 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Single image dehazing via combining the prior knowledge and CNNs
Nov 10, 2021

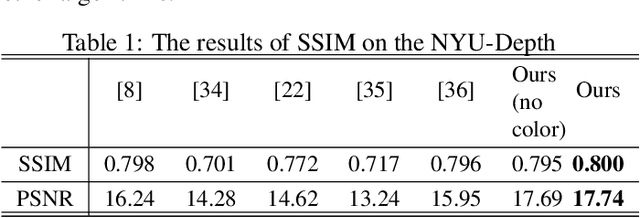
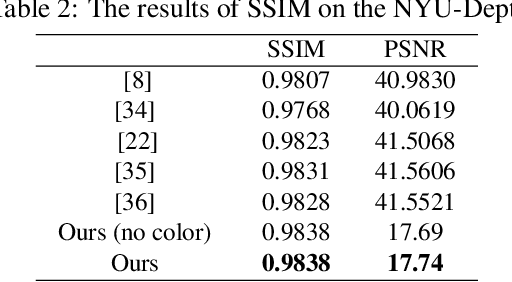
Aiming at the existing single image haze removal algorithms, which are based on prior knowledge and assumptions, subject to many limitations in practical applications, and could suffer from noise and halo amplification. An end-to-end system is proposed in this paper to reduce defects by combining the prior knowledge and deep learning method. The haze image is decomposed into the base layer and detail layers through a weighted guided image filter (WGIF) firstly, and the airlight is estimated from the base layer. Then, the base layer image is passed to the efficient deep convolutional network for estimating the transmission map. To restore object close to the camera completely without amplifying noise in sky or heavily hazy scene, an adaptive strategy is proposed based on the value of the transmission map. If the transmission map of a pixel is small, the base layer of the haze image is used to recover a haze-free image via atmospheric scattering model, finally. Otherwise, the haze image is used. Experiments show that the proposed method achieves superior performance over existing methods.
Detail-Preserving Transformer for Light Field Image Super-Resolution
Jan 02, 2022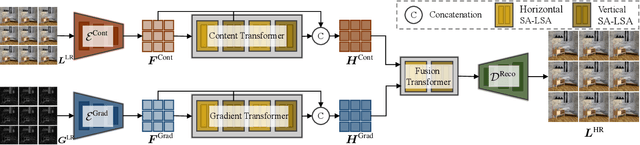
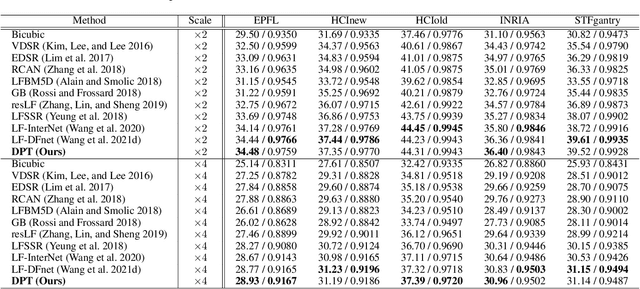
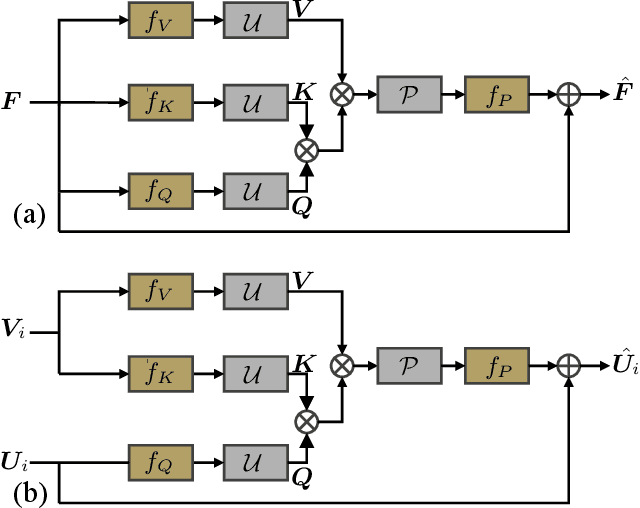
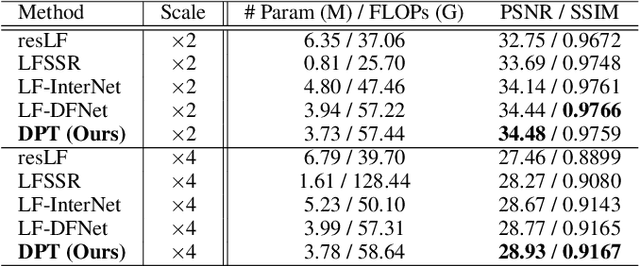
Recently, numerous algorithms have been developed to tackle the problem of light field super-resolution (LFSR), i.e., super-resolving low-resolution light fields to gain high-resolution views. Despite delivering encouraging results, these approaches are all convolution-based, and are naturally weak in global relation modeling of sub-aperture images necessarily to characterize the inherent structure of light fields. In this paper, we put forth a novel formulation built upon Transformers, by treating LFSR as a sequence-to-sequence reconstruction task. In particular, our model regards sub-aperture images of each vertical or horizontal angular view as a sequence, and establishes long-range geometric dependencies within each sequence via