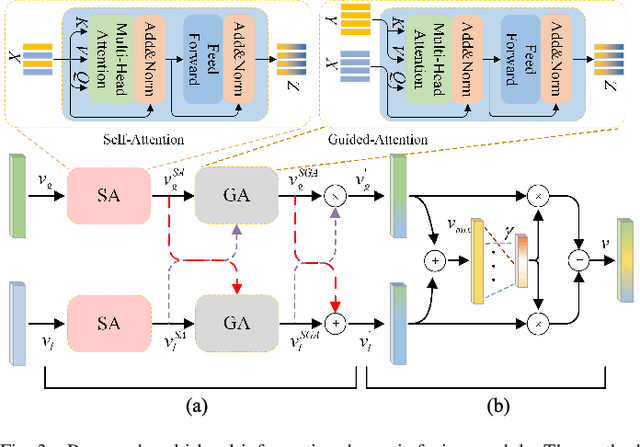
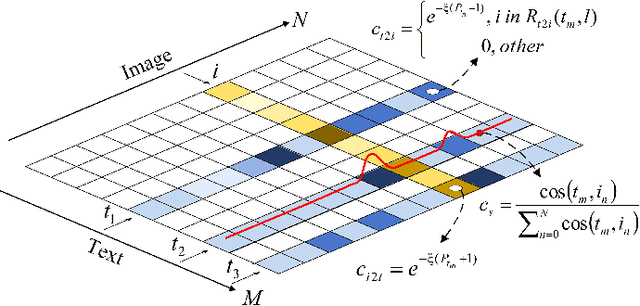
Cross-modal remote sensing text-image retrieval (RSCTIR) has recently become an urgent research hotspot due to its ability of enabling fast and flexible information extraction on remote sensing (RS) images. However, current RSCTIR methods mainly focus on global features of RS images, which leads to the neglect of local features that reflect target relationships and saliency. In this article, we first propose a novel RSCTIR framework based on global and local information (GaLR), and design a multi-level information dynamic fusion (MIDF) module to efficaciously integrate features of different levels. MIDF leverages local information to correct global information, utilizes global information to supplement local information, and uses the dynamic addition of the two to generate prominent visual representation. To alleviate the pressure of the redundant targets on the graph convolution network (GCN) and to improve the model s attention on salient instances during modeling local features, the de-noised representation matrix and the enhanced adjacency matrix (DREA) are devised to assist GCN in producing superior local representations. DREA not only filters out redundant features with high similarity, but also obtains more powerful local features by enhancing the features of prominent objects. Finally, to make full use of the information in the similarity matrix during inference, we come up with a plug-and-play multivariate rerank (MR) algorithm. The algorithm utilizes the k nearest neighbors of the retrieval results to perform a reverse search, and improves the performance by combining multiple components of bidirectional retrieval. Extensive experiments on public datasets strongly demonstrate the state-of-the-art performance of GaLR methods on the RSCTIR task. The code of GaLR method, MR algorithm, and corresponding files have been made available at https://github.com/xiaoyuan1996/GaLR .
Temporal Disentanglement of Representations for Improved Generalisation in Reinforcement Learning
Jul 12, 2022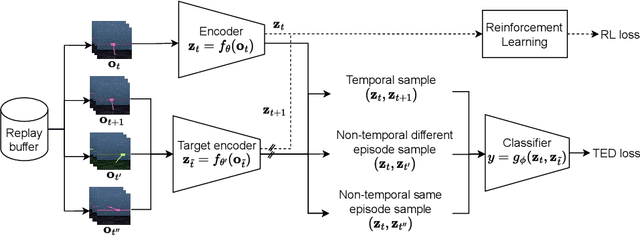

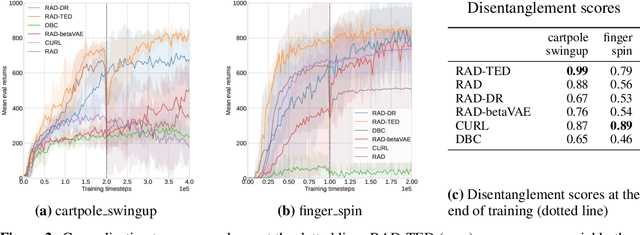
In real-world robotics applications, Reinforcement Learning (RL) agents are often unable to generalise to environment variations that were not observed during training. This issue is intensified for image-based RL where a change in one variable, such as the background colour, can change many pixels in the image, and in turn can change all values in the agent's internal representation of the image. To learn more robust representations, we introduce TEmporal Disentanglement (TED), a self-supervised auxiliary task that leads to disentangled representations using the sequential nature of RL observations. We find empirically that RL algorithms with TED as an auxiliary task adapt more quickly to changes in environment variables with continued training compared to state-of-the-art representation learning methods. Due to the disentangled structure of the representation, we also find that policies trained with TED generalise better to unseen values of variables irrelevant to the task (e.g. background colour) as well as unseen values of variables that affect the optimal policy (e.g. goal positions).
