 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
TGFuse: An Infrared and Visible Image Fusion Approach Based on Transformer and Generative Adversarial Network
Feb 04, 2022

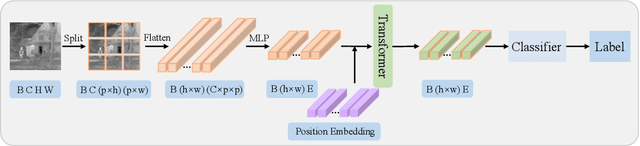
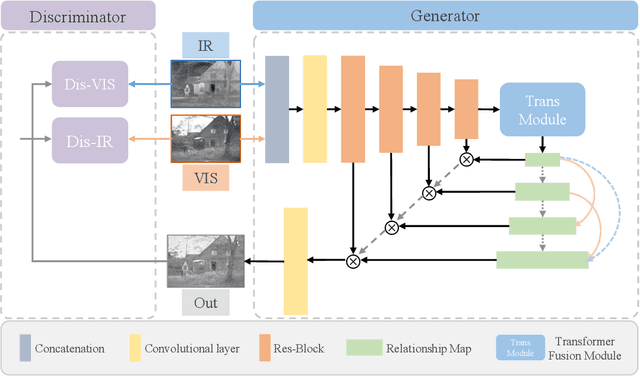
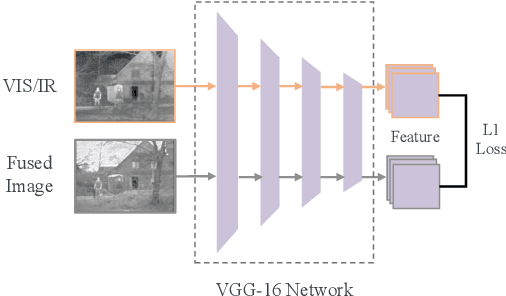
The end-to-end image fusion framework has achieved promising performance, with dedicated convolutional networks aggregating the multi-modal local appearance. However, long-range dependencies are directly neglected in existing CNN fusion approaches, impeding balancing the entire image-level perception for complex scenario fusion. In this paper, therefore, we propose an infrared and visible image fusion algorithm based on a lightweight transformer module and adversarial learning. Inspired by the global interaction power, we use the transformer technique to learn the effective global fusion relations. In particular, shallow features extracted by CNN are interacted in the proposed transformer fusion module to refine the fusion relationship within the spatial scope and across channels simultaneously. Besides, adversarial learning is designed in the training process to improve the output discrimination via imposing competitive consistency from the inputs, reflecting the specific characteristics in infrared and visible images. The experimental performance demonstrates the effectiveness of the proposed modules, with superior improvement against the state-of-the-art, generalising a novel paradigm via transformer and adversarial learning in the fusion task.
Fault Detection and Classification of Aerospace Sensors using a VGG16-based Deep Neural Network
Jul 27, 2022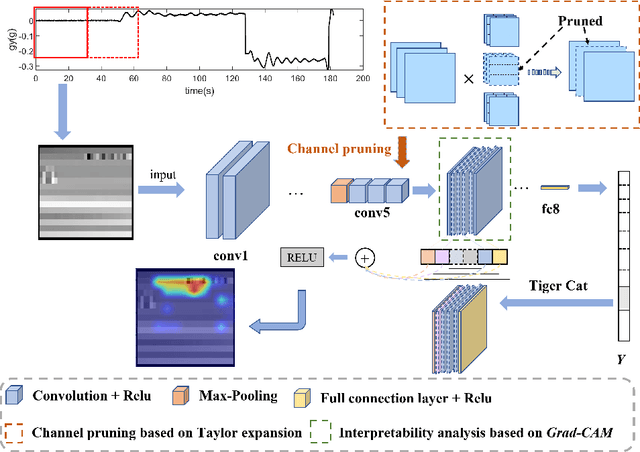
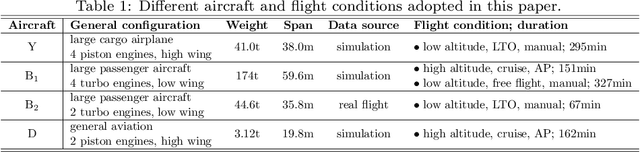

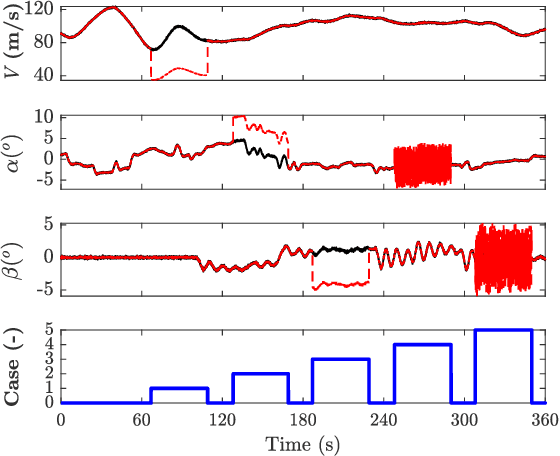
