 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Model Zoos: A Dataset of Diverse Populations of Neural Network Models
Sep 29, 2022
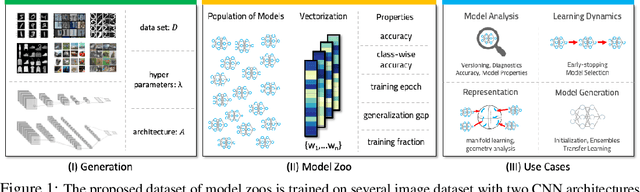
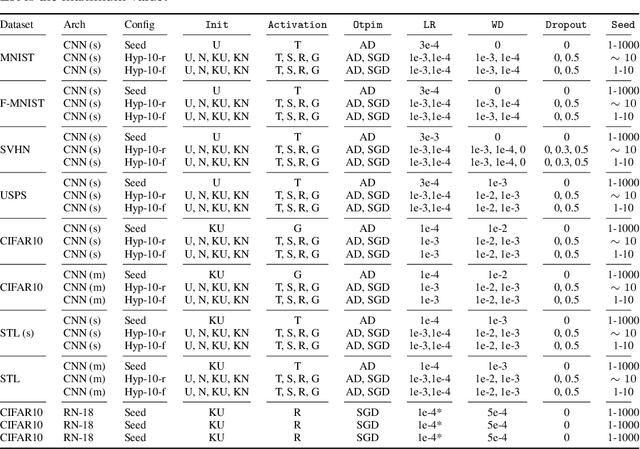
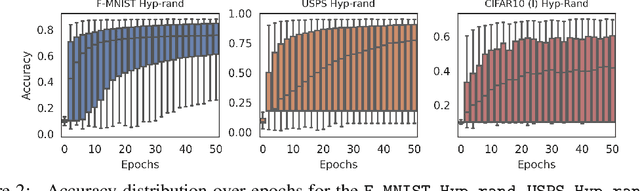
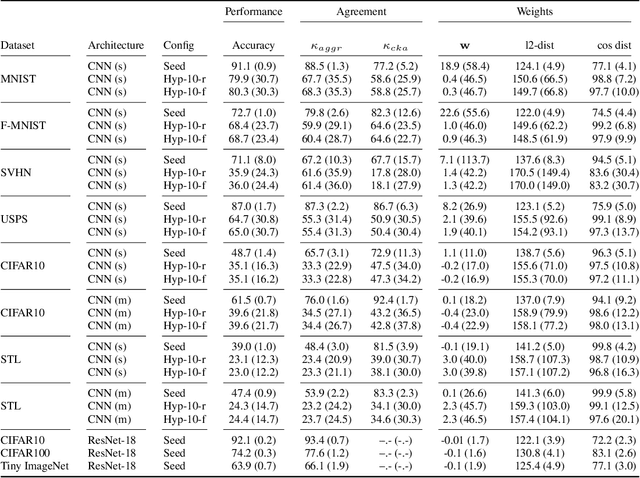
In the last years, neural networks (NN) have evolved from laboratory environments to the state-of-the-art for many real-world problems. It was shown that NN models (i.e., their weights and biases) evolve on unique trajectories in weight space during training. Following, a population of such neural network models (referred to as model zoo) would form structures in weight space. We think that the geometry, curvature and smoothness of these structures contain information about the state of training and can reveal latent properties of individual models. With such model zoos, one could investigate novel approaches for (i) model analysis, (ii) discover unknown learning dynamics, (iii) learn rich representations of such populations, or (iv) exploit the model zoos for generative modelling of NN weights and biases. Unfortunately, the lack of standardized model zoos and available benchmarks significantly increases the friction for further research about populations of NNs. With this work, we publish a novel dataset of model zoos containing systematically generated and diverse populations of NN models for further research. In total the proposed model zoo dataset is based on eight image datasets, consists of 27 model zoos trained with varying hyperparameter combinations and includes 50'360 unique NN models as well as their sparsified twins, resulting in over 3'844'360 collected model states. Additionally, to the model zoo data we provide an in-depth analysis of the zoos and provide benchmarks for multiple downstream tasks. The dataset can be found at www.modelzoos.cc.
