 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Intention-driven Ego-to-Exo Video Generation
Mar 14, 2024


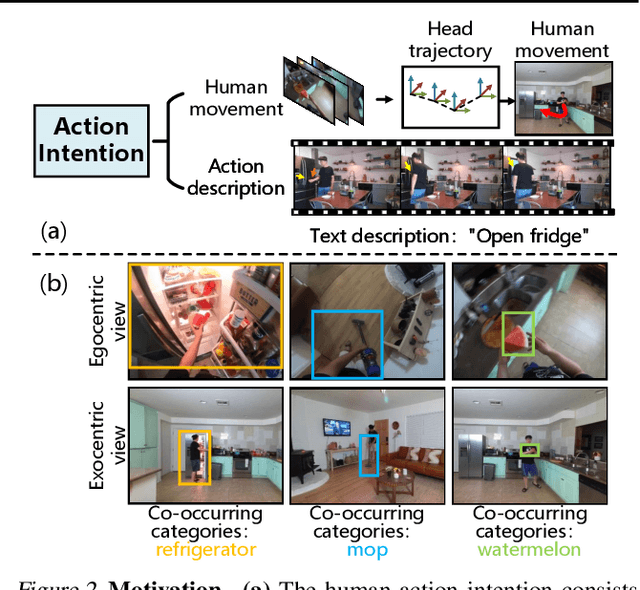
Ego-to-exo video generation refers to generating the corresponding exocentric video according to the egocentric video, providing valuable applications in AR/VR and embodied AI. Benefiting from advancements in diffusion model techniques, notable progress has been achieved in video generation. However, existing methods build upon the spatiotemporal consistency assumptions between adjacent frames, which cannot be satisfied in the ego-to-exo scenarios due to drastic changes in views. To this end, this paper proposes an Intention-Driven Ego-to-exo video generation framework (IDE) that leverages action intention consisting of human movement and action description as view-independent representation to guide video generation, preserving the consistency of content and motion. Specifically, the egocentric head trajectory is first estimated through multi-view stereo matching. Then, cross-view feature perception module is introduced to establish correspondences between exo- and ego- views, guiding the trajectory transformation module to infer human full-body movement from the head trajectory. Meanwhile, we present an action description unit that maps the action semantics into the feature space consistent with the exocentric image. Finally, the inferred human movement and high-level action descriptions jointly guide the generation of exocentric motion and interaction content (i.e., corresponding optical flow and occlusion maps) in the backward process of the diffusion model, ultimately warping them into the corresponding exocentric video. We conduct extensive experiments on the relevant dataset with diverse exo-ego video pairs, and our IDE outperforms state-of-the-art models in both subjective and objective assessments, demonstrating its efficacy in ego-to-exo video generation.
