 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Dual-Flow Transformation Network for Deformable Image Registration with Region Consistency Constraint
Dec 04, 2021
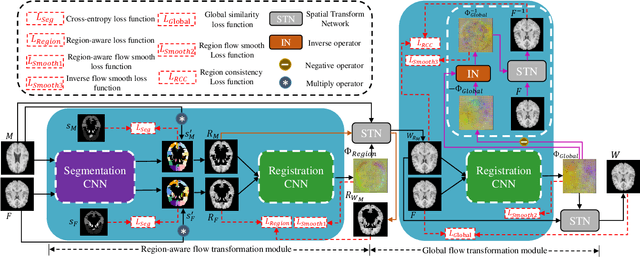
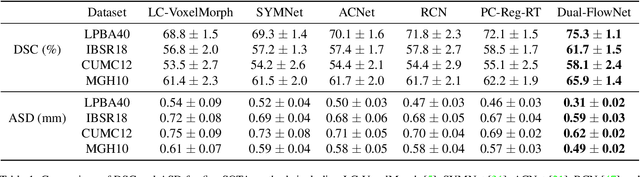
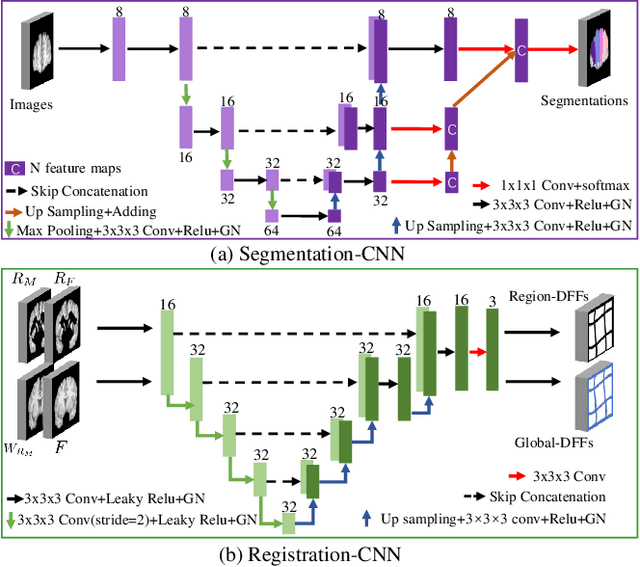

Deformable image registration is able to achieve fast and accurate alignment between a pair of images and thus plays an important role in many medical image studies. The current deep learning (DL)-based image registration approaches directly learn the spatial transformation from one image to another by leveraging a convolutional neural network, requiring ground truth or similarity metric. Nevertheless, these methods only use a global similarity energy function to evaluate the similarity of a pair of images, which ignores the similarity of regions of interest (ROIs) within images. Moreover, DL-based methods often estimate global spatial transformations of image directly, which never pays attention to region spatial transformations of ROIs within images. In this paper, we present a novel dual-flow transformation network with region consistency constraint which maximizes the similarity of ROIs within a pair of images and estimates both global and region spatial transformations simultaneously. Experiments on four public 3D MRI datasets show that the proposed method achieves the best registration performance in accuracy and generalization compared with other state-of-the-art methods.
