 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Attention Spiking Neural Networks
Sep 28, 2022
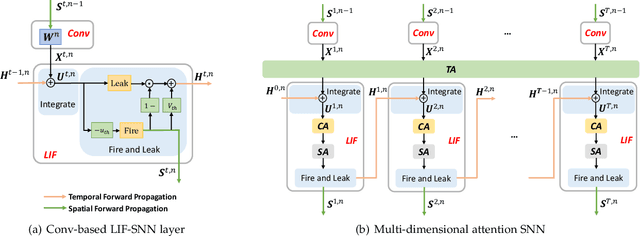
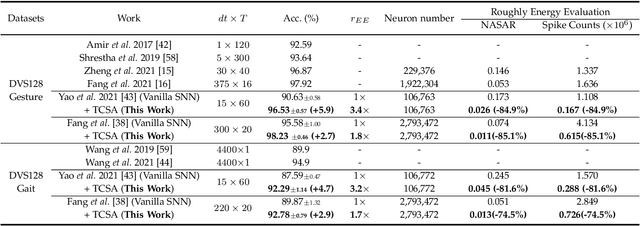
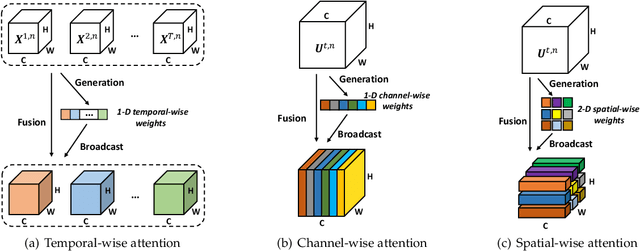
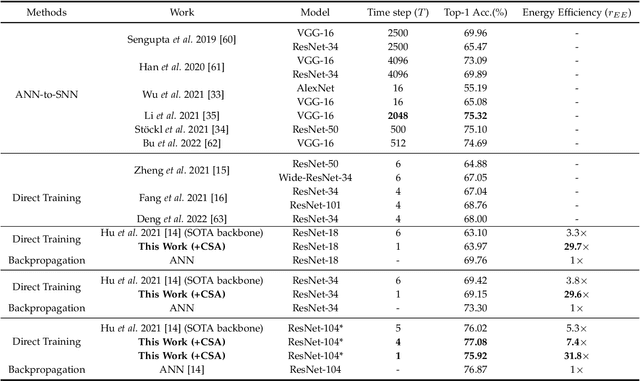
Benefiting from the event-driven and sparse spiking characteristics of the brain, spiking neural networks (SNNs) are becoming an energy-efficient alternative to artificial neural networks (ANNs). However, the performance gap between SNNs and ANNs has been a great hindrance to deploying SNNs ubiquitously for a long time. To leverage the full potential of SNNs, we study the effect of attention mechanisms in SNNs. We first present our idea of attention with a plug-and-play kit, termed the Multi-dimensional Attention (MA). Then, a new attention SNN architecture with end-to-end training called "MA-SNN" is proposed, which infers attention weights along the temporal, channel, as well as spatial dimensions separately or simultaneously. Based on the existing neuroscience theories, we exploit the attention weights to optimize membrane potentials, which in turn regulate the spiking response in a data-dependent way. At the cost of negligible additional parameters, MA facilitates vanilla SNNs to achieve sparser spiking activity, better performance, and energy efficiency concurrently. Experiments are conducted in event-based DVS128 Gesture/Gait action recognition and ImageNet-1k image classification. On Gesture/Gait, the spike counts are reduced by 84.9%/81.6%, and the task accuracy and energy efficiency are improved by 5.9%/4.7% and 3.4$\times$/3.2$\times$. On ImageNet-1K, we achieve top-1 accuracy of 75.92% and 77.08% on single/4-step Res-SNN-104, which are state-of-the-art results in SNNs. To our best knowledge, this is for the first time, that the SNN community achieves comparable or even better performance compared with its ANN counterpart in the large-scale dataset. Our work lights up SNN's potential as a general backbone to support various applications for SNNs, with a great balance between effectiveness and efficiency.
