 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Strong Transfer Baseline for RGB-D Fusion in Vision Transformers
Oct 03, 2022
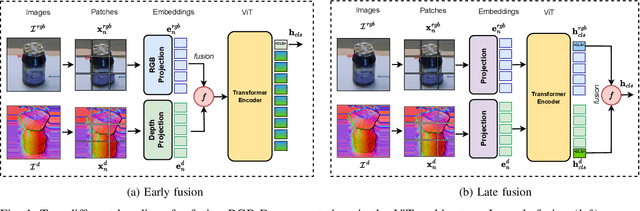
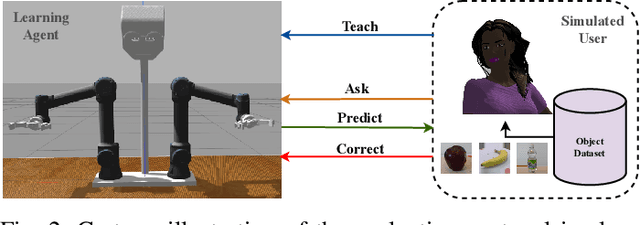

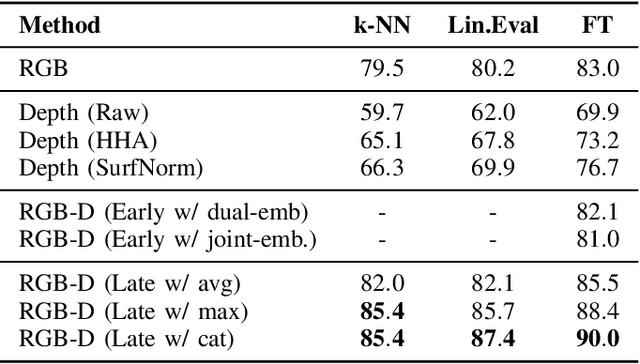
The Vision Transformer (ViT) architecture has recently established its place in the computer vision literature, with multiple architectures for recognition of image data or other visual modalities. However, training ViTs for RGB-D object recognition remains an understudied topic, viewed in recent literature only through the lens of multi-task pretraining in multiple modalities. Such approaches are often computationally intensive and have not yet been applied for challenging object-level classification tasks. In this work, we propose a simple yet strong recipe for transferring pretrained ViTs in RGB-D domains for single-view 3D object recognition, focusing on fusing RGB and depth representations encoded jointly by the ViT. Compared to previous works in multimodal Transformers, the key challenge here is to use the atested flexibility of ViTs to capture cross-modal interactions at the downstream and not the pretraining stage. We explore which depth representation is better in terms of resulting accuracy and compare two methods for injecting RGB-D fusion within the ViT architecture (i.e., early vs. late fusion). Our results in the Washington RGB-D Objects dataset demonstrates that in such RGB $\rightarrow$ RGB-D scenarios, late fusion techniques work better than most popularly employed early fusion. With our transfer baseline, adapted ViTs score up to 95.1\% top-1 accuracy in Washington, achieving new state-of-the-art results in this benchmark. We additionally evaluate our approach with an open-ended lifelong learning protocol, where we show that our adapted RGB-D encoder leads to features that outperform unimodal encoders, even without explicit fine-tuning. We further integrate our method with a robot framework and demonstrate how it can serve as a perception utility in an interactive robot learning scenario, both in simulation and with a real robot.
