 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Dynamic Prompt Learning via Policy Gradient for Semi-structured Mathematical Reasoning
Sep 29, 2022
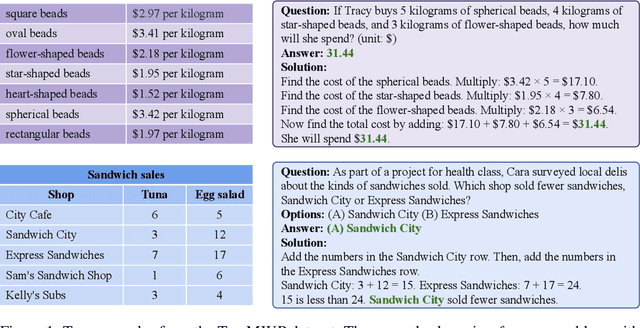
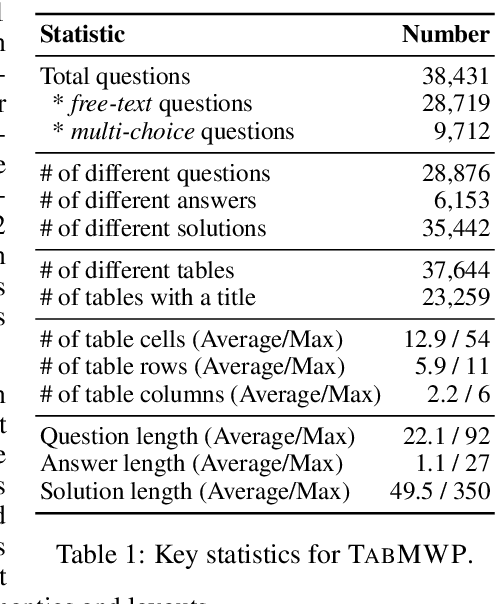
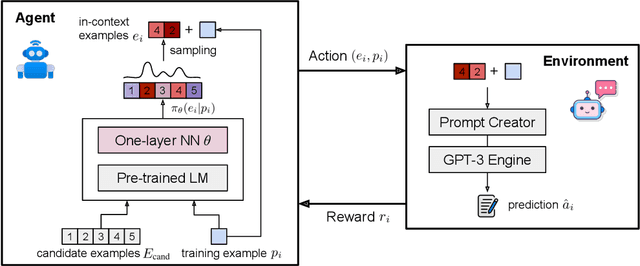
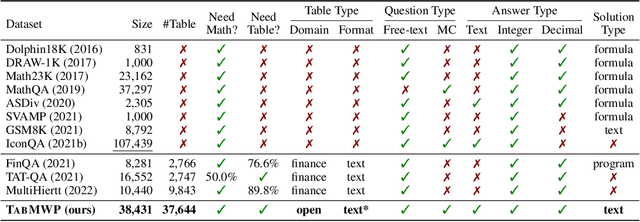
Mathematical reasoning, a core ability of human intelligence, presents unique challenges for machines in abstract thinking and logical reasoning. Recent large pre-trained language models such as GPT-3 have achieved remarkable progress on mathematical reasoning tasks written in text form, such as math word problems (MWP). However, it is unknown if the models can handle more complex problems that involve math reasoning over heterogeneous information, such as tabular data. To fill the gap, we present Tabular Math Word Problems (TabMWP), a new dataset containing 38,431 open-domain grade-level problems that require mathematical reasoning on both textual and tabular data. Each question in TabMWP is aligned with a tabular context, which is presented as an image, semi-structured text, and a structured table. There are two types of questions: free-text and multi-choice, and each problem is annotated with gold solutions to reveal the multi-step reasoning process. We evaluate different pre-trained models on TabMWP, including the GPT-3 model in a few-shot setting. As earlier studies suggest, since few-shot GPT-3 relies on the selection of in-context examples, its performance is unstable and can degrade to near chance. The unstable issue is more severe when handling complex problems like TabMWP. To mitigate this, we further propose a novel approach, PromptPG, which utilizes policy gradient to learn to select in-context examples from a small amount of training data and then constructs the corresponding prompt for the test example. Experimental results show that our method outperforms the best baseline by 5.31% on the accuracy metric and reduces the prediction variance significantly compared to random selection, which verifies its effectiveness in the selection of in-context examples.