FastSAM3D: An Efficient Segment Anything Model for 3D Volumetric Medical Images
Mar 14, 2024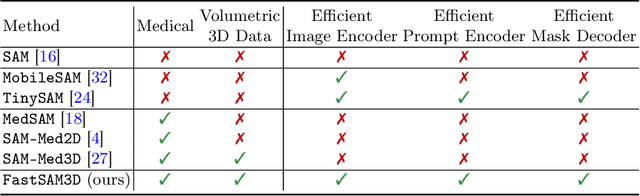
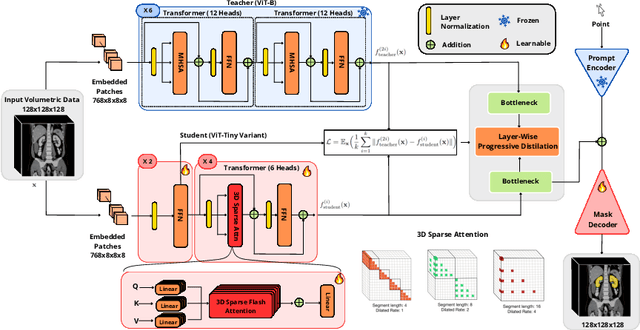
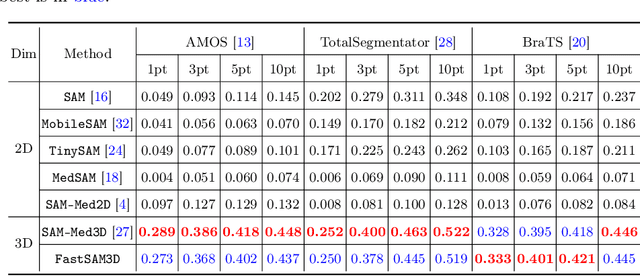
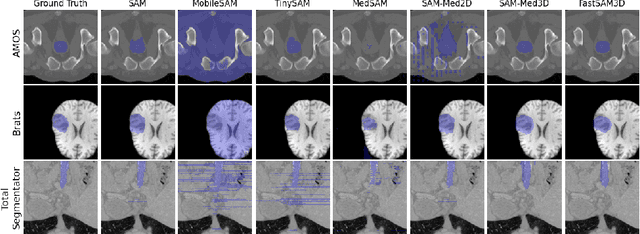
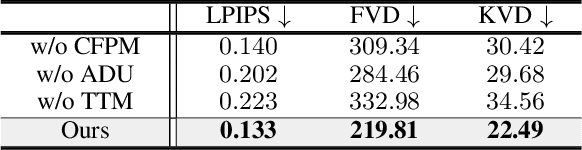
Segment anything models (SAMs) are gaining attention for their zero-shot generalization capability in segmenting objects of unseen classes and in unseen domains when properly prompted. Interactivity is a key strength of SAMs, allowing users to iteratively provide prompts that specify objects of interest to refine outputs. However, to realize the interactive use of SAMs for 3D medical imaging tasks, rapid inference times are necessary. High memory requirements and long processing delays remain constraints that hinder the adoption of SAMs for this purpose. Specifically, while 2D SAMs applied to 3D volumes contend with repetitive computation to process all slices independently, 3D SAMs suffer from an exponential increase in model parameters and FLOPS. To address these challenges, we present FastSAM3D which accelerates SAM inference to 8 milliseconds per 128*128*128 3D volumetric image on an NVIDIA A100 GPU. This speedup is accomplished through 1) a novel layer-wise progressive distillation scheme that enables knowledge transfer from a complex 12-layer ViT-B to a lightweight 6-layer ViT-Tiny variant encoder without training from scratch; and 2) a novel 3D sparse flash attention to replace vanilla attention operators, substantially reducing memory needs and improving parallelization. Experiments on three diverse datasets reveal that FastSAM3D achieves a remarkable speedup of 527.38x compared to 2D SAMs and 8.75x compared to 3D SAMs on the same volumes without significant performance decline. Thus, FastSAM3D opens the door for low-cost truly interactive SAM-based 3D medical imaging segmentation with commonly used GPU hardware. Code is available at https://github.com/arcadelab/FastSAM3D.