Compared with traditional model-based fault detection and classification (FDC) methods, deep neural networks (DNN) prove to be effective for the aerospace sensors FDC problems. However, time being consumed in training the DNN is excessive, and explainability analysis for the FDC neural network is still underwhelming. A concept known as imagefication-based intelligent FDC has been studied in recent years. This concept advocates to stack the sensors measurement data into an image format, the sensors FDC issue is then transformed to abnormal regions detection problem on the stacked image, which may well borrow the recent advances in the machine vision vision realm. Although promising results have been claimed in the imagefication-based intelligent FDC researches, due to the low size of the stacked image, small convolutional kernels and shallow DNN layers were used, which hinders the FDC performance. In this paper, we first propose a data augmentation method which inflates the stacked image to a larger size (correspondent to the VGG16 net developed in the machine vision realm). The FDC neural network is then trained via fine-tuning the VGG16 directly. To truncate and compress the FDC net size (hence its running time), we perform model pruning on the fine-tuned net. Class activation mapping (CAM) method is also adopted for explainability analysis of the FDC net to verify its internal operations. Via data augmentation, fine-tuning from VGG16, and model pruning, the FDC net developed in this paper claims an FDC accuracy 98.90% across 4 aircraft at 5 flight conditions (running time 26 ms). The CAM results also verify the FDC net w.r.t. its internal operations.
No way to crop: On robust image crop localization
Oct 12, 2021
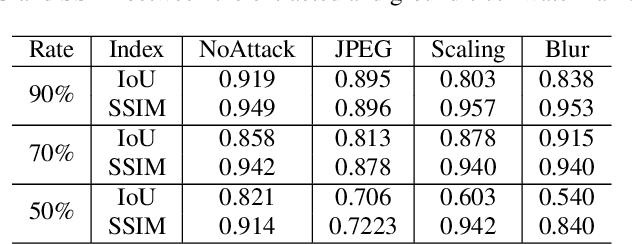
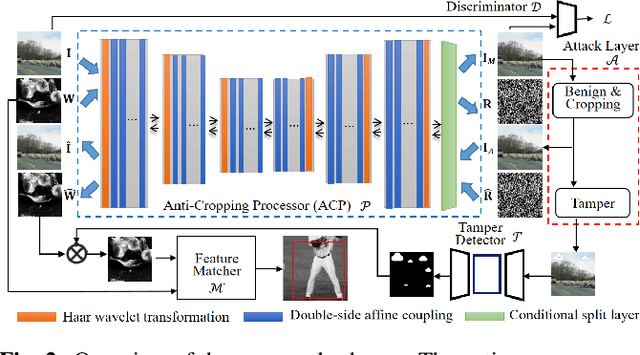
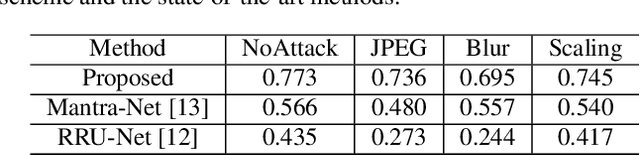
Previous image forensics schemes for crop detection are only limited on predicting whether an image has been cropped. This paper presents a novel scheme for image crop localization using robust watermarking. We further extend our scheme to detect tampering attack on the attacked image. We demonstrate that our scheme is the first to provide high-accuracy and robust image crop localization. Besides, the accuracy of tamper detection is comparable to many state-of-the-art methods.
