 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Image quality enhancement of embedded holograms in holographic information hiding using deep neural networks
Dec 20, 2021
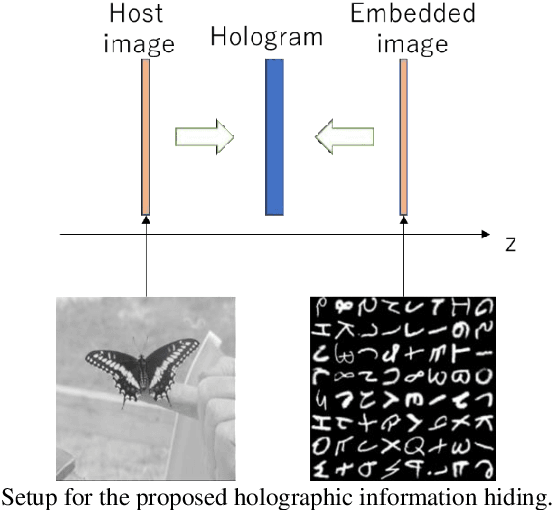

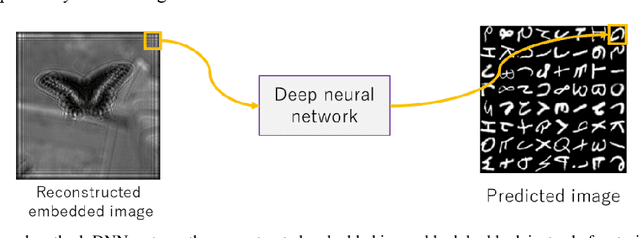
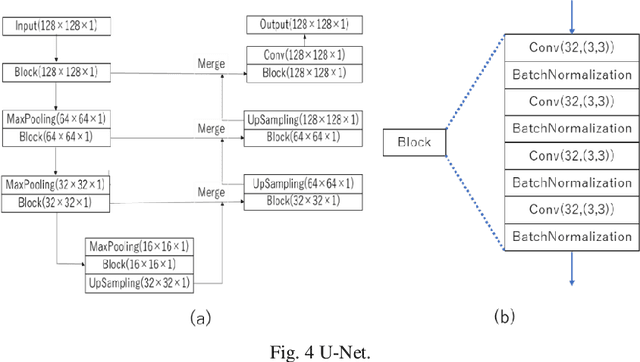
Holographic information hiding is a technique for embedding holograms or images into another hologram, used for copyright protection and steganography of holograms. Using deep neural networks, we offer a way to improve the visual quality of embedded holograms. The brightness of an embedded hologram is set to a fraction of that of the host hologram, resulting in a barely damaged reconstructed image of the host hologram. However, it is difficult to perceive because the embedded hologram's reconstructed image is darker than the reconstructed host image. In this study, we use deep neural networks to restore the darkened image.
CELESTIAL: Classification Enabled via Labelless Embeddings with Self-supervised Telescope Image Analysis Learning
Jan 20, 2022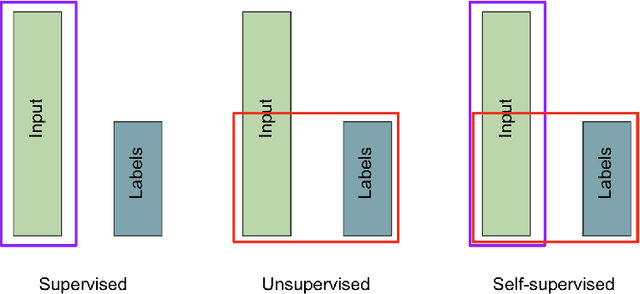


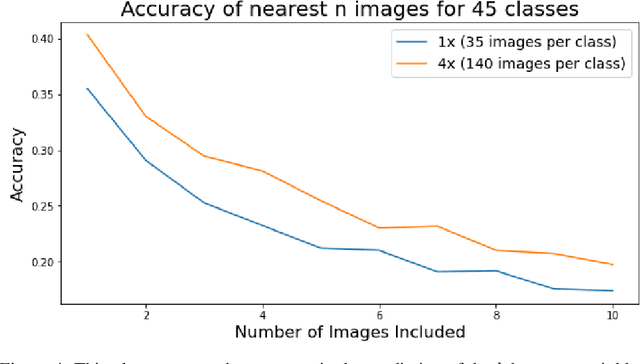
A common class of problems in remote sensing is scene classification, a fundamentally important task for natural hazards identification, geographic image retrieval, and environment monitoring. Recent developments in this field rely label-dependent supervised learning techniques which is antithetical to the 35 petabytes of unlabelled satellite imagery in NASA GIBS. To solve this problem, we establish CELESTIAL-a self-supervised learning pipeline for effectively leveraging sparsely-labeled satellite imagery. This pipeline successfully adapts SimCLR, an algorithm that first learns image representations on unlabelled data and then fine-tunes this knowledge on the provided labels. Our results show CELESTIAL requires only a third of the labels that the supervised method needs to attain the same accuracy on an experimental dataset. The first unsupervised tier can enable applications such as reverse image search for NASA Worldview (i.e. searching similar atmospheric phenomenon over years of unlabelled data with minimal samples) and the second supervised tier can lower the necessity of expensive data annotation significantly. In the future, we hope we can generalize the CELESTIAL pipeline to other data types, algorithms, and applications.
