 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Analysing Statistical methods for Automatic Detection of Image Forgery
Nov 24, 2021
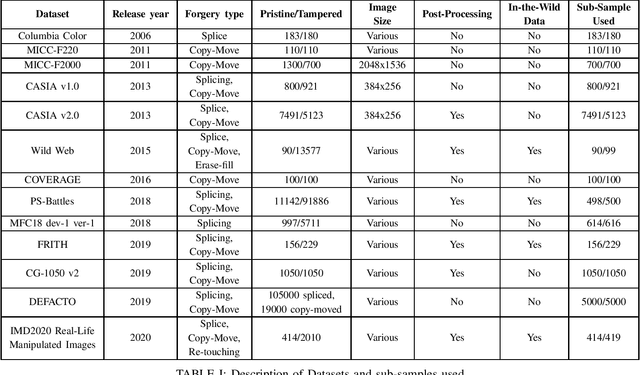
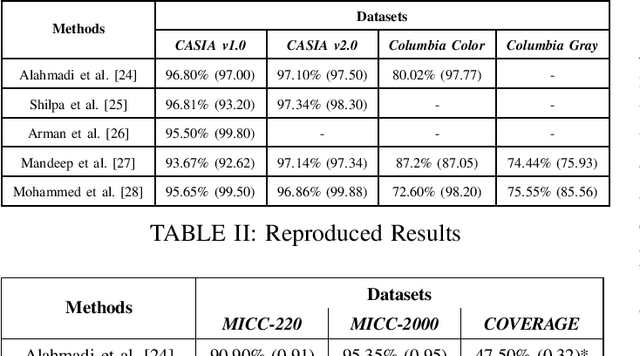
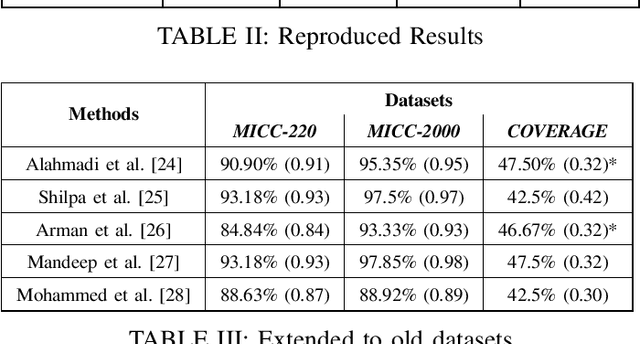
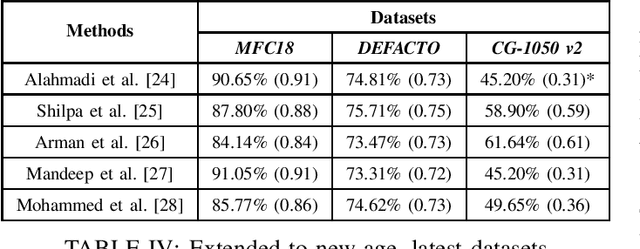
Image manipulation and forgery detection have been a topic of research for more than a decade now. New-age tools and large-scale social platforms have given space for manipulated media to thrive. These media can be potentially dangerous and thus innumerable methods have been designed and tested to prove their robustness in detecting forgery. However, the results reported by state-of-the-art systems indicate that supervised approaches achieve almost perfect performance but only with particular datasets. In this work, we analyze the issue of out-of-distribution generalisability of the current state-of-the-art image forgery detection techniques through several experiments. Our study focuses on models that utilise handcrafted features for image forgery detection. We show that the developed methods fail to perform well on cross-dataset evaluations and in-the-wild manipulated media. As a consequence, a question is raised about the current evaluation and overestimated performance of the systems under consideration. Note: This work was done during a summer research internship at ITMR Lab, IIIT-Allahabad under the supervision of Prof. Anupam Agarwal.
