 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Multi-scale Transformer for Medical Image Segmentation: Architectures, Model Efficiency, and Benchmarks
Mar 03, 2022
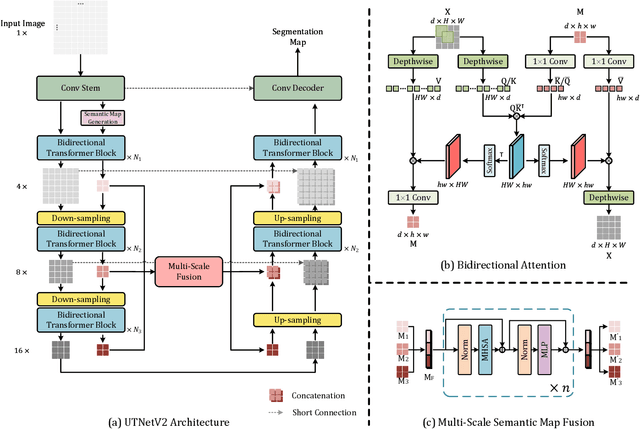
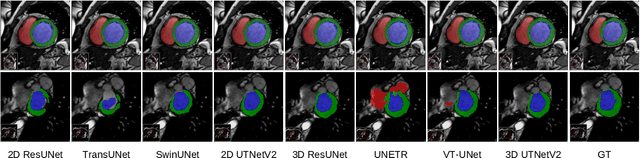
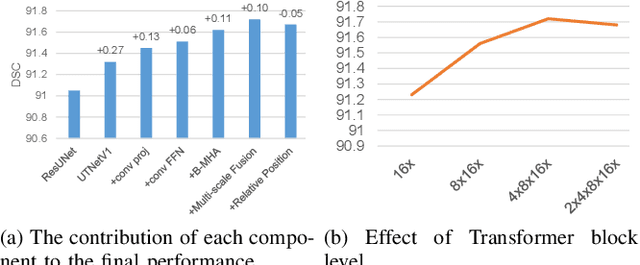
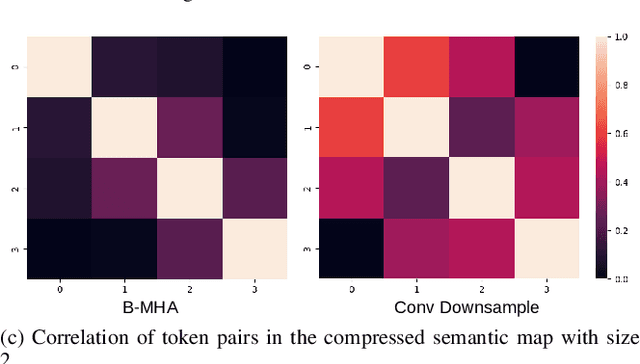
Transformers have emerged to be successful in a number of natural language processing and vision tasks, but their potential applications to medical imaging remain largely unexplored due to the unique difficulties of this field. In this study, we present UTNetV2, a simple yet powerful backbone model that combines the strengths of the convolutional neural network and Transformer for enhancing performance and efficiency in medical image segmentation. The critical design of UTNetV2 includes three innovations: (1) We used a hybrid hierarchical architecture by introducing depthwise separable convolution to projection and feed-forward network in the Transformer block, which brings local relationship modeling and desirable properties of CNNs (translation invariance) to Transformer, thus eliminate the requirement of large-scale pre-training. (2) We proposed efficient bidirectional attention (B-MHA) that reduces the quadratic computation complexity of self-attention to linear by introducing an adaptively updated semantic map. The efficient attention makes it possible to capture long-range relationship and correct the fine-grained errors in high-resolution token maps. (3) The semantic maps in the B-MHA allow us to perform semantically and spatially global multi-scale feature fusion without introducing much computational overhead. Furthermore, we provide a fair comparison codebase of CNN-based and Transformer-based on various medical image segmentation tasks to evaluate the merits and defects of both architectures. UTNetV2 demonstrated state-of-the-art performance across various settings, including large-scale datasets, small-scale datasets, 2D and 3D settings.