A Lightweight Machine Learning Pipeline for LiDAR-simulation
Aug 05, 2022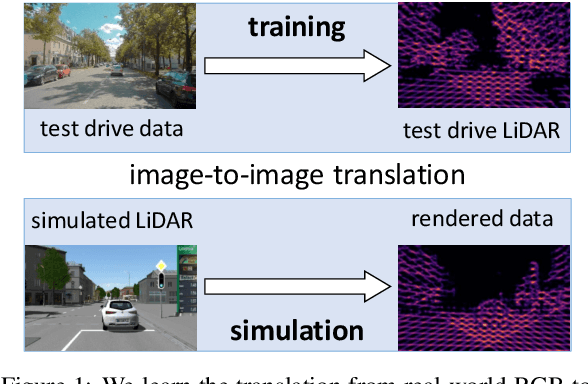
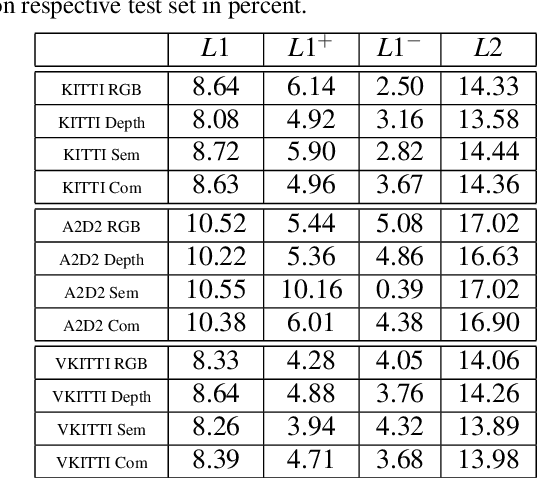
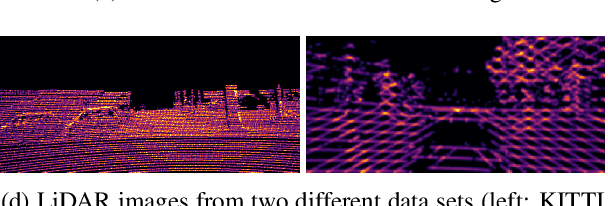
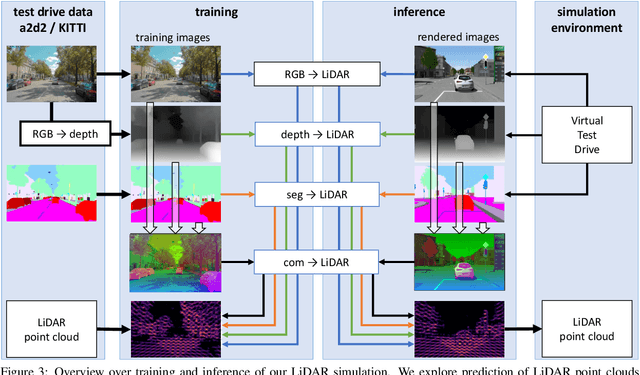
Virtual testing is a crucial task to ensure safety in autonomous driving, and sensor simulation is an important task in this domain. Most current LiDAR simulations are very simplistic and are mainly used to perform initial tests, while the majority of insights are gathered on the road. In this paper, we propose a lightweight approach for more realistic LiDAR simulation that learns a real sensor's behavior from test drive data and transforms this to the virtual domain. The central idea is to cast the simulation into an image-to-image translation problem. We train our pix2pix based architecture on two real world data sets, namely the popular KITTI data set and the Audi Autonomous Driving Dataset which provide both, RGB and LiDAR images. We apply this network on synthetic renderings and show that it generalizes sufficiently from real images to simulated images. This strategy enables to skip the sensor-specific, expensive and complex LiDAR physics simulation in our synthetic world and avoids oversimplification and a large domain-gap through the clean synthetic environment.