Contrastive Masked Autoencoders are Stronger Vision Learners
Jul 27, 2022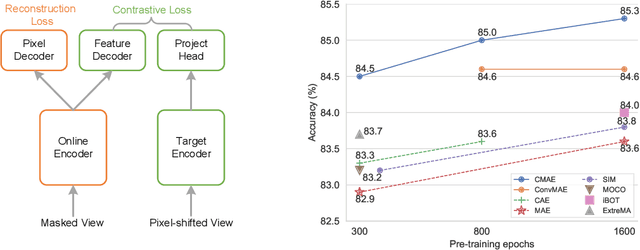

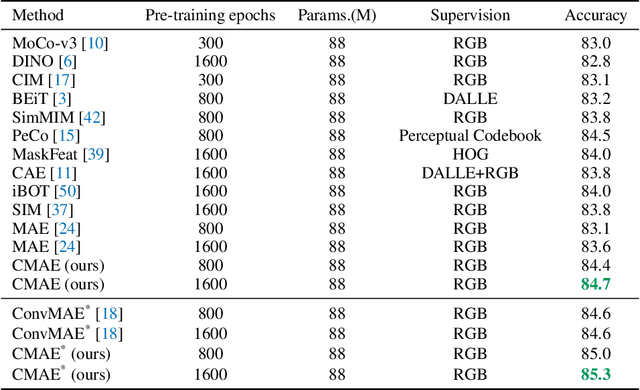
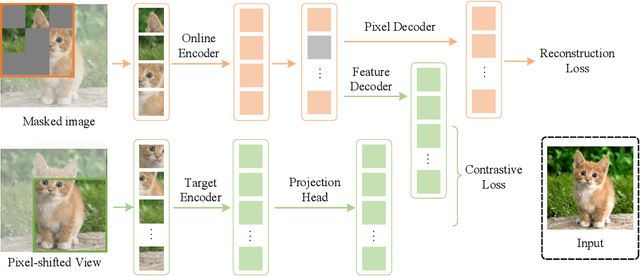
Masked image modeling (MIM) has achieved promising results on various vision tasks. However, the limited discriminability of learned representation manifests there is still plenty to go for making a stronger vision learner. Towards this goal, we propose Contrastive Masked Autoencoders (CMAE), a new self-supervised pre-training method for learning more comprehensive and capable vision representations. By elaboratively unifying contrastive learning (CL) and masked image model (MIM) through novel designs, CMAE leverages their respective advantages and learns representations with both strong instance discriminability and local perceptibility. Specifically, CMAE consists of two branches where the online branch is an asymmetric encoder-decoder and the target branch is a momentum updated encoder. During training, the online encoder reconstructs original images from latent representations of masked images to learn holistic features. The target encoder, fed with the full images, enhances the feature discriminability via contrastive learning with its online counterpart. To make CL compatible with MIM, CMAE introduces two new components, i.e. pixel shift for generating plausible positive views and feature decoder for complementing features of contrastive pairs. Thanks to these novel designs, CMAE effectively improves the representation quality and transfer performance over its MIM counterpart. CMAE achieves the state-of-the-art performance on highly competitive benchmarks of image classification, semantic segmentation and object detection. Notably, CMAE-Base achieves $85.3\%$ top-1 accuracy on ImageNet and $52.5\%$ mIoU on ADE20k, surpassing previous best results by $0.7\%$ and $1.8\%$ respectively. Codes will be made publicly available.