Data Augmentation For Medical MR Image Using Generative Adversarial Networks
Nov 29, 2021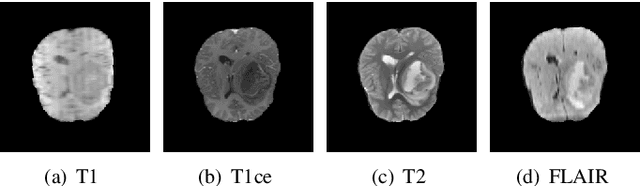
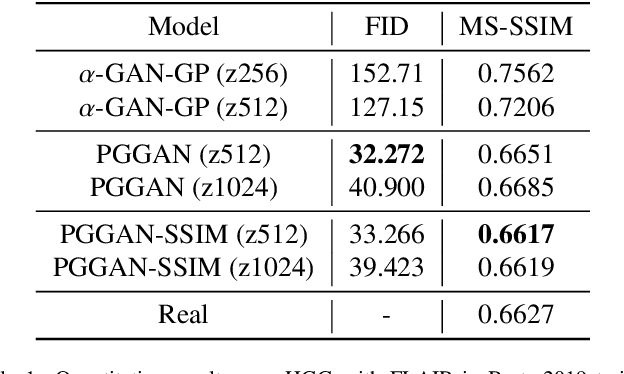
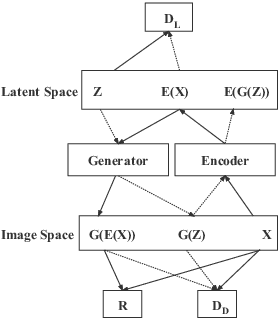
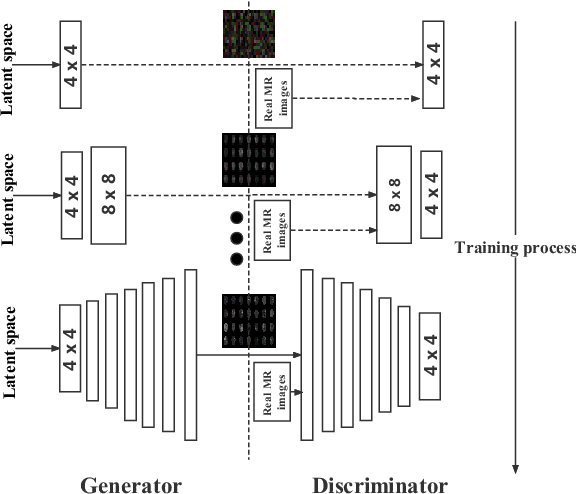
Computer-assisted diagnosis (CAD) based on deep learning has become a crucial diagnostic technology in the medical industry, effectively improving diagnosis accuracy. However, the scarcity of brain tumor Magnetic Resonance (MR) image datasets causes the low performance of deep learning algorithms. The distribution of transformed images generated by traditional data augmentation (DA) intrinsically resembles the original ones, resulting in a limited performance in terms of generalization ability. This work improves Progressive Growing of GANs with a structural similarity loss function (PGGAN-SSIM) to solve image blurriness problems and model collapse. We also explore other GAN-based data augmentation to demonstrate the effectiveness of the proposed model. Our results show that PGGAN-SSIM successfully generates 256x256 realistic brain tumor MR images which fill the real image distribution uncovered by the original dataset. Furthermore, PGGAN-SSIM exceeds other GAN-based methods, achieving promising performance improvement in Frechet Inception Distance (FID) and Multi-scale Structural Similarity (MS-SSIM).