* Conference: DeLTA 22; ISBN 978-989-758-584-5; ISSN 2184-9277; publisher: SciTePress, organization: INSTICC
Image recognition via Vietoris-Rips complex
Sep 06, 2021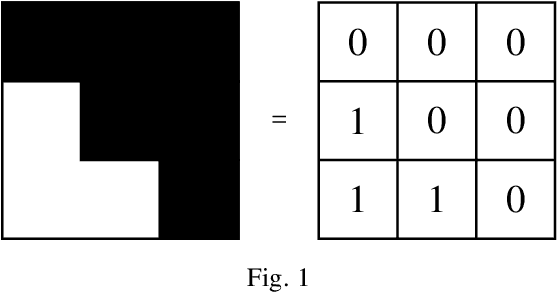
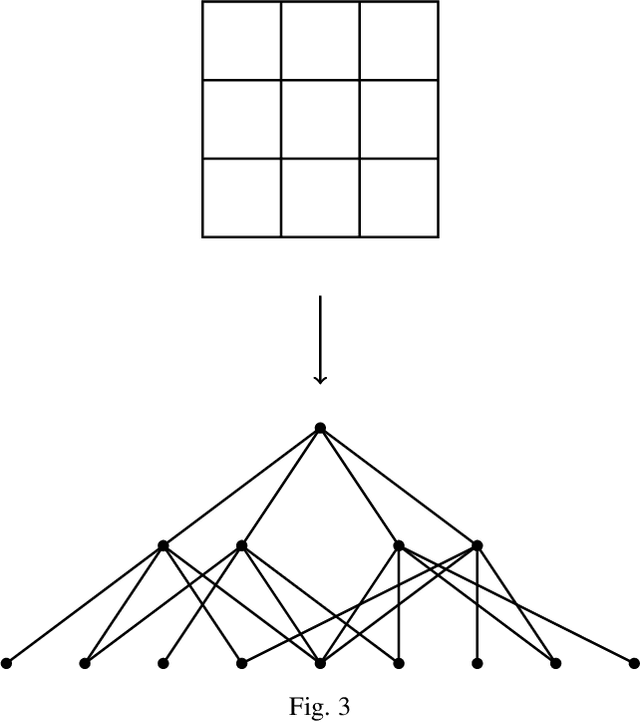
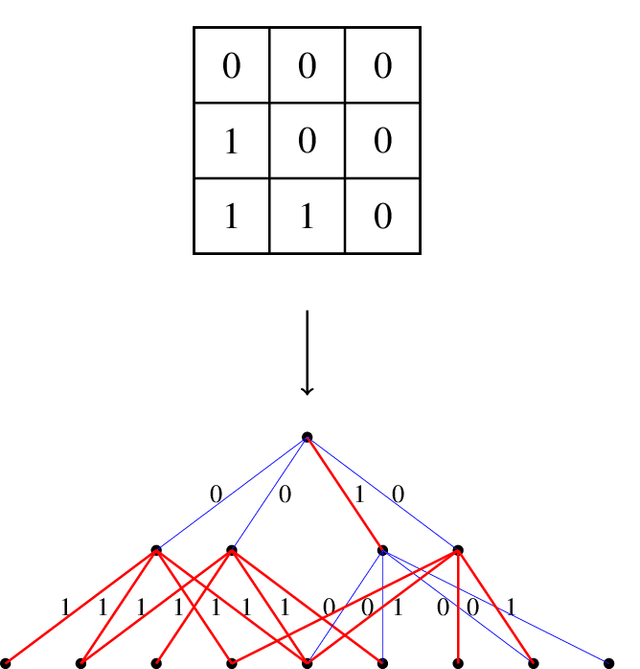
Extracting informative features from images has been of capital importance in computer vision. In this paper, we propose a way to extract such features from images by a method based on algebraic topology. To that end, we construct a weighted graph from an image, which extracts local information of an image. By considering this weighted graph as a pseudo-metric space, we construct a Vietoris-Rips complex with a parameter $\varepsilon$ by a well-known process of algebraic topology. We can extract information of complexity of the image and can detect a sub-image with a relatively high concentration of information from this Vietoris-Rips complex. The parameter $\varepsilon$ of the Vietoris-Rips complex produces robustness to noise. We empirically show that the extracted feature captures well images' characteristics.
