 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Data Augmentation by Selecting Mixed Classes Considering Distance Between Classes
Sep 12, 2022
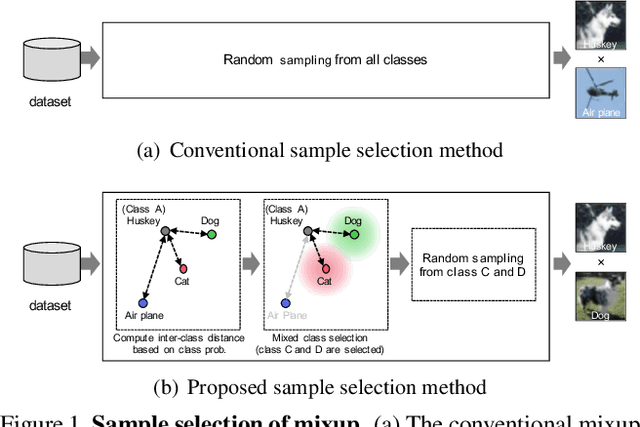
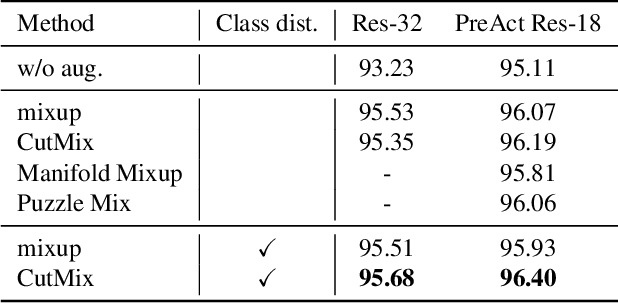
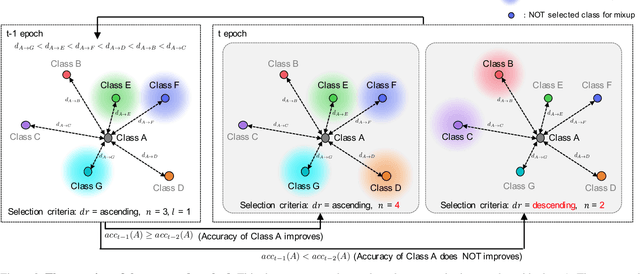
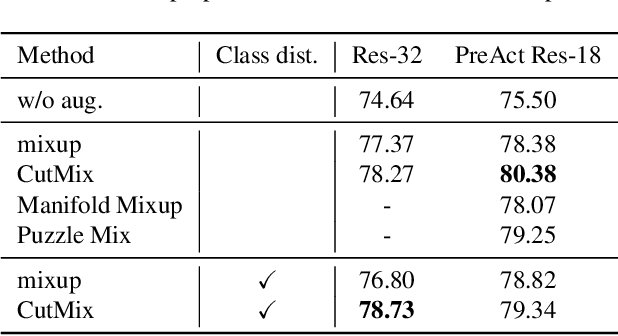
Data augmentation is an essential technique for improving recognition accuracy in object recognition using deep learning. Methods that generate mixed data from multiple data sets, such as mixup, can acquire new diversity that is not included in the training data, and thus contribute significantly to accuracy improvement. However, since the data selected for mixing are randomly sampled throughout the training process, there are cases where appropriate classes or data are not selected. In this study, we propose a data augmentation method that calculates the distance between classes based on class probabilities and can select data from suitable classes to be mixed in the training process. Mixture data is dynamically adjusted according to the training trend of each class to facilitate training. The proposed method is applied in combination with conventional methods for generating mixed data. Evaluation experiments show that the proposed method improves recognition performance on general and long-tailed image recognition datasets.