Generative Visual Prompt: Unifying Distributional Control of Pre-Trained Generative Models
Sep 14, 2022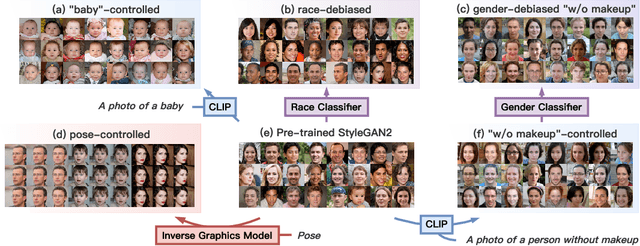



Generative models (e.g., GANs and diffusion models) learn the underlying data distribution in an unsupervised manner. However, many applications of interest require sampling from a specific region of the generative model's output space or evenly over a range of characteristics. To allow efficient sampling in these scenarios, we propose Generative Visual Prompt (PromptGen), a framework for distributional control over pre-trained generative models by incorporating knowledge of arbitrary off-the-shelf models. PromptGen defines control as an energy-based model (EBM) and samples images in a feed-forward manner by approximating the EBM with invertible neural networks, avoiding optimization at inference. We demonstrate how PromptGen can control several generative models (e.g., StyleGAN2, StyleNeRF, diffusion autoencoder, and NVAE) using various off-the-shelf models: (1) with the CLIP model, PromptGen can sample images guided by text, (2) with image classifiers, PromptGen can de-bias generative models across a set of attributes, and (3) with inverse graphics models, PromptGen can sample images of the same identity in different poses. (4) Finally, PromptGen reveals that the CLIP model shows "reporting bias" when used as control, and PromptGen can further de-bias this controlled distribution in an iterative manner. Our code is available at https://github.com/ChenWu98/Generative-Visual-Prompt.
Auto-FedRL: Federated Hyperparameter Optimization for Multi-institutional Medical Image Segmentation
Mar 12, 2022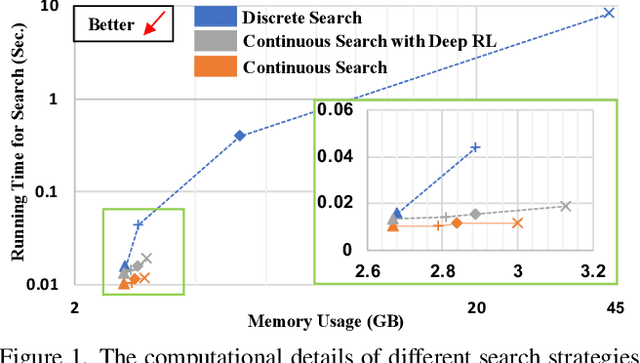

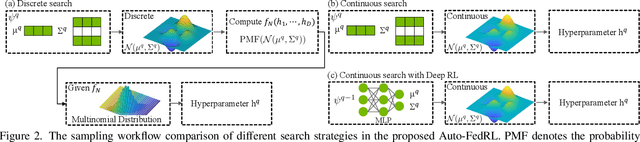

Federated learning (FL) is a distributed machine learning technique that enables collaborative model training while avoiding explicit data sharing. The inherent privacy-preserving property of FL algorithms makes them especially attractive to the medical field. However, in case of heterogeneous client data distributions, standard FL methods are unstable and require intensive hyperparameter tuning to achieve optimal performance. Conventional hyperparameter optimization algorithms are impractical in real-world FL applications as they involve numerous training trials, which are often not affordable with limited compute budgets. In this work, we propose an efficient reinforcement learning~(RL)-based federated hyperparameter optimization algorithm, termed Auto-FedRL, in which an online RL agent can dynamically adjust hyperparameters of each client based on the current training progress. Extensive experiments are conducted to investigate different search strategies and RL agents. The effectiveness of the proposed method is validated on a heterogeneous data split of the CIFAR-10 dataset as well as two real-world medical image segmentation datasets for COVID-19 lesion segmentation in chest CT and pancreas segmentation in abdominal CT.
