 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Shape-constrained Symbolic Regression with NSGA-III
Sep 28, 2022
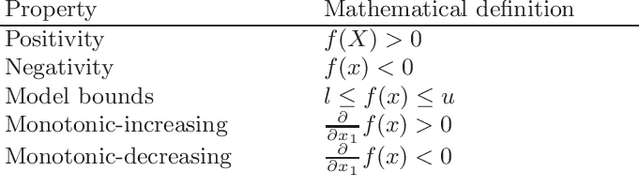


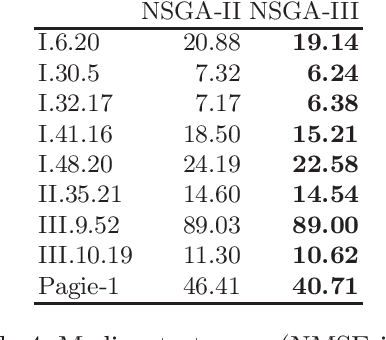
Shape-constrained symbolic regression (SCSR) allows to include prior knowledge into data-based modeling. This inclusion allows to ensure that certain expected behavior is better reflected by the resulting models. The expected behavior is defined via constraints, which refer to the function form e.g. monotonicity, concavity, convexity or the models image boundaries. In addition to the advantage of obtaining more robust and reliable models due to defining constraints over the functions shape, the use of SCSR allows to find models which are more robust to noise and have a better extrapolation behavior. This paper presents a mutlicriterial approach to minimize the approximation error as well as the constraint violations. Explicitly the two algorithms NSGA-II and NSGA-III are implemented and compared against each other in terms of model quality and runtime. Both algorithms are capable of dealing with multiple objectives, whereas NSGA-II is a well established multi-objective approach performing well on instances with up-to 3 objectives. NSGA-III is an extension of the NSGA-II algorithm and was developed to handle problems with "many" objectives (more than 3 objectives). Both algorithms are executed on a selected set of benchmark instances from physics textbooks. The results indicate that both algorithms are able to find largely feasible solutions and NSGA-III provides slight improvements in terms of model quality. Moreover, an improvement in runtime can be observed using the many-objective approach.
Attention based Broadly Self-guided Network for Low light Image Enhancement
Dec 12, 2021
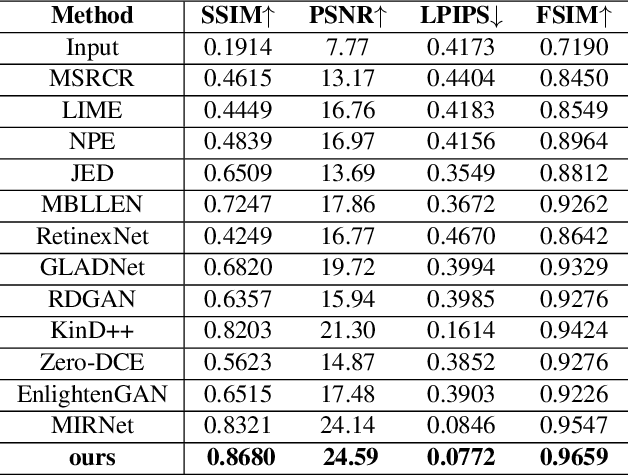
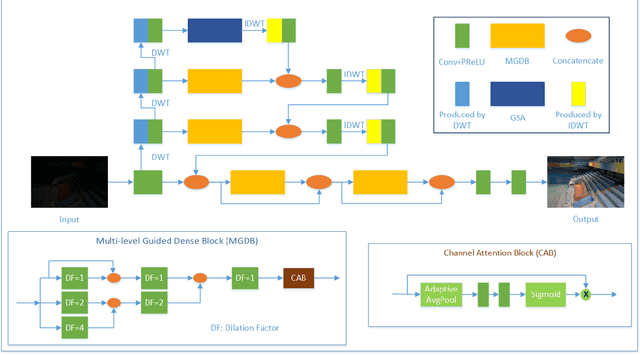
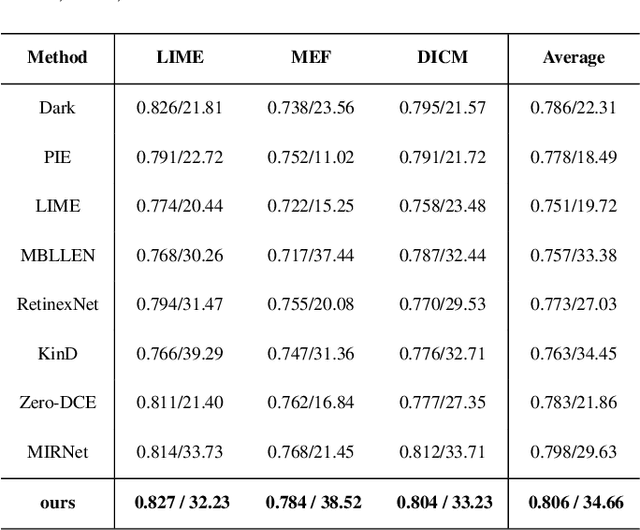