Towards a Unified View on Visual Parameter-Efficient Transfer Learning
Oct 03, 2022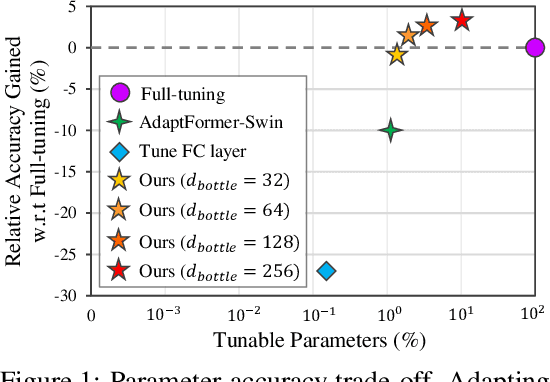
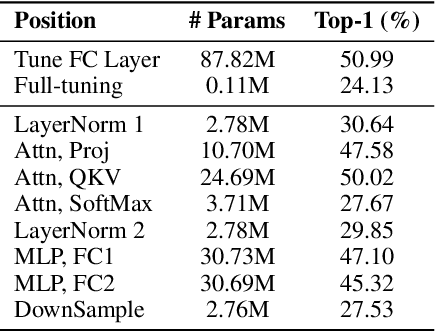
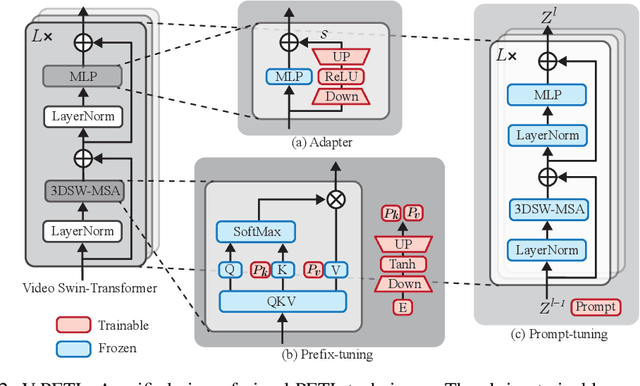
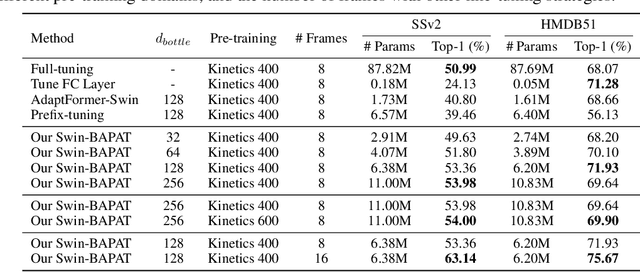
Since the release of various large-scale natural language processing (NLP) pre-trained models, parameter efficient transfer learning (PETL) has become a popular paradigm capable of achieving impressive performance on various downstream tasks. PETL aims at making good use of the representation knowledge in the pre-trained large models by fine-tuning a small number of parameters. Recently, it has also attracted increasing attention to developing various PETL techniques for vision tasks. Popular PETL techniques such as Prompt-tuning and Adapter have been proposed for high-level visual downstream tasks such as image classification and video recognition. However, Prefix-tuning remains under-explored for vision tasks. In this work, we intend to adapt large video-based models to downstream tasks with a good parameter-accuracy trade-off. Towards this goal, we propose a framework with a unified view called visual-PETL (V-PETL) to investigate the different aspects affecting the trade-off. Specifically, we analyze the positional importance of trainable parameters and differences between NLP and vision tasks in terms of data structures and pre-training mechanisms while implementing various PETL techniques, especially for the under-explored prefix-tuning technique. Based on a comprehensive understanding of differences between NLP and video data, we propose a new variation of prefix-tuning module called parallel attention (PATT) for video-based downstream tasks. An extensive empirical analysis on two video datasets via different frozen backbones has been carried and the findings show that the proposed PATT can effectively contribute to other PETL techniques. An effective scheme Swin-BAPAT derived from the proposed V-PETL framework achieves significantly better performance than the state-of-the-art AdaptFormer-Swin with slightly more parameters and outperforms full-tuning with far less parameters.
