 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Dynamic Prompt Learning via Policy Gradient for Semi-structured Mathematical Reasoning
Sep 29, 2022
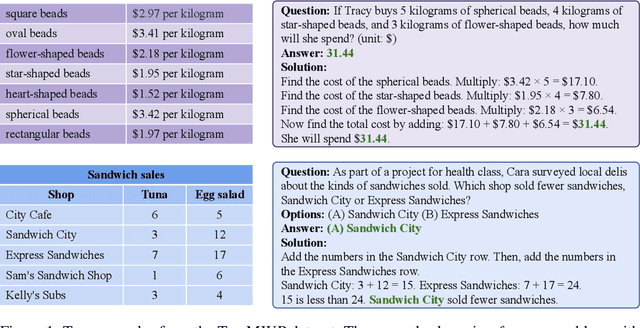
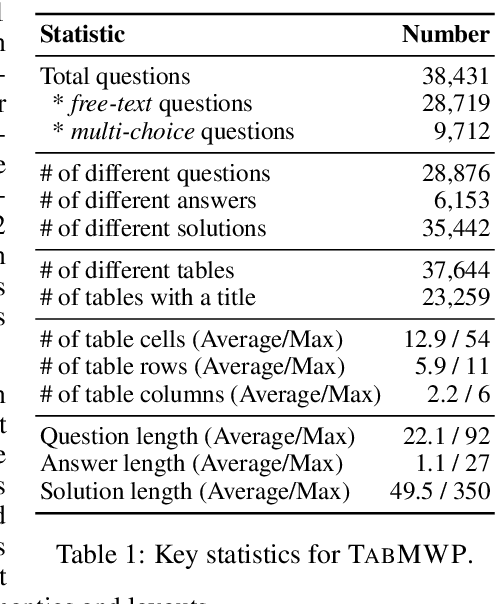
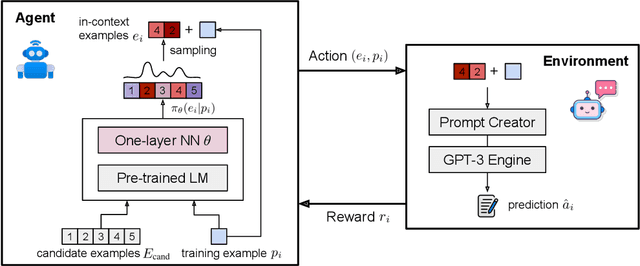
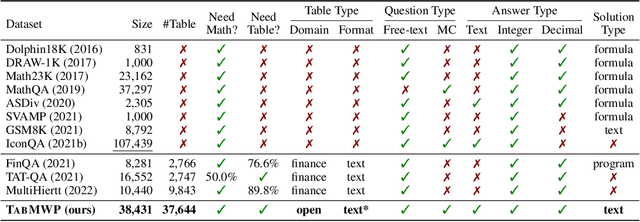
Mathematical reasoning, a core ability of human intelligence, presents unique challenges for machines in abstract thinking and logical reasoning. Recent large pre-trained language models such as GPT-3 have achieved remarkable progress on mathematical reasoning tasks written in text form, such as math word problems (MWP). However, it is unknown if the models can handle more complex problems that involve math reasoning over heterogeneous information, such as tabular data. To fill the gap, we present Tabular Math Word Problems (TabMWP), a new dataset containing 38,431 open-domain grade-level problems that require mathematical reasoning on both textual and tabular data. Each question in TabMWP is aligned with a tabular context, which is presented as an image, semi-structured text, and a structured table. There are two types of questions: free-text and multi-choice, and each problem is annotated with gold solutions to reveal the multi-step reasoning process. We evaluate different pre-trained models on TabMWP, including the GPT-3 model in a few-shot setting. As earlier studies suggest, since few-shot GPT-3 relies on the selection of in-context examples, its performance is unstable and can degrade to near chance. The unstable issue is more severe when handling complex problems like TabMWP. To mitigate this, we further propose a novel approach, PromptPG, which utilizes policy gradient to learn to select in-context examples from a small amount of training data and then constructs the corresponding prompt for the test example. Experimental results show that our method outperforms the best baseline by 5.31% on the accuracy metric and reduces the prediction variance significantly compared to random selection, which verifies its effectiveness in the selection of in-context examples.