Generalization Properties of NAS under Activation and Skip Connection Search
Sep 15, 2022
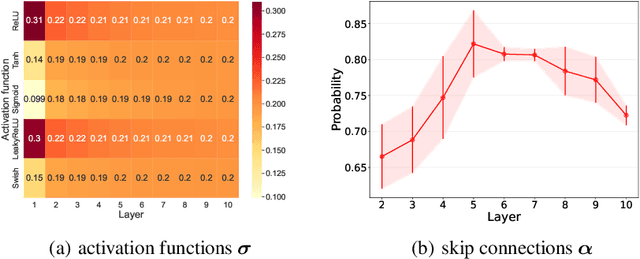
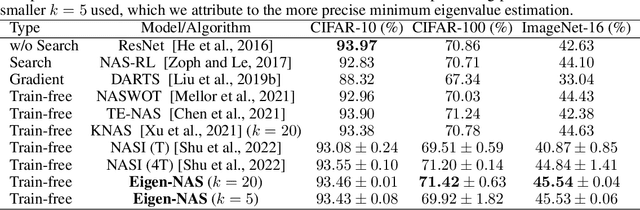
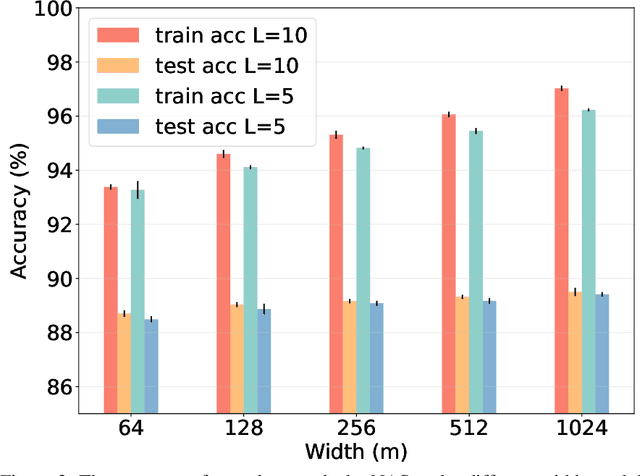
Neural Architecture Search (NAS) has fostered the automatic discovery of neural architectures, which achieve state-of-the-art accuracy in image recognition. Despite the progress achieved with NAS, so far there is little attention to theoretical guarantees on NAS. In this work, we study the generalization properties of NAS under a unifying framework enabling (deep) layer skip connection search and activation function search. To this end, we derive the lower (and upper) bounds of the minimum eigenvalue of Neural Tangent Kernel under the (in)finite width regime from a search space including mixed activation functions, fully connected, and residual neural networks. Our analysis is non-trivial due to the coupling of various architectures and activation functions under the unifying framework. Then, we leverage the eigenvalue bounds to establish generalization error bounds of NAS in the stochastic gradient descent training. Importantly, we theoretically and experimentally show how the derived results can guide NAS to select the top-performing architectures, even in the case without training, leading to a training-free algorithm based on our theory. Accordingly, our numerical validation shed light on the design of computationally efficient methods for NAS.
Motion-Adapted Three-Dimensional Frequency Selective Extrapolation
Sep 15, 2022
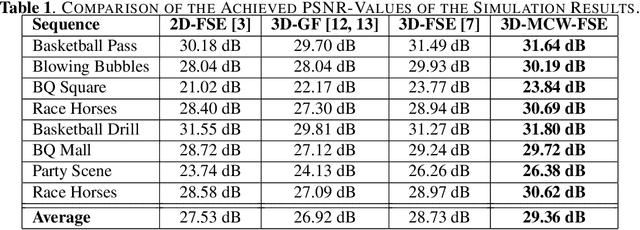
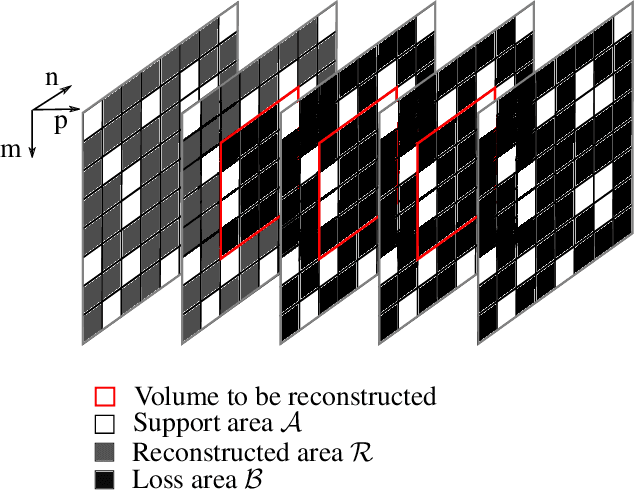
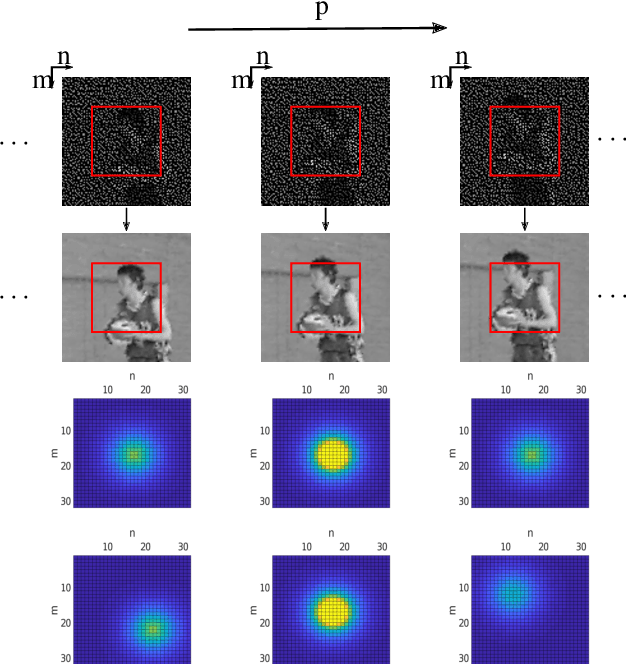
It has been shown, that high resolution images can be acquired using a low resolution sensor with non-regular sampling. Therefore, post-processing is necessary. In terms of video data, not only the spatial neighborhood can be used to assist the reconstruction, but also the temporal neighborhood. A popular and well performing algorithm for this kind of problem is the three-dimensional frequency selective extrapolation (3D-FSE) for which a motion adapted version is introduced in this paper. This proposed extension solves the problem of changing content within the area considered by the 3D-FSE, which is caused by motion within the sequence. Because of this motion, it may happen that regions are emphasized during the reconstruction that are not present in the original signal within the considered area. By that, false content is introduced into the extrapolated sequence, which affects the resulting image quality negatively. The novel extension, presented in the following, incorporates motion data of the sequence in order to adapt the algorithm accordingly, and compensates changing content, resulting in gains of up to 1.75 dB compared to the existing 3D-FSE.
Transformer based Fingerprint Feature Extraction
Sep 08, 2022
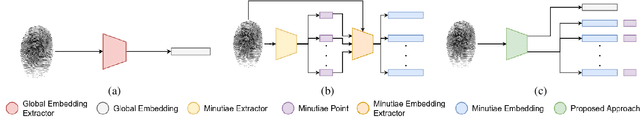
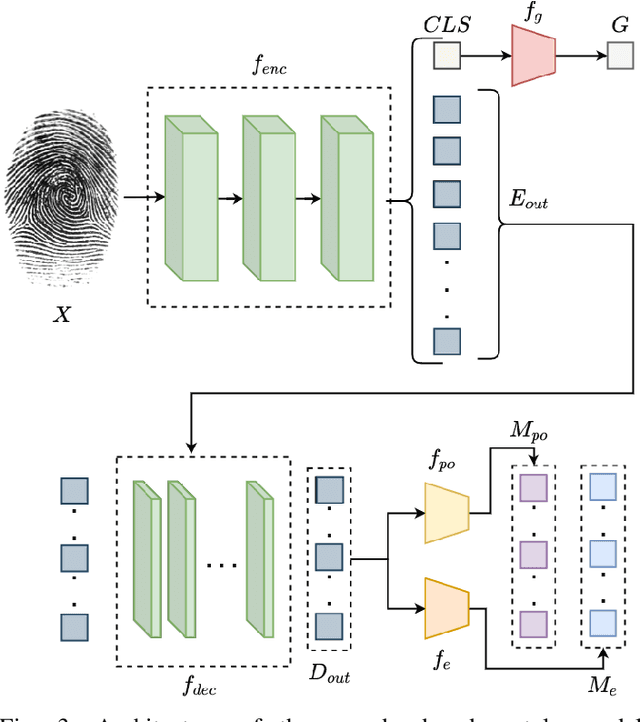
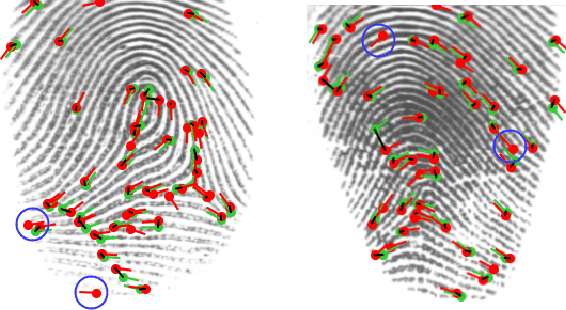
Fingerprint feature extraction is a task that is solved using either a global or a local representation. State-of-the-art global approaches use heavy deep learning models to process the full fingerprint image at once, which makes the corresponding approach memory intensive. On the other hand, local approaches involve minutiae based patch extraction, multiple feature extraction steps and an expensive matching stage, which make the corresponding approach time intensive. However, both these approaches provide useful and sometimes exclusive insights for solving the problem. Using both approaches together for extracting fingerprint representations is semantically useful but quite inefficient. Our convolutional transformer based approach with an in-built minutiae extractor provides a time and memory efficient solution to extract a global as well as a local representation of the fingerprint. The use of these representations along with a smart matching process gives us state-of-the-art performance across multiple databases. The project page can be found at https://saraansh1999.github.io/global-plus-local-fp-transformer.
A Joint Convolution Auto-encoder Network for Infrared and Visible Image Fusion
