 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Optimizing Latent Space Directions For GAN-based Local Image Editing
Nov 24, 2021
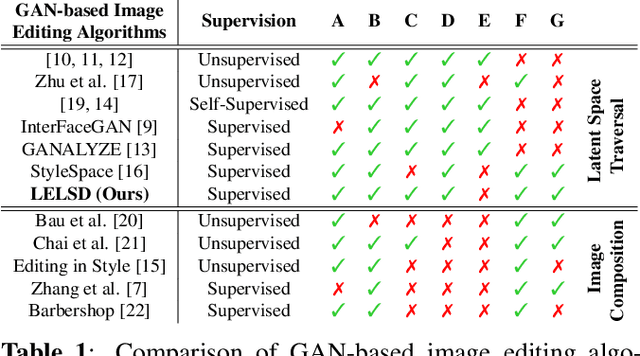
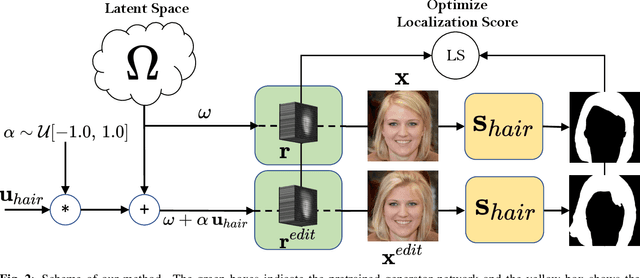


Generative Adversarial Network (GAN) based localized image editing can suffer ambiguity between semantic attributes. We thus present a novel objective function to evaluate the locality of an image edit. By introducing the supervision from a pre-trained segmentation network and optimizing the objective function, our framework, called Locally Effective Latent Space Direction (LELSD), is applicable to any dataset and GAN architecture. Our method is also computationally fast and exhibits a high extent of disentanglement, which allows users to interactively perform a sequence of edits on an image. Our experiments on both GAN-generated and real images qualitatively demonstrate the high quality and advantages of our method.
Transformer based Fingerprint Feature Extraction
Sep 08, 2022
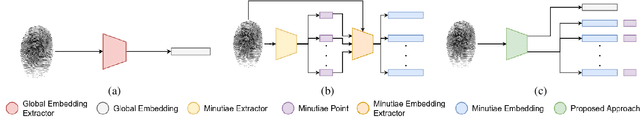
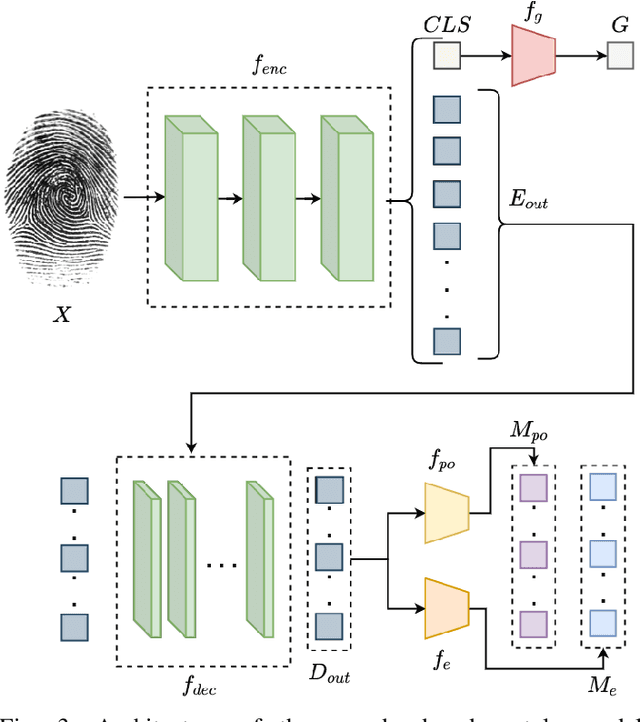
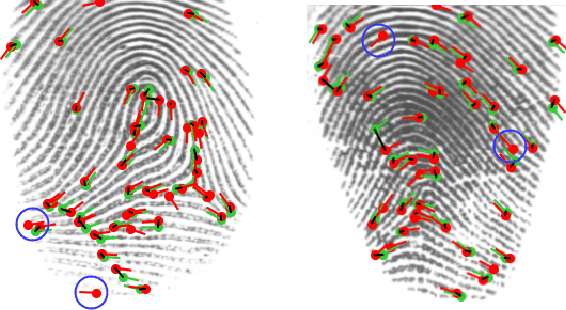
Fingerprint feature extraction is a task that is solved using either a global or a local representation. State-of-the-art global approaches use heavy deep learning models to process the full fingerprint image at once, which makes the corresponding approach memory intensive. On the other hand, local approaches involve minutiae based patch extraction, multiple feature extraction steps and an expensive matching stage, which make the corresponding approach time intensive. However, both these approaches provide useful and sometimes exclusive insights for solving the problem. Using both approaches together for extracting fingerprint representations is semantically useful but quite inefficient. Our convolutional