Research on the quantity and brightness evolution characteristics of Photospheric Bright Points groups
Oct 06, 2022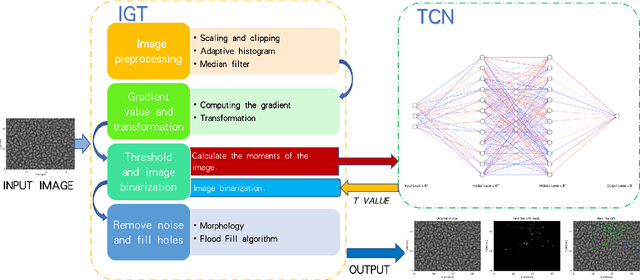
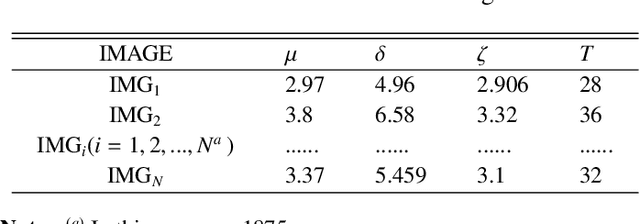

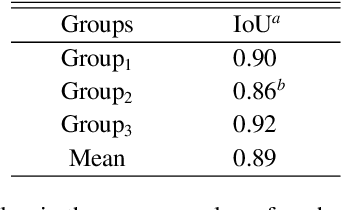
Context. Photospheric bright points (BPs), as the smallest magnetic element of the photosphere and the footpoint tracer of the magnetic flux tube, are of great significance to the study of BPs. Compared with the study of the characteristics and evolution of a few specific BPs, the study of BPs groups can provide us with a better understanding of the characteristics and overall activities of BPs groups. Aims. We aim to find out the evolution characteristics of the brightness and number of BPs groups at different brightness levels, and how these characteristics differ between quiet and active regions. Methods. We propose a hybrid BPs detection model (HBD Model) combining traditional technology and neural network. The Model is used to detect and calculate the BPs brightness characteristics of each frame of continuous high resolution image sequences of active and quiet regions in TiO-band of a pair of BBSO. Using machine learning clustering method, the PBs of each frame was divided into four levels groups (level1-level4) according to the brightness from low to high. Finally, Fourier transform and inverse Fourier transform are used to analyze the evolution of BPs brightness and quantity in these four levels groups. Results. The activities of BPs groups are not random and disorderly. In different levels of brightness, their quantity and brightness evolution show complex changes. Among the four levels of brightness, BPs in the active region were more active and intense than those in the quiet region. However, the quantity and brightness evolution of BPs groups in the quiet region showed the characteristics of large periodic changes and small periodic changes in the medium and high brightness levels (level3 and level4). The brightness evolution of PBs group in the quiet region has obvious periodic changes, but the active region is in a completely random and violent fluctuation state.