Jan 26, 2022Background: Leaning redundant and complementary relationships is a critical step in the human visual system. Inspired by the infrared cognition ability of crotalinae animals, we design a joint convolution auto-encoder (JCAE) network for infrared and visible image fusion. Methods: Our key insight is to feed infrared and visible pair images into the network simultaneously and separate an encoder stream into two private branches and one common branch, the private branch works for complementary features learning and the common branch does for redundant features learning. We also build two fusion rules to integrate redundant and complementary features into their fused feature which are then fed into the decoder layer to produce the final fused image. We detail the structure, fusion rule and explain its multi-task loss function. Results: Our JCAE network achieves good results in terms of both subjective effect and objective evaluation metrics.
Denoising single images by feature ensemble revisited
Jul 11, 2022
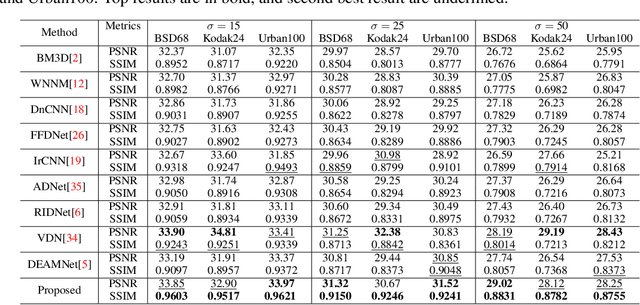
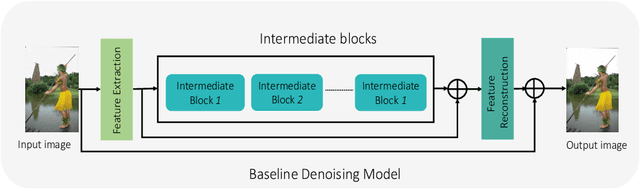

Image denoising is still a challenging issue in many computer vision sub-domains. Recent studies show that significant improvements are made possible in a supervised setting. However, few challenges, such as spatial fidelity and cartoon-like smoothing remain unresolved or decisively overlooked. Our study proposes a simple yet efficient architecture for the denoising problem that addresses the aforementioned issues. The proposed architecture revisits the concept of modular concatenation instead of long and deeper cascaded connections, to recover a cleaner approximation of the given image. We find that different modules can capture versatile representations, and concatenated representation creates a richer subspace for low-level image restoration. The proposed architecture's number of parameters remains smaller than the number for most of the previous networks and still achieves significant improvements over the current state-of-the-art networks.
