 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Signal Strength and Noise Drive Feature Preference in CNN Image Classifiers
Jan 19, 2022
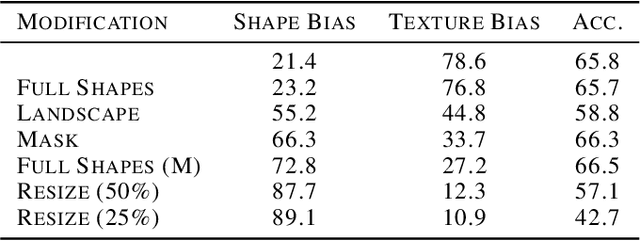
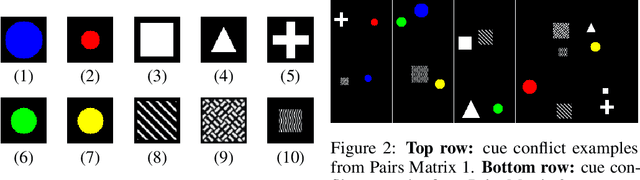
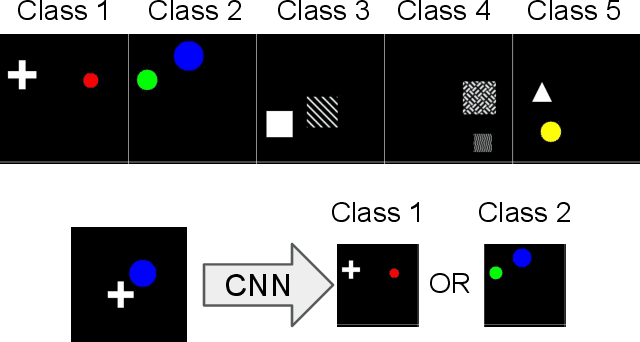
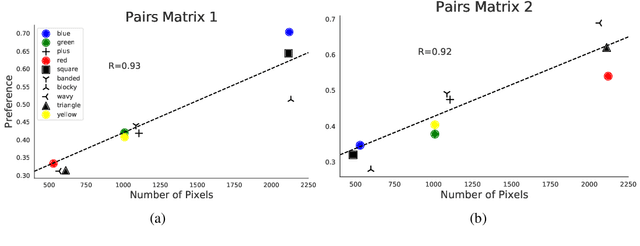
Feature preference in Convolutional Neural Network (CNN) image classifiers is integral to their decision making process, and while the topic has been well studied, it is still not understood at a fundamental level. We test a range of task relevant feature attributes (including shape, texture, and color) with varying degrees of signal and noise in highly controlled CNN image classification experiments using synthetic datasets to determine feature preferences. We find that CNNs will prefer features with stronger signal strength and lower noise irrespective of whether the feature is texture, shape, or color. This provides guidance for a predictive model for task relevant feature preferences, demonstrates pathways for bias in machine models that can be avoided with careful controls on experimental setup, and suggests that comparisons between how humans and machines prefer task relevant features in vision classification tasks should be revisited. Code to reproduce experiments in this paper can be found at \url{https://github.com/mwolff31/signal_preference}.