a spatial-angular locally-enhanced self-attention layer, which maintains the locality of each sub-aperture image as well. Additionally, to better recover image details, we propose a detail-preserving Transformer (termed as DPT), by leveraging gradient maps of light field to guide the sequence learning. DPT consists of two branches, with each associated with a Transformer for learning from an original or gradient image sequence. The two branches are finally fused to obtain comprehensive feature representations for reconstruction. Evaluations are conducted on a number of light field datasets, including real-world scenes and synthetic data. The proposed method achieves superior performance comparing with other state-of-the-art schemes. Our code is publicly available at: https://github.com/BITszwang/DPT.
Histogram of Oriented Gradients Meet Deep Learning: A Novel Multi-task Deep Network for Medical Image Semantic Segmentation
Apr 02, 2022
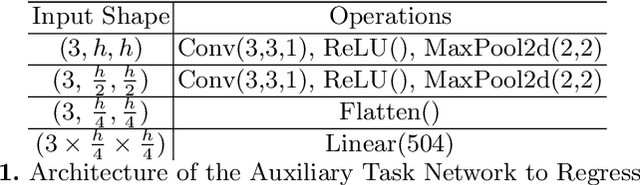
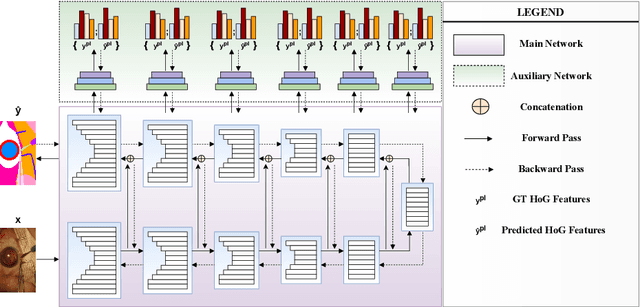
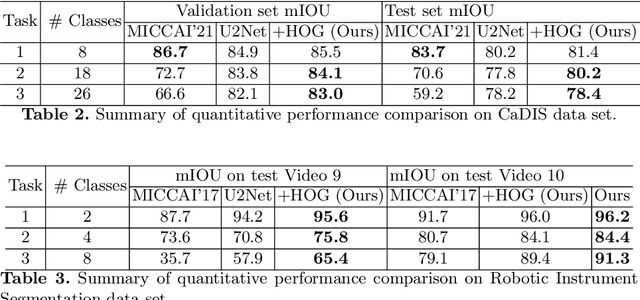
We present our novel deep multi-task learning method for medical image segmentation. Existing multi-task methods demand ground truth annotations for both the primary and auxiliary tasks. Contrary to it, we propose to generate the pseudo-labels of an auxiliary task in an unsupervised manner. To generate the pseudo-labels, we leverage Histogram of Oriented Gradients (HOGs), one of the most widely used and powerful hand-crafted features for detection. Together with the ground truth semantic segmentation masks for the primary task and pseudo-labels for the auxiliary task, we learn the parameters of the deep network to minimise the loss of both the primary task and the auxiliary task jointly. We employed our method on two powerful and widely used semantic segmentation networks: UNet and U2Net to train in a multi-task setup. To validate our hypothesis, we performed experiments on two different medical image segmentation data sets. From the extensive quantitative and qualitative results, we observe that our method consistently improves the performance compared to the counter-part method. Moreover, our method is the winner of FetReg Endovis Sub-challenge on Semantic Segmentation organised in conjunction with MICCAI 2021.