Resolving Copycat Problems in Visual Imitation Learning via Residual Action Prediction
Jul 20, 2022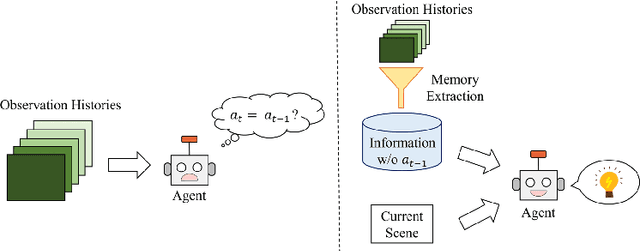

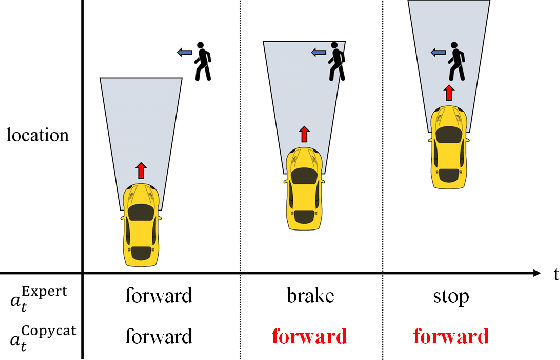
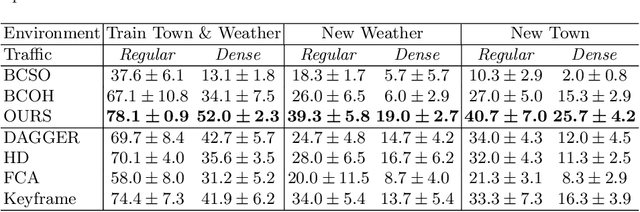
Imitation learning is a widely used policy learning method that enables intelligent agents to acquire complex skills from expert demonstrations. The input to the imitation learning algorithm is usually composed of both the current observation and historical observations since the most recent observation might not contain enough information. This is especially the case with image observations, where a single image only includes one view of the scene, and it suffers from a lack of motion information and object occlusions. In theory, providing multiple observations to the imitation learning agent will lead to better performance. However, surprisingly people find that sometimes imitation from observation histories performs worse than imitation from the most recent observation. In this paper, we explain this phenomenon from the information flow within the neural network perspective. We also propose a novel imitation learning neural network architecture that does not suffer from this issue by design. Furthermore, our method scales to high-dimensional image observations. Finally, we benchmark our approach on two widely used simulators, CARLA and MuJoCo, and it successfully alleviates the copycat problem and surpasses the existing solutions.
