 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Fine-tuning or top-tuning? Transfer learning with pretrained features and fast kernel methods
Sep 16, 2022
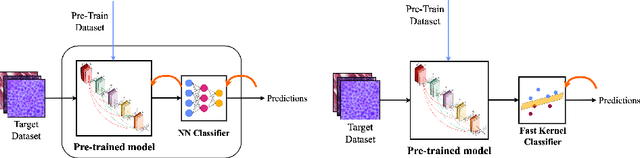
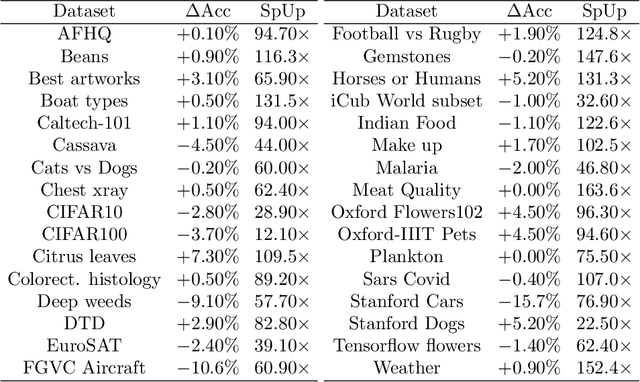
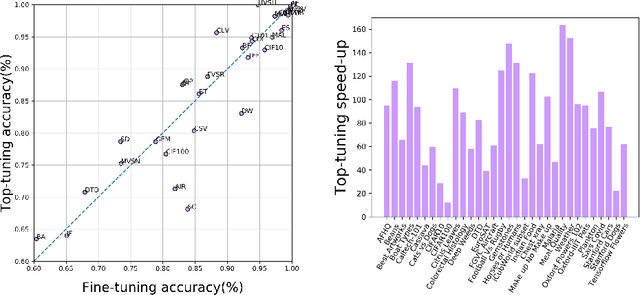
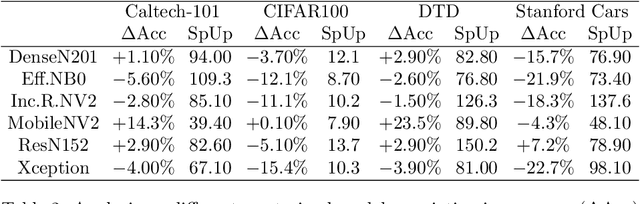
The impressive performances of deep learning architectures is associated to massive increase of models complexity. Millions of parameters need be tuned, with training and inference time scaling accordingly. But is massive fine-tuning necessary? In this paper, focusing on image classification, we consider a simple transfer learning approach exploiting pretrained convolutional features as input for a fast kernel method. We refer to this approach as top-tuning, since only the kernel classifier is trained. By performing more than 2500 training processes we show that this top-tuning approach provides comparable accuracy w.r.t. fine-tuning, with a training time that is between one and two orders of magnitude smaller. These results suggest that top-tuning provides a useful alternative to fine-tuning in small/medium datasets, especially when training efficiency is crucial.