Hyperspectral Image Super-resolution with Deep Priors and Degradation Model Inversion
Jan 24, 2022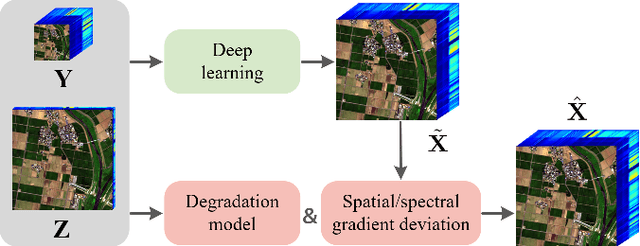
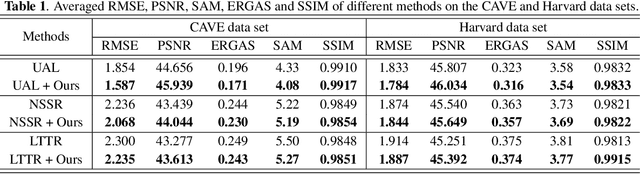
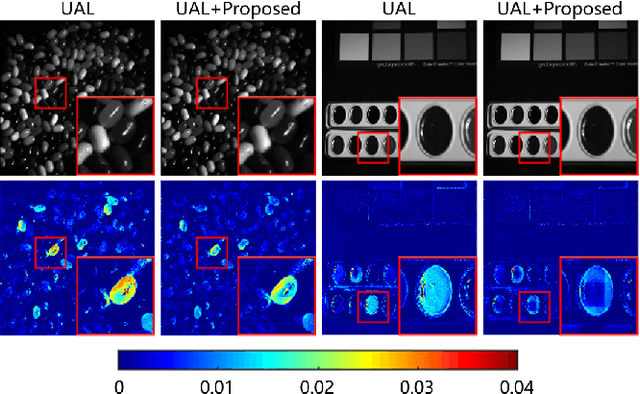
To overcome inherent hardware limitations of hyperspectral imaging systems with respect to their spatial resolution, fusion-based hyperspectral image (HSI) super-resolution is attracting increasing attention. This technique aims to fuse a low-resolution (LR) HSI and a conventional high-resolution (HR) RGB image in order to obtain an HR HSI. Recently, deep learning architectures have been used to address the HSI super-resolution problem and have achieved remarkable performance. However, they ignore the degradation model even though this model has a clear physical interpretation and may contribute to improve the performance. We address this problem by proposing a method that, on the one hand, makes use of the linear degradation model in the data-fidelity term of the objective function and, on the other hand, utilizes the output of a convolutional neural network for designing a deep prior regularizer in spectral and spatial gradient domains. Experiments show the performance improvement achieved with this strategy.
Visual Anomaly Detection Via Partition Memory Bank Module and Error Estimation
Sep 26, 2022
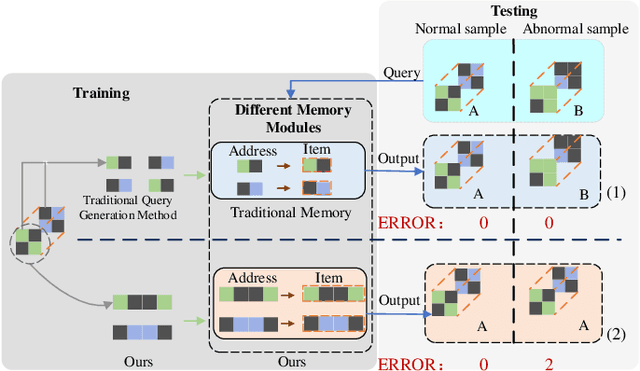
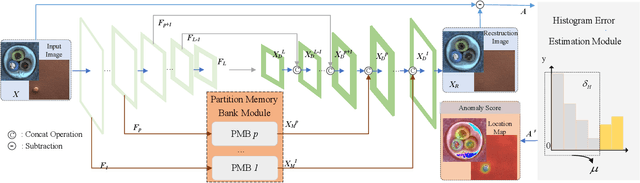
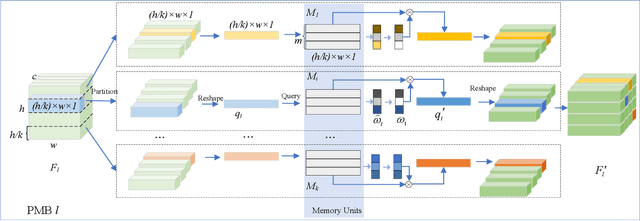
Reconstruction method based on the memory module for visual anomaly detection attempts to narrow the reconstruction error for normal samples while enlarging it for anomalous samples. Unfortunately, the existing memory module is not fully applicable to the anomaly detection task, and the reconstruction error of the anomaly samples remains small. Towards this end, this work proposes a new unsupervised visual anomaly detection method to jointly learn effective normal features and eliminate unfavorable reconstruction errors. Specifically, a novel Partition Memory Bank (PMB) module is proposed to effectively learn and store detailed features with semantic