 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Expansion and Shrinkage of Localization for Weakly-Supervised Semantic Segmentation
Sep 20, 2022
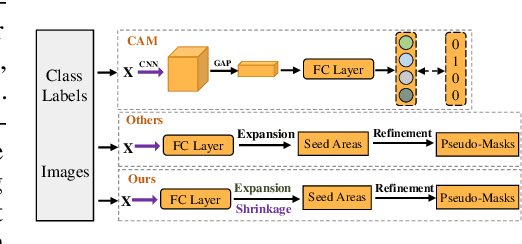
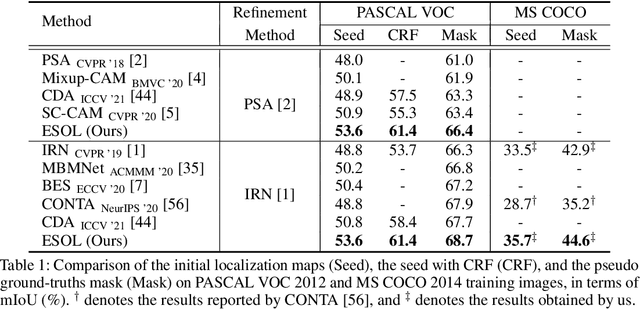
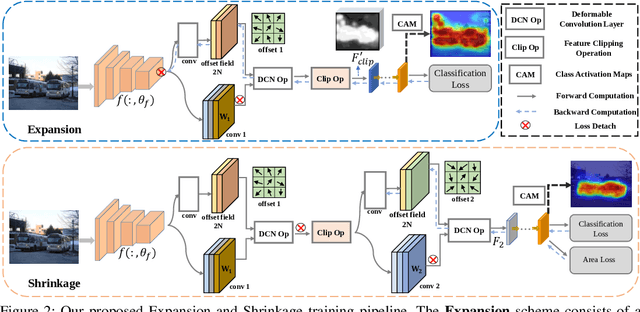

Generating precise class-aware pseudo ground-truths, a.k.a, class activation maps (CAMs), is essential for weakly-supervised semantic segmentation. The original CAM method usually produces incomplete and inaccurate localization maps. To tackle with this issue, this paper proposes an Expansion and Shrinkage scheme based on the offset learning in the deformable convolution, to sequentially improve the recall and precision of the located object in the two respective stages. In the Expansion stage, an offset learning branch in a deformable convolution layer, referred as "expansion sampler" seeks for sampling increasingly less discriminative object regions, driven by an inverse supervision signal that maximizes image-level classification loss. The located more complete object in the Expansion stage is then gradually narrowed down to the final object region during the Shrinkage stage. In the Shrinkage stage, the offset learning branch of another deformable convolution layer, referred as "shrinkage sampler", is introduced to exclude the false positive background regions attended in the Expansion stage to improve the precision of the localization maps. We conduct various experiments on PASCAL VOC 2012 and MS COCO 2014 to well demonstrate the superiority of our method over other state-of-the-art methods for weakly-supervised semantic segmentation. Code will be made publicly available here https://github.com/TyroneLi/ESOL_WSSS.
Deformable Image Registration using Neural ODEs
Aug 27, 2021



Deformable image registration, aiming to find spatial correspondence between a given image pair, is one of the most critical problems in the domain of medical image analysis. In this paper, we present a generic, fast, and accurate diffeomorphic image registration framework that leverages neural ordinary differential equations (NODEs). We model each voxel as a moving particle and consider the set of all voxels in a 3D image as a high-dimensional dynamical system whose trajectory determines the targeted deformation field. Compared with traditional optimization-based methods, our framework reduces the running time from tens of minutes to tens of seconds. Compared with recent data-driven deep learning methods, our framework is more accessible since it does not require large amounts of training data. Our experiments show that the registration results of our method outperform state-of-the-arts under various metrics, indicating that our modeling approach is well fitted for the task of deformable image registration.
GPR1200: A Benchmark for General-Purpose Content-Based Image Retrieval
Nov 25, 2021



Even though it has extensively been shown that retrieval specific training of deep neural networks is beneficial for nearest neighbor image search quality, most of these models are trained and tested in the domain of landmarks images. However, some applications use images from various other domains and therefore need a network with good generalization properties - a general-purpose CBIR model. To the best of our knowledge, no testing protocol has so far been introduced to benchmark models with respect to general image retrieval quality. After analyzing popular image retrieval test sets we decided to manually curate GPR1200, an easy to use and accessible but challenging benchmark dataset with a broad range of image categories. This benchmark is subsequently used to evaluate various pretrained models of different architectures on their generalization qualities. We show that large-scale pretraining significantly improves retrieval performance and present experiments on how to further increase these properties by appropriate fine-tuning. With these promising results, we hope to increase interest in the research topic of general-purpose CBIR.
