 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep Learning-based Anonymization of Chest Radiographs: A Utility-preserving Measure for Patient Privacy
Sep 23, 2022
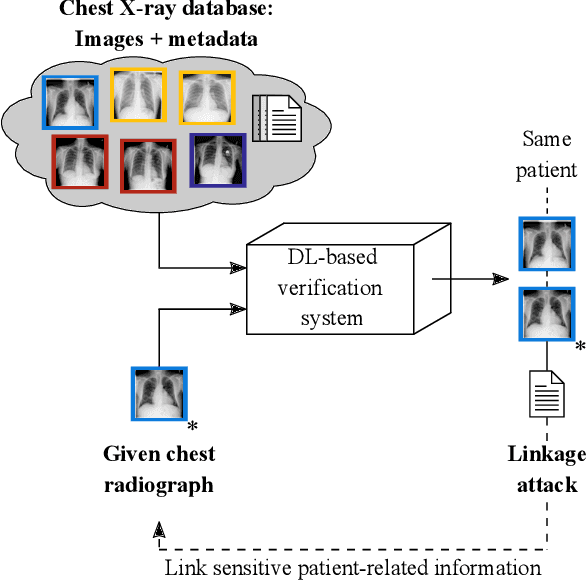

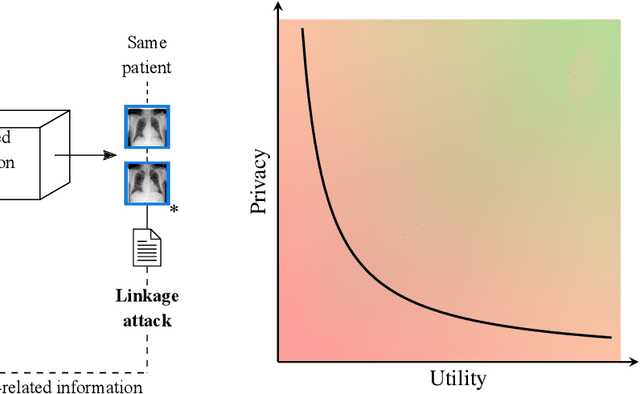

Robust and reliable anonymization of chest radiographs constitutes an essential step before publishing large datasets of such for research purposes. The conventional anonymization process is carried out by obscuring personal information in the images with black boxes and removing or replacing meta-information. However, such simple measures retain biometric information in the chest radiographs, allowing patients to be re-identified by a linkage attack. Therefore, we see an urgent need to obfuscate the biometric information appearing in the images. To the best of our knowledge, we propose the first deep learning-based approach to targetedly anonymize chest radiographs while maintaining data utility for diagnostic and machine learning purposes. Our model architecture is a composition of three independent neural networks that, when collectively used, allow for learning a deformation field that is able to impede patient re-identification. The individual influence of each component is investigated with an ablation study. Quantitative results on the ChestX-ray14 dataset show a reduction of patient re-identification from 81.8% to 58.6% in the area under the receiver operating characteristic curve (AUC) with little impact on the abnormality classification performance. This indicates the ability to preserve underlying abnormality patterns while increasing patient privacy. Furthermore, we compare the proposed deep learning-based anonymization approach with differentially private image pixelization, and demonstrate the superiority of our method towards resolving the privacy-utility trade-off for chest radiographs.