BoxShrink: From Bounding Boxes to Segmentation Masks
Aug 05, 2022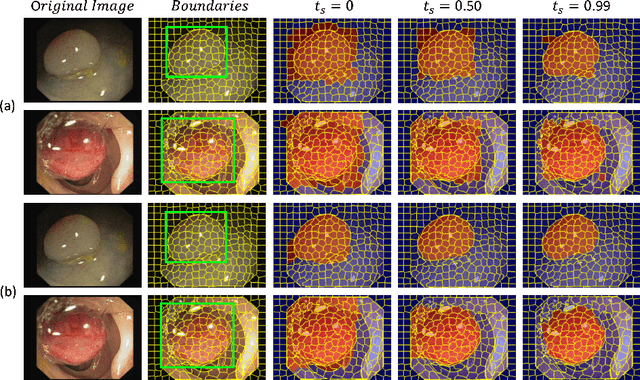
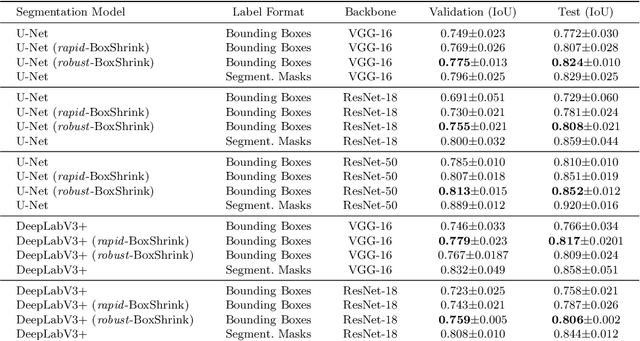
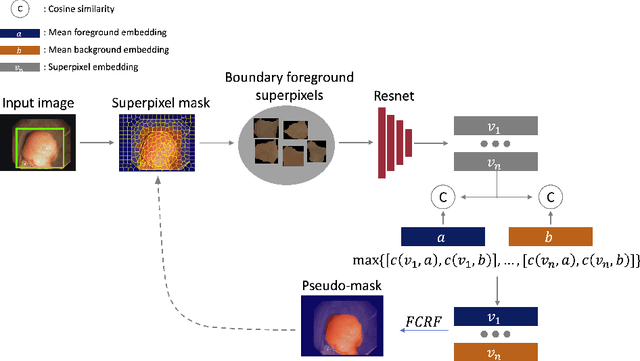
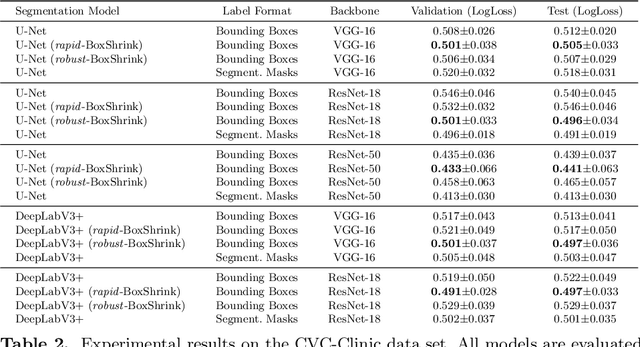
One of the core challenges facing the medical image computing community is fast and efficient data sample labeling. Obtaining fine-grained labels for segmentation is particularly demanding since it is expensive, time-consuming, and requires sophisticated tools. On the contrary, applying bounding boxes is fast and takes significantly less time than fine-grained labeling, but does not produce detailed results. In response, we propose a novel framework for weakly-supervised tasks with the rapid and robust transformation of bounding boxes into segmentation masks without training any machine learning model, coined BoxShrink. The proposed framework comes in two variants - rapid-BoxShrink for fast label transformations, and robust-BoxShrink for more precise label transformations. An average of four percent improvement in IoU is found across several models when being trained using BoxShrink in a weakly-supervised setting, compared to using only bounding box annotations as inputs on a colonoscopy image data set. We open-sourced the code for the proposed framework and published it online.