Learning while Acquisition: Towards Active Learning Framework for Beamforming in Ultrasound Imaging
Jul 31, 2022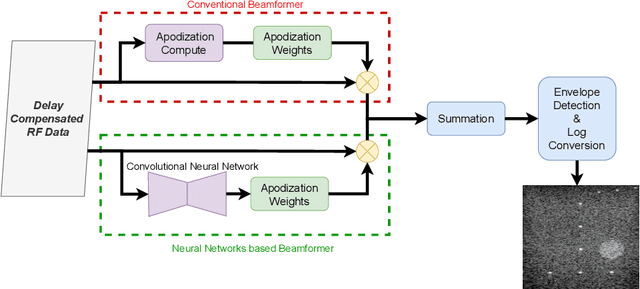
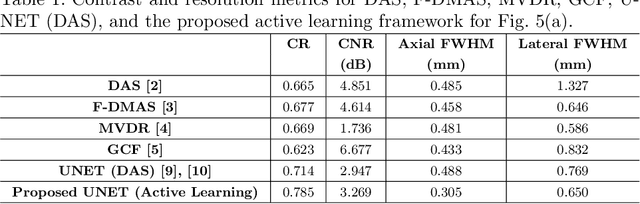
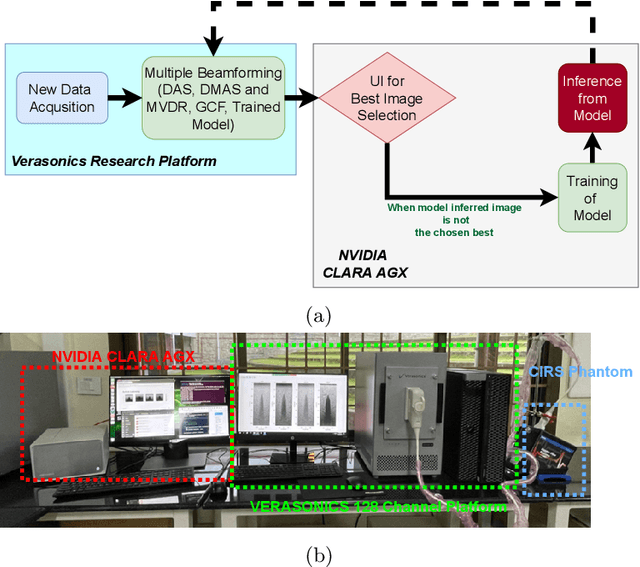
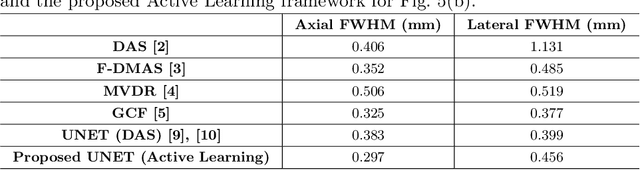
In the recent past, there have been many efforts to accelerate adaptive beamforming for ultrasound (US) imaging using neural networks (NNs). However, most of these efforts are based on static models, i.e., they are trained to learn a single adaptive beamforming approach (e.g., minimum variance distortionless response (MVDR)) assuming that they result in the best image quality. Moreover, the training of such NNs is initiated only after acquiring a large set of data that consumes several gigabytes (GBs) of storage space. In this study, an active learning framework for beamforming is described for the first time in the context of NNs. The best quality image chosen by the user serves as the ground truth for the proposed technique, which trains the NN concurrently with data acqusition. On average, the active learning approach takes 0.5 seconds to complete a single iteration of training.
Robust Reinforcement Learning Algorithm for Vision-based Ship Landing of UAVs
Sep 17, 2022

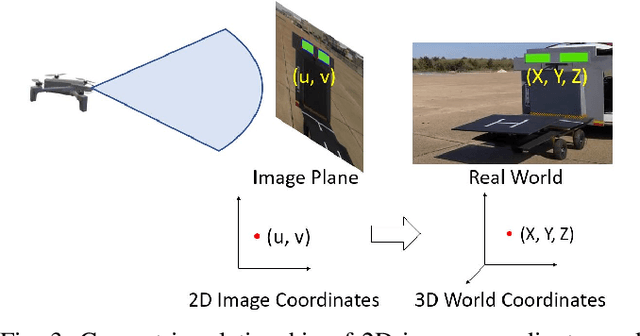
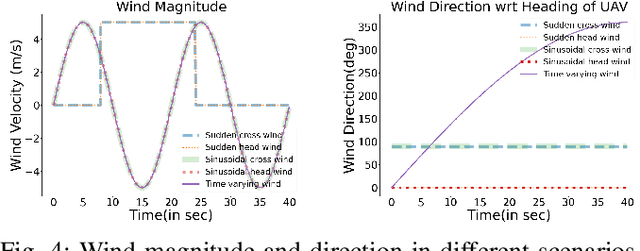
This paper addresses the problem of developing an algorithm for autonomous ship landing of vertical take-off and landing (VTOL) capable unmanned aerial vehicles (UAVs), using only a monocular camera in the UAV for tracking and localization. Ship landing is a challenging task due to the small landing space, six degrees of freedom ship deck motion, limited visual references for localization, and adversarial environmental conditions such as wind gusts. We first develop a computer vision algorithm which estimates the relative position of the UAV with respect to a horizon reference bar on the landing platform using the image stream from a monocular vision camera on the UAV. Our approach is motivated by the actual ship landing procedure followed by the Navy helicopter pilots in tracking the horizon reference bar as a visual cue. We then develop a robust reinforcement learning (RL) algorithm for controlling the UAV towards the landing platform even in the presence of adversarial environmental conditions such as wind gusts. We demonstrate the superior performance of our algorithm compared to a benchmark nonlinear PID control approach, both in the simulation experiments using the Gazebo environment and in the real-world setting using a Parrot ANAFI quad-rotor and sub-scale ship platform undergoing 6 degrees of freedom (DOF) deck motion.
