 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Prayatul Matrix: A Direct Comparison Approach to Evaluate Performance of Supervised Machine Learning Models
Sep 26, 2022
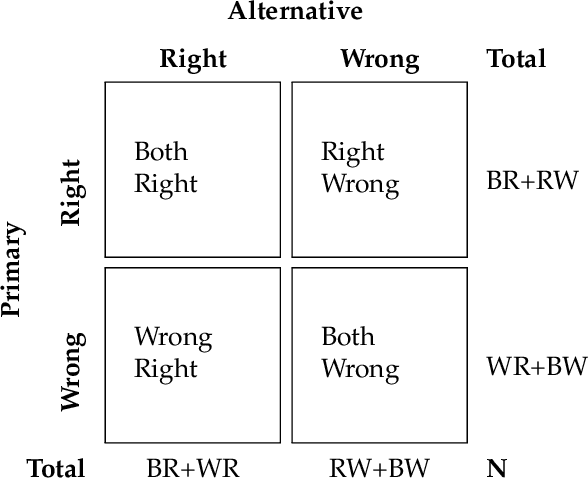

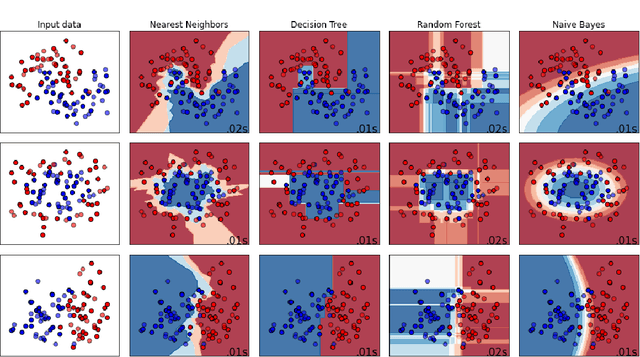

Performance comparison of supervised machine learning (ML) models are widely done in terms of different confusion matrix based scores obtained on test datasets. However, a dataset comprises several instances having different difficulty levels. Therefore, it is more logical to compare effectiveness of ML models on individual instances instead of comparing scores obtained for the entire dataset. In this paper, an alternative approach is proposed for direct comparison of supervised ML models in terms of individual instances within the dataset. A direct comparison matrix called \emph{Prayatul Matrix} is introduced, which accounts for comparative outcome of two ML algorithms on different instances of a dataset. Five different performance measures are designed based on prayatul matrix. Efficacy of the proposed approach as well as designed measures is analyzed with four classification techniques on three datasets. Also analyzed on four large-scale complex image datasets with four deep learning models namely ResNet50V2, MobileNetV2, EfficientNet, and XceptionNet. Results are evident that the newly designed measure are capable of giving more insight about the comparing ML algorithms, which were impossible with existing confusion matrix based scores like accuracy, precision and recall.
ClipCap: CLIP Prefix for Image Captioning
Nov 18, 2021
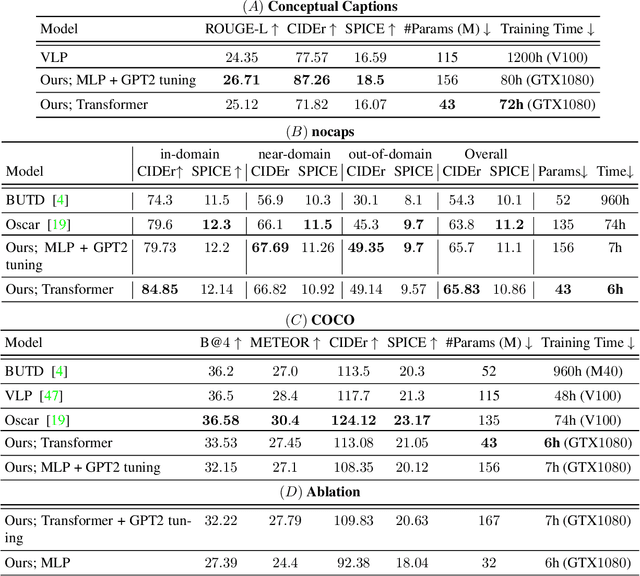
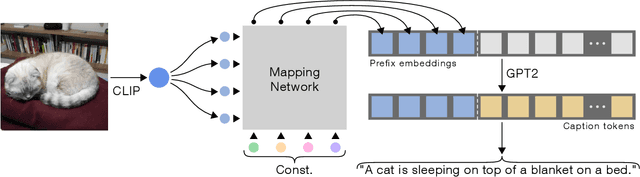

Image captioning is a fundamental task in vision-language understanding, where the model predicts a textual informative caption to a given input image. In this paper, we present a simple approach to address this task. We use CLIP encoding as a prefix to the caption, by employing a simple mapping network, and then fine-tunes a language model to generate the image captions. The recently proposed CLIP model contains rich semantic features which were trained with