Portuguese Man-of-War Image Classification with Convolutional Neural Networks
Jul 04, 2022


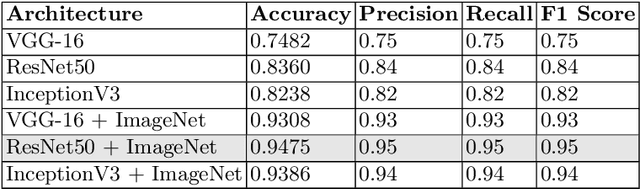
Portuguese man-of-war (PMW) is a gelatinous organism with long tentacles capable of causing severe burns, thus leading to negative impacts on human activities, such as tourism and fishing. There is a lack of information about the spatio-temporal dynamics of this species. Therefore, the use of alternative methods for collecting data can contribute to their monitoring. Given the widespread use of social networks and the eye-catching look of PMW, Instagram posts can be a promising data source for monitoring. The first task to follow this approach is to identify posts that refer to PMW. This paper reports on the use of convolutional neural networks for PMW images classification, in order to automate the recognition of Instagram posts. We created a suitable dataset, and trained three different neural networks: VGG-16, ResNet50, and InceptionV3, with and without a pre-trained step with the ImageNet dataset. We analyzed their results using accuracy, precision, recall, and F1 score metrics. The pre-trained ResNet50 network presented the best results, obtaining 94% of accuracy and 95% of precision, recall, and F1 score. These results show that convolutional neural networks can be very effective for recognizing PMW images from the Instagram social media.
Leveraging Image-based Generative Adversarial Networks for Time Series Generation
Dec 15, 2021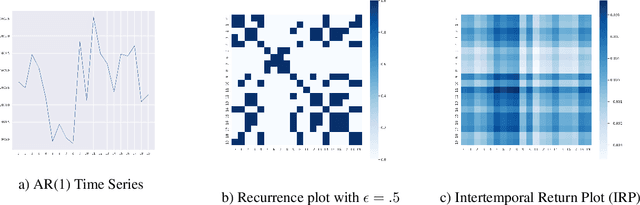

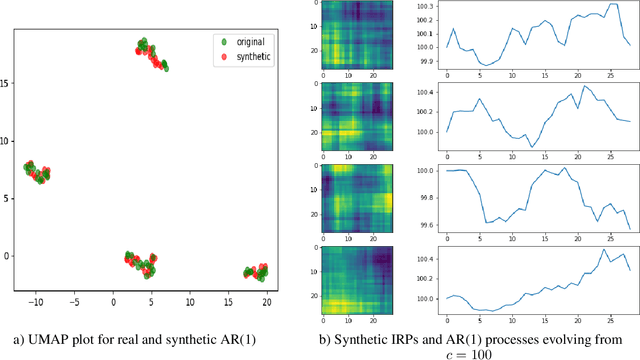
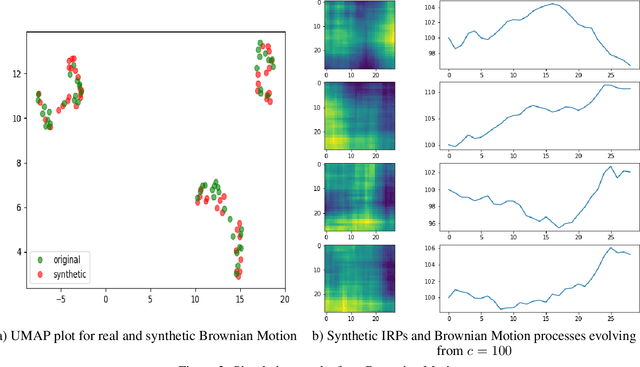
Generative models synthesize image data with great success regarding sampling quality, diversity and feature disentanglement. Generative models for time series lack these benefits due to a missing representation, which captures temporal dynamics and allows inversion for sampling. The paper proposes the intertemporal return plot (IRP) representation to facilitate the use of image-based generative adversarial networks for time series generation. The representation proves effective in capturing time series characteristics and, compared to alternative representations, benefits from invertibility and scale-invariance. Empirical benchmarks confirm these features and demonstrate that the IRP enables an off-the-shelf Wasserstein GAN with gradient penalty to sample realistic time series, which outperform a specialized RNN-based GAN, while simultaneously reducing model complexity.