During the past years,deep convolutional neural networks have achieved impressive success in low-light Image Enhancement.Existing deep learning methods mostly enhance the ability of feature extraction by stacking network structures and deepening the depth of the network.which causes more runtime cost on single image.In order to reduce inference time while fully extracting local features and global features.Inspired by SGN,we propose a Attention based Broadly self-guided network (ABSGN) for real world low-light image Enhancement.such a broadly strategy is able to handle the noise at different exposures.The proposed network is validated by many mainstream benchmark.Additional experimental results show that the proposed network outperforms most of state-of-the-art low-light image Enhancement solutions.
Maximizing Self-supervision from Thermal Image for Effective Self-supervised Learning of Depth and Ego-motion
Jan 12, 2022

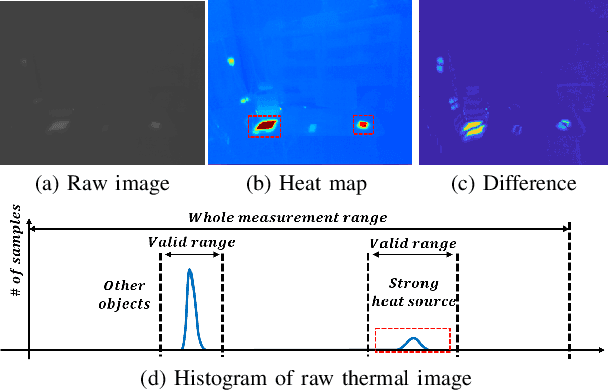
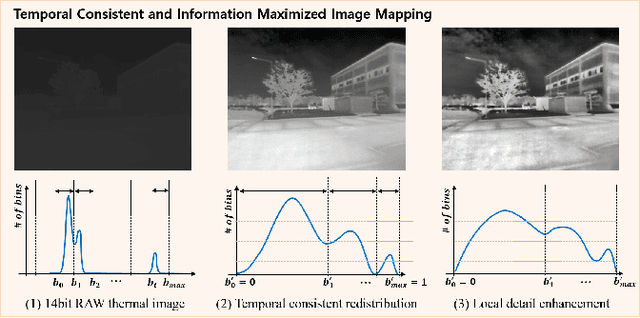
Recently, self-supervised learning of depth and ego-motion from thermal images shows strong robustness and reliability under challenging scenarios. However, the inherent thermal image properties such as weak contrast, blurry edges, and noise hinder to generate effective self-supervision from thermal images. Therefore, most research relies on additional self-supervision sources such as well-lit RGB images, generative models, and Lidar information. In this paper, we conduct an in-depth analysis of thermal image characteristics that degenerates self-supervision from thermal images. Based on the analysis, we propose an effective thermal image mapping method that significantly increases image information, such as overall structure, contrast, and details, while preserving temporal consistency. The proposed method shows outperformed depth and pose results than previous state-of-the-art networks without leveraging additional RGB guidance.