Gaussian Splatting in Style
Mar 13, 2024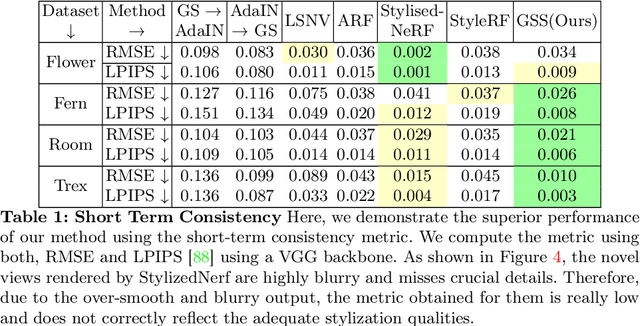

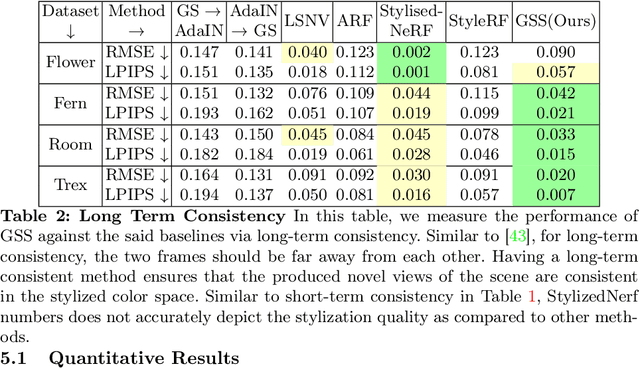
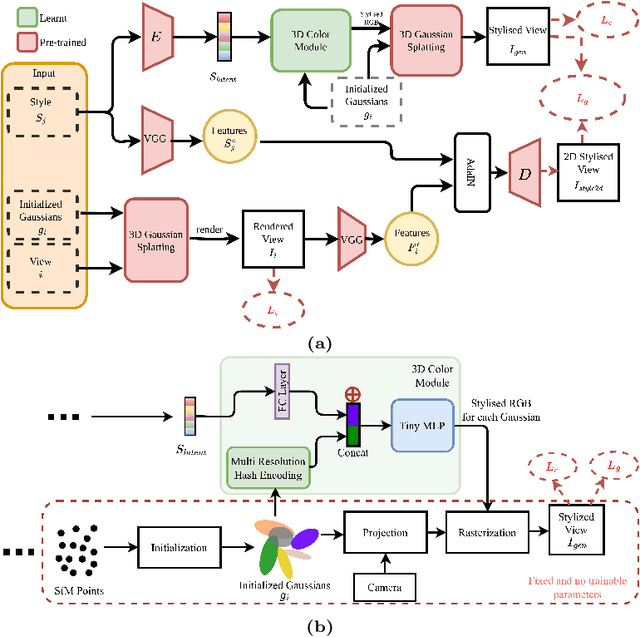
Scene stylization extends the work of neural style transfer to three spatial dimensions. A vital challenge in this problem is to maintain the uniformity of the stylized appearance across a multi-view setting. A vast majority of the previous works achieve this by optimizing the scene with a specific style image. In contrast, we propose a novel architecture trained on a collection of style images, that at test time produces high quality stylized novel views. Our work builds up on the framework of 3D Gaussian splatting. For a given scene, we take the pretrained Gaussians and process them using a multi resolution hash grid and a tiny MLP to obtain the conditional stylised views. The explicit nature of 3D Gaussians give us inherent advantages over NeRF-based methods including geometric consistency, along with having a fast training and rendering regime. This enables our method to be useful for vast practical use cases such as in augmented or virtual reality applications. Through our experiments, we show our methods achieve state-of-the-art performance with superior visual quality on various indoor and outdoor real-world data.
MIM4D: Masked Modeling with Multi-View Video for Autonomous Driving Representation Learning
Mar 13, 2024
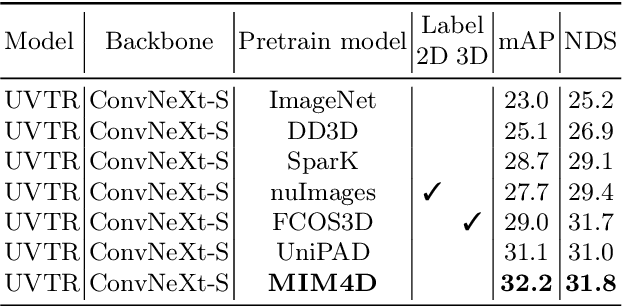
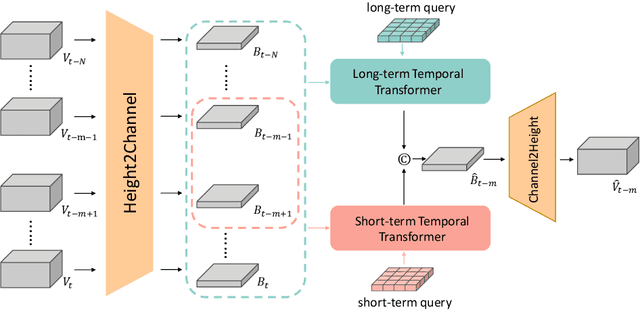
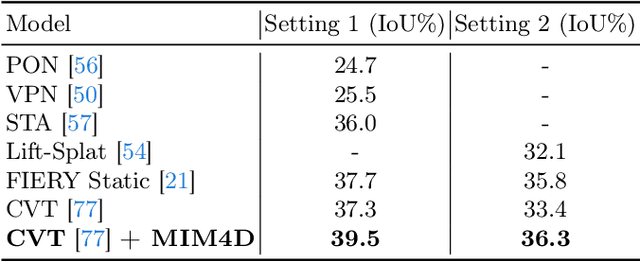
Learning robust and scalable visual representations from massive multi-view video data remains a challenge in computer vision and autonomous driving. Existing pre-training methods either rely on expensive supervised learning with 3D annotations, limiting the scalability, or focus on single-frame or monocular inputs, neglecting the temporal information. We propose MIM4D, a novel pre-training paradigm based on dual masked image modeling (MIM). MIM4D leverages both spatial and temporal relations by training on masked multi-view video inputs. It constructs pseudo-3D features using continuous scene flow and projects them onto 2D plane for