Perceptual Optimization of a Biologically-Inspired Tone Mapping Operator
Jun 18, 2022

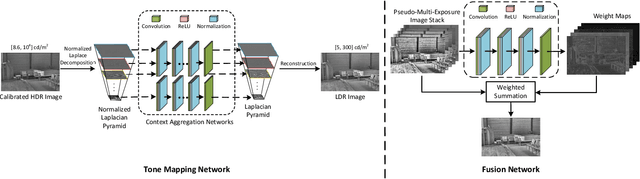
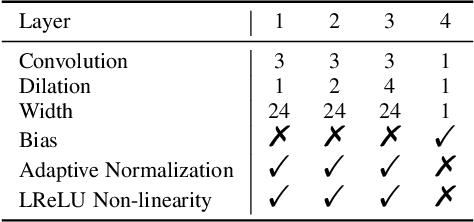
With the increasing popularity and accessibility of high dynamic range (HDR) photography, tone mapping operators (TMOs) for dynamic range compression and medium presentation are practically demanding. In this paper, we develop a two-stage neural network-based HDR image TMO that is biologically-inspired, computationally efficient, and perceptually optimized. In Stage one, motivated by the physiology of the early stages of the human visual system (HVS), we first decompose an HDR image into a normalized Laplacian pyramid. We then use two lightweight deep neural networks (DNNs) that take this normalized representation as input and estimate the Laplacian pyramid of the corresponding LDR image. We optimize the tone mapping network by minimizing the normalized Laplacian pyramid distance (NLPD), a perceptual metric calibrated against human judgments of tone-mapped image quality. In Stage two, we generate a pseudo-multi-exposure image stack with different color saturation and detail visibility by inputting an HDR image ``calibrated'' with different maximum luminances to the learned tone mapping network. We then train another lightweight DNN to fuse the LDR image stack into a desired LDR image by maximizing a variant of MEF-SSIM, another perceptually calibrated metric for image fusion. By doing so, the proposed TMO is fully automatic to tone map uncalibrated HDR images. Across an independent set of HDR images, we find that our method produces images with consistently better visual quality, and is among the fastest local TMOs.