On the Surprising Effectiveness of Transformers in Low-Labeled Video Recognition
Sep 15, 2022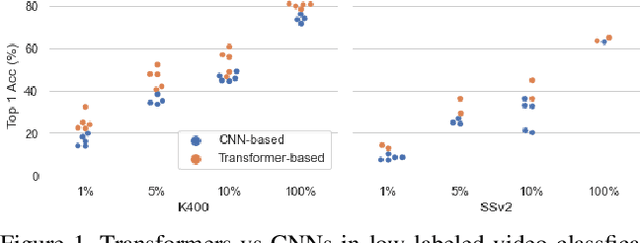
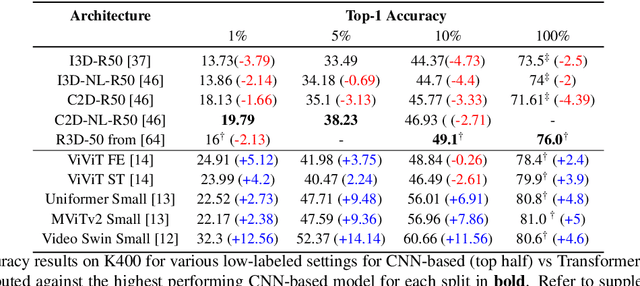
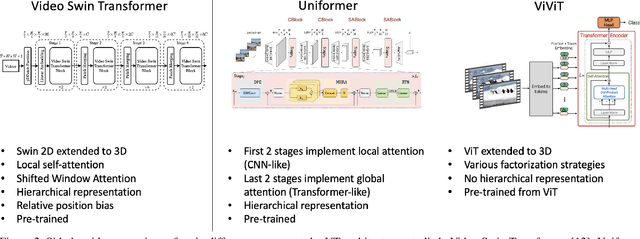

Recently vision transformers have been shown to be competitive with convolution-based methods (CNNs) broadly across multiple vision tasks. The less restrictive inductive bias of transformers endows greater representational capacity in comparison with CNNs. However, in the image classification setting this flexibility comes with a trade-off with respect to sample efficiency, where transformers require ImageNet-scale training. This notion has carried over to video where transformers have not yet been explored for video classification in the low-labeled or semi-supervised settings. Our work empirically explores the low data regime for video classification and discovers that, surprisingly, transformers perform extremely well in the low-labeled video setting compared to CNNs. We specifically evaluate video vision transformers across two contrasting video datasets (Kinetics-400 and SomethingSomething-V2) and perform thorough analysis and ablation studies to explain this observation using the predominant features of video transformer architectures. We even show that using just the labeled data, transformers significantly outperform complex semi-supervised CNN methods that leverage large-scale unlabeled data as well. Our experiments inform our recommendation that semi-supervised learning video work should consider the use of video transformers in the future.