Adaptive Contrast for Image Regression in Computer-Aided Disease Assessment
Dec 22, 2021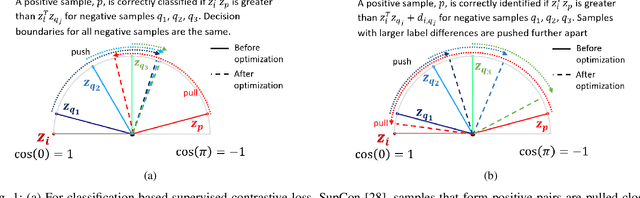
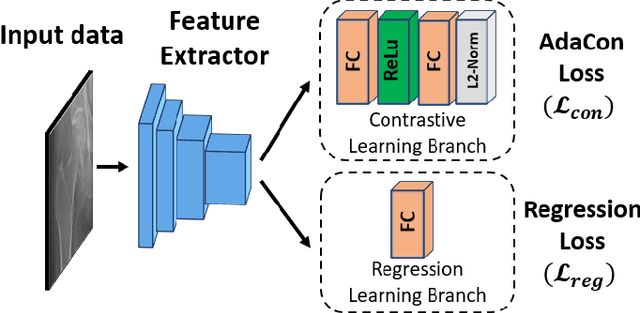
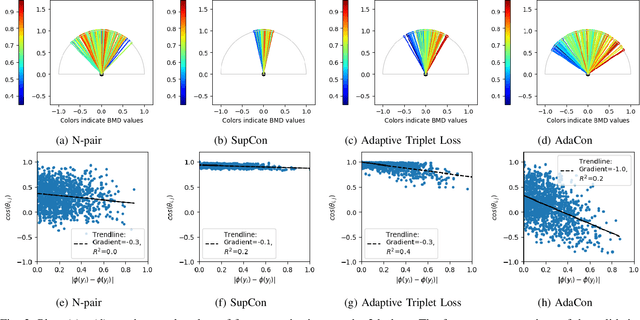
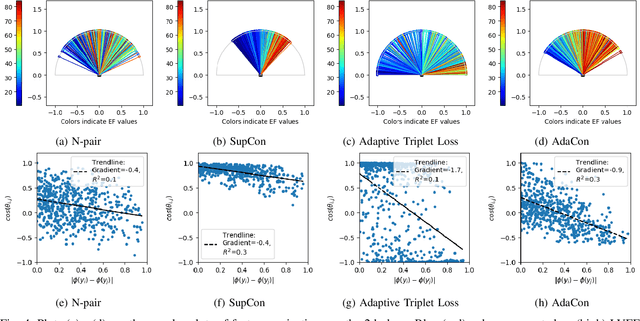
Image regression tasks for medical applications, such as bone mineral density (BMD) estimation and left-ventricular ejection fraction (LVEF) prediction, play an important role in computer-aided disease assessment. Most deep regression methods train the neural network with a single regression loss function like MSE or L1 loss. In this paper, we propose the first contrastive learning framework for deep image regression, namely AdaCon, which consists of a feature learning branch via a novel adaptive-margin contrastive loss and a regression prediction branch. Our method incorporates label distance relationships as part of the learned feature representations, which allows for better performance in downstream regression tasks. Moreover, it can be used as a plug-and-play module to improve performance of existing regression methods. We demonstrate the effectiveness of AdaCon on two medical image regression tasks, ie, bone mineral density estimation from X-ray images and left-ventricular ejection fraction prediction from echocardiogram videos. AdaCon leads to relative improvements of 3.3% and 5.9% in MAE over state-of-the-art BMD estimation and LVEF prediction methods, respectively.