Towards Multimodal Vision-Language Models Generating Non-Generic Text
Jul 09, 2022
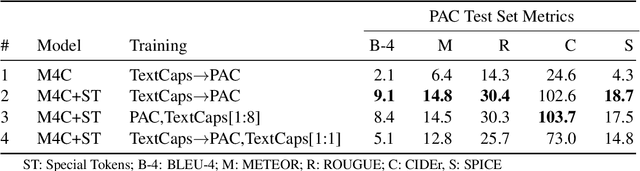
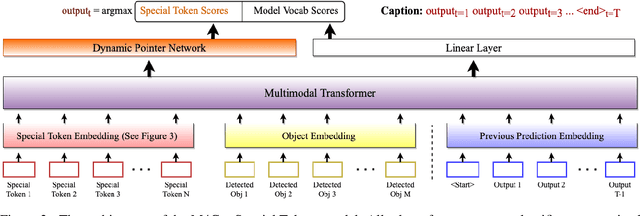

Vision-language models can assess visual context in an image and generate descriptive text. While the generated text may be accurate and syntactically correct, it is often overly general. To address this, recent work has used optical character recognition to supplement visual information with text extracted from an image. In this work, we contend that vision-language models can benefit from additional information that can be extracted from an image, but are not used by current models. We modify previous multimodal frameworks to accept relevant information from any number of auxiliary classifiers. In particular, we focus on person names as an additional set of tokens and create a novel image-caption dataset to facilitate captioning with person names. The dataset, Politicians and Athletes in Captions (PAC), consists of captioned images of well-known people in context. By fine-tuning pretrained models with this dataset, we demonstrate a model that can naturally integrate facial recognition tokens into generated text by training on limited data. For the PAC dataset, we provide a discussion on collection and baseline benchmark scores.
State of the Art: Image Hashing
Aug 26, 2021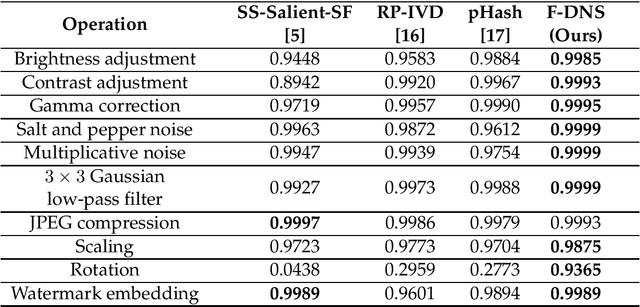
Perceptual image hashing methods are often applied in various objectives, such as image retrieval, finding duplicate or near-duplicate images, and finding similar images from large-scale image content. The main challenge in image hashing techniques is robust feature extraction, which generates the same or similar hashes in images that are visually identical. In this article, we present a short review of the state-of-the-art traditional perceptual hashing and deep learning-based perceptual hashing methods, identifying the best approaches.
Signal Strength and Noise Drive Feature Preference in CNN Image Classifiers
Jan 19, 2022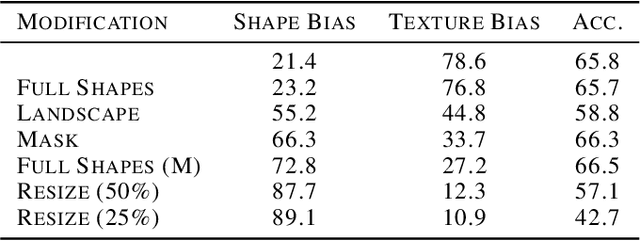
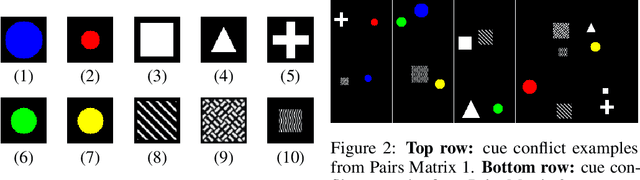
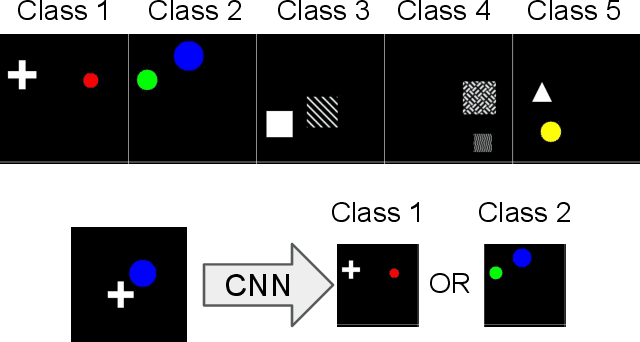
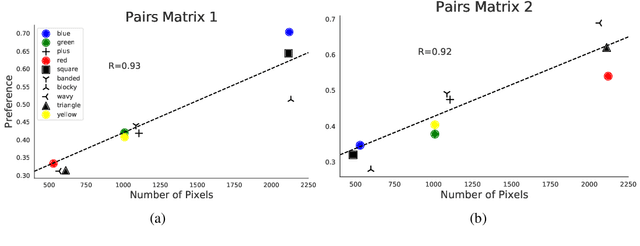