Projected Gradient Descent Algorithms for Solving Nonlinear Inverse Problems with Generative Priors
Sep 21, 2022

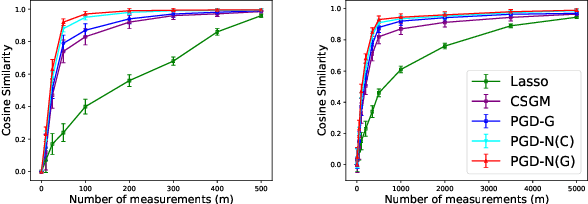

In this paper, we propose projected gradient descent (PGD) algorithms for signal estimation from noisy nonlinear measurements. We assume that the unknown $p$-dimensional signal lies near the range of an $L$-Lipschitz continuous generative model with bounded $k$-dimensional inputs. In particular, we consider two cases when the nonlinear link function is either unknown or known. For unknown nonlinearity, similarly to \cite{liu2020generalized}, we make the assumption of sub-Gaussian observations and propose a linear least-squares estimator. We show that when there is no representation error and the sensing vectors are Gaussian, roughly $O(k \log L)$ samples suffice to ensure that a PGD algorithm converges linearly to a point achieving the optimal statistical rate using arbitrary initialization. For known nonlinearity, we assume monotonicity as in \cite{yang2016sparse}, and make much weaker assumptions on the sensing vectors and allow for representation error. We propose a nonlinear least-squares estimator that is guaranteed to enjoy an optimal statistical rate. A corresponding PGD algorithm is provided and is shown to also converge linearly to the estimator using arbitrary initialization. In addition, we present experimental results on image datasets to demonstrate the performance of our PGD algorithms.
Attention based Broadly Self-guided Network for Low light Image Enhancement
Dec 15, 2021
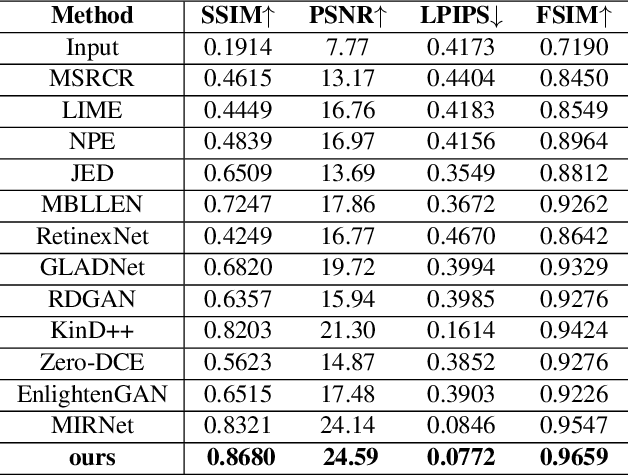
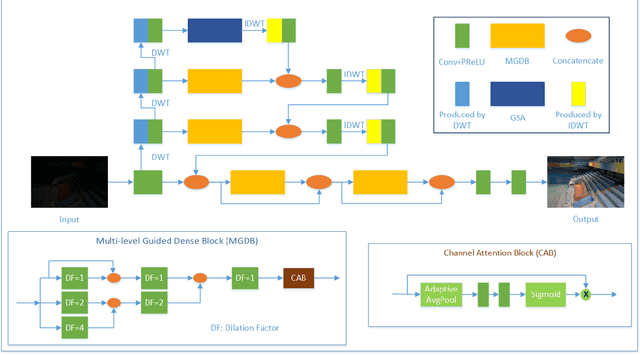
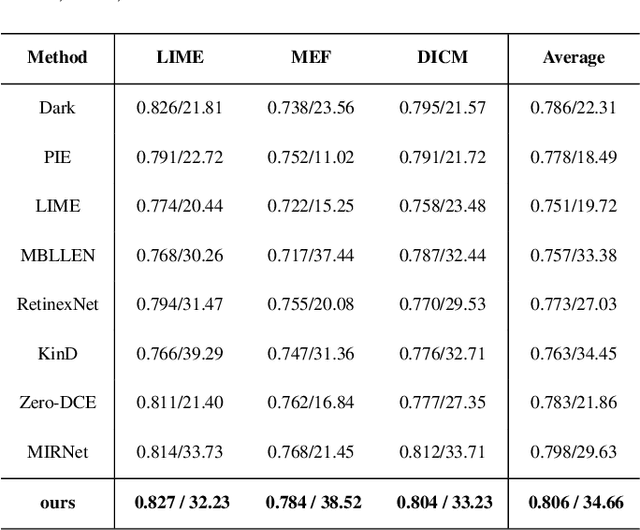
During the past years,deep convolutional neural networks have achieved impressive success in low-light Image Enhancement.Existing deep learning methods mostly enhance the ability of feature extraction by stacking network structures and deepening the depth of the network.which causes more runtime cost on single image.In order to reduce inference time while fully extracting local features and global features.Inspired by SGN,we propose a Attention based Broadly self-guided network (ABSGN) for real world low-light image Enhancement.such a broadly strategy is able to handle the noise at different exposures.The proposed network is validated by many mainstream benchmark.Additional experimental results show that the proposed network outperforms most of state-of-the-art low-light image Enhancement solutions.