Continuous Facial Motion Deblurring
Jul 14, 2022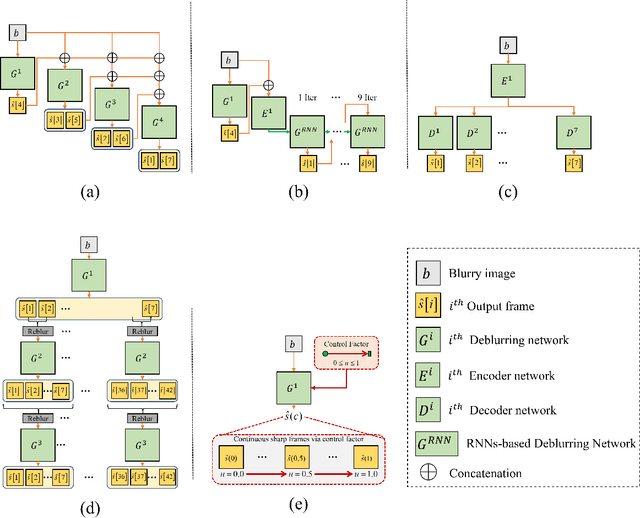
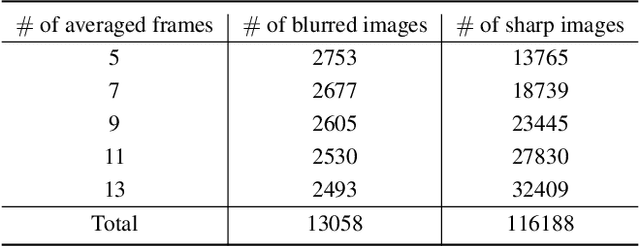

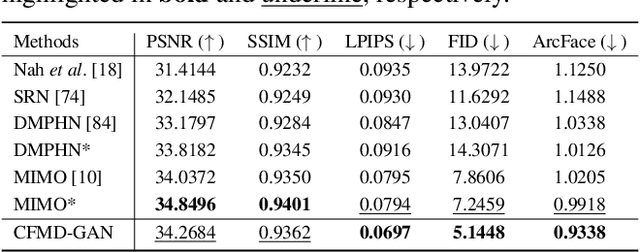
We introduce a novel framework for continuous facial motion deblurring that restores the continuous sharp moment latent in a single motion-blurred face image via a moment control factor. Although a motion-blurred image is the accumulated signal of continuous sharp moments during the exposure time, most existing single image deblurring approaches aim to restore a fixed number of frames using multiple networks and training stages. To address this problem, we propose a continuous facial motion deblurring network based on GAN (CFMD-GAN), which is a novel framework for restoring the continuous moment latent in a single motion-blurred face image with a single network and a single training stage. To stabilize the network training, we train the generator to restore continuous moments in the order determined by our facial motion-based reordering process (FMR) utilizing domain-specific knowledge of the face. Moreover, we propose an auxiliary regressor that helps our generator produce more accurate images by estimating continuous sharp moments. Furthermore, we introduce a control-adaptive (ContAda) block that performs spatially deformable convolution and channel-wise attention as a function of the control factor. Extensive experiments on the 300VW datasets demonstrate that the proposed framework generates a various number of continuous output frames by varying the moment control factor. Compared with the recent single-to-single image deblurring networks trained with the same 300VW training set, the proposed method show the superior performance in restoring the central sharp frame in terms of perceptual metrics, including LPIPS, FID and Arcface identity distance. The proposed method outperforms the existing single-to-video deblurring method for both qualitative and quantitative comparisons.
A Continual Development Methodology for Large-scale Multitask Dynamic ML Systems
Sep 15, 2022
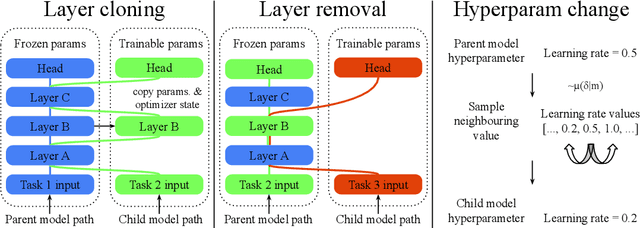
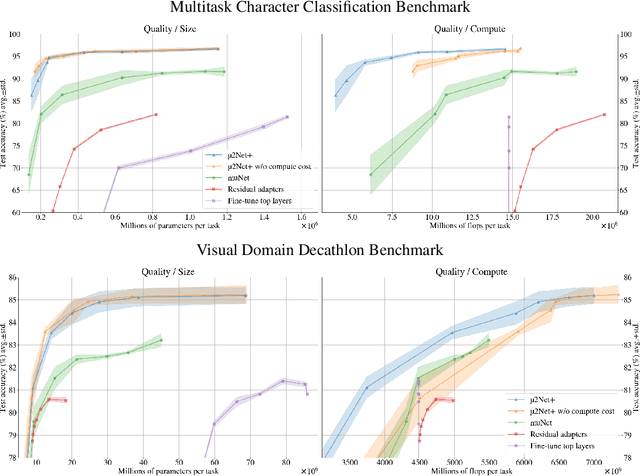
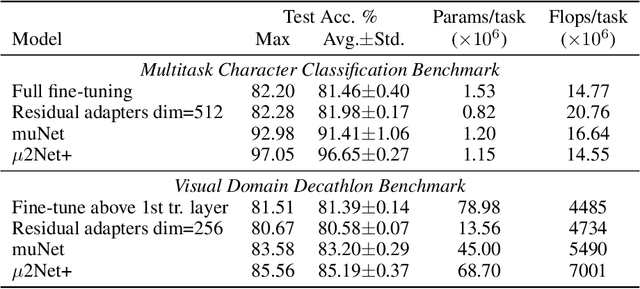