Segmentation-Reconstruction-Guided Facial Image De-occlusion
Dec 15, 2021
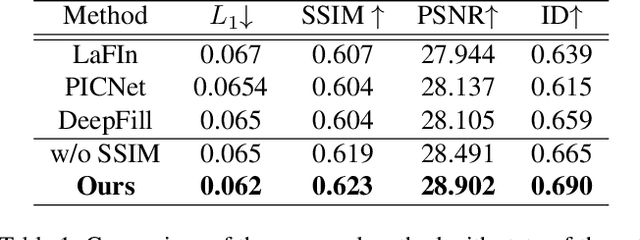
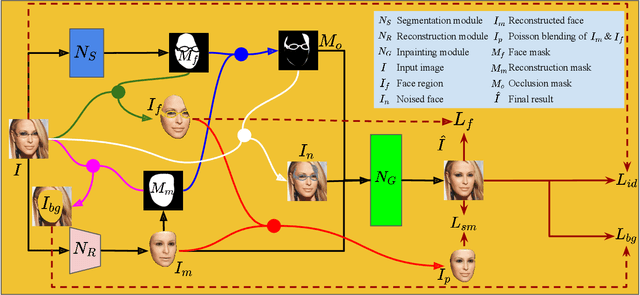
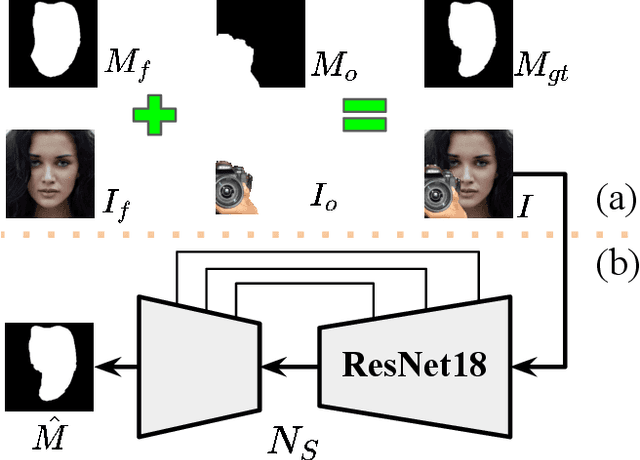
Occlusions are very common in face images in the wild, leading to the degraded performance of face-related tasks. Although much effort has been devoted to removing occlusions from face images, the varying shapes and textures of occlusions still challenge the robustness of current methods. As a result, current methods either rely on manual occlusion masks or only apply to specific occlusions. This paper proposes a novel face de-occlusion model based on face segmentation and 3D face reconstruction, which automatically removes all kinds of face occlusions with even blurred boundaries,e.g., hairs. The proposed model consists of a 3D face reconstruction module, a face segmentation module, and an image generation module. With the face prior and the occlusion mask predicted by the first two, respectively, the image generation module can faithfully recover the missing facial textures. To supervise the training, we further build a large occlusion dataset, with both manually labeled and synthetic occlusions. Qualitative and quantitative results demonstrate the effectiveness and robustness of the proposed method.
Saliency Guided Adversarial Training for Learning Generalizable Features with Applications to Medical Imaging Classification System
Sep 09, 2022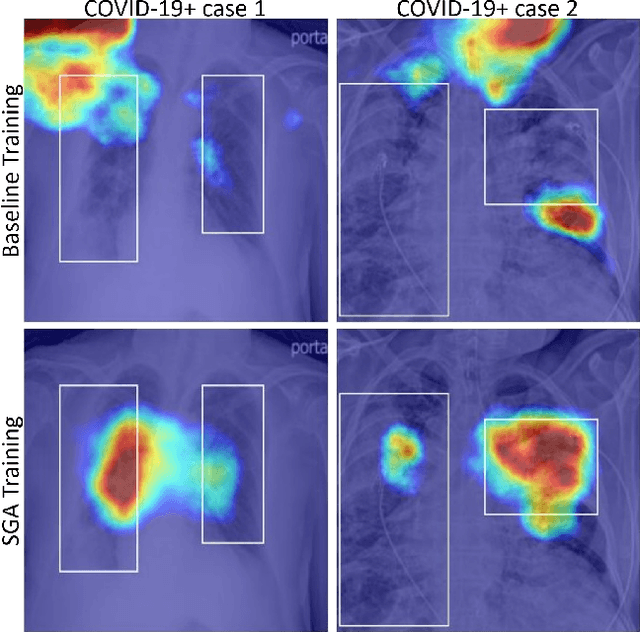
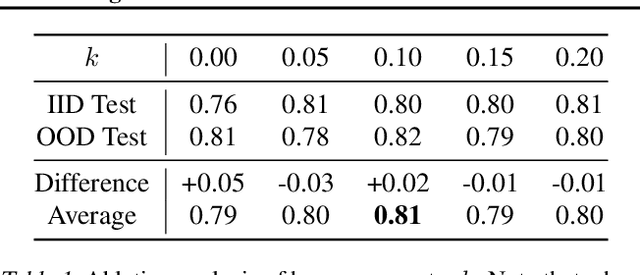
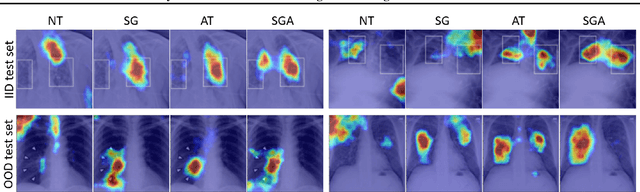
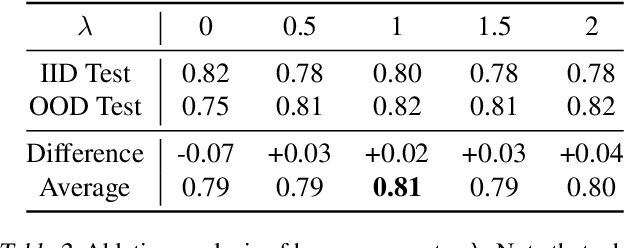