Towards Better Dermoscopic Image Feature Representation Learning for Melanoma Classification
Jul 15, 2022Deep learning-based melanoma classification with dermoscopic images has recently shown great potential in automatic early-stage melanoma diagnosis. However, limited by the significant data imbalance and obvious extraneous artifacts, i.e., the hair and ruler markings, discriminative feature extraction from dermoscopic images is very challenging. In this study, we seek to resolve these problems respectively towards better representation learning for lesion features. Specifically, a GAN-based data augmentation (GDA) strategy is adapted to generate synthetic melanoma-positive images, in conjunction with the proposed implicit hair denoising (IHD) strategy. Wherein the hair-related representations are implicitly disentangled via an auxiliary classifier network and reversely sent to the melanoma-feature extraction backbone for better melanoma-specific representation learning. Furthermore, to train the IHD module, the hair noises are additionally labeled on the ISIC2020 dataset, making it the first large-scale dermoscopic dataset with annotation of hair-like artifacts. Extensive experiments demonstrate the superiority of the proposed framework as well as the effectiveness of each component. The improved dataset publicly avaliable at https://github.com/kirtsy/DermoscopicDataset.
Using Deep Learning to Improve Early Diagnosis of Pneumonia in Underdeveloped Countries
Oct 10, 2022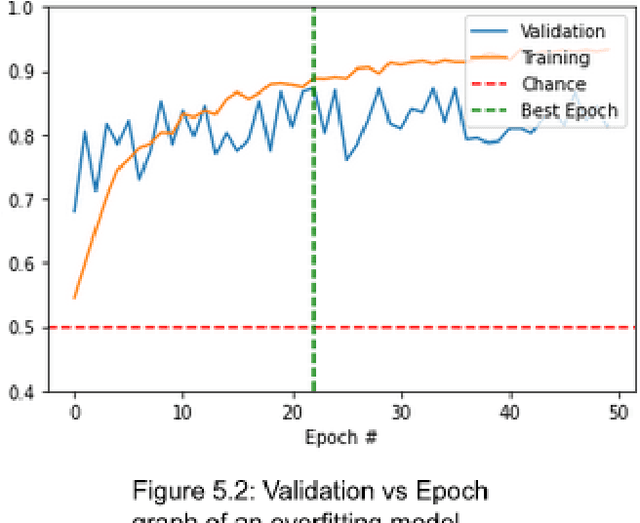
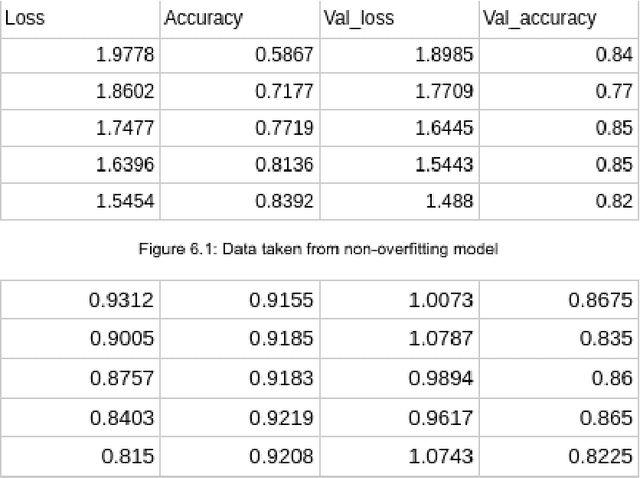
As advancements in technology and medicine are being made, many countries are still unable to access quality medical care due to cost and lack of qualified medical personnel. This discrepancy in healthcare has caused many preventable deaths, either due to lack of detection or lack of care. One of the most prevalent diseases in the world is pneumonia, an infection of the lungs that killed 2.56 million people worldwide in 2017. In this same year, the United States recorded a pneumonia death rate of 15.88 people per 100000 in population, while much of Sub-Saharan Africa, such as Chad and Guinea, experienced death rates of over 150 people per 100000. In sub-Saharan Africa, there is an extreme shortage of doctors and nurses, estimated to be around 2.4 