 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Object Detection Using Sim2Real Domain Randomization for Robotic Applications
Aug 08, 2022
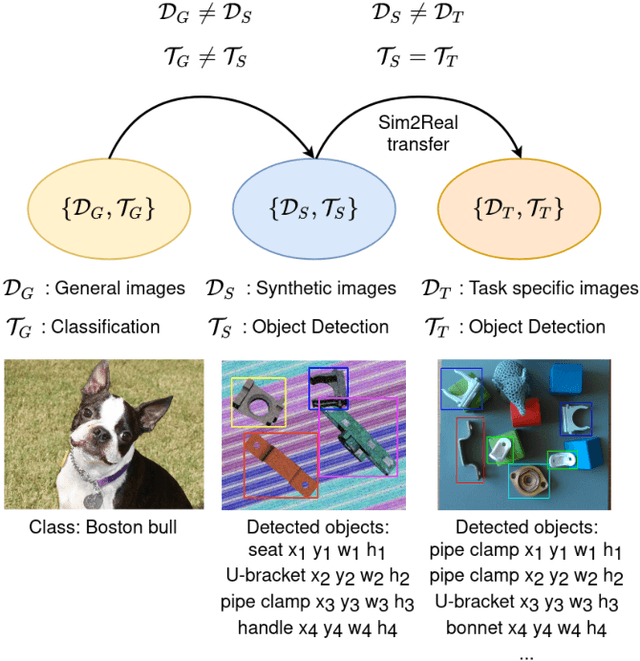
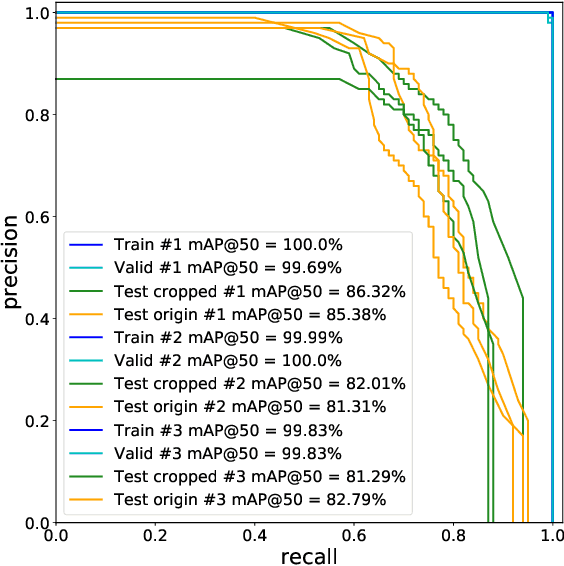
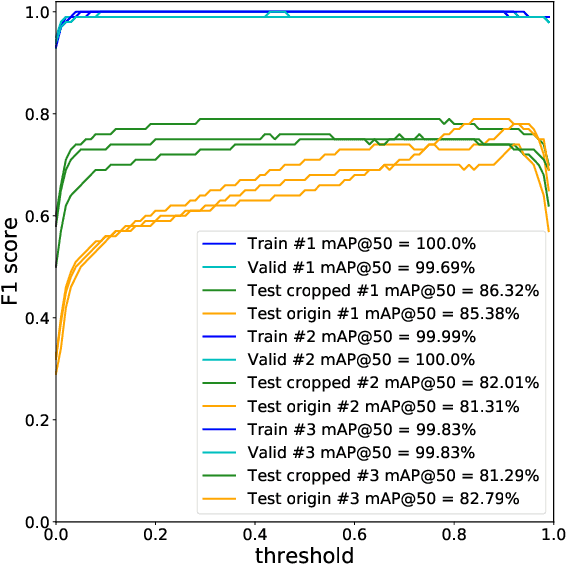
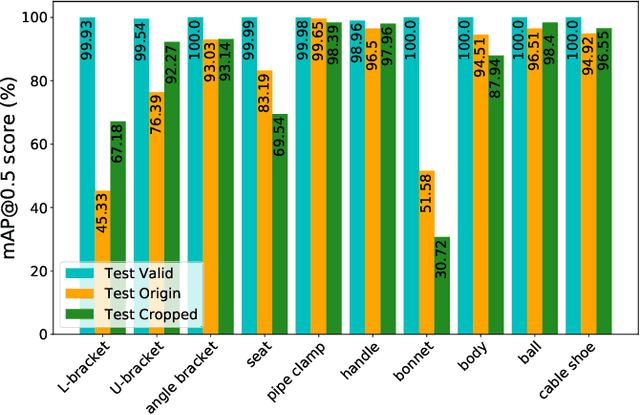
Robots working in unstructured environments must be capable of sensing and interpreting their surroundings. One of the main obstacles of deep learning based models in the field of robotics is the lack of domain-specific labeled data for different industrial applications. In this paper, we propose a sim2real transfer learning method based on domain randomization for object detection with which labeled synthetic datasets of arbitrary size and object types can be automatically generated. Subsequently, a state-of-the-art convolutional neural network, YOLOv4, is trained to detect the different types of industrial objects. With the proposed domain randomization method, we could shrink the reality gap to a satisfactory level, achieving 86.32% and 97.38% mAP50 scores respectively in the case of zero-shot and one-shot transfers, on our manually annotated dataset containing 190 real images. On a GeForce RTX 2080 Ti GPU, the data generation process takes