Registration based Few-Shot Anomaly Detection
Jul 15, 2022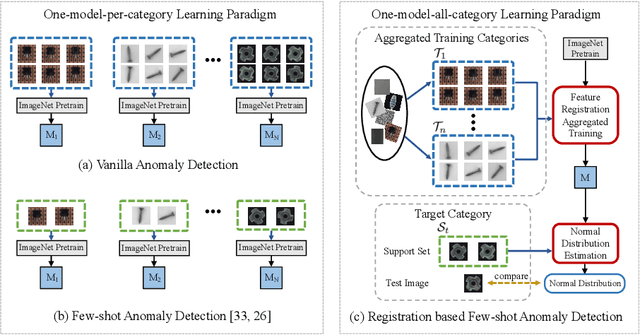
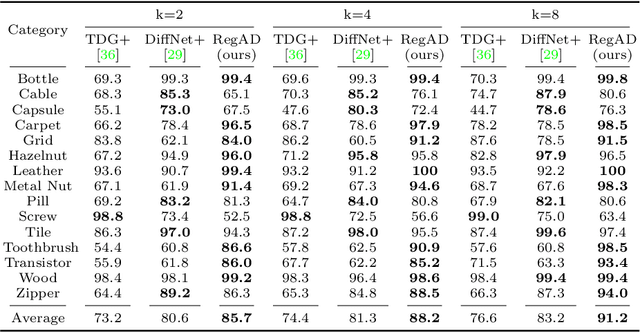
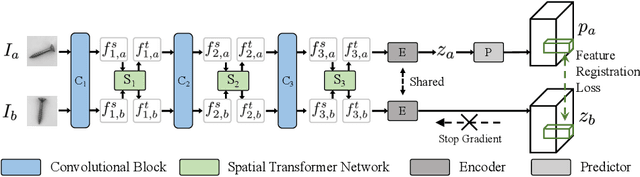
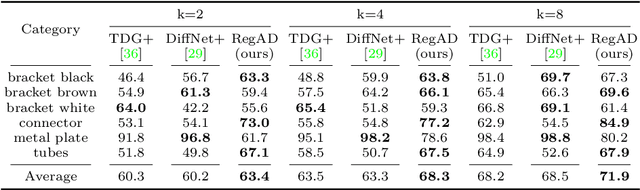
This paper considers few-shot anomaly detection (FSAD), a practical yet under-studied setting for anomaly detection (AD), where only a limited number of normal images are provided for each category at training. So far, existing FSAD studies follow the one-model-per-category learning paradigm used for standard AD, and the inter-category commonality has not been explored. Inspired by how humans detect anomalies, i.e., comparing an image in question to normal images, we here leverage registration, an image alignment task that is inherently generalizable across categories, as the proxy task, to train a category-agnostic anomaly detection model. During testing, the anomalies are identified by comparing the registered features of the test image and its corresponding support (normal) images. As far as we know, this is the first FSAD method that trains a single generalizable model and requires no re-training or parameter fine-tuning for new categories. Experimental results have shown that the proposed method outperforms the state-of-the-art FSAD methods by 3%-8% in AUC on the MVTec and MPDD benchmarks.