State of the Art: Image Hashing
Aug 26, 2021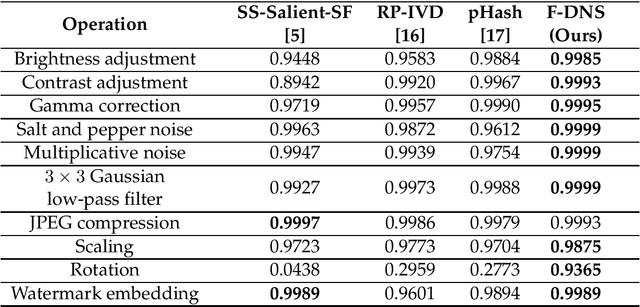
Perceptual image hashing methods are often applied in various objectives, such as image retrieval, finding duplicate or near-duplicate images, and finding similar images from large-scale image content. The main challenge in image hashing techniques is robust feature extraction, which generates the same or similar hashes in images that are visually identical. In this article, we present a short review of the state-of-the-art traditional perceptual hashing and deep learning-based perceptual hashing methods, identifying the best approaches.
Learning Pseudo Front Depth for 2D Forward-Looking Sonar-based Multi-view Stereo
Jul 30, 2022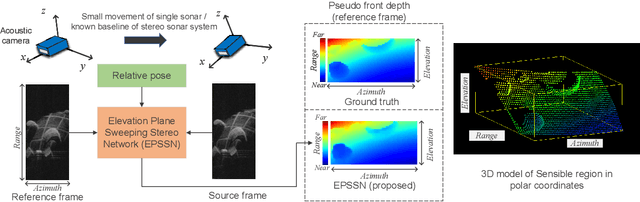
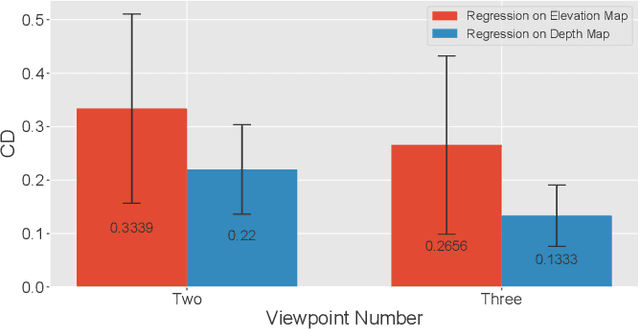
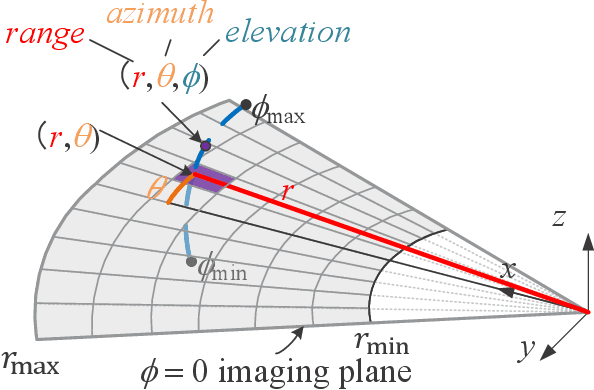
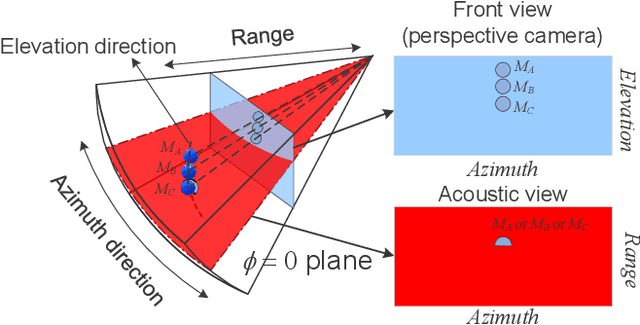
Retrieving the missing dimension information in acoustic images from 2D forward-looking sonar is a well-known problem in the field of underwater robotics. There are works attempting to retrieve 3D information from a single image which allows the robot to generate 3D maps with fly-through motion. However, owing to the unique image formulation principle, estimating 3D information from a single image faces severe ambiguity problems. Classical methods of multi-view stereo can avoid the ambiguity problems, but may require a large number of viewpoints to generate an accurate model. In this work, we propose a novel learning-based multi-view stereo method to estimate 3D information. To better utilize the information from multiple frames, an elevation plane sweeping method is proposed to generate the depth-azimuth-elevation cost volume. The volume after regularization can be considered as a probabilistic volumetric representation of the target. Instead of performing regression on the elevation angles, we use pseudo front depth from the cost volume to represent the 3D information which can avoid the 2D-3D problem in acoustic imaging. High-accuracy results can be generated with only two or three images. Synthetic datasets were generated to simulate various underwater targets. We also built the first real dataset with accurate ground truth in a large scale water tank. Experimental results demonstrate the superiority of our method, compared to other state-of-the-art methods.