Airway Tree Modeling Using Dual-channel 3D UNet 3+ with Vesselness Prior
Aug 30, 2022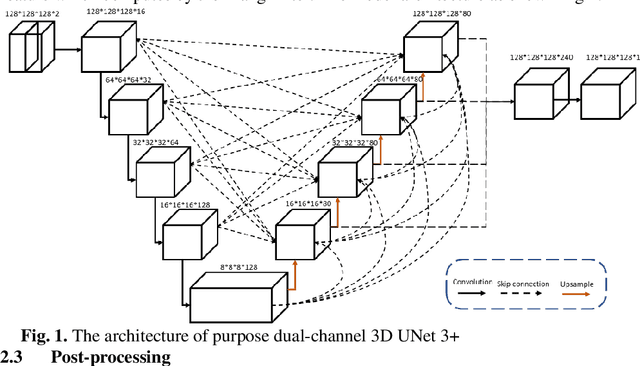
The lung airway tree modeling is essential to work for the diagnosis of pulmonary diseases, especially for X-Ray computed tomography (CT). The airway tree modeling on CT images can provide the experts with 3-dimension measurements like wall thickness, etc. This information can tremendously aid the diagnosis of pulmonary diseases like chronic obstructive pulmonary disease [1-4]. Many scholars have attempted various ways to model the lung airway tree, which can be split into two major categories based on its nature. Namely, the model-based approach and the deep learning approach. The performance of a typical model-based approach usually depends on the manual tuning of the model parameter, which can be its advantages and disadvantages. The advantage is its don't require a large amount of training data which can be beneficial for a small dataset like medical imaging. On the other hand, the performance of model-based may be a misconcep-tion [5,6]. In recent years, deep learning has achieved good results in the field of medical image processing, and many scholars have used UNet-based methods in medical image segmentation [7-11]. Among all the variation of UNet, the UNet 3+ [11] have relatively good result compare to the rest of the variation of UNet. Therefor to further improve the accuracy of lung airway tree modeling, this study combines the Frangi filter [5] with UNet 3+ [11] to develop a dual-channel 3D UNet 3+. The Frangi filter is used to extracting vessel-like feature. The vessel-like feature then used as input to guide the dual-channel UNet 3+ training and testing procedures.
Image Inpainting using Partial Convolution
Aug 19, 2021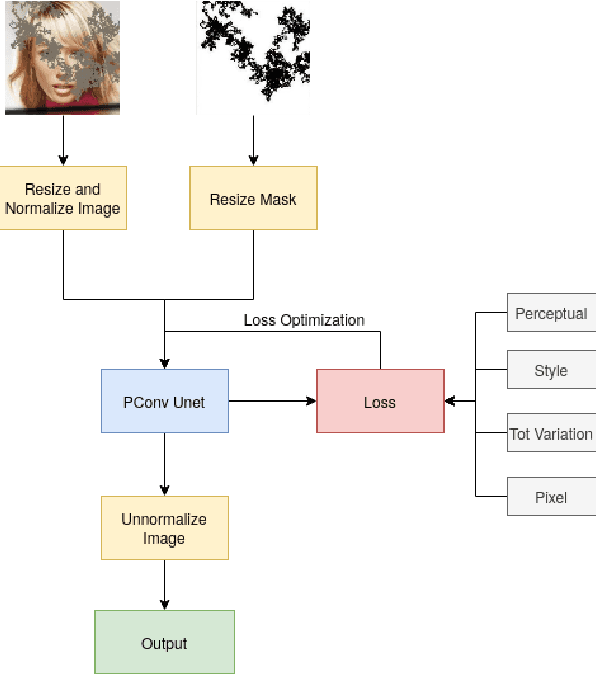



Image Inpainting is one of the very popular tasks in the field of image processing with broad applications in computer vision. In various practical applications, images are often deteriorated by noise due to the presence of corrupted, lost, or undesirable information. There have been various restoration techniques used in the past with both classical and deep learning approaches for handling such issues. Some traditional methods include image restoration by filling gap pixels using the nearby known pixels or using the moving average over the same. The aim of this paper is to perform image inpainting using robust deep learning methods that use partial convolution layers.