Optimal Transport-based Graph Matching for 3D retinal OCT image registration
Feb 28, 2022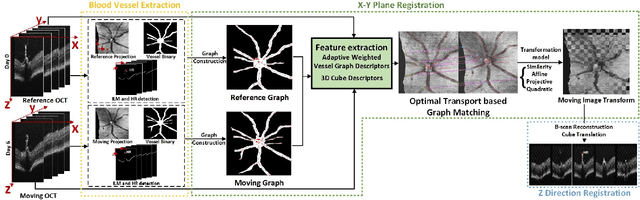
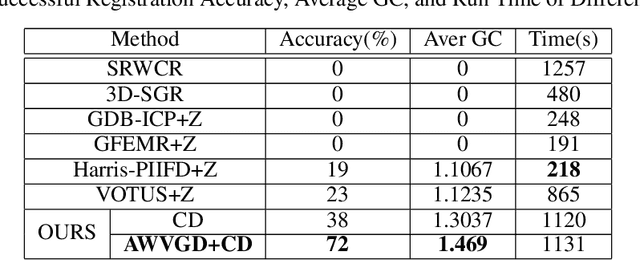

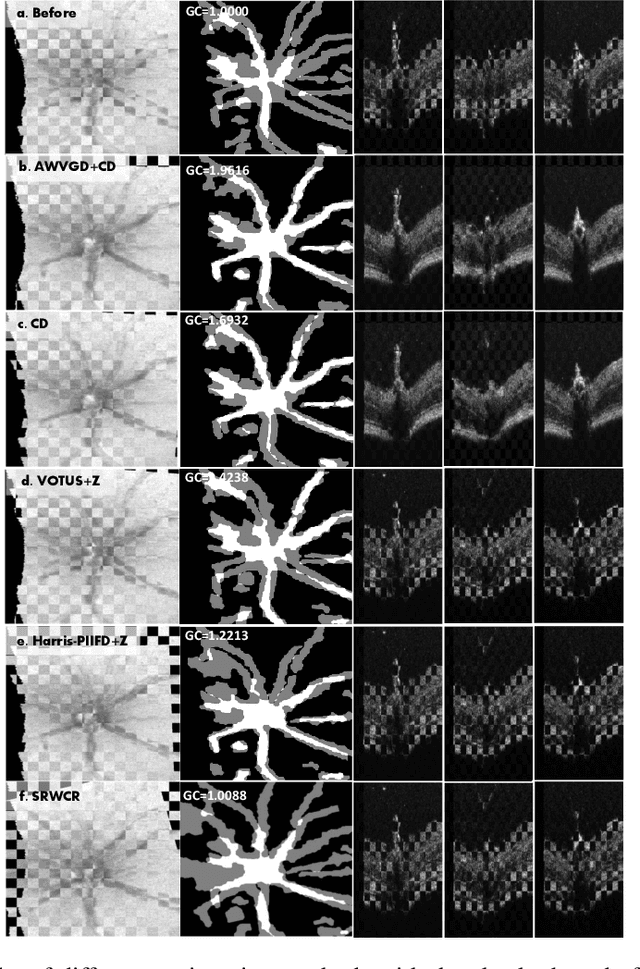
Registration of longitudinal optical coherence tomography (OCT) images assists disease monitoring and is essential in image fusion applications. Mouse retinal OCT images are often collected for longitudinal study of eye disease models such as uveitis, but their quality is often poor compared with human imaging. This paper presents a novel but efficient framework involving an optimal transport based graph matching (OT-GM) method for 3D mouse OCT image registration. We first perform registration of fundus-like images obtained by projecting all b-scans of a volume on a plane orthogonal to them, hereafter referred to as the x-y plane. We introduce Adaptive Weighted Vessel Graph Descriptors (AWVGD) and 3D Cube Descriptors (CD) to identify the correspondence between nodes of graphs extracted from segmented vessels within the OCT projection images. The AWVGD comprises scaling, translation and rotation, which are computationally efficient, whereas CD exploits 3D spatial and frequency domain information. The OT-GM method subsequently performs the correct alignment in the x-y plane. Finally, registration along the direction orthogonal to the x-y plane (the z-direction) is guided by the segmentation of two important anatomical features peculiar to mouse b-scans, the Internal Limiting Membrane (ILM) and the hyaloid remnant (HR). Both subjective and objective evaluation results demonstrate that our framework outperforms other well-established methods on mouse OCT images within a reasonable execution time.