CR-FIQA: Face Image Quality Assessment by Learning Sample Relative Classifiability
Dec 13, 2021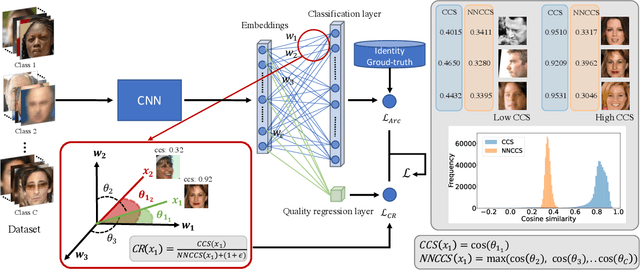
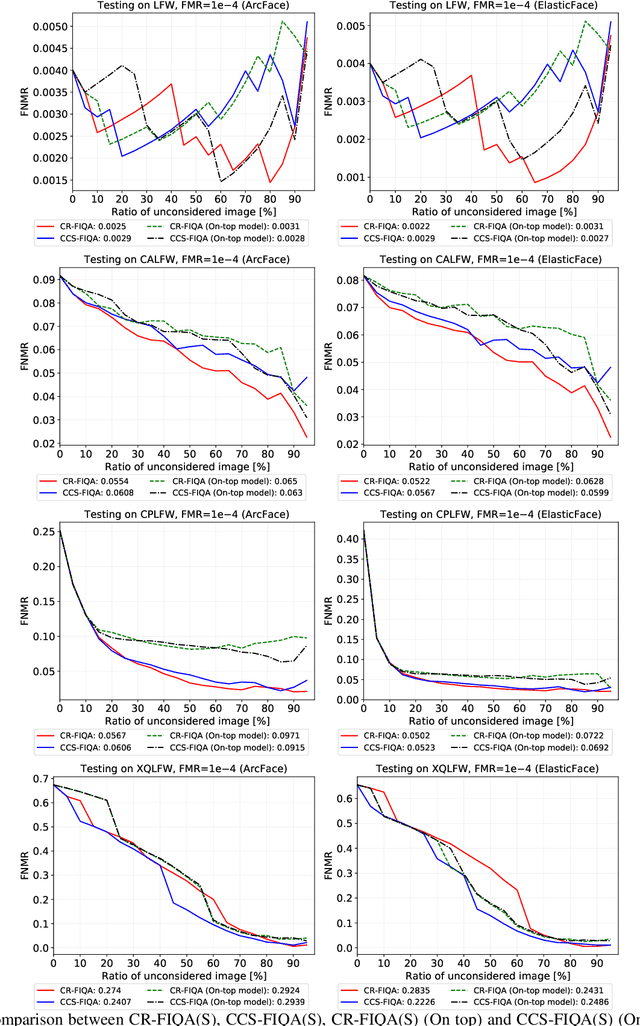
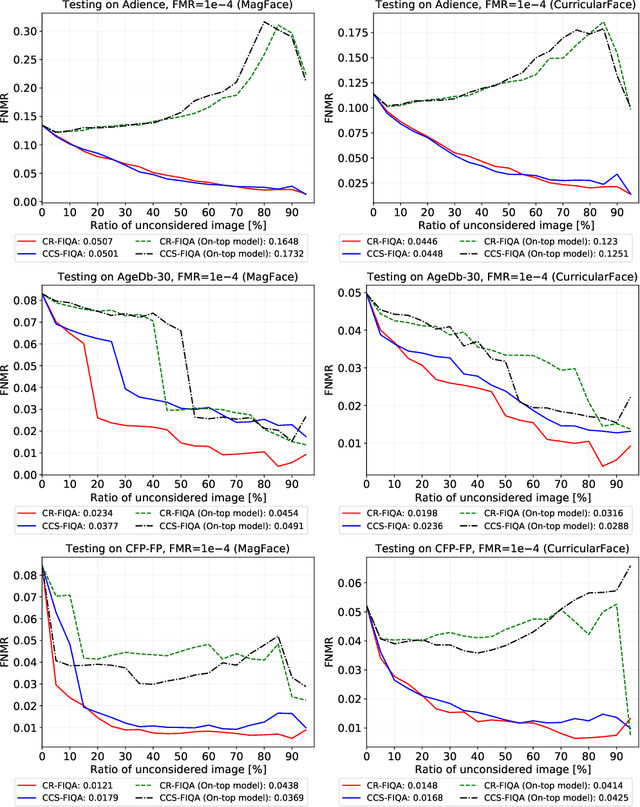
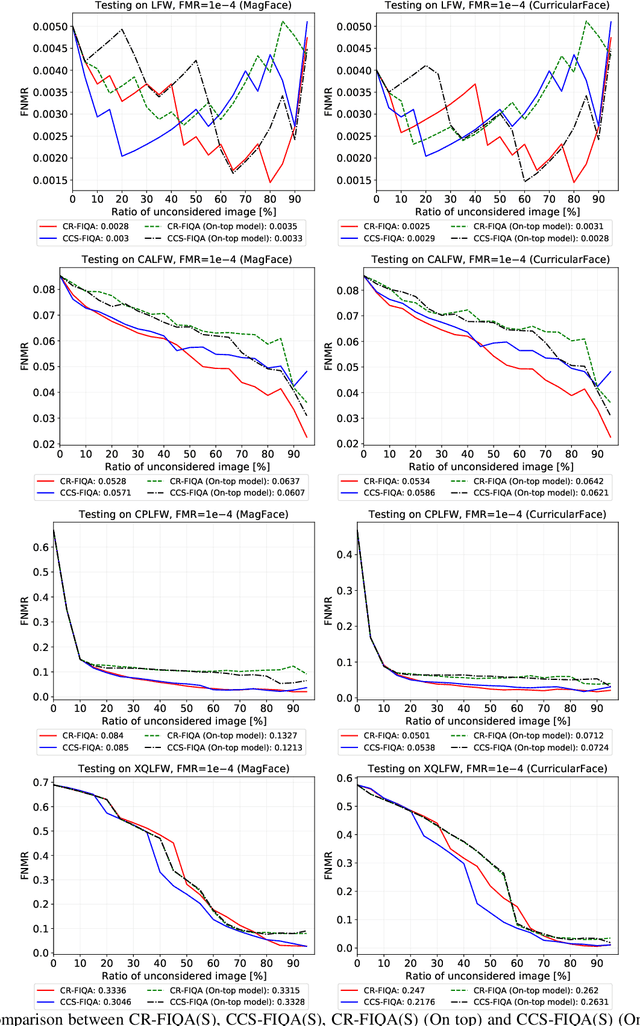
The quality of face images significantly influences the performance of underlying face recognition algorithms. Face image quality assessment (FIQA) estimates the utility of the captured image in achieving reliable and accurate recognition performance. In this work, we propose a novel learning paradigm that learns internal network observations during the training process. Based on that, our proposed CR-FIQA uses this paradigm to estimate the face image quality of a sample by predicting its relative classifiability. This classifiability is measured based on the allocation of the training sample feature representation in angular space with respect to its class center and the nearest negative class center. We experimentally illustrate the correlation between the face image quality and the sample relative classifiability. As such property is only observable for the training dataset, we propose to learn this property from the training dataset and utilize it to predict the quality measure on unseen samples. This training is performed simultaneously while optimizing the class centers by an angular margin penalty-based softmax loss used for face recognition model training. Through extensive evaluation experiments on eight benchmarks and four face recognition models, we demonstrate the superiority of our proposed CR-FIQA over state-of-the-art (SOTA) FIQA algorithms.