CACTUSS: Common Anatomical CT-US Space for US examinations
Jul 18, 2022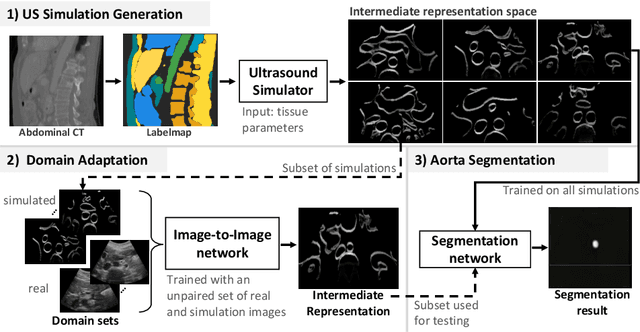
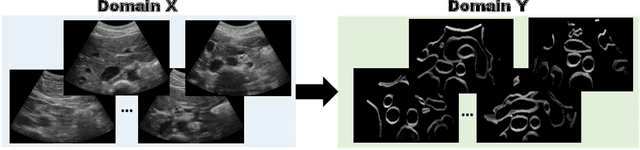
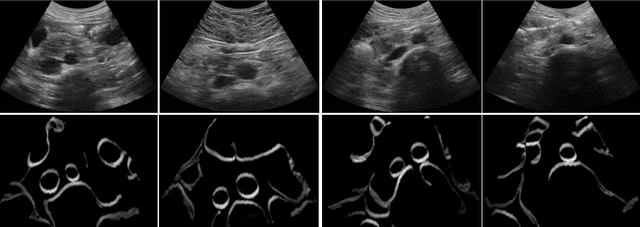
Abdominal aortic aneurysm (AAA) is a vascular disease in which a section of the aorta enlarges, weakening its walls and potentially rupturing the vessel. Abdominal ultrasound has been utilized for diagnostics, but due to its limited image quality and operator dependency, CT scans are usually required for monitoring and treatment planning. Recently, abdominal CT datasets have been successfully utilized to train deep neural networks for automatic aorta segmentation. Knowledge gathered from this solved task could therefore be leveraged to improve US segmentation for AAA diagnosis and monitoring. To this end, we propose CACTUSS: a common anatomical CT-US space, which acts as a virtual bridge between CT and US modalities to enable automatic AAA screening sonography. CACTUSS makes use of publicly available labelled data to learn to segment based on an intermediary representation that inherits properties from both US and CT. We train a segmentation network in this new representation and employ an additional image-to-image translation network which enables our model to perform on real B-mode images. Quantitative comparisons against fully supervised methods demonstrate the capabilities of CACTUSS in terms of Dice Score and diagnostic metrics, showing that our method also meets the clinical requirements for AAA scanning and diagnosis.
Flow 2.0 -a flexible, scalable, cross-platform post-processing software for realtime phase contrast sequences
Jul 26, 2022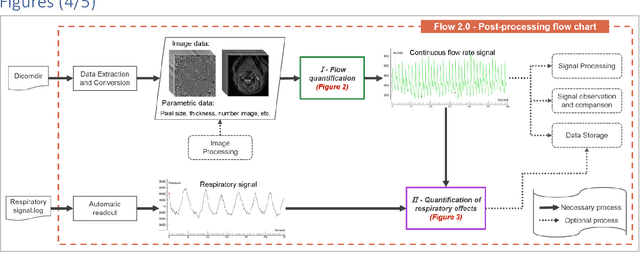
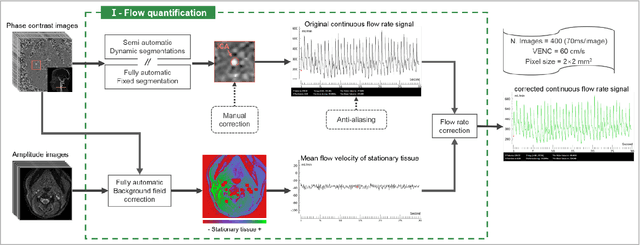
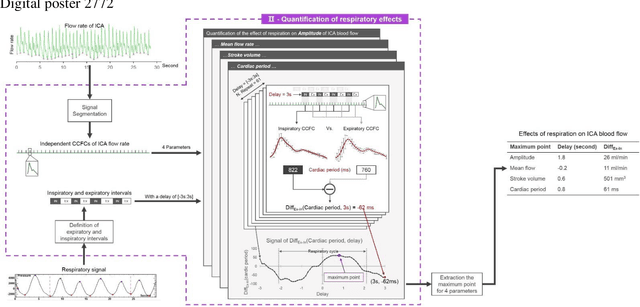
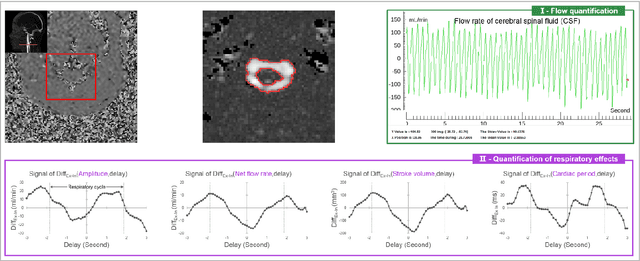
Flow 2.0 is an end-to-end easy-of-use software that allows us to quickly, robustly and accurately perform a batch process real-time phase contrast data and multivariate analysis of the effect of respiration on cerebral fluids circulation. Synopsis (99/100) Real-time phase contrast sequences (RT-PC) have potential value as a scientific and clinical tool in quantifying the effects of respiration on cerebral circulation. To simplify its complicated post-processing process, we developed Flow 2.0 software, which provides a complete post-processing workflow including converting DICOM data, image segmentation, image processing, data extraction, background field correction, antialiasing filter, signal processing and analysis and a novel time-domain method for quantifying the effect of respiration on the cerebral circulation. This end-to-end software allows us to quickly, robustly and accurately perform batch process RT-PC and multivariate analysis of the effects of respiration on cerebral circulation.