million. The hypothesis being tested is that a deep learning model can receive input in the form of an x-ray and produce a diagnosis with the equivalent accuracy of a physician, compared to a prediagnosed image. The model used in this project is a modified convolutional neural network. The model was trained on a set of 2000 x-ray images that have predetermined normal and abnormal lung findings, and then tested on a set of 400 images that contains evenly split images of pneumonia and healthy lungs. For each computer-run test, data was collected on a base measurement of accuracy, as well as more specific metrics such as specificity and sensitivity. Results show that the algorithm tested was able to accurately identify abnormal lung findings an average of 82.5% of the time. The model achieved a maximum specificity of 98.5% and a maximum sensitivity of 90% separately, and the highest simultaneous values of these two metrics was a sensitivity of 90% and a specificity of 78.5%. This research can be further improved by testing other deep learning models as well as machine learning models to improve the metric scores and chance of correct diagnoses.
Multi-Scale Single Image Dehazing Using Laplacian and Gaussian Pyramids
Nov 10, 2021



Model driven single image dehazing was widely studied on top of different priors due to its extensive applications. Ambiguity between object radiance and haze and noise amplification in sky regions are two inherent problems of model driven single image dehazing. In this paper, a dark direct attenuation prior (DDAP) is proposed to address the former problem. A novel haze line averaging is proposed to reduce the morphological artifacts caused by the DDAP which enables a weighted guided image filter with a smaller radius to further reduce the morphological artifacts while preserve the fine structure in the image. A multi-scale dehazing algorithm is then proposed to address the latter problem by adopting Laplacian and Guassian pyramids to decompose the hazy image into different levels and applying different haze removal and noise reduction approaches to restore the scene radiance at different levels of the pyramid. The resultant pyramid is collapsed to restore a haze-free image. Experiment results demonstrate that the proposed algorithm outperforms state of the art dehazing algorithms and the noise is indeed prevented from being amplified in the sky region.