Towards Local Underexposed Photo Enhancement
Aug 17, 2022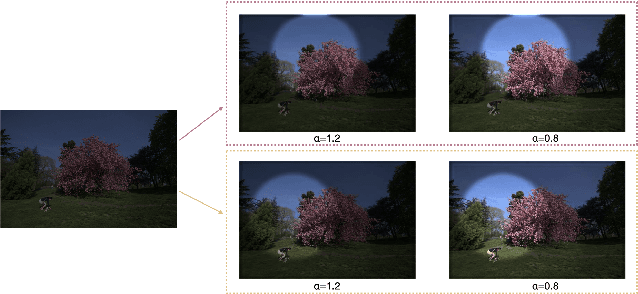
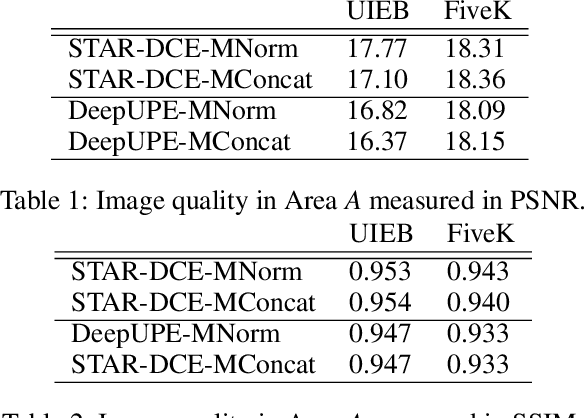
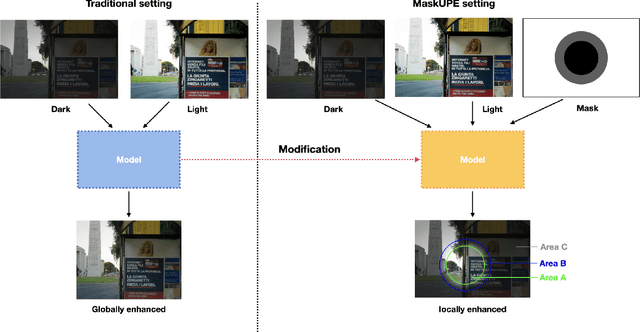
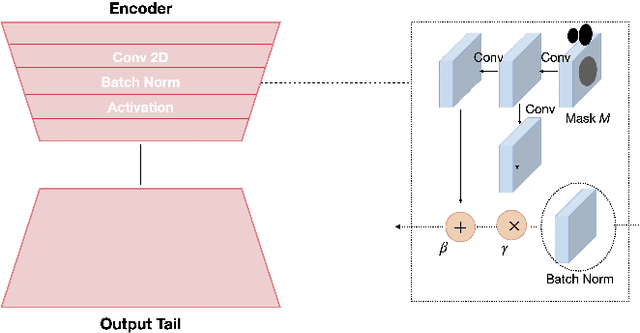
Inspired by the ability of deep generative models to generate highly realistic images, much recent work has made progress in enhancing underexposed images globally. However, the local image enhancement approach has not been explored, although they are requisite in the real-world scenario, e.g., fixing local underexposure. In this work, we define a new task setting for underexposed image enhancement where users are able to control which region to be enlightened with an input mask. As indicated by the mask, an image can be divided into three areas, including Masked Area A, Transition Area B, and Unmasked Area C. As a result, Area A should be enlightened to the desired lighting, and there shall be a smooth transition (Area B) from the enlightened area (Area A) to the unchanged region (Area C). To finish this task, we propose two methods: Concatenate the mask as additional channels (MConcat), Mask-based Normlization (MNorm). While MConcat simply append the mask channels to the input images, MNorm can dynamically enhance the spatial-varying pixels, guaranteeing the enhanced images are consistent with the requirement indicated by the input mask. Moreover, MConcat serves as a play-and-plug module, and can be incorporated with existing networks, which globally enhance images, to achieve the local enhancement. And the overall network can be trained with three kinds of loss functions in Area A, Area B, and Area C, which are unified for various model structures. We perform extensive experiments on public datasets with various parametric approaches for low-light enhancement, %the Convolutional-Neutral-Network-based model and Transformer-based model, demonstrating the effectiveness of our methods.