textual context, making it best for vision-language perception. Our key idea is that together with a pre-trained language model (GPT2), we obtain a wide understanding of both visual and textual data. Hence, our approach only requires rather quick training to produce a competent captioning model. Without additional annotations or pre-training, it efficiently generates meaningful captions for large-scale and diverse datasets. Surprisingly, our method works well even when only the mapping network is trained, while both CLIP and the language model remain frozen, allowing a lighter architecture with less trainable parameters. Through quantitative evaluation, we demonstrate our model achieves comparable results to state-of-the-art methods on the challenging Conceptual Captions and nocaps datasets, while it is simpler, faster, and lighter. Our code is available in https://github.com/rmokady/CLIP_prefix_caption.
TeST: Test-time Self-Training under Distribution Shift
Sep 23, 2022
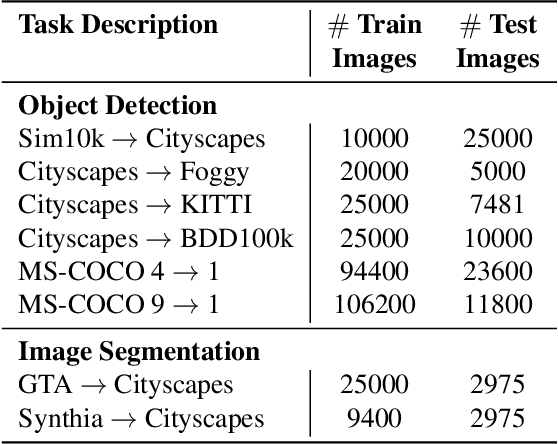
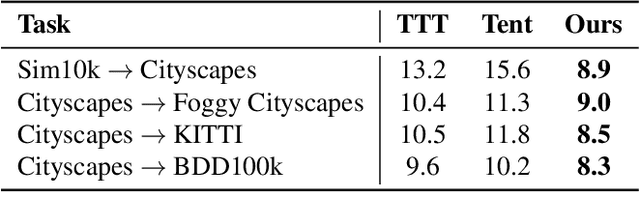
Despite their recent success, deep neural networks continue to perform poorly when they encounter distribution shifts at test time. Many recently proposed approaches try to counter this by aligning the model to the new distribution prior to inference. With no labels available this requires unsupervised objectives to adapt the model on the observed test data. In this paper, we propose Test-Time Self-Training (TeST): a technique that takes as input a model trained on some source data and a novel data distribution at test time, and learns invariant and robust representations using a student-teacher framework. We find that models adapted using TeST significantly improve over baseline test-time adaptation algorithms. TeST achieves competitive performance to modern domain adaptation algorithms, while having access to 5-10x less data at time of adaption. We thoroughly evaluate a variety of baselines on two tasks: object detection and image segmentation and find that models adapted with TeST. We find that TeST sets the new state-of-the art for test-time domain adaptation algorithms.