Adaptive 3D Localization of 2D Freehand Ultrasound Brain Images
Sep 12, 2022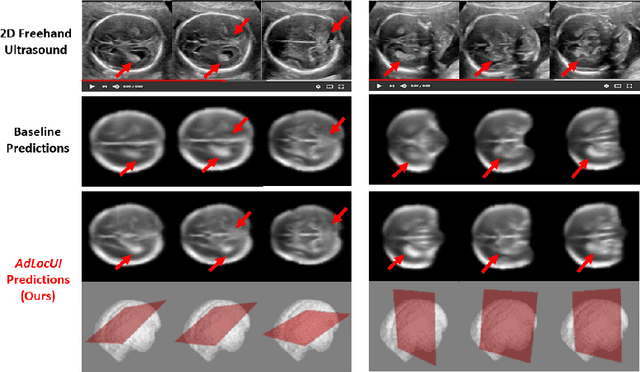
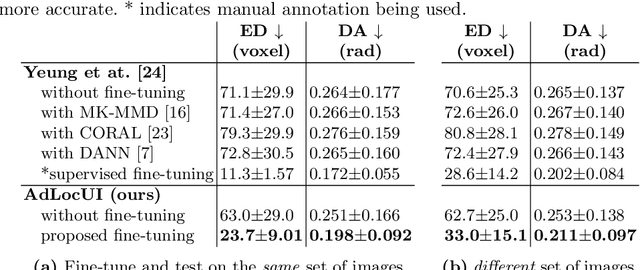
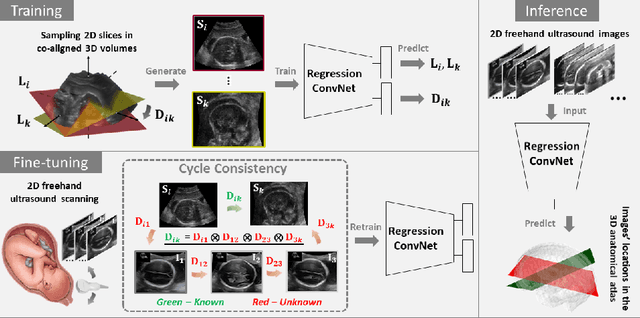
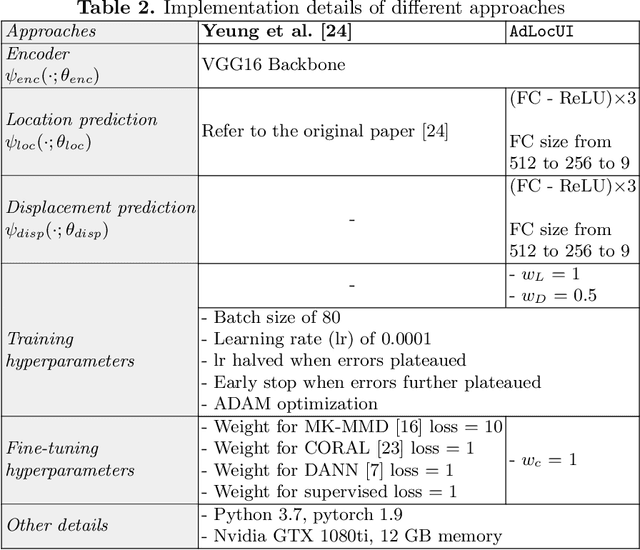
Two-dimensional (2D) freehand ultrasound is the mainstay in prenatal care and fetal growth monitoring. The task of matching corresponding cross-sectional planes in the 3D anatomy for a given 2D ultrasound brain scan is essential in freehand scanning, but challenging. We propose AdLocUI, a framework that Adaptively Localizes 2D Ultrasound Images in the 3D anatomical atlas without using any external tracking sensor.. We first train a convolutional neural network with 2D slices sampled from co-aligned 3D ultrasound volumes to predict their locations in the 3D anatomical atlas. Next, we fine-tune it with 2D freehand ultrasound images using a novel unsupervised cycle consistency, which utilizes the fact that the overall displacement of a sequence of images in the 3D anatomical atlas is equal to the displacement from the first image to the last in that sequence. We demonstrate that AdLocUI can adapt to three different ultrasound datasets, acquired with different machines and protocols, and achieves significantly better localization accuracy than the baselines. AdLocUI can be used for sensorless 2D freehand ultrasound guidance by the bedside. The source code is available at https://github.com/pakheiyeung/AdLocUI.