Video Reconstruction from a Single Motion Blurred Image using Learned Dynamic Phase Coding
Dec 28, 2021

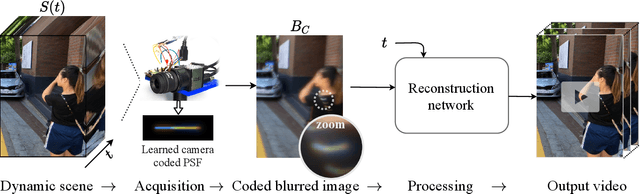
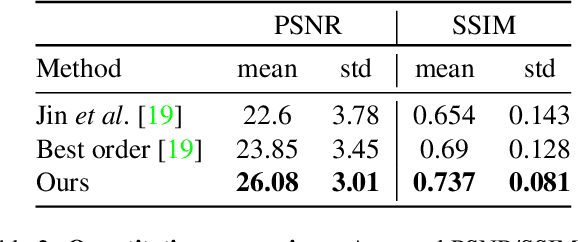
Video reconstruction from a single motion-blurred image is a challenging problem, which can enhance existing cameras' capabilities. Recently, several works addressed this task using conventional imaging and deep learning. Yet, such purely-digital methods are inherently limited, due to direction ambiguity and noise sensitivity. Some works proposed to address these limitations using non-conventional image sensors, however, such sensors are extremely rare and expensive. To circumvent these limitations with simpler means, we propose a hybrid optical-digital method for video reconstruction that requires only simple modifications to existing optical systems. We use a learned dynamic phase-coding in the lens aperture during the image acquisition to encode the motion trajectories, which serve as prior information for the video reconstruction process. The proposed computational camera generates a sharp frame burst of the scene at various frame rates from a single coded motion-blurred image, using an image-to-video convolutional neural network. We present advantages and improved performance compared to existing methods, using both simulations and a real-world camera prototype.
SITA: Single Image Test-time Adaptation
Dec 08, 2021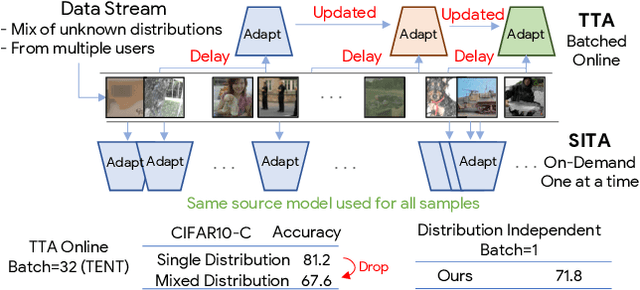


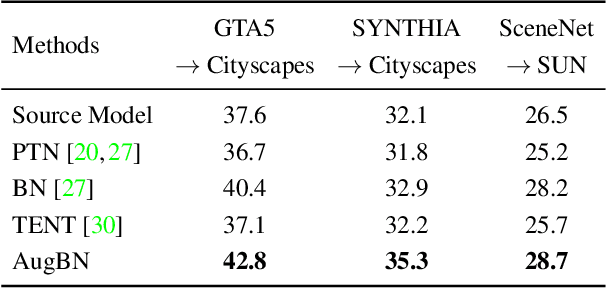
In Test-time Adaptation (TTA), given a model trained on some source data, the goal is to adapt it to make better predictions for test instances from a different distribution. Crucially, TTA assumes no access to the source data or even any additional labeled/unlabeled samples from the target distribution to finetune the source model. In this work, we consider TTA in a more pragmatic setting which we refer to as SITA (Single Image Test-time Adaptation). Here, when making each prediction, the model has access only to the given single test instance, rather than a batch of instances, as has typically been considered in the literature. This is motivated by the realistic scenarios where inference is needed in an on-demand fashion that may not be delayed to "batch-ify" incoming requests or the inference is happening on an edge device (like mobile phone) where there is no scope for batching. The entire adaptation process in SITA should be extremely fast as it happens at inference time. To address this, we propose a novel approach AugBN for the SITA setting that requires only forward propagation. The approach can adapt any off-the-shelf trained model to individual test instances for both classification and segmentation tasks. AugBN estimates normalisation statistics of the unseen test distribution from the given test image using only one forward pass with label-preserving transformations. Since AugBN does not involve any back-propagation, it is significantly faster compared to other recent methods. To the best of our knowledge, this is the first work that addresses this hard adaptation problem using only a single test image. Despite being very simple, our framework is able to achieve significant performance gains compared to directly applying the source model on the target instances, as reflected in our extensive experiments and ablation studies.