CMA-CLIP: Cross-Modality Attention CLIP for Image-Text Classification
Dec 07, 2021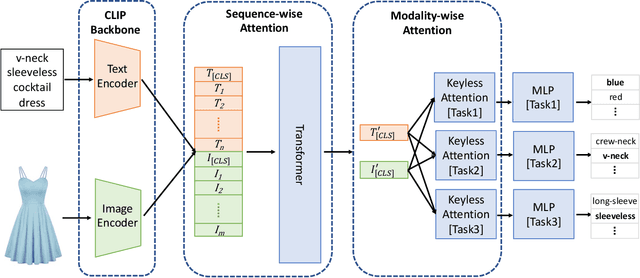

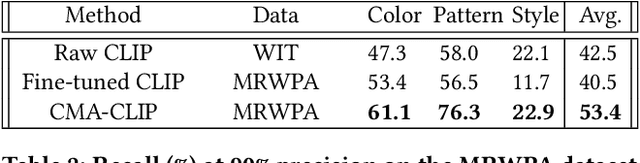

Modern Web systems such as social media and e-commerce contain rich contents expressed in images and text. Leveraging information from multi-modalities can improve the performance of machine learning tasks such as classification and recommendation. In this paper, we propose the Cross-Modality Attention Contrastive Language-Image Pre-training (CMA-CLIP), a new framework which unifies two types of cross-modality attentions, sequence-wise attention and modality-wise attention, to effectively fuse information from image and text pairs. The sequence-wise attention enables the framework to capture the fine-grained relationship between image patches and text tokens, while the modality-wise attention weighs each modality by its relevance to the downstream tasks. In addition, by adding task specific modality-wise attentions and multilayer perceptrons, our proposed framework is capable of performing multi-task classification with multi-modalities. We conduct experiments on a Major Retail Website Product Attribute (MRWPA) dataset and two public datasets, Food101 and Fashion-Gen. The results show that CMA-CLIP outperforms the pre-trained and fine-tuned CLIP by an average of 11.9% in recall at the same level of precision on the MRWPA dataset for multi-task classification. It also surpasses the state-of-the-art method on Fashion-Gen Dataset by 5.5% in accuracy and achieves competitive performance on Food101 Dataset. Through detailed ablation studies, we further demonstrate the effectiveness of both cross-modality attention modules and our method's robustness against noise in image and text inputs, which is a common challenge in practice.
Stochastic Optimization of 3D Non-Cartesian Sampling Trajectory (SNOPY)
Sep 22, 2022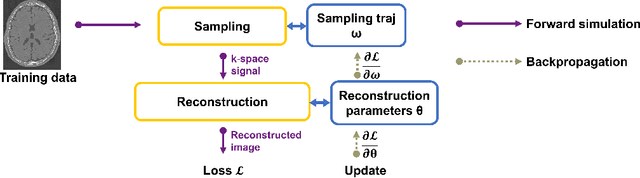
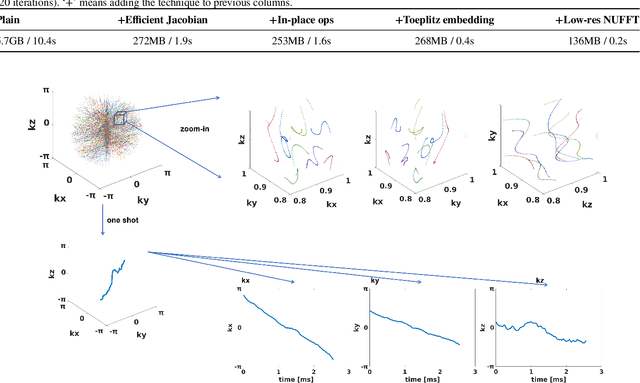
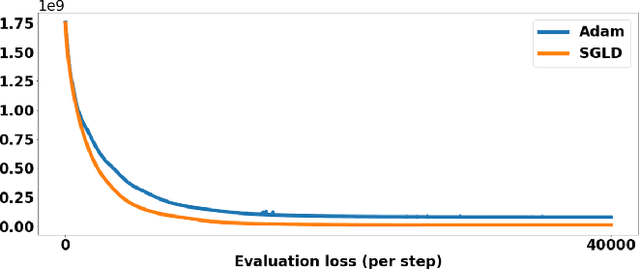

Optimizing 3D k-space sampling trajectories for efficient MRI is important yet challenging. This work proposes a generalized framework for optimizing 3D non-Cartesian sampling patterns via data-driven optimization. We built a differentiable MRI system model to enable gradient-based methods for sampling trajectory optimization. By combining training losses, the algorithm can simultaneously optimize multiple properties of sampling patterns, including image quality, hardware constraints (maximum slew rate and gradient strength), reduced peripheral nerve stimulation (PNS), and parameter-weighted contrast. The proposed method can either optimize the gradient waveform (spline-based freeform optimization) or optimize properties of given sampling trajectories (such as the rotation angle of radial trajectories). Notably, the method optimizes sampling trajectories synergistically with either model-based or learning-based reconstruction methods. We proposed several strategies to alleviate the severe non-convexity and huge computation demand posed by the high-dimensional optimization. The corresponding code is organized as an open-source, easy-to-use toolbox. We applied the optimized trajectory to multiple applications including structural and functional imaging. In the simulation studies, the reconstruction PSNR of a 3D kooshball trajectory was increased by 4 dB with SNOPY optimization. In the prospective studies, by optimizing the rotation angles of a stack-of-stars (SOS) trajectory, SNOPY improved the PSNR by 1.4dB compared to the best empirical method. Optimizing the gradient waveform of a rotational EPI trajectory improved subjects' rating of the PNS effect from 'strong' to 'mild.' In short, SNOPY provides an efficient data-driven and optimization-based method to tailor non-Cartesian sampling trajectories.
