 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
TransNorm: Transformer Provides a Strong Spatial Normalization Mechanism for a Deep Segmentation Model
Jul 27, 2022
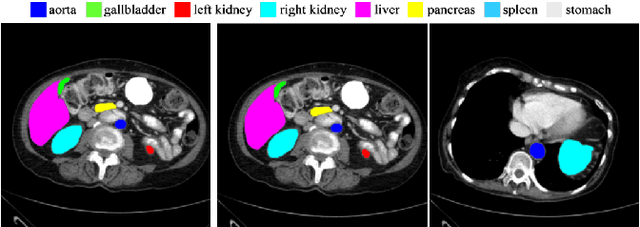

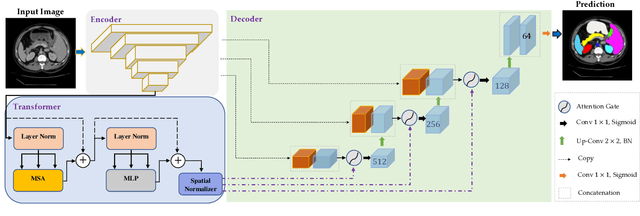
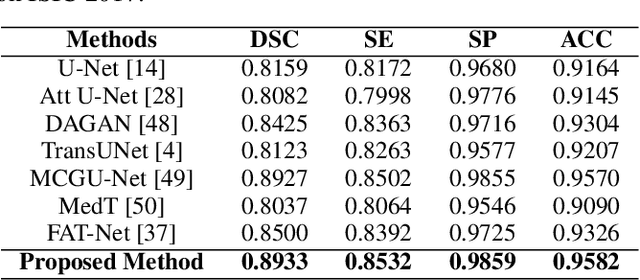
In the past few years, convolutional neural networks (CNNs), particularly U-Net, have been the prevailing technique in the medical image processing era. Specifically, the seminal U-Net, as well as its alternatives, have successfully managed to address a wide variety of medical image segmentation tasks. However, these architectures are intrinsically imperfect as they fail to exhibit long-range interactions and spatial dependencies leading to a severe performance drop in the segmentation of medical images with variable shapes and structures. Transformers, preliminary proposed for sequence-to-sequence prediction, have arisen as surrogate architectures to precisely model global information assisted by the self-attention mechanism. Despite being feasibly designed, utilizing a pure Transformer for image segmentation purposes can result in limited localization capacity stemming from inadequate low-level features. Thus, a line of research strives to design robust variants of Transformer-based U-Net. In this paper, we propose Trans-Norm, a novel deep segmentation framework which concomitantly consolidates a Transformer module into both encoder and skip-connections of the standard U-Net. We argue that the expedient design of skip-connections can be crucial for accurate segmentation as it can assist in feature fusion between the expanding and contracting paths. In this respect, we derive a Spatial Normalization mechanism from the Transformer module to adaptively recalibrate the skip connection path. Extensive experiments across three typical tasks for medical image segmentation demonstrate the effectiveness of TransNorm. The codes and trained models are publicly available at https://github.com/rezazad68/transnorm.
Zero-Shot Image-to-Text Generation for Visual-Semantic Arithmetic
Nov 29, 2021
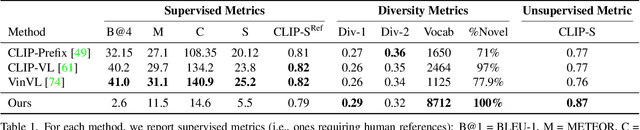
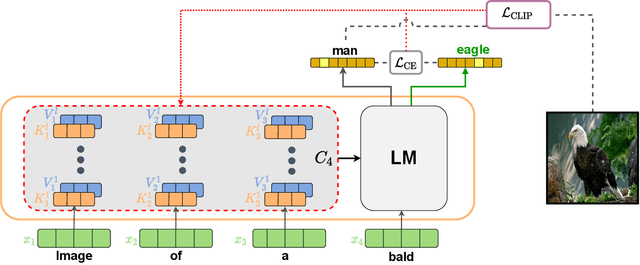

Recent text-to-image matching models apply contrastive learning to large corpora of uncurated pairs of images and sentences. While such models can provide a powerful score for matching and subsequent zero-shot tasks, they are not capable of generating caption given an image. In this work, we repurpose such models to generate a descriptive text given an image at inference time, without any further training or tuning step. This is done by combining the visual-semantic model with a large language model, benefiting from the knowledge in both web-scale models. The resulting captions are much less restrictive than those obtained by supervised captioning methods. Moreover, as a zero-shot learning method, it is extremely flexible and we demonstrate its ability to perform image arithmetic in which the inputs can be either images or text and the output is a sentence. This enables novel high-level vision capabilities such as comparing two images or solving visual analogy tests.