Graph Neural Networks for Image Classification and Reinforcement Learning using Graph representations
Mar 08, 2022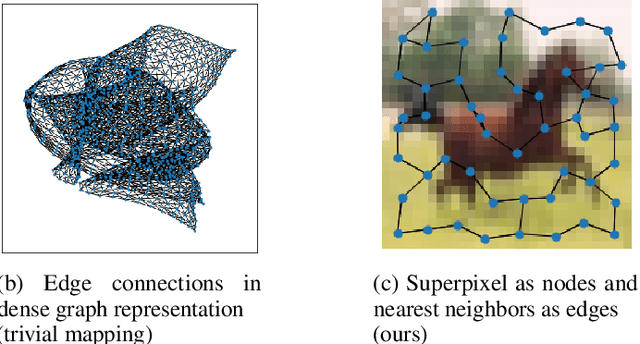
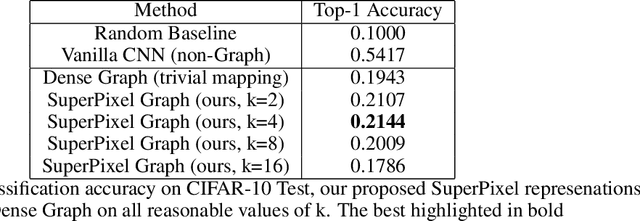
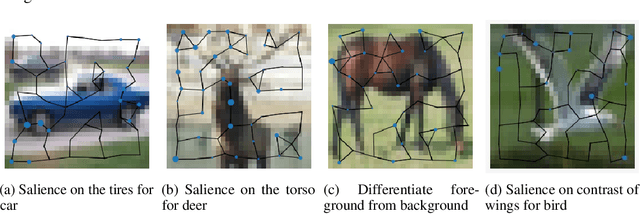
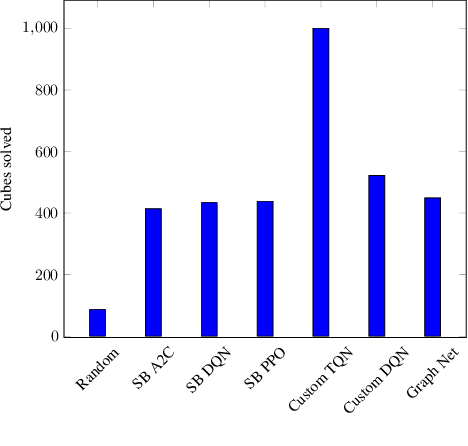
In this paper, we will evaluate the performance of graph neural networks in two distinct domains: computer vision and reinforcement learning. In the computer vision section, we seek to learn whether a novel non-redundant representation for images as graphs can improve performance over trivial pixel to node mapping on a graph-level prediction graph, specifically image classification. For the reinforcement learning section, we seek to learn if explicitly modeling solving a Rubik's cube as a graph problem can improve performance over a standard model-free technique with no inductive bias.
Implicit Neural Representations for Image Compression
Dec 08, 2021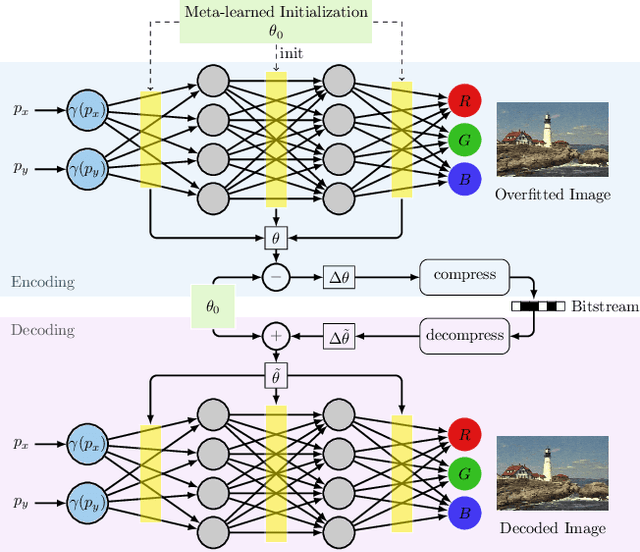
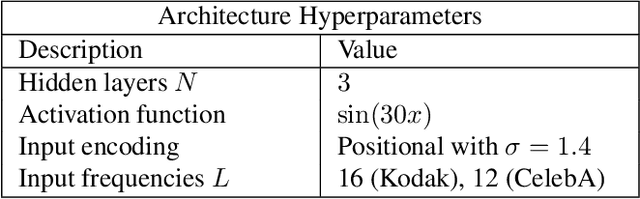

Recently Implicit Neural Representations (INRs) gained attention as a novel and effective representation for various data types. Thus far, prior work mostly focused on optimizing their reconstruction performance. This work investigates INRs from a novel perspective, i.e., as a tool for image compression. To this end, we propose the first comprehensive compression pipeline based on INRs including quantization, quantization-aware retraining and entropy coding. Encoding with INRs, i.e. overfitting to a data sample, is typically orders of magnitude slower. To mitigate this drawback, we leverage meta-learned initializations based on MAML to reach the encoding in fewer gradient updates which also generally improves rate-distortion performance of INRs. We find that our approach to source compression with INRs vastly outperforms similar prior work, is competitive with common compression algorithms designed specifically for images and closes the gap to state-of-the-art learned approaches based on Rate-Distortion Autoencoders. Moreover, we provide an extensive ablation study on the importance of individual components of our method which we hope facilitates future research on this novel approach to image compression.