Direct Handheld Burst Imaging to Simulated Defocus
Jul 13, 2022

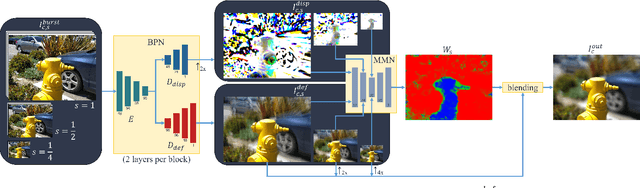
A shallow depth-of-field image keeps the subject in focus, and the foreground and background contexts blurred. This effect requires much larger lens apertures than those of smartphone cameras. Conventional methods acquire RGB-D images and blur image regions based on their depth. However, this approach is not suitable for reflective or transparent surfaces, or finely detailed object silhouettes, where the depth value is inaccurate or ambiguous. We present a learning-based method to synthesize the defocus blur in shallow depth-of-field images from handheld bursts acquired with a single small aperture lens. Our deep learning model directly produces the shallow depth-of-field image, avoiding explicit depth-based blurring. The simulated aperture diameter equals the camera translation during burst acquisition. Our method does not suffer from artifacts due to inaccurate or ambiguous depth estimation, and it is well-suited to portrait photography.
DualCam: A Novel Benchmark Dataset for Fine-grained Real-time Traffic Light Detection
Sep 03, 2022
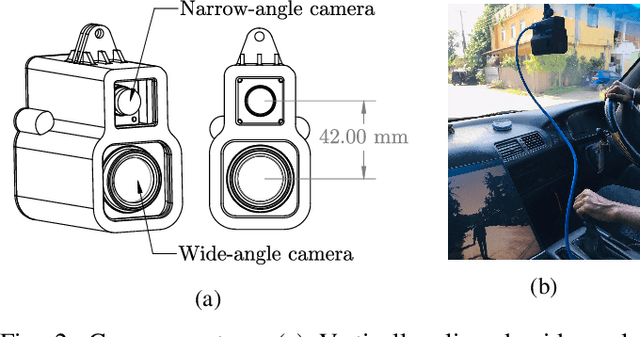

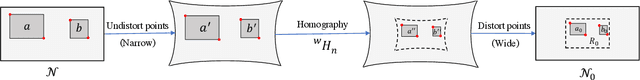
Traffic light detection is essential for self-driving cars to navigate safely in urban areas. Publicly available traffic light datasets are inadequate for the development of algorithms for detecting distant traffic lights that provide important navigation information. We introduce a novel benchmark traffic light dataset captured using a synchronized pair of narrow-angle and wide-angle cameras covering urban and semi-urban roads. We provide 1032 images for training and 813 synchronized image pairs for testing. Additionally, we provide synchronized video pairs for qualitative analysis. The dataset includes images of resolution 1920$\times$1080 covering 10 different classes. Furthermore, we propose a post-processing algorithm for combining outputs from the two cameras. Results show that our technique can strike a balance between speed and accuracy, compared to the conventional approach of using a single camera frame.