Development and Clinical Evaluation of an AI Support Tool for Improving Telemedicine Photo Quality
Sep 12, 2022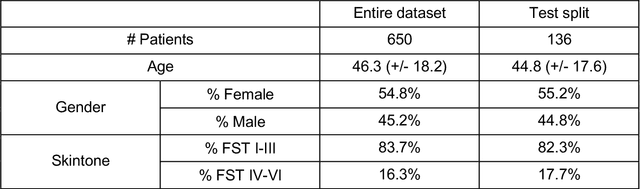
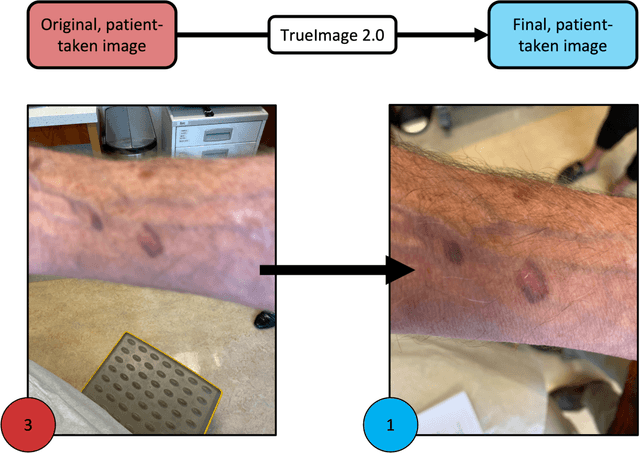

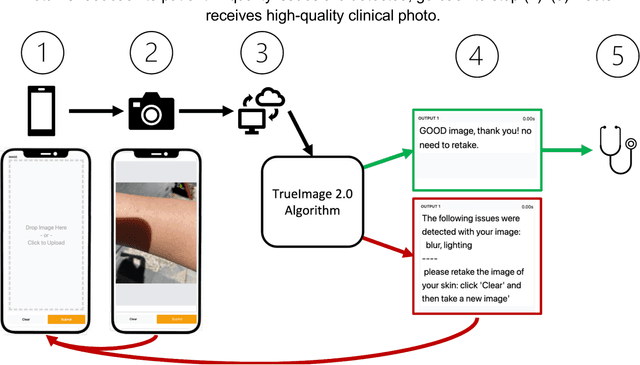
Telemedicine utilization was accelerated during the COVID-19 pandemic, and skin conditions were a common use case. However, the quality of photographs sent by patients remains a major limitation. To address this issue, we developed TrueImage 2.0, an artificial intelligence (AI) model for assessing patient photo quality for telemedicine and providing real-time feedback to patients for photo quality improvement. TrueImage 2.0 was trained on 1700 telemedicine images annotated by clinicians for photo quality. On a retrospective dataset of 357 telemedicine images, TrueImage 2.0 effectively identified poor quality images (Receiver operator curve area under the curve (ROC-AUC) =0.78) and the reason for poor quality (Blurry ROC-AUC=0.84, Lighting issues ROC-AUC=0.70). The performance is consistent across age, gender, and skin tone. Next, we assessed whether patient-TrueImage 2.0 interaction led to an improvement in submitted photo quality through a prospective clinical pilot study with 98 patients. TrueImage 2.0 reduced the number of patients with a poor-quality image by 68.0%.