Low-complexity Rounded KLT Approximation for Image Compression
Nov 28, 2021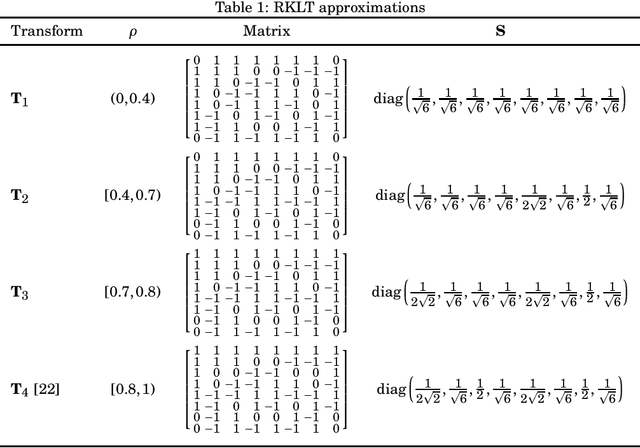
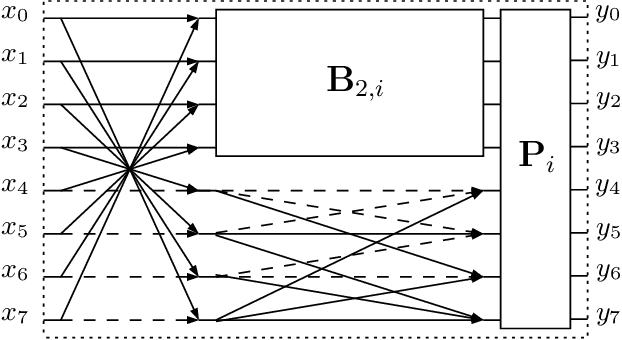

The Karhunen-Lo\`eve transform (KLT) is often used for data decorrelation and dimensionality reduction. Because its computation depends on the matrix of covariances of the input signal, the use of the KLT in real-time applications is severely constrained by the difficulty in developing fast algorithms to implement it. In this context, this paper proposes a new class of low-complexity transforms that are obtained through the application of the round function to the elements of the KLT matrix. The proposed transforms are evaluated considering figures of merit that measure the coding power and distance of the proposed approximations to the exact KLT and are also explored in image compression experiments. Fast algorithms are introduced for the proposed approximate transforms. It was shown that the proposed transforms perform well in image compression and require a low implementation cost.