ConMatch: Semi-Supervised Learning with Confidence-Guided Consistency Regularization
Aug 18, 2022
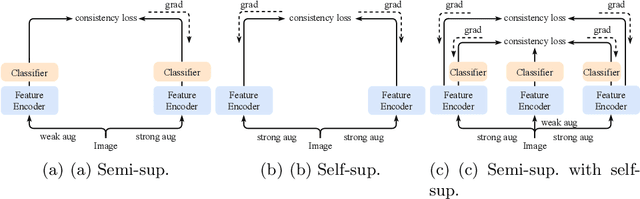
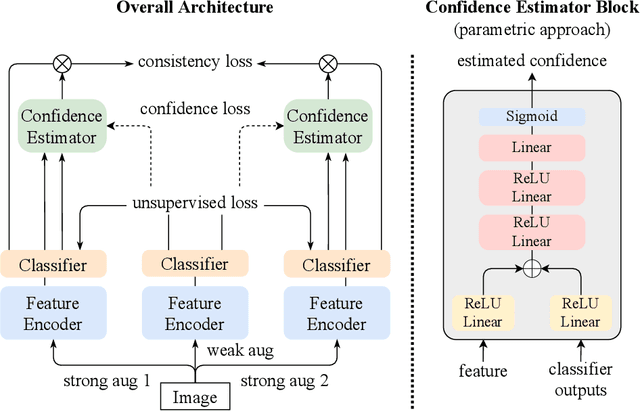
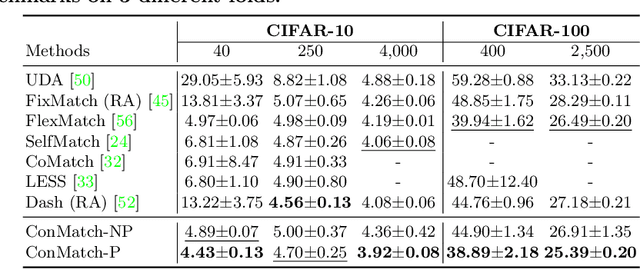
We present a novel semi-supervised learning framework that intelligently leverages the consistency regularization between the model's predictions from two strongly-augmented views of an image, weighted by a confidence of pseudo-label, dubbed ConMatch. While the latest semi-supervised learning methods use weakly- and strongly-augmented views of an image to define a directional consistency loss, how to define such direction for the consistency regularization between two strongly-augmented views remains unexplored. To account for this, we present novel confidence measures for pseudo-labels from strongly-augmented views by means of weakly-augmented view as an anchor in non-parametric and parametric approaches. Especially, in parametric approach, we present, for the first time, to learn the confidence of pseudo-label within the networks, which is learned with backbone model in an end-to-end manner. In addition, we also present a stage-wise training to boost the convergence of training. When incorporated in existing semi-supervised learners, ConMatch consistently boosts the performance. We conduct experiments to demonstrate the effectiveness of our ConMatch over the latest methods and provide extensive ablation studies. Code has been made publicly available at https://github.com/JiwonCocoder/ConMatch.