Just Rotate it: Deploying Backdoor Attacks via Rotation Transformation
Jul 22, 2022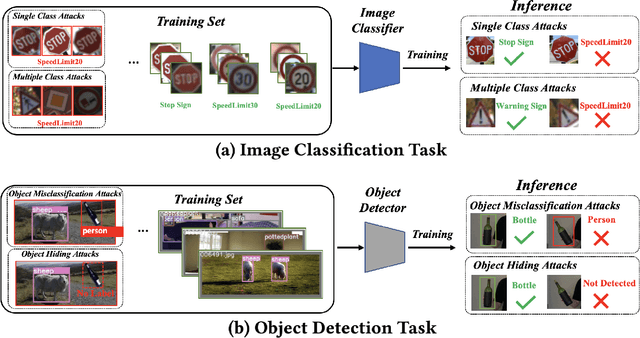
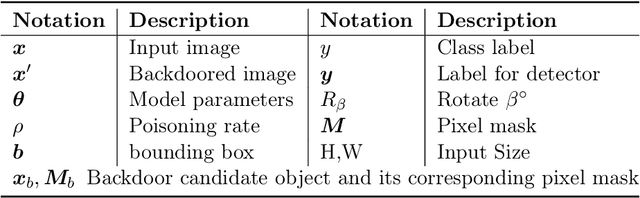
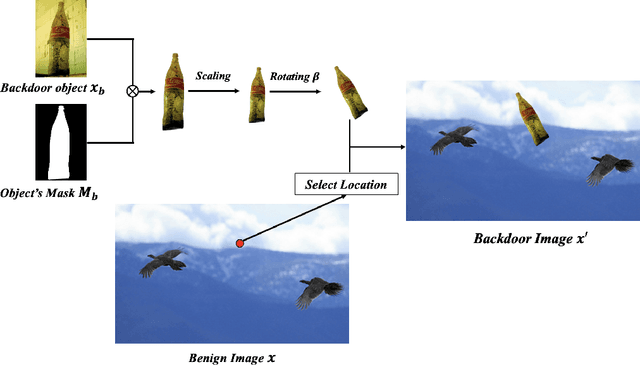
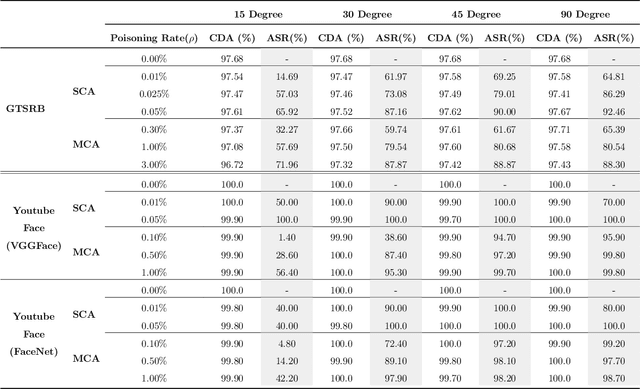
Recent works have demonstrated that deep learning models are vulnerable to backdoor poisoning attacks, where these attacks instill spurious correlations to external trigger patterns or objects (e.g., stickers, sunglasses, etc.). We find that such external trigger signals are unnecessary, as highly effective backdoors can be easily inserted using rotation-based image transformation. Our method constructs the poisoned dataset by rotating a limited amount of objects and labeling them incorrectly; once trained with it, the victim's model will make undesirable predictions during run-time inference. It exhibits a significantly high attack success rate while maintaining clean performance through comprehensive empirical studies on image classification and object detection tasks. Furthermore, we evaluate standard data augmentation techniques and four different backdoor defenses against our attack and find that none of them can serve as a consistent mitigation approach. Our attack can be easily deployed in the real world since it only requires rotating the object, as we show in both image classification and object detection applications. Overall, our work highlights a new, simple, physically realizable, and highly effective vector for backdoor attacks. Our video demo is available at https://youtu.be/6JIF8wnX34M.