* 10 pages, 7 figures, 3 tables
GLocal: Global Graph Reasoning and Local Structure Transfer for Person Image Generation
Dec 01, 2021
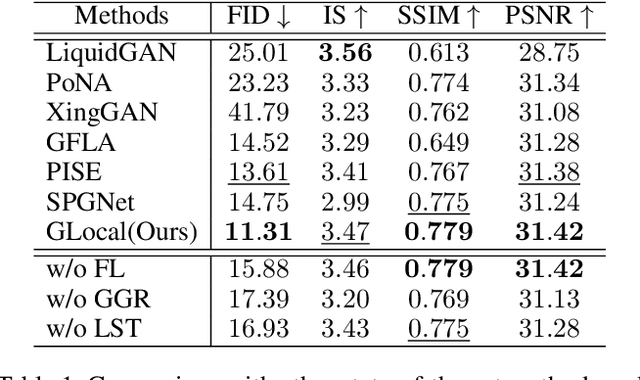
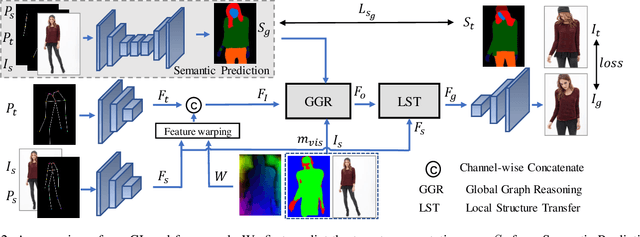
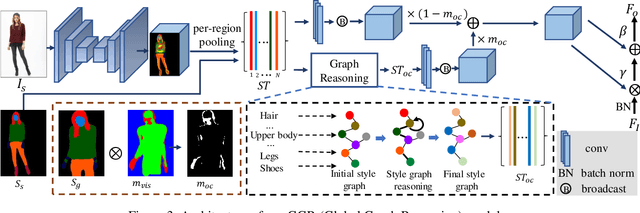
In this paper, we focus on person image generation, namely, generating person image under various conditions, e.g., corrupted texture or different pose. To address texture occlusion and large pose misalignment in this task, previous works just use the corresponding region's style to infer the occluded area and rely on point-wise alignment to reorganize the context texture information, lacking the ability to globally correlate the region-wise style codes and preserve the local structure of the source. To tackle these problems, we present a GLocal framework to improve the occlusion-aware texture estimation by globally reasoning the style inter-correlations among different semantic regions, which can also be employed to recover the corrupted images in texture inpainting. For local structural information preservation, we further extract the local structure of the source image and regain it in the generated image via local structure transfer. We benchmark our method to fully characterize its performance on DeepFashion dataset and present extensive ablation studies that highlight the novelty of our method.
D-Former: A U-shaped Dilated Transformer for 3D Medical Image Segmentation
Jan 03, 2022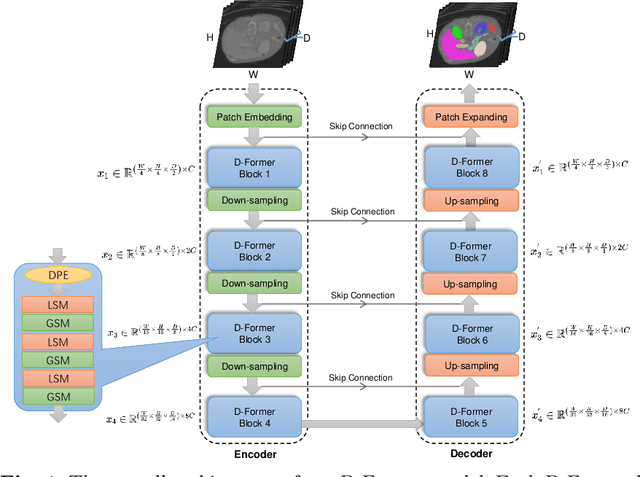
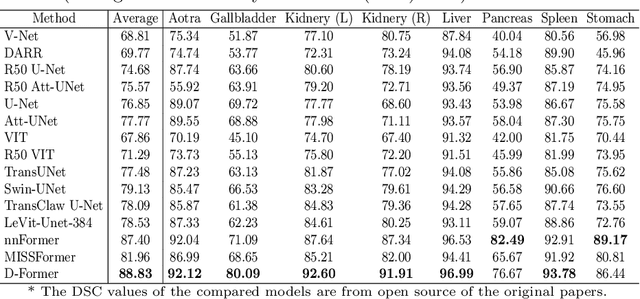
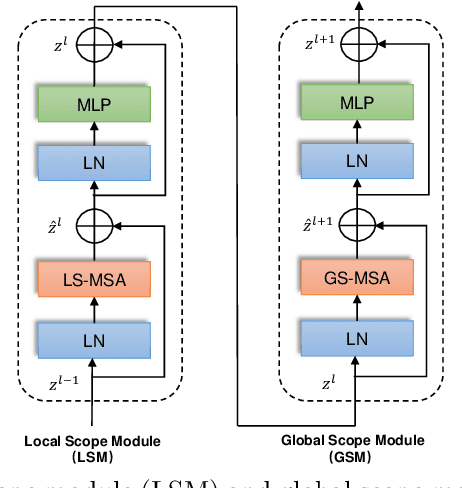
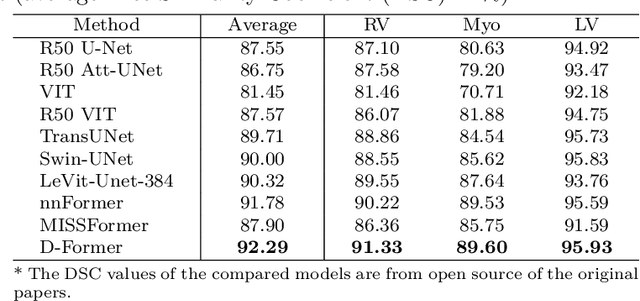
Computer-aided medical image segmentation has been applied widely in diagnosis and treatment to obtain clinically useful information of shapes and volumes of target organs and tissues. In the past several years, convolutional neural network (CNN) based methods (e.g., U-Net) have dominated this area, but still suffered from inadequate long-range information capturing. Hence, recent work presented computer vision Transformer variants for medical image segmentation tasks and obtained promising performances. Such Transformers model long-range dependency by computing pair-wise patch relations. However, they incur prohibitive computational costs, especially on 3D medical images (e.g., CT