less than 0.5s per image and the training lasts around 12h which makes it convenient for industrial use. Our solution matches industrial needs as it can reliably differentiate similar classes of objects by using only 1 real image for training. To our best knowledge, this is the only work thus far satisfying these constraints.
Spatial-context-aware deep neural network for multi-class image classification
Nov 24, 2021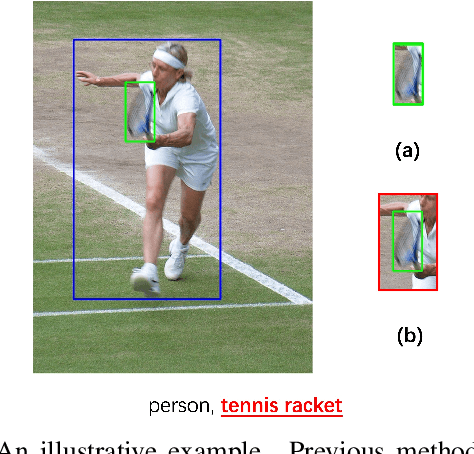
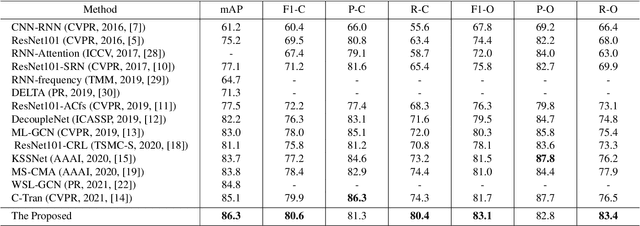
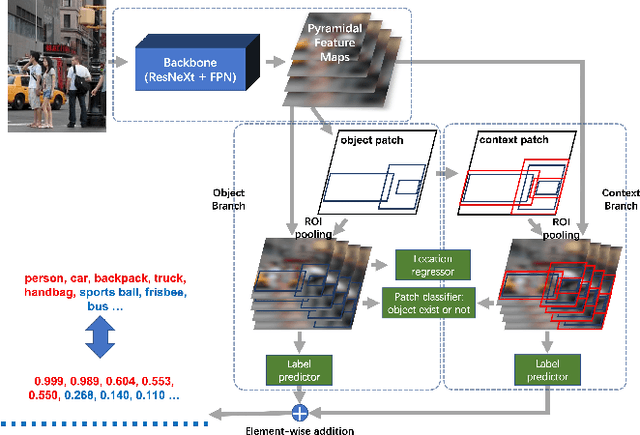

Multi-label image classification is a fundamental but challenging task in computer vision. Over the past few decades, solutions exploring relationships between semantic labels have made great progress. However, the underlying spatial-contextual information of labels is under-exploited. To tackle this problem, a spatial-context-aware deep neural network is proposed to predict labels taking into account both semantic and spatial information. This proposed framework is evaluated on Microsoft COCO and PASCAL VOC, two widely used benchmark datasets for image multi-labelling. The results show that the proposed approach is superior to the state-of-the-art solutions on dealing with the multi-label image classification problem.