A Privacy-Preserving Image Retrieval Scheme Using A Codebook Generated From Independent Plain-Image Dataset
Sep 04, 2021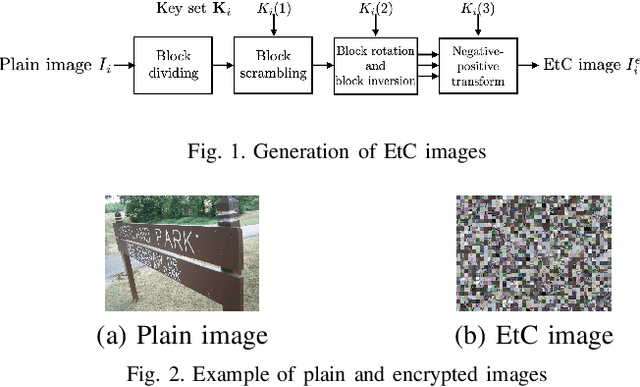

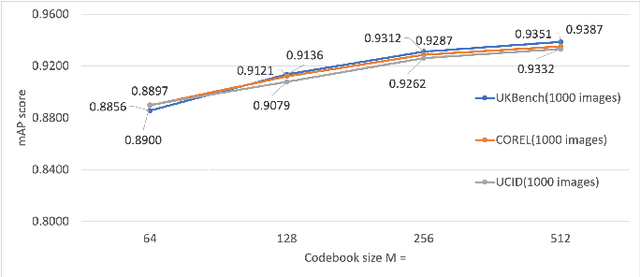
In this paper, we propose a privacy-preserving image-retrieval scheme using a codebook generated by using a plain-image dataset. Encryption-then-compression (EtC) images, which were proposed for EtC systems, have been used in conventional privacy-preserving image-retrieval schemes, in which a codebook is generated from EtC images uploaded by image owners, and extended SIMPLE descriptors are then calculated as image descriptors by using the codebook. In contrast, in the proposed scheme, a codebook is generated from a dataset independent of uploaded images. The use of an independent dataset enables us not only to use a codebook that does not require recalculation but also to constantly provide a high retrieval accuracy. In an experiment, the proposed scheme is demonstrated to maintain a high retrieval performance, even if codebooks are generated from a plain image dataset independent of image owners' encrypted images.
Image Segmentation with Adaptive Spatial Priors from Joint Registration
Mar 29, 2022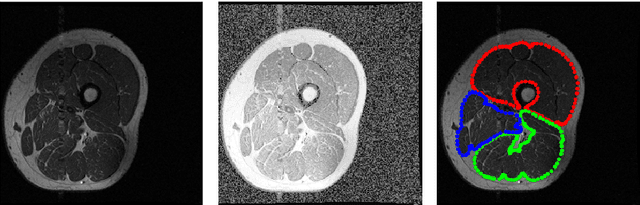
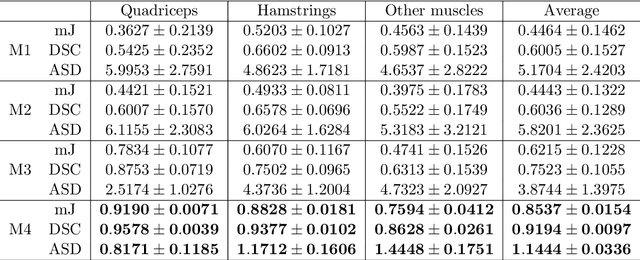


Image segmentation is a crucial but challenging task that has many applications. In medical imaging for instance, intensity inhomogeneity and noise are common. In thigh muscle images, different muscles are closed packed together and there are often no clear boundaries between them. Intensity based segmentation models cannot separate one muscle from another. To solve such problems, in this work we present a segmentation model with adaptive spatial priors from joint registration. This model combines segmentation and registration in a unified framework to leverage their positive mutual influence. The segmentation is based on a modified Gaussian mixture model (GMM), which integrates intensity inhomogeneity and spacial smoothness. The registration plays the role of providing a shape prior. We adopt a modified sum of squared difference (SSD) fidelity term and Tikhonov regularity term for registration, and also utilize Gaussian pyramid and parametric method for robustness. The connection between segmentation and registration is guaranteed by the cross entropy metric that aims to make the segmentation map (from segmentation) and deformed atlas (from registration) as similar as possible. This joint framework is implemented within a constraint optimization framework, which leads to an efficient algorithm. We evaluate our proposed model on synthetic and thigh muscle MR images. Numerical results show the improvement as compared to segmentation and registration performed separately and other joint models.