integrity of normal samples. It develops a new partition mechanism and a unique query generation method to preserve the context information and then improves the learning ability of the memory module. The proposed PMB and the skip connection are alternatively explored to make the reconstruction of abnormal samples worse. To obtain more precise anomaly localization results and solve the problem of cumulative reconstruction error, a novel Histogram Error Estimation module is proposed to adaptively eliminate the unfavorable errors by the histogram of the difference image. It improves the anomaly localization performance without increasing the cost. To evaluate the effectiveness of the proposed method for anomaly detection and localization, extensive experiments are conducted on three widely-used anomaly detection datasets. The encouraging performance of the proposed method compared to the recent approaches based on the memory module demonstrates its superiority.
Maximizing Self-supervision from Thermal Image for Effective Self-supervised Learning of Depth and Ego-motion
Jan 12, 2022

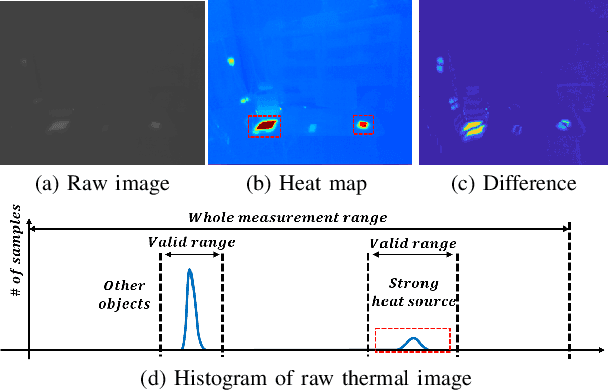
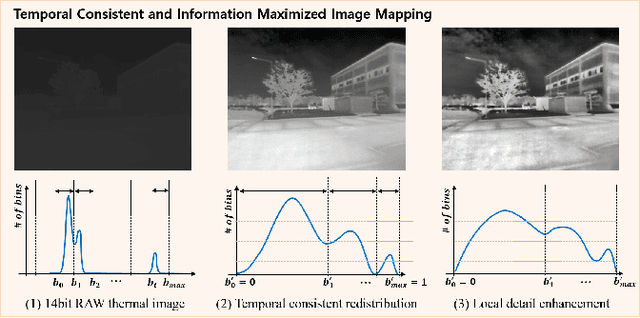
Recently, self-supervised learning of depth and ego-motion from thermal images shows strong robustness and reliability under challenging scenarios. However, the inherent thermal image properties such as weak contrast, blurry edges, and noise hinder to generate effective self-supervision from thermal images. Therefore, most research relies on additional self-supervision sources such as well-lit RGB images, generative models, and Lidar information. In this paper, we conduct an in-depth analysis of thermal image characteristics that degenerates self-supervision from thermal images. Based on the analysis, we propose an effective thermal image mapping method that significantly increases image information, such as overall structure, contrast, and details, while preserving temporal consistency. The proposed method shows outperformed depth and pose results than previous state-of-the-art networks without leveraging additional RGB guidance.