PP-ShiTu: A Practical Lightweight Image Recognition System
Nov 01, 2021
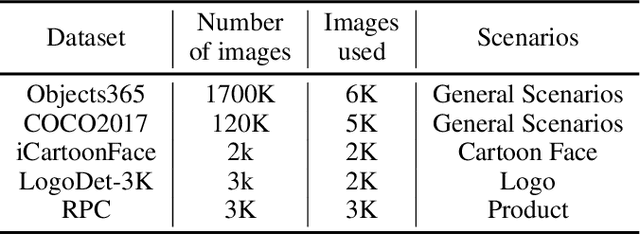
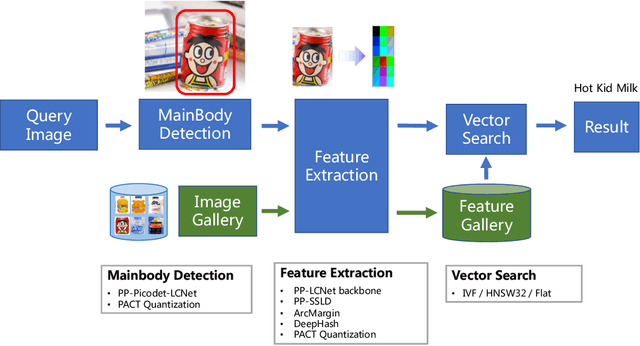
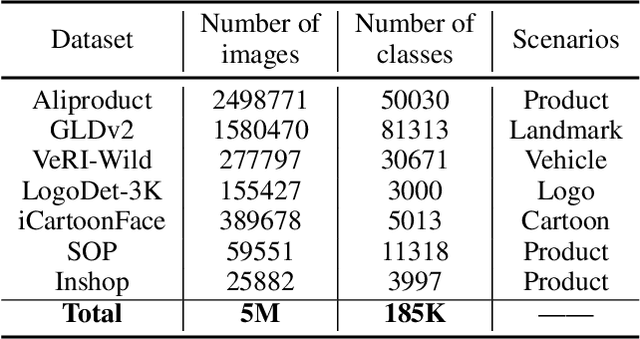
In recent years, image recognition applications have developed rapidly. A large number of studies and techniques have emerged in different fields, such as face recognition, pedestrian and vehicle re-identification, landmark retrieval, and product recognition. In this paper, we propose a practical lightweight image recognition system, named PP-ShiTu, consisting of the following 3 modules, mainbody detection, feature extraction and vector search. We introduce popular strategies including metric learning, deep hash, knowledge distillation and model quantization to improve accuracy and inference speed. With strategies above, PP-ShiTu works well in different scenarios with a set of models trained on a mixed dataset. Experiments on different datasets and benchmarks show that the system is widely effective in different domains of image recognition. All the above mentioned models are open-sourced and the code is available in the GitHub repository PaddleClas on PaddlePaddle.
A Study on the Efficient Product Search Service for the Damaged Image Information
Nov 14, 2021
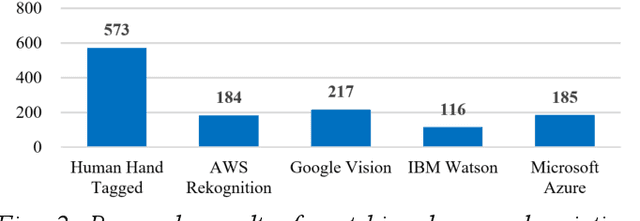
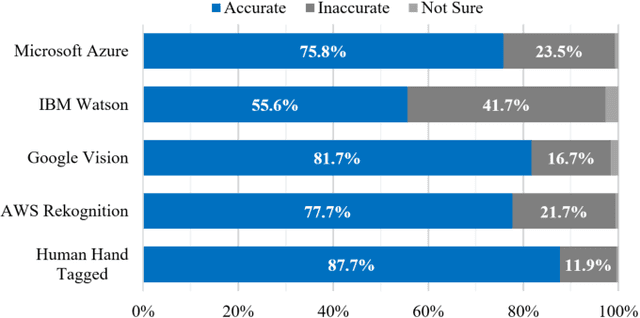

With the development of Information and Communication Technologies and the dissemination of smartphones, especially now that image search is possible through the internet, e-commerce markets are more activating purchasing services for a wide variety of products. However, it often happens that the image of the desired product is impaired and that the search engine does not recognize it properly. The idea of this study is to help search for products through image restoration using an image pre-processing and image inpainting algorithm for damaged images. It helps users easily purchase the items they want by providing a more accurate image search system. Besides, the system has the advantage of efficiently showing information by category, so that enables efficient sales of registered information.