Normal and Visibility Estimation of Human Face from a Single Image
Mar 09, 2022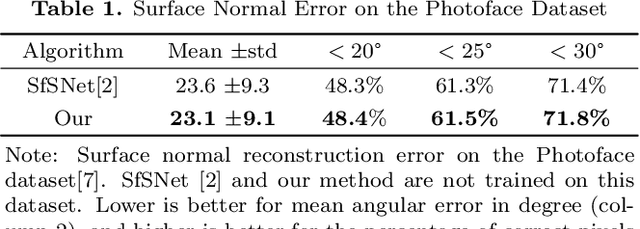
Recent work on the intrinsic image of humans starts to consider the visibility of incident illumination and encodes the light transfer function by spherical harmonics. In this paper, we show that such a light transfer function can be further decomposed into visibility and cosine terms related to surface normal. Such decomposition allows us to recover the surface normal in addition to visibility. We propose a deep learning-based approach with a reconstruction loss for training on real-world images. Results show that compared with previous works, the reconstruction of human face from our method better reveals the surface normal and shading details especially around regions where visibility effect is strong.
Stochastic Planner-Actor-Critic for Unsupervised Deformable Image Registration
Dec 14, 2021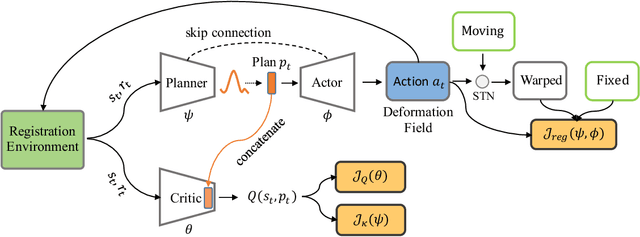
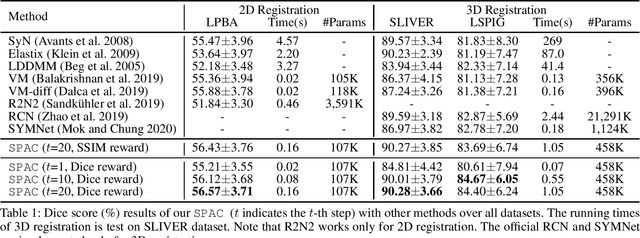
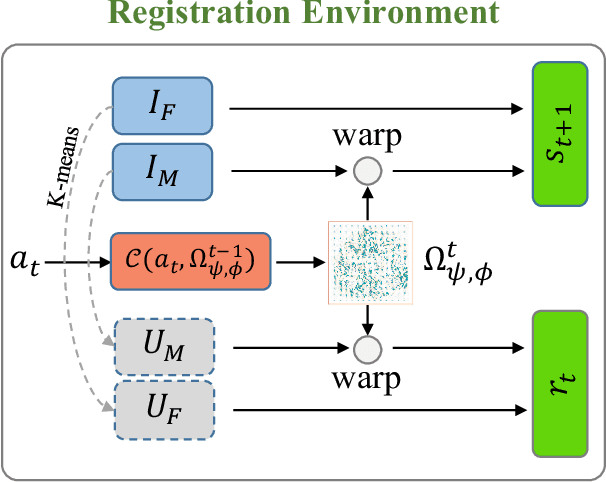
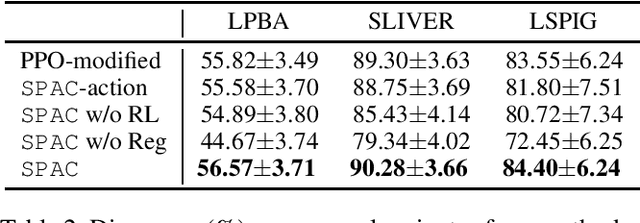
Large deformations of organs, caused by diverse shapes and nonlinear shape changes, pose a significant challenge for medical image registration. Traditional registration methods need to iteratively optimize an objective function via a specific deformation model along with meticulous parameter tuning, but which have limited capabilities in registering images with large deformations. While deep learning-based methods can learn the complex mapping from input images to their respective deformation field, it is regression-based and is prone to be stuck at local minima, particularly when large deformations are involved. To this end, we present Stochastic Planner-Actor-Critic (SPAC), a novel reinforcement learning-based framework that performs step-wise registration. The key notion is warping a moving image successively by each time step to finally align to a fixed image. Considering that it is challenging to handle high dimensional continuous action and state spaces in the conventional reinforcement learning (RL) framework, we introduce a new concept `Plan' to the standard Actor-Critic model, which is of low dimension and can facilitate the actor to generate a tractable high dimensional action. The entire framework is based on unsupervised training and operates in an end-to-end manner. We evaluate our method on several 2D and 3D medical image datasets, some of which contain large deformations. Our empirical results highlight that our work achieves consistent, significant gains and outperforms state-of-the-art methods.