Adaptive Contrast for Image Regression in Computer-Aided Disease Assessment
Dec 22, 2021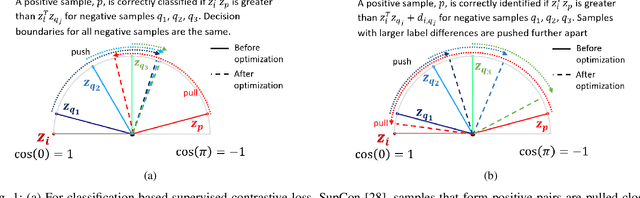
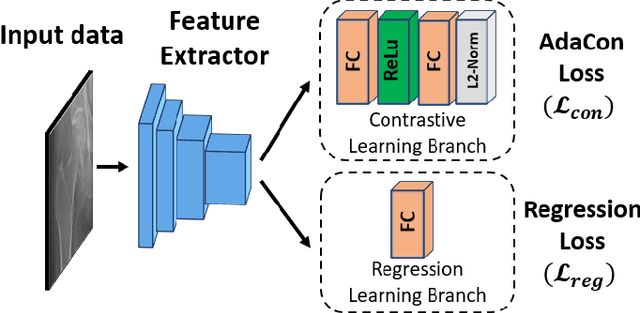
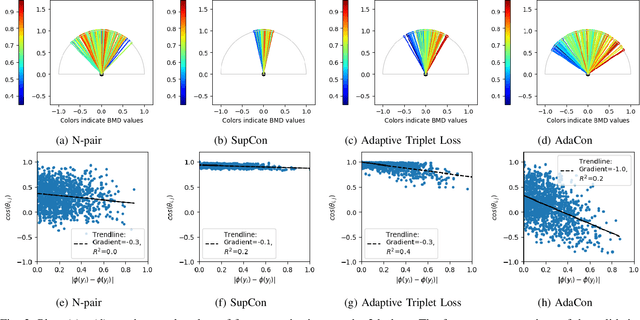
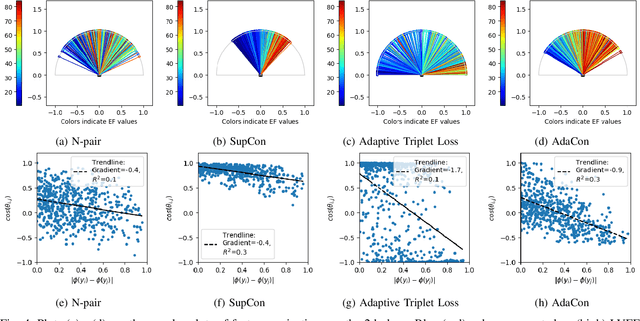
Image regression tasks for medical applications, such as bone mineral density (BMD) estimation and left-ventricular ejection fraction (LVEF) prediction, play an important role in computer-aided disease assessment. Most deep regression methods train the neural network with a single regression loss function like MSE or L1 loss. In this paper, we propose the first contrastive learning framework for deep image regression, namely AdaCon, which consists of a feature learning branch via a novel adaptive-margin contrastive loss and a regression prediction branch. Our method incorporates label distance relationships as part of the learned feature representations, which allows for better performance in downstream regression tasks. Moreover, it can be used as a plug-and-play module to improve performance of existing regression methods. We demonstrate the effectiveness of AdaCon on two medical image regression tasks, ie, bone mineral density estimation from X-ray images and left-ventricular ejection fraction prediction from echocardiogram videos. AdaCon leads to relative improvements of 3.3% and 5.9% in MAE over state-of-the-art BMD estimation and LVEF prediction methods, respectively.
LSAP: Rethinking Inversion Fidelity, Perception and Editability in GAN Latent Space
Sep 26, 2022
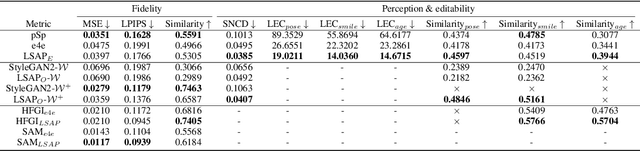
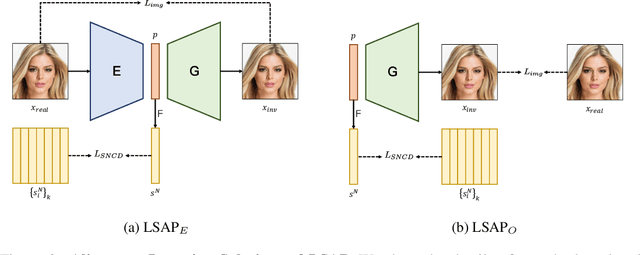
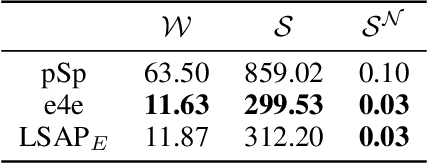
As the methods evolve, inversion is mainly divided into two steps. The first step is Image Embedding, in which an encoder or optimization process embeds images to get the corresponding latent codes. Afterward, the second step aims to refine the inversion and editing results, which we named Result Refinement. Although the second step significantly improves fidelity, perception and editability are almost unchanged, deeply dependent on inverse latent codes attained in the first step. Therefore, a crucial problem is gaining the latent codes with better perception and editability while retaining the reconstruction fidelity. In this work, we first point out that these two characteristics are related to the degree of alignment (or disalignment) of the inverse codes with the synthetic distribution. Then, we propose Latent Space Alignment Inversion Paradigm (LSAP), which consists of evaluation metric and solution for this problem. Specifically, we introduce Normalized Style Space ($\mathcal{S^N}$ space) and $\mathcal{S^N}$ Cosine Distance (SNCD) to measure disalignment of inversion methods. Since our proposed SNCD is differentiable, it can be optimized in both encoder-based and optimization-based embedding methods to conduct a uniform solution. Extensive experiments in various domains demonstrate that SNCD effectively reflects perception and editability, and our alignment paradigm archives the state-of-the-art in both two steps. Code is available on https://github.com/caopulan/GANInverter.
