 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Neural Correspondence Field for Object Pose Estimation
Jul 30, 2022

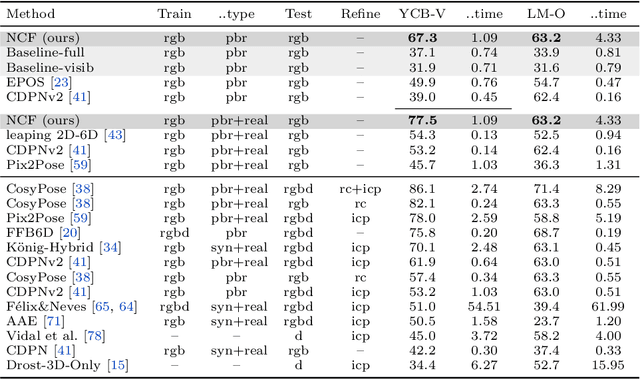
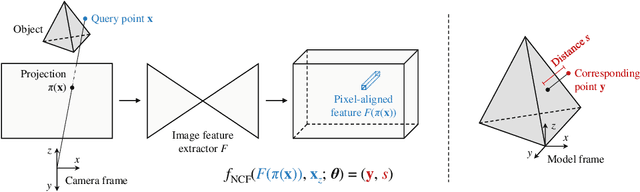
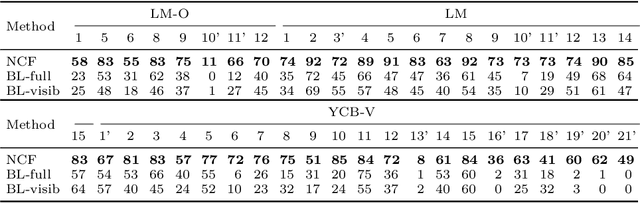
We propose a method for estimating the 6DoF pose of a rigid object with an available 3D model from a single RGB image. Unlike classical correspondence-based methods which predict 3D object coordinates at pixels of the input image, the proposed method predicts 3D object coordinates at 3D query points sampled in the camera frustum. The move from pixels to 3D points, which is inspired by recent PIFu-style methods for 3D reconstruction, enables reasoning about the whole object, including its (self-)occluded parts. For a 3D query point associated with a pixel-aligned image feature, we train a fully-connected neural network to predict: (i) the corresponding 3D object coordinates, and (ii) the signed distance to the object surface, with the first defined only for query points in the surface vicinity. We call the mapping realized by this network as Neural Correspondence Field. The object pose is then robustly estimated from the predicted 3D-3D correspondences by the Kabsch-RANSAC algorithm. The proposed method achieves state-of-the-art results on three BOP datasets and is shown superior especially in challenging cases with occlusion. The project website is at: linhuang17.github.io/NCF.
A model-agnostic approach for generating Saliency Maps to explain inferred decisions of Deep Learning Models
Sep 27, 2022
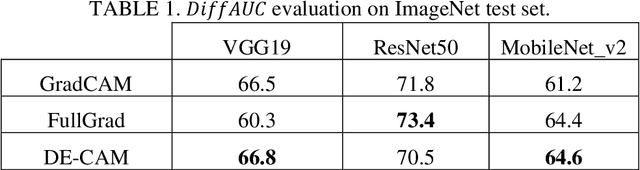

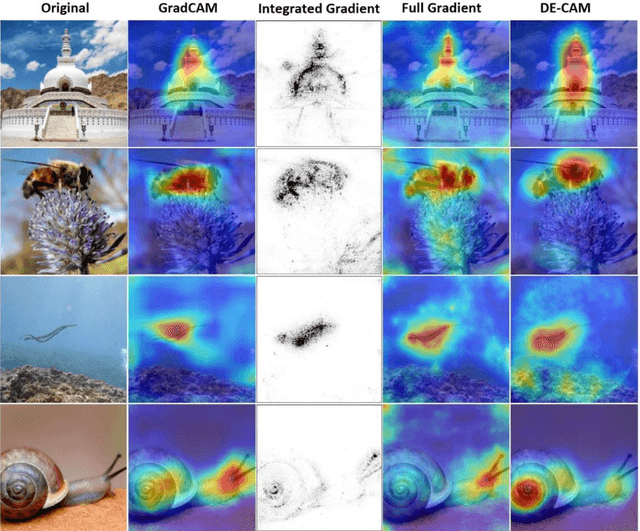
The widespread use of black-box AI models has raised the need for algorithms and methods that explain the decisions made by these models. In recent years, the AI research community is increasingly interested in models' explainability since black-box models take over more and more complicated and challenging tasks. Explainability becomes critical considering the dominance of deep learning techniques for a wide range of applications, including