transformer based approach with an in-built minutiae extractor provides a time and memory efficient solution to extract a global as well as a local representation of the fingerprint. The use of these representations along with a smart matching process gives us state-of-the-art performance across multiple databases. The project page can be found at https://saraansh1999.github.io/global-plus-local-fp-transformer.
QSAM-Net: Rain streak removal by quaternion neural network with self-attention module
Aug 08, 2022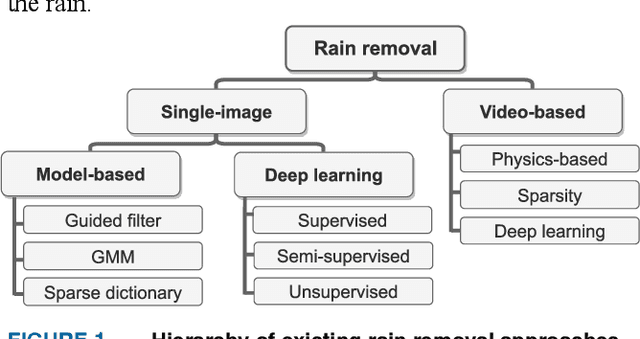
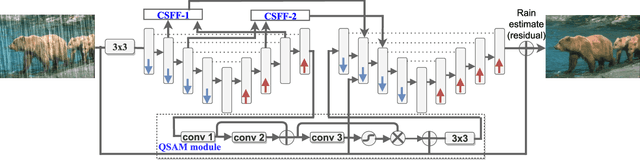


Images captured in real-world applications in remote sensing, image or video retrieval, and outdoor surveillance suffer degraded quality introduced by poor weather conditions. Conditions such as rain and mist, introduce artifacts that make visual analysis challenging and limit the performance of high-level computer vision methods. For time-critical applications where a rapid response is necessary, it becomes crucial to develop algorithms that automatically remove rain, without diminishing the quality of the image contents. This article aims to develop a novel quaternion multi-stage multiscale neural network with a self-attention module called QSAM-Net to remove rain streaks. The novelty of this algorithm is that it requires significantly fewer parameters by a factor of 3.98, over prior methods, while improving visual quality. This is demonstrated by the extensive evaluation and benchmarking on synthetic and real-world rainy images. This feature of QSAM-Net makes the network suitable for implementation on edge devices and applications requiring near real-time performance. The experiments demonstrate that by improving the visual quality of images. In addition, object detection accuracy and training speed are also improved.