Counterfactual Explanation of Brain Activity Classifiers using Image-to-Image Transfer by Generative Adversarial Network
Oct 28, 2021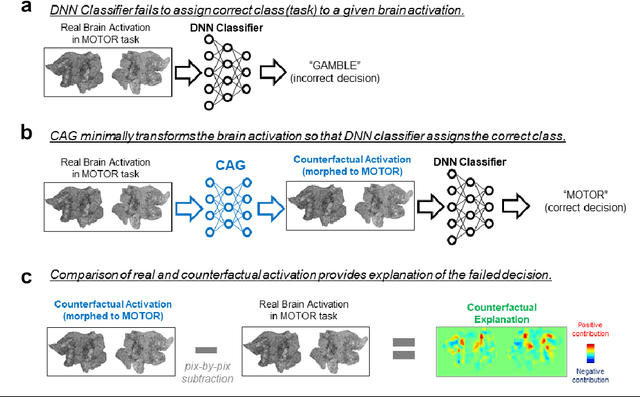
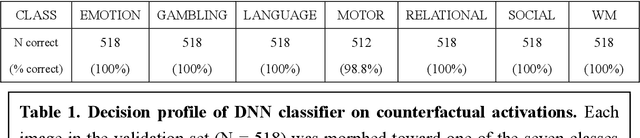
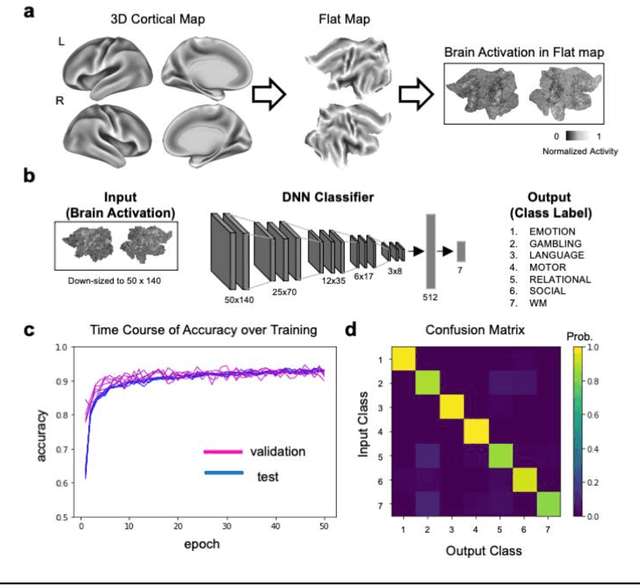

Deep neural networks (DNNs) can accurately decode task-related information from brain activations. However, because of the nonlinearity of the DNN, the decisions made by DNNs are hardly interpretable. One of the promising approaches for explaining such a black-box system is counterfactual explanation. In this framework, the behavior of a black-box system is explained by comparing real data and realistic synthetic data that are specifically generated such that the black-box system outputs an unreal outcome. Here we introduce a novel generative DNN (counterfactual activation generator, CAG) that can provide counterfactual explanations for DNN-based classifiers of brain activations. Importantly, CAG can simultaneously handle image transformation among multiple classes associated with different behavioral tasks. Using CAG, we demonstrated counterfactual explanation of DNN-based classifiers that learned to discriminate brain activations of seven behavioral tasks. Furthermore, by iterative applications of CAG, we were able to enhance and extract subtle spatial brain activity patterns that affected the classifier's decisions. Together, these results demonstrate that the counterfactual explanation based on image-to-image transformation would be a promising approach to understand and extend the current application of DNNs in fMRI analyses.