DRL-ISP: Multi-Objective Camera ISP with Deep Reinforcement Learning
Jul 07, 2022
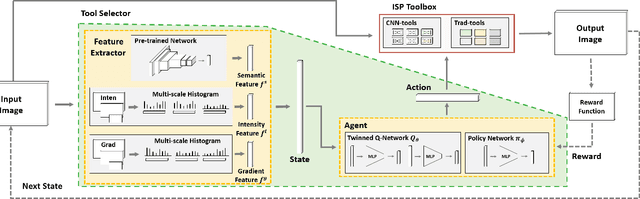

In this paper, we propose a multi-objective camera ISP framework that utilizes Deep Reinforcement Learning (DRL) and camera ISP toolbox that consist of network-based and conventional ISP tools. The proposed DRL-based camera ISP framework iteratively selects a proper tool from the toolbox and applies it to the image to maximize a given vision task-specific reward function. For this purpose, we implement total 51 ISP tools that include exposure correction, color-and-tone correction, white balance, sharpening, denoising, and the others. We also propose an efficient DRL network architecture that can extract the various aspects of an image and make a rigid mapping relationship between images and a large number of actions. Our proposed DRL-based ISP framework effectively improves the image quality according to each vision task such as RAW-to-RGB image restoration, 2D object detection, and monocular depth estimation.
M2-Net: Multi-stages Specular Highlight Detection and Removal in Multi-scenes
Jul 20, 2022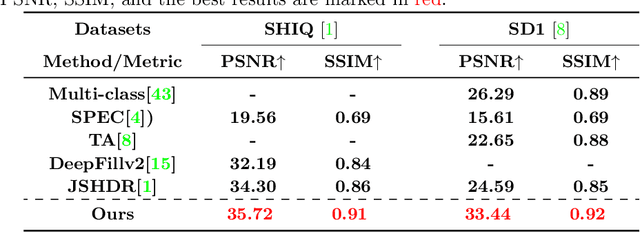
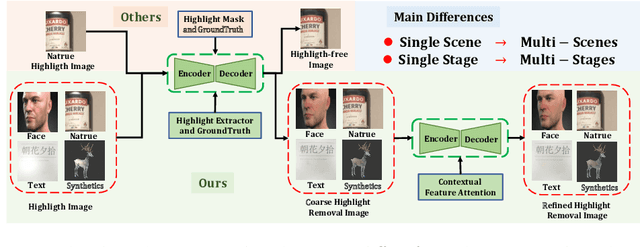
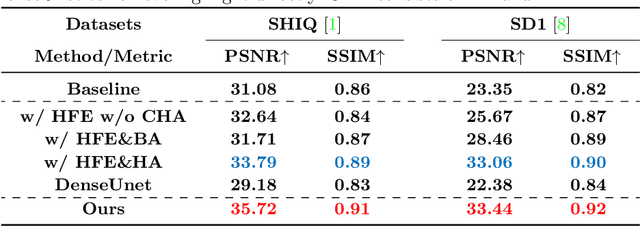
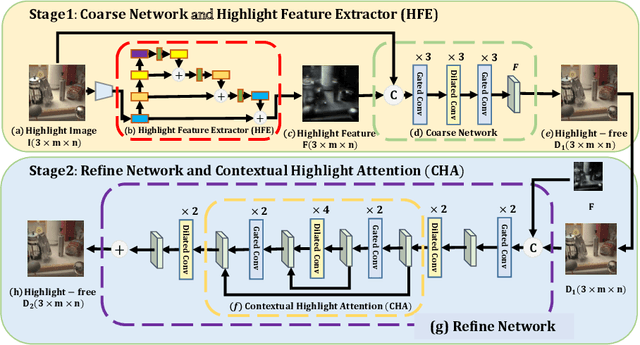
In this paper, we propose a novel uniformity framework for highlight detection and removal in multi-scenes, including synthetic images, face images, natural images, and text images. The framework consists of three main components, highlight feature extractor module, highlight coarse removal module, and highlight refine removal module. Firstly, the highlight feature extractor module can directly separate the highlight feature and non-highlight feature from the original highlight image. Then highlight removal image is obtained using a coarse highlight removal network. To further improve the highlight removal effect, the refined highlight removal image is finally obtained using refine highlight removal module based on contextual highlight attention mechanisms. Extensive experimental results in multiple scenes indicate that the proposed framework can obtain excellent visual effects of highlight removal and achieve state-of-the-art results in several quantitative evaluation metrics. Our algorithm is applied for the first time in video highlight removal with promising results.