Persuasion Strategies in Advertisements: Dataset, Modeling, and Baselines
Aug 20, 2022
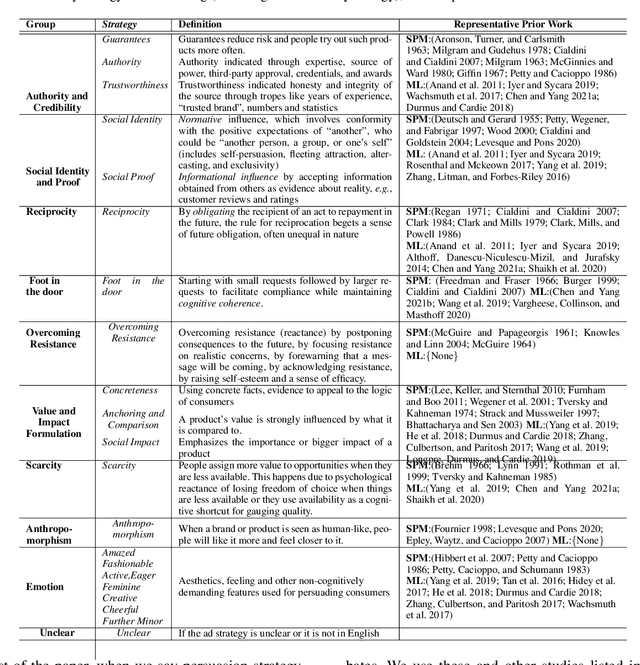
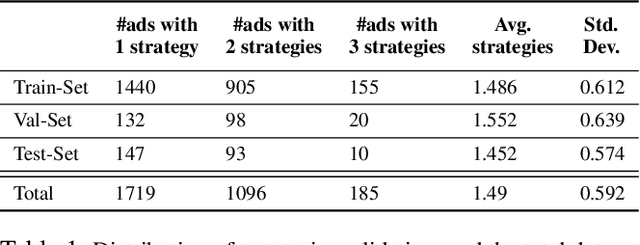

Modeling what makes an advertisement persuasive, i.e., eliciting the desired response from consumer, is critical to the study of propaganda, social psychology, and marketing. Despite its importance, computational modeling of persuasion in computer vision is still in its infancy, primarily due to the lack of benchmark datasets that can provide persuasion-strategy labels associated with ads. Motivated by persuasion literature in social psychology and marketing, we introduce an extensive vocabulary of persuasion strategies and build the first ad image corpus annotated with persuasion strategies. We then formulate the task of persuasion strategy prediction with multi-modal learning, where we design a multi-task attention fusion model that can leverage other ad-understanding tasks to predict persuasion strategies. Further, we conduct a real-world case study on 1600 advertising campaigns of 30 Fortune-500 companies where we use our model's predictions to analyze which strategies work with different demographics (age and gender). The dataset also provides image segmentation masks, which labels persuasion strategies in the corresponding ad images on the test split. We publicly release our code and dataset https://midas-research.github.io/persuasion-advertisements/.
Interpreting Latent Spaces of Generative Models for Medical Images using Unsupervised Methods
Jul 20, 2022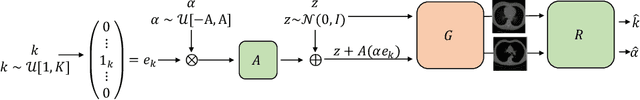

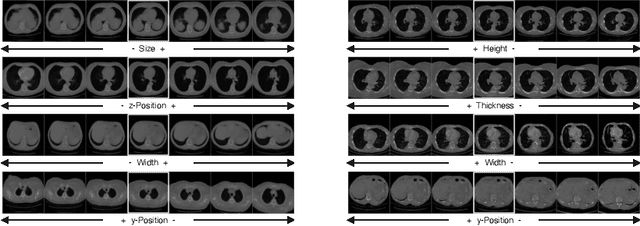
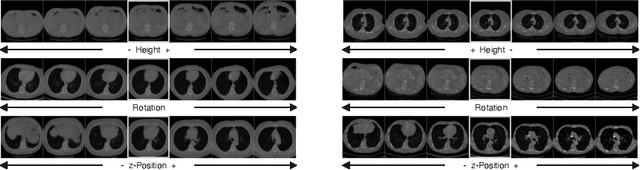
Generative models such as Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs) play an increasingly important role in medical image analysis. The latent spaces of these models often show semantically meaningful directions corresponding to human-interpretable image transformations. However, until now, their exploration for medical images has been limited due to the requirement of supervised data. Several methods for unsupervised discovery of interpretable directions in GAN latent spaces have shown interesting results on natural images. This work explores the potential of applying these techniques on medical images by training a GAN and a VAE on thoracic CT scans and using an unsupervised method to discover interpretable directions in the resulting latent space. We find several directions corresponding to non-trivial image transformations, such as rotation or breast size. Furthermore, the directions show that the generative models capture 3D structure despite being presented only with 2D data. The results show that unsupervised methods to discover interpretable directions in GANs generalize to VAEs and can be applied to medical images. This opens a wide array of future work using these methods in medical image analysis.