Feature preference in Convolutional Neural Network (CNN) image classifiers is integral to their decision making process, and while the topic has been well studied, it is still not understood at a fundamental level. We test a range of task relevant feature attributes (including shape, texture, and color) with varying degrees of signal and noise in highly controlled CNN image classification experiments using synthetic datasets to determine feature preferences. We find that CNNs will prefer features with stronger signal strength and lower noise irrespective of whether the feature is texture, shape, or color. This provides guidance for a predictive model for task relevant feature preferences, demonstrates pathways for bias in machine models that can be avoided with careful controls on experimental setup, and suggests that comparisons between how humans and machines prefer task relevant features in vision classification tasks should be revisited. Code to reproduce experiments in this paper can be found at \url{https://github.com/mwolff31/signal_preference}.
Transform and Bitstream Domain Image Classification
Oct 13, 2021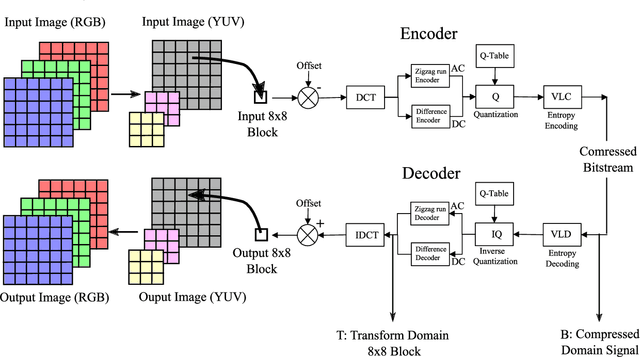
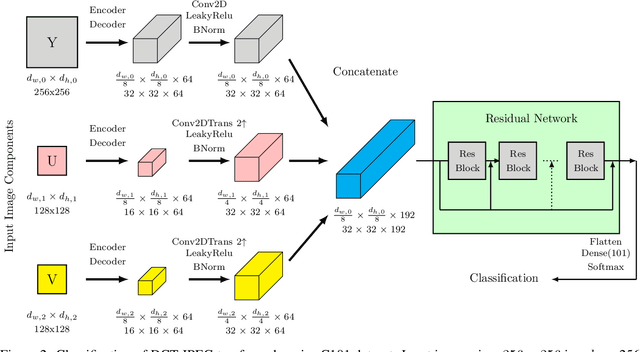
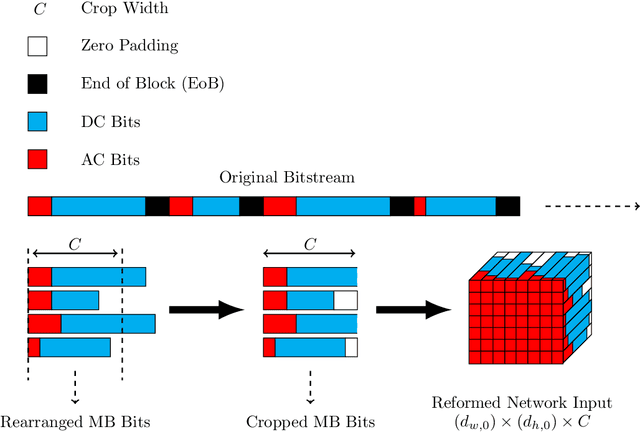
Classification of images within the compressed domain offers significant benefits. These benefits include reduced memory and computational requirements of a classification system. This paper proposes two such methods as a proof of concept: The first classifies within the JPEG image transform domain (i.e. DCT transform data); the second classifies the JPEG compressed binary bitstream directly. These two methods are implemented using Residual Network CNNs and an adapted Vision Transformer. Top-1 accuracy of approximately 70% and 60% were achieved using these methods respectively when classifying the Caltech C101 database. Although these results are significantly behind the state of the art for classification for this database (~95%), it illustrates the first time direct bitstream image classification has been achieved. This work confirms that direct bitstream image classification is possible and could be utilised in a first pass database screening of a raw bitstream (within a wired or wireless network) or where computational, memory and bandwidth requirements are severely restricted.