SwinIR: Image Restoration Using Swin Transformer
Aug 23, 2021
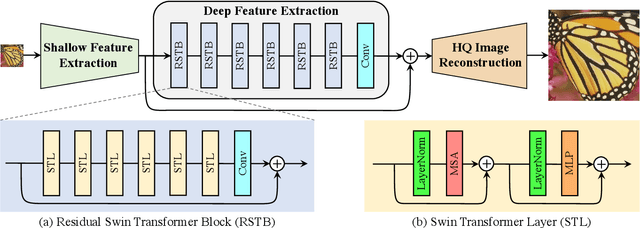
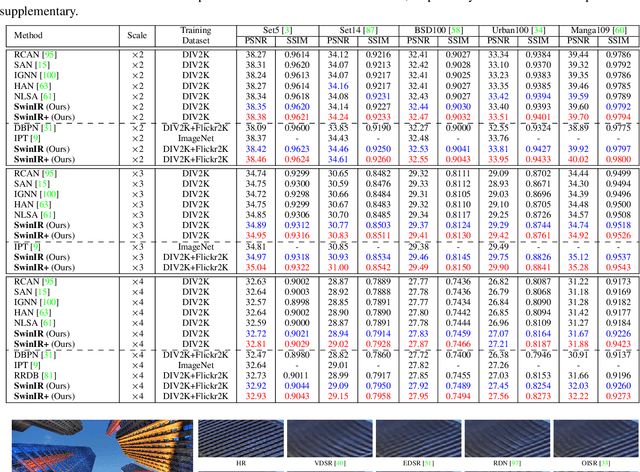
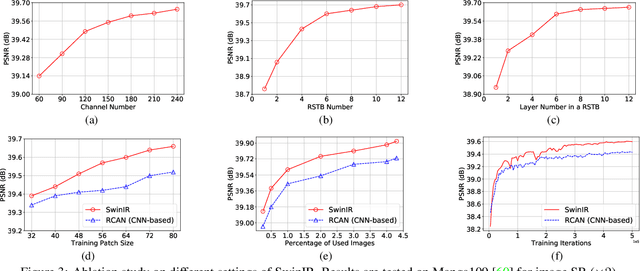
Image restoration is a long-standing low-level vision problem that aims to restore high-quality images from low-quality images (e.g., downscaled, noisy and compressed images). While state-of-the-art image restoration methods are based on convolutional neural networks, few attempts have been made with Transformers which show impressive performance on high-level vision tasks. In this paper, we propose a strong baseline model SwinIR for image restoration based on the Swin Transformer. SwinIR consists of three parts: shallow feature extraction, deep feature extraction and high-quality image reconstruction. In particular, the deep feature extraction module is composed of several residual Swin Transformer blocks (RSTB), each of which has several Swin Transformer layers together with a residual connection. We conduct experiments on three representative tasks: image super-resolution (including classical, lightweight and real-world image super-resolution), image denoising (including grayscale and color image denoising) and JPEG compression artifact reduction. Experimental results demonstrate that SwinIR outperforms state-of-the-art methods on different tasks by $\textbf{up to 0.14$\sim$0.45dB}$, while the total number of parameters can be reduced by $\textbf{up to 67%}$.