Extrapolating from a Single Image to a Thousand Classes using Distillation
Dec 01, 2021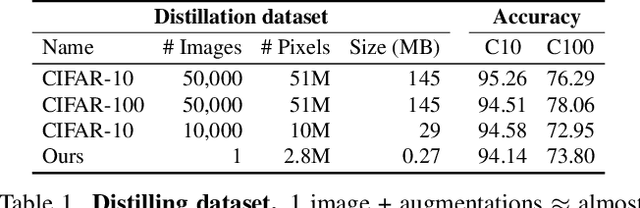

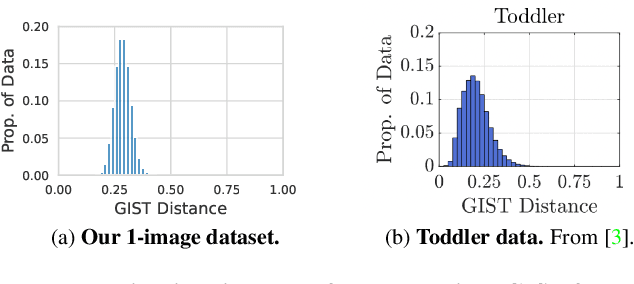

What can neural networks learn about the visual world from a single image? While it obviously cannot contain the multitudes of possible objects, scenes and lighting conditions that exist - within the space of all possible 256^(3x224x224) 224-sized square images, it might still provide a strong prior for natural images. To analyze this hypothesis, we develop a framework for training neural networks from scratch using a single image by means of knowledge distillation from a supervisedly pretrained teacher. With this, we find that the answer to the above question is: 'surprisingly, a lot'. In quantitative terms, we find top-1 accuracies of 94%/74% on CIFAR-10/100, 59% on ImageNet and, by extending this method to audio, 84% on SpeechCommands. In extensive analyses we disentangle the effect of augmentations, choice of source image and network architectures and also discover "panda neurons" in networks that have never seen a panda. This work shows that one image can be used to extrapolate to thousands of object classes and motivates a renewed research agenda on the fundamental interplay of augmentations and image.
Zero-Shot Image-to-Text Generation for Visual-Semantic Arithmetic
Nov 29, 2021
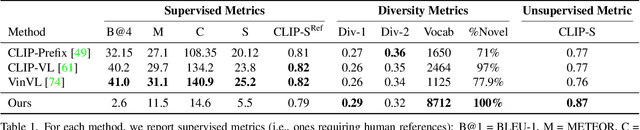
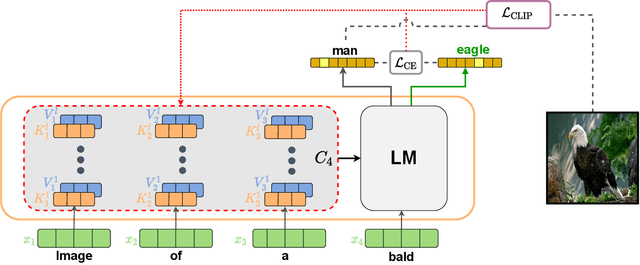

Recent text-to-image matching models apply contrastive learning to large corpora of uncurated pairs of images and sentences. While such models can provide a powerful score for matching and subsequent zero-shot tasks, they are not capable of generating caption given an image. In this work, we repurpose such models to generate a descriptive text given an image at inference time, without any further training or tuning step. This is done by combining the visual-semantic model with a large language model, benefiting from the knowledge in both web-scale models. The resulting captions are much less restrictive than those obtained by supervised captioning methods. Moreover, as a zero-shot learning method, it is extremely flexible and we demonstrate its ability to perform image arithmetic in which the inputs can be either images or text and the output is a sentence. This enables novel high-level vision capabilities such as comparing two images or solving visual analogy tests.