but not limited to computer vision. In the direction of understanding the inference process of deep learning models, many methods that provide human comprehensible evidence for the decisions of AI models have been developed, with the vast majority relying their operation on having access to the internal architecture and parameters of these models (e.g., the weights of neural networks). We propose a model-agnostic method for generating saliency maps that has access only to the output of the model and does not require additional information such as gradients. We use Differential Evolution (DE) to identify which image pixels are the most influential in a model's decision-making process and produce class activation maps (CAMs) whose quality is comparable to the quality of CAMs created with model-specific algorithms. DE-CAM achieves good performance without requiring access to the internal details of the model's architecture at the cost of more computational complexity.
CrossDTR: Cross-view and Depth-guided Transformers for 3D Object Detection
Sep 27, 2022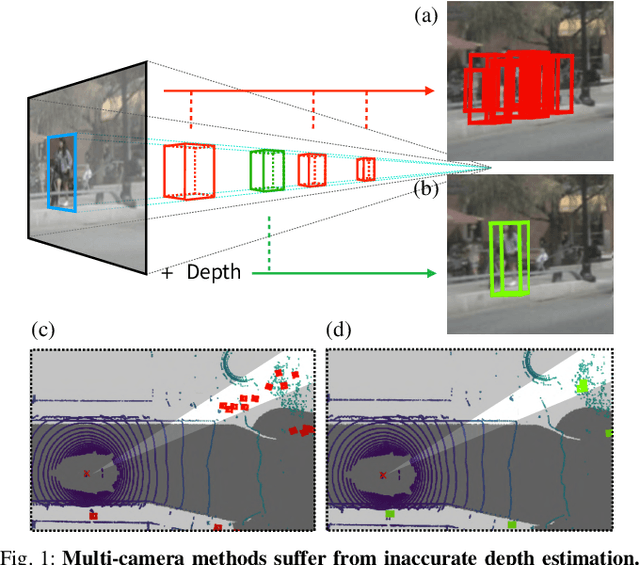
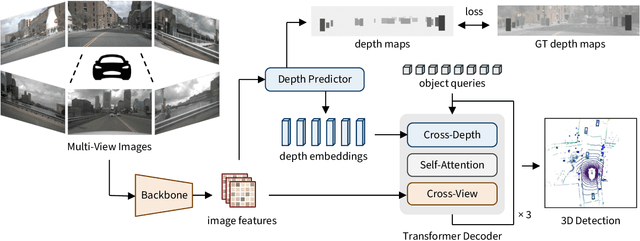
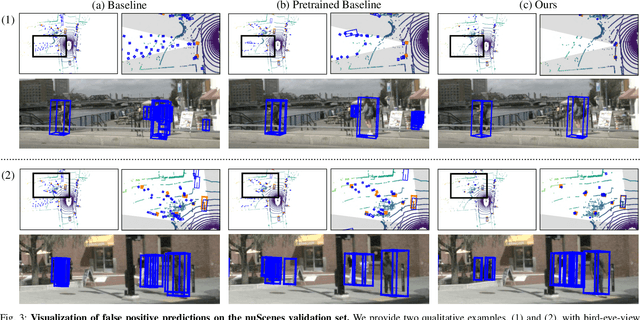
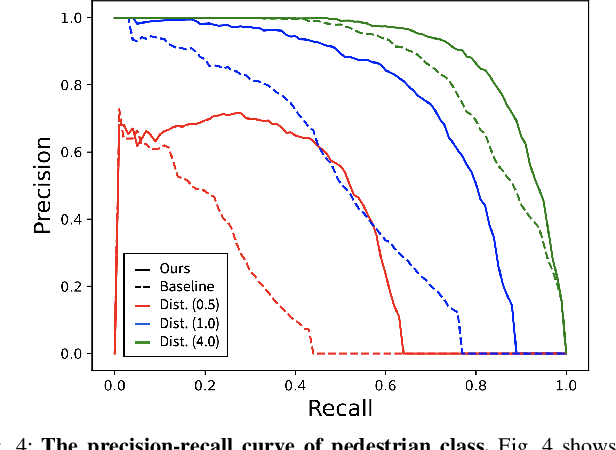
To achieve accurate 3D object detection at a low cost for autonomous driving, many multi-camera methods have been proposed and solved the occlusion problem of monocular approaches. However, due to the lack of accurate estimated depth, existing multi-camera methods often generate multiple bounding boxes along a ray of depth direction for difficult small objects such as pedestrians, resulting in an extremely low recall. Furthermore, directly applying depth prediction modules to existing multi-camera methods, generally composed of large network architectures, cannot meet the real-time requirements of self-driving applications. To address these issues, we propose Cross-view and Depth-guided Transformers for 3D Object Detection, CrossDTR. First, our lightweight depth predictor is designed to produce precise object-wise sparse depth maps and