High-resolution synthesis of high-density breast mammograms: Application to improved fairness in deep learning based mass detection
Sep 20, 2022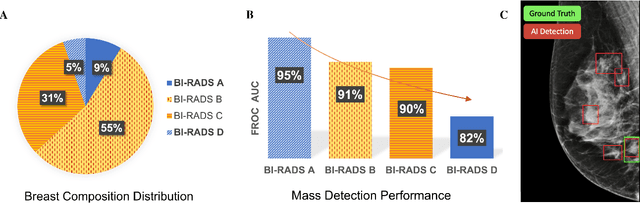
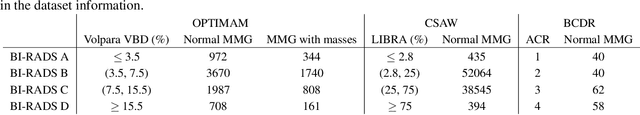
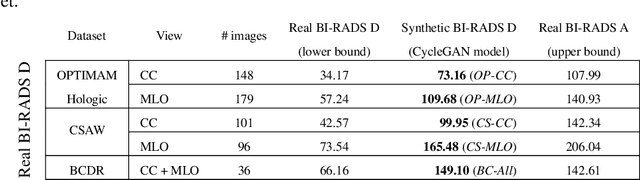
Computer-aided detection systems based on deep learning have shown good performance in breast cancer detection. However, high-density breasts show poorer detection performance since dense tissues can mask or even simulate masses. Therefore, the sensitivity of mammography for breast cancer detection can be reduced by more than 20% in dense breasts. Additionally, extremely dense cases reported an increased risk of cancer compared to low-density breasts. This study aims to improve the mass detection performance in high-density breasts using synthetic high-density full-field digital mammograms (FFDM) as data augmentation during breast mass detection model training. To this end, a total of five cycle-consistent GAN (CycleGAN) models using three FFDM datasets were trained for low-to-high-density image translation in high-resolution mammograms. The training images were split by breast density BI-RADS categories, being BI-RADS A almost entirely fatty and BI-RADS D extremely dense breasts. Our results showed that the proposed data augmentation technique improved the sensitivity and precision of mass detection in high-density breasts by 2% and 6% in two different test sets and was useful as a domain adaptation technique. In addition, the clinical realism of the synthetic images was evaluated in a reader study involving two expert radiologists and one surgical oncologist.
Attention based Broadly Self-guided Network for Low light Image Enhancement
Dec 12, 2021
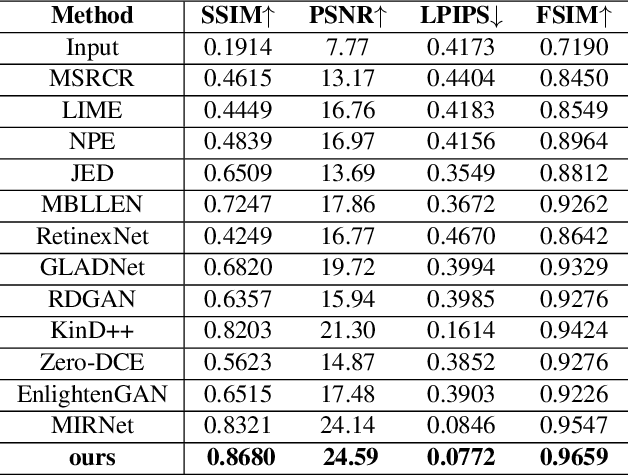
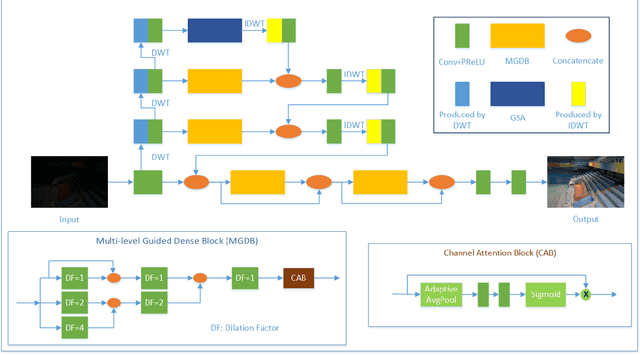
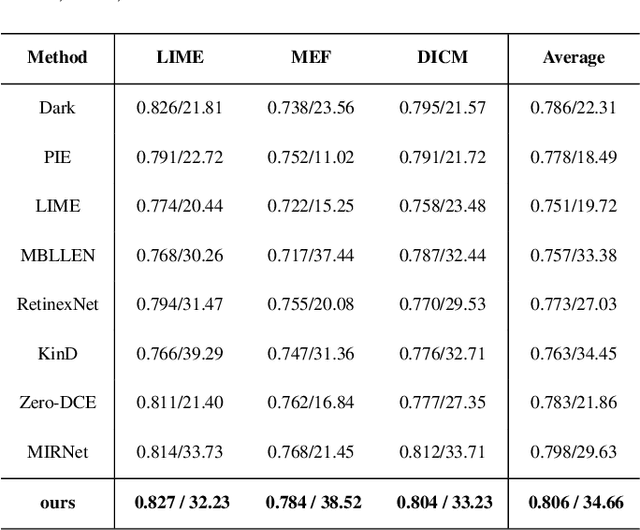
During the past years,deep convolutional neural networks have achieved impressive success in low-light Image Enhancement.Existing deep learning methods mostly enhance the ability of feature extraction by stacking network structures and deepening the depth of the network.which causes more runtime cost on single image.In order to reduce inference time while fully extracting local features and global features.Inspired by SGN,we propose a Attention based Broadly self-guided network (ABSGN) for real world low-light image Enhancement.such a broadly strategy is able to handle the noise at different exposures.The proposed network is validated by many mainstream benchmark.Additional experimental results show that the proposed network outperforms most of state-of-the-art low-light image Enhancement solutions.