CMA-CLIP: Cross-Modality Attention CLIP for Image-Text Classification
Dec 09, 2021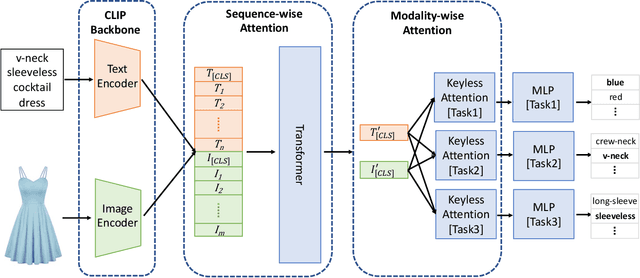

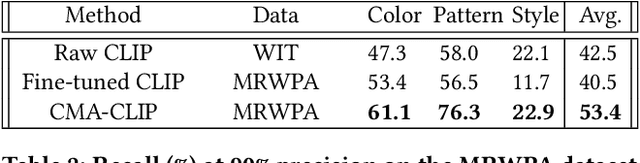

Modern Web systems such as social media and e-commerce contain rich contents expressed in images and text. Leveraging information from multi-modalities can improve the performance of machine learning tasks such as classification and recommendation. In this paper, we propose the Cross-Modality Attention Contrastive Language-Image Pre-training (CMA-CLIP), a new framework which unifies two types of cross-modality attentions, sequence-wise attention and modality-wise attention, to effectively fuse information from image and text pairs. The sequence-wise attention enables the framework to capture the fine-grained relationship between image patches and text tokens, while the modality-wise attention weighs each modality by its relevance to the downstream tasks. In addition, by adding task specific modality-wise attentions and multilayer perceptrons, our proposed framework is capable of performing multi-task classification with multi-modalities. We conduct experiments on a Major Retail Website Product Attribute (MRWPA) dataset and two public datasets, Food101 and Fashion-Gen. The results show that CMA-CLIP outperforms the pre-trained and fine-tuned CLIP by an average of 11.9% in recall at the same level of precision on the MRWPA dataset for multi-task classification. It also surpasses the state-of-the-art method on Fashion-Gen Dataset by 5.5% in accuracy and achieves competitive performance on Food101 Dataset. Through detailed ablation studies, we further demonstrate the effectiveness of both cross-modality attention modules and our method's robustness against noise in image and text inputs, which is a common challenge in practice.
Self-supervised Sequential Information Bottleneck for Robust Exploration in Deep Reinforcement Learning
Sep 12, 2022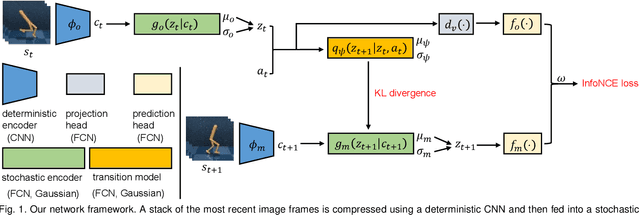
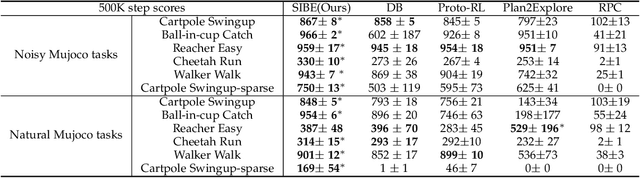
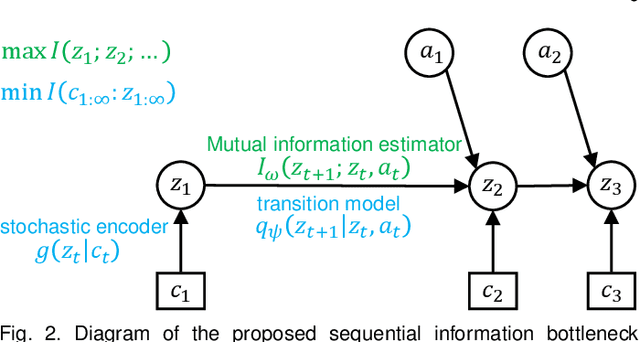

Effective exploration is critical for reinforcement learning agents in environments with sparse rewards or high-dimensional state-action spaces. Recent works based on state-visitation counts, curiosity and entropy-maximization generate intrinsic reward signals to motivate the agent to visit novel states for exploration. However, the agent can get distracted by perturbations to sensor inputs that contain novel but task-irrelevant information, e.g. due to sensor noise or changing background. In this work, we introduce the sequential information bottleneck objective for learning compressed and temporally coherent representations by modelling and compressing sequential predictive information in time-series observations. For efficient exploration in noisy environments, we further construct intrinsic rewards that capture task-relevant state novelty based on the learned representations. We derive a variational upper bound of our sequential information bottleneck objective for practical optimization and provide an information-theoretic interpretation of the derived upper bound. Our experiments on a set of challenging image-based simulated control tasks show that our method achieves better sample efficiency, and robustness to both white noise and natural video backgrounds compared to state-of-art methods based on curiosity, entropy maximization and information-gain.