Revisiting Rolling Shutter Bundle Adjustment: Toward Accurate and Fast Solution
Sep 18, 2022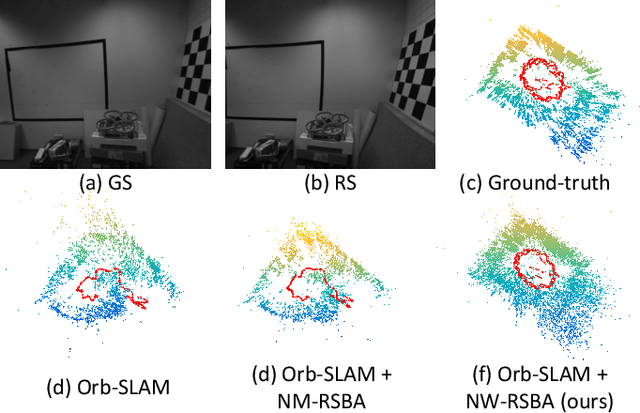
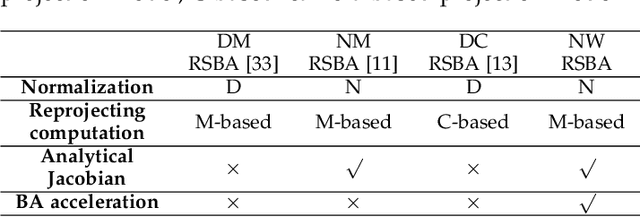
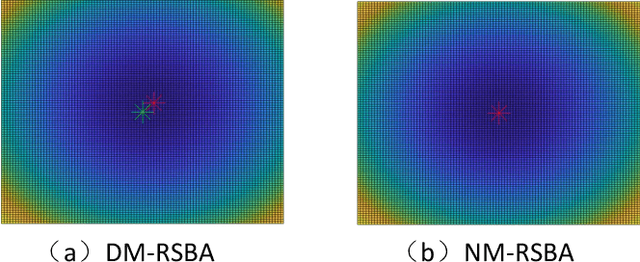
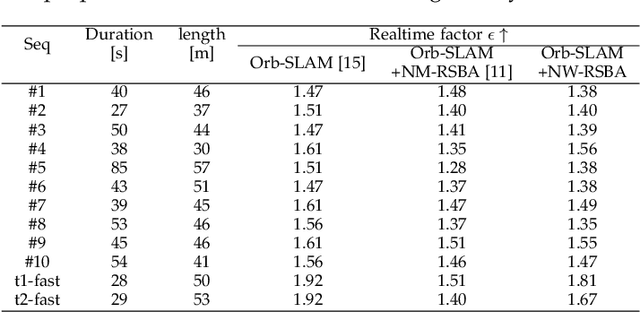
We propose a robust and fast bundle adjustment solution that estimates the 6-DoF pose of the camera and the geometry of the environment based on measurements from a rolling shutter (RS) camera. This tackles the challenges in the existing works, namely relying on additional sensors, high frame rate video as input, restrictive assumptions on camera motion, readout direction, and poor efficiency. To this end, we first investigate the influence of normalization to the image point on RSBA performance and show its better approximation in modelling the real 6-DoF camera motion. Then we present a novel analytical model for the visual residual covariance, which can be used to standardize the reprojection error during the optimization, consequently improving the overall accuracy. More importantly, the combination of normalization and covariance standardization weighting in RSBA (NW-RSBA) can avoid common planar degeneracy without needing to constrain the filming manner. Besides, we propose an acceleration strategy for NW-RSBA based on the sparsity of its Jacobian matrix and Schur complement. The extensive synthetic and real data experiments verify the effectiveness and efficiency of the proposed solution over the state-of-the-art works. We also demonstrate the proposed method can be easily implemented and plug-in famous GSSfM and GSSLAM systems as completed RSSfM and RSSLAM solutions.