Human Pose Driven Object Effects Recommendation
Sep 17, 2022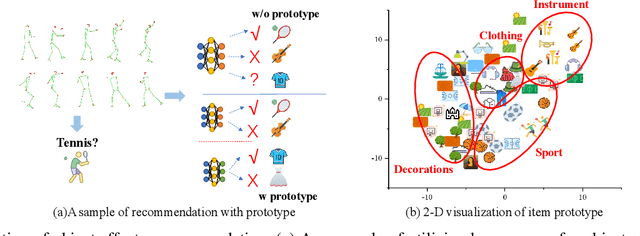
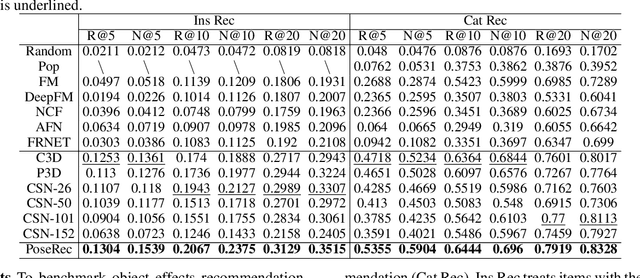
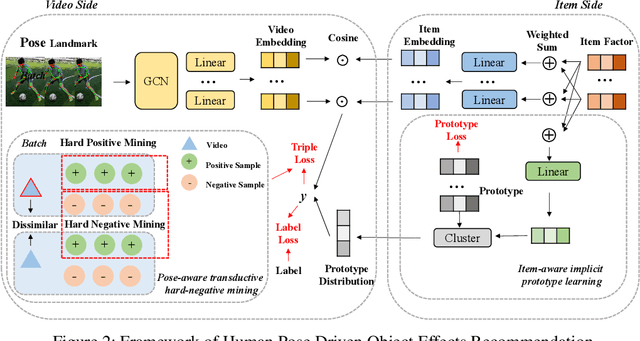
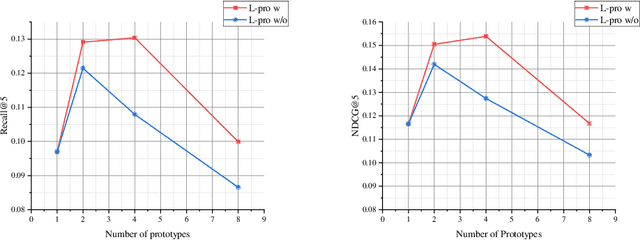
In this paper, we research the new topic of object effects recommendation in micro-video platforms, which is a challenging but important task for many practical applications such as advertisement insertion. To avoid the problem of introducing background bias caused by directly learning video content from image frames, we propose to utilize the meaningful body language hidden in 3D human pose for recommendation. To this end, in this work, a novel human pose driven object effects recommendation network termed PoseRec is introduced. PoseRec leverages the advantages of 3D human pose detection and learns information from multi-frame 3D human pose for video-item registration, resulting in high quality object effects recommendation performance. Moreover, to solve the inherent ambiguity and sparsity issues that exist in object effects recommendation, we further propose a novel item-aware implicit prototype learning module and a novel pose-aware transductive hard-negative mining module to better learn pose-item relationships. What's more, to benchmark methods for the new research topic, we build a new dataset for object effects recommendation named Pose-OBE. Extensive experiments on Pose-OBE demonstrate that our method can achieve superior performance than strong baselines.