Multi-Grained Angle Representation for Remote Sensing Object Detection
Sep 07, 2022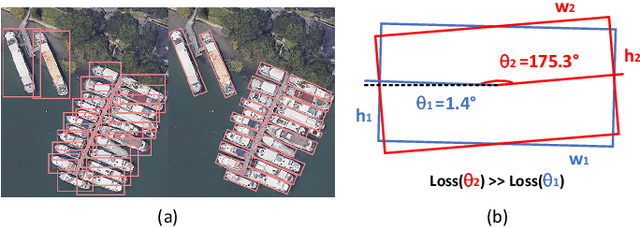
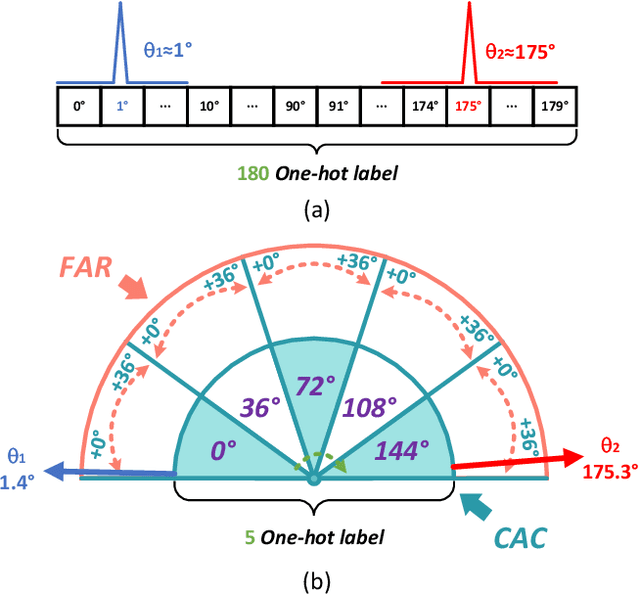
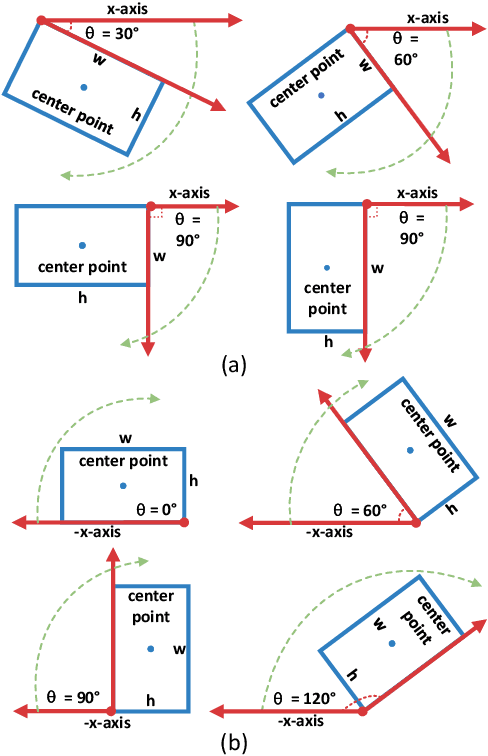
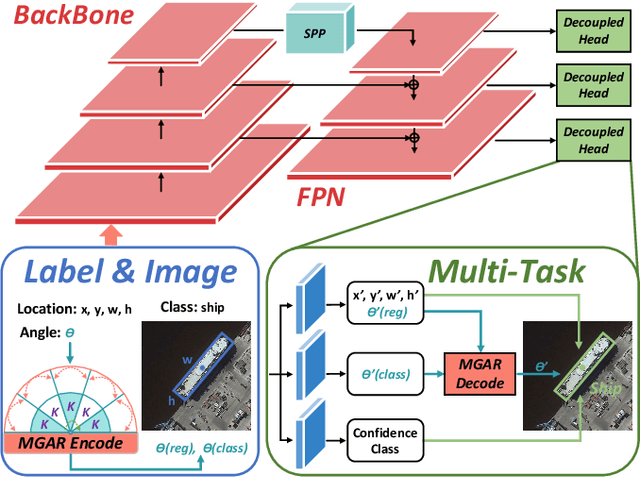
Arbitrary-oriented object detection (AOOD) plays a significant role for image understanding in remote sensing scenarios. The existing AOOD methods face the challenges of ambiguity and high costs in angle representation. To this end, a multi-grained angle representation (MGAR) method, consisting of coarse-grained angle classification (CAC) and fine-grained angle regression (FAR), is proposed. Specifically, the designed CAC avoids the ambiguity of angle prediction by discrete angular encoding (DAE) and reduces complexity by coarsening the granularity of DAE. Based on CAC, FAR is developed to refine the angle prediction with much lower costs than narrowing the granularity of DAE. Furthermore, an Intersection over Union (IoU) aware FAR-Loss (IFL) is designed to improve accuracy of angle prediction using an adaptive re-weighting mechanism guided by IoU. Extensive experiments are performed on several public remote sensing datasets, which demonstrate the effectiveness of the proposed MGAR. Moreover, experiments on embedded devices demonstrate that the proposed MGAR is also friendly for lightweight deployments.
Physically Explainable CNN for SAR Image Classification
Oct 27, 2021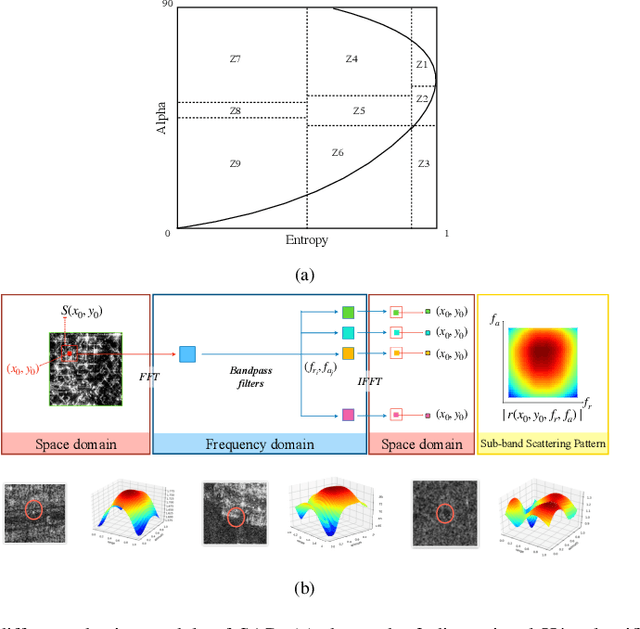
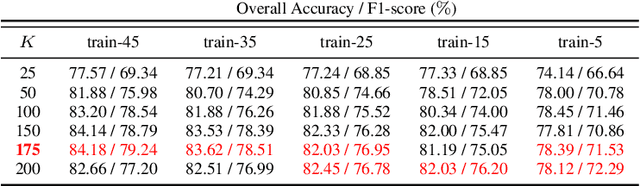

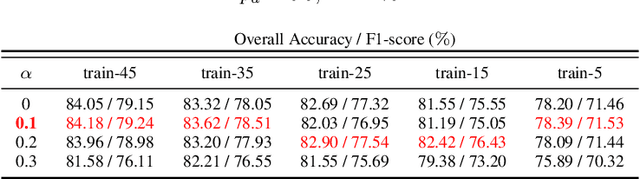
Integrating the special electromagnetic characteristics of Synthetic Aperture Radar (SAR) in deep neural networks is essential in order to enhance the explainability and physics awareness of deep learning. In this paper, we firstly propose a novel physics guided and injected neural network for SAR image classification, which is mainly guided by explainable physics models and can be learned with very limited labeled data. The proposed framework comprises three parts: (1) generating physics guided signals using existing explainable models, (2) learning physics-aware features with physics guided network, and (3) injecting the physics-aware features adaptively to the conventional classification deep learning model for prediction. The prior knowledge, physical scattering characteristic of SAR in this paper, is injected into the deep neural network in the form of physics-aware features which is more conducive to understanding the semantic labels of SAR image patches. A hybrid Image-Physics SAR dataset format is proposed, and both Sentinel-1 and Gaofen-3 SAR data are taken for evaluation. The experimental results show that our proposed method substantially improve the classification performance compared with the counterpart data-driven CNN. Moreover, the guidance of explainable physics signals leads to explainability of physics-aware features and the physics consistency of features are also preserved in the predictions. We deem the proposed method would promote the development of physically explainable deep learning in SAR image interpretation field.