MBW: Multi-view Bootstrapping in the Wild
Oct 04, 2022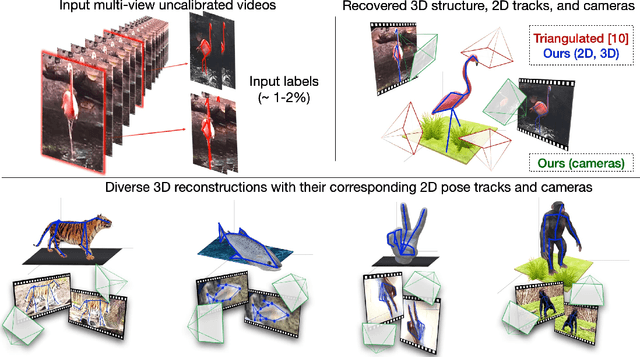
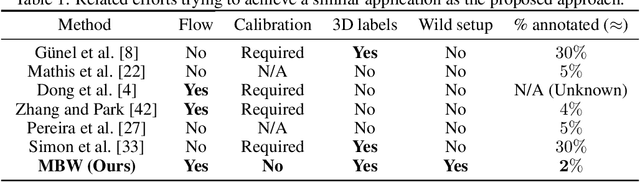
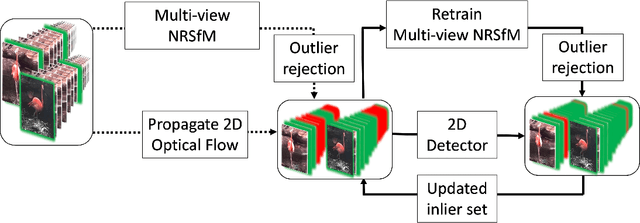
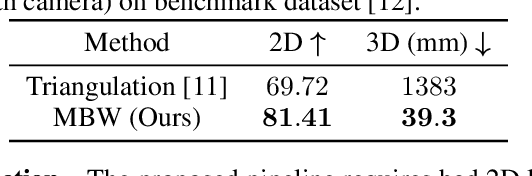
Labeling articulated objects in unconstrained settings have a wide variety of applications including entertainment, neuroscience, psychology, ethology, and many fields of medicine. Large offline labeled datasets do not exist for all but the most common articulated object categories (e.g., humans). Hand labeling these landmarks within a video sequence is a laborious task. Learned landmark detectors can help, but can be error-prone when trained from only a few examples. Multi-camera systems that train fine-grained detectors have shown significant promise in detecting such errors, allowing for self-supervised solutions that only need a small percentage of the video sequence to be hand-labeled. The approach, however, is based on calibrated cameras and rigid geometry, making it expensive, difficult to manage, and impractical in real-world scenarios. In this paper, we address these bottlenecks by combining a non-rigid 3D neural prior with deep flow to obtain high-fidelity landmark estimates from videos with only two or three uncalibrated, handheld cameras. With just a few annotations (representing 1-2% of the frames), we are able to produce 2D results comparable to state-of-the-art fully supervised methods, along with 3D reconstructions that are impossible with other existing approaches. Our Multi-view Bootstrapping in the Wild (MBW) approach demonstrates impressive results on standard human datasets, as well as tigers, cheetahs, fish, colobus monkeys, chimpanzees, and flamingos from videos captured casually in a zoo. We release the codebase for MBW as well as this challenging zoo dataset consisting image frames of tail-end distribution categories with their corresponding 2D, 3D labels generated from minimal human intervention.