Content-aware Scalable Deep Compressed Sensing
Jul 19, 2022To more efficiently address image compressed sensing (CS) problems, we present a novel content-aware scalable network dubbed CASNet which collectively achieves adaptive sampling rate allocation, fine granular scalability and high-quality reconstruction. We first adopt a data-driven saliency detector to evaluate the importances of different image regions and propose a saliency-based block ratio aggregation (BRA) strategy for sampling rate allocation. A unified learnable generating matrix is then developed to produce sampling matrix of any CS ratio with an ordered structure. Being equipped with the optimization-inspired recovery subnet guided by saliency information and a multi-block training scheme preventing blocking artifacts, CASNet jointly reconstructs the image blocks sampled at various sampling rates with one single model. To accelerate training convergence and improve network robustness, we propose an SVD-based initialization scheme and a random transformation enhancement (RTE) strategy, which are extensible without introducing extra parameters. All the CASNet components can be combined and learned end-to-end. We further provide a four-stage implementation for evaluation and practical deployments. Experiments demonstrate that CASNet outperforms other CS networks by a large margin, validating the collaboration and mutual supports among its components and strategies. Codes are available at https://github.com/Guaishou74851/CASNet.
POP: Mining POtential Performance of new fashion products via webly cross-modal query expansion
Jul 22, 2022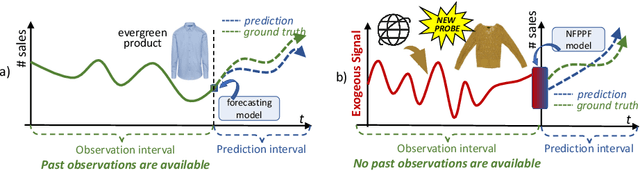
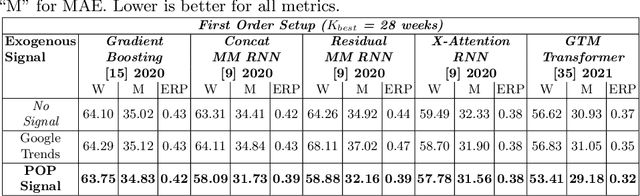

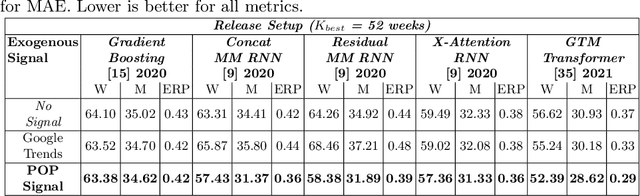
We propose a data-centric pipeline able to generate exogenous observation data for the New Fashion Product Performance Forecasting (NFPPF) problem, i.e., predicting the performance of a brand-new clothing probe with no available past observations. Our pipeline manufactures the missing past starting from a single, available image of the clothing probe. It starts by expanding textual tags associated with the image, querying related fashionable or unfashionable images uploaded on the web at a specific time in the past. A binary classifier is robustly trained on these web images by confident learning, to learn