Alternating Cross-attention Vision-Language Model for Efficient Learning with Medical Image and Report without Curation
Aug 10, 2022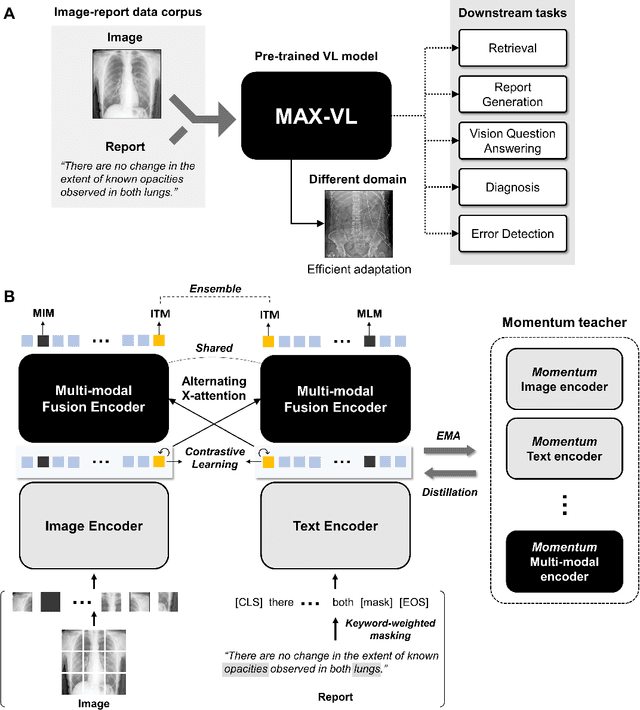
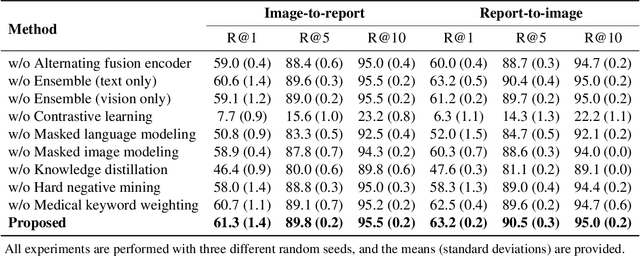
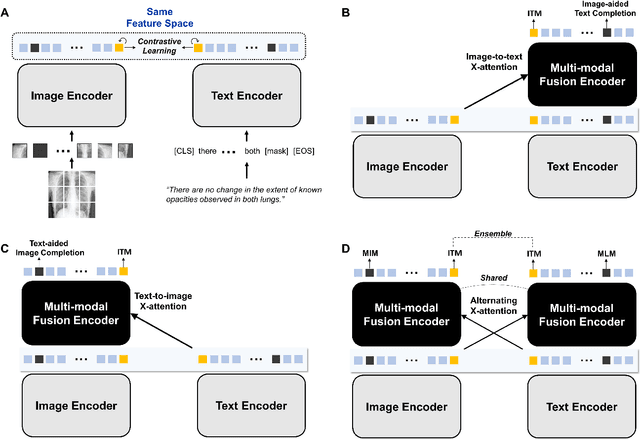
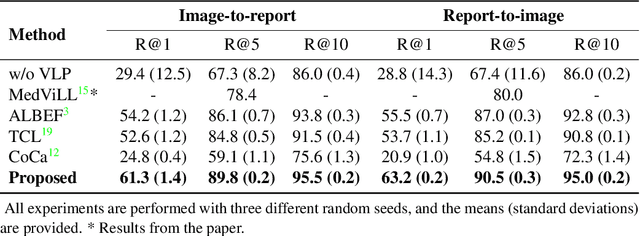
Recent advances in vision-language pre-training have demonstrated astounding performances in diverse vision-language tasks, shedding a light on the long-standing problems of a comprehensive understanding of both visual and textual concepts in artificial intelligence research. However, there has been limited success in the application of vision-language pre-training in the medical domain, as the current vision-language models and learning strategies for photographic images and captions are not optimal to process the medical data which are usually insufficient in the amount and the diversity, which impedes successful learning of joint vision-language concepts. In this study, we introduce MAX-VL, a model tailored for efficient vision-language pre-training in the medical domain. We experimentally demonstrated that the pre-trained MAX-VL model outperforms the current state-of-the-art vision language models in various vision-language tasks. We also suggested the clinical utility for the diagnosis of newly emerging diseases and human error detection as well as showed the widespread applicability of the model in different domain data.