Histopathology DatasetGAN: Synthesizing Large-Resolution Histopathology Datasets
Jul 06, 2022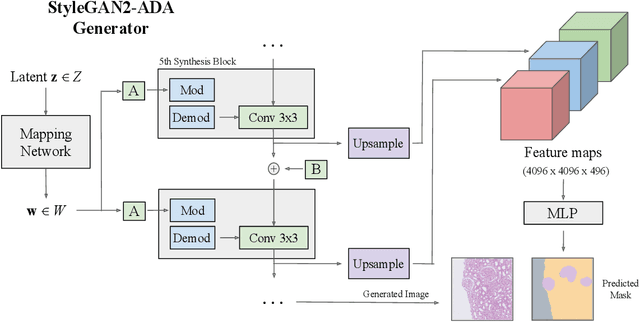
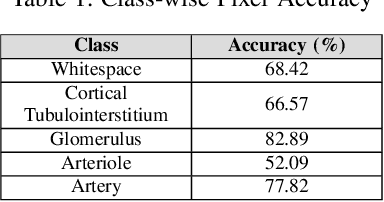
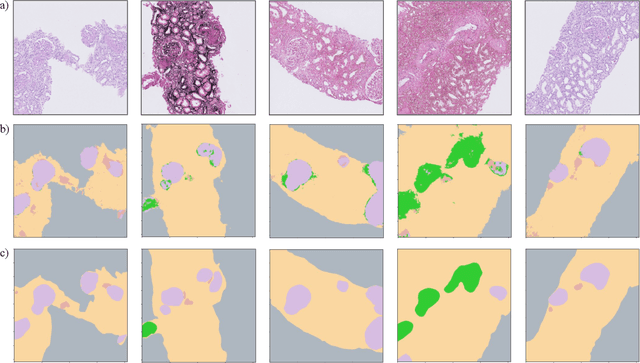
Self-supervised learning (SSL) methods are enabling an increasing number of deep learning models to be trained on image datasets in domains where labels are difficult to obtain. These methods, however, struggle to scale to the high resolution of medical imaging datasets, where they are critical for achieving good generalization on label-scarce medical image datasets. In this work, we propose the Histopathology DatasetGAN (HDGAN) framework, an extension of the DatasetGAN semi-supervised framework for image generation and segmentation that scales well to large-resolution histopathology images. We make several adaptations from the original framework, including updating the generative backbone, selectively extracting latent features from the generator, and switching to memory-mapped arrays. These changes reduce the memory consumption of the framework, improving its applicability to medical imaging domains. We evaluate HDGAN on a thrombotic microangiopathy high-resolution tile dataset, demonstrating strong performance on the high-resolution image-annotation generation task. We hope that this work enables more application of deep learning models to medical datasets, in addition to encouraging more exploration of self-supervised frameworks within the medical imaging domain.