Delving into Rectifiers in Style-Based Image Translation
Nov 23, 2021
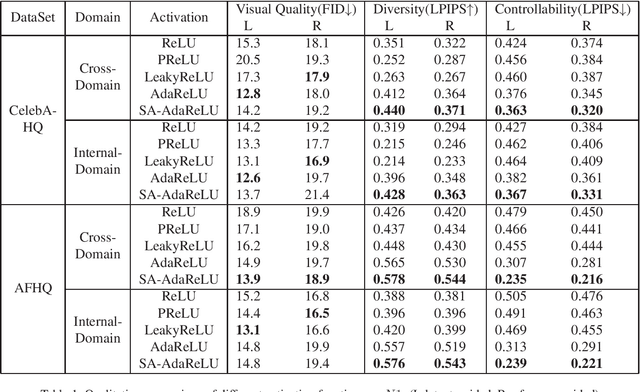
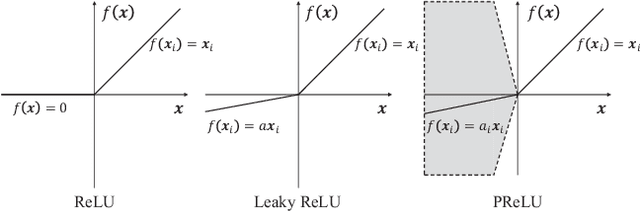
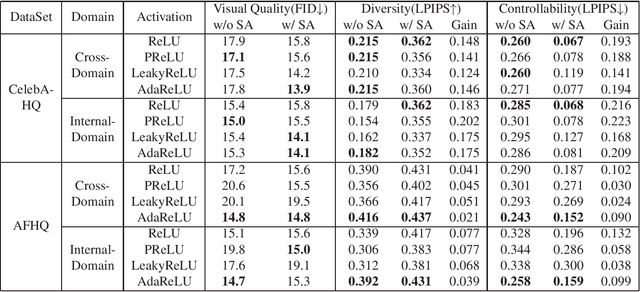
While modern image translation techniques can create photorealistic synthetic images, they have limited style controllability, thus could suffer from translation errors. In this work, we show that the activation function is one of the crucial components in controlling the direction of image synthesis. Specifically, we explicitly demonstrated that the slope parameters of the rectifier could change the data distribution and be used independently to control the direction of translation. To improve the style controllability, two simple but effective techniques are proposed, including Adaptive ReLU (AdaReLU) and structural adaptive function. The AdaReLU can dynamically adjust the slope parameters according to the target style and can be utilized to increase the controllability by combining with Adaptive Instance Normalization (AdaIN). Meanwhile, the structural adaptative function enables rectifiers to manipulate the structure of feature maps more effectively. It is composed of the proposed structural convolution (StruConv), an efficient convolutional module that can choose the area to be activated based on the mean and variance specified by AdaIN. Extensive experiments show that the proposed techniques can greatly increase the network controllability and output diversity in style-based image translation tasks.
Ptychographic lens-less polarization microscopy
Sep 13, 2022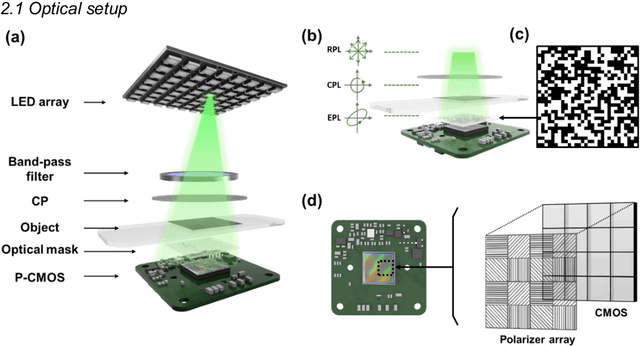
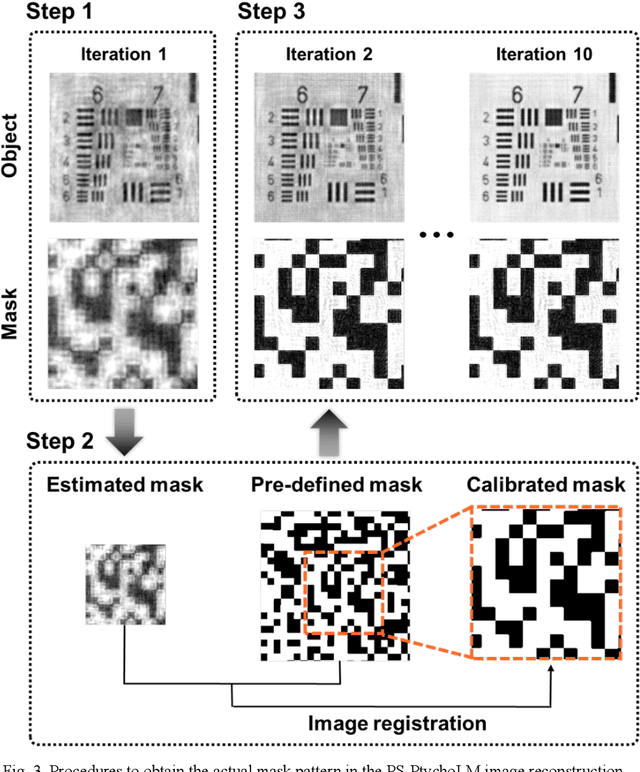
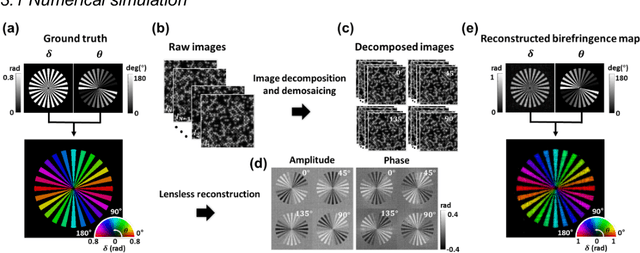
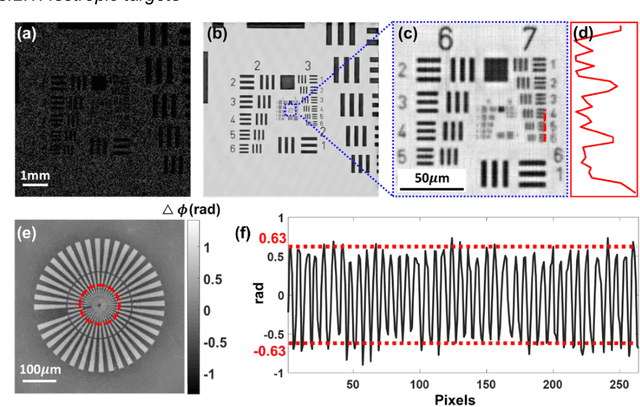
Birefringence, an inherent characteristic of optically anisotropic materials, is widely utilized in various imaging applications ranging from material characterizations to clinical diagnosis. Polarized light microscopy enables high-resolution, high-contrast imaging of optically anisotropic specimens, but it is associated with mechanical rotations of polarizer/analyzer and relatively complex optical designs. Here, we present