supervision. To address the lack of dense 3D supervision, MIM4D reconstruct pixels by employing 3D volumetric differentiable rendering to learn geometric representations. We demonstrate that MIM4D achieves state-of-the-art performance on the nuScenes dataset for visual representation learning in autonomous driving. It significantly improves existing methods on multiple downstream tasks, including BEV segmentation (8.7% IoU), 3D object detection (3.5% mAP), and HD map construction (1.4% mAP). Our work offers a new choice for learning representation at scale in autonomous driving. Code and models are released at https://github.com/hustvl/MIM4D
Reduced Jeffries-Matusita distance: A Novel Loss Function to Improve Generalization Performance of Deep Classification Models
Mar 13, 2024
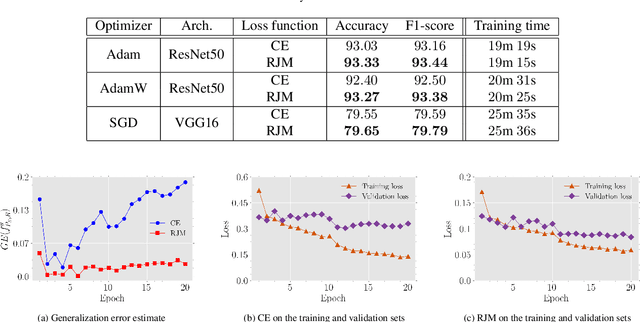
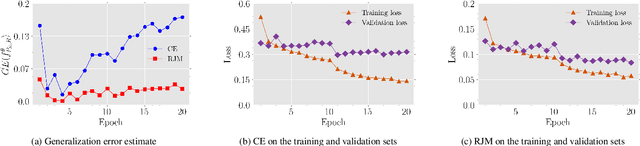
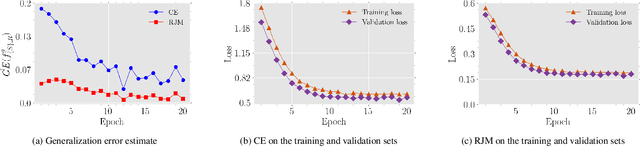
The generalization performance of deep neural networks in classification tasks is a major concern in machine learning research. Despite widespread techniques used to diminish the over-fitting issue such as data augmentation, pseudo-labeling, regularization, and ensemble learning, this performance still needs to be enhanced with other approaches. In recent years, it has been theoretically demonstrated that the loss function characteristics i.e. its Lipschitzness and maximum value affect the generalization performance of deep neural networks which can be utilized as a guidance to propose novel distance measures. In this paper, by analyzing the aforementioned characteristics, we introduce a distance called Reduced Jeffries-Matusita as a loss function for training deep classification models to reduce the over-fitting issue. In our experiments, we evaluate the new loss function in two different problems: image classification in computer vision and node classification in the context of graph learning. The results show that the new distance measure stabilizes the training process significantly, enhances the generalization ability, and improves the performance of the models in the Accuracy and F1-score metrics, even if the training set size is small.