low-dimensional depth embeddings without extra depth datasets during supervision. Second, a cross-view depth-guided transformer is developed to fuse the depth embeddings as well as image features from cameras of different views and generate 3D bounding boxes. Extensive experiments demonstrated that our method hugely surpassed existing multi-camera methods by 10 percent in pedestrian detection and about 3 percent in overall mAP and NDS metrics. Also, computational analyses showed that our method is 5 times faster than prior approaches. Our codes will be made publicly available at https://github.com/sty61010/CrossDTR.
Capturing and Animation of Body and Clothing from Monocular Video
Oct 04, 2022
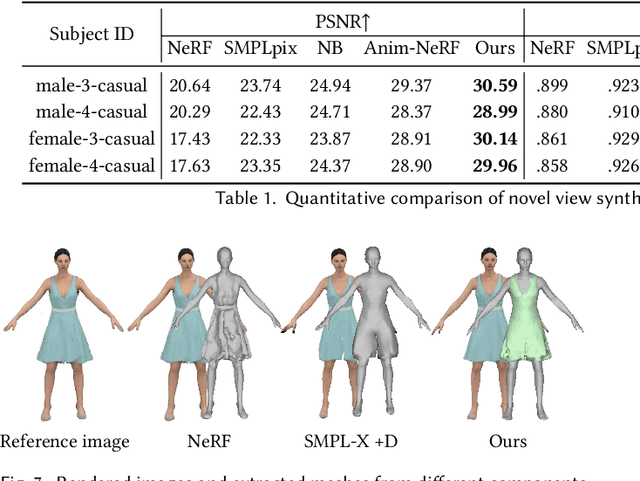
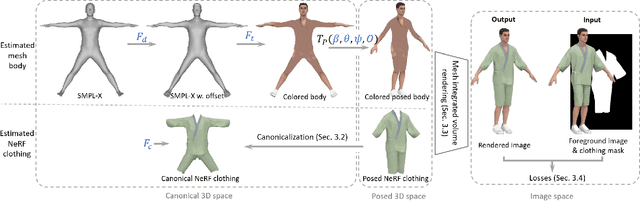
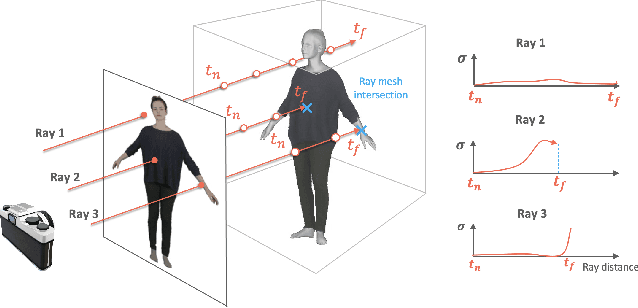
While recent work has shown progress on extracting clothed 3D human avatars from a single image, video, or a set of 3D scans, several limitations remain. Most methods use a holistic representation to jointly model the body and clothing, which means that the clothing and body cannot be separated for applications like virtual try-on. Other methods separately model the body and clothing, but they require training from a large set of 3D clothed human meshes obtained from 3D/4D scanners or physics simulations. Our insight is that the body and clothing have different modeling requirements. While the body is well represented by a mesh-based parametric 3D model, implicit representations and neural radiance fields are better suited to capturing the large variety in shape and appearance present in clothing. Building on this insight, we propose SCARF (Segmented Clothed Avatar Radiance Field), a hybrid model combining a mesh-based body with a neural radiance field. Integrating the mesh into the volumetric rendering in combination with a differentiable rasterizer enables us to optimize SCARF directly from monocular videos, without any 3D supervision. The hybrid modeling enables SCARF to (i) animate the clothed body avatar by changing body poses (including