Is a Caption Worth a Thousand Images? A Controlled Study for Representation Learning
Jul 15, 2022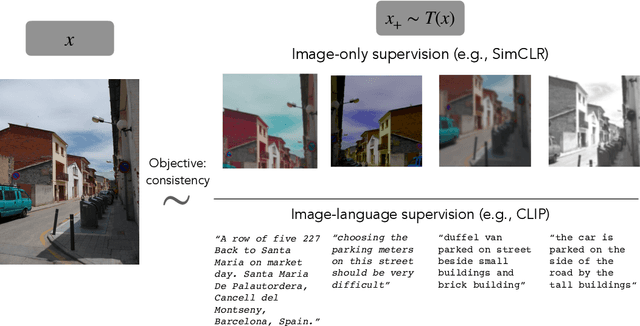
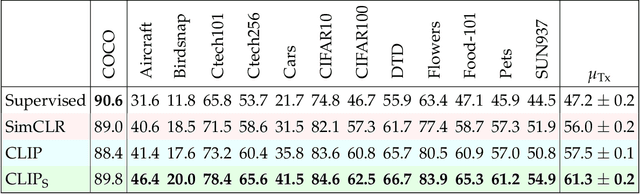

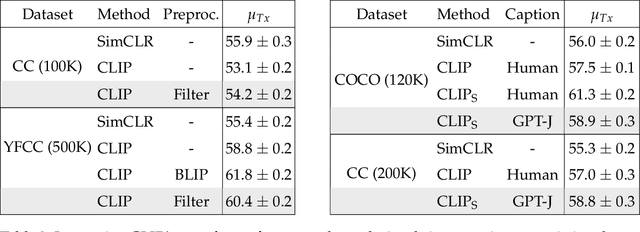
The development of CLIP [Radford et al., 2021] has sparked a debate on whether language supervision can result in vision models with more transferable representations than traditional image-only methods. Our work studies this question through a carefully controlled comparison of two approaches in terms of their ability to learn representations that generalize to downstream classification tasks. We find that when the pre-training dataset meets certain criteria -- it is sufficiently large and contains descriptive captions with low variability -- image-only methods do not match CLIP's transfer performance, even when they are trained with more image data. However, contrary to what one might expect, there are practical settings in which these criteria are not met, wherein added supervision through captions is actually detrimental. Motivated by our findings, we devise simple prescriptions to enable CLIP to better leverage the language information present in existing pre-training datasets.
Generative Memory-Guided Semantic Reasoning Model for Image Inpainting
Oct 01, 2021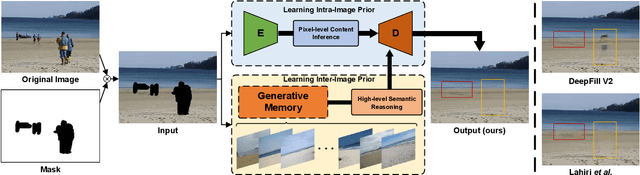

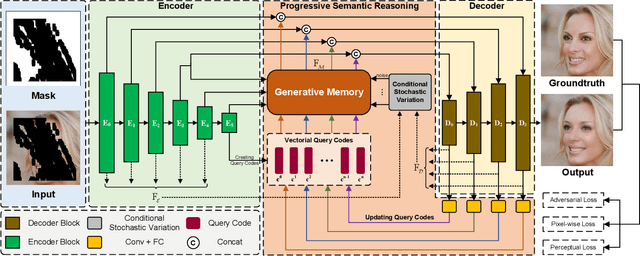
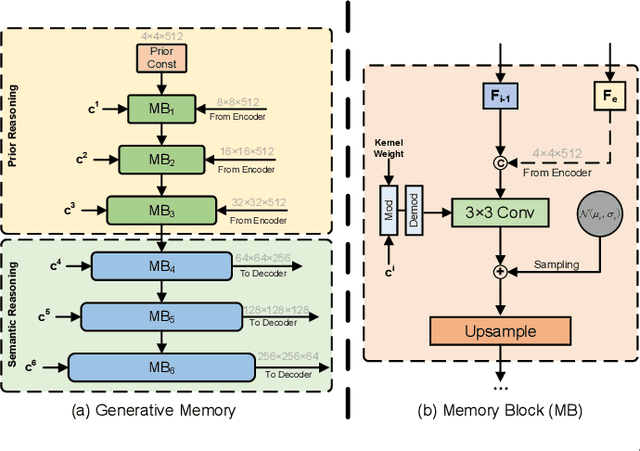
Most existing methods for image inpainting focus on learning the intra-image priors from the known regions of the current input image to infer the content of the corrupted regions in the same image. While such methods perform well on images with small corrupted regions, it is challenging for these methods to deal with images with large corrupted area due to two potential limitations: 1) such methods tend to overfit each single training pair of images relying solely on the intra-image prior knowledge learned from the limited known area; 2) the inter-image prior knowledge about the general distribution patterns of visual semantics, which can be transferred across images sharing similar semantics, is not exploited. In this paper, we propose the Generative Memory-Guided Semantic Reasoning Model (GM-SRM), which not only learns the intra-image priors from the known regions, but also distills the inter-image reasoning priors to infer the content of the corrupted regions. In particular, the proposed GM-SRM first pre-learns a generative memory from the whole training data to capture the semantic distribution patterns in a global view. Then the learned memory are leveraged to retrieve the matching inter-image priors for the current corrupted image to perform semantic reasoning during image inpainting. While the intra-image priors are used for guaranteeing the pixel-level content consistency, the inter-image priors are favorable for performing high-level semantic reasoning, which is particularly effective for inferring semantic content for large corrupted area. Extensive experiments on Paris Street View, CelebA-HQ, and Places2 benchmarks demonstrate that our GM-SRM outperforms the state-of-the-art methods for image inpainting in terms of both the visual quality and quantitative metrics.
Few-Shot Real Image Restoration via Distortion-Relation Guided Transfer Learning