Cartoon Explanations of Image Classifiers
Oct 07, 2021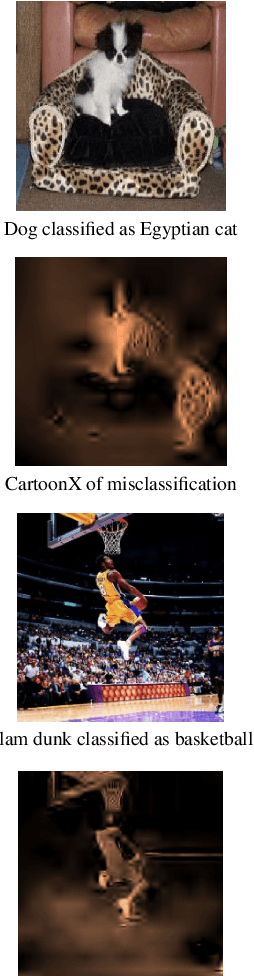
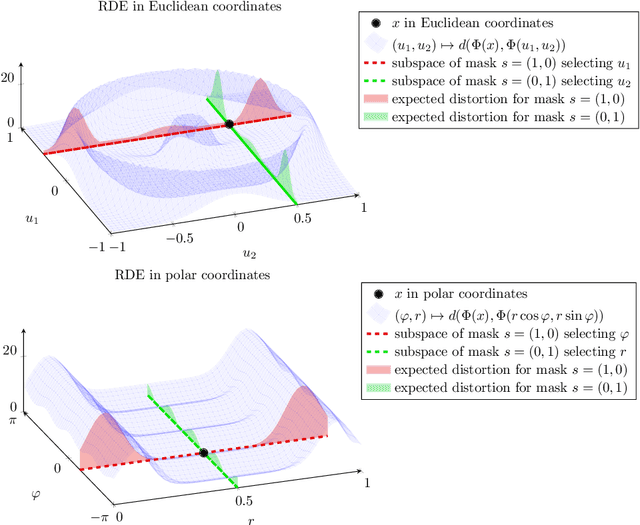
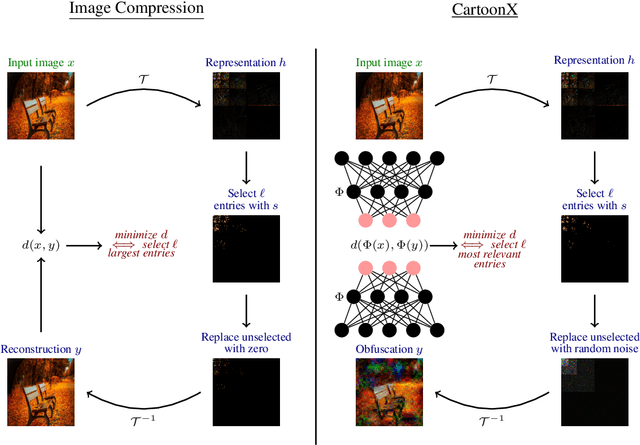
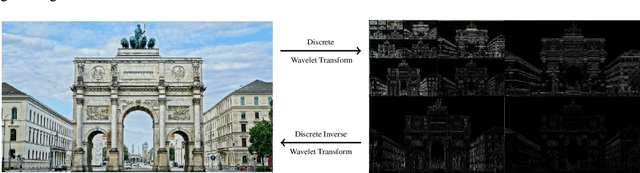
We present CartoonX (Cartoon Explanation), a novel model-agnostic explanation method tailored towards image classifiers and based on the rate-distortion explanation (RDE) framework. Natural images are roughly piece-wise smooth signals -- also called cartoon images -- and tend to be sparse in the wavelet domain. CartoonX is the first explanation method to exploit this by requiring its explanations to be sparse in the wavelet domain, thus extracting the \emph{relevant piece-wise smooth} part of an image instead of relevant pixel-sparse regions. We demonstrate experimentally that CartoonX is not only highly interpretable due to its piece-wise smooth nature but also particularly apt at explaining misclassifications.