hand articulation and facial expressions), (ii) synthesize novel views of the avatar, and (iii) transfer clothing between avatars in virtual try-on applications. We demonstrate that SCARF reconstructs clothing with higher visual quality than existing methods, that the clothing deforms with changing body pose and body shape, and that clothing can be successfully transferred between avatars of different subjects. The code and models are available at https://github.com/YadiraF/SCARF.
FedMed-GAN: Federated Multi-Modal Unsupervised Brain Image Synthesis
Jan 22, 2022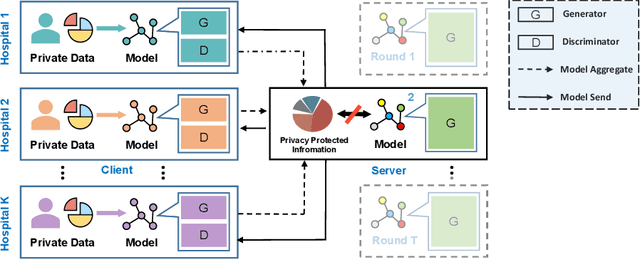

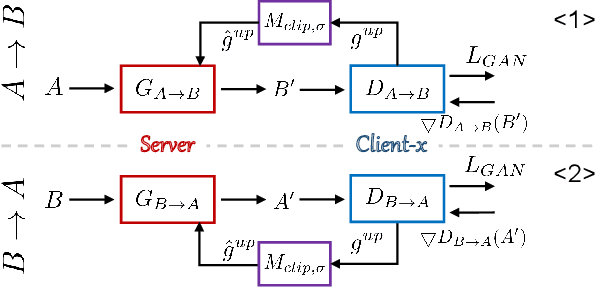
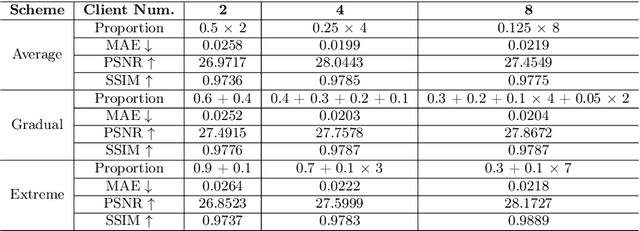
Utilizing the paired multi-modal neuroimaging data has been proved to be effective to investigate human cognitive activities and certain pathologies. However, it is not practical to obtain the full set of paired neuroimaging data centrally since the collection faces several constraints, e.g., high examination costs, long acquisition time, and even image corruption. In addition, most of the paired neuroimaging data are dispersed into different medical institutions and cannot group together for centralized training considering the privacy issues. Under the circumstance, there is a clear need to launch federated learning and facilitate the integration of other unpaired data from different hospitals or data owners. In this paper, we build up a new benchmark for federated multi-modal unsupervised brain image synthesis (termed as FedMed-GAN) to bridge the gap between federated learning and medical GAN. Moreover, based on the similarity of edge information across multi-modal neuroimaging data, we propose a novel edge loss to solve the generative mode collapse issue of FedMed-GAN and mitigate the performance drop resulting from differential privacy. Compared with the state-of-the-art method shown in our built benchmark, our novel edge loss could significantly speed up the generator convergence rate without sacrificing performance under different unpaired data distribution settings.