FoVolNet: Fast Volume Rendering using Foveated Deep Neural Networks
Sep 20, 2022



Volume data is found in many important scientific and engineering applications. Rendering this data for visualization at high quality and interactive rates for demanding applications such as virtual reality is still not easily achievable even using professional-grade hardware. We introduce FoVolNet -- a method to significantly increase the performance of volume data visualization. We develop a cost-effective foveated rendering pipeline that sparsely samples a volume around a focal point and reconstructs the full-frame using a deep neural network. Foveated rendering is a technique that prioritizes rendering computations around the user's focal point. This approach leverages properties of the human visual system, thereby saving computational resources when rendering data in the periphery of the user's field of vision. Our reconstruction network combines direct and kernel prediction methods to produce fast, stable, and perceptually convincing output. With a slim design and the use of quantization, our method outperforms state-of-the-art neural reconstruction techniques in both end-to-end frame times and visual quality. We conduct extensive evaluations of the system's rendering performance, inference speed, and perceptual properties, and we provide comparisons to competing neural image reconstruction techniques. Our test results show that FoVolNet consistently achieves significant time saving over conventional rendering while preserving perceptual quality.
Transformers and CNNs both Beat Humans on SBIR
Sep 14, 2022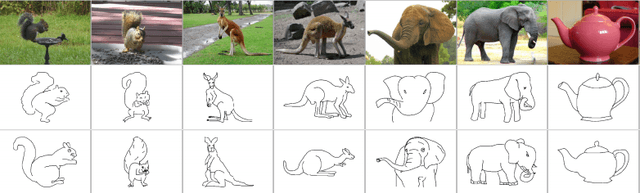


Sketch-based image retrieval (SBIR) is the task of retrieving natural images (photos) that match the semantics and the spatial configuration of hand-drawn sketch queries. The universality of sketches extends the scope of possible applications and increases the demand for efficient SBIR solutions. In this paper, we study classic triplet-based SBIR solutions and show that a persistent invariance to horizontal flip (even after model finetuning) is harming performance. To overcome this limitation, we propose several approaches and evaluate in depth each of them to check their effectiveness. Our main contributions are twofold: We propose and evaluate several intuitive modifications to build SBIR solutions with better flip equivariance. We show that vision transformers are more suited for the SBIR task, and that they outperform CNNs with a large margin. We carried out numerous experiments and introduce the first models to outperform human performance on a large-scale SBIR benchmark (Sketchy). Our best model achieves a recall of 62.25% (at k = 1) on the sketchy benchmark compared to previous state-of-the-art methods 46.2%.
Multi-Granularity Graph Pooling for Video-based Person Re-Identification
Sep 23, 2022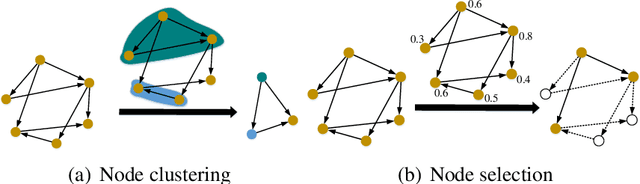
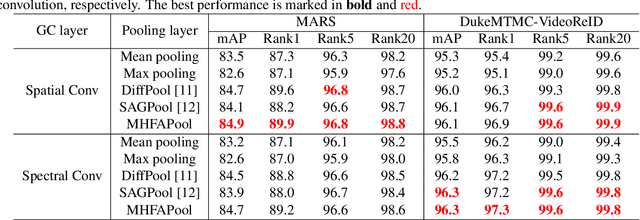
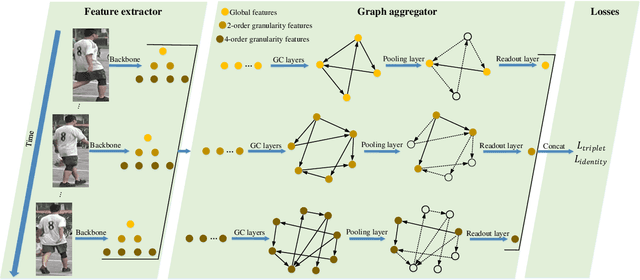
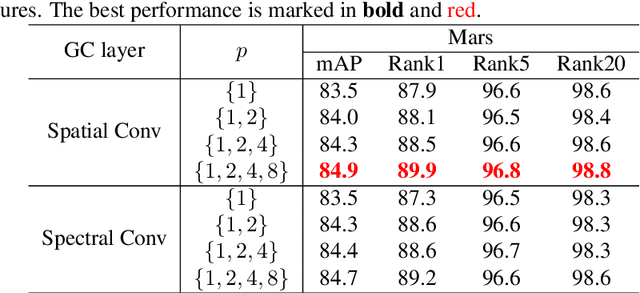