a novel form of polarization-sensitive microscopy capable of birefringence imaging of transparent objects without an optical lens and any moving parts. Our method exploits an optical mask-modulated polarization image sensor and single-input-state LED illumination design to obtain complex and birefringence images of the object via ptychographic phase retrieval. Using a camera with a pixel resolution of 3.45 um, the method achieves birefringence imaging with a half-pitch resolution of 2.46 um over a 59.74 mm^2 field-of-view, which corresponds to a space-bandwidth product of 9.9 megapixels. We demonstrate the high-resolution, large-area birefringence imaging capability of our method by presenting the birefringence images of various anisotropic objects, including a birefringent resolution target, liquid crystal polymer depolarizer, monosodium urate crystal, and excised mouse eye and heart tissues.
Video Restoration with a Deep Plug-and-Play Prior
Sep 06, 2022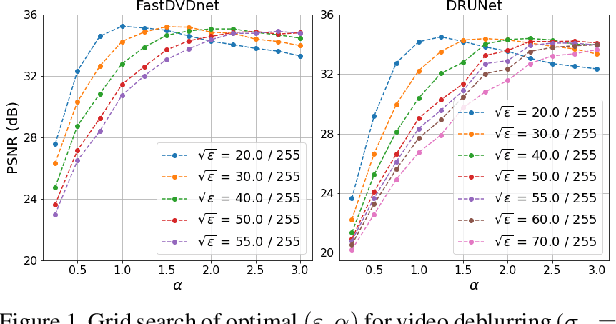

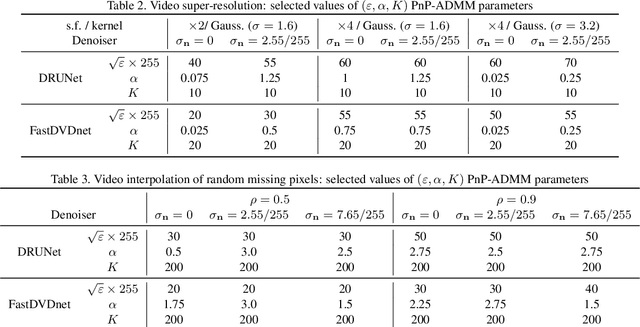
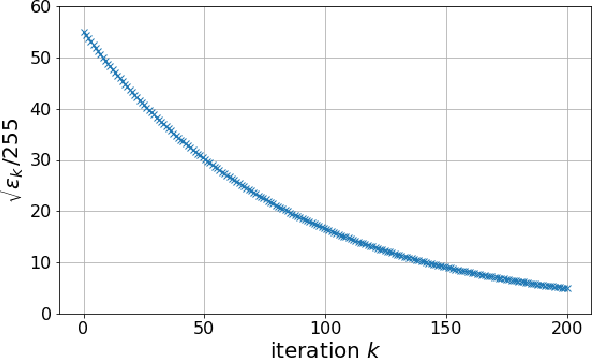
This paper presents a novel method for restoring digital videos via a Deep Plug-and-Play (PnP) approach. Under a Bayesian formalism, the method consists in using a deep convolutional denoising network in place of the proximal operator of the prior in an alternating optimization scheme. We distinguish ourselves from prior PnP work by directly applying that method to restore a digital video from a degraded video observation. This way, a network trained once for denoising can be repurposed for other video restoration tasks. Our experiments in video deblurring, super-resolution, and interpolation of random missing pixels all show a clear benefit to using a network specifically designed for video denoising, as it yields better restoration performance and better temporal stability than a single image network with similar denoising performance using the same PnP formulation. Moreover, our method compares favorably to applying a different state-of-the-art PnP scheme separately on each frame of the sequence. This opens new perspectives in the field of video restoration.