DiscrimLoss: A Universal Loss for Hard Samples and Incorrect Samples Discrimination
Aug 21, 2022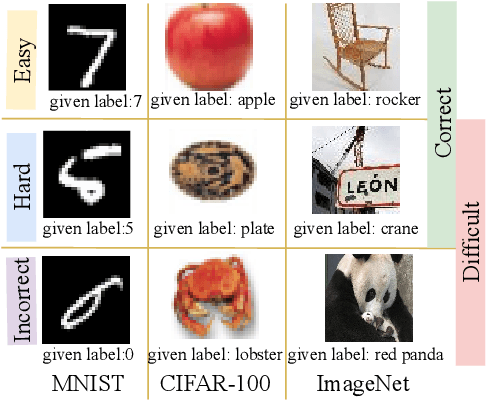
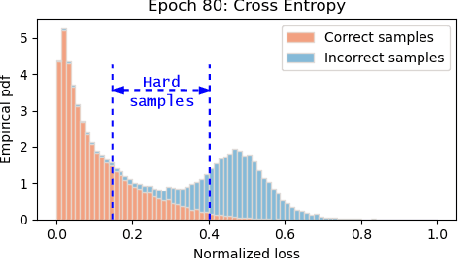
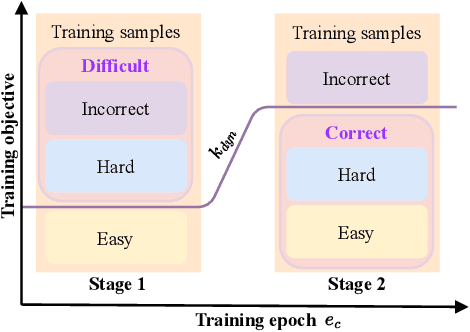
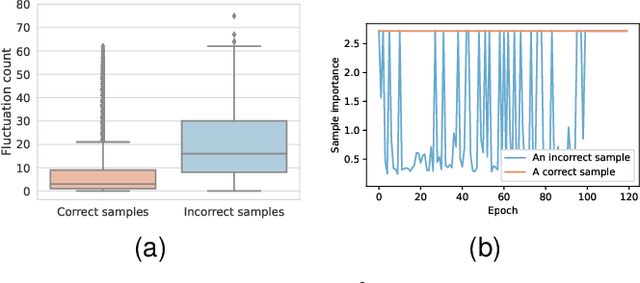
Given data with label noise (i.e., incorrect data), deep neural networks would gradually memorize the label noise and impair model performance. To relieve this issue, curriculum learning is proposed to improve model performance and generalization by ordering training samples in a meaningful (e.g., easy to hard) sequence. Previous work takes incorrect samples as generic hard ones without discriminating between hard samples (i.e., hard samples in correct data) and incorrect samples. Indeed, a model should learn from hard samples to promote generalization rather than overfit to incorrect ones. In this paper, we address this problem by appending a novel loss function DiscrimLoss, on top of the existing task loss. Its main effect is to automatically and stably estimate the importance of easy samples and difficult samples (including hard and incorrect samples) at the early stages of training to improve the model performance. Then, during the following stages, DiscrimLoss is dedicated to discriminating between hard and incorrect samples to improve the model generalization. Such a training strategy can be formulated dynamically in a self-supervised manner, effectively mimicking the main principle of curriculum learning. Experiments on image classification, image regression, text sequence regression, and event relation reasoning demonstrate the versatility and effectiveness of our method, particularly in the presence of diversified noise levels.