The video-based person re-identification (ReID) aims to identify the given pedestrian video sequence across multiple non-overlapping cameras. To aggregate the temporal and spatial features of the video samples, the graph neural networks (GNNs) are introduced. However, existing graph-based models, like STGCN, perform the \textit{mean}/\textit{max pooling} on node features to obtain the graph representation, which neglect the graph topology and node importance. In this paper, we propose the graph pooling network (GPNet) to learn the multi-granularity graph representation for the video retrieval, where the \textit{graph pooling layer} is implemented to downsample the graph. We first construct a multi-granular graph, whose node features denote image embedding learned by backbone, and edges are established between the temporal and Euclidean neighborhood nodes. We then implement multiple graph convolutional layers to perform the neighborhood aggregation on the graphs. To downsample the graph, we propose a multi-head full attention graph pooling (MHFAPool) layer, which integrates the advantages of existing node clustering and node selection pooling methods. Specifically, MHFAPool takes the main eigenvector of full attention matrix as the aggregation coefficients to involve the global graph information in each pooled nodes. Extensive experiments demonstrate that our GPNet achieves the competitive results on four widely-used datasets, i.e., MARS, DukeMTMC-VideoReID, iLIDS-VID and PRID-2011.
Deep Labeling of fMRI Brain Networks Using Cloud Based Processing
Sep 20, 2022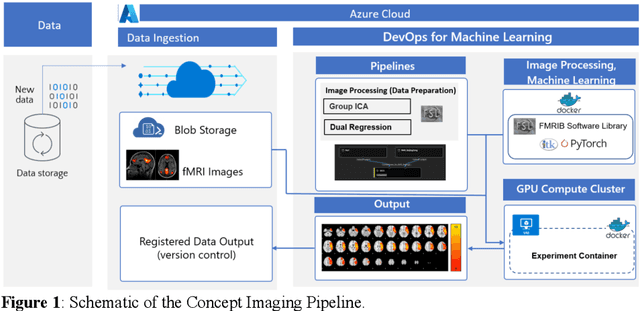
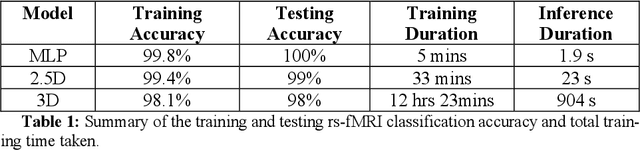

Resting state fMRI is an imaging modality which reveals brain activity localization through signal changes, in what is known as Resting State Networks (RSNs). This technique is gaining popularity in neurosurgical pre-planning to visualize the functional regions and assess regional activity. Labeling of rs-fMRI networks require subject-matter expertise and is time consuming, creating a need for an automated classification algorithm. While the impact of AI in medical diagnosis has shown great progress; deploying and maintaining these in a clinical setting is an unmet need. We propose an end-to-end reproducible pipeline which incorporates image processing of rs-fMRI in a cloud-based workflow while using deep learning to automate the classification of RSNs. We have architected a reproducible Azure Machine Learning cloud-based medical imaging concept pipeline for fMRI analysis integrating the popular FMRIB Software Library (FSL) toolkit. To demonstrate a clinical application using a large dataset, we compare three neural network architectures for classification of deeper RSNs derived from processed rs-fMRI. The three algorithms are: an MLP, a 2D projection-based CNN, and a fully 3D CNN classification networks. Each of the net-works was trained on the rs-fMRI back-projected independent components giving >98% accuracy for each classification method.