Active Perception Applied To Unmanned Aerial Vehicles Through Deep Reinforcement Learning
Sep 13, 2022

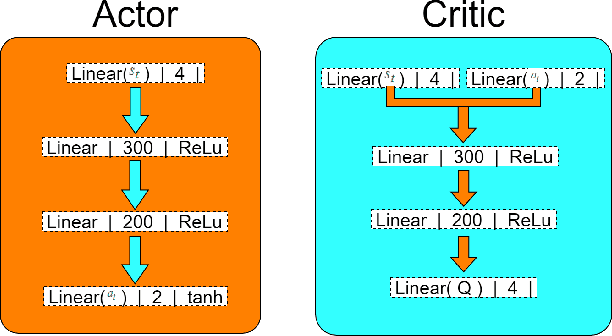
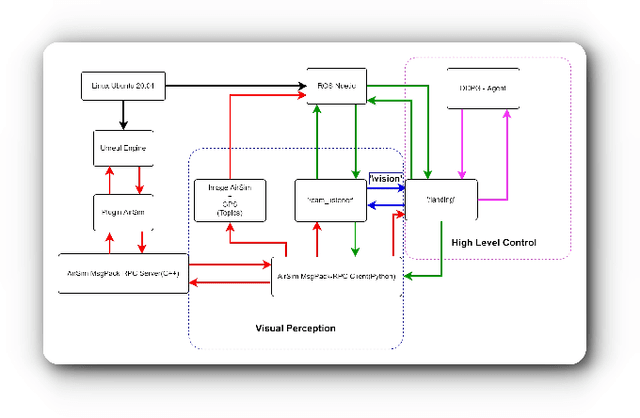
Unmanned Aerial Vehicles (UAV) have been standing out due to the wide range of applications in which they can be used autonomously. However, they need intelligent systems capable of providing a greater understanding of what they perceive to perform several tasks. They become more challenging in complex environments since there is a need to perceive the environment and act under environmental uncertainties to make a decision. In this context, a system that uses active perception can improve performance by seeking the best next view through the recognition of targets while displacement occurs. This work aims to contribute to the active perception of UAVs by tackling the problem of tracking and recognizing water surface structures to perform a dynamic landing. We show that our system with classical image processing techniques and a simple Deep Reinforcement Learning (Deep-RL) agent is capable of perceiving the environment and dealing with uncertainties without making the use of complex Convolutional Neural Networks (CNN) or Contrastive Learning (CL).