The traditional Machine Learning (ML) methodology requires to fragment the development and experimental process into disconnected iterations whose feedback is used to guide design or tuning choices. This methodology has multiple efficiency and scalability disadvantages, such as leading to spend significant resources into the creation of multiple trial models that do not contribute to the final solution.The presented work is based on the intuition that defining ML models as modular and extensible artefacts allows to introduce a novel ML development methodology enabling the integration of multiple design and evaluation iterations into the continuous enrichment of a single unbounded intelligent system. We define a novel method for the generation of dynamic multitask ML models as a sequence of extensions and generalizations. We first analyze the capabilities of the proposed method by using the standard ML empirical evaluation methodology. Finally, we propose a novel continuous development methodology that allows to dynamically extend a pre-existing multitask large-scale ML system while analyzing the properties of the proposed method extensions. This results in the generation of an ML model capable of jointly solving 124 image classification tasks achieving state of the art quality with improved size and compute cost.
Gradient-based Uncertainty for Monocular Depth Estimation
Aug 03, 2022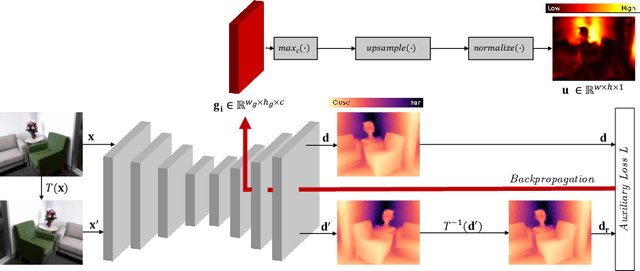
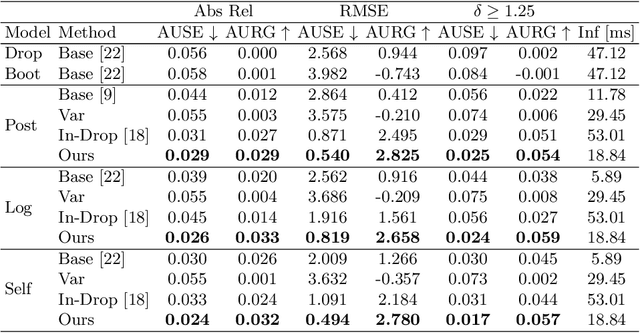
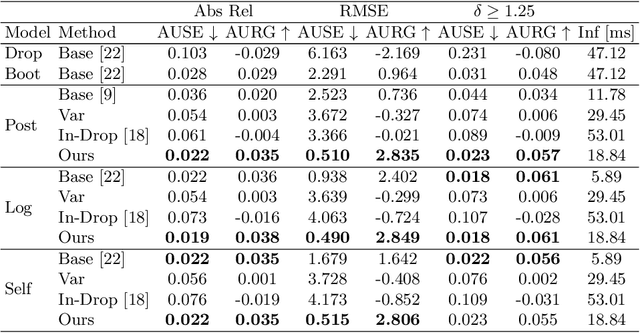
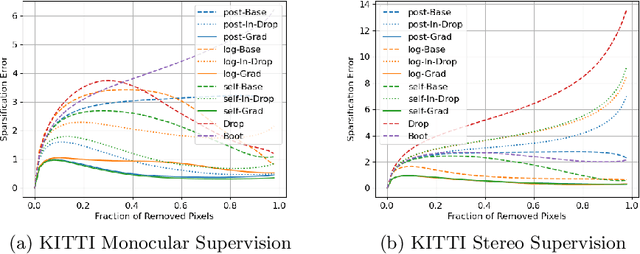
In monocular depth estimation, disturbances in the image context, like moving objects or reflecting materials, can easily lead to erroneous predictions. For that reason, uncertainty estimates for each pixel are necessary, in particular for safety-critical applications such as automated driving. We propose a post hoc uncertainty estimation approach for an already trained and thus fixed depth estimation model, represented by a deep neural network. The uncertainty is estimated with the gradients which are extracted with an auxiliary loss function. To avoid relying on ground-truth information for the loss definition, we present an auxiliary loss function based on the correspondence of the depth prediction for an image and its horizontally flipped counterpart. Our approach achieves state-of-the-art uncertainty estimation results on the KITTI and NYU Depth V2 benchmarks without the need to retrain the neural network. Models and code are publicly available at https://github.com/jhornauer/GrUMoDepth.