Single MR Image Super-Resolution using Generative Adversarial Network
Jul 16, 2022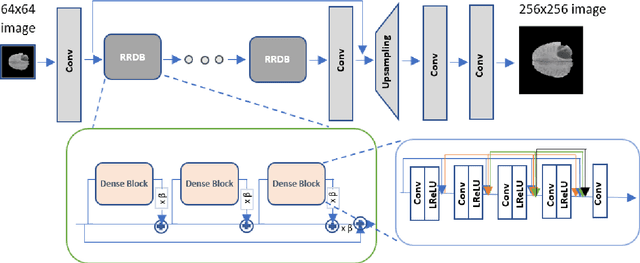
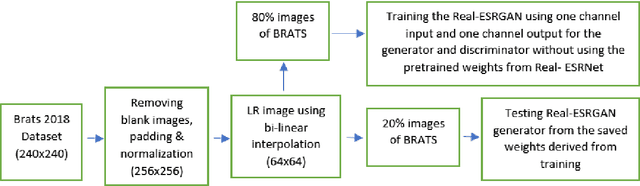

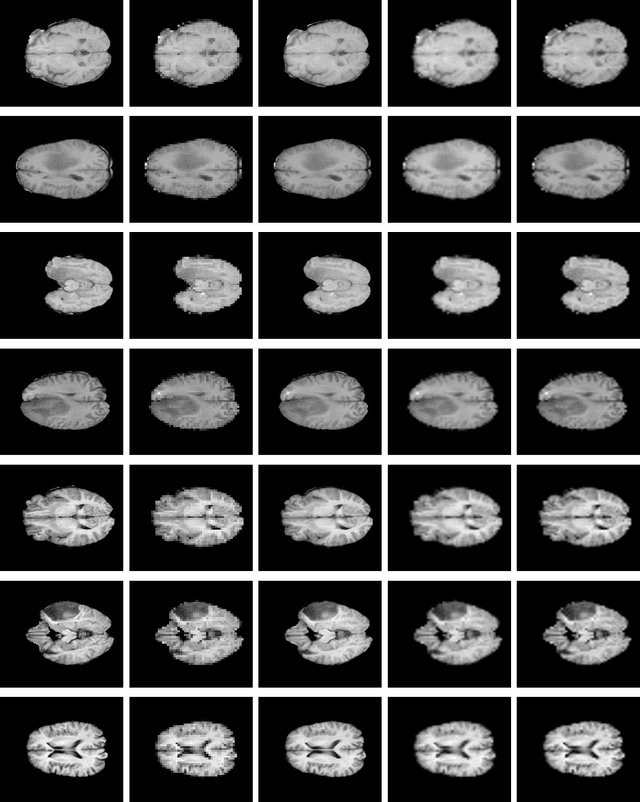
Spatial resolution of medical images can be improved using super-resolution methods. Real Enhanced Super Resolution Generative Adversarial Network (Real-ESRGAN) is one of the recent effective approaches utilized to produce higher resolution images, given input images of lower resolution. In this paper, we apply this method to enhance the spatial resolution of 2D MR images. In our proposed approach, we slightly modify the structure of the Real-ESRGAN to train 2D Magnetic Resonance images (MRI) taken from the Brain Tumor Segmentation Challenge (BraTS) 2018 dataset. The obtained results are validated qualitatively and quantitatively by computing SSIM (Structural Similarity Index Measure), NRMSE (Normalized Root Mean Square Error), MAE (Mean Absolute Error), and VIF (Visual Information Fidelity) values.
Model-Based Single Image Deep Dehazing
Nov 22, 2021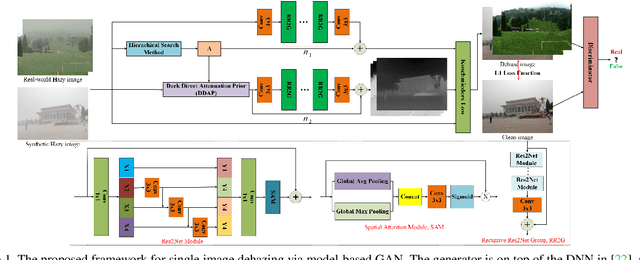


Model-based single image dehazing algorithms restore images with sharp edges and rich details at the expense of low PSNR values. Data-driven ones restore images with high PSNR values but with low contrast, and even some remaining haze. In this paper, a novel single image dehazing algorithm is introduced by fusing model-based and data-driven approaches. Both transmission map and atmospheric light are initialized by the model-based methods, and refined by deep learning approaches which form a neural augmentation. Haze-free images are restored by using the transmission map and atmospheric light. Experimental results indicate that the proposed algorithm can remove haze well from real-world and synthetic hazy images.