Advancing Security in AI Systems: A Novel Approach to Detecting Backdoors in Deep Neural Networks
Mar 13, 2024
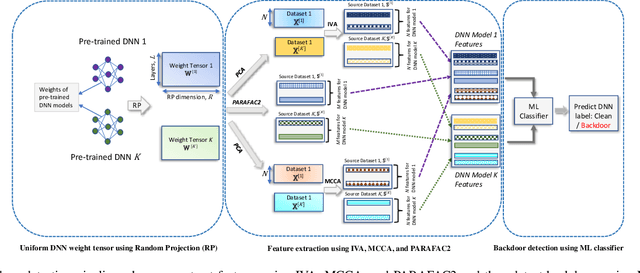

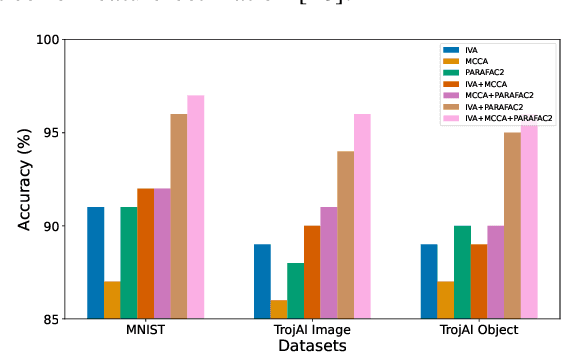
In the rapidly evolving landscape of communication and network security, the increasing reliance on deep neural networks (DNNs) and cloud services for data processing presents a significant vulnerability: the potential for backdoors that can be exploited by malicious actors. Our approach leverages advanced tensor decomposition algorithms Independent Vector Analysis (IVA), Multiset Canonical Correlation Analysis (MCCA), and Parallel Factor Analysis (PARAFAC2) to meticulously analyze the weights of pre-trained DNNs and distinguish between backdoored and clean models effectively. The key strengths of our method lie in its domain independence, adaptability to various network architectures, and ability to operate without access to the training data of the scrutinized models. This not only ensures versatility across different application scenarios but also addresses the challenge of identifying backdoors without prior knowledge of the specific triggers employed to alter network behavior. We have applied our detection pipeline to three distinct computer vision datasets, encompassing both image classification and object detection tasks. The results demonstrate a marked improvement in both accuracy and efficiency over existing backdoor detection methods. This advancement enhances the security of deep learning and AI in networked systems, providing essential cybersecurity against evolving threats in emerging technologies.
Model Will Tell: Training Membership Inference for Diffusion Models
Mar 13, 2024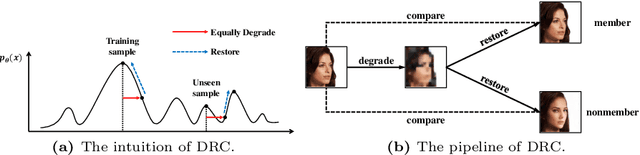
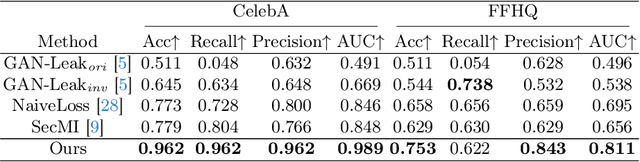
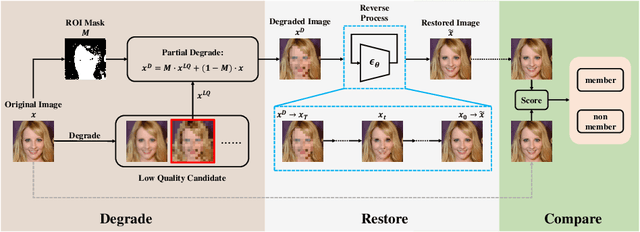
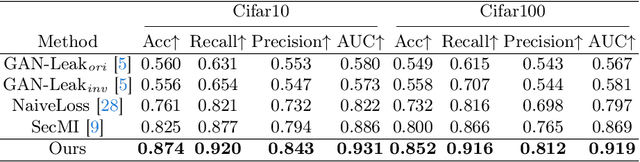
Diffusion models pose risks of privacy breaches and copyright disputes, primarily stemming from the potential utilization of unauthorized data during the training phase. The Training Membership Inference (TMI) task aims to determine whether a specific sample has been used in the training process of a target model, representing a critical tool for privacy violation verification. However, the increased stochasticity inherent in diffusion renders traditional shadow-model-based or metric-based methods ineffective when applied to diffusion models. Moreover, existing methods only yield binary classification labels which lack necessary comprehensibility in practical applications. In this paper, we explore a novel perspective for the TMI task by leveraging the intrinsic generative priors within the diffusion model. Compared with unseen samples, training samples exhibit stronger generative priors within the diffusion