Hyperspectral Image Super-resolution with Deep Priors and Degradation Model Inversion
Jan 24, 2022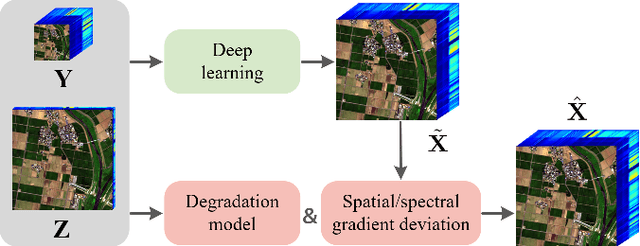
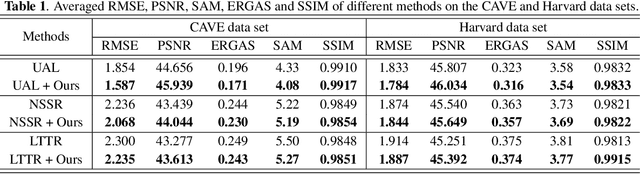
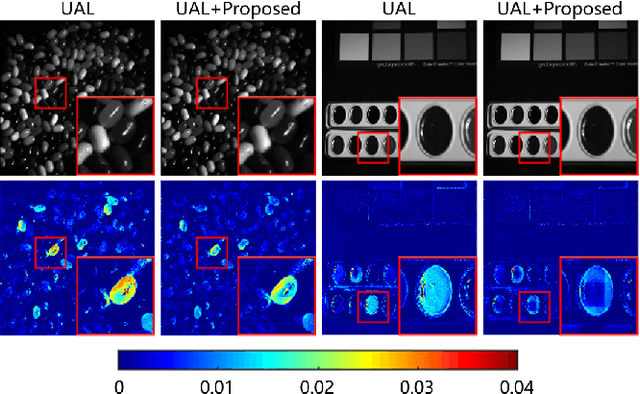
To overcome inherent hardware limitations of hyperspectral imaging systems with respect to their spatial resolution, fusion-based hyperspectral image (HSI) super-resolution is attracting increasing attention. This technique aims to fuse a low-resolution (LR) HSI and a conventional high-resolution (HR) RGB image in order to obtain an HR HSI. Recently, deep learning architectures have been used to address the HSI super-resolution problem and have achieved remarkable performance. However, they ignore the degradation model even though this model has a clear physical interpretation and may contribute to improve the performance. We address this problem by proposing a method that, on the one hand, makes use of the linear degradation model in the data-fidelity term of the objective function and, on the other hand, utilizes the output of a convolutional neural network for designing a deep prior regularizer in spectral and spatial gradient domains. Experiments show the performance improvement achieved with this strategy.