Nov 25, 2021



Collecting large clean-distorted training image pairs in real world is non-trivial, which seriously limits the practical applications of these supervised learning based image restoration (IR) methods. Previous works attempt to address this problem by leveraging unsupervised learning technologies to alleviate the dependency for paired training samples. However, these methods typically suffer from unsatisfactory textures synthesis due to the lack of clean image supervision. Compared with purely unsupervised solution, the under-explored scheme with Few-Shot clean images (FS-IR) is more feasible to tackle this challenging real Image Restoration task. In this paper, we are the first to investigate the few-shot real image restoration and propose a Distortion-Relation guided Transfer Learning (termed as DRTL) framework. DRTL assigns a knowledge graph to capture the distortion relation between auxiliary tasks (i.e., synthetic distortions) and target tasks (i.e., real distortions with few images), and then adopt a gradient weighting strategy to guide the knowledge transfer from auxiliary task to target task. In this way, DRTL could quickly learn the most relevant knowledge from the prior distortions for target distortion. We instantiate DRTL integrated with pre-training and meta-learning pipelines as an embodiment to realize a distortion-relation aware FS-IR. Extensive experiments on multiple benchmarks demonstrate the effectiveness of DRTL on few-shot real image restoration.
The Importance of the Instantaneous Phase in Detecting Faces with Convolutional Neural Networks
Aug 03, 2022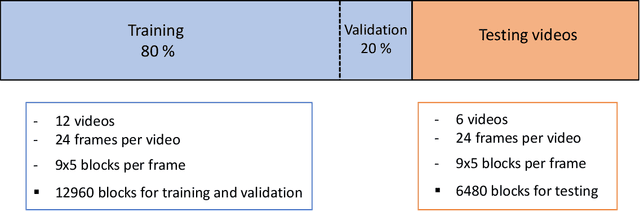

Convolutional Neural Networks (CNN) have provided new and accurate methods for processing digital images and videos. Yet, training CNNs is extremely demanding in terms of computational resources. Also, for specific applications, the standard use of transfer learning also tends to require far more resources than what may be needed. Furthermore, the final systems tend to operate as black boxes that are difficult to interpret. The current thesis considers the problem of detecting faces from the AOLME video dataset. The AOLME dataset consists of a large video collection of group interactions that are recorded in unconstrained classroom environments. For the thesis, still image frames were extracted at every minute from 18 24-minute videos. Then, each video frame was divided into 9x5 blocks with 50x50 pixels each. For each of the 19440 blocks, the percentage of face pixels was set as ground truth. Face detection was then defined as a regression problem for determining the face pixel percentage for each block. For testing different methods, 12 videos were used for training and validation. The remaining 6 videos were used for testing. The thesis examines the impact of using the instantaneous phase for the AOLME block-based face detection application. For comparison, the thesis compares the use of the Frequency Modulation image based on the instantaneous phase, the use of the instantaneous amplitude, and the original gray scale image. To generate the FM and AM inputs, the thesis uses dominant component analysis that aims to decrease the training overhead while maintaining interpretability.