Learning Category-Level Manipulation Tasks from Point Clouds with Dynamic Graph CNNs
Sep 13, 2022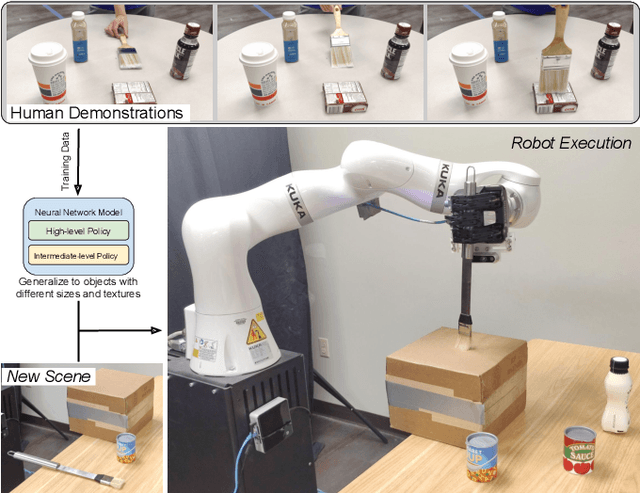
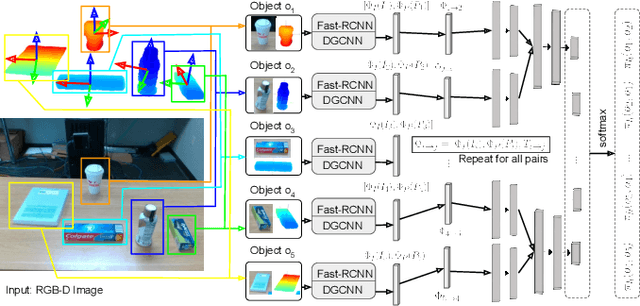
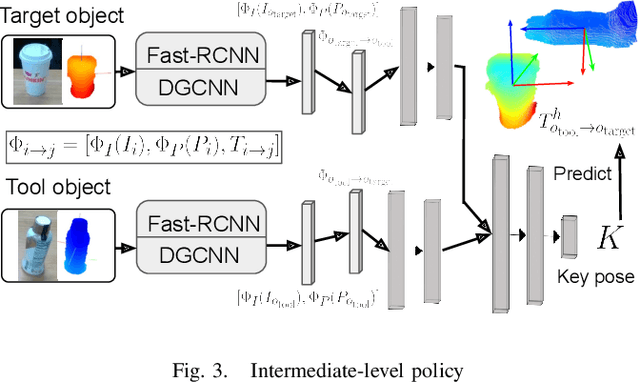

This paper presents a new technique for learning category-level manipulation from raw RGB-D videos of task demonstrations, with no manual labels or annotations. Category-level learning aims to acquire skills that can be generalized to new objects, with geometries and textures that are different from the ones of the objects used in the demonstrations. We address this problem by first viewing both grasping and manipulation as special cases of tool use, where a tool object is moved to a sequence of key-poses defined in a frame of reference of a target object. Tool and target objects, along with their key-poses, are predicted using a dynamic graph convolutional neural network that takes as input an automatically segmented depth and color image of the entire scene. Empirical results on object manipulation tasks with a real robotic arm show that the proposed network can efficiently learn from real visual demonstrations to perform the tasks on novel objects within the same category, and outperforms alternative approaches.
Segmentation-Reconstruction-Guided Facial Image De-occlusion
Dec 15, 2021
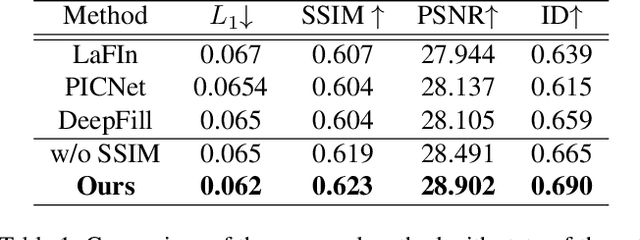
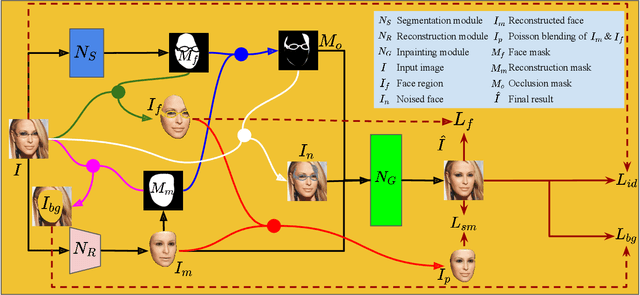
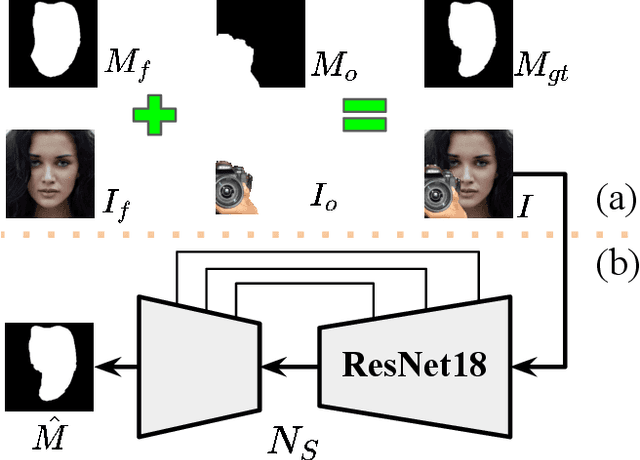
Occlusions are very common in face images in the wild, leading to the degraded performance of face-related tasks. Although much effort has been devoted to removing occlusions from face images, the varying shapes and textures of occlusions still challenge the robustness of current methods. As a result, current methods either rely on manual occlusion masks or only apply to specific occlusions. This paper proposes a novel face de-occlusion model based on face segmentation and 3D face reconstruction, which automatically removes all kinds of face occlusions with even blurred boundaries,e.g., hairs. The proposed model consists of a 3D face reconstruction module, a face segmentation module, and an image generation module. With the face prior and the occlusion mask predicted by the first two, respectively, the image generation module can faithfully recover the missing facial textures. To supervise the training, we further build a large occlusion dataset, with both manually labeled and synthetic occlusions. Qualitative and quantitative results demonstrate the effectiveness and robustness of the proposed method.