Fuse and Attend: Generalized Embedding Learning for Art and Sketches
Aug 20, 2022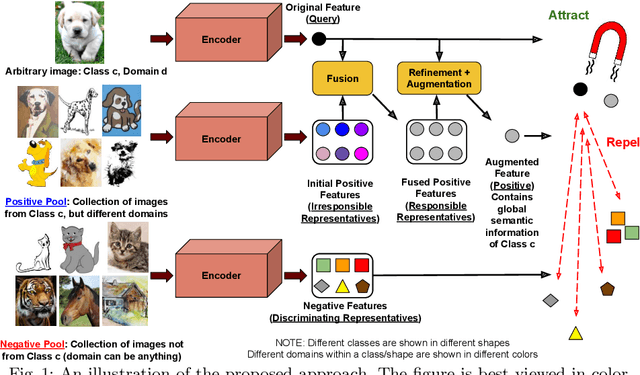
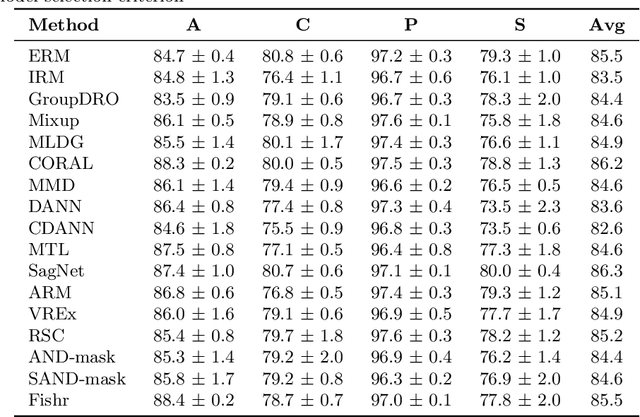
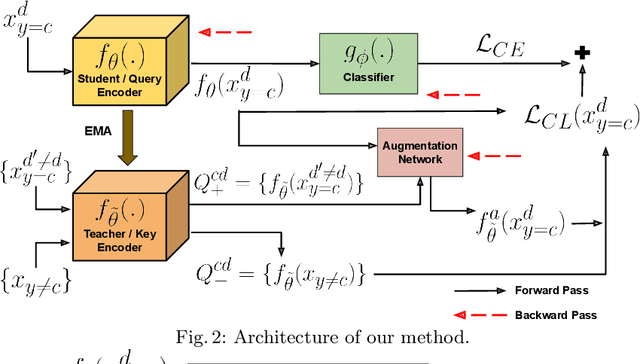
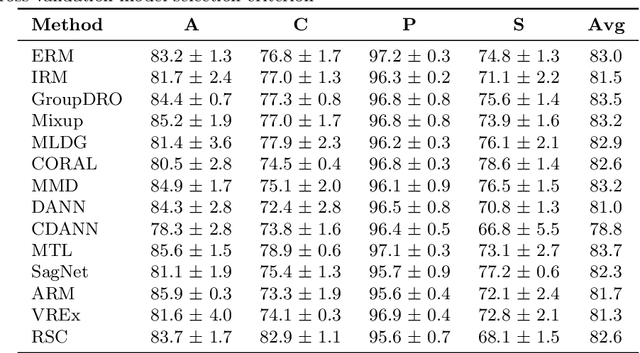
While deep Embedding Learning approaches have witnessed widespread success in multiple computer vision tasks, the state-of-the-art methods for representing natural images need not necessarily perform well on images from other domains, such as paintings, cartoons, and sketch. This is because of the huge shift in the distribution of data from across these domains, as compared to natural images. Domains like sketch often contain sparse informative pixels. However, recognizing objects in such domains is crucial, given multiple relevant applications leveraging such data, for instance, sketch to image retrieval. Thus, achieving an Embedding Learning model that could perform well across multiple domains is not only challenging, but plays a pivotal role in computer vision. To this end, in this paper, we propose a novel Embedding Learning approach with the goal of generalizing across different domains. During training, given a query image from a domain, we employ gated fusion and attention to generate a positive example, which carries a broad notion of the semantics of the query object category (from across multiple domains). By virtue of Contrastive Learning, we pull the embeddings of the query and positive, in order to learn a representation which is robust across domains. At the same time, to teach the model to be discriminative against examples from different semantic categories (across domains), we also maintain a pool of negative embeddings (from different categories). We show the prowess of our method using the DomainBed framework, on the popular PACS (Photo, Art painting, Cartoon, and Sketch) dataset.