model, enabling the successful reconstruction of substantially degraded training images. Consequently, we propose the Degrade Restore Compare (DRC) framework. In this framework, an image undergoes sequential degradation and restoration, and its membership is determined by comparing it with the restored counterpart. Experimental results verify that our approach not only significantly outperforms existing methods in terms of accuracy but also provides comprehensible decision criteria, offering evidence for potential privacy violations.
Audio-Synchronized Visual Animation
Mar 08, 2024
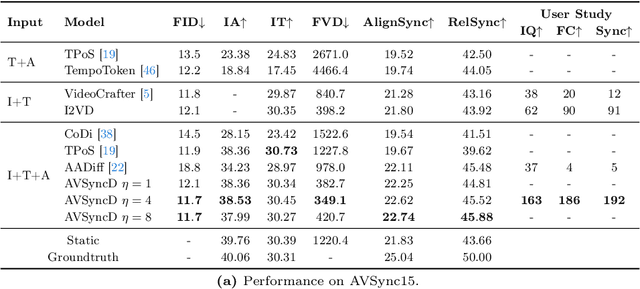
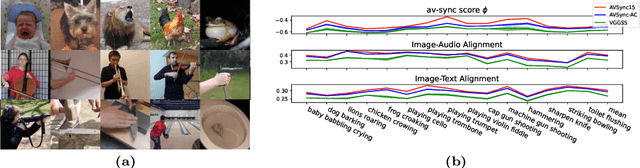

Current visual generation methods can produce high quality videos guided by texts. However, effectively controlling object dynamics remains a challenge. This work explores audio as a cue to generate temporally synchronized image animations. We introduce Audio Synchronized Visual Animation (ASVA), a task animating a static image to demonstrate motion dynamics, temporally guided by audio clips across multiple classes. To this end, we present AVSync15, a dataset curated from VGGSound with videos featuring synchronized audio visual events across 15 categories. We also present a diffusion model, AVSyncD, capable of generating dynamic animations guided by audios. Extensive evaluations validate AVSync15 as a reliable benchmark for synchronized generation and demonstrate our models superior performance. We further explore AVSyncDs potential in a variety of audio synchronized generation tasks, from generating full videos without a base image to controlling object motions with various sounds. We hope our established benchmark can open new avenues for controllable visual generation. More videos on project webpage https://lzhangbj.github.io/projects/asva/asva.html.
Masked Gamma-SSL: Learning Uncertainty Estimation via Masked Image Modeling
Feb 27, 2024This work proposes a semantic segmentation network that produces high-quality uncertainty estimates in a single forward pass. We exploit general representations from foundation models and unlabelled datasets through a Masked Image Modeling (MIM) approach, which is robust to augmentation hyper-parameters and simpler than previous techniques. For neural networks used in safety-critical applications, bias in the training data can lead to errors; therefore it is crucial to understand a network's limitations at run time and act accordingly. To this end, we test our proposed method on a number of test domains including the SAX Segmentation benchmark, which includes labelled test data from dense urban, rural and off-road driving domains. The proposed method consistently outperforms uncertainty estimation and Out-of-Distribution (OoD) techniques on this difficult benchmark.