Warm Start Active Learning with Proxy Labels \& Selection via Semi-Supervised Fine-Tuning
Sep 13, 2022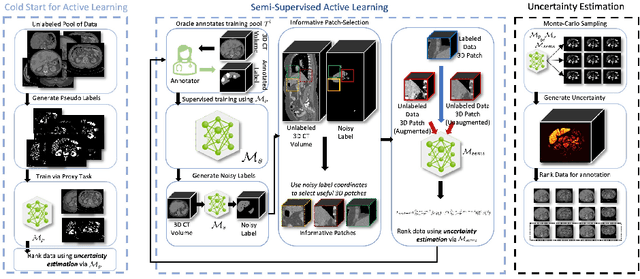
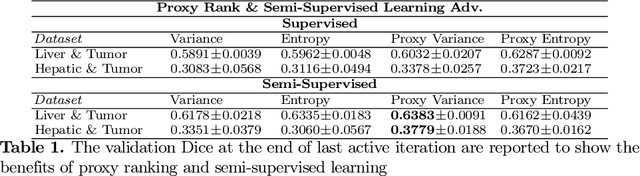
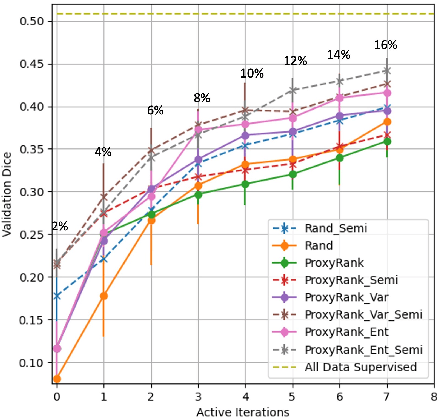
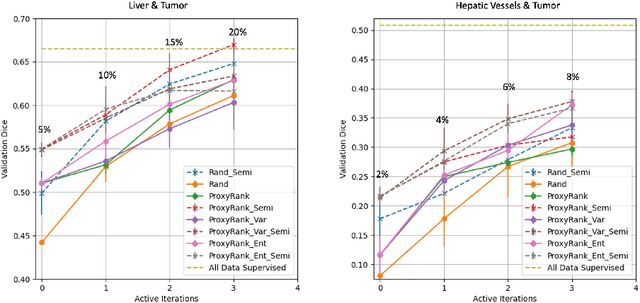
Which volume to annotate next is a challenging problem in building medical imaging datasets for deep learning. One of the promising methods to approach this question is active learning (AL). However, AL has been a hard nut to crack in terms of which AL algorithm and acquisition functions are most useful for which datasets. Also, the problem is exacerbated with which volumes to label first when there is zero labeled data to start with. This is known as the cold start problem in AL. We propose two novel strategies for AL specifically for 3D image segmentation. First, we tackle the cold start problem by proposing a proxy task and then utilizing uncertainty generated from the proxy task to rank the unlabeled data to be annotated. Second, we craft a two-stage learning framework for each active iteration where the unlabeled data is also used in the second stage as a semi-supervised fine-tuning strategy. We show the promise of our approach on two well-known large public datasets from medical segmentation decathlon. The results indicate that the initial selection of data and semi-supervised framework both showed significant improvement for several AL strategies.