Urine Microscopic Image Dataset
Nov 19, 2021Urinalysis is a standard diagnostic test to detect urinary system related problems. The automation of urinalysis will reduce the overall diagnostic time. Recent studies used urine microscopic datasets for designing deep learning based algorithms to classify and detect urine cells. But these datasets are not publicly available for further research. To alleviate the need for urine datsets, we prepare our urine sediment microscopic image (UMID) dataset comprising of around 3700 cell annotations and 3 categories of cells namely RBC, pus and epithelial cells. We discuss the several challenges involved in preparing the dataset and the annotations. We make the dataset publicly available.
StyleGAN of All Trades: Image Manipulation with Only Pretrained StyleGAN
Nov 02, 2021
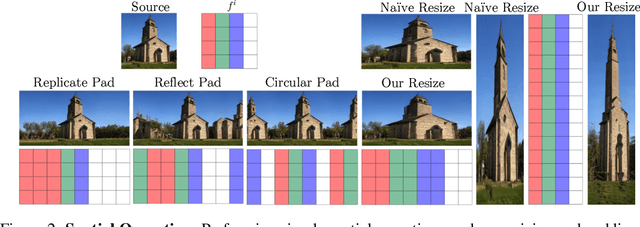


Recently, StyleGAN has enabled various image manipulation and editing tasks thanks to the high-quality generation and the disentangled latent space. However, additional architectures or task-specific training paradigms are usually required for different tasks. In this work, we take a deeper look at the spatial properties of StyleGAN. We show that with a pretrained StyleGAN along with some operations, without any additional architecture, we can perform comparably to the state-of-the-art methods on various tasks, including image blending, panorama generation, generation from a single image, controllable and local multimodal image to image translation, and attributes transfer. The proposed method is simple, effective, efficient, and applicable to any existing pretrained StyleGAN model.
Learning the Degradation Distribution for Blind Image Super-Resolution
Mar 09, 2022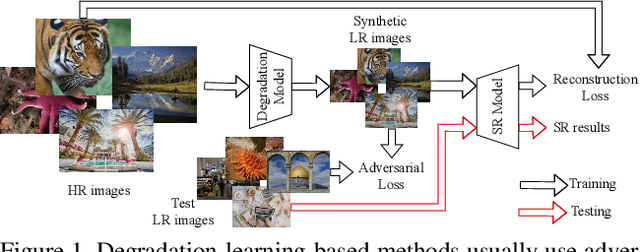
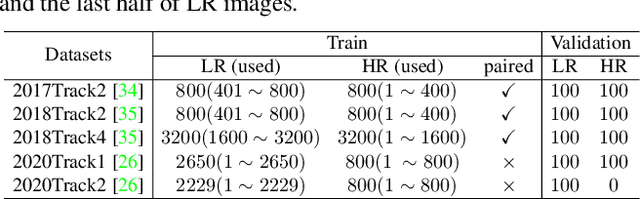
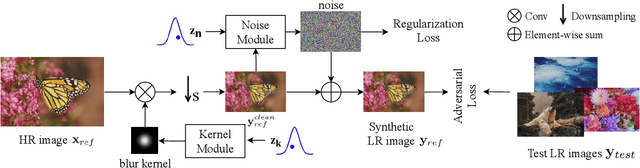
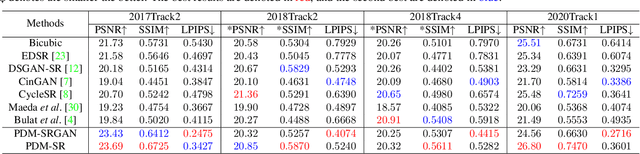
Synthetic high-resolution (HR) \& low-resolution (LR) pairs are widely used in existing super-resolution (SR) methods. To avoid the domain gap between synthetic and test images, most previous methods try to adaptively learn the synthesizing (degrading) process via a deterministic model. However, some degradations in real scenarios are stochastic and cannot be determined by the content of the image. These deterministic models may fail to model the random factors and content-independent parts of degradations, which will limit the performance of the following SR models. In this paper, we propose a probabilistic degradation model (PDM), which studies the degradation $\mathbf{D}$ as a random variable, and learns its distribution by modeling the mapping from a priori random variable $\mathbf{z}$ to $\mathbf{D}$. Compared with previous deterministic degradation models, PDM could model more diverse degradations and generate HR-LR pairs that may better cover the various degradations of test images, and thus prevent the SR model from over-fitting to specific ones. Extensive experiments have demonstrated that our degradation model can help the SR model achieve better performance on different datasets. The source codes are released at \url{git@github.com:greatlog/UnpairedSR.git}.