Reconstruction-guided attention improves the robustness and shape processing of neural networks
Sep 27, 2022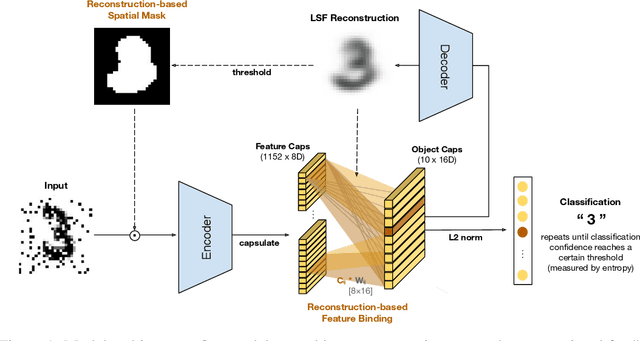
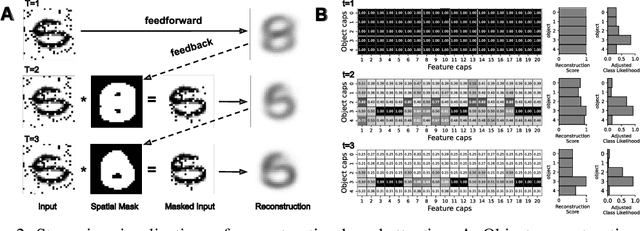
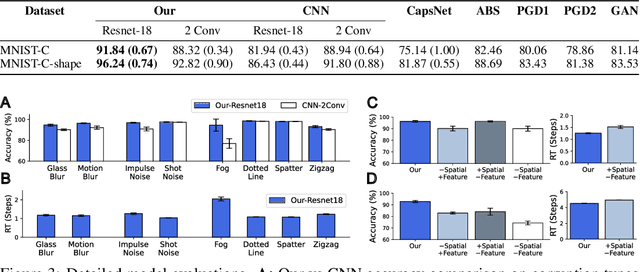
Many visual phenomena suggest that humans use top-down generative or reconstructive processes to create visual percepts (e.g., imagery, object completion, pareidolia), but little is known about the role reconstruction plays in robust object recognition. We built an iterative encoder-decoder network that generates an object reconstruction and used it as top-down attentional feedback to route the most relevant spatial and feature information to feed-forward object recognition processes. We tested this model using the challenging out-of-distribution digit recognition dataset, MNIST-C, where 15 different types of transformation and corruption are applied to handwritten digit images. Our model showed strong generalization performance against various image perturbations, on average outperforming all other models including feedforward CNNs and adversarially trained networks. Our model is particularly robust to blur, noise, and occlusion corruptions, where shape perception plays an important role. Ablation studies further reveal two complementary roles of spatial and feature-based attention in robust object recognition, with the former largely consistent with spatial masking benefits in the attention literature (the reconstruction serves as a mask) and the latter mainly contributing to the model's inference speed (i.e., number of time steps to reach a certain confidence threshold) by reducing the space of possible object hypotheses. We also observed that the model sometimes hallucinates a non-existing pattern out of noise, leading to highly interpretable human-like errors. Our study shows that modeling reconstruction-based feedback endows AI systems with a powerful attention mechanism, which can help us understand the role of generating perception in human visual processing.