Multi-task Learning for Monocular Depth and Defocus Estimations with Real Images
Aug 21, 2022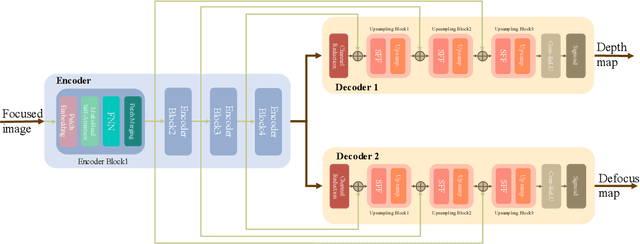
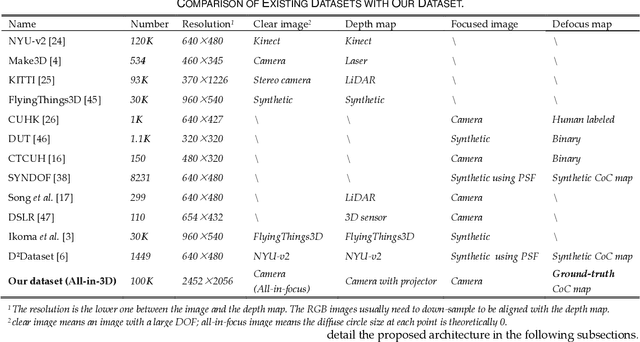
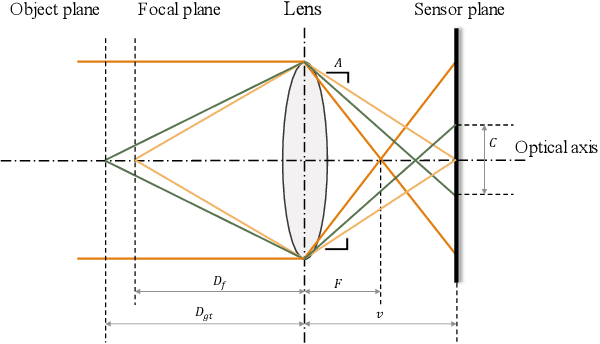

Monocular depth estimation and defocus estimation are two fundamental tasks in computer vision. Most existing methods treat depth estimation and defocus estimation as two separate tasks, ignoring the strong connection between them. In this work, we propose a multi-task learning network consisting of an encoder with two decoders to estimate the depth and defocus map from a single focused image. Through the multi-task network, the depth estimation facilitates the defocus estimation to get better results in the weak texture region and the defocus estimation facilitates the depth estimation by the strong physical connection between the two maps. We set up a dataset (named ALL-in-3D dataset) which is the first all-real image dataset consisting of 100K sets of all-in-focus images, focused images with focus depth, depth maps, and defocus maps. It enables the network to learn features and solid physical connections between the depth and real defocus images. Experiments demonstrate that the network learns more solid features from the real focused images than the synthetic focused images. Benefiting from this multi-task structure where different tasks facilitate each other, our depth and defocus estimations achieve significantly better performance than other state-of-art algorithms. The code and dataset will be publicly available at https://github.com/cubhe/MDDNet.
No way to crop: On robust image crop localization
Oct 12, 2021
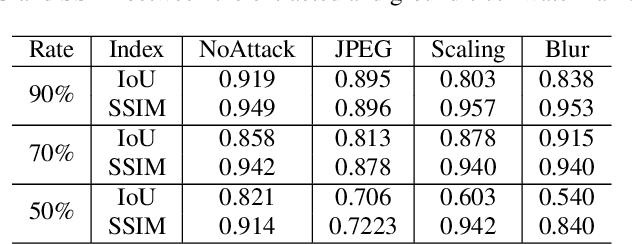
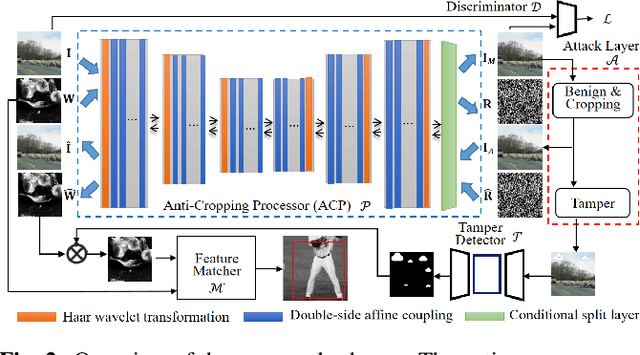
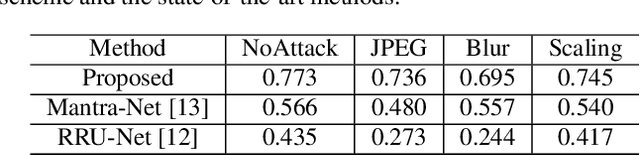
Previous image forensics schemes for crop detection are only limited on predicting whether an image has been cropped. This paper presents a novel scheme for image crop localization using robust watermarking. We further extend our scheme to detect tampering attack on the attacked image. We demonstrate that our scheme is the first to provide high-accuracy and robust image crop localization. Besides, the accuracy of tamper detection is comparable to many state-of-the-art methods.