Recursive Self-Improvement for Camera Image and Signal Processing Pipeline
Nov 15, 2021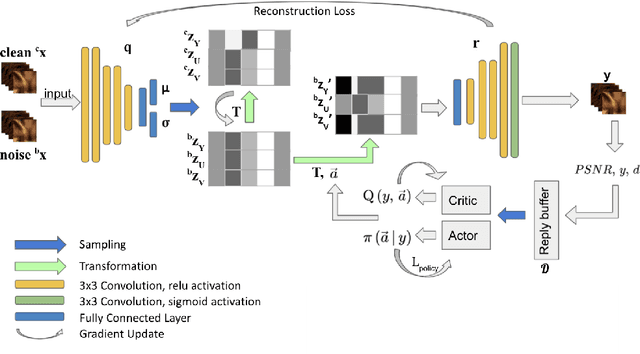
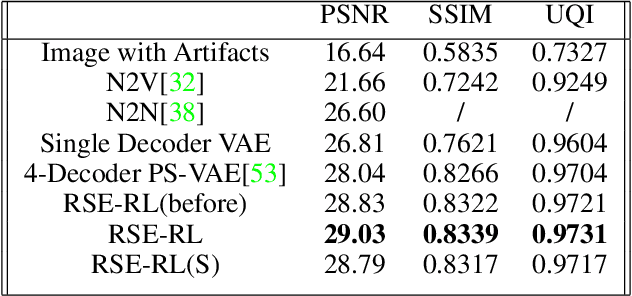

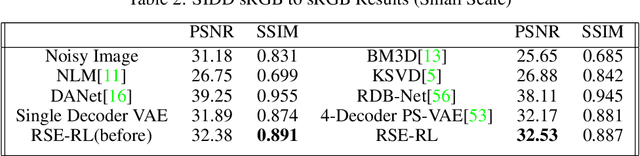
Current camera image and signal processing pipelines (ISPs), including deep trained versions, tend to apply a single filter that is uniformly applied to the entire image. This despite the fact that most acquired camera images have spatially heterogeneous artifacts. This spatial heterogeneity manifests itself across the image space as varied Moire ringing, motion-blur, color-bleaching or lens based projection distortions. Moreover, combinations of these image artifacts can be present in small or large pixel neighborhoods, within an acquired image. Here, we present a deep reinforcement learning model that works in learned latent subspaces, recursively improves camera image quality through a patch-based spatially adaptive artifact filtering and image enhancement. Our RSE-RL model views the identification and correction of artifacts as a recursive self-learning and self-improvement exercise and consists of two major sub-modules: (i) The latent feature sub-space clustering/grouping obtained through an equivariant variational auto-encoder enabling rapid identification of the correspondence and discrepancy between noisy and clean image patches. (ii) The adaptive learned transformation controlled by a trust-region soft actor-critic agent that progressively filters and enhances the noisy patches using its closest feature distance neighbors of clean patches. Artificial artifacts that may be introduced in a patch-based ISP, are also removed through a reward based de-blocking recovery and image enhancement. We demonstrate the self-improvement feature of our model by recursively training and testing on images, wherein the enhanced images resulting from each epoch provide a natural data augmentation and robustness to the RSE-RL training-filtering pipeline.