MD-Net: Multi-Detector for Local Feature Extraction
Aug 10, 2022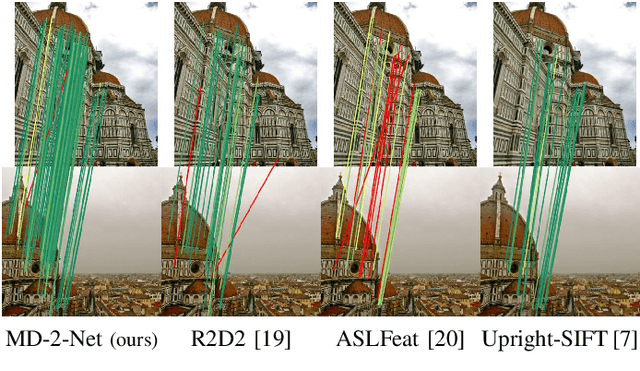
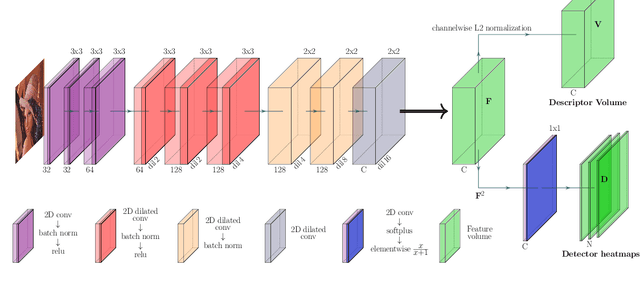
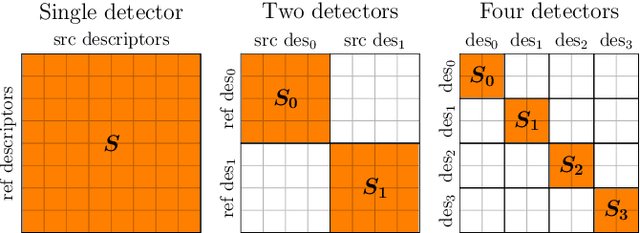

Establishing a sparse set of keypoint correspon dences between images is a fundamental task in many computer vision pipelines. Often, this translates into a computationally expensive nearest neighbor search, where every keypoint descriptor at one image must be compared with all the descriptors at the others. In order to lower the computational cost of the matching phase, we propose a deep feature extraction network capable of detecting a predefined number of complementary sets of keypoints at each image. Since only the descriptors within the same set need to be compared across the different images, the matching phase computational complexity decreases with the number of sets. We train our network to predict the keypoints and compute the corresponding descriptors jointly. In particular, in order to learn complementary sets of keypoints, we introduce a novel unsupervised loss which penalizes intersections among the different sets. Additionally, we propose a novel descriptor-based weighting scheme meant to penalize the detection of keypoints with non-discriminative descriptors. With extensive experiments we show that our feature extraction network, trained only on synthetically warped images and in a fully unsupervised manner, achieves competitive results on 3D reconstruction and re-localization tasks at a reduced matching complexity.