Disentangled Unsupervised Image Translation via Restricted Information Flow
Nov 26, 2021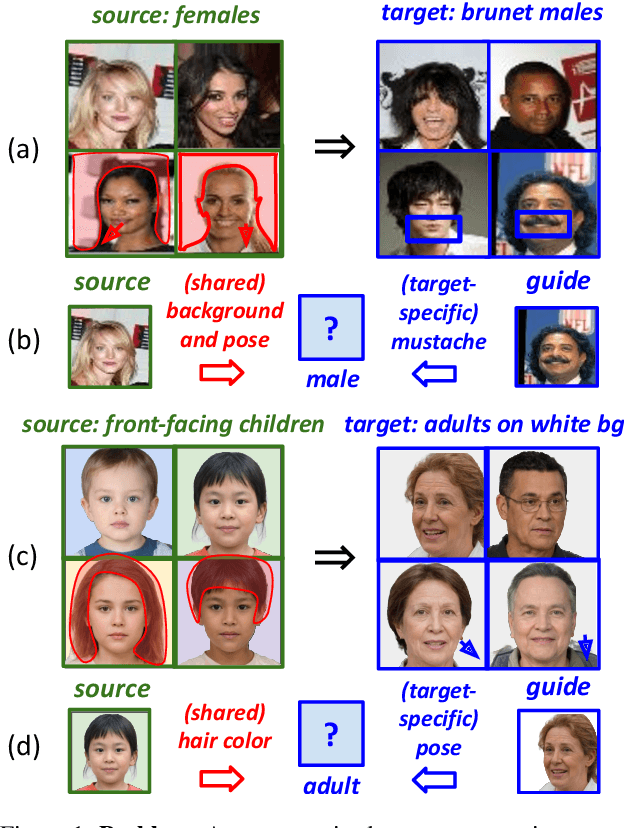
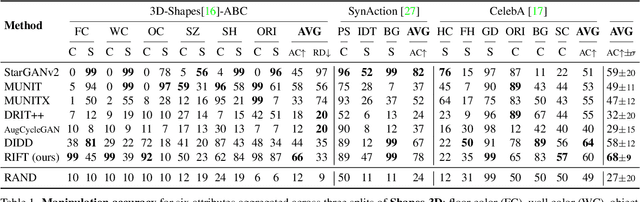
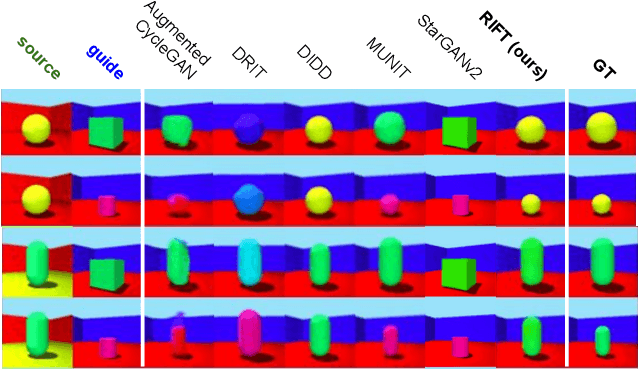
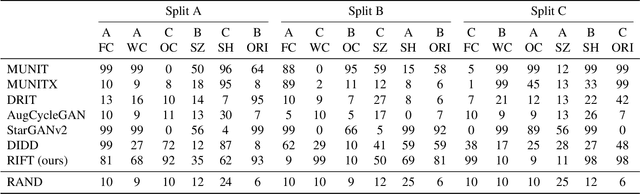
Unsupervised image-to-image translation methods aim to map images from one domain into plausible examples from another domain while preserving structures shared across two domains. In the many-to-many setting, an additional guidance example from the target domain is used to determine domain-specific attributes of the generated image. In the absence of attribute annotations, methods have to infer which factors are specific to each domain from data during training. Many state-of-art methods hard-code the desired shared-vs-specific split into their architecture, severely restricting the scope of the problem. In this paper, we propose a new method that does not rely on such inductive architectural biases, and infers which attributes are domain-specific from data by constraining information flow through the network using translation honesty losses and a penalty on the capacity of domain-specific embedding. We show that the proposed method achieves consistently high manipulation accuracy across two synthetic and one natural dataset spanning a wide variety of domain-specific and shared attributes.
Robust Category-Level 6D Pose Estimation with Coarse-to-Fine Rendering of Neural Features
Sep 12, 2022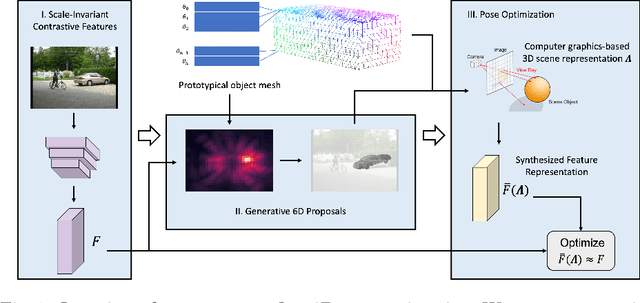
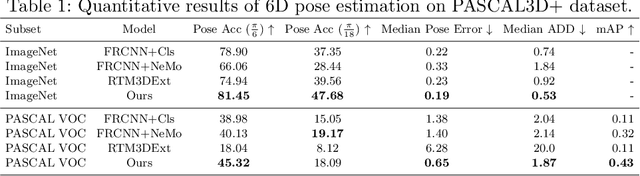


We consider the problem of category-level 6D pose estimation from a single RGB image. Our approach represents an object category as a cuboid mesh and learns a generative model of the neural feature activations at each mesh vertex to perform pose estimation through differentiable rendering. A common problem of rendering-based approaches is that they rely on bounding box proposals, which do not convey information about the 3D rotation of the object and are not reliable when objects are partially occluded. Instead, we introduce a coarse-to-fine optimization strategy that utilizes the rendering process to estimate a sparse set of 6D object proposals, which are subsequently refined with gradient-based optimization. The key to enabling the convergence of our approach is a neural feature representation that is trained to be scale- and rotation-invariant using contrastive learning. Our experiments demonstrate an enhanced category-level 6D pose estimation performance compared to prior work, particularly under strong partial occlusion.