Geolocation estimation of target vehicles using image processing and geometric computation
Mar 08, 2022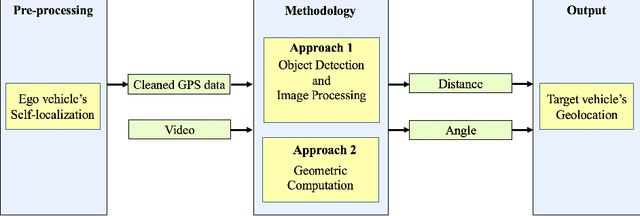
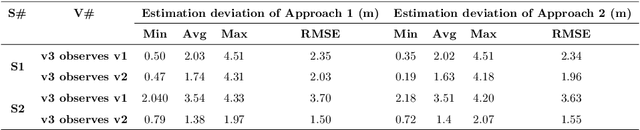
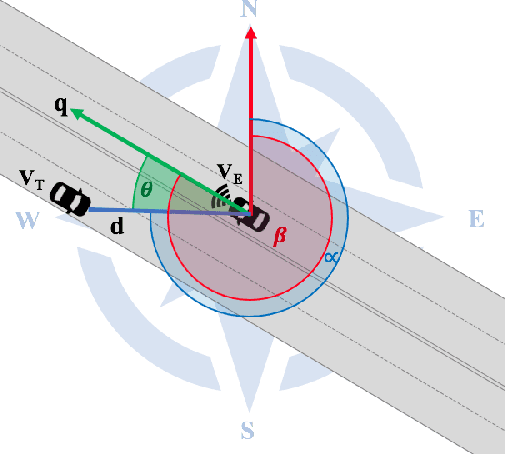
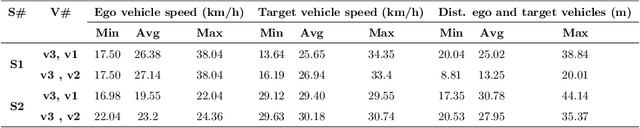
Estimating vehicles' locations is one of the key components in intelligent traffic management systems (ITMSs) for increasing traffic scene awareness. Traditionally, stationary sensors have been employed in this regard. The development of advanced sensing and communication technologies on modern vehicles (MVs) makes it feasible to use such vehicles as mobile sensors to estimate the traffic data of observed vehicles. This study aims to explore the capabilities of a monocular camera mounted on an MV in order to estimate the geolocation of the observed vehicle in a global positioning system (GPS) coordinate system. We proposed a new methodology by integrating deep learning, image processing, and geometric computation to address the observed-vehicle localization problem. To evaluate our proposed methodology, we developed new algorithms and tested them using real-world traffic data. The results indicated that our proposed methodology and algorithms could effectively estimate the observed vehicle's latitude and longitude dynamically.
Mixed X-Ray Image Separation for Artworks with Concealed Designs
Jan 23, 2022
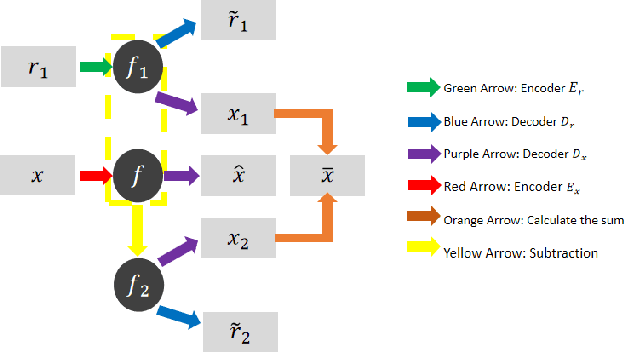
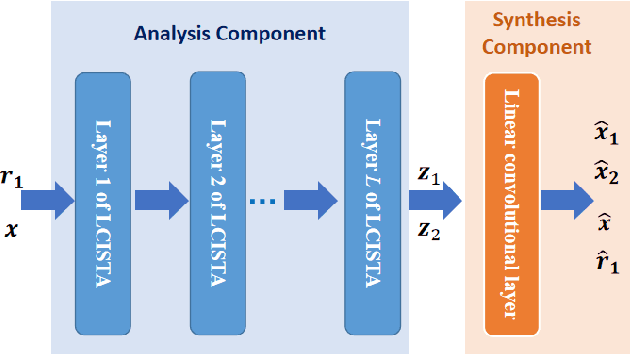
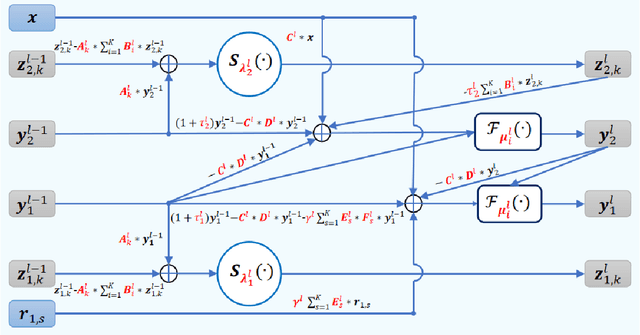
In this paper, we focus on X-ray images of paintings with concealed sub-surface designs (e.g., deriving from reuse of the painting support or revision of a composition by the artist), which include contributions from both the surface painting and the concealed features. In particular, we propose a self-supervised deep learning-based image separation approach that can be applied to the X-ray images from such paintings to separate them into two hypothetical X-ray images. One of these reconstructed images is related to the X-ray image of the concealed painting, while the second one contains only information related to the X-ray of the visible painting. The proposed separation network consists of two components: the analysis and the synthesis sub-networks. The analysis sub-network is based on learned coupled iterative shrinkage thresholding algorithms (LCISTA) designed using algorithm unrolling techniques, and the synthesis sub-network consists of several linear mappings. The learning algorithm operates in a totally self-supervised fashion without requiring a sample set that contains both the mixed X-ray images and the separated ones. The proposed method is demonstrated on a real painting with concealed content, Do\~na Isabel de Porcel by Francisco de Goya, to show its effectiveness.