Using Unmanned Aerial Systems (UAS) for Assessing and Monitoring Fall Hazard Prevention Systems in High-rise Building Projects
Sep 27, 2022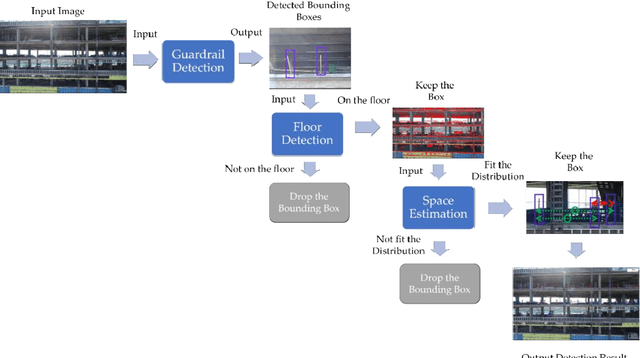


This study develops a framework for unmanned aerial systems (UASs) to monitor fall hazard prevention systems near unprotected edges and openings in high-rise building projects. A three-step machine-learning-based framework was developed and tested to detect guardrail posts from the images captured by UAS. First, a guardrail detector was trained to localize the candidate locations of posts supporting the guardrail. Since images were used in this process collected from an actual job site, several false detections were identified. Therefore, additional constraints were introduced in the following steps to filter out false detections. Second, the research team applied a horizontal line detector to the image to properly detect floors and remove the detections that were not close to the floors. Finally, since the guardrail posts are installed with approximately normal distribution between each post, the space between them was estimated and used to find the most likely distance between the two posts. The research team used various combinations of the developed approaches to monitor guardrail systems in the captured images from a high-rise building project. Comparing the precision and recall metrics indicated that the cascade classifier achieves better performance with floor detection and guardrail spacing estimation. The research outcomes illustrate that the proposed guardrail recognition system can improve the assessment of guardrails and facilitate the safety engineer's task of identifying fall hazards in high-rise building projects.
Object Detection in Aerial Images with Uncertainty-Aware Graph Network
Aug 24, 2022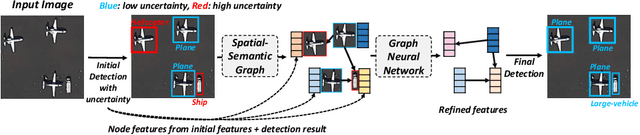
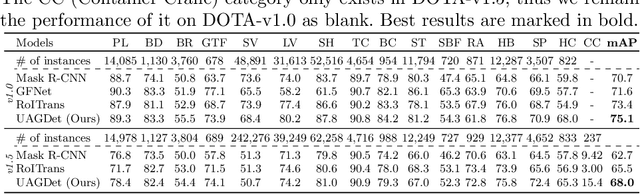


In this work, we propose a novel uncertainty-aware object detection framework with a structured-graph, where nodes and edges are denoted by objects and their spatial-semantic similarities, respectively. Specifically, we aim to consider relationships among objects for effectively contextualizing them. To achieve this, we first detect objects and then measure their semantic and spatial distances to construct an object graph, which is then represented by a graph neural network (GNN) for refining visual CNN features for objects. However, refining CNN features and detection results of every object are inefficient and may not be necessary, as that include correct predictions with low uncertainties. Therefore, we propose to handle uncertain objects by not only transferring the representation from certain objects (sources) to uncertain objects (targets) over the directed graph, but also improving CNN features only on objects regarded as uncertain with their representational outputs from the GNN. Furthermore, we calculate a training loss by giving larger weights on uncertain objects, to concentrate on improving uncertain object predictions while maintaining high performances on certain objects. We refer to our model as Uncertainty-Aware Graph network for object DETection (UAGDet). We then experimentally validate ours on the challenging large-scale aerial image dataset, namely DOTA, that consists of lots of objects with small to large sizes in an image, on which ours improves the performance of the existing object detection network.