what was fashionable in the past and how much the probe image conforms to this notion of fashionability. This compliance produces the POtential Performance (POP) time series, indicating how performing the probe could have been if it were available earlier. POP proves to be highly predictive for the probe's future performance, ameliorating the sales forecasts of all state-of-the-art models on the recent VISUELLE fast-fashion dataset. We also show that POP reflects the ground-truth popularity of new styles (ensembles of clothing items) on the Fashion Forward benchmark, demonstrating that our webly-learned signal is a truthful expression of popularity, accessible by everyone and generalizable to any time of analysis. Forecasting code, data and the POP time series are available at: https://github.com/HumaticsLAB/POP-Mining-POtential-Performance
CLIP-NeRF: Text-and-Image Driven Manipulation of Neural Radiance Fields
Dec 09, 2021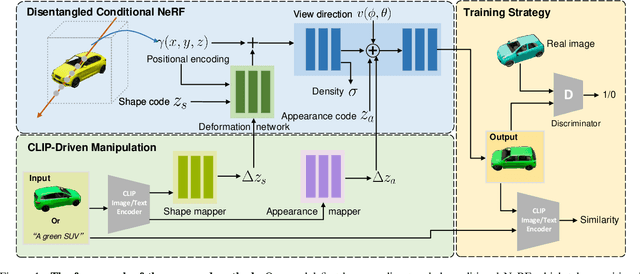
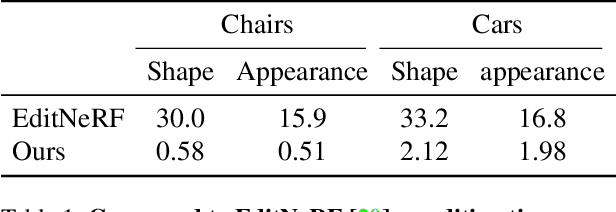
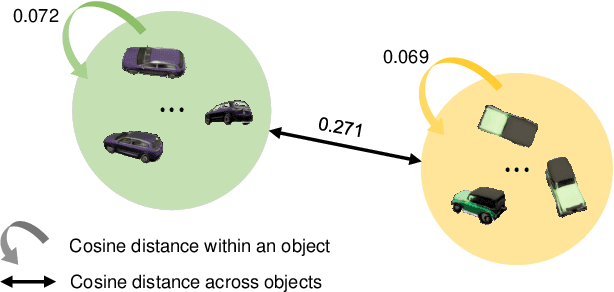
We present CLIP-NeRF, a multi-modal 3D object manipulation method for neural radiance fields (NeRF). By leveraging the joint language-image embedding space of the recent Contrastive Language-Image Pre-Training (CLIP) model, we propose a unified framework that allows manipulating NeRF in a user-friendly way, using either a short text prompt or an exemplar image. Specifically, to combine the novel view synthesis capability of NeRF and the controllable manipulation ability of latent representations from generative models, we introduce a disentangled conditional NeRF architecture that allows individual control over both shape and appearance. This is achieved by performing the shape conditioning via applying a learned deformation field to the positional encoding and deferring color conditioning to the volumetric rendering stage. To bridge this disentangled latent representation to the CLIP embedding, we design two code mappers that take a CLIP embedding as input and update the latent codes to reflect the targeted editing. The mappers are trained with a CLIP-based matching loss to ensure the manipulation accuracy. Furthermore, we propose an inverse optimization method that accurately projects an input image to the latent codes for manipulation to enable editing on real images. We evaluate our approach by extensive experiments on a variety of text prompts and exemplar images and also provide an intuitive interface for interactive editing. Our implementation is available at https://cassiepython.github.io/clipnerf/