This work tackles a central machine learning problem of performance degradation on out-of-distribution (OOD) test sets. The problem is particularly salient in medical imaging based diagnosis system that appears to be accurate but fails when tested in new hospitals/datasets. Recent studies indicate the system might learn shortcut and non-relevant features instead of generalizable features, so-called good features. We hypothesize that adversarial training can eliminate shortcut features whereas saliency guided training can filter out non-relevant features; both are nuisance features accounting for the performance degradation on OOD test sets. With that, we formulate a novel model training scheme for the deep neural network to learn good features for classification and/or detection tasks ensuring a consistent generalization performance on OOD test sets. The experimental results qualitatively and quantitatively demonstrate the superior performance of our method using the benchmark CXR image data sets on classification tasks.
* 9 pages, 3 figures
Image quality enhancement of embedded holograms in holographic information hiding using deep neural networks
Dec 20, 2021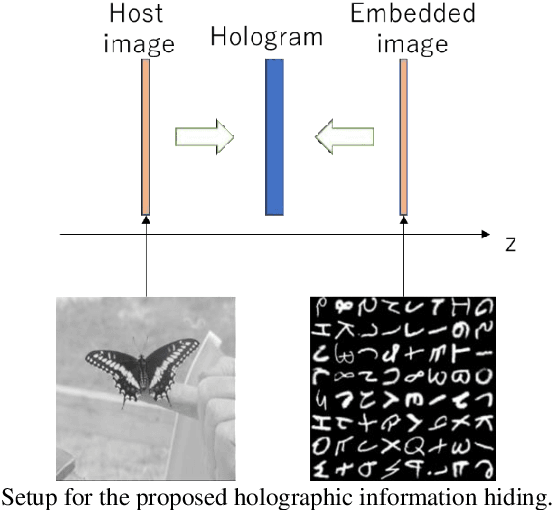

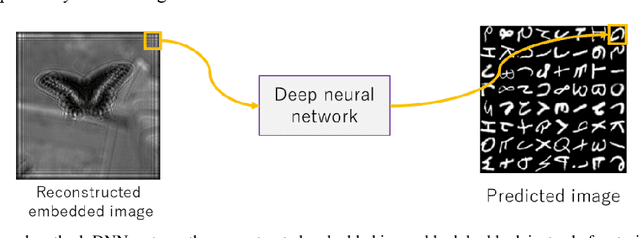
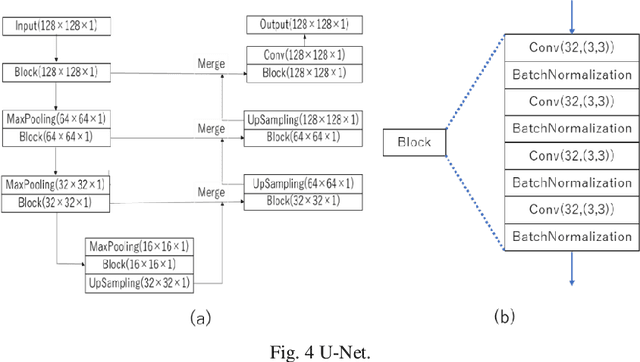
Holographic information hiding is a technique for embedding holograms or images into another hologram, used for copyright protection and steganography of holograms. Using deep neural networks, we offer a way to improve the visual quality of embedded holograms. The brightness of an embedded hologram is set to a fraction of that of the host hologram, resulting in a barely damaged reconstructed image of the host hologram. However, it is difficult to perceive because the embedded hologram's reconstructed image is darker than the reconstructed host image. In this study, we use deep neural networks to restore the darkened image.