Disentangled Unsupervised Image Translation via Restricted Information Flow
Nov 26, 2021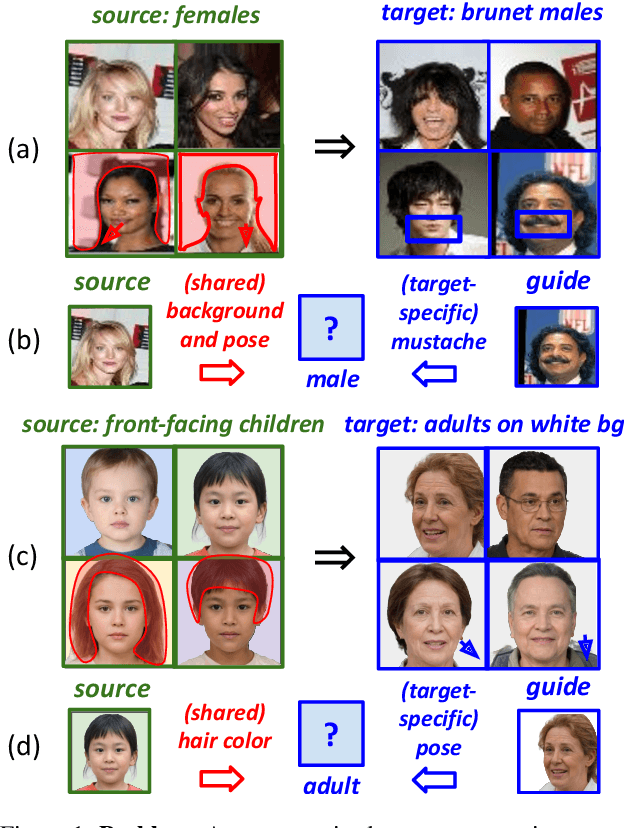
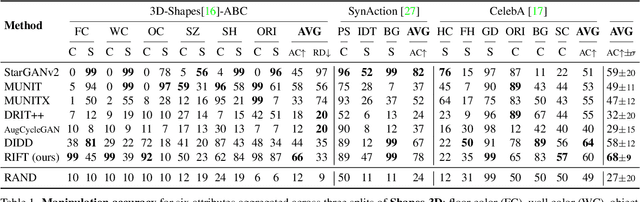
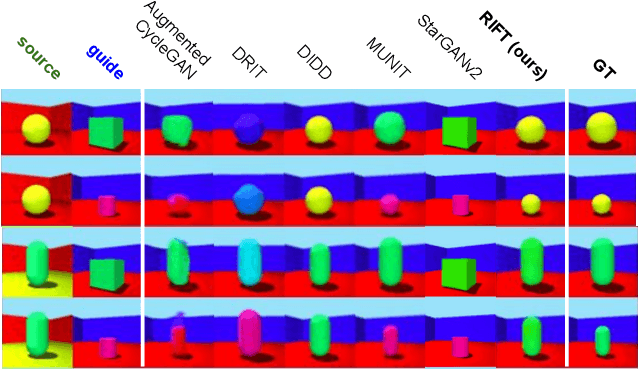
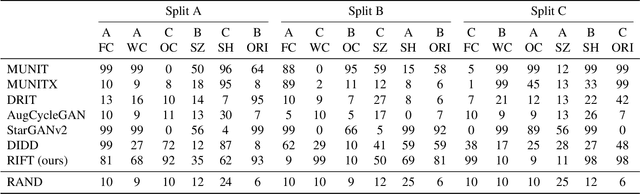
Unsupervised image-to-image translation methods aim to map images from one domain into plausible examples from another domain while preserving structures shared across two domains. In the many-to-many setting, an additional guidance example from the target domain is used to determine domain-specific attributes of the generated image. In the absence of attribute annotations, methods have to infer which factors are specific to each domain from data during training. Many state-of-art methods hard-code the desired shared-vs-specific split into their architecture, severely restricting the scope of the problem. In this paper, we propose a new method that does not rely on such inductive architectural biases, and infers which attributes are domain-specific from data by constraining information flow through the network using translation honesty losses and a penalty on the capacity of domain-specific embedding. We show that the proposed method achieves consistently high manipulation accuracy across two synthetic and one natural dataset spanning a wide variety of domain-specific and shared attributes.