Causality-inspired Single-source Domain Generalization for Medical Image Segmentation
Dec 06, 2021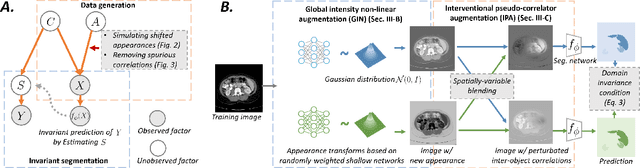
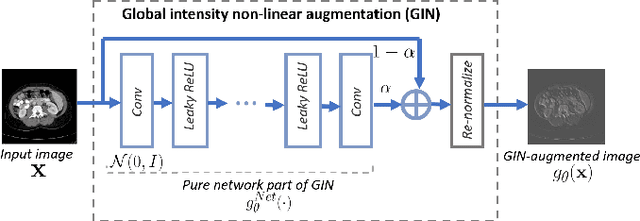
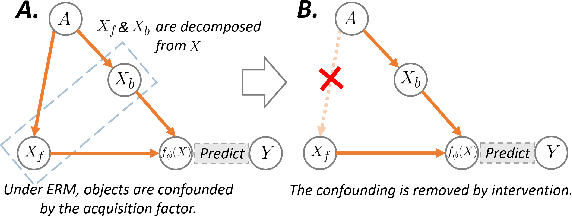
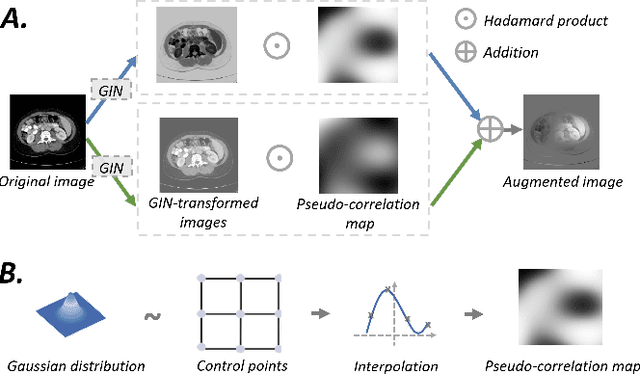
Deep learning models usually suffer from domain shift issues, where models trained on one source domain do not generalize well to other unseen domains. In this work, we investigate the single-source domain generalization problem: training a deep network that is robust to unseen domains, under the condition that training data is only available from one source domain, which is common in medical imaging applications. We tackle this problem in the context of cross-domain medical image segmentation. Under this scenario, domain shifts are mainly caused by different acquisition processes. We propose a simple causality-inspired data augmentation approach to expose a segmentation model to synthesized domain-shifted training examples. Specifically, 1) to make the deep model robust to discrepancies in image intensities and textures, we employ a family of randomly-weighted shallow networks. They augment training images using diverse appearance transformations. 2) Further we show that spurious correlations among objects in an image are detrimental to domain robustness. These correlations might be taken by the network as domain-specific clues for making predictions, and they may break on unseen domains. We remove these spurious correlations via causal intervention. This is achieved by resampling the appearances of potentially correlated objects independently. The proposed approach is validated on three cross-domain segmentation tasks: cross-modality (CT-MRI) abdominal image segmentation, cross-sequence (bSSFP-LGE) cardiac MRI segmentation, and cross-center prostate MRI segmentation. The proposed approach yields consistent performance gains compared with competitive methods when tested on unseen domains.
Generator Knows What Discriminator Should Learn in Unconditional GANs
Jul 27, 2022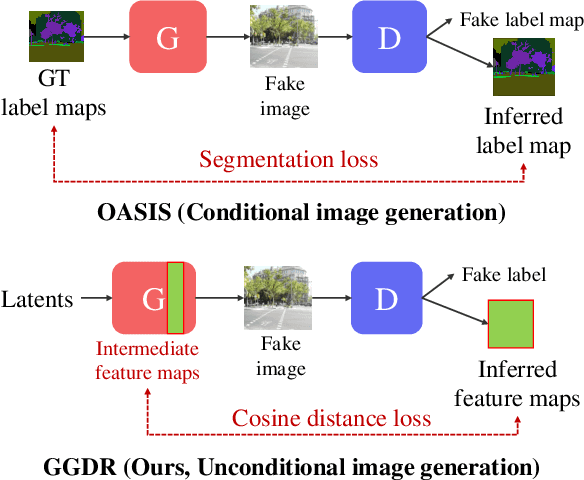
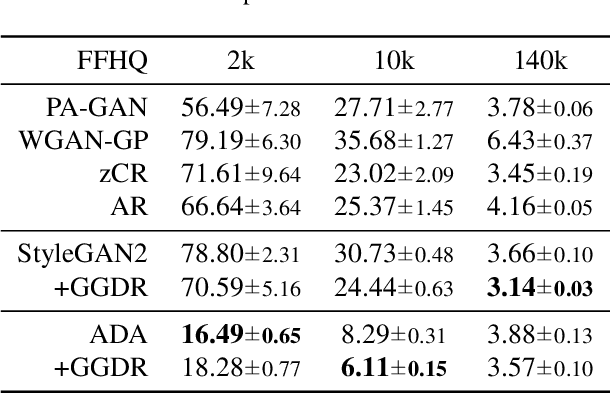