Generative Adversarial Networks and Other Generative Models
Jul 08, 2022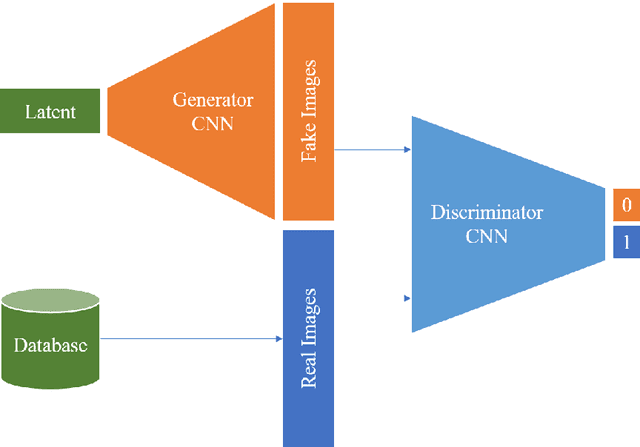
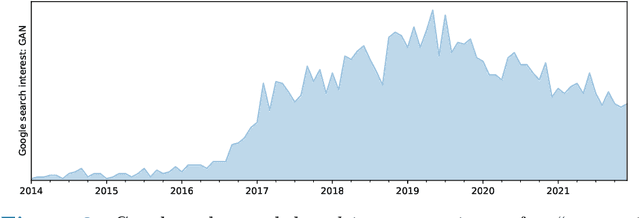
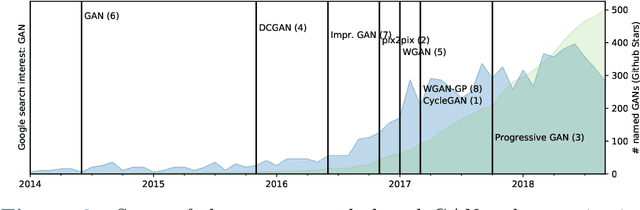
Generative networks are fundamentally different in their aim and methods compared to CNNs for classification, segmentation, or object detection. They have initially not been meant to be an image analysis tool, but to produce naturally looking images. The adversarial training paradigm has been proposed to stabilize generative methods, and has proven to be highly successful -- though by no means from the first attempt. This chapter gives a basic introduction into the motivation for Generative Adversarial Networks (GANs) and traces the path of their success by abstracting the basic task and working mechanism, and deriving the difficulty of early practical approaches. Methods for a more stable training will be shown, and also typical signs for poor convergence and their reasons. Though this chapter focuses on GANs that are meant for image generation and image analysis, the adversarial training paradigm itself is not specific to images, and also generalizes to tasks in image analysis. Examples of architectures for image semantic segmentation and abnormality detection will be acclaimed, before contrasting GANs with further generative modeling approaches lately entering the scene. This will allow a contextualized view on the limits but also benefits of GANs.
TransNorm: Transformer Provides a Strong Spatial Normalization Mechanism for a Deep Segmentation Model
Jul 27, 2022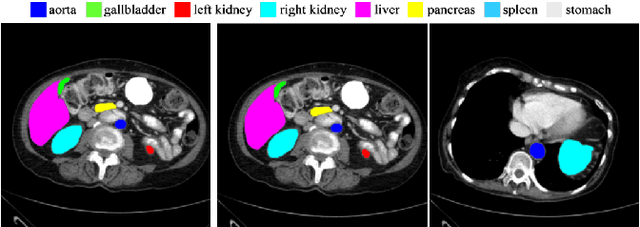

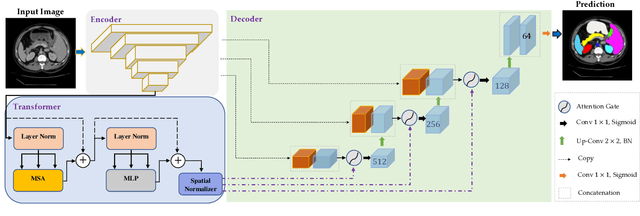
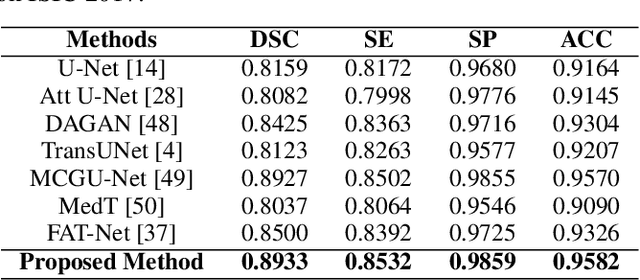
In the past few years, convolutional neural networks (CNNs), particularly U-Net, have been the prevailing technique in the medical image processing era. Specifically, the seminal U-Net, as well as its alternatives, have successfully managed to address a wide variety of medical image segmentation tasks. However, these architectures are intrinsically imperfect as they fail to exhibit long-range interactions and spatial dependencies leading to a severe performance drop in the segmentation of medical images with variable shapes and structures. Transformers, preliminary proposed for sequence-to-sequence prediction, have arisen as surrogate architectures to precisely model global information assisted by the self-attention mechanism. Despite being feasibly designed, utilizing a pure Transformer for image segmentation purposes can result in limited localization capacity stemming from inadequate