MS-HLMO: Multi-scale Histogram of Local Main Orientation for Remote Sensing Image Registration
Apr 01, 2022

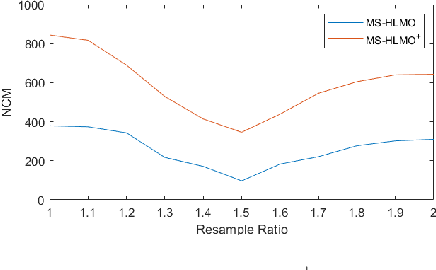

Multi-source image registration is challenging due to intensity, rotation, and scale differences among the images. Considering the characteristics and differences of multi-source remote sensing images, a feature-based registration algorithm named Multi-scale Histogram of Local Main Orientation (MS-HLMO) is proposed. Harris corner detection is first adopted to generate feature points. The HLMO feature of each Harris feature point is extracted on a Partial Main Orientation Map (PMOM) with a Generalized Gradient Location and Orientation Histogram-like (GGLOH) feature descriptor, which provides high intensity, rotation, and scale invariance. The feature points are matched through a multi-scale matching strategy. Comprehensive experiments on 17 multi-source remote sensing scenes demonstrate that the proposed MS-HLMO and its simplified version MS-HLMO$^+$ outperform other competitive registration algorithms in terms of effectiveness and generalization.
Bag of Tricks and A Strong baseline for Image Copy Detection
Dec 04, 2021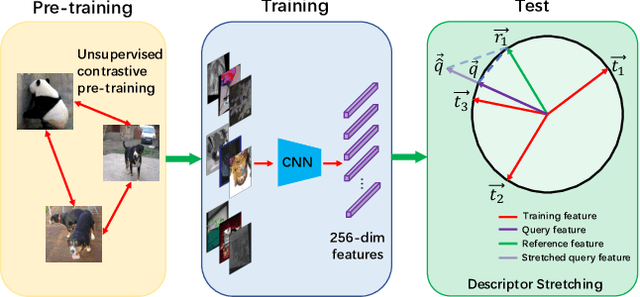
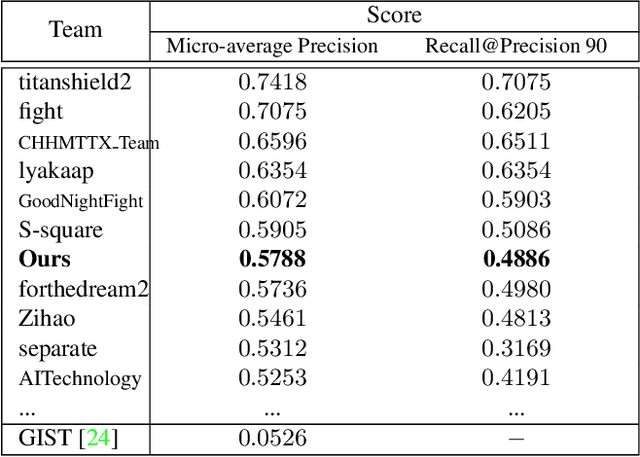
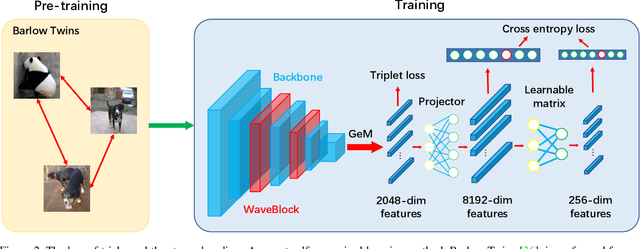
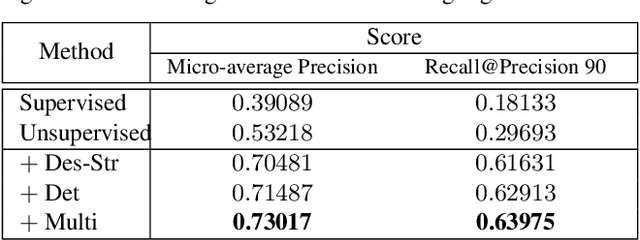
Image copy detection is of great importance in real-life social media. In this paper, a bag of tricks and a strong baseline are proposed for image copy detection. Unsupervised pre-training substitutes the commonly-used supervised one. Beyond that, we design a descriptor