Learning Visibility for Robust Dense Human Body Estimation
Aug 23, 2022
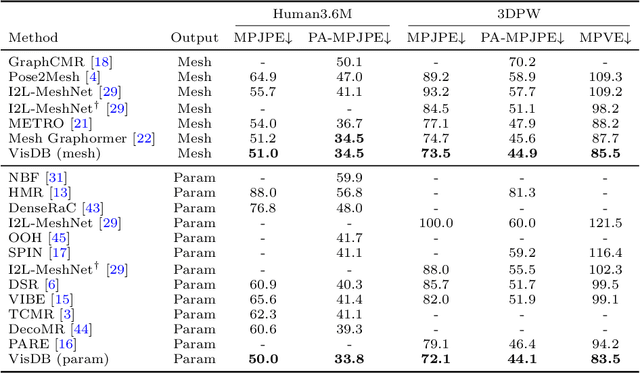
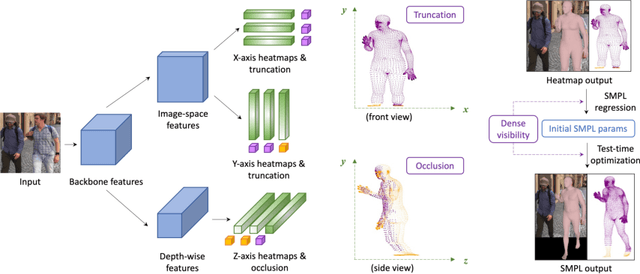

Estimating 3D human pose and shape from 2D images is a crucial yet challenging task. While prior methods with model-based representations can perform reasonably well on whole-body images, they often fail when parts of the body are occluded or outside the frame. Moreover, these results usually do not faithfully capture the human silhouettes due to their limited representation power of deformable models (e.g., representing only the naked body). An alternative approach is to estimate dense vertices of a predefined template body in the image space. Such representations are effective in localizing vertices within an image but cannot handle out-of-frame body parts. In this work, we learn dense human body estimation that is robust to partial observations. We explicitly model the visibility of human joints and vertices in the x, y, and z axes separately. The visibility in x and y axes help distinguishing out-of-frame cases, and the visibility in depth axis corresponds to occlusions (either self-occlusions or occlusions by other objects). We obtain pseudo ground-truths of visibility labels from dense UV correspondences and train a neural network to predict visibility along with 3D coordinates. We show that visibility can serve as 1) an additional signal to resolve depth ordering ambiguities of self-occluded vertices and 2) a regularization term when fitting a human body model to the predictions. Extensive experiments on multiple 3D human datasets demonstrate that visibility modeling significantly improves the accuracy of human body estimation, especially for partial-body cases. Our project page with code is at: https://github.com/chhankyao/visdb.
HighlightNet: Highlighting Low-Light Potential Features for Real-Time UAV Tracking
Aug 14, 2022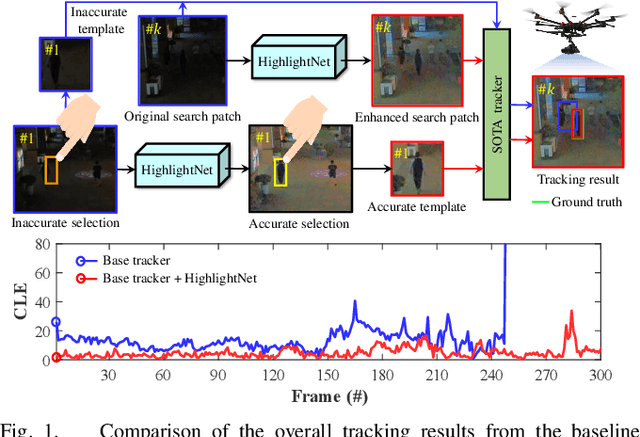
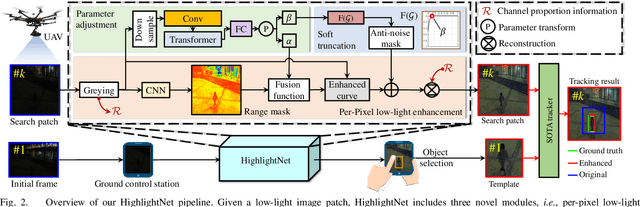


Low-light environments have posed a formidable challenge for robust unmanned aerial vehicle (UAV) tracking even with state-of-the-art (SOTA) trackers since the potential image features are hard to extract under adverse light conditions. Besides, due to the low visibility, accurate online selection of the object also becomes extremely difficult for human monitors to initialize UAV tracking in ground control stations. To solve these problems, this work proposes a novel enhancer, i.e., HighlightNet, to light up potential objects for both human operators and UAV trackers. By employing Transformer, HighlightNet can adjust enhancement parameters according to global features and is thus adaptive for the illumination variation. Pixel-level range mask is introduced to make HighlightNet more focused on the enhancement of the tracking object and regions without light sources. Furthermore, a soft truncation mechanism is built to prevent background noise from being mistaken for crucial features. Evaluations on image enhancement benchmarks demonstrate HighlightNet has advantages in facilitating human perception. Experiments on the public UAVDark135 benchmark show that HightlightNet is more suitable for UAV tracking tasks than other SOTA low-light enhancers. In addition, real-world tests on a typical UAV platform verify HightlightNet's practicability and efficiency in nighttime aerial tracking-related applications. The code and demo videos are available at https://github.com/vision4robotics/HighlightNet.