Uncertainty Quantification for Deep Unrolling-Based Computational Imaging
Jul 02, 2022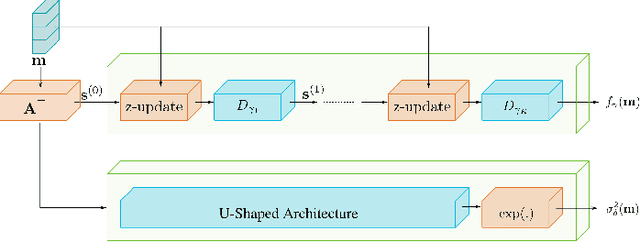
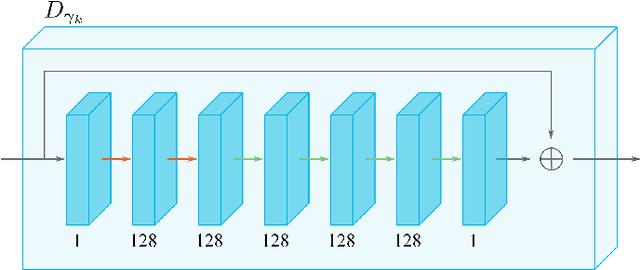

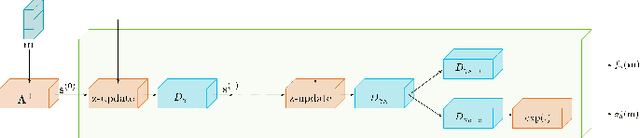
Deep unrolling is an emerging deep learning-based image reconstruction methodology that bridges the gap between model-based and purely deep learning-based image reconstruction methods. Although deep unrolling methods achieve state-of-the-art performance for imaging problems and allow the incorporation of the observation model into the reconstruction process, they do not provide any uncertainty information about the reconstructed image, which severely limits their use in practice, especially for safety-critical imaging applications. In this paper, we propose a learning-based image reconstruction framework that incorporates the observation model into the reconstruction task and that is capable of quantifying epistemic and aleatoric uncertainties, based on deep unrolling and Bayesian neural networks. We demonstrate the uncertainty characterization capability of the proposed framework on magnetic resonance imaging and computed tomography reconstruction problems. We investigate the characteristics of the epistemic and aleatoric uncertainty information provided by the proposed framework to motivate future research on utilizing uncertainty information to develop more accurate, robust, trustworthy, uncertainty-aware, learning-based image reconstruction and analysis methods for imaging problems. We show that the proposed framework can provide uncertainty information while achieving comparable reconstruction performance to state-of-the-art deep unrolling methods.
BigColor: Colorization using a Generative Color Prior for Natural Images
Jul 20, 2022
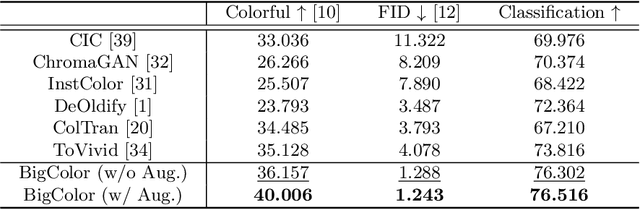
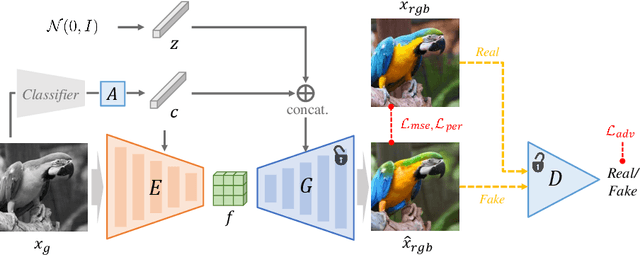
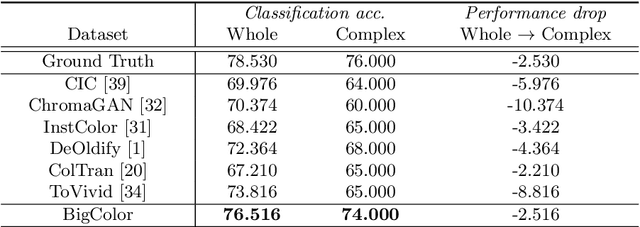
For realistic and vivid colorization, generative priors have recently been exploited. However, such generative priors often fail for in-the-wild complex images due to their limited representation space. In this paper, we propose BigColor, a novel colorization approach that provides vivid colorization for diverse in-the-wild images with complex structures. While previous generative priors are trained to synthesize both image structures and colors, we learn a generative color prior to focus on color synthesis given the spatial structure of an image. In this way, we reduce the burden of synthesizing image structures from the generative prior and expand its representation space to cover diverse images. To this end, we propose a BigGAN-inspired encoder-generator network that uses a spatial feature map instead of a spatially-flattened BigGAN latent code, resulting in an enlarged representation space. Our method enables robust colorization for diverse inputs in a single forward pass, supports arbitrary input resolutions, and provides multi-modal colorization results. We demonstrate that BigColor significantly outperforms existing methods especially on in-the-wild images with complex structures.