Liquid Structural State-Space Models
Sep 26, 2022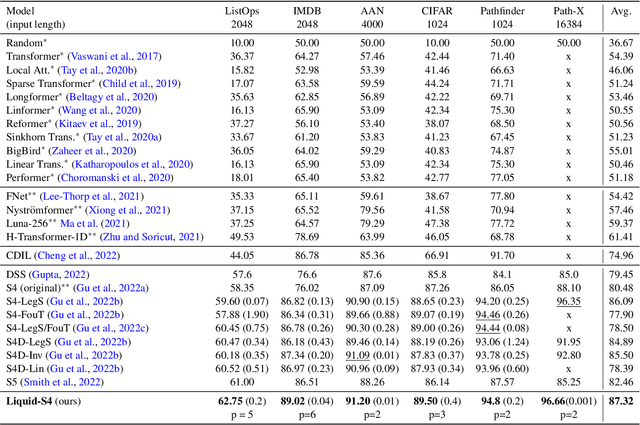
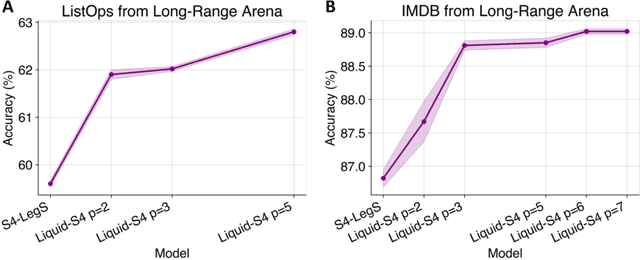
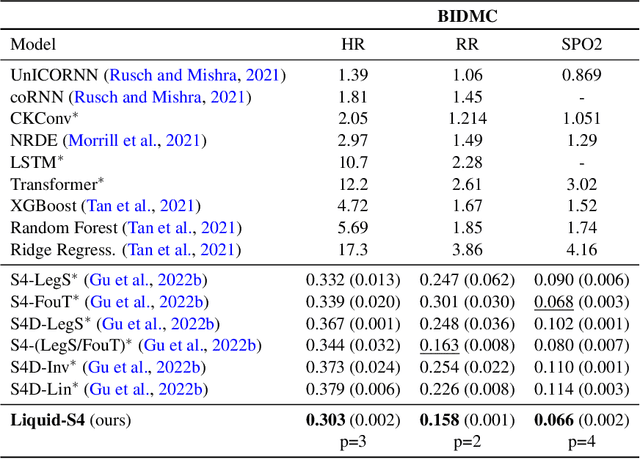
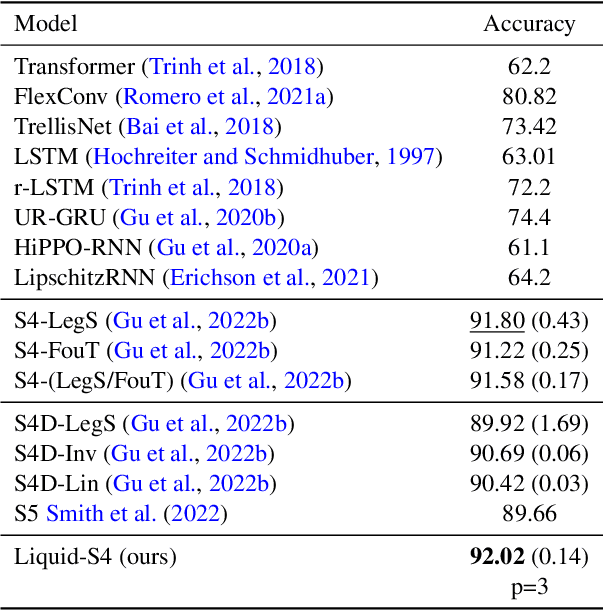
A proper parametrization of state transition matrices of linear state-space models (SSMs) followed by standard nonlinearities enables them to efficiently learn representations from sequential data, establishing the state-of-the-art on a large series of long-range sequence modeling benchmarks. In this paper, we show that we can improve further when the structural SSM such as S4 is given by a linear liquid time-constant (LTC) state-space model. LTC neural networks are causal continuous-time neural networks with an input-dependent state transition module, which makes them learn to adapt to incoming inputs at inference. We show that by using a diagonal plus low-rank decomposition of the state transition matrix introduced in S4, and a few simplifications, the LTC-based structural state-space model, dubbed Liquid-S4, achieves the new state-of-the-art generalization across sequence modeling tasks with long-term dependencies such as image, text, audio, and medical time-series, with an average performance of 87.32% on the Long-Range Arena benchmark. On the full raw Speech Command recognition, dataset Liquid-S4 achieves 96.78% accuracy with a 30% reduction in parameter counts compared to S4. The additional gain in performance is the direct result of the Liquid-S4's kernel structure that takes into account the similarities of the input sequence samples during training and inference.