Spikformer: When Spiking Neural Network Meets Transformer
Sep 29, 2022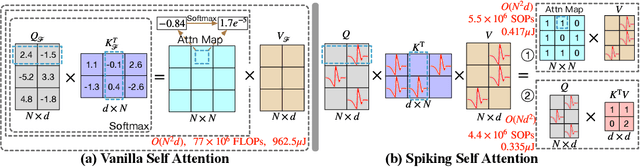
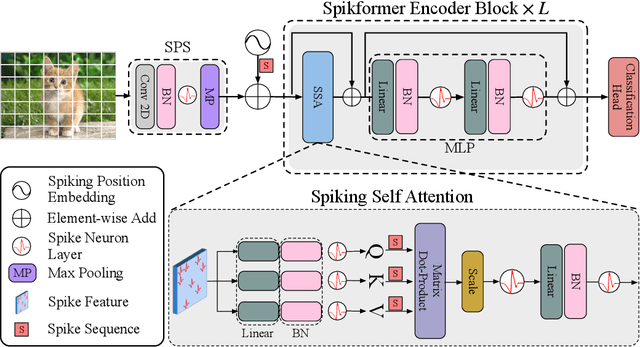
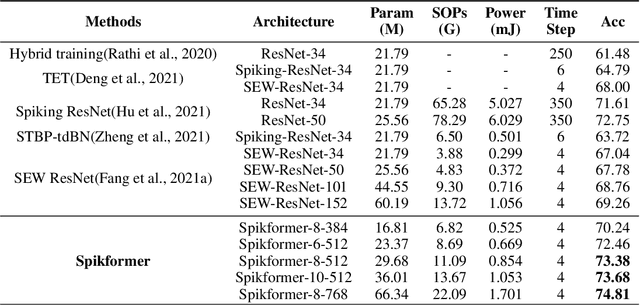
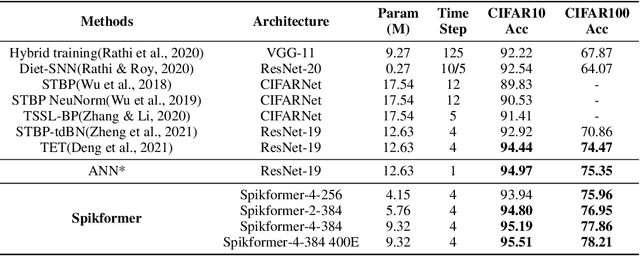
We consider two biologically plausible structures, the Spiking Neural Network (SNN) and the self-attention mechanism. The former offers an energy-efficient and event-driven paradigm for deep learning, while the latter has the ability to capture feature dependencies, enabling Transformer to achieve good performance. It is intuitively promising to explore the marriage between them. In this paper, we consider leveraging both self-attention capability and biological properties of SNNs, and propose a novel Spiking Self Attention (SSA) as well as a powerful framework, named Spiking Transformer (Spikformer). The SSA mechanism in Spikformer models the sparse visual feature by using spike-form Query, Key, and Value without softmax. Since its computation is sparse and avoids multiplication, SSA is efficient and has low computational energy consumption. It is shown that Spikformer with SSA can outperform the state-of-the-art SNNs-like frameworks in image classification on both neuromorphic and static datasets. Spikformer (66.3M parameters) with comparable size to SEW-ResNet-152 (60.2M,69.26%) can achieve 74.81% top1 accuracy on ImageNet using 4 time steps, which is the state-of-the-art in directly trained SNNs models.