Continual Learning for Tumor Classification in Histopathology Images
Aug 07, 2022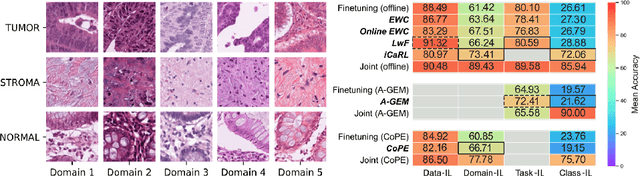
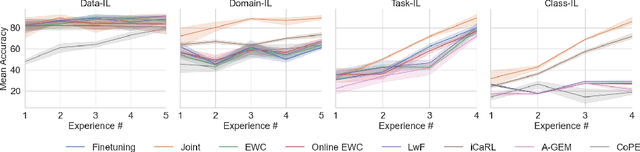
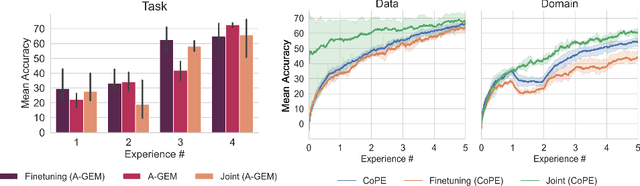
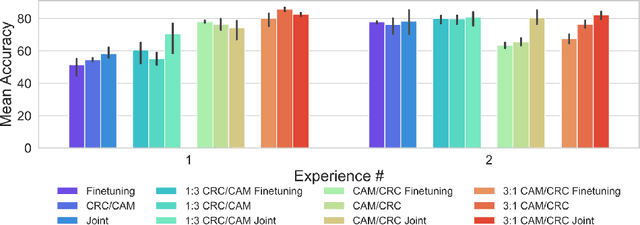
Recent years have seen great advancements in the development of deep learning models for histopathology image analysis in digital pathology applications, evidenced by the increasingly common deployment of these models in both research and clinical settings. Although such models have shown unprecedented performance in solving fundamental computational tasks in DP applications, they suffer from catastrophic forgetting when adapted to unseen data with transfer learning. With an increasing need for deep learning models to handle ever changing data distributions, including evolving patient population and new diagnosis assays, continual learning models that alleviate model forgetting need to be introduced in DP based analysis. However, to our best knowledge, there is no systematic study of such models for DP-specific applications. Here, we propose CL scenarios in DP settings, where histopathology image data from different sources/distributions arrive sequentially, the knowledge of which is integrated into a single model without training all the data from scratch. We then established an augmented dataset for colorectal cancer H&E classification to simulate shifts of image appearance and evaluated CL model performance in the proposed CL scenarios. We leveraged a breast tumor H&E dataset along with the colorectal cancer to evaluate CL from different tumor types. In addition, we evaluated CL methods in an online few-shot setting under the constraints of annotation and computational resources. We revealed promising results of CL in DP applications, potentially paving the way for application of these methods in clinical practice.