stretching strategy to stabilize the scores of different queries. Experiments demonstrate that the proposed method is effective. The proposed baseline ranks third out of 526 participants on the Facebook AI Image Similarity Challenge: Descriptor Track. The code and trained models are available at https://github.com/WangWenhao0716/ISC-Track2-Submission.
Semantic decoupled representation learning for remote sensing image change detection
Jan 15, 2022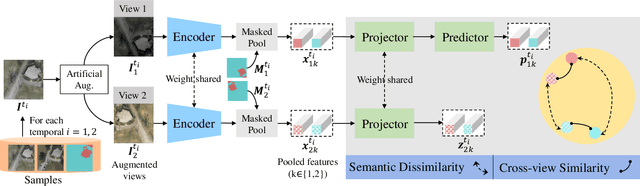
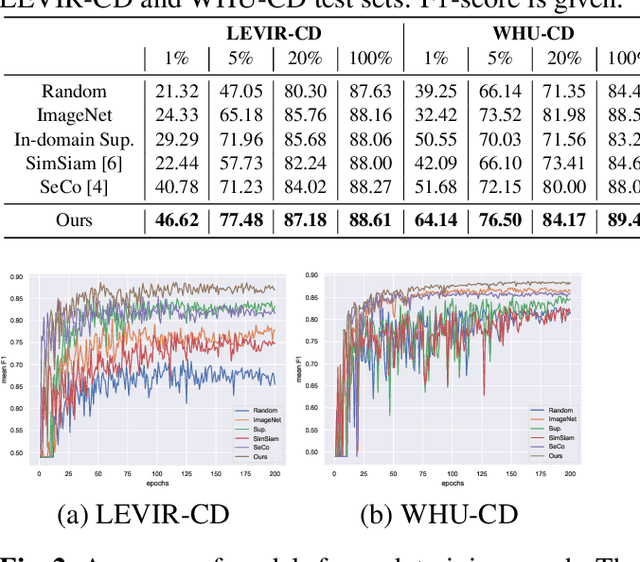
Contemporary transfer learning-based methods to alleviate the data insufficiency in change detection (CD) are mainly based on ImageNet pre-training. Self-supervised learning (SSL) has recently been introduced to remote sensing (RS) for learning in-domain representations. Here, we propose a semantic decoupled representation learning for RS image CD. Typically, the object of interest (e.g., building) is relatively small compared to the vast background. Different from existing methods expressing an image into one representation vector that may be dominated by irrelevant land-covers, we disentangle representations of different semantic regions by leveraging the semantic mask. We additionally force the model to distinguish different semantic representations, which benefits the recognition of objects of interest in the downstream CD task. We construct a dataset of bitemporal images with semantic masks in an effortless manner for pre-training. Experiments on two CD datasets show our model outperforms ImageNet pre-training, in-domain supervised pre-training, and several recent SSL methods.