2nd Place Solutions for UG2+ Challenge 2022 -- D$^{3}$Net for Mitigating Atmospheric Turbulence from Images
Aug 25, 2022
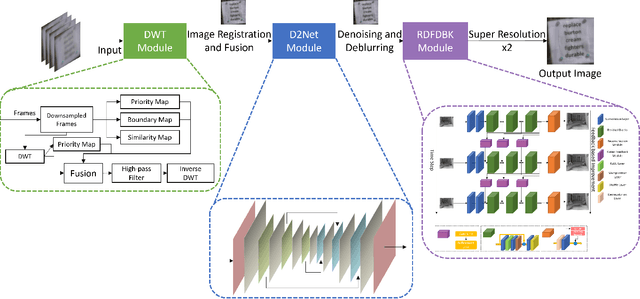

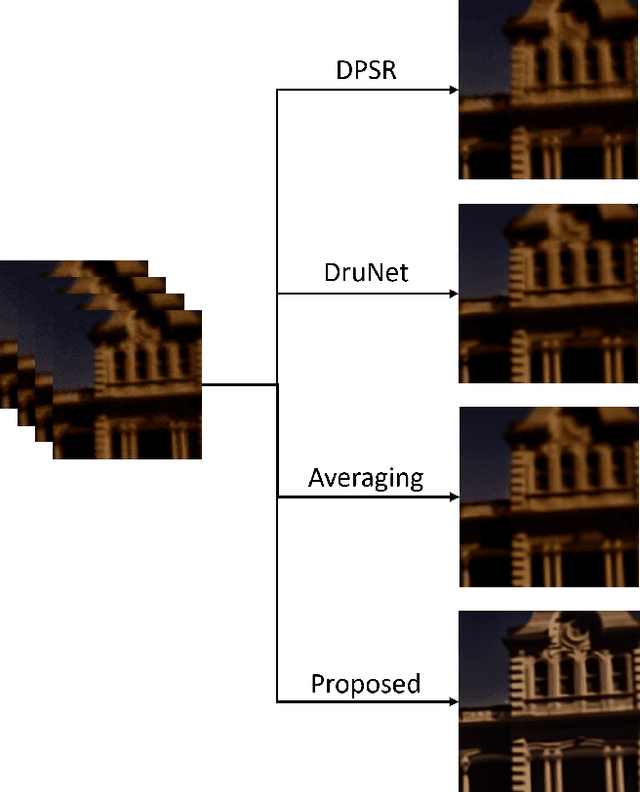
This technical report briefly introduces to the D$^{3}$Net proposed by our team "TUK-IKLAB" for Atmospheric Turbulence Mitigation in $UG2^{+}$ Challenge at CVPR 2022. In the light of test and validation results on textual images to improve text recognition performance and hot-air balloon images for image enhancement, we can say that the proposed method achieves state-of-the-art performance. Furthermore, we also provide a visual comparison with publicly available denoising, deblurring, and frame averaging methods with respect to the proposed work. The proposed method ranked 2nd on the final leader-board of the aforementioned challenge in the testing phase, respectively.