MGTR: End-to-End Mutual Gaze Detection with Transformer
Sep 22, 2022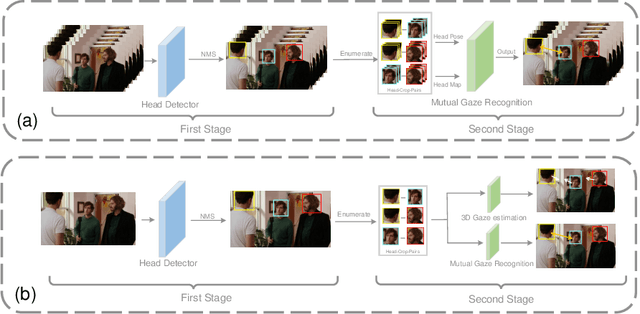
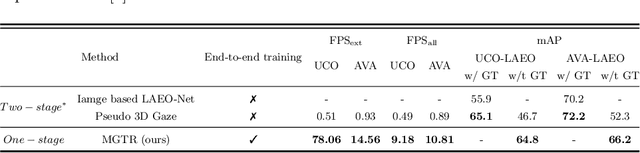
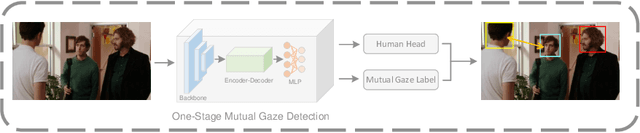
People's looking at each other or mutual gaze is ubiquitous in our daily interactions, and detecting mutual gaze is of great significance for understanding human social scenes. Current mutual gaze detection methods focus on two-stage methods, whose inference speed is limited by the two-stage pipeline and the performance in the second stage is affected by the first one. In this paper, we propose a novel one-stage mutual gaze detection framework called Mutual Gaze TRansformer or MGTR to perform mutual gaze detection in an end-to-end manner. By designing mutual gaze instance triples, MGTR can detect each human head bounding box and simultaneously infer mutual gaze relationship based on global image information, which streamlines the whole process with simplicity. Experimental results on two mutual gaze datasets show that our method is able to accelerate mutual gaze detection process without losing performance. Ablation study shows that different components of MGTR can capture different levels of semantic information in images. Code is available at https://github.com/Gmbition/MGTR
Dual-space Compressed Sensing
Jul 15, 2022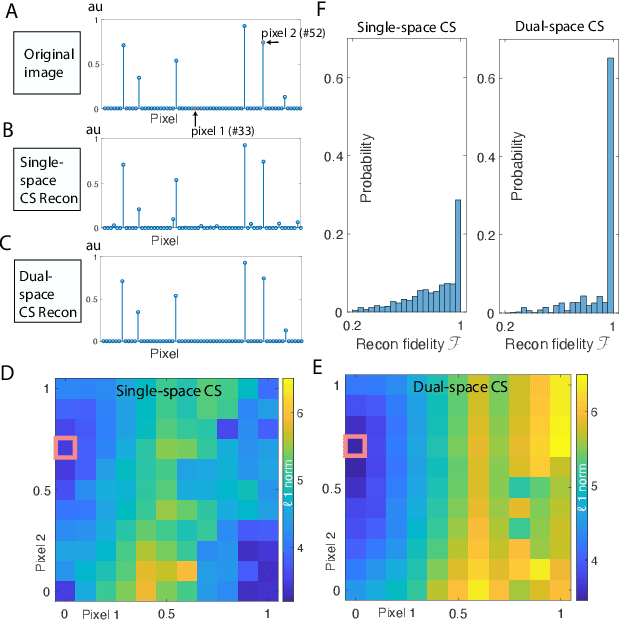
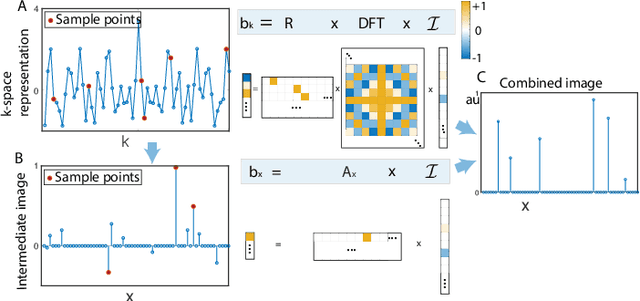