Optimizing Latent Space Directions For GAN-based Local Image Editing
Nov 24, 2021
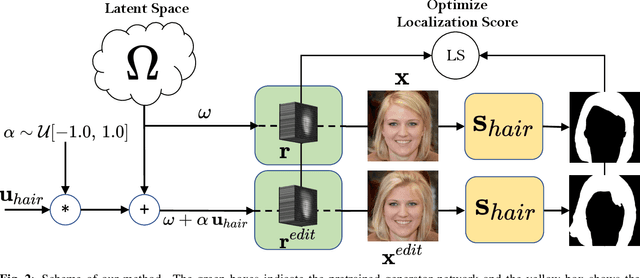


Generative Adversarial Network (GAN) based localized image editing can suffer ambiguity between semantic attributes. We thus present a novel objective function to evaluate the locality of an image edit. By introducing the supervision from a pre-trained segmentation network and optimizing the objective function, our framework, called Locally Effective Latent Space Direction (LELSD), is applicable to any dataset and GAN architecture. Our method is also computationally fast and exhibits a high extent of disentanglement, which allows users to interactively perform a sequence of edits on an image. Our experiments on both GAN-generated and real images qualitatively demonstrate the high quality and advantages of our method.
Learning Deformable Object Manipulation from Expert Demonstrations
Jul 20, 2022
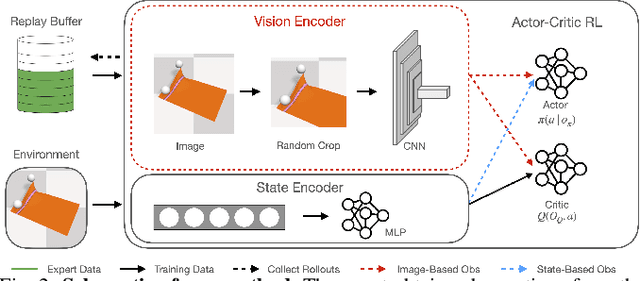
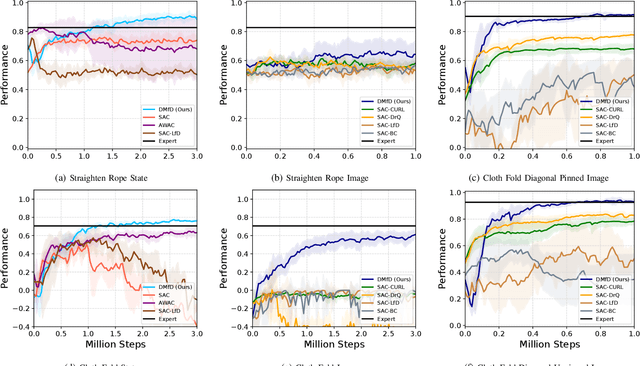
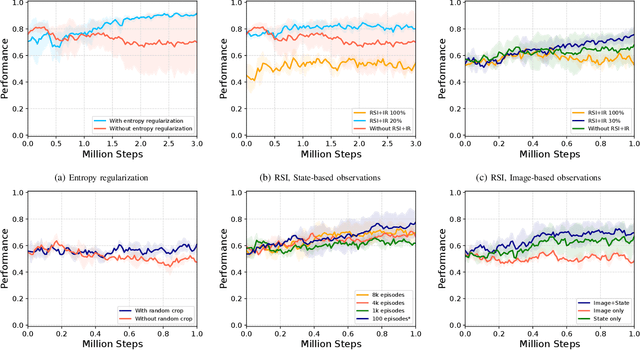
We present a novel Learning from Demonstration (LfD) method, Deformable Manipulation from Demonstrations (DMfD), to solve deformable manipulation tasks using states or images as inputs, given expert demonstrations. Our method uses demonstrations in three different ways, and balances the trade-off between exploring the environment online and using guidance from experts to explore high dimensional spaces effectively. We test DMfD on a set of representative manipulation tasks for a 1-dimensional rope and a 2-dimensional cloth from the SoftGym suite of tasks, each with state and image observations. Our method exceeds baseline performance by up to 12.9% for state-based tasks and up to 33.44% on image-based tasks, with comparable or better robustness to randomness. Additionally, we create two challenging environments for folding a 2D cloth using image-based observations, and set a performance benchmark for them. We deploy DMfD on a real robot with a minimal loss in normalized performance during real-world execution compared to simulation (~6%). Source code is on github.com/uscresl/dmfd