Adaptive Sparse ViT: Towards Learnable Adaptive Token Pruning by Fully Exploiting Self-Attention
Sep 28, 2022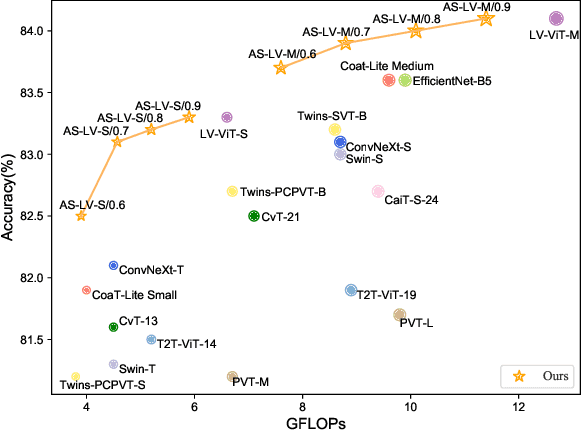
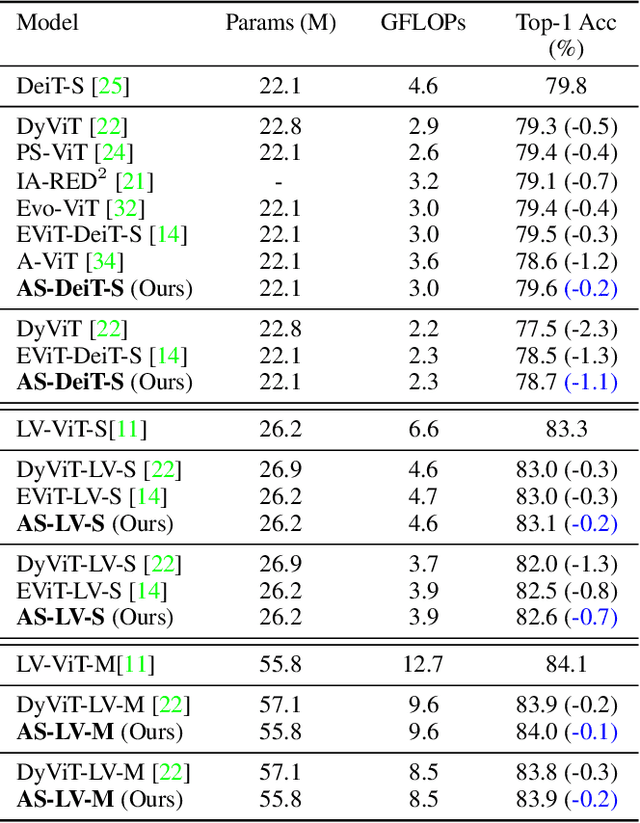

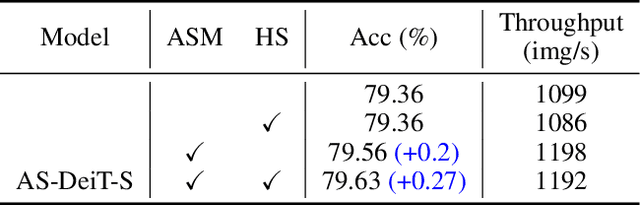
Vision transformer has emerged as a new paradigm in computer vision, showing excellent performance while accompanied by expensive computational cost. Image token pruning is one of the main approaches for ViT compression, due to the facts that the complexity is quadratic with respect to the token number, and many tokens containing only background regions do not truly contribute to the final prediction. Existing works either rely on additional modules to score the importance of individual tokens, or implement a fixed ratio pruning strategy for different input instances. In this work, we propose an adaptive sparse token pruning framework with a minimal cost. Our approach is based on learnable thresholds and leverages the Multi-Head Self-Attention to evaluate token informativeness with little additional operations. Specifically, we firstly propose an inexpensive attention head importance weighted class attention scoring mechanism. Then, learnable parameters are inserted in ViT as thresholds to distinguish informative tokens from unimportant ones. By comparing token attention scores and thresholds, we can discard useless tokens hierarchically and thus accelerate inference. The learnable thresholds are optimized in budget-aware training to balance accuracy and complexity, performing the corresponding pruning configurations for different input instances. Extensive experiments demonstrate the effectiveness of our approach. For example, our method improves the throughput of DeiT-S by 50% and brings only 0.2% drop in top-1 accuracy, which achieves a better trade-off between accuracy and latency than the previous methods.