Multi-manifold Attention for Vision Transformers
Jul 18, 2022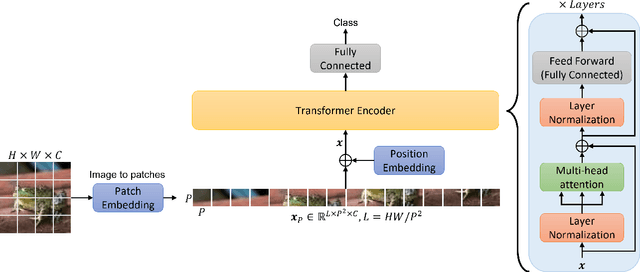
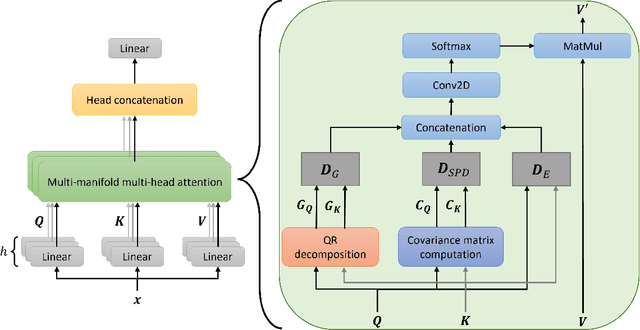
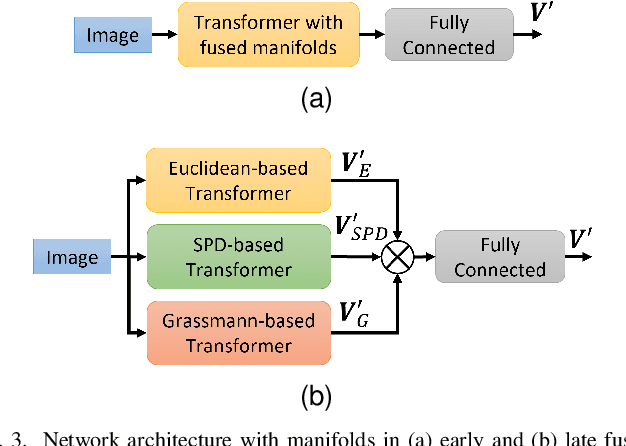

Vision Transformer are very popular nowadays due to their state-of-the-art performance in several computer vision tasks, such as image classification and action recognition. Although the performance of Vision Transformers have been greatly improved by employing Convolutional Neural Networks, hierarchical structures and compact forms, there is limited research on ways to utilize additional data representations to refine the attention map derived from the multi-head attention of a Transformer network. This work proposes a novel attention mechanism, called multi-manifold attention, that can substitute any standard attention mechanism in a Transformer-based network. The proposed attention models the input space in three distinct manifolds, namely Euclidean, Symmetric Positive Definite and Grassmann, with different statistical and geometrical properties, guiding the network to take into consideration a rich set of information that describe the appearance, color and texture of an image, for the computation of a highly descriptive attention map. In this way, a Vision Transformer with the proposed attention is guided to become more attentive towards discriminative features, leading to improved classification results, as shown by the experimental results on several well-known image classification datasets.