FIBA: Frequency-Injection based Backdoor Attack in Medical Image Analysis
Dec 02, 2021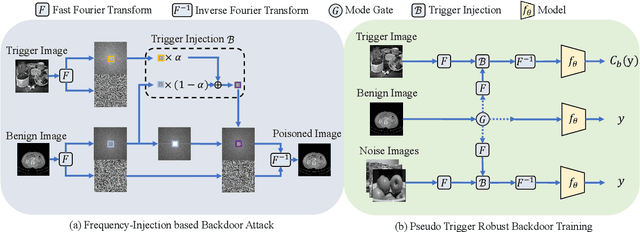
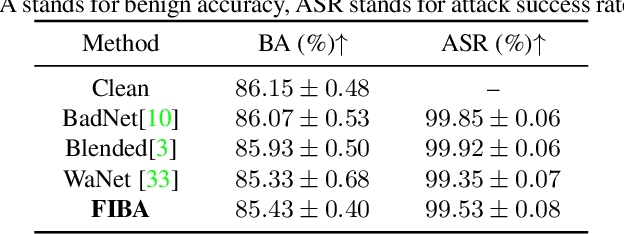
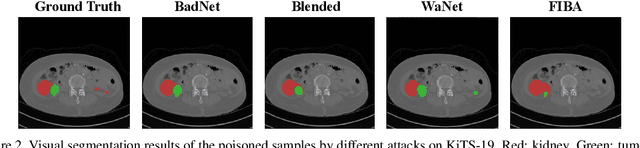

In recent years, the security of AI systems has drawn increasing research attention, especially in the medical imaging realm. To develop a secure medical image analysis (MIA) system, it is a must to study possible backdoor attacks (BAs), which can embed hidden malicious behaviors into the system. However, designing a unified BA method that can be applied to various MIA systems is challenging due to the diversity of imaging modalities (e.g., X-Ray, CT, and MRI) and analysis tasks (e.g., classification, detection, and segmentation). Most existing BA methods are designed to attack natural image classification models, which apply spatial triggers to training images and inevitably corrupt the semantics of poisoned pixels, leading to the failures of attacking dense prediction models. To address this issue, we propose a novel Frequency-Injection based Backdoor Attack method (FIBA) that is capable of delivering attacks in various MIA tasks. Specifically, FIBA leverages a trigger function in the frequency domain that can inject the low-frequency information of a trigger image into the poisoned image by linearly combining the spectral amplitude of both images. Since it preserves the semantics of the poisoned image pixels, FIBA can perform attacks on both classification and dense prediction models. Experiments on three benchmarks in MIA (i.e., ISIC-2019 for skin lesion classification, KiTS-19 for kidney tumor segmentation, and EAD-2019 for endoscopic artifact detection), validate the effectiveness of FIBA and its superiority over state-of-the-art methods in attacking MIA models as well as bypassing backdoor defense. The code will be available at https://github.com/HazardFY/FIBA.