Learned Lossless JPEG Transcoding via Joint Lossy and Residual Compression
Aug 24, 2022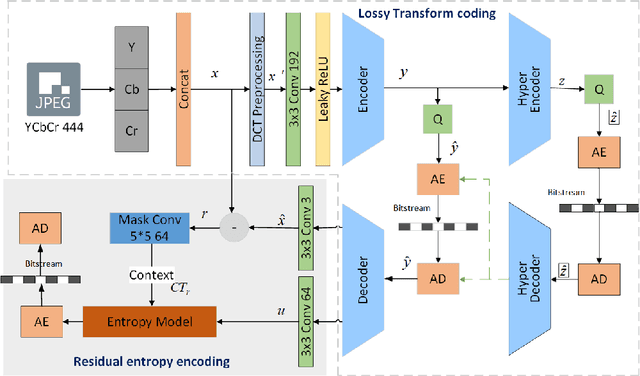
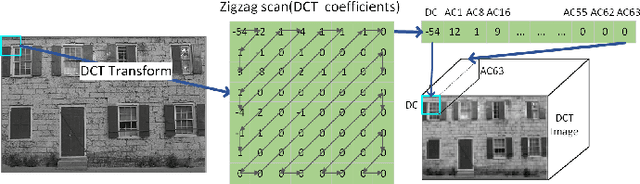
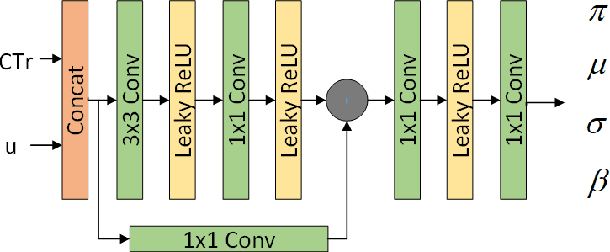
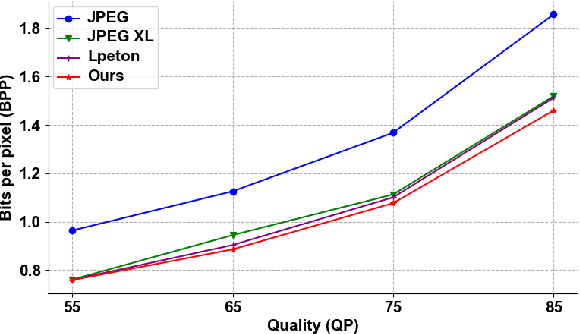
As a commonly-used image compression format, JPEG has been broadly applied in the transmission and storage of images. To further reduce the compression cost while maintaining the quality of JPEG images, lossless transcoding technology has been proposed to recompress the compressed JPEG image in the DCT domain. Previous works, on the other hand, typically reduce the redundancy of DCT coefficients and optimize the probability prediction of entropy coding in a hand-crafted manner that lacks generalization ability and flexibility. To tackle the above challenge, we propose the learned lossless JPEG transcoding framework via Joint Lossy and Residual Compression. Instead of directly optimizing the entropy estimation, we focus on the redundancy that exists in the DCT coefficients. To the best of our knowledge, we are the first to utilize the learned end-to-end lossy transform coding to reduce the redundancy of DCT coefficients in a compact representational domain. We also introduce residual compression for lossless transcoding, which adaptively learns the distribution of residual DCT coefficients before compressing them using context-based entropy coding. Our proposed transcoding architecture shows significant superiority in the compression of JPEG images thanks to the collaboration of learned lossy transform coding and residual entropy coding. Extensive experiments on multiple datasets have demonstrated that our proposed framework can achieve about 21.49% bits saving in average based on JPEG compression, which outperforms the typical lossless transcoding framework JPEG-XL by 3.51%.
A Novel Explainable Out-of-Distribution Detection Approach for Spiking Neural Networks
Sep 30, 2022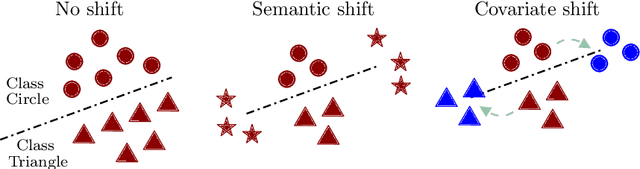

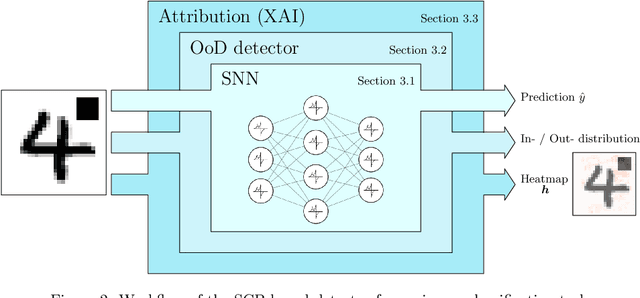
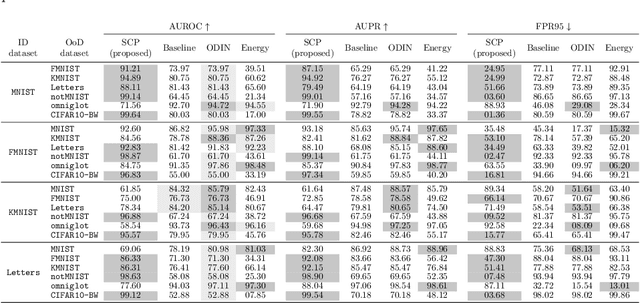
Research around Spiking Neural Networks has ignited during the last years due to their advantages when compared to traditional neural networks, including their efficient processing and inherent ability to model complex temporal dynamics. Despite these differences, Spiking Neural Networks face similar issues than other neural computation counterparts when deployed in real-world settings. This work addresses one of the practical circumstances that can hinder the trustworthiness of this family of models: the possibility of querying a trained model with samples far from the distribution of its training data (also referred to as Out-of-Distribution or OoD data). Specifically, this work presents a novel OoD detector that can identify whether test examples input to a Spiking Neural Network belong to the distribution of the data over which it was trained. For this purpose, we characterize the internal activations of the hidden layers of the network in the form of spike count patterns, which lay a