FD-MAR: Fourier Dual-domain Network for CT Metal Artifact Reduction
Jul 24, 2022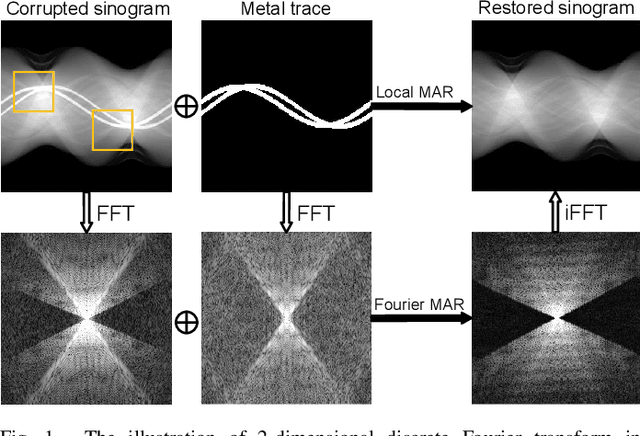
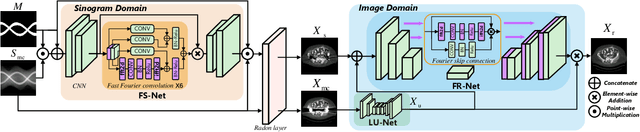
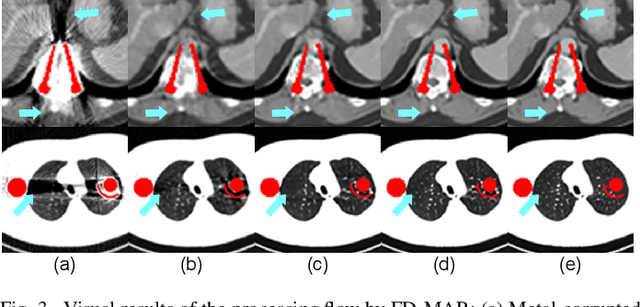
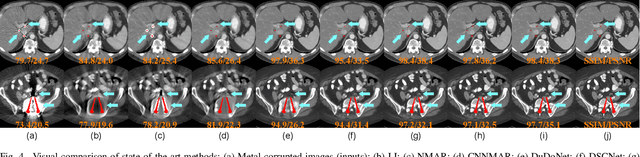
The presence of high-density objects such as metal implants and dental fillings can introduce severely streak-like artifacts in computed tomography (CT) images, greatly limiting subsequent diagnosis. Although various deep neural networks-based methods have been proposed for metal artifact reduction (MAR), they usually suffer from poor performance due to limited exploitation of global context in the sinogram domain, secondary artifacts introduced in the image domain, and the requirement of precise metal masks. To address these issues, this paper explores fast Fourier convolution for MAR in both sinogram and image domains, and proposes a Fourier dual-domain network for MAR, termed FD-MAR. Specifically, we first propose a Fourier sinogram restoration network, which can leverage sinogram-wide receptive context to fill in the metal-corrupted region from uncorrupted region and, hence, is robust to the metal trace. Second, we propose a Fourier refinement network in the image domain, which can refine the reconstructed images in a local-to-global manner by exploring image-wide context information. As a result, the proposed FD-MAR can explore the sinogram- and image-wide receptive fields for MAR. By optimizing FD-MAR with a composite loss function, extensive experimental results demonstrate the superiority of the proposed FD-MAR over the state-of-the-art MAR methods in terms of quantitative metrics and visual comparison. Notably, FD-MAR does not require precise metal masks, which is of great importance in clinical routine.
Deep Multimodal Guidance for Medical Image Classification
Mar 10, 2022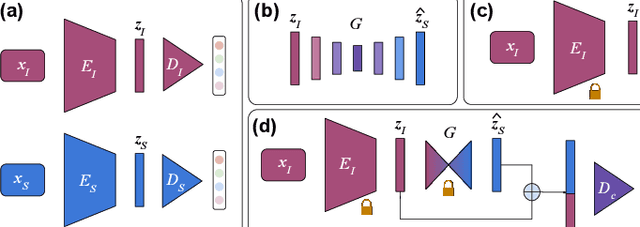
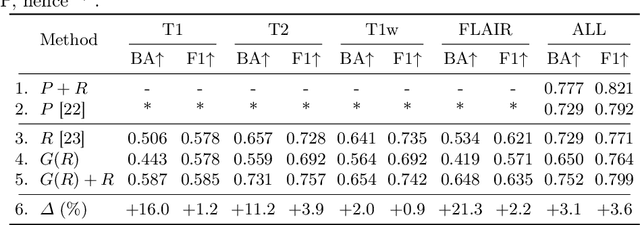
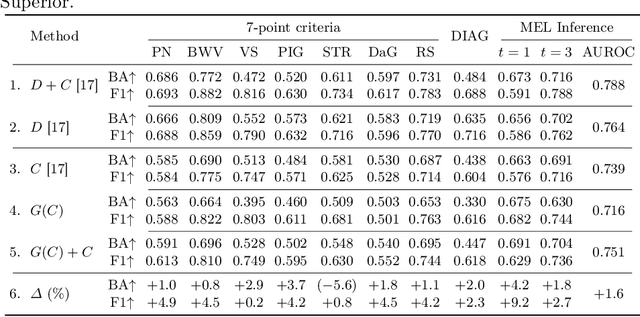