low-level features. Thus, a line of research strives to design robust variants of Transformer-based U-Net. In this paper, we propose Trans-Norm, a novel deep segmentation framework which concomitantly consolidates a Transformer module into both encoder and skip-connections of the standard U-Net. We argue that the expedient design of skip-connections can be crucial for accurate segmentation as it can assist in feature fusion between the expanding and contracting paths. In this respect, we derive a Spatial Normalization mechanism from the Transformer module to adaptively recalibrate the skip connection path. Extensive experiments across three typical tasks for medical image segmentation demonstrate the effectiveness of TransNorm. The codes and trained models are publicly available at https://github.com/rezazad68/transnorm.
Learning with MISELBO: The Mixture Cookbook
Sep 30, 2022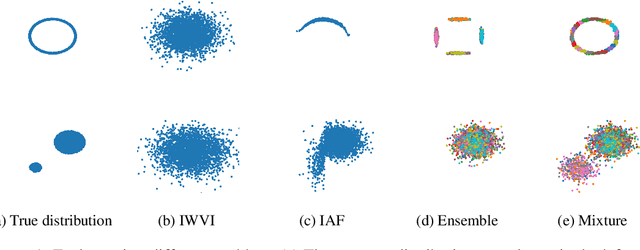
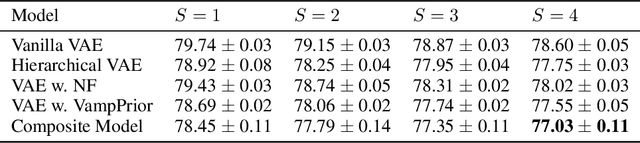

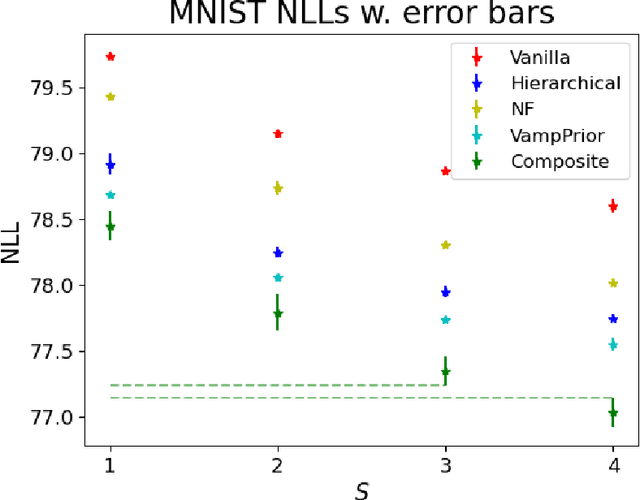
Mixture models in variational inference (VI) is an active field of research. Recent works have established their connection to multiple importance sampling (MIS) through the MISELBO and advanced the use of ensemble approximations for large-scale problems. However, as we show here, an independent learning of the ensemble components can lead to suboptimal diversity. Hence, we study the effect of instead using MISELBO as an objective function for learning mixtures, and we propose the first ever mixture of variational approximations for a normalizing flow-based hierarchical variational autoencoder (VAE) with VampPrior and a PixelCNN decoder network. Two major insights led to the construction of this novel composite model. First, mixture models have potential to be off-the-shelf tools for practitioners to obtain more flexible posterior approximations in VAEs. Therefore, we make them more accessible by demonstrating how to apply them to four popular architectures. Second, the mixture components cooperate in order to cover the target distribution while trying to maximize their diversity when MISELBO is the objective function. We explain this cooperative behavior by drawing a novel connection between VI and adaptive importance sampling. Finally, we demonstrate the superiority of the Mixture VAEs' learned feature representations on both image and single-cell transcriptome data, and obtain state-of-the-art results among VAE architectures in terms of negative log-likelihood on the MNIST and FashionMNIST datasets. Code available here: \url{https://github.com/Lagergren-Lab/MixtureVAEs}.