basis for determining when the activations induced by a test instance is atypical. Furthermore, a local explanation method is devised to produce attribution maps revealing which parts of the input instance push most towards the detection of an example as an OoD sample. Experimental results are performed over several image classification datasets to compare the proposed detector to other OoD detection schemes from the literature. As the obtained results clearly show, the proposed detector performs competitively against such alternative schemes, and produces relevance attribution maps that conform to expectations for synthetically created OoD instances.
SinIR: Efficient General Image Manipulation with Single Image Reconstruction
Jun 14, 2021

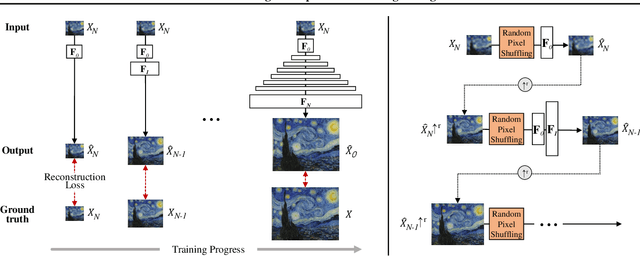
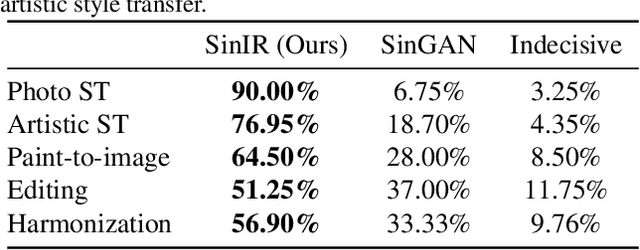
We propose SinIR, an efficient reconstruction-based framework trained on a single natural image for general image manipulation, including super-resolution, editing, harmonization, paint-to-image, photo-realistic style transfer, and artistic style transfer. We train our model on a single image with cascaded multi-scale learning, where each network at each scale is responsible for image reconstruction. This reconstruction objective greatly reduces the complexity and running time of training, compared to the GAN objective. However, the reconstruction objective also exacerbates the output quality. Therefore, to solve this problem, we further utilize simple random pixel shuffling, which also gives control over manipulation, inspired by the Denoising Autoencoder. With quantitative evaluation, we show that SinIR has competitive performance on various image manipulation tasks. Moreover, with a much simpler training objective (i.e., reconstruction), SinIR is trained 33.5 times faster than SinGAN (for 500 X 500 images) that solves similar tasks. Our code is publicly available at github.com/YooJiHyeong/SinIR.
Non-Parametric Style Transfer
Jun 26, 2022Recent feed-forward neural methods of arbitrary image style transfer mainly utilized encoded feature map upto its second-order statistics, i.e., linearly transformed the encoded feature map of a content image to have the same mean and variance (or covariance) of a target style feature map. In this work, we extend the second-order statistical feature matching into a general distribution matching based on the understanding that style of an image is represented by the distribution of responses from receptive fields. For this generalization, first, we propose a new feature transform layer that exactly matches the feature map distribution of content image into that of target style image. Second, we analyze the recent style losses consistent with our new feature transform layer to train a decoder network which generates a style transferred image from the transformed feature map. Based on our experimental results, it is proven that the stylized images obtained with our method are more similar with the target style images in all existing style measures without losing content clearness.