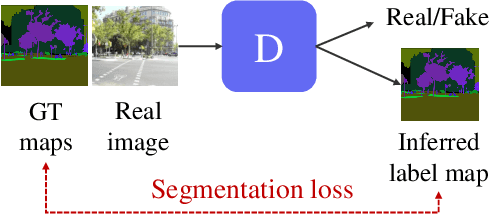
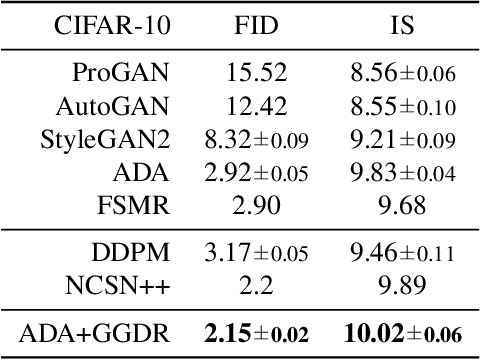
Recent methods for conditional image generation benefit from dense supervision such as segmentation label maps to achieve high-fidelity. However, it is rarely explored to employ dense supervision for unconditional image generation. Here we explore the efficacy of dense supervision in unconditional generation and find generator feature maps can be an alternative of cost-expensive semantic label maps. From our empirical evidences, we propose a new generator-guided discriminator regularization(GGDR) in which the generator feature maps supervise the discriminator to have rich semantic representations in unconditional generation. In specific, we employ an U-Net architecture for discriminator, which is trained to predict the generator feature maps given fake images as inputs. Extensive experiments on mulitple datasets show that our GGDR consistently improves the performance of baseline methods in terms of quantitative and qualitative aspects. Code is available at https://github.com/naver-ai/GGDR
Incremental Learning in Semantic Segmentation from Image Labels
Dec 03, 2021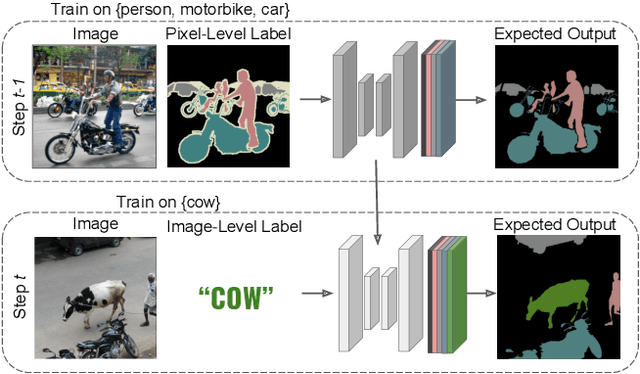
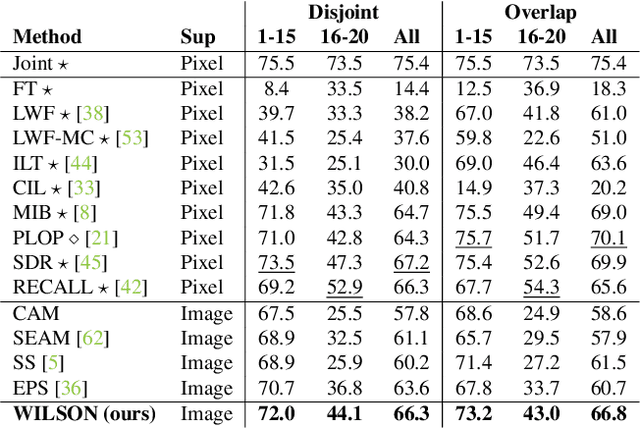
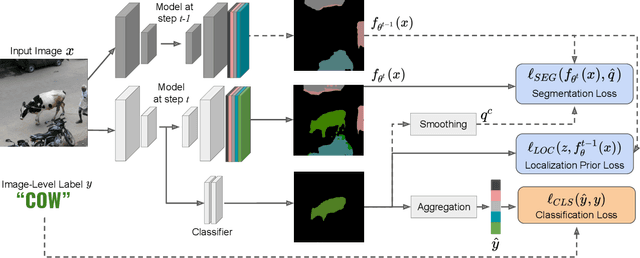
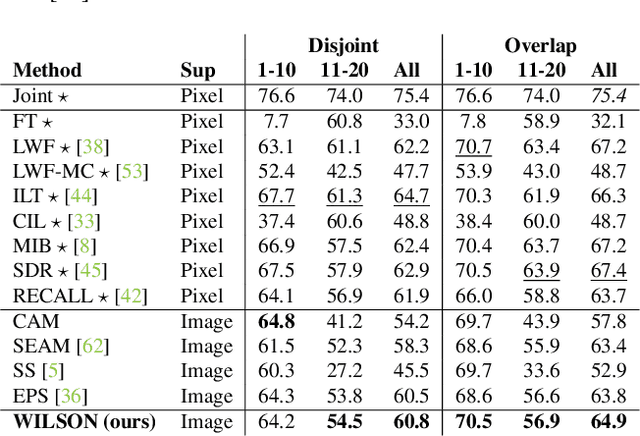
Although existing semantic segmentation approaches achieve impressive results, they still struggle to update their models incrementally as new categories are uncovered. Furthermore, pixel-by-pixel annotations are expensive and time-consuming. This paper proposes a novel framework for Weakly Incremental Learning for Semantic Segmentation, that aims at learning to segment new classes from cheap and largely available image-level labels. As opposed to existing approaches, that need to generate pseudo-labels offline, we use an auxiliary classifier, trained with image-level labels and regularized by the segmentation model, to obtain pseudo-supervision online and update the model incrementally. We cope with the inherent noise in the process by using soft-labels generated by the auxiliary classifier. We demonstrate the effectiveness of our approach on the Pascal VOC and COCO datasets, outperforming offline weakly-supervised methods and obtaining results comparable with incremental learning methods with full supervision.