Medical imaging is a cornerstone of therapy and diagnosis in modern medicine. However, the choice of imaging modality for a particular theranostic task typically involves trade-offs between the feasibility of using a particular modality (e.g., short wait times, low cost, fast acquisition, reduced radiation/invasiveness) and the expected performance on a clinical task (e.g., diagnostic accuracy, efficacy of treatment planning and guidance). In this work, we aim to apply the knowledge learned from the less feasible but better-performing (superior) modality to guide the utilization of the more-feasible yet under-performing (inferior) modality and steer it towards improved performance. We focus on the application of deep learning for image-based diagnosis. We develop a light-weight guidance model that leverages the latent representation learned from the superior modality, when training a model that consumes only the inferior modality. We examine the advantages of our method in the context of two clinical applications: multi-task skin lesion classification from clinical and dermoscopic images and brain tumor classification from multi-sequence magnetic resonance imaging (MRI) and histopathology images. For both these scenarios we show a boost in diagnostic performance of the inferior modality without requiring the superior modality. Furthermore, in the case of brain tumor classification, our method outperforms the model trained on the superior modality while producing comparable results to the model that uses both modalities during inference.
Rapid dynamic speech imaging at 3 Tesla using combination of a custom vocal tract coil, variable density spirals and manifold regularization
Sep 06, 2022
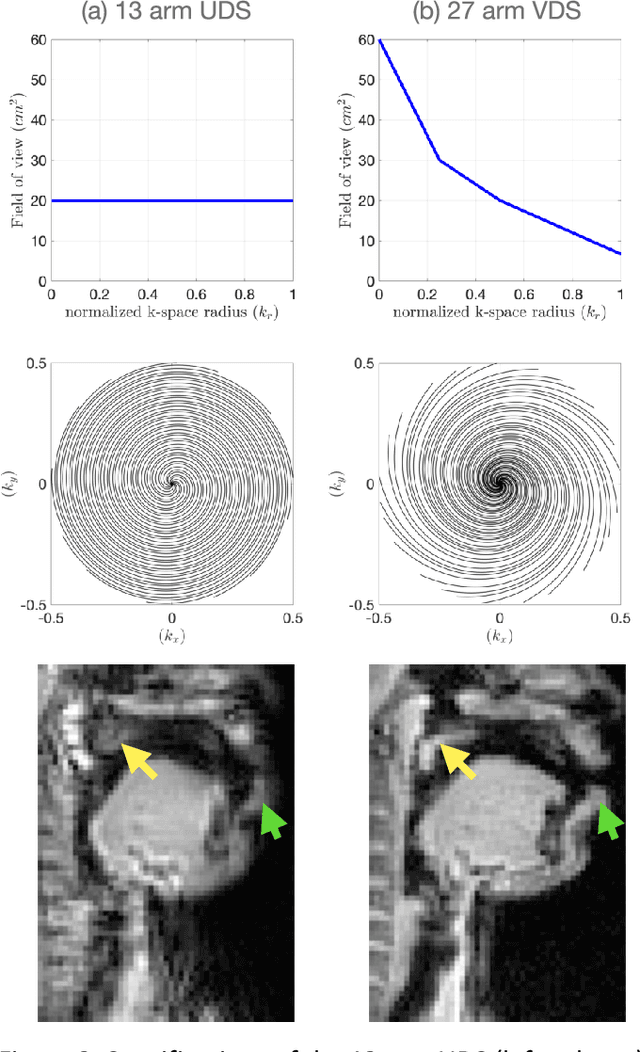
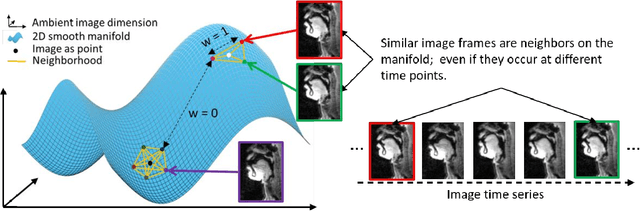
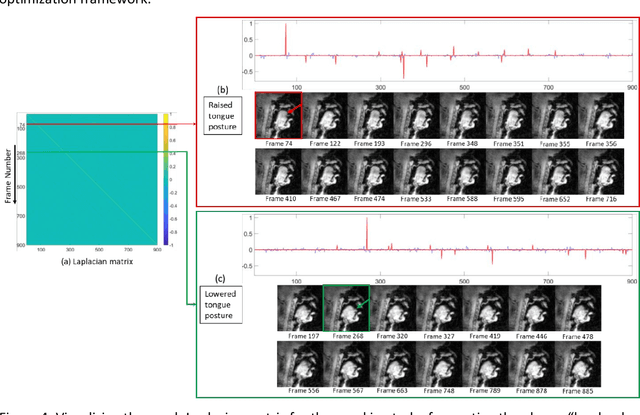
Purpose: To improve dynamic speech imaging at 3 Tesla. Methods: A novel scheme combining a 16-channel vocal tract coil, variable density spirals (VDS), and manifold regularization was developed. Short readout duration spirals (1.3 ms long) were used to minimize sensitivity to off-resonance. The manifold model leveraged similarities between frames sharing similar vocal tract postures without explicit motion binning. Reconstruction was posed as a SENSE-based non-local soft weighted temporal regularization scheme. The self-navigating capability of VDS was leveraged to learn the structure