Importance of Preprocessing in Histopathology Image Classification Using Deep Convolutional Neural Network
Jan 24, 2022
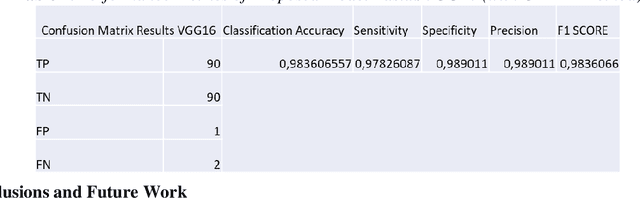
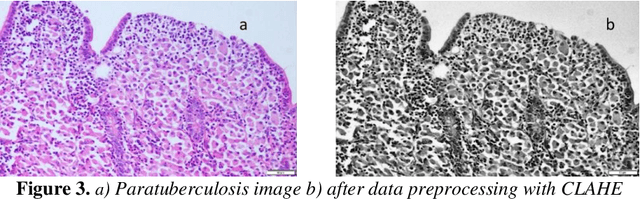
The aim of this study is to propose an alternative and hybrid solution method for diagnosing the disease from histopathology images taken from animals with paratuberculosis and intact intestine. In detail, the hybrid method is based on using both image processing and deep learning for better results. Reliable disease detection from histo-pathology images is known as an open problem in medical image processing and alternative solutions need to be developed. In this context, 520 histopathology images were collected in a joint study with Burdur Mehmet Akif Ersoy University, Faculty of Veterinary Medicine, and Department of Pathology. Manually detecting and interpreting these images requires expertise and a lot of processing time. For this reason, veterinarians, especially newly recruited physicians, have a great need for imaging and computer vision systems in the development of detection and treatment methods for this disease. The proposed solution method in this study is to use the CLAHE method and image processing together. After this preprocessing, the diagnosis is made by classifying a convolutional neural network sup-ported by the VGG-16 architecture. This method uses completely original dataset images. Two types of systems were applied for the evaluation parameters. While the F1 Score was 93% in the method classified without data preprocessing, it was 98% in the method that was preprocessed with the CLAHE method.
Boosting Modern and Historical Handwritten Text Recognition with Deformable Convolutions
Aug 17, 2022Handwritten Text Recognition (HTR) in free-layout pages is a challenging image understanding task that can provide a relevant boost to the digitization of handwritten documents and reuse of their content. The task becomes even more challenging when dealing with historical documents due to the variability of the writing style and degradation of the page quality. State-of-the-art HTR approaches typically couple recurrent structures for sequence modeling with Convolutional Neural Networks for visual feature extraction. Since convolutional kernels are defined on fixed grids and focus on all input pixels independently while moving over the input image, this strategy disregards the fact that handwritten characters can vary in shape, scale, and orientation even within the same document and that the ink pixels are more relevant than the background ones. To cope with these specific HTR difficulties, we propose to adopt deformable convolutions, which can deform depending on the input at hand and better adapt to the geometric variations of the text. We design two deformable architectures and conduct extensive experiments on both modern and historical datasets. Experimental results confirm the suitability of deformable convolutions for the HTR task.