COPE: End-to-end trainable Constant Runtime Object Pose Estimation
Aug 22, 2022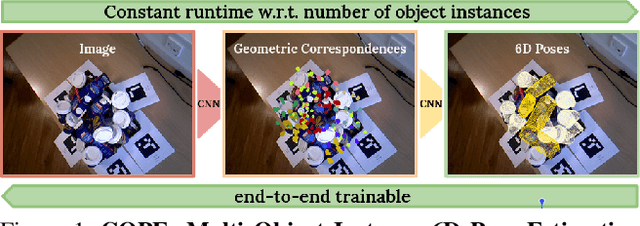
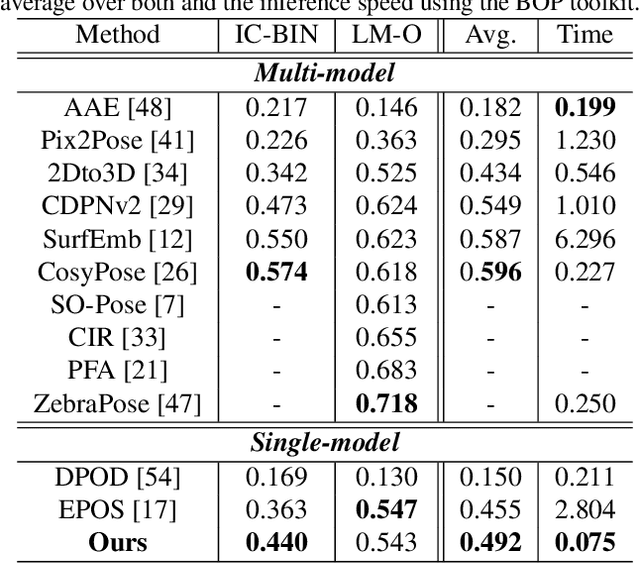
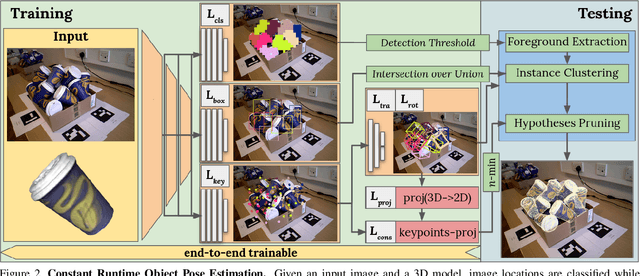
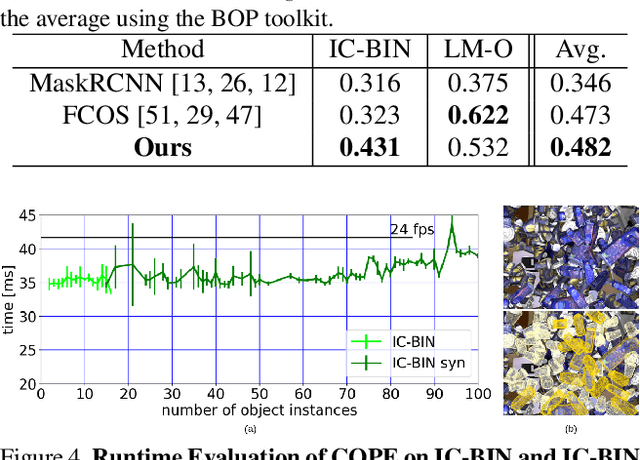
State-of-the-art object pose estimation handles multiple instances in a test image by using multi-model formulations: detection as a first stage and then separately trained networks per object for 2D-3D geometric correspondence prediction as a second stage. Poses are subsequently estimated using the Perspective-n-Points algorithm at runtime. Unfortunately, multi-model formulations are slow and do not scale well with the number of object instances involved. Recent approaches show that direct 6D object pose estimation is feasible when derived from the aforementioned geometric correspondences. We present an approach that learns an intermediate geometric representation of multiple objects to directly regress 6D poses of all instances in a test image. The inherent end-to-end trainability overcomes the requirement of separately processing individual object instances. By calculating the mutual Intersection-over-Unions, pose hypotheses are clustered into distinct instances, which achieves negligible runtime overhead with respect to the number of object instances. Results on multiple challenging standard datasets show that the pose estimation performance is superior to single-model state-of-the-art approaches despite being more than ~35 times faster. We additionally provide an analysis showing real-time applicability (>24 fps) for images where more than 90 object instances are present. Further results show the advantage of supervising geometric-correspondence-based object pose estimation with the 6D pose.