* Accepted to IEEE Robotics & Automation Letters (RA-L) and IEEE IROS 2022. Project website: https://uscresl.github.io/dmfd
Generalization Properties of NAS under Activation and Skip Connection Search
Sep 15, 2022
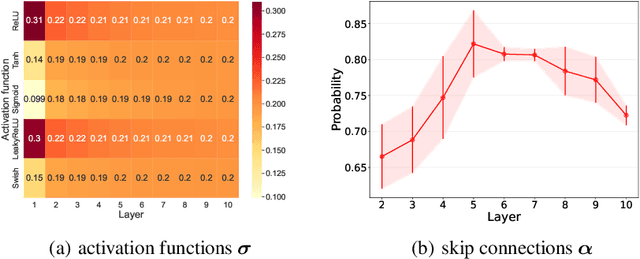
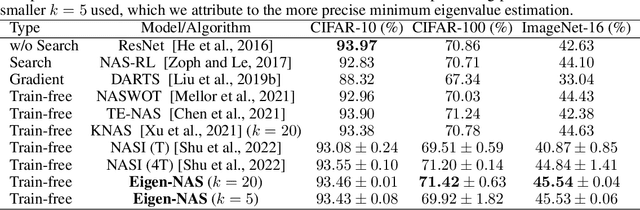
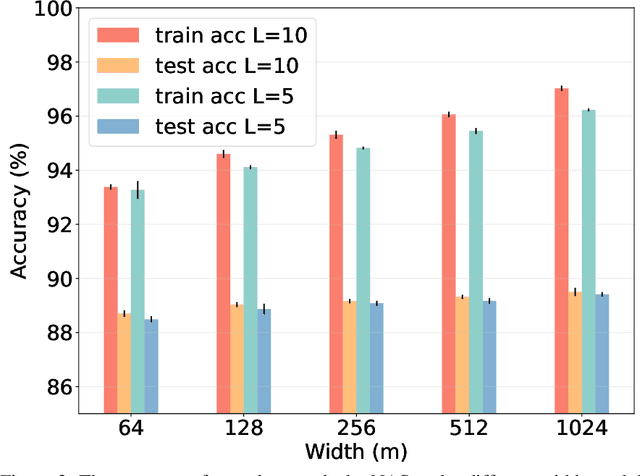
Neural Architecture Search (NAS) has fostered the automatic discovery of neural architectures, which achieve state-of-the-art accuracy in image recognition. Despite the progress achieved with NAS, so far there is little attention to theoretical guarantees on NAS. In this work, we study the generalization properties of NAS under a unifying framework enabling (deep) layer skip connection search and activation function search. To this end, we derive the lower (and upper) bounds of the minimum eigenvalue of Neural Tangent Kernel under the (in)finite width regime from a search space including mixed activation functions, fully connected, and residual neural networks. Our analysis is non-trivial due to the coupling of various architectures and activation functions under the unifying framework. Then, we leverage the eigenvalue bounds to establish generalization error bounds of NAS in the stochastic gradient descent training. Importantly, we theoretically and experimentally show how the derived results can guide NAS to select the top-performing architectures, even in the case without training, leading to a training-free algorithm based on our theory. Accordingly, our numerical validation shed light on the design of computationally efficient methods for NAS.