Deep Autoencoder Model Construction Based on Pytorch
Aug 17, 2022
This paper proposes a deep autoencoder model based on Pytorch. This algorithm introduces the idea of Pytorch into the auto-encoder, and randomly clears the input weights connected to the hidden layer neurons with a certain probability, so as to achieve the effect of sparse network, which is similar to the starting point of the sparse auto-encoder. The new algorithm effectively solves the problem of possible overfitting of the model and improves the accuracy of image classification. Finally, the experiment is carried out, and the experimental results are compared with ELM, RELM, AE, SAE, DAE.
Deep Image Prior using Stein's Unbiased Risk Estimator: SURE-DIP
Nov 21, 2021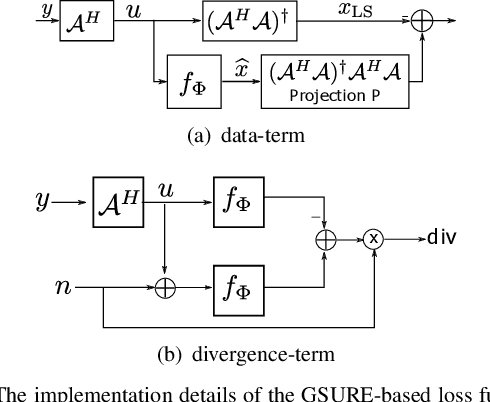
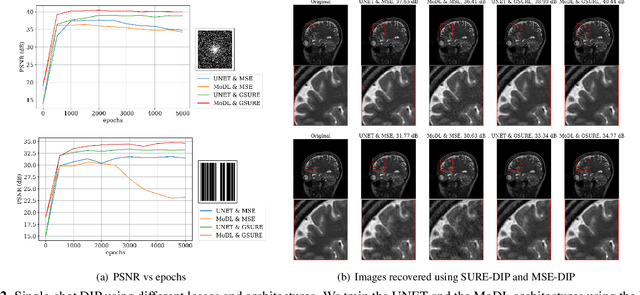
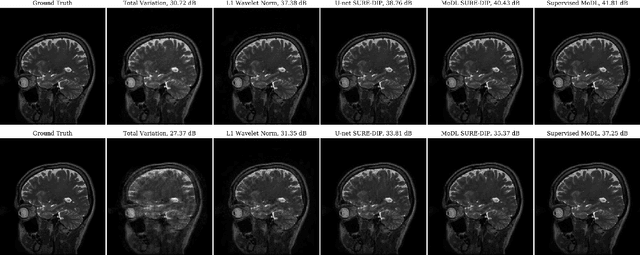
Deep learning algorithms that rely on extensive training data are revolutionizing image recovery from ill-posed measurements. Training data is scarce in many imaging applications, including ultra-high-resolution imaging. The deep image prior (DIP) algorithm was introduced for single-shot image recovery, completely eliminating the need for training data. A challenge with this scheme is the need for early stopping to minimize the overfitting of the CNN parameters to the noise in the measurements. We introduce a generalized Stein's unbiased risk estimate (GSURE) loss metric to minimize the overfitting. Our experiments show that the SURE-DIP approach minimizes the overfitting issues, thus offering significantly improved performance over classical DIP schemes. We also use the SURE-DIP approach with model-based unrolling architectures, which offers improved performance over direct inversion schemes.