of the manifold. Our approach was compared against low-rank and finite difference reconstruction constraints on two volunteers performing repetitive and arbitrary speaking tasks. Blinded image quality evaluation in the categories of alias artifacts, spatial blurring, and temporal blurring were performed by three experts in voice research. Results: We achieved a spatial resolution of 2.4mm2/pixel and a temporal resolution of 17.4 ms/frame for single slice imaging, and 52.2 ms/frame for concurrent 3-slice imaging. Implicit motion binning of the manifold scheme for both repetitive and fluent speaking tasks was demonstrated. The manifold scheme provided superior fidelity in modeling articulatory motion compared to low rank and temporal finite difference schemes. This was reflected by higher image quality scores in spatial and temporal blurring categories. Our technique exhibited faint alias artifacts, but offered a reduced interquartile range of scores compared to other methods in alias artifact category. Conclusion: Synergistic combination of a custom vocal-tract coil, variable density spirals and manifold regularization enables robust dynamic speech imaging at 3 Tesla.
Mitigating Channel-wise Noise for Single Image Super Resolution
Dec 14, 2021



In practice, images can contain different amounts of noise for different color channels, which is not acknowledged by existing super-resolution approaches. In this paper, we propose to super-resolve noisy color images by considering the color channels jointly. Noise statistics are blindly estimated from the input low-resolution image and are used to assign different weights to different color channels in the data cost. Implicit low-rank structure of visual data is enforced via nuclear norm minimization in association with adaptive weights, which is added as a regularization term to the cost. Additionally, multi-scale details of the image are added to the model through another regularization term that involves projection onto PCA basis, which is constructed using similar patches extracted across different scales of the input image. The results demonstrate the super-resolving capability of the approach in real scenarios.