QuantNAS for super resolution: searching for efficient quantization-friendly architectures against quantization noise
Aug 31, 2022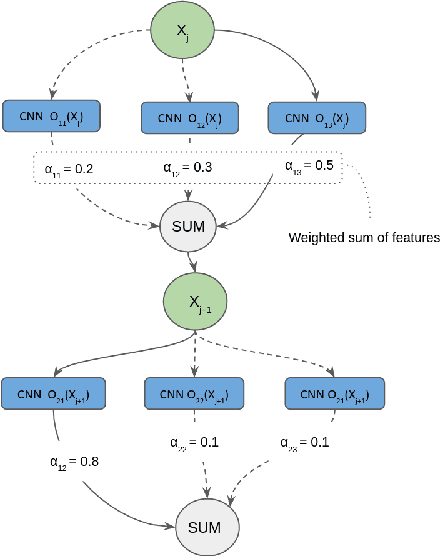
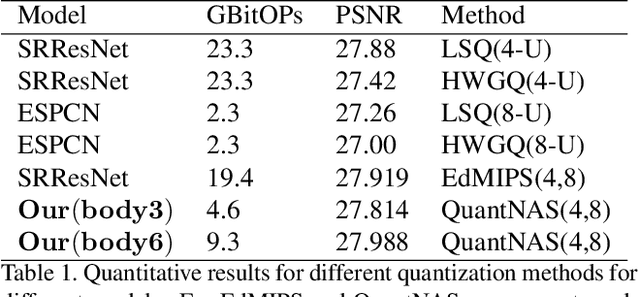
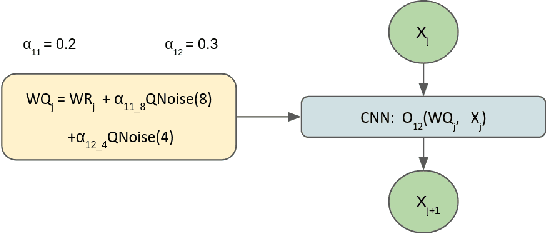
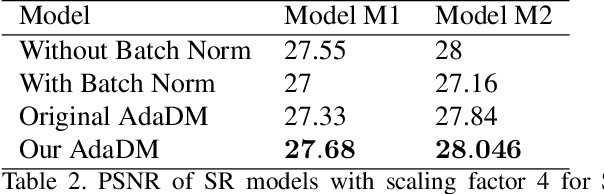
There is a constant need for high-performing and computationally efficient neural network models for image super-resolution (SR) often used on low-capacity devices. One way to obtain such models is to compress existing architectures, e.g. quantization. Another option is a neural architecture search (NAS) that discovers new efficient solutions. We propose a novel quantization-aware NAS procedure for a specifically designed SR search space. Our approach performs NAS to find quantization-friendly SR models. The search relies on adding quantization noise to parameters and activations instead of quantizing parameters directly. Our QuantNAS finds architectures with better PSNR/BitOps trade-off than uniform or mixed precision quantization of fixed architectures. Additionally, our search against noise procedure is up to 30% faster than directly quantizing weights.