Viewpoint Planning based on Shape Completion for Fruit Mapping and Reconstruction
Sep 30, 2022
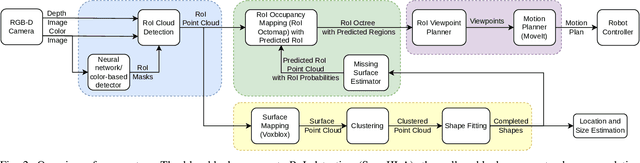
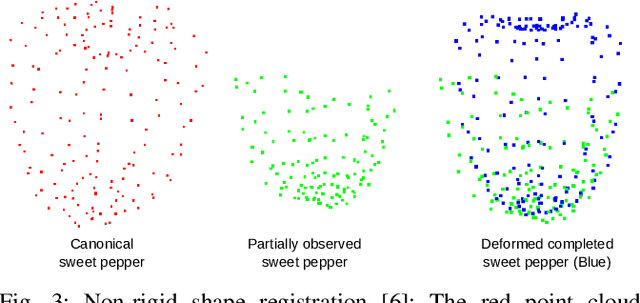
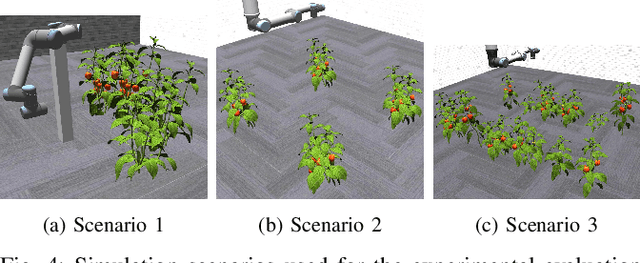
Robotic systems in agriculture do not only enable increasing automation of farming activities but also represent new challenges for robotics due to the unstructured environment and the non-rigid structures of crops. Especially, active perception for fruit mapping and harvesting is a difficult task since occlusions frequently occur and image segmentation provides only limited accuracy on the actual shape of the fruits. In this paper, we present a viewpoint planning approach that explictly uses the shape prediction from collected data to guide the sensor to view as yet unobserved parts of the fruits. We developed a novel pipeline for continuous interaction between prediction and observation to maximize the information gain about sweet pepper fruits. We adapted two different shape prediction approaches, namely parametric superellipsoid fitting and model based non-rigid latent space registration, and integrated them into our Region of Interest (RoI) viewpoint planner. Additionally, we used a new concept of viewpoint dissimilarity to aid the planner to select good viewpoints and for shortening the planning times. Our simulation experiments with a UR5e arm equipped with a Realsense L515 sensor provide a quantitative demonstration of the efficacy of our iterative shape completion based viewpoint planning. In comparative experiments with a state-of-the-art viewpoint planner, we demonstrate improvement not only in the estimation of the fruit sizes, but also in their reconstruction. Finally, we show the viability of our approach for mapping sweet peppers with a real robotic system in a commercial glasshouse.