ScaleFace: Uncertainty-aware Deep Metric Learning
Sep 12, 2022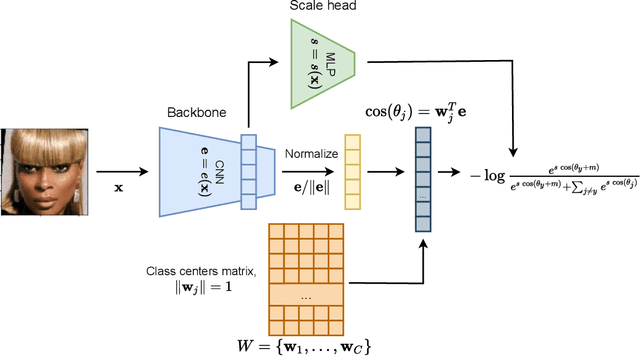
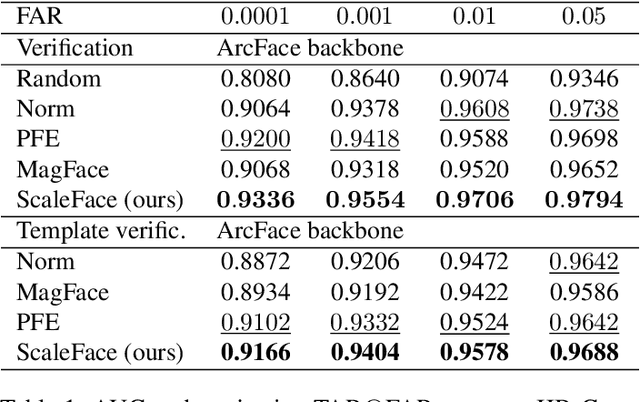

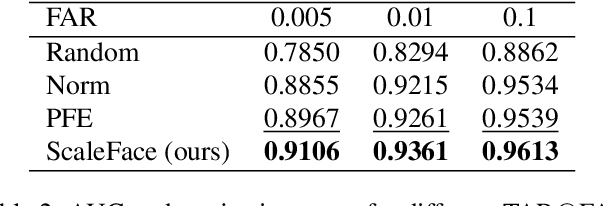
The performance of modern deep learning-based systems dramatically depends on the quality of input objects. For example, face recognition quality would be lower for blurry or corrupted inputs. However, it is hard to predict the influence of input quality on the resulting accuracy in more complex scenarios. We propose an approach for deep metric learning that allows direct estimation of the uncertainty with almost no additional computational cost. The developed \textit{ScaleFace} algorithm uses trainable scale values that modify similarities in the space of embeddings. These input-dependent scale values represent a measure of confidence in the recognition result, thus allowing uncertainty estimation. We provide comprehensive experiments on face recognition tasks that show the superior performance of ScaleFace compared to other uncertainty-aware face recognition approaches. We also extend the results to the task of text-to-image retrieval showing that the proposed approach beats the competitors with significant margin.
Towards Better Dermoscopic Image Feature Representation Learning for Melanoma Classification
Jul 15, 2022Deep learning-based melanoma classification with dermoscopic images has recently shown great potential in automatic early-stage melanoma diagnosis. However, limited by the significant data imbalance and obvious extraneous artifacts, i.e., the hair and ruler markings, discriminative feature extraction from dermoscopic images is very challenging. In this study, we seek to resolve these problems respectively towards better representation learning for lesion features. Specifically, a GAN-based data augmentation (GDA) strategy is adapted to generate synthetic melanoma-positive images, in conjunction with the proposed implicit hair denoising (IHD) strategy. Wherein the hair-related representations are implicitly disentangled via an auxiliary classifier network and reversely sent to the melanoma-feature extraction backbone for better melanoma-specific representation learning. Furthermore, to train the IHD module, the hair noises are additionally labeled on the ISIC2020 dataset, making it the first large-scale dermoscopic dataset with annotation of hair-like artifacts. Extensive experiments demonstrate the superiority of the proposed framework as well as the effectiveness of each component. The improved dataset publicly avaliable at https://github.com/kirtsy/DermoscopicDataset.