Attention based Broadly Self-guided Network for Low light Image Enhancement
Dec 12, 2021
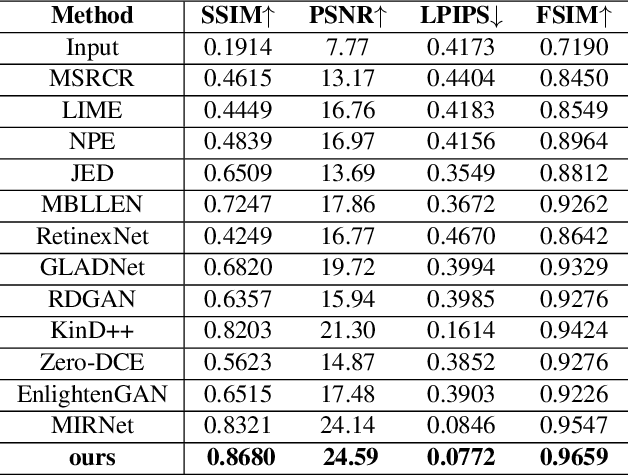
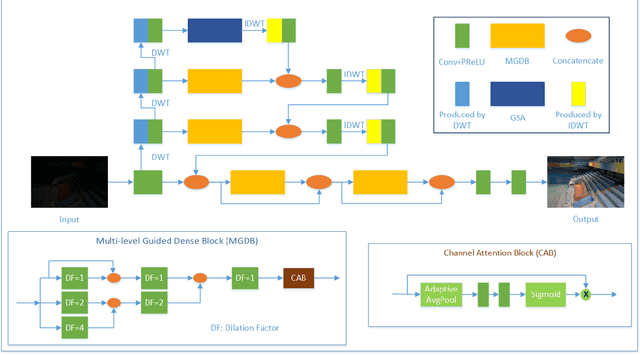
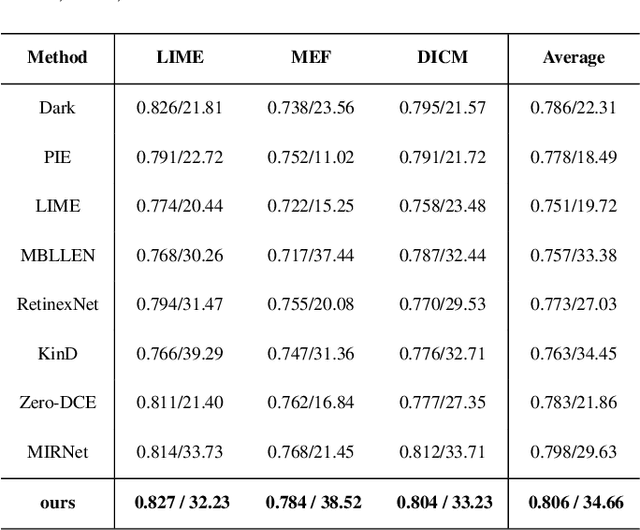
During the past years,deep convolutional neural networks have achieved impressive success in low-light Image Enhancement.Existing deep learning methods mostly enhance the ability of feature extraction by stacking network structures and deepening the depth of the network.which causes more runtime cost on single image.In order to reduce inference time while fully extracting local features and global features.Inspired by SGN,we propose a Attention based Broadly self-guided network (ABSGN) for real world low-light image Enhancement.such a broadly strategy is able to handle the noise at different exposures.The proposed network is validated by many mainstream benchmark.Additional experimental results show that the proposed network outperforms most of state-of-the-art low-light image Enhancement solutions.