Multi-Grained Angle Representation for Remote Sensing Object Detection
Sep 07, 2022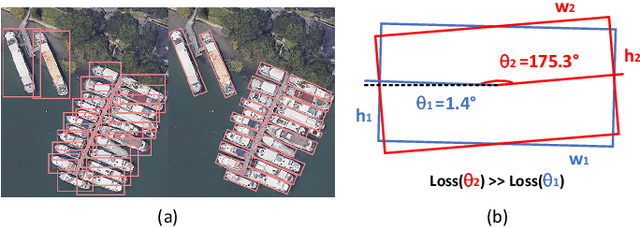
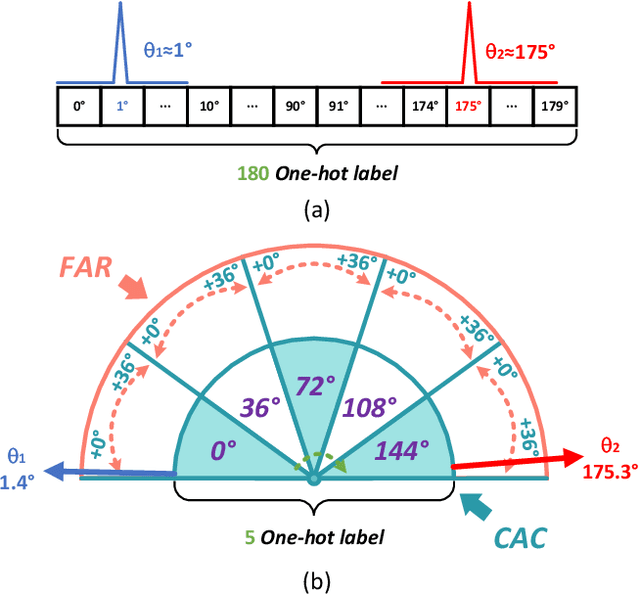
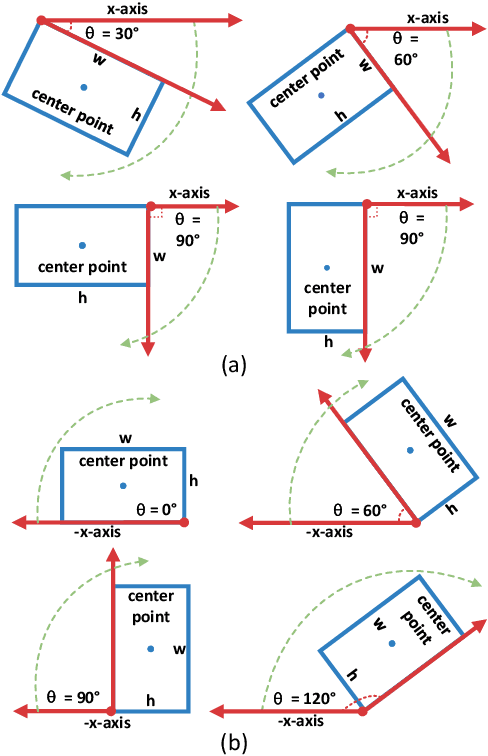
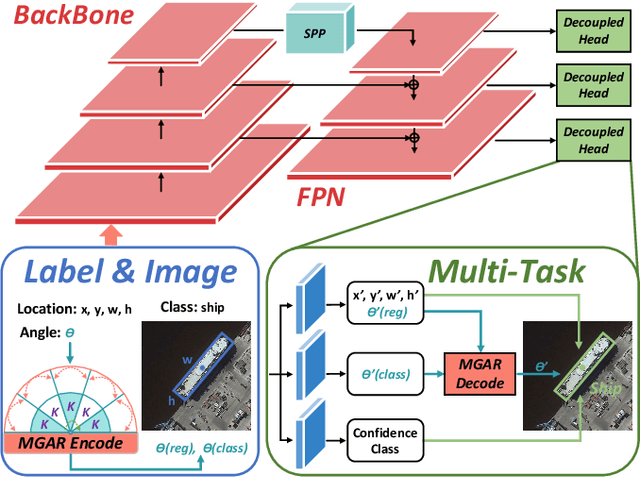
Arbitrary-oriented object detection (AOOD) plays a significant role for image understanding in remote sensing scenarios. The existing AOOD methods face the challenges of ambiguity and high costs in angle representation. To this end, a multi-grained angle representation (MGAR) method, consisting of coarse-grained angle classification (CAC) and fine-grained angle regression (FAR), is proposed. Specifically, the designed CAC avoids the ambiguity of angle prediction by discrete angular encoding (DAE) and reduces complexity by coarsening the granularity of DAE. Based on CAC, FAR is developed to refine the angle prediction with much lower costs than narrowing the granularity of DAE. Furthermore, an Intersection over Union (IoU) aware FAR-Loss (IFL) is designed to improve accuracy of angle prediction using an adaptive re-weighting mechanism guided by IoU. Extensive experiments are performed on several public remote sensing datasets, which demonstrate the effectiveness of the proposed MGAR. Moreover, experiments on embedded devices demonstrate that the proposed MGAR is also friendly for lightweight deployments.