and MRI). In this paper, we propose a new method called Dilated Transformer, which conducts self-attention for pair-wise patch relations captured alternately in local and global scopes. Inspired by dilated convolution kernels, we conduct the global self-attention in a dilated manner, enlarging receptive fields without increasing the patches involved and thus reducing computational costs. Based on this design of Dilated Transformer, we construct a U-shaped encoder-decoder hierarchical architecture called D-Former for 3D medical image segmentation. Experiments on the Synapse and ACDC datasets show that our D-Former model, trained from scratch, outperforms various competitive CNN-based or Transformer-based segmentation models at a low computational cost without time-consuming per-training process.
Towards Sparsification of Graph Neural Networks
Sep 11, 2022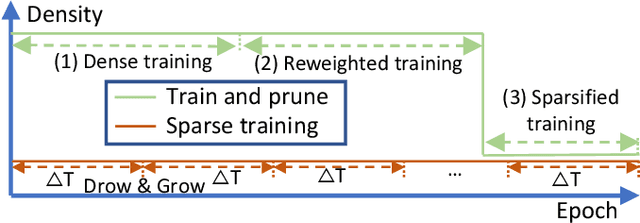
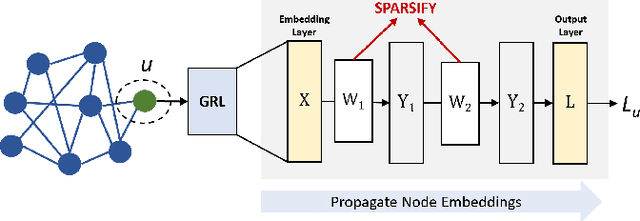
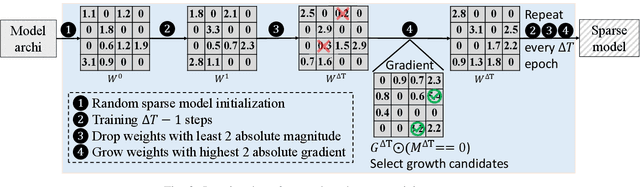

As real-world graphs expand in size, larger GNN models with billions of parameters are deployed. High parameter count in such models makes training and inference on graphs expensive and challenging. To reduce the computational and memory costs of GNNs, optimization methods such as pruning the redundant nodes and edges in input graphs have been commonly adopted. However, model compression, which directly targets the sparsification of model layers, has been mostly limited to traditional Deep Neural Networks (DNNs) used for tasks such as image classification and object detection. In this paper, we utilize two state-of-the-art model compression methods (1) train and prune and (2) sparse training for the sparsification of weight layers in GNNs. We evaluate and compare the efficiency of both methods in terms of accuracy, training sparsity, and training FLOPs on real-world graphs. Our experimental results show that on the ia-email, wiki-talk, and stackoverflow datasets for link prediction, sparse training with much lower training FLOPs achieves a comparable accuracy with the train and prune method. On the brain dataset for node classification, sparse training uses a lower number FLOPs (less than 1/7 FLOPs of train and prune method) and preserves a much better accuracy performance under extreme model sparsity.