Deep Convolutional Neural Network and Transfer Learning for Locomotion Intent Prediction
Sep 26, 2022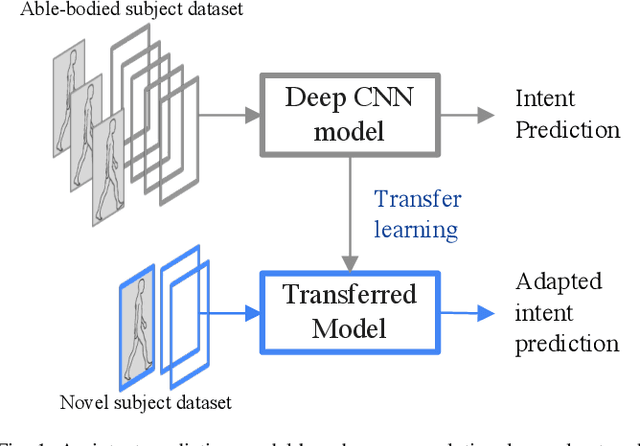
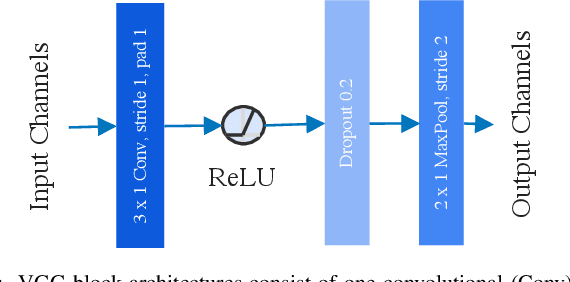
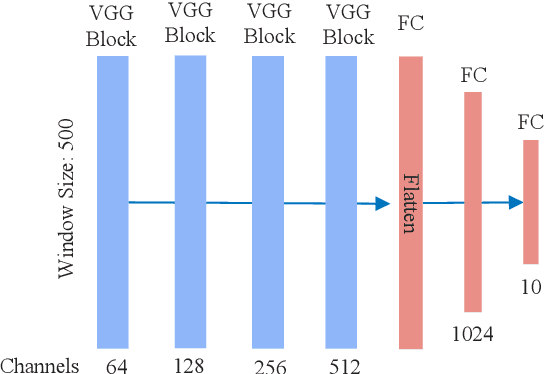
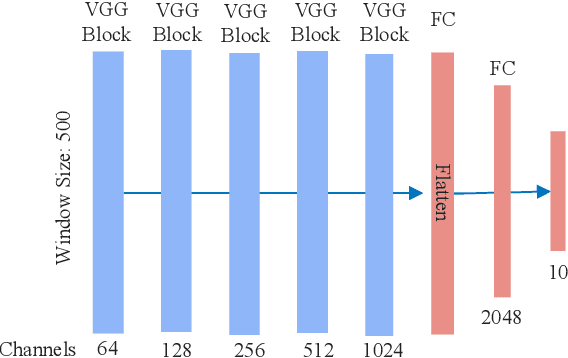
Powered prosthetic legs must anticipate the user's intent when switching between different locomotion modes (e.g., level walking, stair ascent/descent, ramp ascent/descent). Numerous data-driven classification techniques have demonstrated promising results for predicting user intent, but the performance of these intent prediction models on novel subjects remains undesirable. In other domains (e.g., image classification), transfer learning has improved classification accuracy by using previously learned features from a large dataset (i.e., pre-trained models) and then transferring this learned model to a new task where a smaller dataset is available. In this paper, we develop a deep convolutional neural network with intra-subject (subject-dependent) and inter-subject (subject-independent) validations based on a human locomotion dataset. We then apply transfer learning for the subject-independent model using a small portion (10%) of the data from the left-out subject. We compare the performance of these three models. Our results indicate that the transfer learning (TL) model outperforms the subject-independent (IND) model and is comparable to the subject-dependent (DEP) model (DEP Error: 0.74 $\pm$ 0.002%, IND Error: 11.59 $\pm$ 0.076%, TL Error: 3.57 $\pm$ 0.02% with 10% data). Moreover, as expected, transfer learning accuracy increases with the availability of more data from the left-out subject. We also evaluate the performance of the intent prediction system in various sensor configurations that may be available in a prosthetic leg application. Our results suggest that a thigh IMU on the the prosthesis is sufficient to predict locomotion intent in practice.