Poisson Flow Generative Models
Sep 22, 2022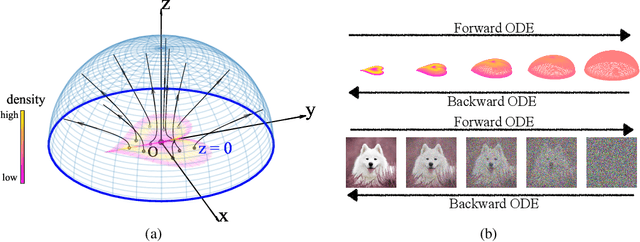
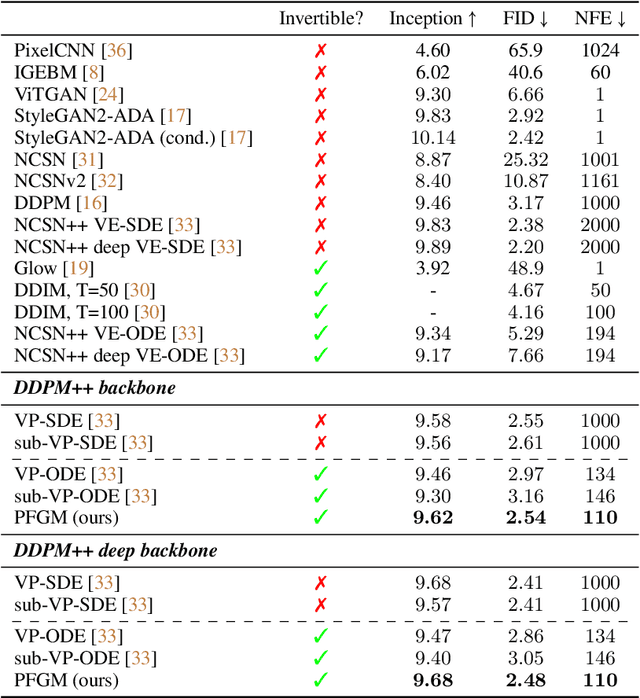
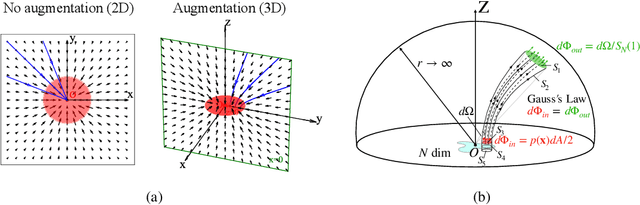

We propose a new "Poisson flow" generative model (PFGM) that maps a uniform distribution on a high-dimensional hemisphere into any data distribution. We interpret the data points as electrical charges on the $z=0$ hyperplane in a space augmented with an additional dimension $z$, generating a high-dimensional electric field (the gradient of the solution to Poisson equation). We prove that if these charges flow upward along electric field lines, their initial distribution in the $z=0$ plane transforms into a distribution on the hemisphere of radius $r$ that becomes uniform in the $r \to\infty$ limit. To learn the bijective transformation, we estimate the normalized field in the augmented space. For sampling, we devise a backward ODE that is anchored by the physically meaningful additional dimension: the samples hit the unaugmented data manifold when the $z$ reaches zero. Experimentally, PFGM achieves current state-of-the-art performance among the normalizing flow models on CIFAR-10, with an Inception score of $9.68$ and a FID score of $2.48$. It also performs on par with the state-of-the-art SDE approaches while offering $10\times $ to $20 \times$ acceleration on image generation tasks. Additionally, PFGM appears more tolerant of estimation errors on a weaker network architecture and robust to the step size in the Euler method. The code is available at https://github.com/Newbeeer/poisson_flow .
TIPS: Text-Induced Pose Synthesis
Jul 24, 2022
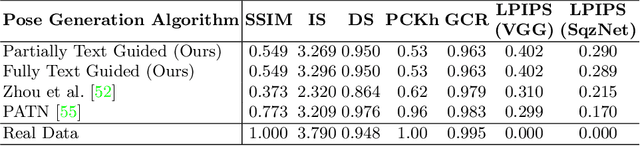
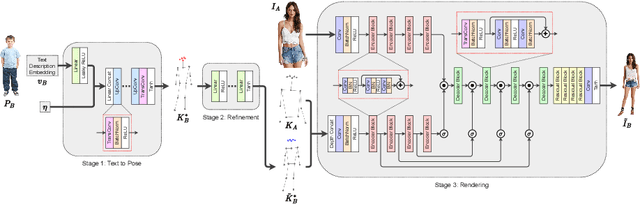
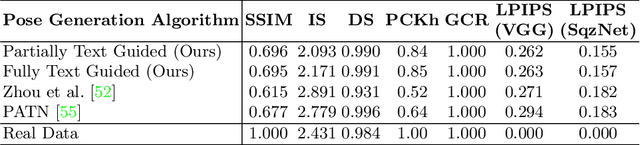
In computer vision, human pose synthesis and transfer deal with probabilistic image generation of a person in a previously unseen pose from an already available observation of that person. Though researchers have recently proposed several methods to achieve this task, most of these techniques derive the target pose directly from the desired target image on a specific dataset, making the underlying process challenging to apply in real-world scenarios as the generation of the target image is the actual aim. In this paper, we first present the shortcomings of current pose transfer algorithms and then propose a novel text-based pose transfer technique to address those issues. We divide the problem into three independent stages: (a) text to pose representation, (b) pose refinement, and (c) pose rendering. To the best of our knowledge, this is one of the first attempts to develop a text-based pose transfer framework where we also introduce a new dataset DF-PASS, by adding descriptive pose annotations for the images of the DeepFashion dataset. The proposed method generates promising results with significant qualitative and quantitative scores in our experiments.