A Deep Learning-based Audio-in-Image Watermarking Scheme
Oct 06, 2021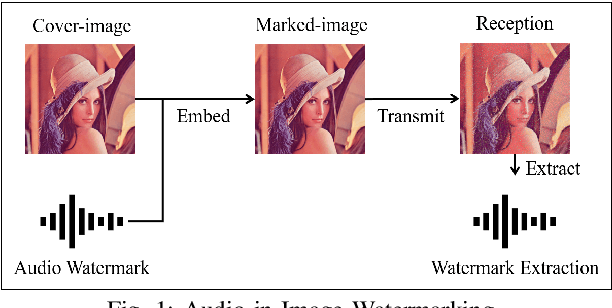
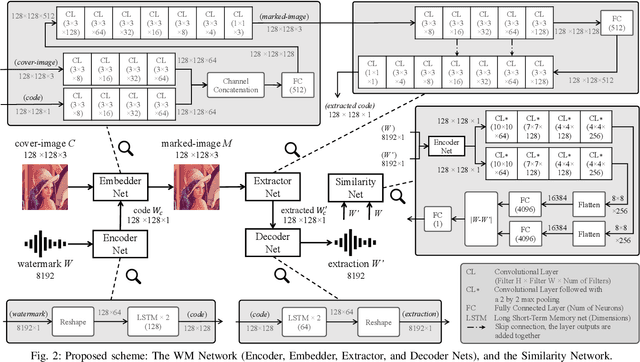
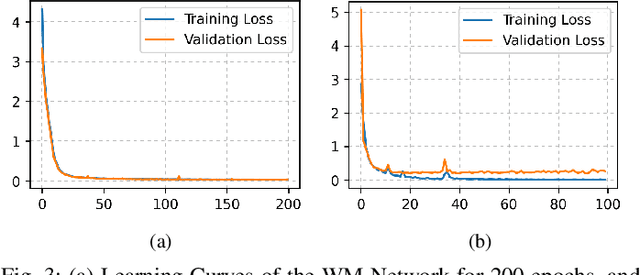
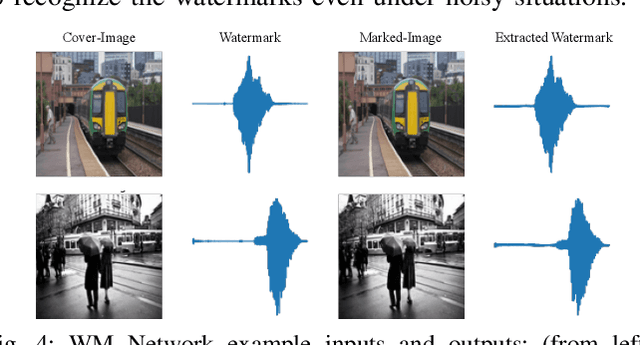
This paper presents a deep learning-based audio-in-image watermarking scheme. Audio-in-image watermarking is the process of covertly embedding and extracting audio watermarks on a cover-image. Using audio watermarks can open up possibilities for different downstream applications. For the purpose of implementing an audio-in-image watermarking that adapts to the demands of increasingly diverse situations, a neural network architecture is designed to automatically learn the watermarking process in an unsupervised manner. In addition, a similarity network is developed to recognize the audio watermarks under distortions, therefore providing robustness to the proposed method. Experimental results have shown high fidelity and robustness of the proposed blind audio-in-image watermarking scheme.