Memory-based Adapters for Online 3D Scene Perception
Mar 11, 2024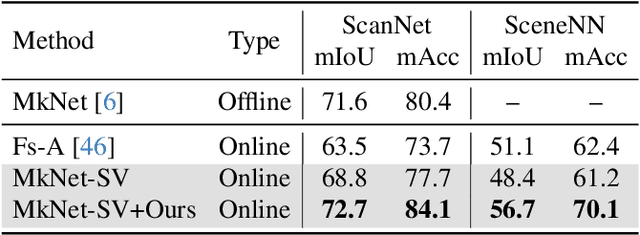
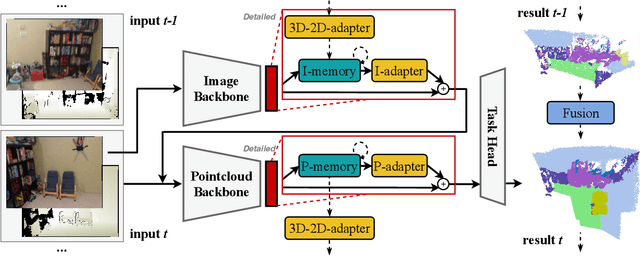
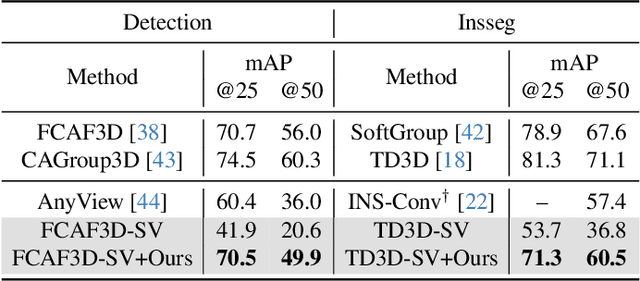
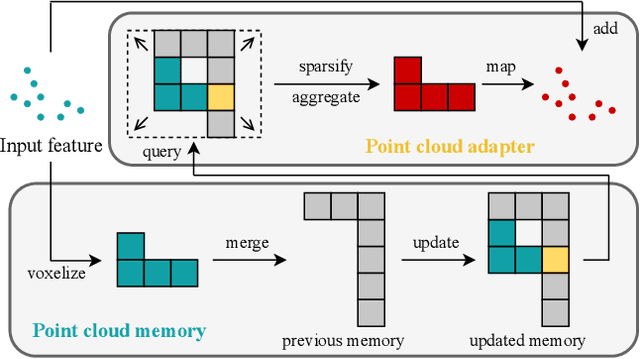
In this paper, we propose a new framework for online 3D scene perception. Conventional 3D scene perception methods are offline, i.e., take an already reconstructed 3D scene geometry as input, which is not applicable in robotic applications where the input data is streaming RGB-D videos rather than a complete 3D scene reconstructed from pre-collected RGB-D videos. To deal with online 3D scene perception tasks where data collection and perception should be performed simultaneously, the model should be able to process 3D scenes frame by frame and make use of the temporal information. To this end, we propose an adapter-based plug-and-play module for the backbone of 3D scene perception model, which constructs memory to cache and aggregate the extracted RGB-D features to empower offline models with temporal learning ability. Specifically, we propose a queued memory mechanism to cache the supporting point cloud and image features. Then we devise aggregation modules which directly perform on the memory and pass temporal information to current frame. We further propose 3D-to-2D adapter to enhance image features with strong global context. Our adapters can be easily inserted into mainstream offline architectures of different tasks and significantly boost their performance on online tasks. Extensive experiments on ScanNet and SceneNN datasets demonstrate our approach achieves leading performance on three 3D scene perception tasks compared with state-of-the-art online methods by simply finetuning existing offline models, without any model and task-specific designs. \href{https://xuxw98.github.io/Online3D/}{Project page}.