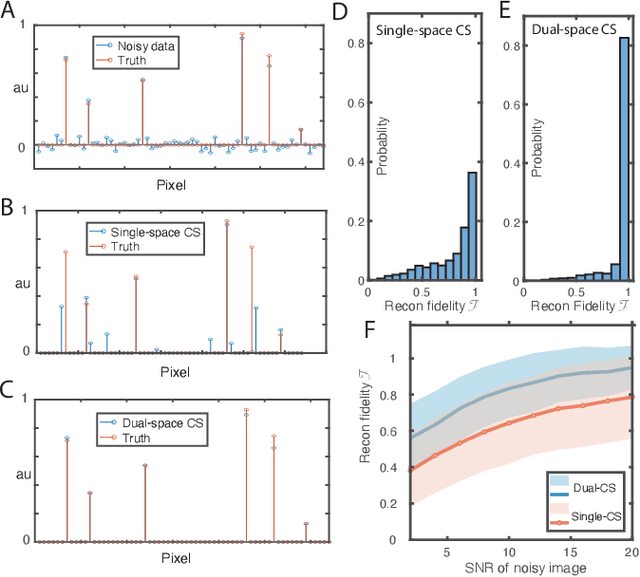
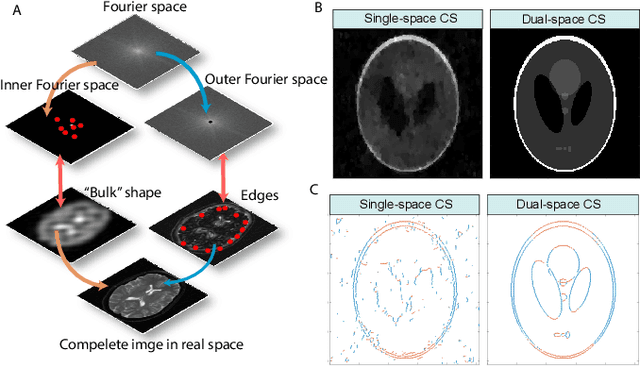
Compressed sensing (CS) is a powerful method routinely employed to accelerate image acquisition. It is particularly suited to situations when the image under consideration is sparse but can be sampled in a basis where it is non-sparse. Here we propose an alternate CS regime in situations where the image can be sampled in two incoherent spaces simultaneously, with a special focus on image sampling in Fourier reciprocal spaces (e.g. real-space and k-space). Information is fed-forward from one space to the other, allowing new opportunities to efficiently solve the optimization problem at the heart of CS image reconstruction. We show that considerable gains in imaging acceleration are then possible over conventional CS. The technique provides enhanced robustness to noise, and is well suited to edge-detection problems. We envision applications for imaging collections of nanodiamond (ND) particles targeting specific regions in a volume of interest, exploiting the ability of lattice defects (NV centers) to allow ND particles to be imaged in reciprocal spaces simultaneously via optical fluorescence and 13C magnetic resonance imaging (MRI) respectively. Broadly this work suggests the potential to interface CS principles with hybrid sampling strategies to yield speedup in signal acquisition in many practical settings.