RGB-Event Fusion for Moving Object Detection in Autonomous Driving
Sep 17, 2022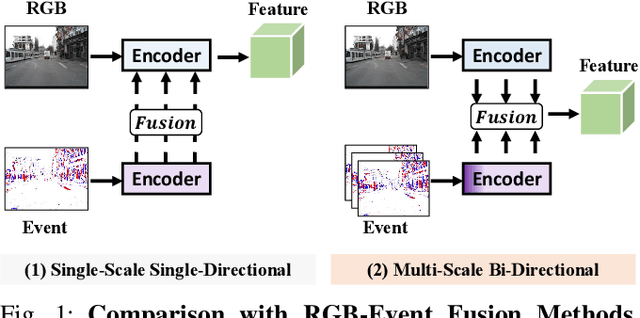
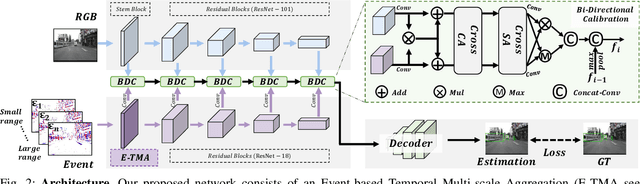
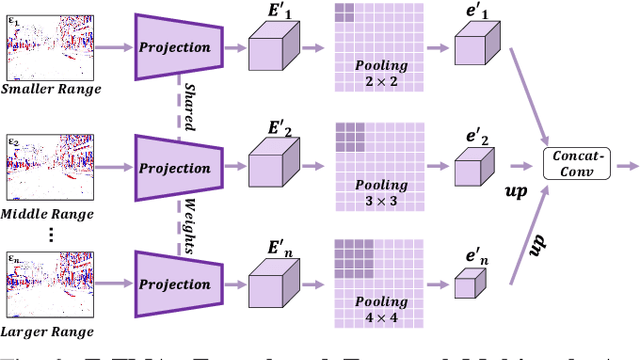
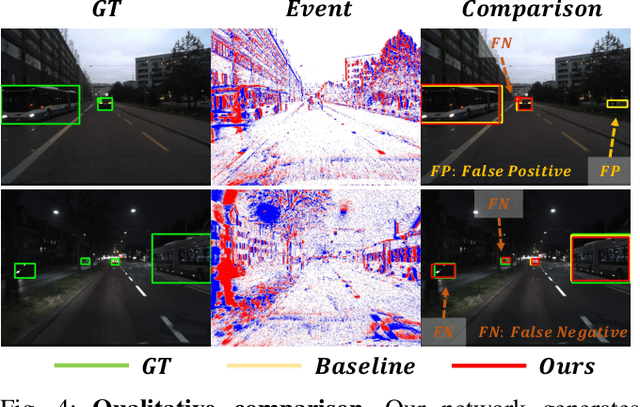
Moving Object Detection (MOD) is a critical vision task for successfully achieving safe autonomous driving. Despite plausible results of deep learning methods, most existing approaches are only frame-based and may fail to reach reasonable performance when dealing with dynamic traffic participants. Recent advances in sensor technologies, especially the Event camera, can naturally complement the conventional camera approach to better model moving objects. However, event-based works often adopt a pre-defined time window for event representation, and simply integrate it to estimate image intensities from events, neglecting much of the rich temporal information from the available asynchronous events. Therefore, from a new perspective, we propose RENet, a novel RGB-Event fusion Network, that jointly exploits the two complementary modalities to achieve more robust MOD under challenging scenarios for autonomous driving. Specifically, we first design a temporal multi-scale aggregation module to fully leverage event frames from both the RGB exposure time and larger intervals. Then we introduce a bi-directional fusion module to attentively calibrate and fuse multi-modal features. To evaluate the performance of our network, we carefully select and annotate a sub-MOD dataset from the commonly used DSEC dataset. Extensive experiments demonstrate that our proposed method performs significantly better than the state-of-the-art RGB-Event fusion alternatives.