Dynamic Attentive Graph Learning for Image Restoration
Sep 14, 2021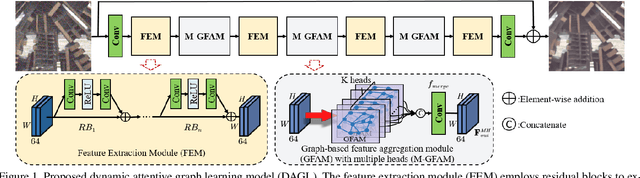
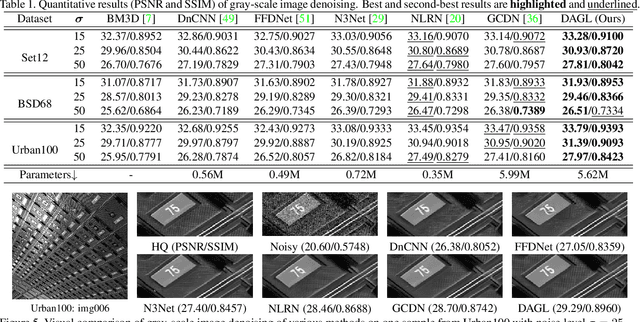
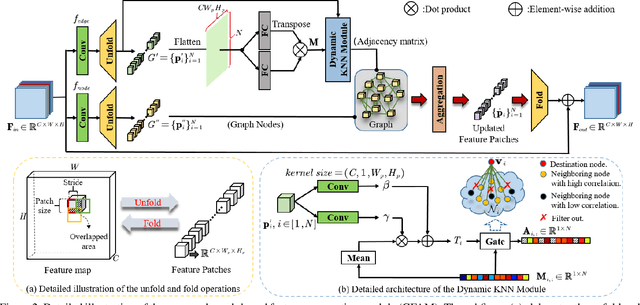
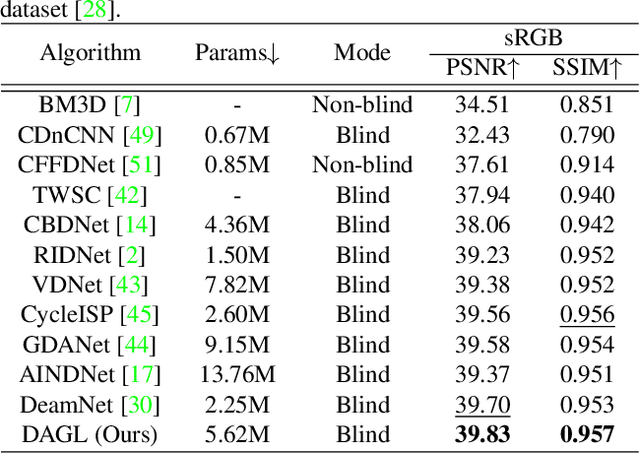
Non-local self-similarity in natural images has been verified to be an effective prior for image restoration. However, most existing deep non-local methods assign a fixed number of neighbors for each query item, neglecting the dynamics of non-local correlations. Moreover, the non-local correlations are usually based on pixels, prone to be biased due to image degradation. To rectify these weaknesses, in this paper, we propose a dynamic attentive graph learning model (DAGL) to explore the dynamic non-local property on patch level for image restoration. Specifically, we propose an improved graph model to perform patch-wise graph convolution with a dynamic and adaptive number of neighbors for each node. In this way, image content can adaptively balance over-smooth and over-sharp artifacts through the number of its connected neighbors, and the patch-wise non-local correlations can enhance the message passing process. Experimental results on various image restoration tasks: synthetic image denoising, real image denoising, image demosaicing, and compression artifact reduction show that our DAGL can produce state-of-the-art results with superior accuracy and visual quality. The source code is available at https://github.com/jianzhangcs/DAGL.