Cartoon Explanations of Image Classifiers
Oct 07, 2021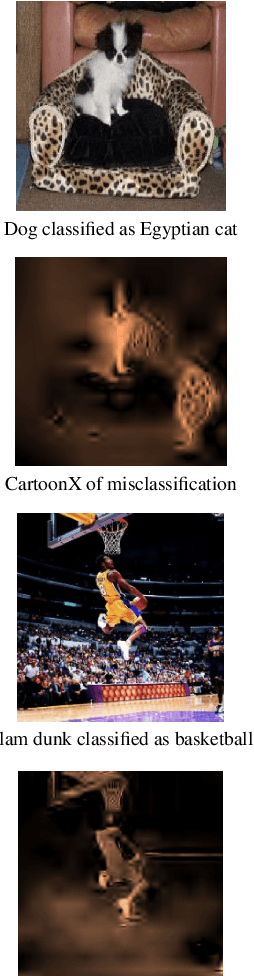
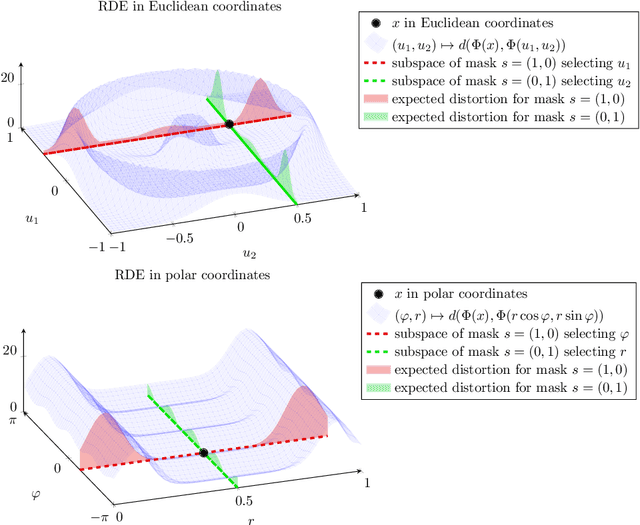
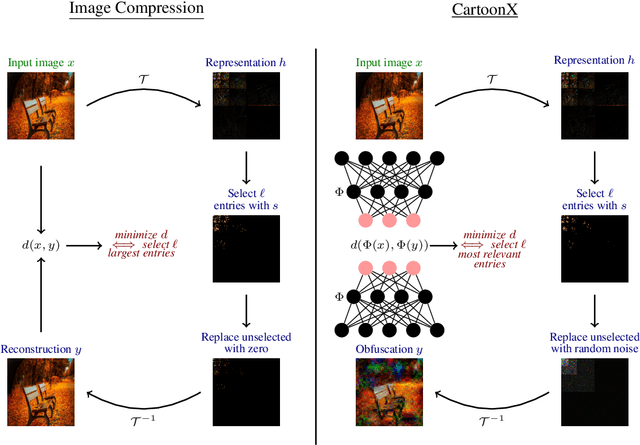
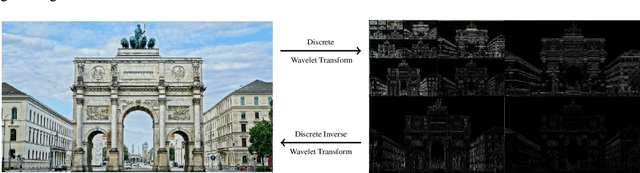
We present CartoonX (Cartoon Explanation), a novel model-agnostic explanation method tailored towards image classifiers and based on the rate-distortion explanation (RDE) framework. Natural images are roughly piece-wise smooth signals -- also called cartoon images -- and tend to be sparse in the wavelet domain. CartoonX is the first explanation method to exploit this by requiring its explanations to be sparse in the wavelet domain, thus extracting the \emph{relevant piece-wise smooth} part of an image instead of relevant pixel-sparse regions. We demonstrate experimentally that CartoonX is not only highly interpretable due to its piece-wise smooth nature but also particularly apt at explaining misclassifications.