Decoupled-and-Coupled Networks: Self-Supervised Hyperspectral Image Super-Resolution with Subpixel Fusion
May 07, 2022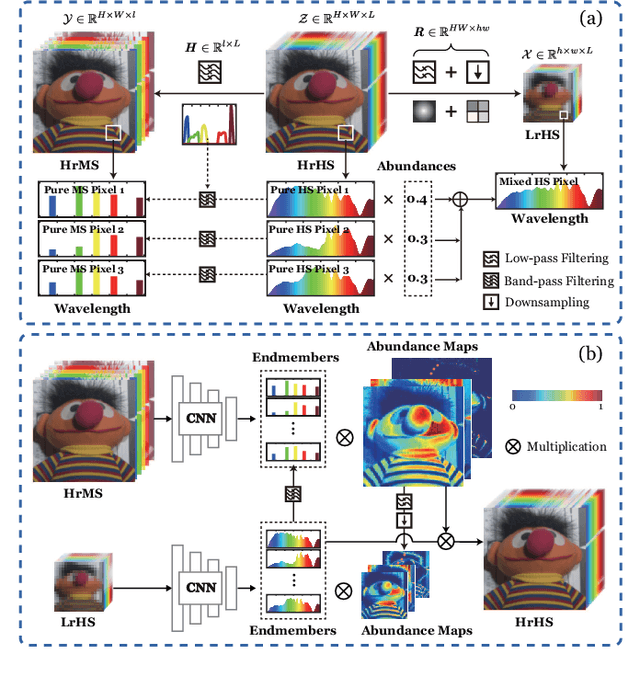
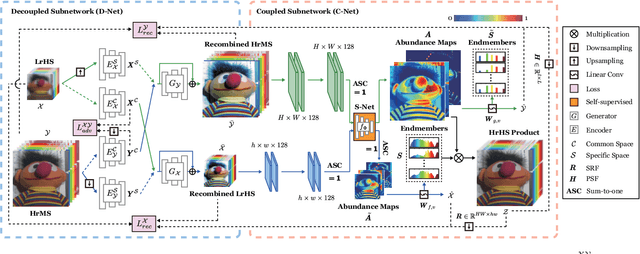
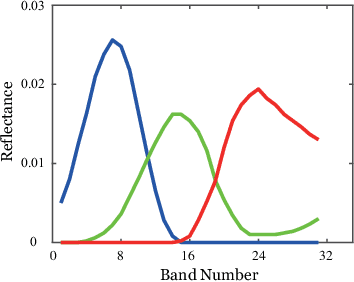
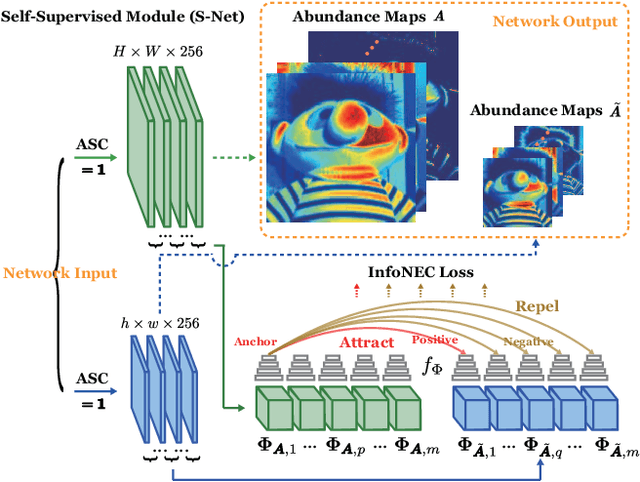
Enormous efforts have been recently made to super-resolve hyperspectral (HS) images with the aid of high spatial resolution multispectral (MS) images. Most prior works usually perform the fusion task by means of multifarious pixel-level priors. Yet the intrinsic effects of a large distribution gap between HS-MS data due to differences in the spatial and spectral resolution are less investigated. The gap might be caused by unknown sensor-specific properties or highly-mixed spectral information within one pixel (due to low spatial resolution). To this end, we propose a subpixel-level HS super-resolution framework by devising a novel decoupled-and-coupled network, called DC-Net, to progressively fuse HS-MS information from the pixel- to subpixel-level, from the image- to feature-level. As the name suggests, DC-Net first decouples the input into common (or cross-sensor) and sensor-specific components to eliminate the gap between HS-MS images before further fusion, and then fully blends them by a model-guided coupled spectral unmixing (CSU) net. More significantly, we append a self-supervised learning module behind the CSU net by guaranteeing the material consistency to enhance the detailed appearances of the restored HS product. Extensive experimental results show the superiority of our method both visually and quantitatively and achieve a significant improvement in comparison with the state-of-the-arts. Furthermore, the codes and datasets will be available at https://sites.google.com/view/danfeng-hong for the sake of reproducibility.