Continuous longitudinal fetus brain atlas construction via implicit neural representation
Sep 14, 2022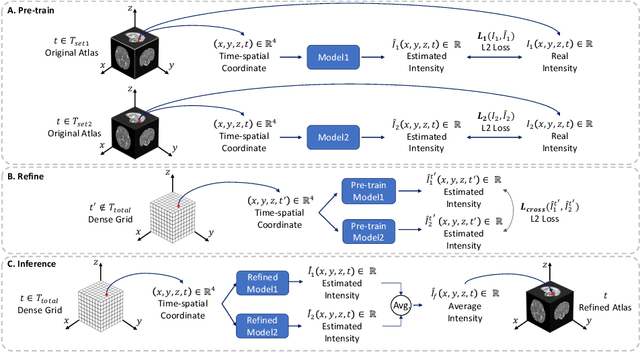
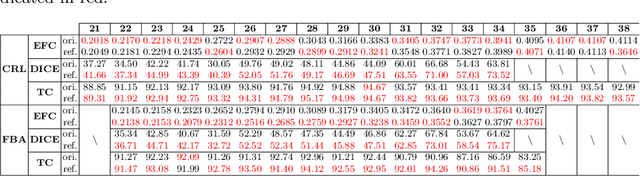
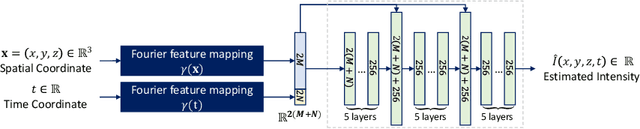
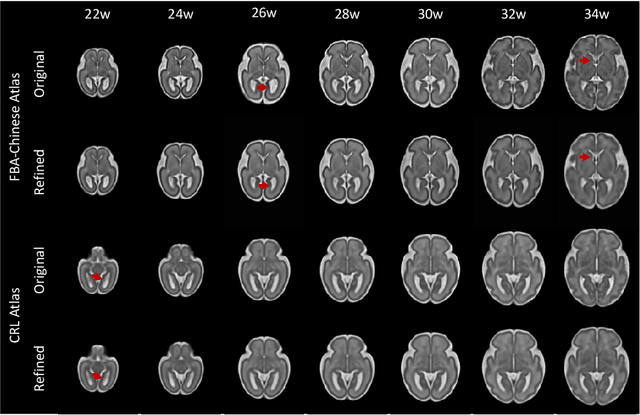
Longitudinal fetal brain atlas is a powerful tool for understanding and characterizing the complex process of fetus brain development. Existing fetus brain atlases are typically constructed by averaged brain images on discrete time points independently over time. Due to the differences in onto-genetic trends among samples at different time points, the resulting atlases suffer from temporal inconsistency, which may lead to estimating error of the brain developmental characteristic parameters along the timeline. To this end, we proposed a multi-stage deep-learning framework to tackle the time inconsistency issue as a 4D (3D brain volume + 1D age) image data denoising task. Using implicit neural representation, we construct a continuous and noise-free longitudinal fetus brain atlas as a function of the 4D spatial-temporal coordinate. Experimental results on two public fetal brain atlases (CRL and FBA-Chinese atlases) show that the proposed method can significantly improve the atlas temporal consistency while maintaining good fetus brain structure representation. In addition, the continuous longitudinal fetus brain atlases can also be extensively applied to generate finer 4D atlases in both spatial and temporal resolution.