Ptychographic lens-less polarization microscopy
Sep 13, 2022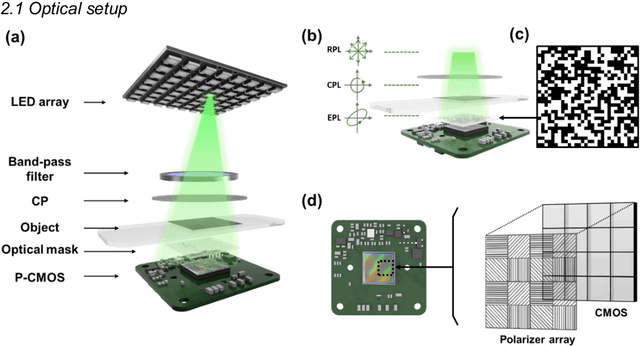
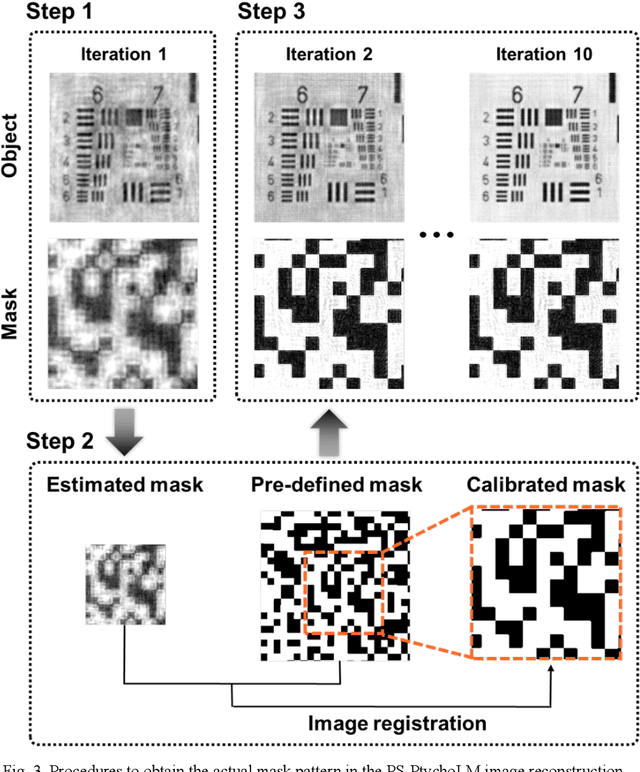
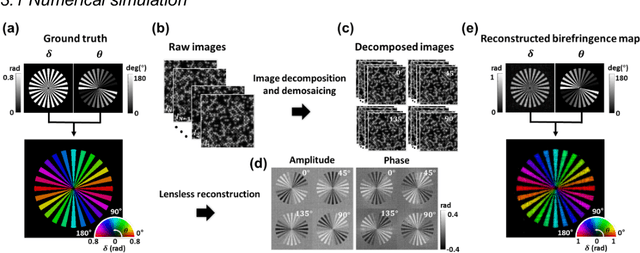
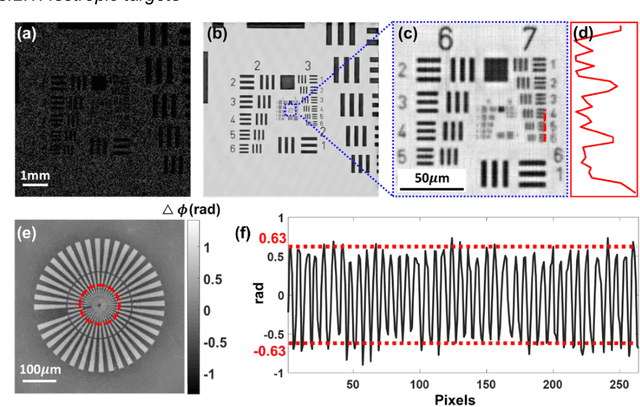
Birefringence, an inherent characteristic of optically anisotropic materials, is widely utilized in various imaging applications ranging from material characterizations to clinical diagnosis. Polarized light microscopy enables high-resolution, high-contrast imaging of optically anisotropic specimens, but it is associated with mechanical rotations of polarizer/analyzer and relatively complex optical designs. Here, we present a novel form of polarization-sensitive microscopy capable of birefringence imaging of transparent objects without an optical lens and any moving parts. Our method exploits an optical mask-modulated polarization image sensor and single-input-state LED illumination design to obtain complex and birefringence images of the object via ptychographic phase retrieval. Using a camera with a pixel resolution of 3.45 um, the method achieves birefringence imaging with a half-pitch resolution of 2.46 um over a 59.74 mm^2 field-of-view, which corresponds to a space-bandwidth product of 9.9 megapixels. We demonstrate the high-resolution, large-area birefringence imaging capability of our method by presenting the birefringence images of various anisotropic objects, including a birefringent resolution target, liquid crystal polymer depolarizer, monosodium urate crystal, and excised mouse eye and heart tissues.